


Integration of Multi-Branch GCNs Enhancing Aspect Sentiment Triplet Extraction

 , ,
, ,  , and
, and
Abstract
1. Introduction
- We propose a framework MBGCN to extract the aspect, opinion, and sentiment triplet from review sentences in an end-to-end fashion, which can avoid error propagation among different subtasks;
- We utilize a structure-biased BERT to improve the ability to extract abundant contextual information, which provides rich textual features for subsequent task-oriented operations;
- Our proposed MBGCN adopts four branch GCNs to integrate the semantic feature with four types of linguistic relations, including syntactic dependency type, part-of-speech combination, tree-based distance, and relative position distance of each word pair. Furthermore, a shallow interaction layer is introduced to output the final textual representation;
- The extensive experiments conducted on multiple ASTE datasets prove that the proposed MBGCN outperforms the mentioned SOTA baselines.
2. Related Works
2.1. Aspect-Based Sentiment Analysis
2.2. ASTE Methods
2.3. Application of GCN in ASTE
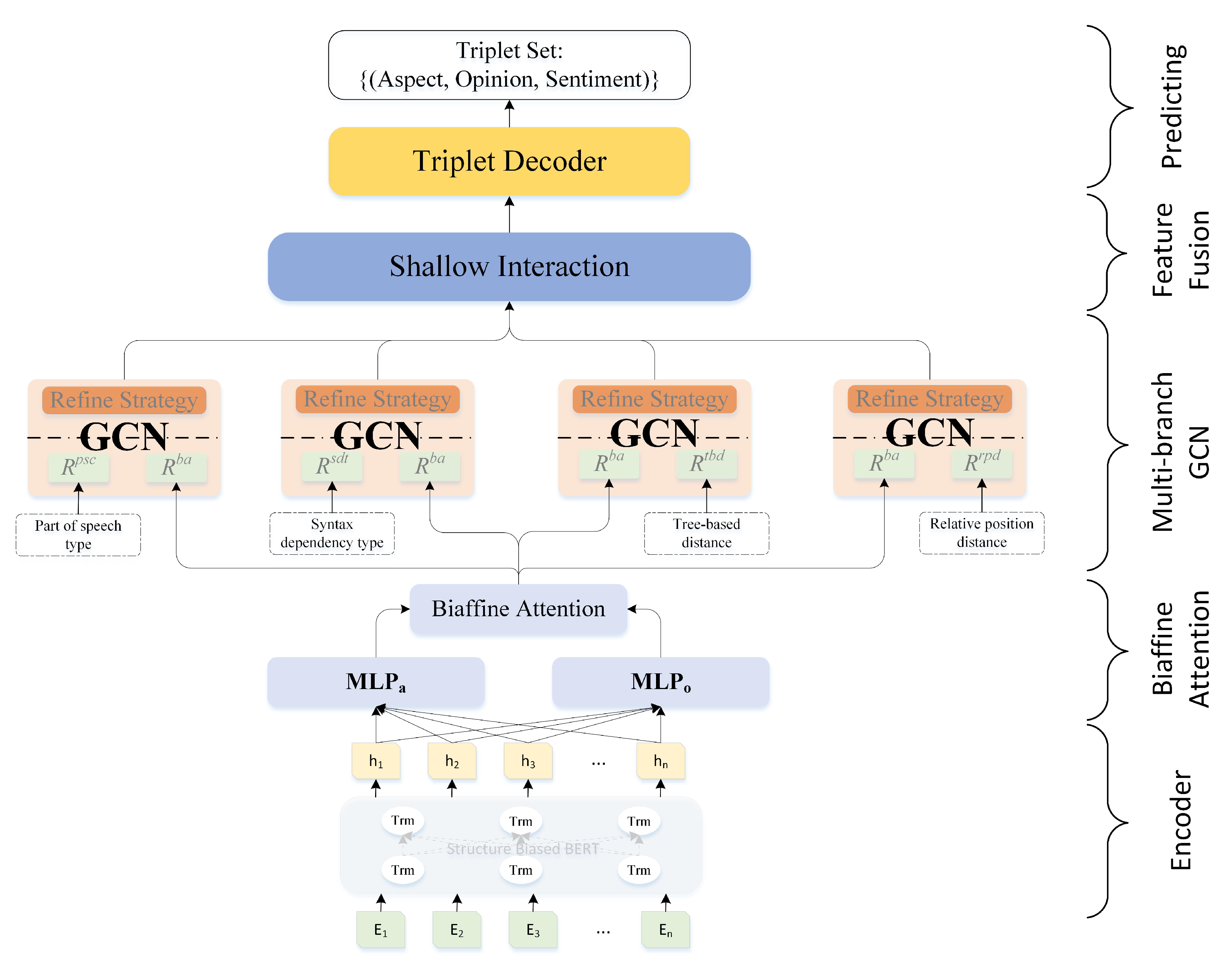
3. Framework of MBGCN
