
Prediction and Optimization of Matte Grade in ISA Furnace Based on GA-BP Neural Network


Abstract
1. Introduction
2. Model
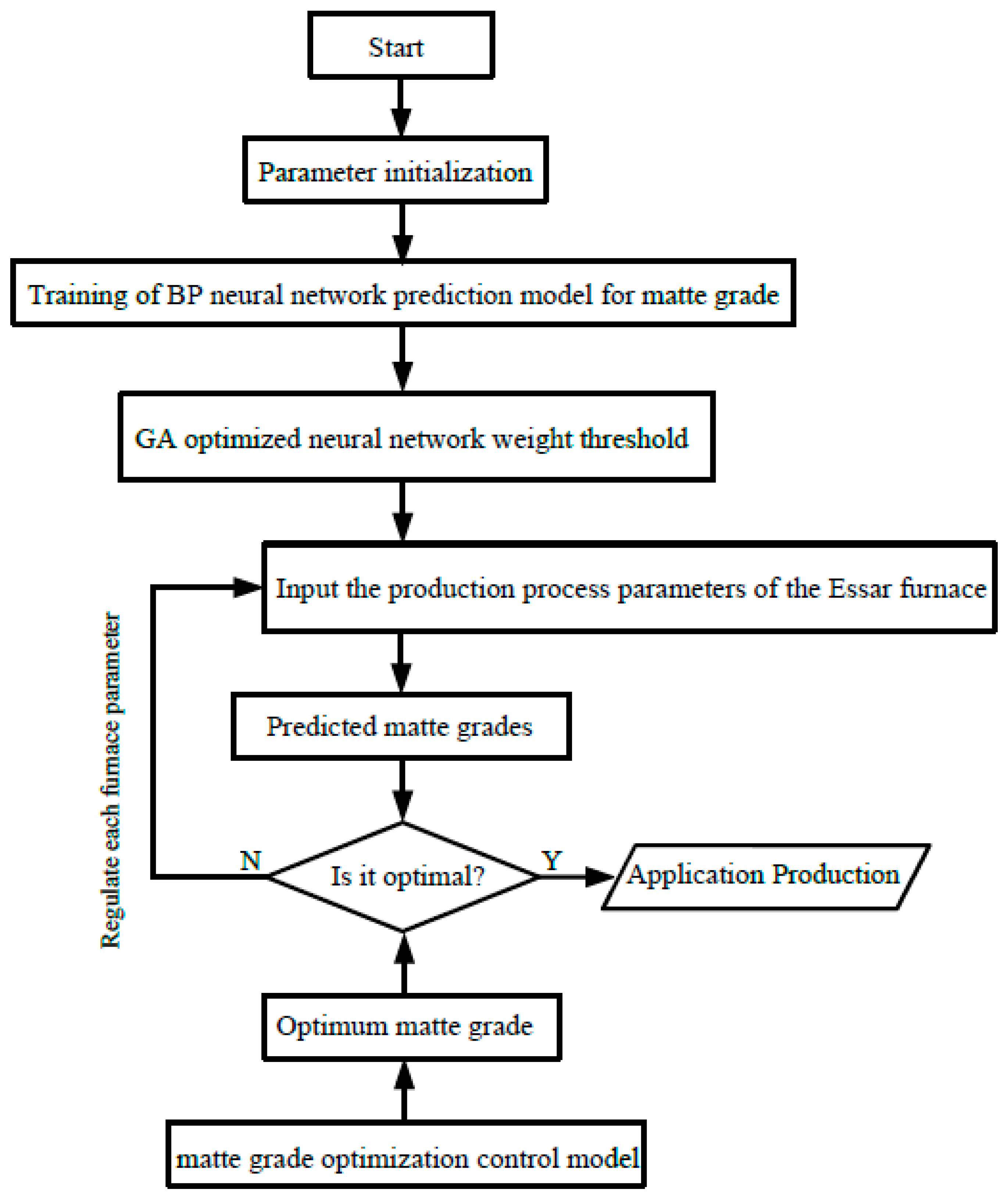
2.1. Matte-Grade Optimization Control Model
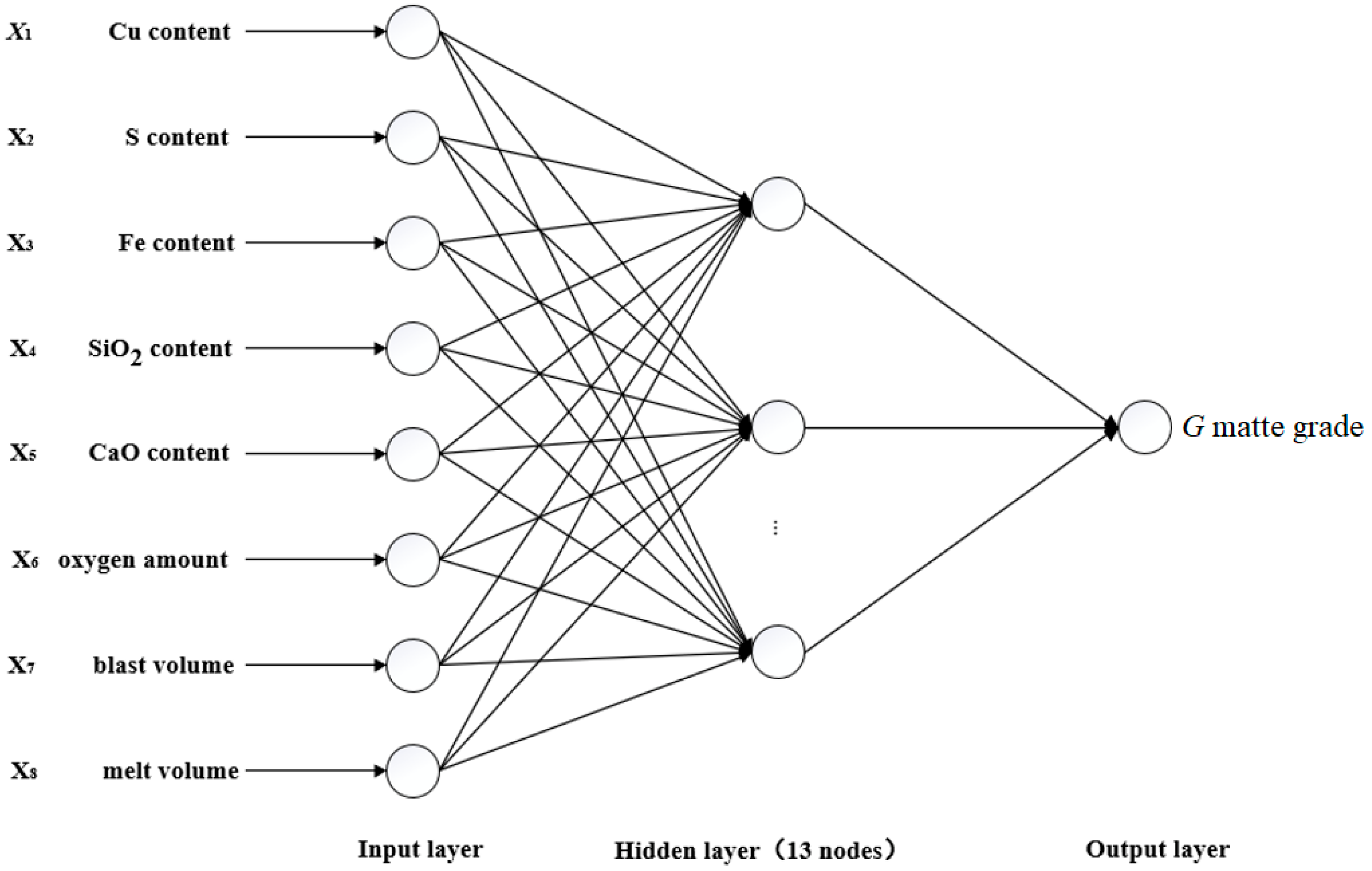
2.2. Matte-Grade Prediction Model Based on BP Neural Network
2.2.1. Model Structure
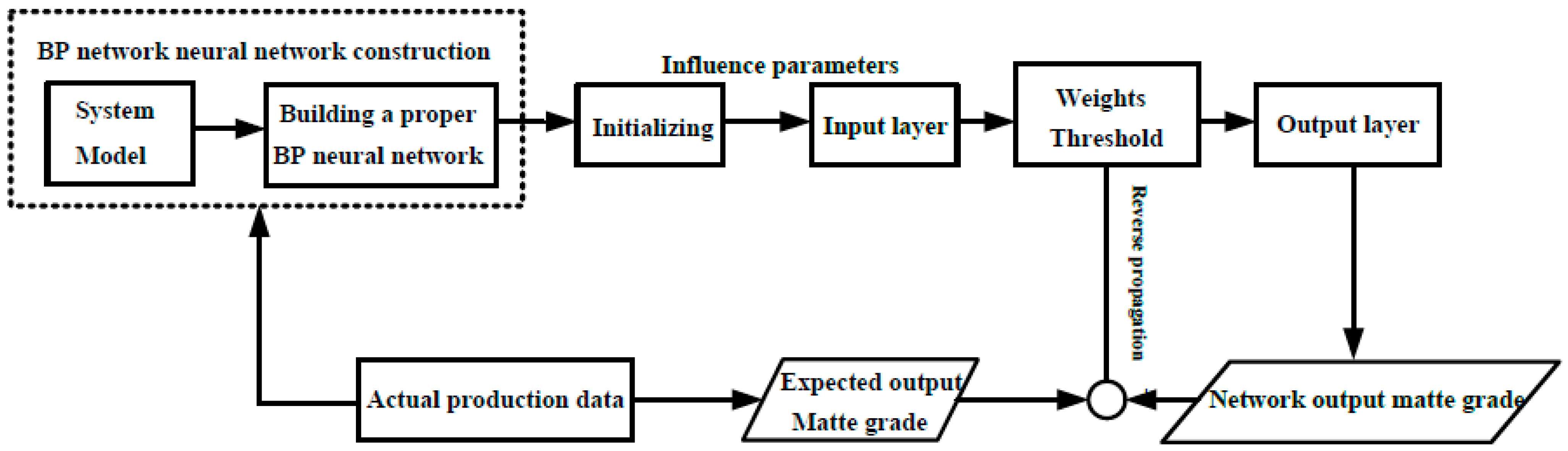
2.2.2. Model Algorithm Process
- (1)
- Small weights and thresholds are randomly assigned to the network.
- (2)
- The training samples (input and output data) were imported, the network output values were calculated and compared with the expected output values, and the local errors of all layers were obtained.
- (3)
- The network is trained, and the weight and threshold of each layer are adjusted by iterative formula. For the output layer and the hidden layer, the weight change from the ith input to the kth output is as follows:
3. Model-Solving Algorithm
3.1. Model-Solving Process
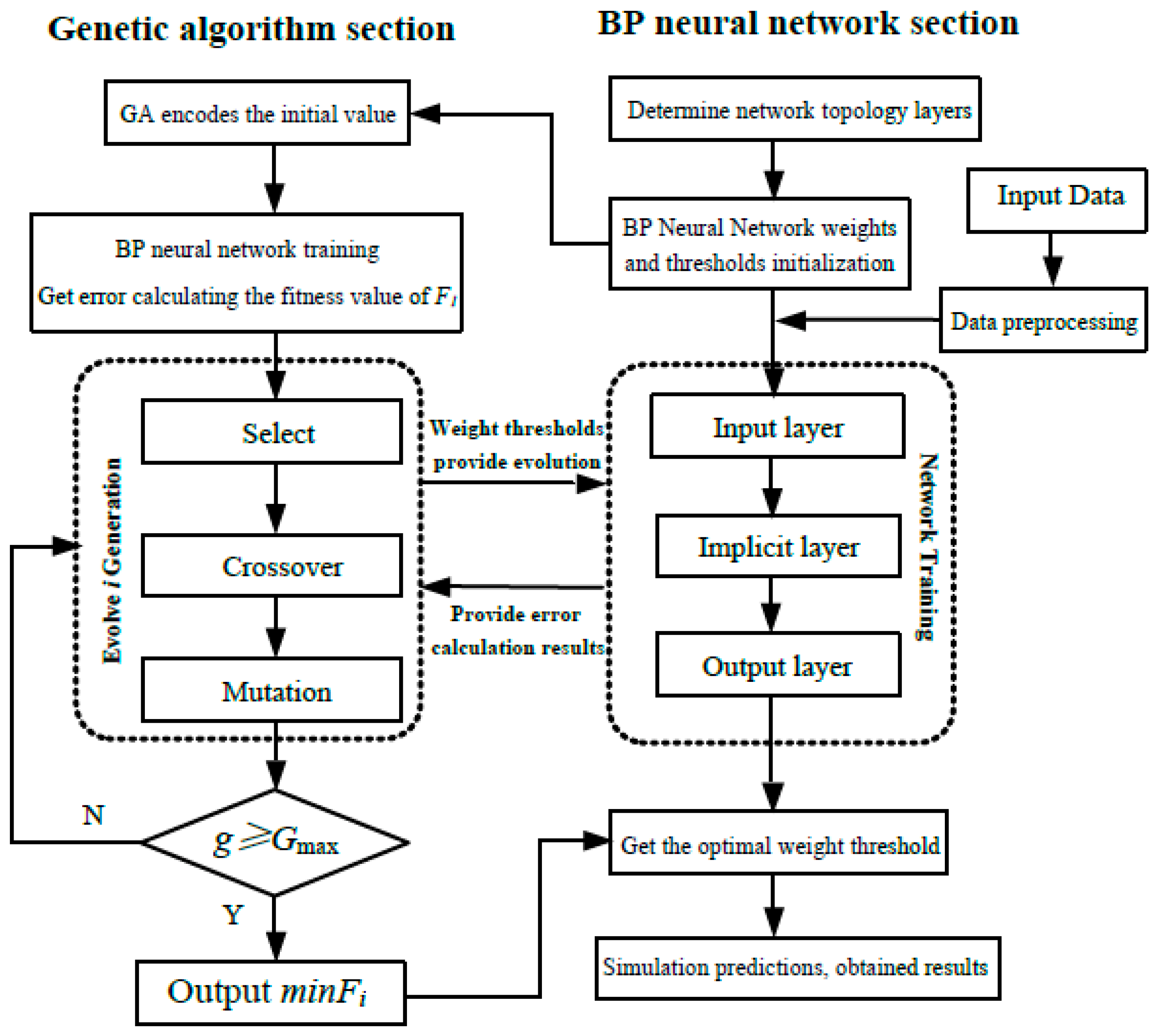
3.2. GA-BP Neural Network Algorithm
- (1)
- Chromosome coding
- (2)
- Population initialization
- (3)
- Adaptation function
- (4)
- Select Operation
- (5)
- Crossover operations
- (6)
- Mutation operation
4. Simulation and Analysis
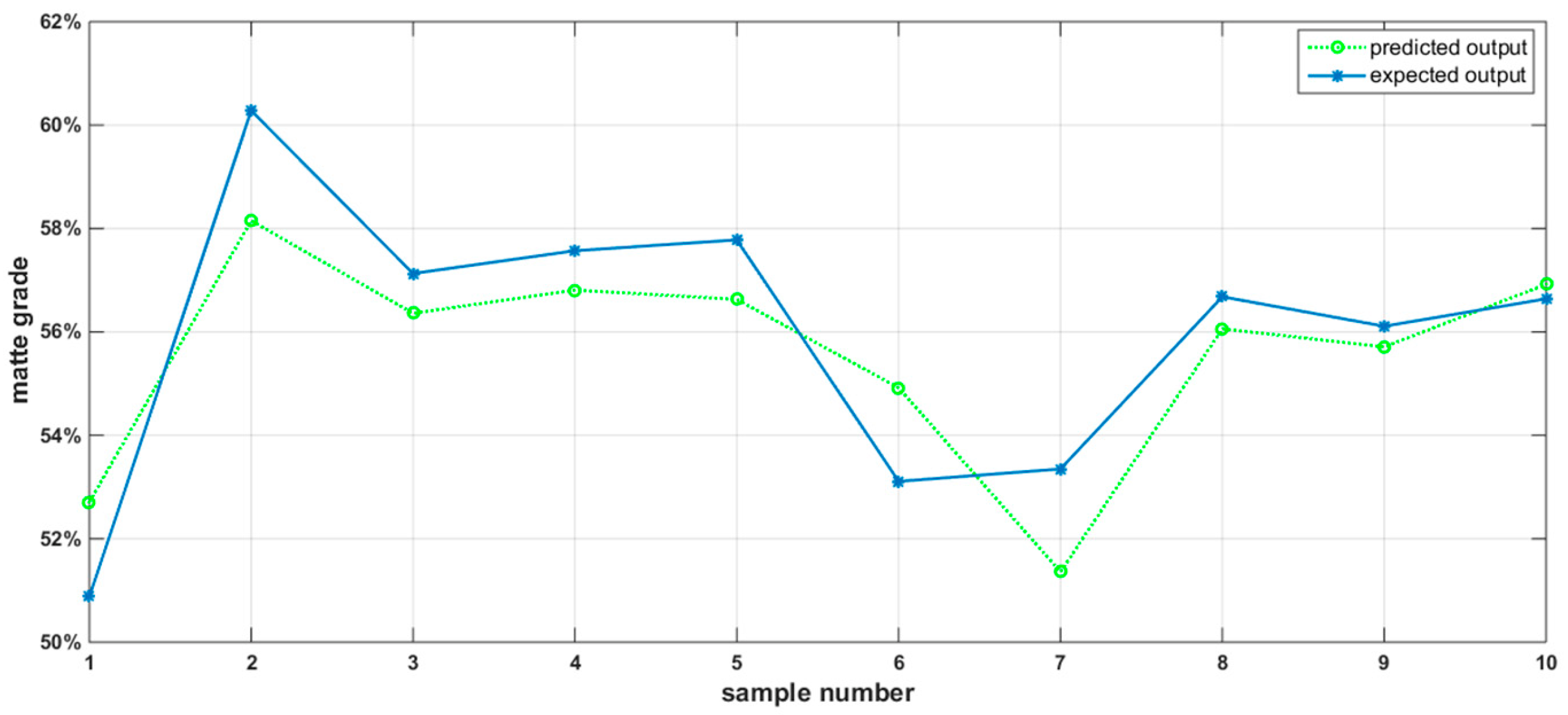
4.1. BP Neural Network Simulation and Analysis
