
Personalized Privacy Protection-Preserving Collaborative Filtering Algorithm for Recommendation Systems

Abstract
1. Introduction
2. Collaborative Filtering Algorithm Based on Personalized Privacy Protection
2.1. Evaluation and Encoding of the Privacy Sensitivity of User Ratings
2.2. Differential Privacy Protection for Rating Data
2.3. Item-Item Similarity
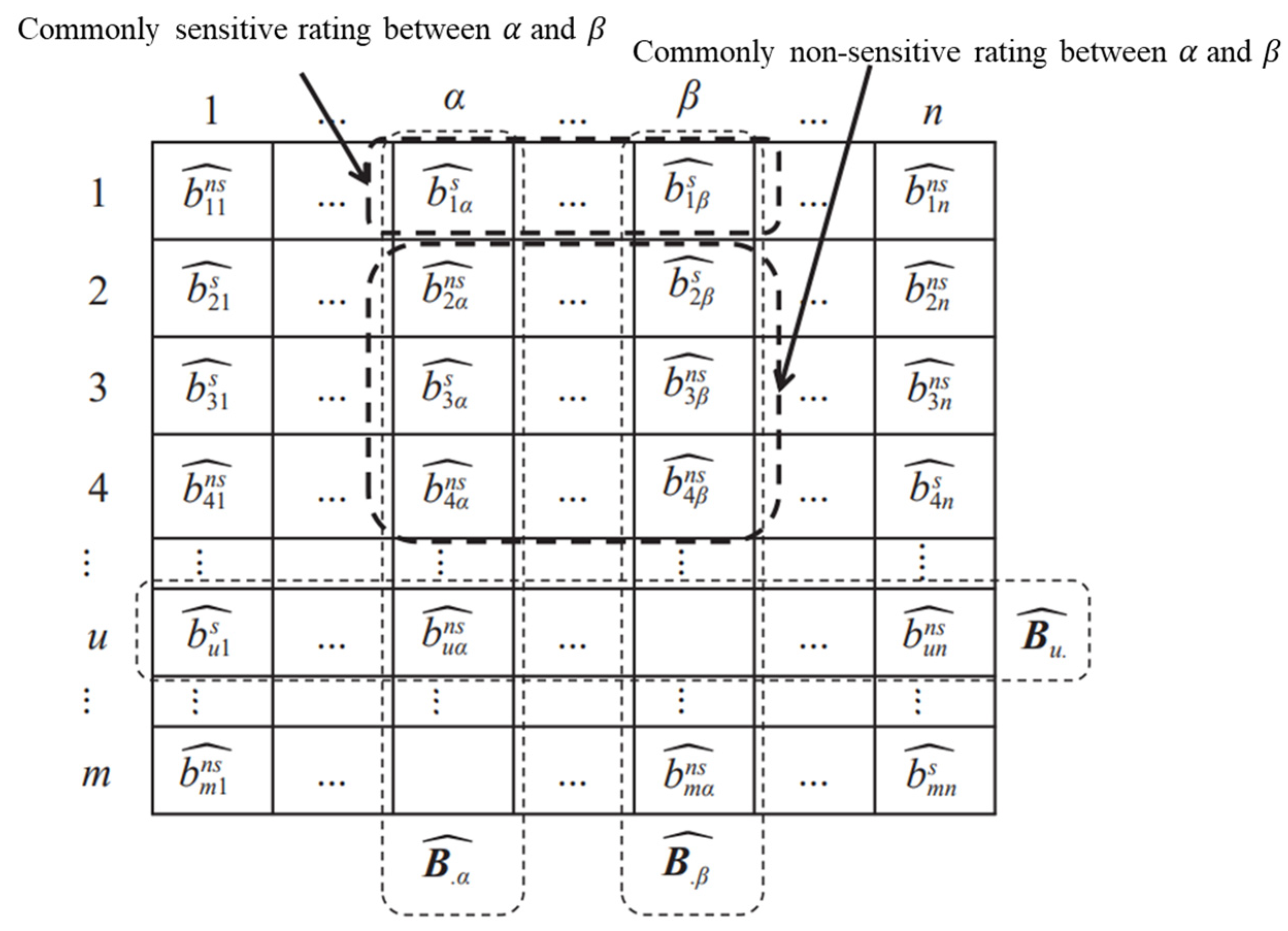
2.3.1. Similarity of the Sensitive Rating Pair
| Algorithm 1: Joint distribution estimation algorithm based on Bayesian method |
| Input: p,q;,;;,; |
| Output: |
| 1. Initialize ; |
| 2. for in |
| 3. for in |
| 4. Calculate the prior probability according to Formula 5; |
| 5. end for |
| 6. end for |
| 7. Initialize ;//The number of iteration executions |
| 8. while () |
| 9. for in |
| 10. for in |
| 11. Calculate the posteriori probability according to Formula 6; |
| 12. end for |
| 13. end for |
| 14. Calculate according to Formula 7; |
| 15. Update ; |
| 16. return ;//Return after the while loop ends |
2.3.2. Similarity of the Weakly Sensitive Rating Pair
2.4. Local Top-N Recommendation
3. Algorithmic Analysis
3.1. Analysis on Efficiency
3.2. Analysis on Security
4. Experimental Analysis
4.1. Algorithms for Comparison
4.2. Parameter Settings
4.3. Parameter Settings
4.3.1. Effect of N on Experimental Results
4.3.2. Effect of on Experimental Results
4.3.3. Algorithmic Efficiency
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wei, S.; Ye, N.; Zhang, S.; Huang, X.; Zhu, J. Item-Based Collaborative Filtering Recommendation Algorithm Combining Item Category with Interestingness Measure. In Proceedings of the 2012 International Conference on Computer Science and Service System, Nanjing, China, 11–13 August 2012; pp. 2038–2041. [Google Scholar]
- Su, X.; Khoshgoftaar, T.M. A Survey of Collaborative Filtering Techniques. Adv. Artif. Intell. 2009, 2009, 421425. [Google Scholar] [CrossRef]
- Kenthapadi, K.; Mironov, I.; Thakurta, A.G. Privacy-preserving Data Mining in Industry. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, VIC, Australia, 11–15 February 2019; pp. 840–841. [Google Scholar]
- Zhang, F.; Xue, E.; Guo, R.; Qu, G.; Zhao, G.; Zomaya, A.Y. DS-ADMM++: A Novel Distributed Quantized ADMM to Speed up Differentially Private Matrix Factorization. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 1289–1302. [Google Scholar] [CrossRef]