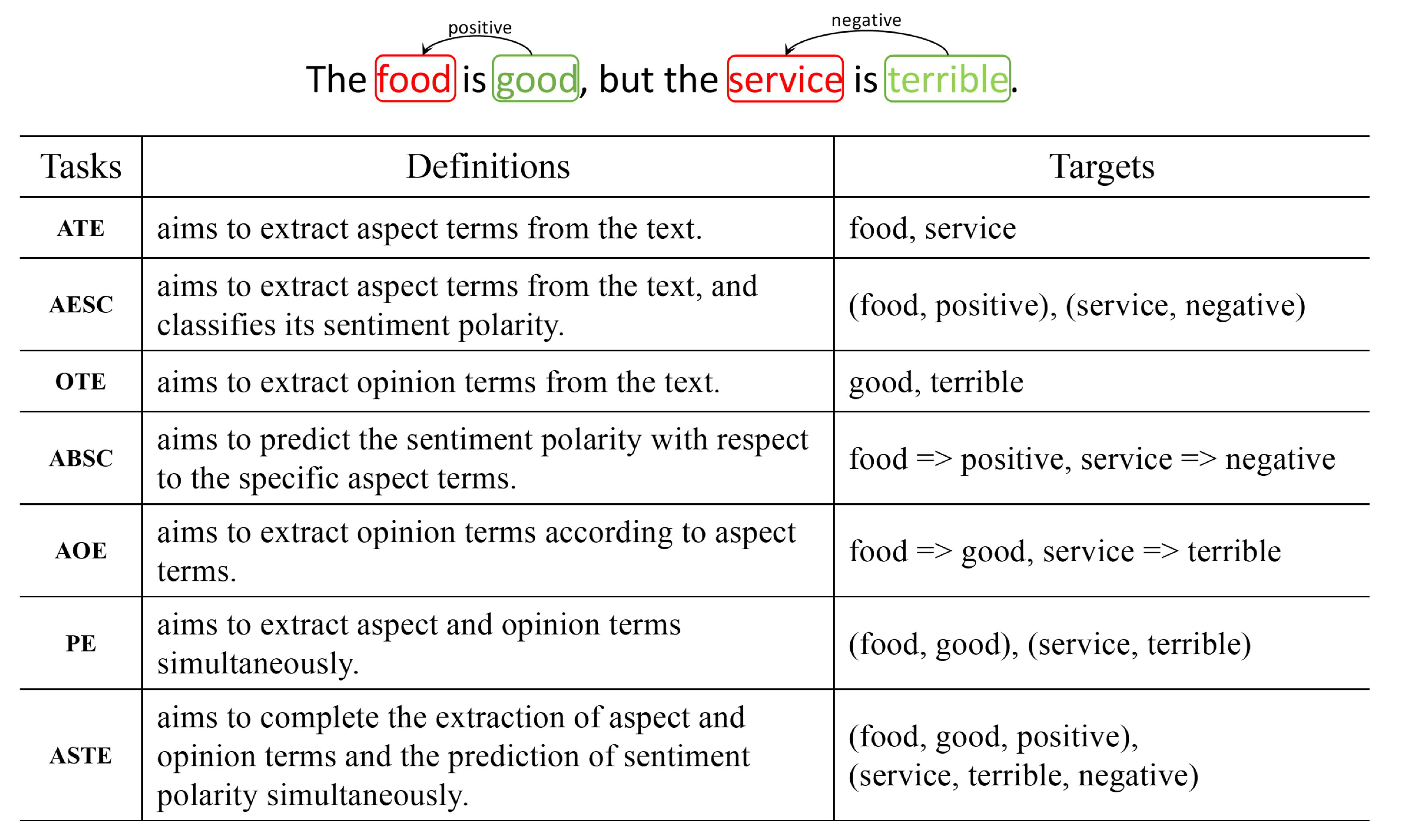
3.1. Task Formulation
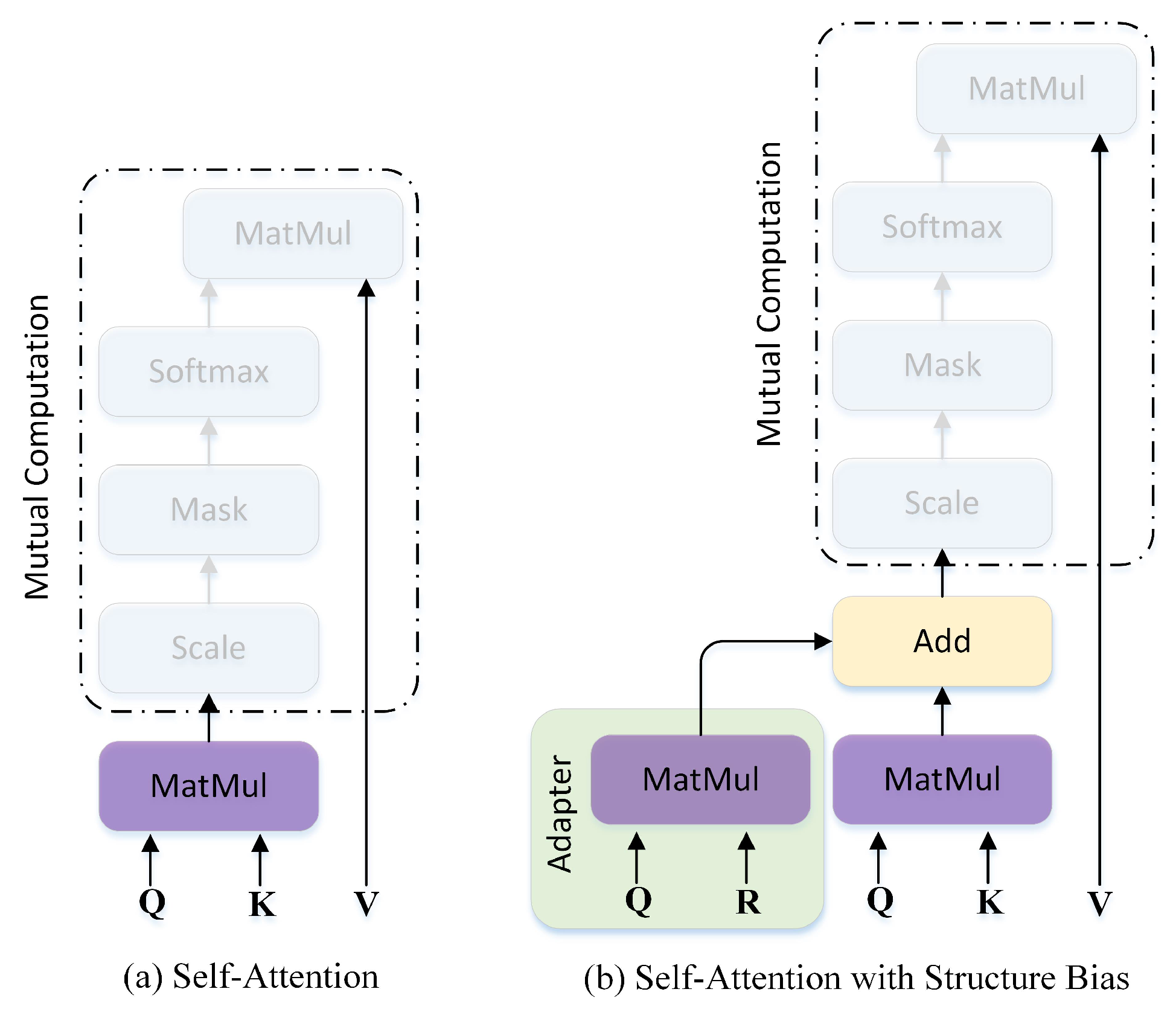
3.2. Embedding via Structure-Biased BERT
3.3. Biaffine Attention
3.4. Multi-Branch GCN
3.5. Shallow Interaction and Output Layer
3.6. Training
4. Experiments and Discussion
4.1. Datasets
4.2. Experimental Setup
4.3. Baselines
- GTS-BERT [56] proposes an end-to-end tagging scheme, Grid Tagging Scheme (GTS) with cooperation with BERT, to address the extraction task;
- GTS-CNN [56] is the Grid Tagging Scheme (GTS) that cooperates with CNN;
- GTS-BiLSTM [56] is the Grid Tagging Scheme (GTS) that cooperates with BiLSTM;
- SE [18] exploits the syntactic and semantic relationships between word pairs in a sentence by a graph-sequence dual representation and modeling paradigm for the ASTE task;
- Peng-two-stage [12] is a two-stage pipeline model. It extracts both aspect–sentiment pairs and opinion terms in the first stage, and pairs the extraction results into triplets in the second stage;
- OTE-MTL [59] treats the ABSA task as an opinion triplet extraction work, and jointly extracts aspect terms, opinion terms, and parses their sentiment via a multi-task learning framework;
- JET-BERT [22] builds a joint model to extract the triplets using a position-aware tagging approach, which is capable of jointly extracting aspect terms, opinion terms, and their sentiment together;
- BMRC [16] transforms the ASTE task into a Multi-Turn Machine Reading Comprehension (MTMRC) task, and three types of queries are devised to handle the related inputs;
- EMC-GCN [23] transforms the sentence into a multi-channel graph by treating words and edges as nodes and edges, respectively, while ten types of relations for ASTE are defined;
- MuG-Bert [24] proposes an approach, Multi-task learning with Grid decoding (MuG), to integrate the multi-task learning framework with grid triplets decoding from GTS;
- UniASTE [11] proposes an end-to-end method that decomposes ASTE into three subtasks, namely target tagging, opinion tagging, and sentiment tagging. Furthermore, a target-aware tagging scheme is introduced to identify the correspondences between opinion targets and opinion expressions;
- Dual-MRC [15] solves the ASTE task via constructing two machine reading comprehension problems, and trains two BERT-MRC models jointly with parameters sharing.