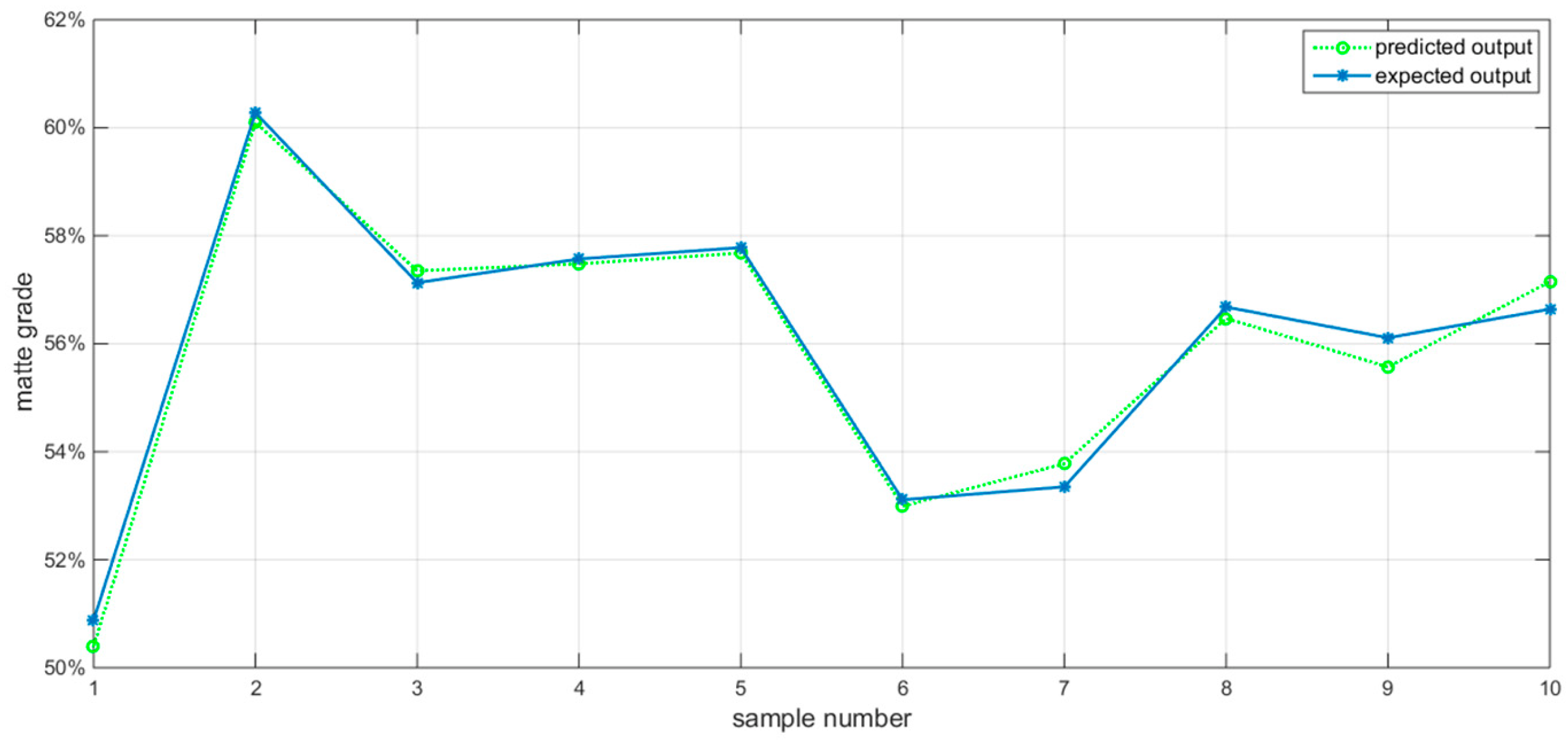
4.2. GA-BP Neural Network Simulation and Analysis
5. Conclusions
- (1)
- An optimized control model for ice matte grade was developed, and the lowest smelting cost W for the whole copper smelting process is the target function to find the best matte grade, and the consumption of other incoming materials such as oxygen, air, and melt corresponding to ISA furnace, converter, and anode furnace.
- (2)
- A BP neural network prediction model of the matte grade was established, and its weight threshold was optimized by GA. A stable and reasonable input–output relationship between matte grade and its influencing factors is obtained through sample training.
- (3)
- Combining the matte-grade optimization control model and the matte-grade BP neural network prediction model, the matte grade is predicted in real time and compared with the optimal matte grade to adjust the process parameters of each furnace to make the production operate economically.
- (4)
- In the future, based on the matte-grade optimization control model and matte-grade GA-BP neural network prediction model, a three-flow optimization prediction model coupled with material flow, energy flow, and value flow can be established for various furnace copper smelting processes.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hagan, M.T.; Demuth, H.B.; Beale, M. Neural Network Design; PWS Publishing Co.: Boston, MA, USA, 2007; Volume 3, pp. 154–196. [Google Scholar]
