
Multiplicative Vector Fusion Model for Detecting Deepfake News in Social Media
Abstract
1. Introduction
- Initially, we performed data pre-processing and sentence generation from deepfake news datasets with the T5 model.
- We designed a fine-tuned RoBERTa model to detect deepfake and real news effectively with optimal parameters.
- To classify deepfake news from real news on social media datasets, we proposed a transfer learning-based multiplicative vector fusion (TL-MVF) model.
- The proposed TL-MVF model was tested and validated on real-time and benchmarked datasets.
- We evaluated the TL-MVF model by taking into consideration accuracy, precision, recall, AUC, and F-score.
- Finally, the proposed TL-MVF model outperformed the existing baseline framework.
2. Background and Literature Survey
2.1. Preliminaries
2.1.1. Transformers
2.1.2. Self-Attention
2.1.3. Transformer Learning
2.1.4. Hyper-Parameter Tuning
2.1.5. Activation Functions
2.1.6. Loss Function
2.2. Deep Learning and Transformer Learning for Deepfake News Detection
- Detecting deepfake news is a challenge because of the lack of a benchmarked, labeled dataset with actual truth labels and a complete information space.
- False news has become increasingly widespread and difficult to detect in today’s environment.
- The most challenging aspect of spotting fake news is doing it early. Lack of data to train detection models is another issue with detecting fake news.
- To identify false news, it is necessary to have a solid awareness of specific authors, entities, and the relationship that exists between each word in a lengthy text.
- To overcome the above-mentioned issues, we proposed and implemented a transfer learning-based multiplicative vector fusion (TL-MVF) model.
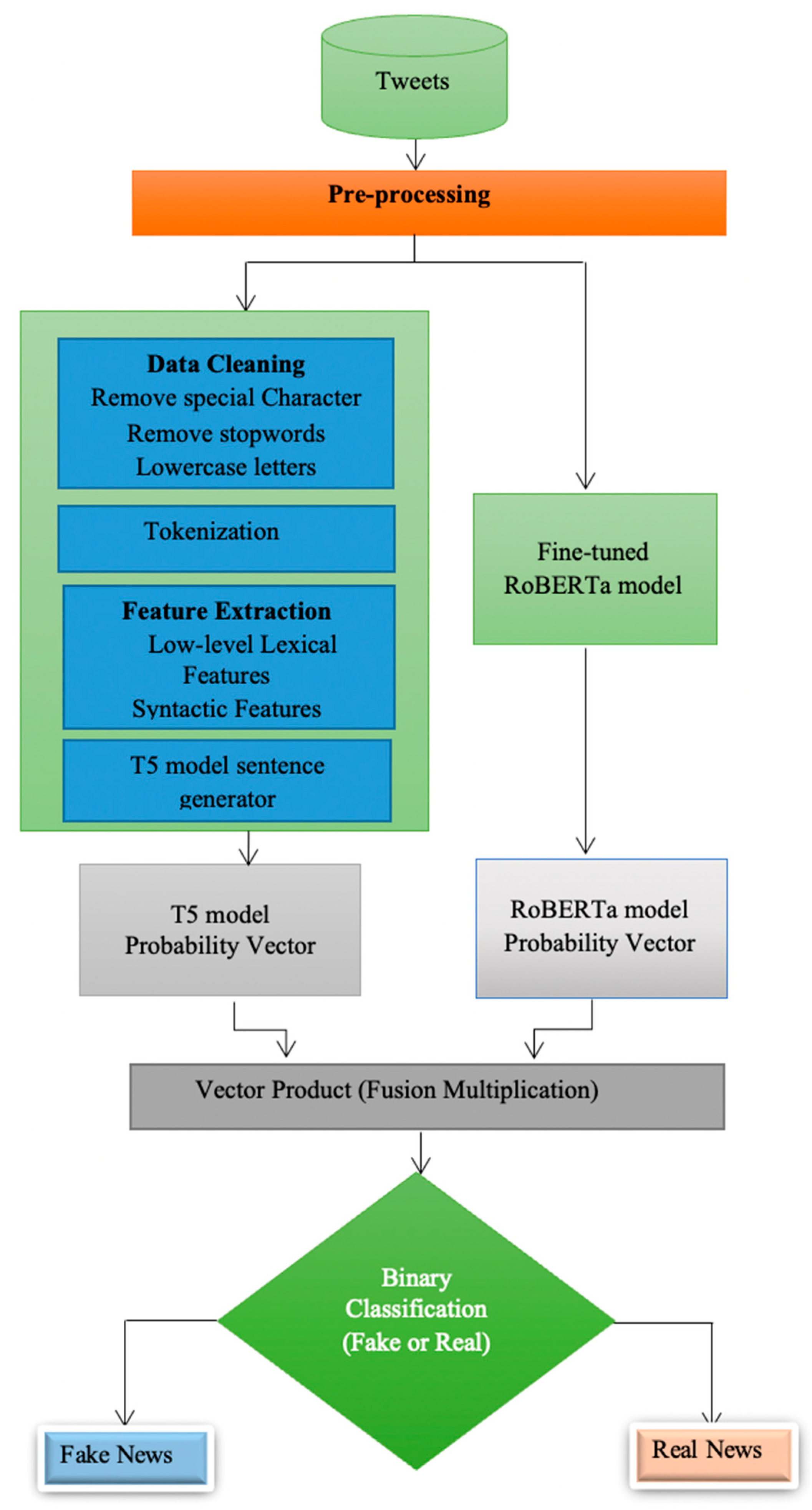
3. Proposed Methodology
3.1. Dataset Description