4.4. Main Results
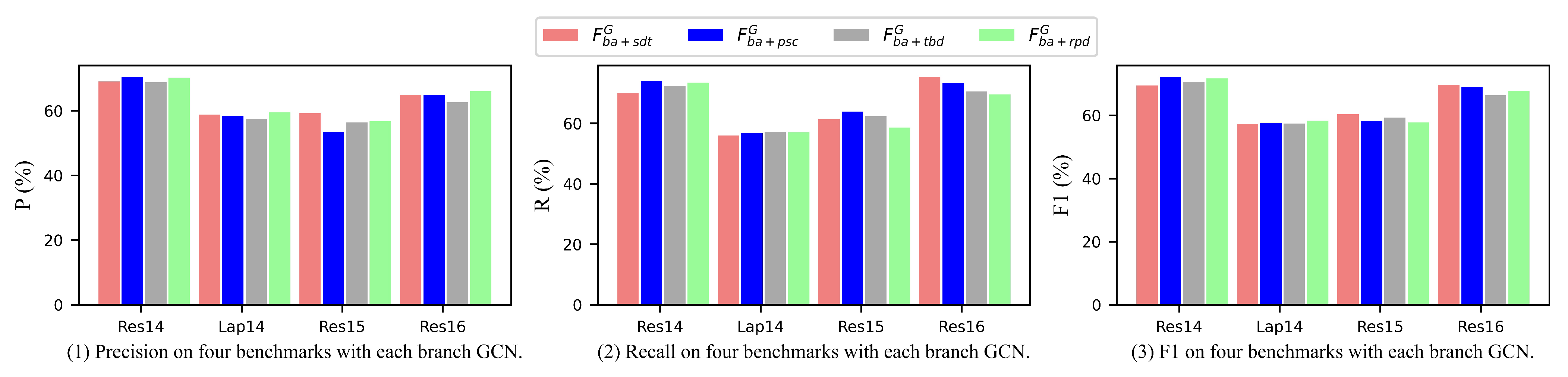
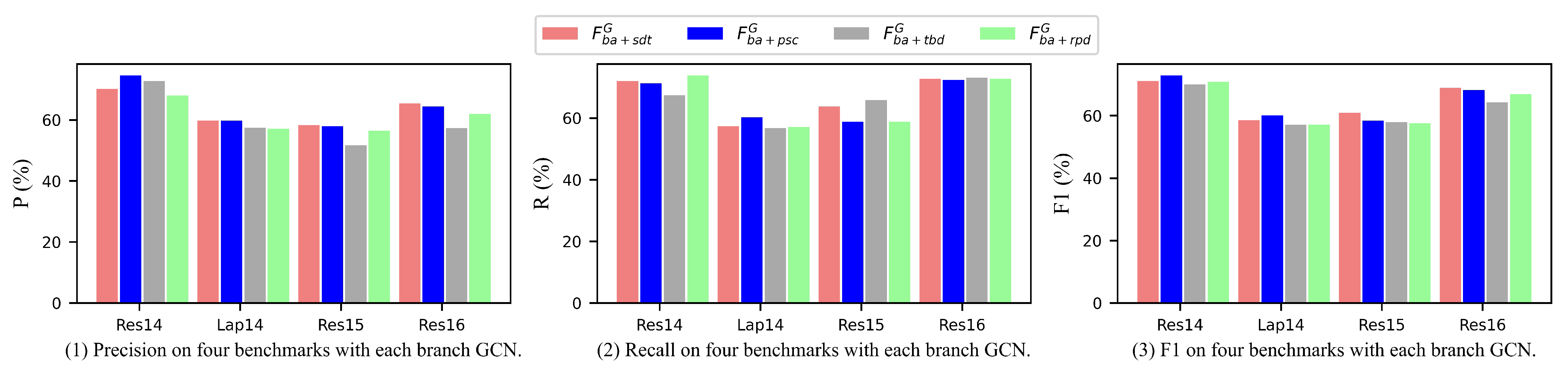
4.5. Ablation Study
- Is the contribution of each linguistic feature equal?
- Does the structure-biased BERT promote the performance of the MBGCN on the ASTE task?
4.5.1. Effect of Each Linguistic Feature
4.5.2. Effect of Adapter BERT
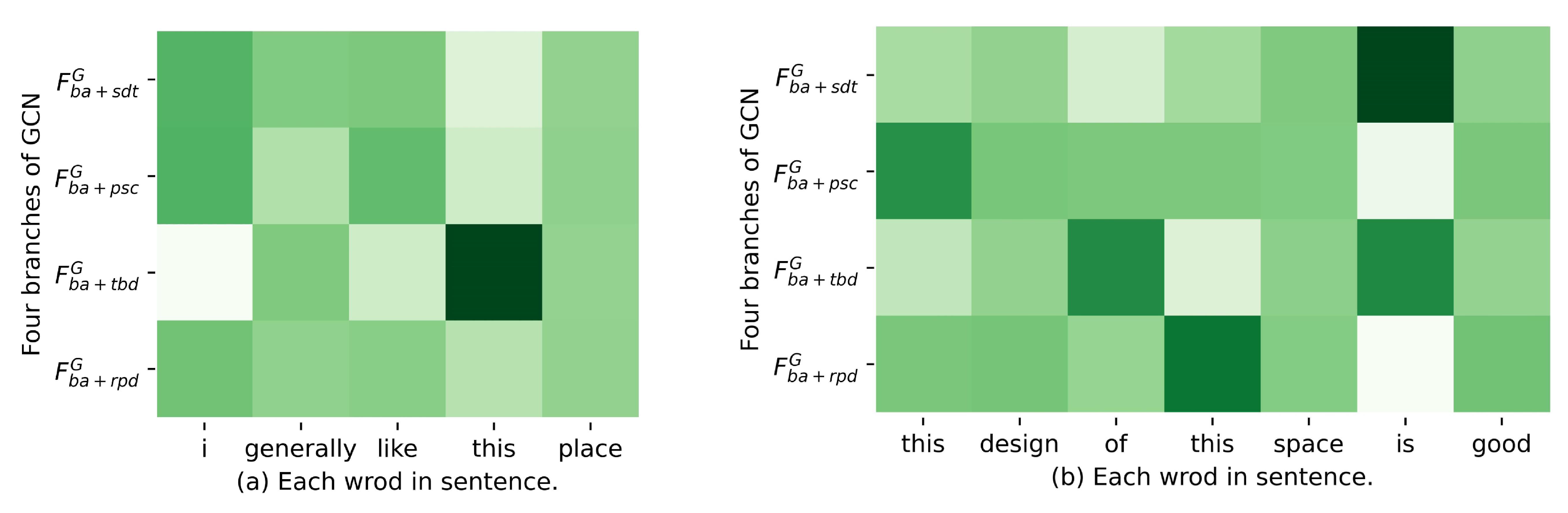
4.6. Case Study
4.7. Attempts via Prompt Learning
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Deng, J.; Ren, F. Multi-label Emotion Detection via Emotion-Specified Feature Extraction and Emotion Correlation Learning. IEEE Trans. Affect. Comput. 2020, 9, 162018–162034. [Google Scholar] [CrossRef]
- Liang, B.; Su, H.; Gui, L.; Cambria, E.; Xu, R. Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowl.-Based Syst. 2022, 235, 107643. [Google Scholar] [CrossRef]
- Zhao, A.; Yu, Y. Knowledge-enabled BERT for aspect-based sentiment analysis. Knowl.-Based Syst. 2021, 227, 107220. [Google Scholar] [CrossRef]
- Bie, Y.; Yang, Y. A multitask multiview neural network for end-to-end aspect-based sentiment analysis. Big Data Min. Anal. 2021, 4, 195–207. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, J.; Ma, X.; Wen, H.; Fortino, G. Aspect-based sentiment analysis for user reviews. Cogn. Comput. 2021, 13, 1114–1127. [Google Scholar] [CrossRef]
- Zhao, H.; Huang, L.; Zhang, R.; Lu, Q.; Xue, H. Spanmlt: A span-based multi-task learning framework for pair-wise aspect and opinion terms extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3239–3248. [Google Scholar]
- Akhtar, M.S.; Garg, T.; Ekbal, A. Multi-task learning for aspect term extraction and aspect sentiment classification. Neurocomputing 2020, 398, 247–256. [Google Scholar] [CrossRef]
- Xu, Q.; Zhu, L.; Dai, T.; Yan, C. Aspect-based sentiment classification with multi-attention network. Neurocomputing 2020, 388, 135–143. [Google Scholar] [CrossRef]
- Ying, C.; Wu, Z.; Dai, X.; Huang, S.; Chen, J. Opinion transmission network for jointly improving aspect-oriented opinion words extraction and sentiment classification. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Zhengzhou, China, 14–18 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 629–640. [Google Scholar]
- Li, Z.; Li, Q.; Zou, X.; Ren, J. Causality extraction based on self-attentive BiLSTM-CRF with transferred embeddings. Neurocomputing 2021, 423, 207–219. [Google Scholar] [CrossRef]
- Chen, F.; Yang, Z.; Huang, Y. A multi-task learning framework for end-to-end aspect sentiment triplet extraction. Neurocomputing 2022, 479, 12–21. [Google Scholar] [CrossRef]
- Peng, H.; Xu, L.; Bing, L.; Huang, F.; Lu, W.; Si, L. Knowing what, how and why: A near complete solution for aspect-based sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8600–8607. [Google Scholar]
- Xu, L.; Chia, Y.K.; Bing, L. Learning Span-Level Interactions for Aspect Sentiment Triplet Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Virtual, 1–6 August 2021; pp. 4755–4766. [Google Scholar]
- Yu Bai Jian, S.; Nayak, T.; Majumder, N.; Poria, S. Aspect sentiment triplet extraction using reinforcement learning. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2021; pp. 3603–3607. [Google Scholar]
- Mao, Y.; Shen, Y.; Yu, C.; Cai, L. A joint training dual-mrc framework for aspect based sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 13543–13551. [Google Scholar]
- Chen, S.; Wang, Y.; Liu, J.; Wang, Y. Bidirectional machine reading comprehension for aspect sentiment triplet extraction. In Proceedings of the AAAI Conference On Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 12666–12674. [Google Scholar]