- Ding, S.; Su, C.; Yu, J. An Optimizing Bp Neural Network Algorithm Based on Genetic Algorithm; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2011. [Google Scholar]
- Ren, C.; An, N.; Wang, J.; Li, L.; Hu, B.; Shang, D. Optimal parameters selection for BP neural network based on particle swarm optimization: A case study of wind speed forecasting. Knowl. Based Syst. 2014, 56, 226–239. [Google Scholar] [CrossRef]
- Okun, M.S. Deep-brain stimulation—Entering the era of human neural-network modulation. N. Engl. J. Med. 2014, 371, 1369–1373. [Google Scholar] [CrossRef] [PubMed]
- He, F.; He, D.-F.; Xu, A.-J.; Wang, H.B.; Tian, N.Y. Hybrid Model of Molten Steel Temperature Prediction Based on Ladle Heat Status and Artificial Neural Network. J. Iron Steel Res. 2014, 21, 181–190. [Google Scholar] [CrossRef]
- Senthilkumar, V.; Balaji, A.; Arulkirubakaran, D. Application of constitutive and neural network models for prediction of high temperature flow behavior of Al/Mg based nanocomposite. Trans. Nonferrous Met. Soc. China 2013, 23, 1737–1750. [Google Scholar] [CrossRef]
- Li, R.-D.; Yuan, T.C.; Fan, W.B.; Qiu, Z.L.; Su, W.J.; Zhong, N.Q. Recovery of indium by acid leaching waste ITO target based on neural network. Trans. Nonferrous Met. Soc. China 2014, 24, 257–262. [Google Scholar] [CrossRef]