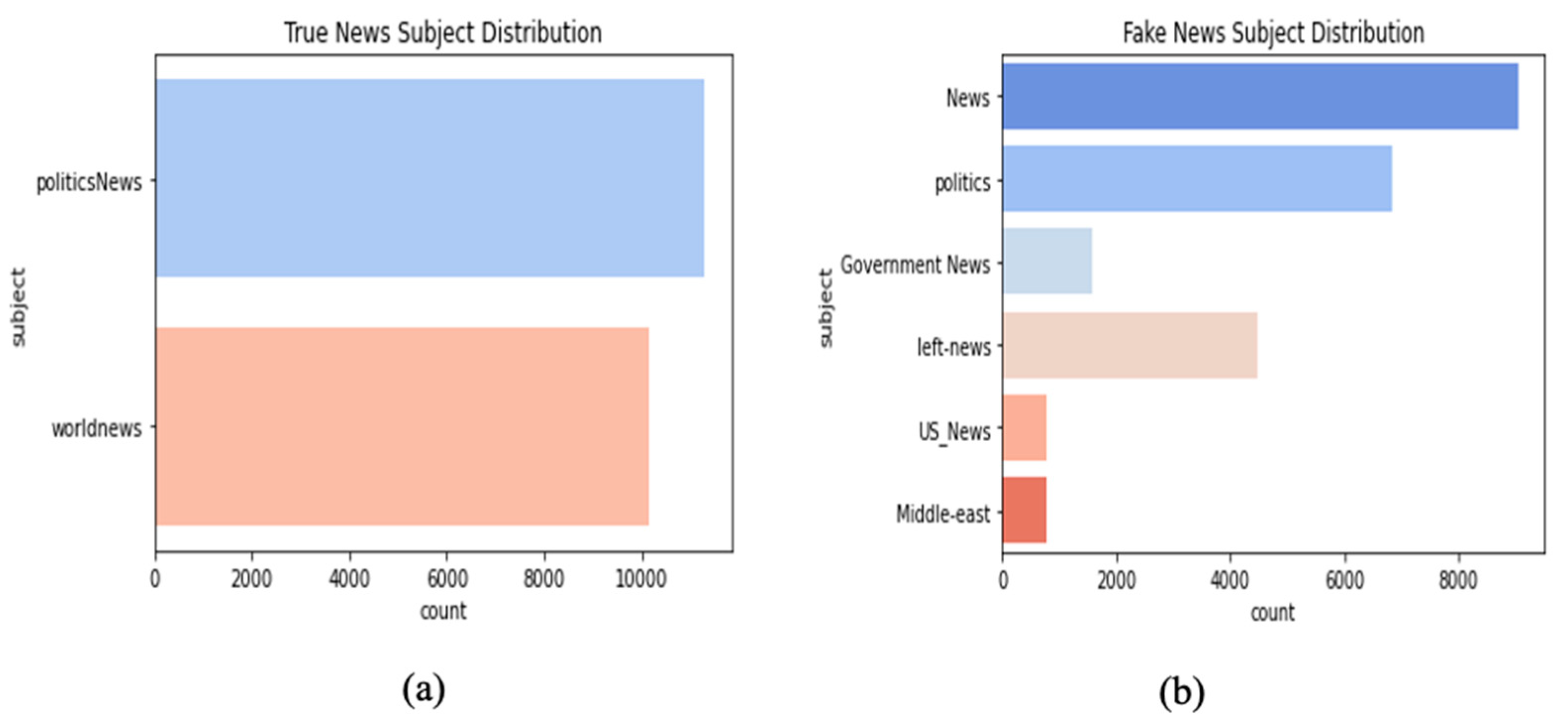
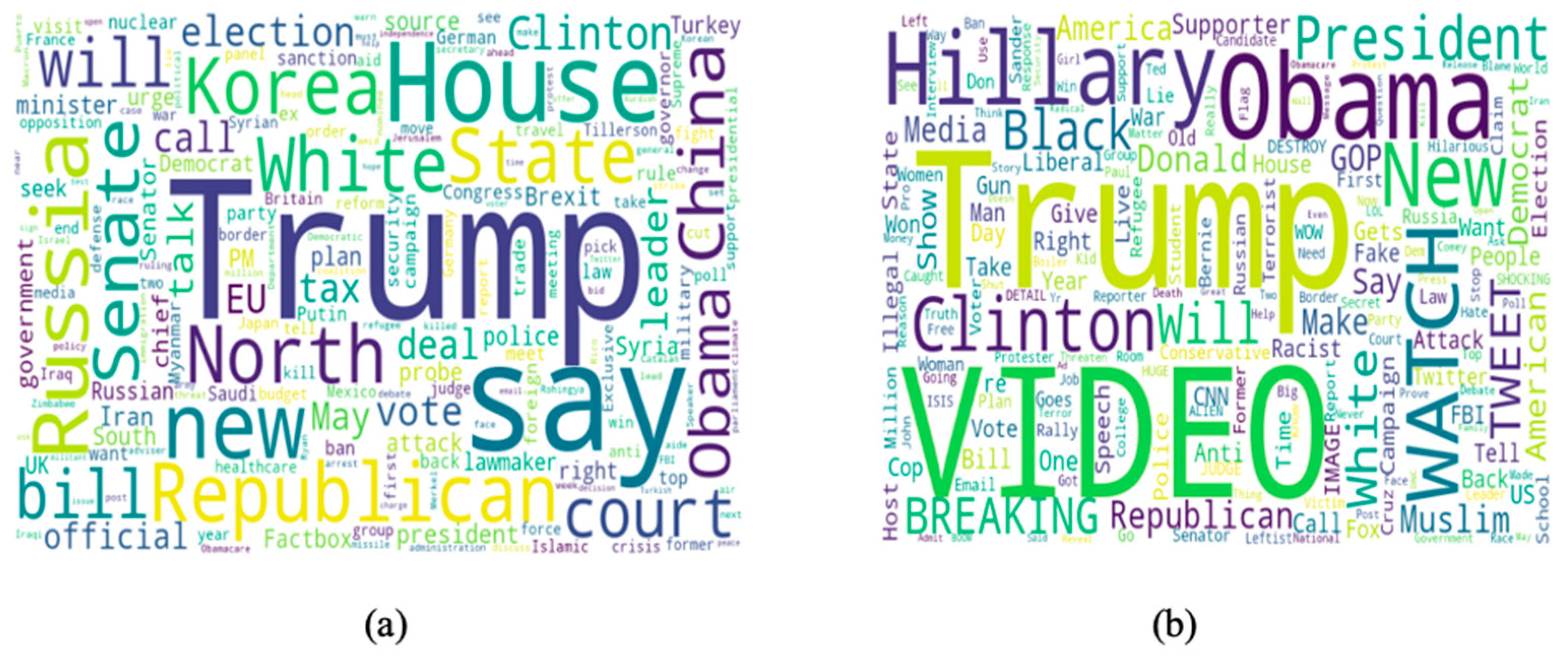
3.1.1. The Fake and Real News Dataset: An Exploration
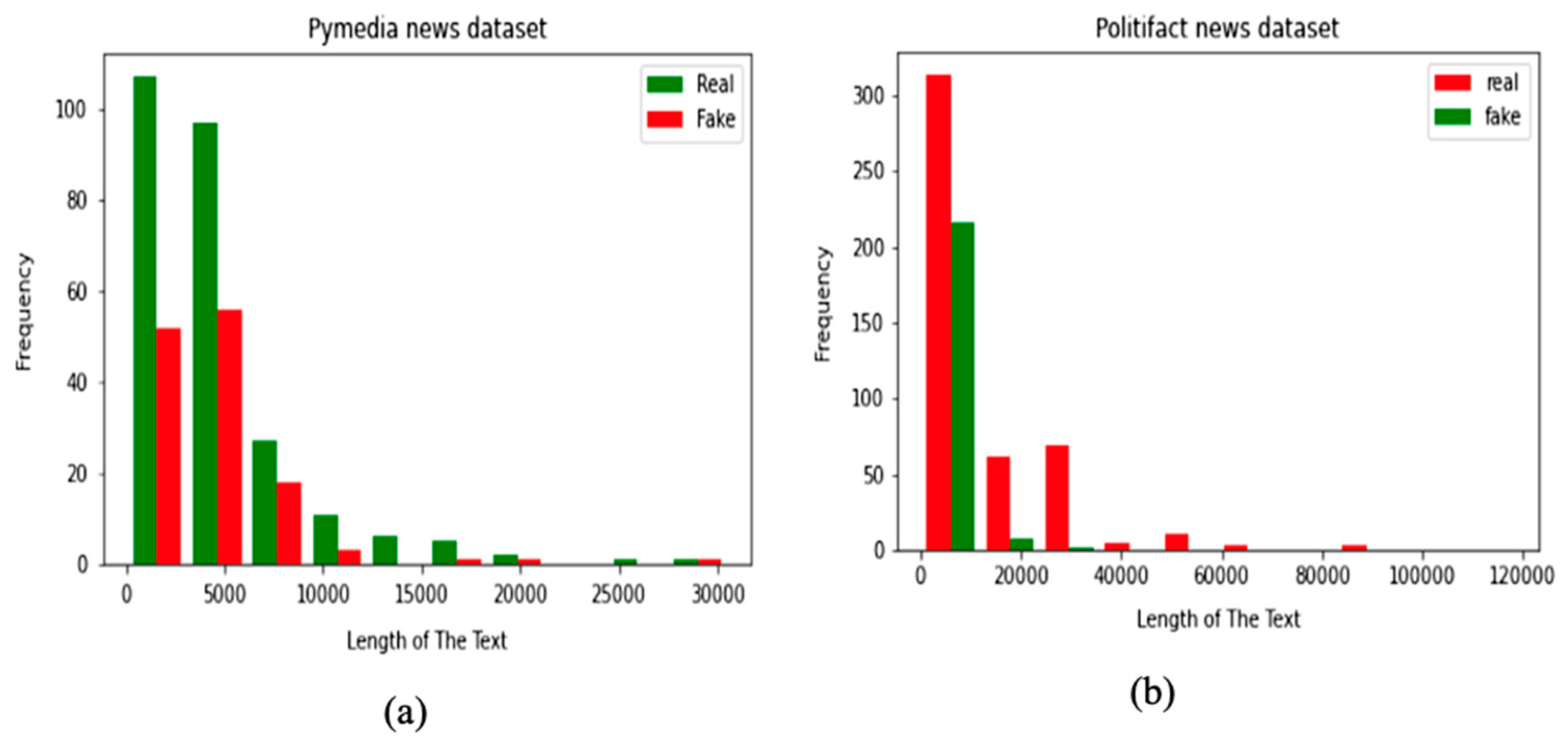
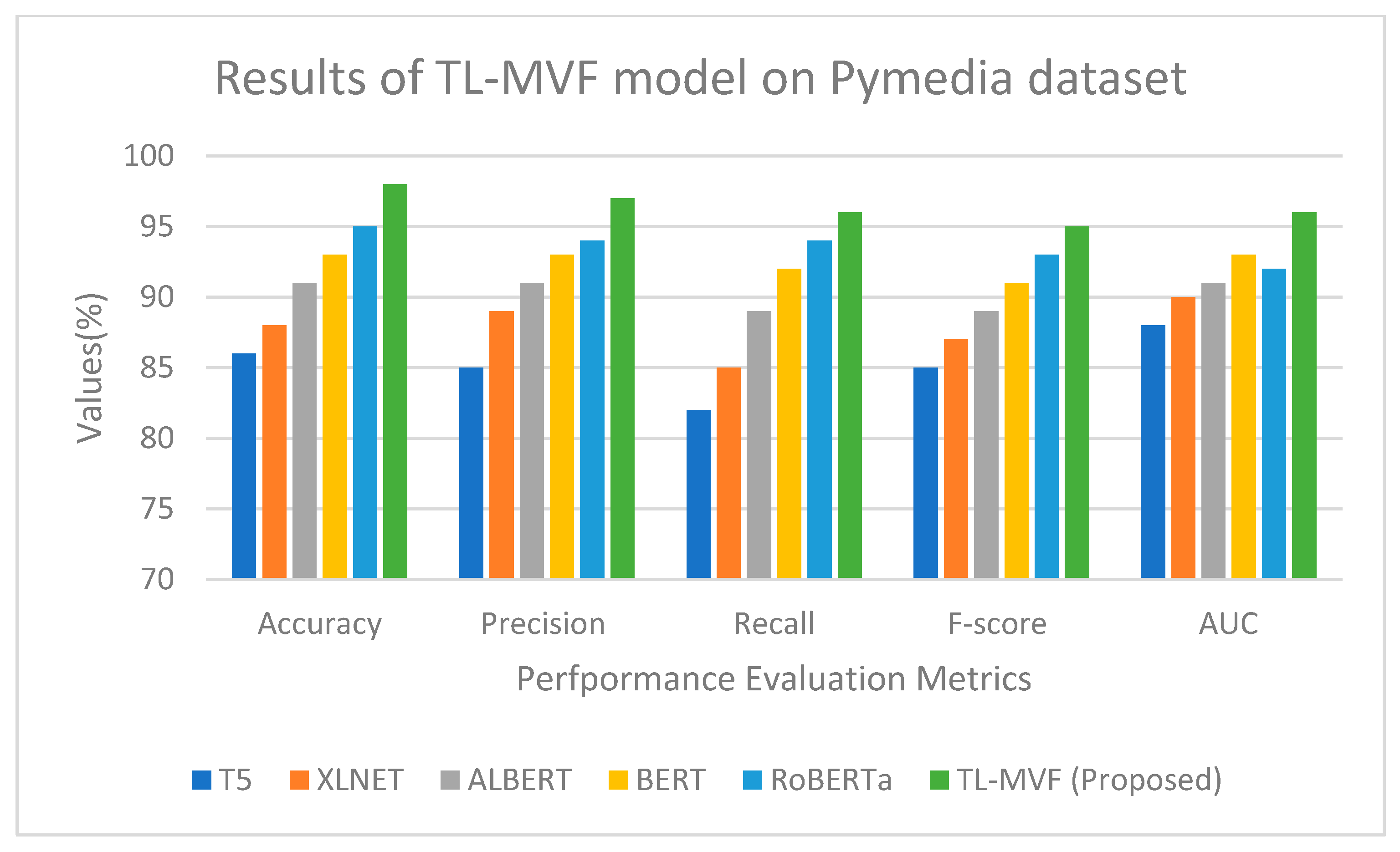
3.1.2. The Pymedia Dataset
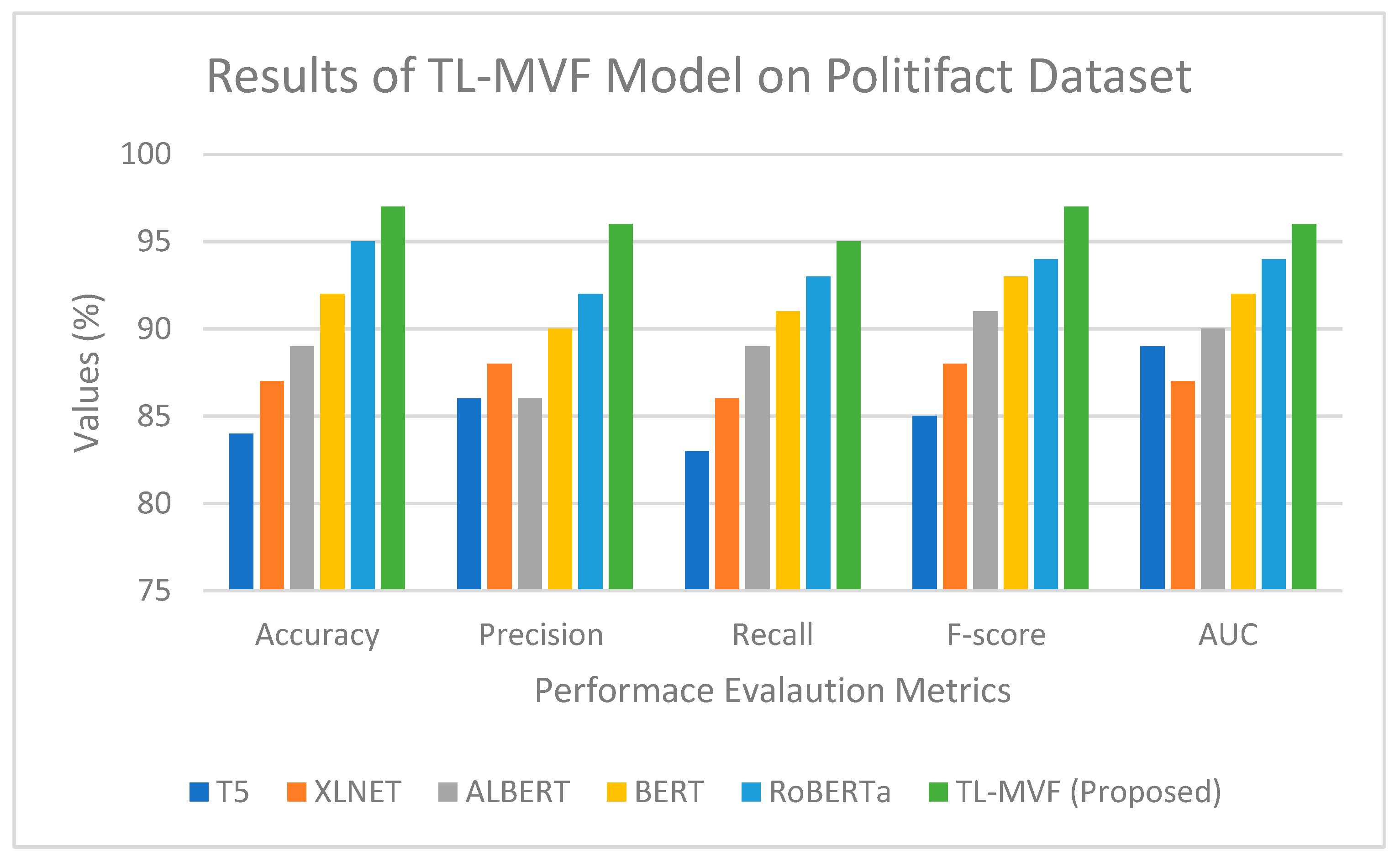
3.1.3. PolitiFact Dataset
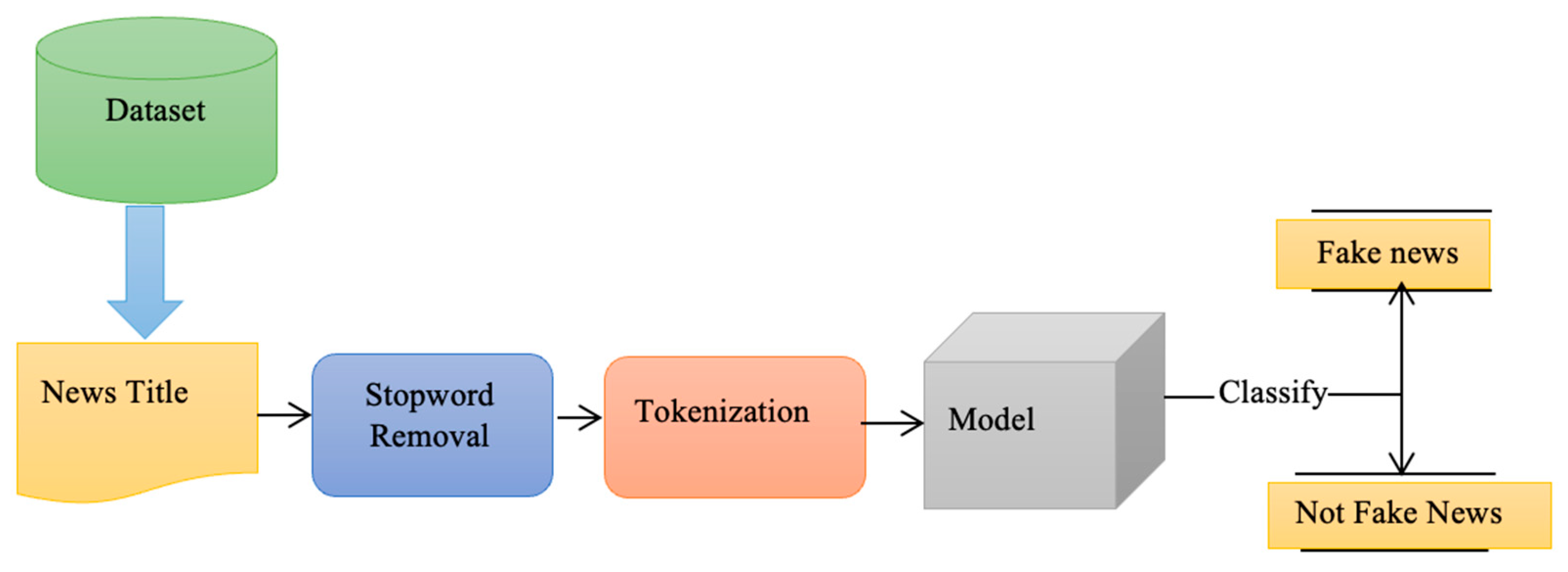
3.2. Dataset Preprocessing
3.3. Problem Definition
3.4. Pre-Processing Data
3.4.1. Data Cleaning
3.4.2. Tokenization
3.4.3. Stemming
3.4.4. Lemmatization
3.4.5. Stop Words
3.4.6. Lexical Features and Syntactic Features
- An essential aspect of a text’s semantics is its meaning (semantics). In this way, the data is transformed into meaningful patterns.
- Word frequency and uniqueness are calculated using lexical features in the TF-IDF vectorization. Hashtags, pronouns, and punctuation are some of the lexical features.
- Syntactic features are generated by speech tags and various components from a parse tree, whereas lexical features are the target words with unigrams, bigrams, and surface forms.
3.5. The T5 model for Sentence Generation
- (i)
- jth element by ignoring the ith element. It means that 0 and is attained, and the self-attention was designed with Equation (10):
- (ii)
- ith element by ignoring the jth element. It means that 1 and is attained, and the self-attention was designed with Equation (11):where p represents the matrix parameters mask in measuring the self-attention of the T5 model. Here, M denotes the mask, and Q is used as a parameter value to optimize the function.
3.6. A Fine-Tuned RoBERTa Model for Deepfake News Detection
- (i)
- The RoBERTa model is pre-trained with 10 times more data and 8 times larger batch sizes.
- (ii)
- As opposed to character-level vocabulary techniques, the model used BPE (byte-pair-encoding).
- (iii)
- NSP (next sentence prediction) was removed from the model.