- Yan, H.; Dai, J.; Ji, T.; Qiu, X.; Zhang, Z. A Unified Generative Framework for Aspect-based Sentiment Analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Virtual, 1–6 August 2021; pp. 2416–2429. [Google Scholar]
- Chen, Z.; Huang, H.; Liu, B.; Shi, X.; Jin, H. Semantic and Syntactic Enhanced Aspect Sentiment Triplet Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 1474–1483. [Google Scholar]
- Wu, S.; Li, B.; Xie, D.; Teng, C.; Ji, D. Neural transition model for aspect-based sentiment triplet extraction with triplet memory. Neurocomputing 2021, 463, 45–58. [Google Scholar] [CrossRef]
- Zhao, Y.; Meng, K.; Liu, G.; Du, J.; Zhu, H. A Multi-Task Dual-Tree Network for Aspect Sentiment Triplet Extraction. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 7065–7074. [Google Scholar]
- Shi, L.; Han, D.; Han, J.; Qiao, B.; Wu, G. Dependency graph enhanced interactive attention network for aspect sentiment triplet extraction. Neurocomputing 2022, 507, 315–324. [Google Scholar] [CrossRef]
- Xu, L.; Li, H.; Lu, W.; Bing, L. Position-Aware Tagging for Aspect Sentiment Triplet Extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual, 16–20 November 2020; pp. 2339–2349. [Google Scholar]
- Chen, H.; Zhai, Z.; Feng, F.; Li, R.; Wang, X. Enhanced Multi-Channel Graph Convolutional Network for Aspect Sentiment Triplet Extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 2974–2985. [Google Scholar]
- Zhang, C.; Ren, L.; Ma, F.; Wang, J.; Wu, W.; Song, D. Structural Bias for Aspect Sentiment Triplet Extraction. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 6736–6745. [Google Scholar]
- Tang, F.; Fu, L.; Yao, B.; Xu, W. Aspect based fine-grained sentiment analysis for online reviews. Inf. Sci. 2019, 488, 190–204. [Google Scholar] [CrossRef]
- Xiao, L.; Xue, Y.; Wang, H.; Hu, X.; Gu, D.; Zhu, Y. Exploring fine-grained syntactic information for aspect-based sentiment classification with dual graph neural networks. Neurocomputing 2022, 471, 48–59. [Google Scholar] [CrossRef]
- Consoli, S.; Barbaglia, L.; Manzan, S. Fine-grained, aspect-based sentiment analysis on economic and financial lexicon. Knowl.-Based Syst. 2022, 247, 108781. [Google Scholar] [CrossRef]
- Phan, M.H.; Ogunbona, P.O. Modelling context and syntactical features for aspect-based sentiment analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3211–3220. [Google Scholar]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational Graph Attention Network for Aspect-based Sentiment Analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3229–3238. [Google Scholar]
- Zhang, B.; Xu, D.; Zhang, H.; Li, M. STCS lexicon: Spectral-clustering-based topic-specific Chinese sentiment lexicon construction for social networks. IEEE Trans. Comput. Soc. Syst. 2019, 6, 1180–1189. [Google Scholar] [CrossRef]
- Kiritchenko, S.; Zhu, X.; Cherry, C.; Mohammad, S. NRC-Canada-2014: Detecting aspects and sentiment in customer reviews. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; pp. 437–442. [Google Scholar]
- Dai, J.; Yan, H.; Sun, T.; Liu, P.; Qiu, X. Does syntax matter? A strong baseline for Aspect-based Sentiment Analysis with RoBERTa. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Mexico City, Mexico, 6–11 June 2021; pp. 1816–1829. [Google Scholar]
- Zhang, Y.; Jin, R.; Zhou, Z.H. Understanding bag-of-words model: A statistical framework. Int. J. Mach. Learn. Cybern. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Tang, H.; Ji, D.; Li, C.; Zhou, Q. Dependency graph enhanced dual-transformer structure for aspect-based sentiment classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6578–6588. [Google Scholar]