- Cui, G.M.; Hu, D.-F.; Xiang, M.A. Operational-Pattern Optimization in Blast Furnace PCI Based on Prediction Model of Neural Network. J. Iron Steel Res. 2014, 26, 8–12. [Google Scholar]
- Zhou, K.X.; Lin, W.H.; Sun, J.K.; Zhang, J.S.; Zhang, D.Z.; Feng, X.M.; Liu, Q. Prediction model of end-point phosphorus content for BOF based on monotone-constrained BP neural network. J. Iron Steel Res. Int. 2021, 29, 751–760. [Google Scholar] [CrossRef]
- Singha, B.; Bar, N.; Das, S.K. The use of artificial neural network (ANN) for modeling of Pb(II) adsorption in batch process. J. Mol. Liq. 2015, 211, 228–232. [Google Scholar] [CrossRef]
- Alabass, M.; Jaf, S.; Abdullah, A.H.M. Optimize BpNN using new breeder genetic algorithm. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics, Cairo, Egypt, 24–26 October 2016; Springer International Publishing: Cham, Switzerland, 2017; pp. 373–382. [Google Scholar]
- Horn, J.; Nafpliotis, N.; Goldberg, D.E. A Niched Pareto Genetic Algorithm for Multiobjective Optimization. In Proceedings of the First IEEE Conference on Evolutionary Computation. IEEE World Congress on Computational Intelligence, Orlando, FL, USA, 27–29 June 1994; Volume 1, pp. 82–87. [Google Scholar]