- (iv)
- Crucial parameters are changed, such as masking patterns applied dynamically, higher learning rates, etc.
3.7. Design of Vector Product Fusion Multiplication Technique
| Algorithm 1 for the proposed Multiplicative Vector Fusion (MVF) technique |
Initialization:
|
| for j = 1 to N |
|
- The news item will be predicted as Fake if is true.
- The news item will be predicted as Real if is true.
- The neutral condition rarely occurs because the proposed technique is trained and tested on the dataset as a binary classification.
4. Results and Analysis
4.1. Performance Evaluation Metrics
4.2. Implementation Details
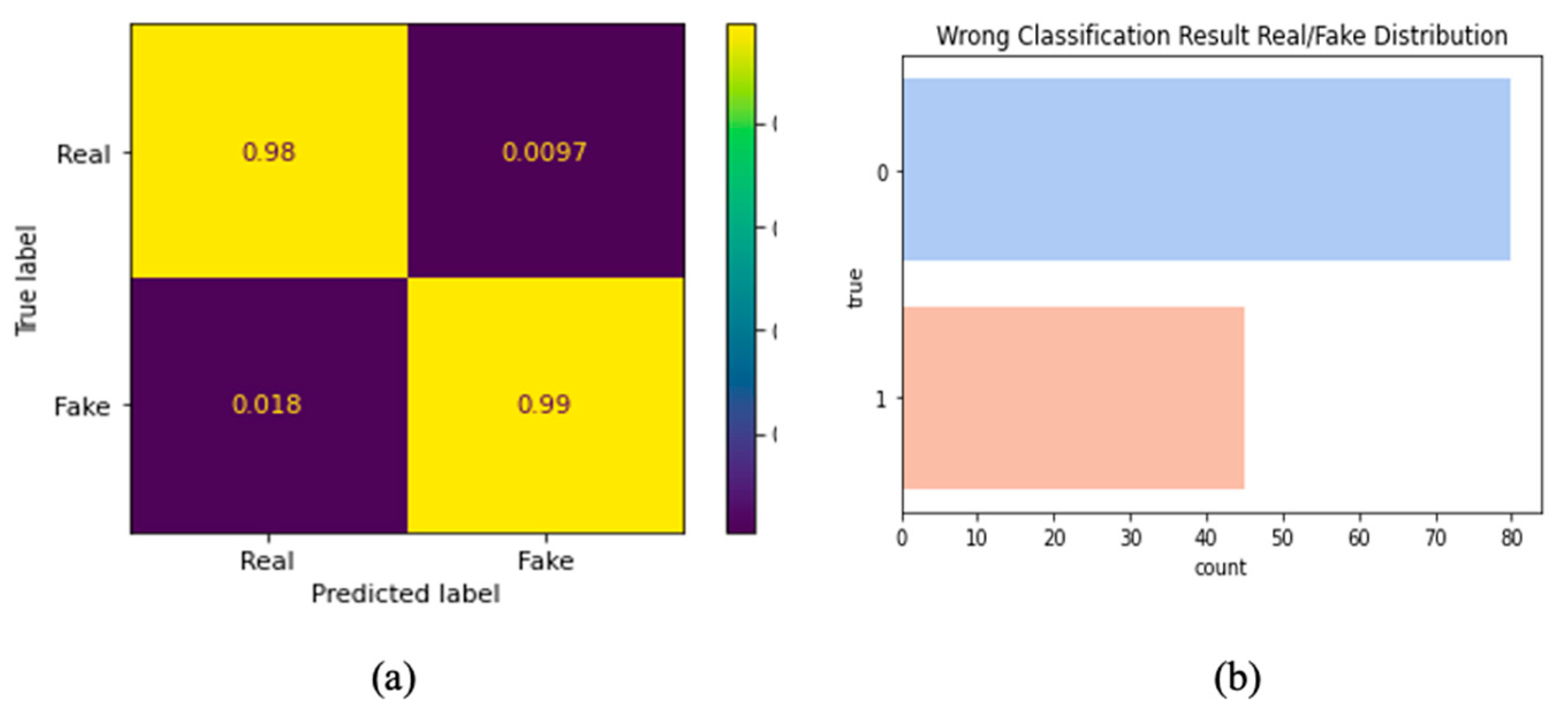
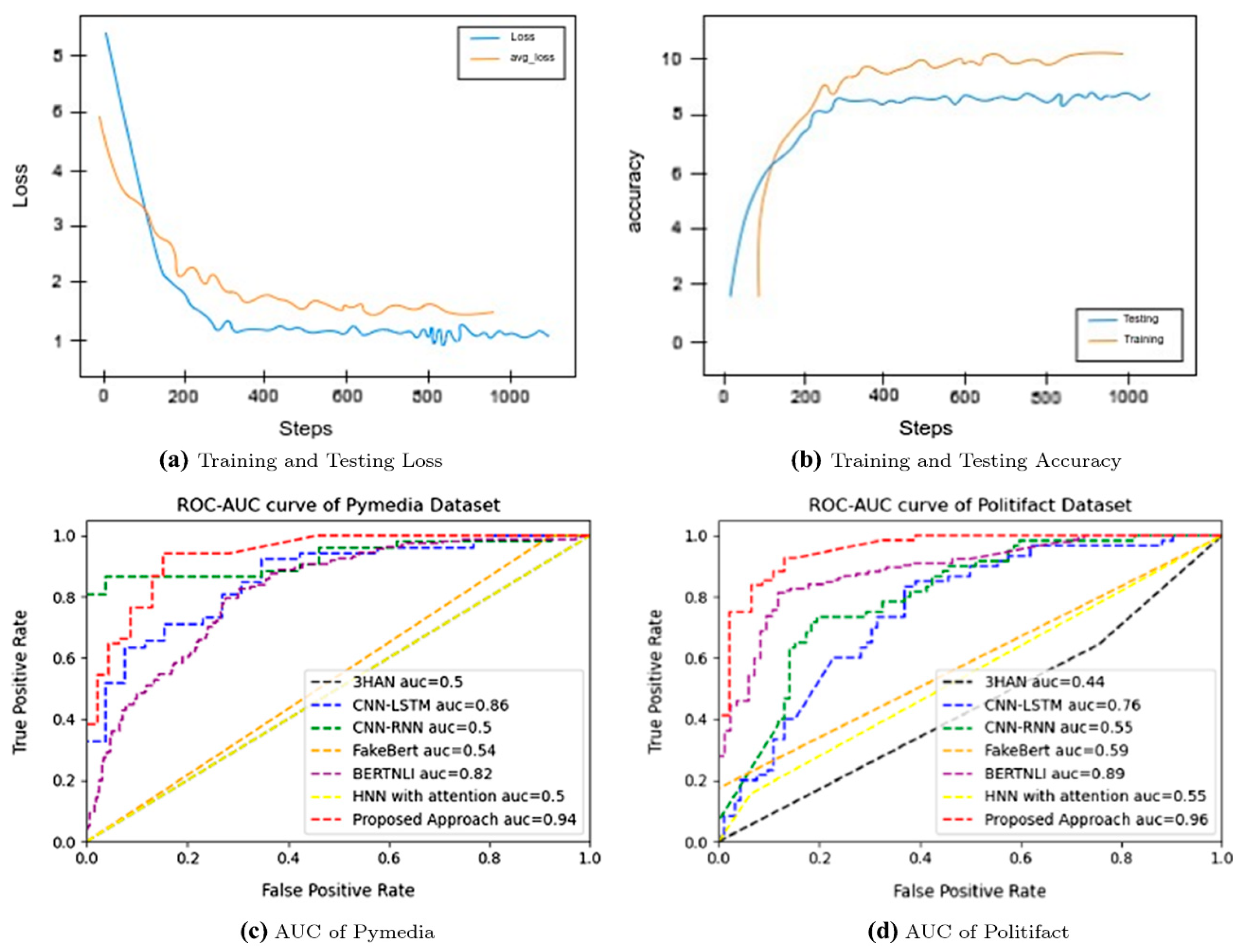
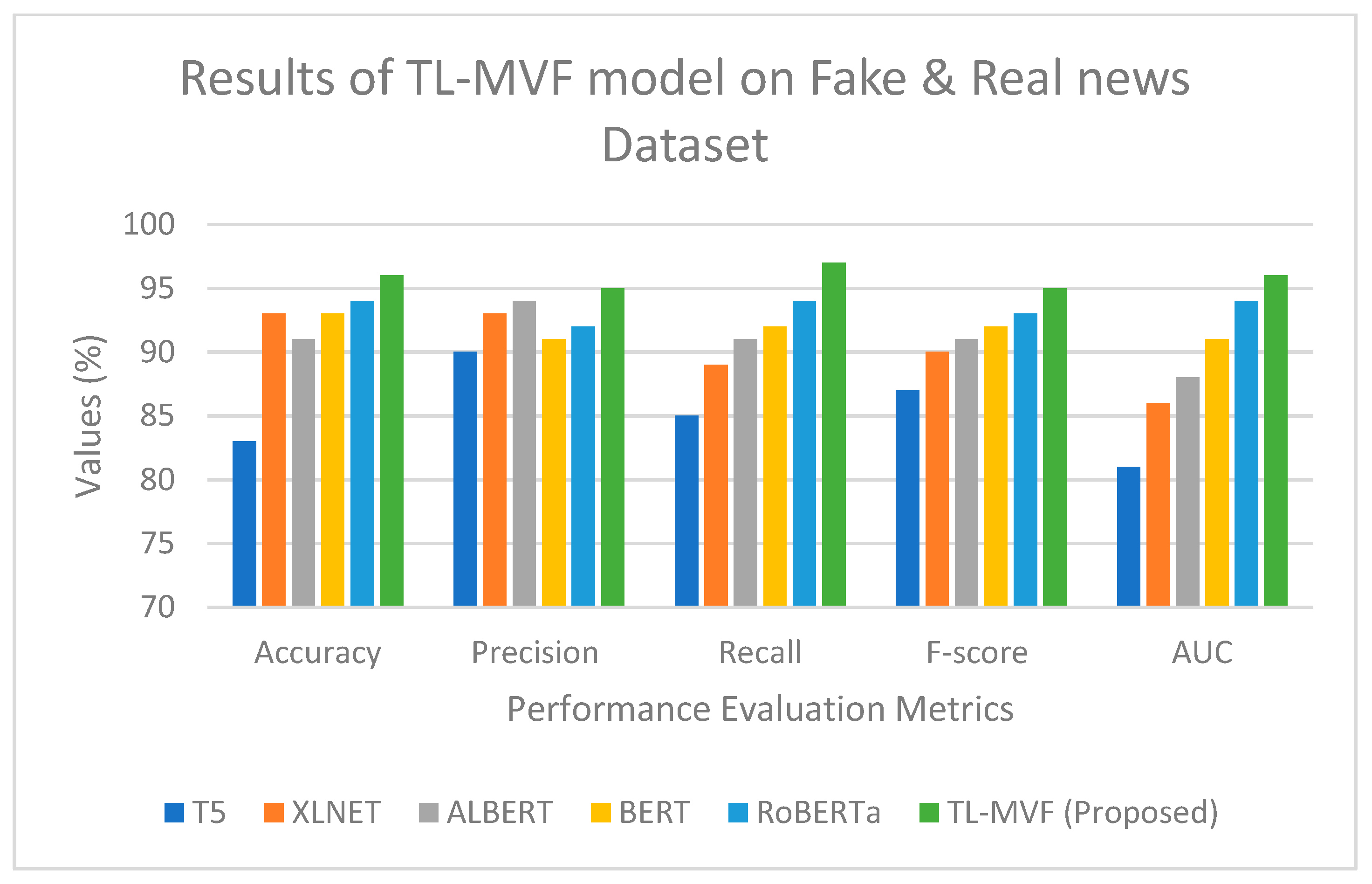
4.3. Result Analysis and Discussions
4.4. Result Analysis of the Proposed TL-MVF Model on the Existing Benchmarked Models
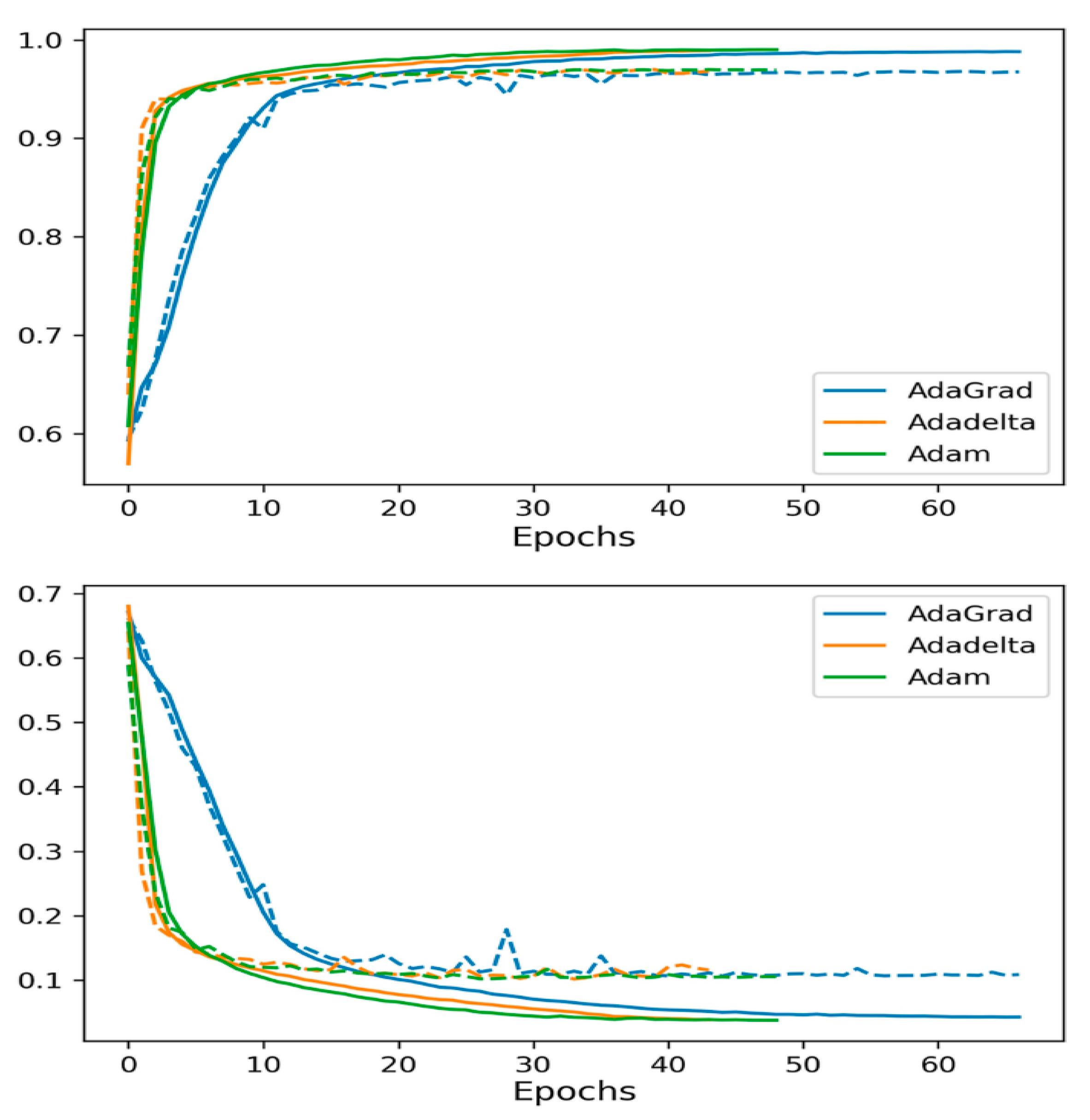
4.5. Hyperparameter Selection
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shubha, M.; Shukla, P.; Agarwal, R. Analysing machine learning enabled fake news detection techniques for diversified datasets. Wirel. Commun. Mob. Comput. 2022, 2022, 1575365. [Google Scholar]
- Raza, S.; Ding, C. Fake news detection based on news content and social contexts: A transformer-based approach. Int. J. Data Sci. Anal. 2022, 13, 335–362. [Google Scholar] [CrossRef]
- Lai, C.-M.; Chen, M.-H.; Kristiani, E.; Verma, V.K.; Yang, C.-T. Fake News Classification Based on Content Level Features. Appl. Sci. 2022, 12, 1116. [Google Scholar] [CrossRef]
- Truică, C.O.; Apostol, E.S.; Paschke, A. Awakened at CheckThat! 2022: Fake news detection using Bi-LSTM and sentence transformer. In Proceedings of the CLEF 2022: Conference and Labs of the Evaluation Forum, Bologna, Italy, 5–8 September 2022. [Google Scholar]
- Alonso, M.A.; Vilares, D.; Gómez-Rodríguez, C.; Vilares, J. Sentiment analysis for fake news detection. Electronics 2021, 10, 1348. [Google Scholar] [CrossRef]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-BERT: Enabling Language Representation with Knowledge Graph. arXiv 2019. [Google Scholar] [CrossRef]