- Xiao, Z.; Wu, J.; Chen, Q.; Deng, C. BERT4GCN: Using BERT Intermediate Layers to Augment GCN for Aspect-based Sentiment Classification. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 7–11 November 2021; pp. 9193–9200. [Google Scholar]
- Zhang, Z.; Zuo, Y.; Wu, J. Aspect Sentiment Triplet Extraction: A Seq2Seq Approach with Span Copy Enhanced Dual Decoder. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2729–2742. [Google Scholar] [CrossRef]
- Dai, D.; Chen, T.; Xia, S.; Wang, G.; Chen, Z. Double embedding and bidirectional sentiment dependence detector for aspect sentiment triplet extraction. Knowl.-Based Syst. 2022, 253, 109506. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, Z.; Zhou, G.; Sun, X.; Chen, K. Span-based dual-decoder framework for aspect sentiment triplet extraction. Neurocomputing 2022, 492, 211–221. [Google Scholar] [CrossRef]
- Mukherjee, R.; Nayak, T.; Butala, Y.; Bhattacharya, S.; Goyal, P. PASTE: A Tagging-Free Decoding Framework Using Pointer Networks for Aspect Sentiment Triplet Extraction. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 7–11 November 2021; pp. 9279–9291. [Google Scholar]
- Xu, K.; Li, F.; Xie, D.; Ji, D. Revisiting Aspect-Sentiment-Opinion Triplet Extraction: Detailed Analyses Towards a Simple and Effective Span-Based Model. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2918–2927. [Google Scholar] [CrossRef]
- Zhu, X.; Zhu, L.; Guo, J.; Liang, S.; Dietze, S. GL-GCN: Global and local dependency guided graph convolutional networks for aspect-based sentiment classification. Expert Syst. Appl. 2021, 186, 115712. [Google Scholar] [CrossRef]
- Cai, H.; Tu, Y.; Zhou, X.; Yu, J.; Xia, R. Aspect-category based sentiment analysis with hierarchical graph convolutional network. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 833–843. [Google Scholar]
- Feng, S.; Wang, B.; Yang, Z.; Ouyang, J. Aspect-based sentiment analysis with attention-assisted graph and variational sentence representation. Knowl.-Based Syst. 2022, 258, 109975. [Google Scholar] [CrossRef]
- Li, Y.; Lin, Y.; Lin, Y.; Chang, L.; Zhang, H. A span-sharing joint extraction framework for harvesting aspect sentiment triplets. Knowl.-Based Syst. 2022, 242, 108366. [Google Scholar] [CrossRef]
- Fei, H.; Ren, Y.; Zhang, Y.; Ji, D. Nonautoregressive Encoder-Decoder Neural Framework for End-to-End Aspect-Based Sentiment Triplet Extraction. IEEE Trans. Neural Netw. Learn. Syst. 2021; 1–13, early access. [Google Scholar] [CrossRef]
- Xu, H.; Shu, L.; Philip, S.Y.; Liu, B. Understanding Pre-trained BERT for Aspect-based Sentiment Analysis. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 244–250. [Google Scholar]
- Wu, Z.; Ong, D.C. Context-guided bert for targeted aspect-based sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 14094–14102. [Google Scholar]
- Zhu, L.; Xu, Y.; Zhu, Z.; Bao, Y.; Kong, X. Fine-Grained Sentiment-Controlled Text Generation Approach Based on Pre-Trained Language Model. Appl. Sci. 2022, 13, 264. [Google Scholar] [CrossRef]
- Mutinda, J.; Mwangi, W.; Okeyo, G. Sentiment Analysis of Text Reviews Using Lexicon-Enhanced Bert Embedding (LeBERT) Model with Convolutional Neural Network. Appl. Sci. 2023, 13, 1445. [Google Scholar] [CrossRef]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-Attention with Relative Position Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 2, (Short Papers). pp. 464–468. [Google Scholar]
- Wang, B.; Shin, R.; Liu, X.; Polozov, O.; Richardson, M. RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7567–7578. [Google Scholar]