- Deb, K.; Agrawal, S.; Pratap, A.; Meyarivan, T. A Fast Elitist Non-dominated Sorting Genetic Algorithm for Multi-objective Optimization: NSGA-II. In Proceedings of the Parallel Problem Solving from Nature PPSN VI, Paris, France, 18–20 September 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 849–858. [Google Scholar]
- Hoseinian, F.S.; Abdollahzade, A.; Mohamadi, S.S.; Hashemzadeh, M. Recovery prediction of copper oxide ore column leaching by hybrid neural genetic algorithm. Trans. Nonferrous Met. Soc. China 2017, 27, 686–693. [Google Scholar] [CrossRef]
- Liu, H.M.; Zhao, Y.L.; Cheng, Y.M.; Wu, J.; Al Shurafa, M.A.; Liu, C.; Lee, I.K. A new power supply strategy for high power rectifying units in electrolytic copper process. J. Electr. Eng. Technol. 2022, 17, 1143–1156. [Google Scholar] [CrossRef]
- Liu, Z.; Cheng, S.; Liu, P. Prediction model of BOF end-point temperature and carbon content based on PCA-GA-BP neural network. Metall. Res. Technol. 2022, 119, 1–11. [Google Scholar] [CrossRef]
- Liu, Z.; Cheng, S.; Liu, P. Prediction model of BOF end-point P and O contents based on PCA–GA–BP neural network. High Temp. Mater. Process. 2022, 41, 505–513. [Google Scholar] [CrossRef]
- Chakraborty, S.; Chattopadhyay, P.P.; Ghosh, S.K.; Datta, S. Incorporation of prior knowledge in neural network model for continuous cooling of steel using genetic algorithm. Appl. Soft Comput. 2017, 58, 297–306. [Google Scholar] [CrossRef]