- Spradling, M.; Straub, J.; Strong, J. Protection from ‘fake news’: The need for descriptive factual labeling for online content. Future Internet 2021, 13, 142. [Google Scholar] [CrossRef]
- He, P.; Liu, X.; Gao, J.; Chen, W. DeBERTa: Decoding-enhanced BERT with Disentangled Attention. arXiv 2020, arXiv:2006.03654. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-XL: Attentive language models beyond a fixed-length context. In Proceedings of the ACL 2019—57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2020. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language un-derstanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Al-Ahmad, B.; Al-Zoubi, A.; Abu Khurma, R.; Aljarah, I. An Evolutionary Fake News Detection Method for COVID-19 Pandemic Information. Symmetry 2021, 13, 1091. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In Lecture Notes in Computer Science, Proceedings of the 27th International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Abonizio, H.Q.; De Morais, J.I.; Tavares, G.M.; Junior, S.B. Language-Independent Fake News Detection: English, Portuguese, and Spanish Mutual Features. Futur. Internet 2020, 12, 87. [Google Scholar] [CrossRef]
- Zhu, Y.; Sheng, Q.; Cao, J.; Nan, Q.; Shu, K.; Wu, M.; Wang, J.; Zhuang, F. Memory-Guided Multi-View Multi-Domain Fake News Detection. IEEE Trans. Knowl. Data Eng. 2022, 1–14. [Google Scholar] [CrossRef]
- Mouratidis, D.; Nikiforos, M.; Kermanidis, K. Deep Learning for Fake News Detection in a Pairwise Textual Input Schema. Computation 2021, 9, 20. [Google Scholar] [CrossRef]
- Segura-Bedmar, I.; Alonso-Bartolome, S. Multimodal Fake News Detection. Information 2022, 13, 284. [Google Scholar] [CrossRef]
- Allcott, H.; Gentzkow, M. social media and Fake News in the 2016 Election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake News Detection on social media. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Wang, W.Y. “Liar, liar pants on fire”: A new benchmark dataset for fake news detection. In Proceedings of the ACL 2017—55th Annual Meeting of the Association for Computational Linguistics, Vancuver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Riedel, B.; Augenstein, I.; Spithourakis, G.P.; Riedel, S. A simple but tough-to-beat baseline for the Fake News Challenge stance detection task. arXiv 2017, arXiv:1707.03264. [Google Scholar]