- Chen, C.; Wu, H.; Su, J.; Lyu, L.; Zheng, X.; Wang, L. Differential Private Knowledge Transfer for Privacy-Preserving Cross-Domain Recommendation. In Proceedings of the ACM Web Conference 2022, Virtual Event, Lyon, France, 25–29 April 2022; pp. 1455–1465. [Google Scholar]
- Zhao, Y.; Chen, J. A Survey on Differential Privacy for Unstructured Data Content. ACM Comput. Surv. 2022, 54, 207. [Google Scholar] [CrossRef]
- Zhu, X.; Sun, Y. Differential Privacy for Collaborative Filtering Recommender Algorithm. In Proceedings of the 2016 ACM on International Workshop on Security And Privacy Analytics, New Orleans, LA, USA, 11 March 2016; pp. 9–16. [Google Scholar]
- Ran, X.; Yin, E.; Wang, Y. Differential Privacy-Preserving Recommendation Algorithm Based on Bhattacharyya Coefficient Clustering. J. Beijing Univ. Posts Telecommun. 2021, 44, 81–88. [Google Scholar] [CrossRef]
- Fenske, E.; Mani, A.; Johnson, A.; Sherr, M. Accountable Private Set Cardinality for Distributed Measurement. ACM Trans. Priv. Secur. 2022, 25, 25. [Google Scholar] [CrossRef]
- Gao, C.; Huang, C.; Lin, D.; Jin, D.; Li, Y. DPLCF: Differentially Private Local Collaborative Filtering. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 961–970. [Google Scholar]
- Guo, T.; Luo, J.; Dong, K.; Yang, M. Locally differentially private item-based collaborative filtering. Inf. Sci. 2019, 502, 229–246. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, X.; Feng, J.; Yang, X. A Comprehensive Survey on Local Differential Privacy toward Data Statistics and Analysis. Sensors 2020, 20, 7030. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.; Wu, F.; Lyu, L.; Huang, Y.; Xie, X. FedCTR: Federated Native Ad CTR Prediction with Cross-platform User Behavior Data. ACM Trans. Intell. Syst. Technol. 2022, 13, 62. [Google Scholar] [CrossRef]
- Knijnenburg, B.P.; Berkovsky, S. Privacy for Recommender Systems: Tutorial Abstract. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 394–395. [Google Scholar]
- Chen, C.; Liu, Z.; Zhao, P.; Zhou, J.; Li, X. Privacy preserving point-of-interest recommendation using decentralized matrix factorization. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Meng, X.; Wang, S.; Shu, K.; Li, J.; Chen, B.; Liu, H.; Zhang, Y. Personalized privacy-preserving social recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Jalili, M.; Ahmadian, S.; Izadi, M.; Moradi, P.; Salehi, M. Evaluating collaborative filtering recommender algorithms: A survey. IEEE Access 2018, 6, 74003–74024. [Google Scholar] [CrossRef]