- Wang, J.L.; Hong, L.U.; Zeng, Q. Application of GA-BP to the Matte Grade Model Based on Neural Network. Jiangxi Nonferrous Met. 2003, 17, 39–42. [Google Scholar]
- Wang, J.L.; Lu, H.; Zeng, Q.Y.; Zhang, C.F. Control optimization of copper flash smelting process based on genetic algorithms. Chin. J. Nonferrous Met. 2007, 17, 156–160. [Google Scholar]
- Zeng, Q.Y.; Wang, I.L. Developing of the Copper Flash Smelting Model based on Neural Network. J. South. Inst. Metall. 2003, 24, 15–18. [Google Scholar]
- Wang, M.; Wu, J.; Guo, J.; Su, L.; An, B. Multi-Point Prediction of Aircraft Motion Trajectory Based on GA-Elman-Regularization Neural Network. Integr. Ferroelectr. 2020, 210, 116–127. [Google Scholar]
- Zhang, L.M. The Model and Application of Artificial Neural Network; Fudan University Press: Shanghai, China, 1993. [Google Scholar]
- Zhou, M.; Sun, S.D. Genetic Algorithms Theory and Applications; National Defence Industry Press: Washington, DC, USA, 1999. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cu (t) | S (t) | Fe (t) | SiO2 (t) | CaO (t) | Oxygen (Nm3) | Blast (Nm3) | Flux (t) | Matte Grade (%) |
|---|---|---|---|---|---|---|---|---|
| 22.916 | 25.297 | 23.620 | 9.241 | 1.663 | 209,300 | 152,660 | 35 | 56.65% |