- Dozat, T.; Manning, C.D. Deep Biaffine Attention for Neural Dependency Parsing. arXiv 2016, arXiv:1611.01734. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S. SemEval-2014 Task 4: Aspect Based Sentiment Analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Association for Computational Linguistics, Dublin, Ireland, 23–24 August 2014; pp. 27–35. [Google Scholar] [CrossRef]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Manandhar, S.; Androutsopoulos, I. SemEval-2015 Task 12: Aspect Based Sentiment Analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Association for Computational Linguistics, Denver, CO, USA, 4–5 June 2015; pp. 486–495. [Google Scholar] [CrossRef]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; AL-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; De Clercq, O.; et al. SemEval-2016 Task 5: Aspect Based Sentiment Analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), Association for Computational Linguistics, San Diego, CA, USA, 16–17 June 2016; pp. 19–30. [Google Scholar] [CrossRef]
- Wu, Z.; Ying, C.; Zhao, F.; Fan, Z.; Dai, X.; Xia, R. Grid Tagging Scheme for Aspect-oriented Fine-grained Opinion Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Punta Cana, Dominican Republic, 8–12 November 2020; pp. 2576–2585. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, USA, 2–7 June 2019; Volume 1, (Long and Short Papers). pp. 4171–4186. [Google Scholar]
- Fan, Z.; Wu, Z.; Dai, X.Y.; Huang, S.; Chen, J. Target-oriented Opinion Words Extraction with Target-fused Neural Sequence Labeling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; pp. 2509–2518. [Google Scholar] [CrossRef]
- Zhang, C.; Li, Q.; Song, D.; Wang, B. A Multi-task Learning Framework for Opinion Triplet Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Punta Cana, Dominican Republic, 8–12 November 2020; pp. 819–828. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. arXiv 2021, arXiv:2107.13586. [Google Scholar] [CrossRef]
- Petroni, F.; Rocktäschel, T.; Riedel, S.; Lewis, P.; Bakhtin, A.; Wu, Y.; Miller, A. Language Models as Knowledge Bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November2019; pp. 2463–2473. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Schick, T.; Schütze, H. Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Kiev, Ukraine, 19–23 April 2021; pp. 255–269. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Relation | Definition |
|---|---|---|
| 1 | B-A | beginning of aspect term. |
| 2 | I-A | inside of aspect term. |
| 3 | A | aspect term. |
| 4 | B-O | beginning of opinion term. |
| 5 | I-O | inside of opinion term. |
| 6 | O | opinion term. |
| 7 | POS | sentiment polarity is positive. |
| 8 | NEU | sentiment polarity is neutral. |
| 9 | NEG | sentiment polarity is negative. |
| 10 | N | belong to no aforementioned relations. |
| Datasets | Laptop14 | Restaurant14 | Restaurant15 | Restaurant16 | |||||
|---|---|---|---|---|---|---|---|---|---|
| #S | #T | #S | #T | #S | #T | #S | #T | ||
| train | 899 | 1452 | 1259 | 2356 | 603 | 1038 | 863 | 1421 | |
| dev | 225 | 383 | 315 | 580 | 151 | 239 | 216 | 348 | |
| test | 332 | 547 | 493 | 1008 | 325 | 493 | 328 | 525 | |
| train | 906 | 1460 | 1266 | 2338 | 605 | 1013 | 857 | 1394 | |
| dev | 219 | 346 | 310 | 577 | 148 | 249 | 210 | 339 | |
| test | 328 | 543 | 492 | 994 | 322 | 485 | 326 | 514 | |
| Models | Restaurant14 | Laptop14 | Restaurant15 | Restaurant16 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| Peng-two-stage+IOG© [56] | 58.89 | 60.41 | 59.64 | 48.62 | 45.52 | 47.02 | 51.70 | 46.04 | 48.71 | 59.25 | 58.09 | 58.67 |
| GTS-CNN© [56] | 70.79 | 61.71 | 65.94 | 55.93 | 47.52 | 51.38 | 60.09 | 53.57 | 56.64 | 62.63 | 66.98 | 64.73 |
| GTS-BiLSTM© [56] | 67.28 | 61.91 | 64.49 | 59.42 | 45.13 | 51.30 | 63.26 | 50.71 | 56.29 | 66.07 | 65.05 | 65.56 |