- Alhijawi, B.; Kilani, Y. A collaborative filtering recommender system using genetic algorithm. Inf. Process. Manag. 2020, 57, 102310. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Riedl, J. Explaining collaborative filtering recommendations. In Proceedings of the 2000 ACM Conference on Computer Supported Cooperative Work, Philadelphia, PA, USA, 2–6 December 2000; pp. 241–250. [Google Scholar]
- Koren, Y.; Rendle, S.; Bell, R. Advances in collaborative filtering. In Recommender Systems Handbook; Springer: New York, NY, USA, 2021; pp. 91–142. [Google Scholar]
- Miyahara, K.; Pazzani, M.J. Collaborative Filtering with the Simple Bayesian Classifier. In Proceedings of the PRICAI 2000 Topics in Artificial Intelligence, Melbourne, Australia, 28 August–1 September 2000; pp. 679–689. [Google Scholar]
- Wang, W.; Duan, L.-Y.; Jiang, H.; Jing, P.; Song, X.; Nie, L. Market2Dish: Health-aware food recommendation. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 33. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Users | Number of Items | Number of Ratings | Range of Ratings | Sparsity (%) |
|---|---|---|---|---|---|
| MovieLens 1M | 6000 | 4000 | 1,000,000 | {1,2,3,4,5} | 95.83 |
| Yahoo Music | 8089 | 1000 | 270,121 | {1,2,3,4,5} | 96.66 |
| Dataset | Indicator | Algorithm | N = 20 | N = 40 | N = 60 | N = 80 | N = 100 |
|---|---|---|---|---|---|---|---|
| MovieLens 1M | MAE | IBCF-DS | 0.7219 | 0.7176 | 0.7169 | 0.7170 | 0.7171 |
| DPLCF | 0.8912 | 0.8722 | 0.8718 | 0.8726 | 0.8694 | ||
| LDP item-base CF | 0.8666 | 0.8484 | 0.8407 | 0.8361 | 0.8330 | ||
| PNCF | 0.9600 | 0.9290 | 0.9110 | 0.8960 | 0.8870 | ||
| Truncated PPPCE | 0.8582 | 0.8527 | 0.8537 | 0.8502 | 0.8498 | ||
| PPPCE | 0.7911 | 0.7830 | 0.7783 | 0.7781 | 0.7798 | ||
| RMSE | IBCF-DS | 0.9288 | 0.9220 | 0.9208 | 0.9207 | 0.9208 | |
| DPLCF | 1.1284 | 1.1050 | 1.1049 | 1.1050 | 0.1021 | ||
| LDP item-base CF | 1.1217 | 1.0983 | 1.0888 | 1.0825 | 01.0784 | ||
| PNCF | 1.2470 | 1.2040 | 1.1790 | 1.160 | 1.1480 | ||
| Truncated PPPCE | 1.0944 | 1.0868 | 1.0883 | 1.0840 | 1.0837 | ||