| 20.918 | 22.631 | 22.209 | 11.559 | 2.268 | 199,852 | 173,140 | 39 | 61.69% |
| 21.245 | 24.429 | 23.853 | 10.598 | 1.333 | 212,448 | 151,890 | 42 | 56.43% |
| 21.780 | 24.488 | 23.971 | 10.460 | 1.181 | 206,088 | 161,237 | 47.7 | 57.06% |
| 22.154 | 23.558 | 22.906 | 10.914 | 1.555 | 207,382 | 170,853 | 49 | 60.09% |
| 22.039 | 23.965 | 23.195 | 10.627 | 1.651 | 205,373 | 164,912 | 50 | 57.72% |
| 20.966 | 23.745 | 22.541 | 10.527 | 1.583 | 209,857 | 170,418 | 46 | 62.72% |
| 22.945 | 23.208 | 22.385 | 11.197 | 2.114 | 203,196 | 162,327 | 40 | 51.46% |
| 22.612 | 25.328 | 24.269 | 9.597 | 1.158 | 202,332 | 169,972 | 43.5 | 57.81% |
| 22.297 | 23.572 | 22.688 | 10.721 | 1.791 | 199,668 | 162,570 | 42 | 51.79% |
| Number | Network Output | Expected Output | Absolute Error | Relative Error |
|---|---|---|---|---|
| 1 | 52.71% | 50.88% | 1.83% | 3.60% |
| 2 | 58.15% | 60.28% | 2.13% | 3.66% |
| 3 | 56.36% | 57.13% | 0.77% | 1.37% |
| 4 | 56.81% | 57.57% | 0.76% | 1.34% |
| 5 | 56.63% | 57.78% | 1.15% | 2.03% |
| 6 | 54.92% | 53.11% | 1.81% | 3.41% |
| 7 | 51.36% | 53.35% | 1.99% | 3.87% |
| 8 | 56.06% | 56.68% | 0.62% | 1.11% |
| 9 | 55.71% | 56.11% | 0.40% | 0.72% |
| 10 | 56.92% | 56.64% | 0.28% | 0.49% |
| Number | Network Output | Expected Output | Absolute Error | Relative Error |
|---|---|---|---|---|
| 1 | 50.40% | 50.88% | 0.48% | 0.95% |