| GTS-BERT© [56] | 70.92 | 69.49 | 70.20 | 57.52 | 51.92 | 54.58 | 59.29 | 58.07 | 58.67 | 68.58 | 66.60 | 67.58 |
| SE© [18] | 69.08 | 64.55 | 66.74 | 59.43 | 46.23 | 52.01 | 61.06 | 56.44 | 58.66 | 71.08 | 63.13 | 66.87 |
| Dual-MRC© [15] | - | - | 70.32 | - | - | 55.58 | - | - | 57.21 | - | - | 67.40 |
| EMC-GCN [23] | 70.92 | 71.49 | 71.20 | 58.96 | 54.31 | 56.54 | 54.99 | 61.46 | 58.04 | 65.74 | 72.66 | 69.03 |
| MBGCN | 72.89 | 71.79 | 72.33 | 57.30 | 57.62 | 57.46 | 60.76 | 58.42 | 59.57 | 71.68 | 69.22 | 70.43 |
| Models | Restaurant14 | Laptop14 | Restaurant15 | Restaurant16 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| Peng-two-stage [12] | 43.24 | 63.66 | 51.46 | 37.38 | 50.38 | 42.87 | 48.07 | 57.51 | 52.32 | 46.96 | 64.24 | 54.21 |
| OTE-MTL [59] | 62.00 | 55.97 | 58.71 | 49.53 | 39.22 | 43.42 | 56.37 | 40.94 | 47.13 | 62.88 | 52.10 | 56.96 |
| JET-BERT [22] | 70.56 | 55.94 | 62.40 | 55.39 | 47.33 | 51.04 | 64.45 | 51.96 | 57.53 | 70.42 | 58.37 | 63.83 |
| BMRC [16] | 75.61 | 61.77 | 67.99 | 70.55 | 48.98 | 57.82 | 68.51 | 53.40 | 60.02 | 71.20 | 61.08 | 65.75 |
| EMC-GCN [23] | 70.35 | 73.14 | 71.72 | 61.48 | 55.45 | 58.31 | 56.33 | 63.30 | 59.61 | 62.46 | 72.32 | 67.03 |
| MuG-BERT© [24] | 68.40 | 67.64 | 68.00 | 58.30 | 52.21 | 55.06 | 60.65 | 54.12 | 57.10 | 66.26 | 67.39 | 66.74 |
| UniASTE [11] | 72.14 | 66.30 | 69.09 | 62.24 | 51.77 | 56.51 | 64.83 | 54.31 | 59.06 | 69.06 | 65.53 | 67.22 |
| MBGCN | 67.92 | 75.18 | 71.37 | 59.96 | 57.86 | 58.89 | 62.25 | 63.92 | 63.07 | 63.76 | 71.35 | 67.34 |
| Versions | Models | Restaurant14 | Laptop14 | Restaurant15 | Restaurant16 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | ||
| MBGCN | 72.89 | 71.79 | 72.33 | 57.30 | 57.62 | 57.46 | 60.76 | 58.42 | 59.57 | 71.68 | 69.22 | 70.43 | |
| Structure bias | 70.38 | 72.99 | 71.66 | 60.86 | 54.50 | 57.50 | 56.76 | 60.45 | 58.55 | 64.53 | 73.04 | 68.52 | |
| MBGCN | 67.92 | 75.18 | 71.37 | 59.96 | 57.86 | 58.89 | 62.25 | 63.92 | 63.07 | 63.76 | 71.35 | 67.34 | |
| Structure bias | 69.49 | 70.19 | 69.84 | 59.77 | 57.67 | 58.70 | 58.88 | 60.83 | 59.84 | 65.36 | 71.74 | 68.40 | |
| Versions | Models | Restaurant14 | Laptop14 | Restaurant15 | Restaurant16 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | ||
| MBGCN | 72.89 | 71.79 | 72.33 | 57.30 | 57.62 | 57.46 | 60.76 | 58.42 | 59.57 | 71.68 | 69.22 | 70.43 | |
| Prompts | 73.27 | 70.18 | 71.69 | 56.35 | 59.45 | 57.86 | 58.32 | 64.71 | 61.35 | 64.11 | 68.64 | 66.30 | |
| MBGCN | 67.92 | 75.18 | 71.37 | 59.96 | 57.86 | 58.89 | 62.25 | 63.92 | 63.07 | 63.76 | 71.35 | 67.34 | |
| Prompts | 73.63 | 71.31 | 72.46 | 58.93 | 56.75 | 57.82 | 64.68 | 62.68 | 63.67 | 65.96 | 72.90 | 69.26 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, X.; Hu, M.; Deng, J.; Ren, F.; Shi, P.; Yang, J. Integration of Multi-Branch GCNs Enhancing Aspect Sentiment Triplet Extraction. Appl. Sci. 2023, 13, 4345. https://doi.org/10.3390/app13074345
Shi X, Hu M, Deng J, Ren F, Shi P, Yang J. Integration of Multi-Branch GCNs Enhancing Aspect Sentiment Triplet Extraction. Applied Sciences. 2023; 13(7):4345. https://doi.org/10.3390/app13074345
Chicago/Turabian StyleShi, Xuefeng, Min Hu, Jiawen Deng, Fuji Ren, Piao Shi, and Jiaoyun Yang. 2023. "Integration of Multi-Branch GCNs Enhancing Aspect Sentiment Triplet Extraction" Applied Sciences 13, no. 7: 4345. https://doi.org/10.3390/app13074345
APA StyleShi, X., Hu, M., Deng, J., Ren, F., Shi, P., & Yang, J. (2023). Integration of Multi-Branch GCNs Enhancing Aspect Sentiment Triplet Extraction. Applied Sciences, 13(7), 4345. https://doi.org/10.3390/app13074345