| PPPCE | 1.0071 | 0.9974 | 0.9220 | 0.9913 | 0.9932 | ||
| Yahoo Music | MAE | IBCF-DS | 0.9482 | 0.9484 | 0.9484 | 0.9485 | 0.9486 |
| DPLCF | 1.0218 | 1.0243 | 1.0228 | 1.0235 | 1.0213 | ||
| LDP item-base CF | 1.0461 | 1.0438 | 1.0427 | 1.0433 | 1.0414 | ||
| PNCF | 1.0700 | 1.0620 | 1.0530 | 1.0389 | 1.0339 | ||
| Truncated PPPCE | 1.0052 | 1.0038 | 1.0014 | 1.0037 | 1.0026 | ||
| PPPCE | 0.9981 | 0.9980 | 0.9996 | 0.9989 | 0.9987 | ||
| RMSE | IBCF-DS | 1.2464 | 1.2449 | 1.2447 | 1.2446 | 1.2445 | |
| DPLCF | 1.2842 | 1.2827 | 1.2813 | 1.2813 | 1.2790 | ||
| LDP item-base CF | 1.3298 | 1.3257 | 1.3265 | 1.3260 | 1.3247 | ||
| PNCF | 1.5120 | 1.4950 | 1.4790 | 1.4500 | 1.4290 | ||
| Truncated PPPCE | 1.2830 | 1.2777 | 1.2756 | 1.2765 | 1.2751 | ||
| PPPCE | 1.2727 | 1.2689 | 1.2713 | 1.2699 | 1.2685 |
| Dataset | Runtime/s | DPLCF | LDP Item-Base CF | Truncated PPPCE | PPPCF |
|---|---|---|---|---|---|
| Yahoo Music | Local Data Processing | 2.36 | 2.55 | 1.78 | 1.83 |
| Similarity Calculation | 32.79 | 41.25 | 22.71 | 382.54 | |
| Rating Prediction | 53.47 | 52.80 | 47.59 | 57.39 | |
| MovieLens 1M | Local Data Processing | 8.22 | 8.62 | 7.79 | 7.71 |
| Similarity Calculation | 652.23 | 833.37 | 507.95 | 5497.68 | |
| Rating Prediction | 464.94 | 488.14 | 467.07 | 475.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, B.; Chen, P.; Zhang, X.; Fang, K.; Qin, X.; Liu, W. Personalized Privacy Protection-Preserving Collaborative Filtering Algorithm for Recommendation Systems. Appl. Sci. 2023, 13, 4600. https://doi.org/10.3390/app13074600
Cheng B, Chen P, Zhang X, Fang K, Qin X, Liu W. Personalized Privacy Protection-Preserving Collaborative Filtering Algorithm for Recommendation Systems. Applied Sciences. 2023; 13(7):4600. https://doi.org/10.3390/app13074600
Chicago/Turabian StyleCheng, Bin, Ping Chen, Xin Zhang, Keyu Fang, Xiaoli Qin, and Wei Liu. 2023. "Personalized Privacy Protection-Preserving Collaborative Filtering Algorithm for Recommendation Systems" Applied Sciences 13, no. 7: 4600. https://doi.org/10.3390/app13074600
APA StyleCheng, B., Chen, P., Zhang, X., Fang, K., Qin, X., & Liu, W. (2023). Personalized Privacy Protection-Preserving Collaborative Filtering Algorithm for Recommendation Systems. Applied Sciences, 13(7), 4600. https://doi.org/10.3390/app13074600