| 2 | 60.10% | 60.28% | 0.18% | 0.30% |
| 3 | 57.35% | 57.13% | 0.22% | 0.39% |
| 4 | 57.48% | 57.57% | 0.09% | 0.16% |
| 5 | 57.68% | 57.78% | 0.10% | 0.17% |
| 6 | 52.99% | 53.11% | 0.12% | 0.23% |
| 7 | 53.78% | 53.35% | 0.43% | 0.81% |
| 8 | 56.47% | 56.68% | 0.21% | 0.37% |
| 9 | 55.57% | 56.11% | 0.54% | 0.97% |
| 10 | 57.15% | 56.64% | 0.51% | 0.90% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Zhu, D.; Liu, D.; Wang, H.; Xiong, Z.; Jiang, L. Prediction and Optimization of Matte Grade in ISA Furnace Based on GA-BP Neural Network. Appl. Sci. 2023, 13, 4246. https://doi.org/10.3390/app13074246
Zhao L, Zhu D, Liu D, Wang H, Xiong Z, Jiang L. Prediction and Optimization of Matte Grade in ISA Furnace Based on GA-BP Neural Network. Applied Sciences. 2023; 13(7):4246. https://doi.org/10.3390/app13074246
Chicago/Turabian StyleZhao, Luo, Daofei Zhu, Dafang Liu, Huitao Wang, Zhangming Xiong, and Lei Jiang. 2023. "Prediction and Optimization of Matte Grade in ISA Furnace Based on GA-BP Neural Network" Applied Sciences 13, no. 7: 4246. https://doi.org/10.3390/app13074246
APA StyleZhao, L., Zhu, D., Liu, D., Wang, H., Xiong, Z., & Jiang, L. (2023). Prediction and Optimization of Matte Grade in ISA Furnace Based on GA-BP Neural Network. Applied Sciences, 13(7), 4246. https://doi.org/10.3390/app13074246