- Ghanem, B.; Rosso, P.; Rangel, F. Stance Detection in Fake News a Combined Feature Representation. In Proceedings of the First Workshop on Fact Extraction and VERification (FEVER), Brussels, Belgium, November 2018. [Google Scholar] [CrossRef]
- Rastogi, S.; Bansal, D. A review on fake news detection 3T’s: Typology, time of detection, taxonomies. Int. J. Inf. Secur. 2022, 22, 177–212. [Google Scholar] [CrossRef]
- Jwa, H.; Oh, D.; Park, K.; Kang, J.M.; Lim, H. exBAKE: Automatic fake news detection model based on Bidirectional En-coder Representations from Transformers (BERT). Appl. Sci. 2019, 9, 4062. [Google Scholar] [CrossRef]
- Fake News. Available online: https://www.kaggle.com/c/fake-news (accessed on 23 December 2020).
- Szczepański, M.; Pawlicki, M.; Kozik, R.; Choraś, M. New explainability method for BERT-based model in fake news detection. Sci. Rep. 2021, 11, 23705. [Google Scholar] [CrossRef] [PubMed]
- Dhiman, P.; Kaur, A.; Iwendi, C.; Mohan, S.K. A Scientometric Analysis of Deep Learning Approaches for Detecting Fake News. Electronics 2023, 12, 948. [Google Scholar] [CrossRef]
- Ahmad, I.; Yousaf, M.; Yousaf, S.; Ahmad, M.O. Fake News Detection Using Machine Learning Ensemble Methods. Complexity 2020, 2020, 8885861. [Google Scholar] [CrossRef]
- Tida, V.S.; Hsu, S. Universal spam detection using transfer learning of BERT model. arXiv 2022, arXiv:2202.03480. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Pavlov, T.; Mirceva, G. COVID-19 Fake News Detection by Using BERT and RoBERTa models. In Proceedings of the 2022 45th Jubilee International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 23–27 May 2022; pp. 312–316. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/datasets/clmentbisaillon/fake-and-real-news-dataset (accessed on 23 December 2020).
- POLITICO. World Net Daily. 2020. Available online: https://www.politico.com/news/world-net-daily (accessed on 23 December 2020).
- Politifact. 2020. Available online: https://www.Politifact.com (accessed on 23 December 2020).
- Singhania, S.; Fernandez, N.; Rao, S. 3HAN: A Deep Neural Network for Fake News Detection. In Neural Information Processing, Proceedings of the 24th International Conference, ICONIP 2017, Guangzhou, China, 14–18 November 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 572–581. [Google Scholar] [CrossRef]
- Okano, E.Y.; Liu, Z.; Ji, D.; Ruiz, E.E.S. Fake News Detection on Fake.Br Using Hierarchical Attention Networks. In Computational, Proceedings of the Portuguese Language 14th International Conference, PROPOR 2020, Evora, Portugal, 2–4 March 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 143–152. [Google Scholar] [CrossRef]
- Salini, Y.; HariKiran, J. Deepfakes on Retinal Images using GAN. Int. J. Adv. Comput. Sci. Appl. 2022, 13. [Google Scholar] [CrossRef]
- Umer, M.; Imtiaz, Z.; Ullah, S.; Mehmood, A.; Choi, G.S.; On, B.-W. Fake News Stance Detection Using Deep Learning Architecture (CNN-LSTM). IEEE Access 2020, 8, 156695–156706. [Google Scholar] [CrossRef]
- Yang, K.; Niven, T.; Kao, H. Fake news detection as natural language inference. arXiv 2019, arXiv:1907.07347. [Google Scholar]
- Kaliyar, R.K.; Goswami, A.; Narang, P. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimed. Tools Appl. 2021, 80, 11765–11788. [Google Scholar] [CrossRef]
- Ni, J.; Abrego, G.H.; Constant, N.; Ma, J.; Hall, K.; Cer, D.; Yang, Y. Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models. arXiv 2021, arXiv:2108.08877. [Google Scholar]
- Kumar, A.; Trueman, T.E.; Cambria, E. Fake news detection using XLNet fine-tuning model. In Proceedings of the 2021 International Conference on Computational Intelligence and Computing Applications (ICCICA), Nagpur, India, 26–27 November 2021; IEEE: Washington, DC, USA, 2021; pp. 1–4. [Google Scholar]
- Gundapu, S.; Mamidi, R. Transformer based automatic COVID-19 fake news detection system. arXiv 2021, arXiv:2101.00180. [Google Scholar]
- Amer, E.; Kwak, K.-S.; El-Sappagh, S. Context-Based Fake News Detection Model Relying on Deep Learning Models. Electronics 2022, 11, 1255. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Features | Fake | Real |
|---|---|---|---|
| Fake and Real News [31] | 4 (title, text, subject, and date) | 21,417 | 23,502 |
| Dataset | Features | Count |
|---|---|---|
| Pymedia dataset [32] | Authors | 3634 |
| Subjects | 152 | |
| Generated articles | 140,55 | |
| Total article subjects | 48,756 |
| Dataset | Features | Count |
|---|---|---|
| Politifact dataset [33] | Websites | 68 |
| Subjects | 1020 | |
| Web links | 1619 |
| Predicted | |||
| Real News | Fake News | ||
| Actual | Real news | TN | FP |
| Fake news | FN | TP | |
| Name of the Hyperparameter | Value |
|---|---|
| Batch size | 32 |
| Learning rate | 0.001 |
| Hidden layers | 12 |
| Patience | 5 |
| Dropout | 0.1 |
| Annealing factor | 5 |
| Time steps | 150 |
| Number of epochs | 5 |
| Max. training epoch | 50 |
| Encoding layer dimensions | 768 |
| Feedforward layer dimensions | 3072 |
| Optimizer | Adam, Adagrad, and Adadelta |
| Activation | ReLU and Softmax |
| Models | Accuracy (%) | Precision (%) | Recall (%) | F-score (%) | AUC (%) |
|---|---|---|---|---|---|
| 3HAN [34] | 96.77 | 89.72 | 87.50 | 88.6 | 90.4 |
| HAN [35] | 83.29 | 90.48 | 85.45 | 87.45 | 81.20 |
| CNN-RNN [36] | 93.27 | 90.87 | 90.24 | 90.25 | 86.30 |
| CNN-LSTM [37] | 91.15 | 90.08 | 92.12 | 91.55 | 88.46 |
| BERT-NLI [38] | 93.65 | 91.10 | 93.48 | 92.65 | 91.55 |
| Fake BERT [39] | 96.84 | 92.03 | 95.74 | 93.70 | 94.70 |
| TL-MVF (Proposed) | 99.12 | 98.28 | 97.46 | 97.82 | 98.34 |
| Models | Accuracy (%) | Precision (%) | Recall (%) | F-Score (%) | AUC (%) |
|---|---|---|---|---|---|
| 3HAN [34] | 88.60 | 91.20 | 85.46 | 87.30 | 92.42 |
| HAN [35] | 86.40 | 86.45 | 90.25 | 88.45 | 91.56 |
| CNN-RNN [36] | 81.95 | 93.40 | 80.75 | 86.74 | 84.80 |
| CNN-LSTM [37] | 86.74 | 90.75 | 79.32 | 85.92 | 89.54 |
| BERT-NLI [38] | 85.65 | 92.32 | 88.76 | 89.43 | 90.25 |
| Fake BERT [39] | 91.42 | 93.40 | 85.24 | 88.50 | 91.35 |
| TL-MVF (Proposed) | 94.50 | 95.46 | 91.42 | 93.64 | 95.68 |
| Models | Accuracy (%) | Precision (%) | Recall (%) | F-Score (%) | AUC (%) |
|---|---|---|---|---|---|
| 3HAN [34] | 82.35 | 90.65 | 84.72 | 87.36 | 92.4 |
| HAN [35] | 85.14 | 86.75 | 87.00 | 86.15 | 92.85 |
| CNN-RNN [36] | 83.70 | 89.23 | 92.41 | 90.42 | 83.29 |
| CNN-LSTM [37] | 89.36 | 92.45 | 93.12 | 92.76 | 93.27 |
| BERT-NLI [38] | 91.25 | 93.62 | 94.15 | 93.95 | 91.15 |
| Fake BERT [39] | 93.85 | 95.40 | 94.25 | 94.76 | 93.65 |
| TL-MVF (Proposed) | 96.20 | 97.55 | 96.45 | 97.05 | 98.21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salini, Y.; Harikiran, J. Multiplicative Vector Fusion Model for Detecting Deepfake News in Social Media. Appl. Sci. 2023, 13, 4207. https://doi.org/10.3390/app13074207
Salini Y, Harikiran J. Multiplicative Vector Fusion Model for Detecting Deepfake News in Social Media. Applied Sciences. 2023; 13(7):4207. https://doi.org/10.3390/app13074207
Chicago/Turabian StyleSalini, Yalamanchili, and Jonnadula Harikiran. 2023. "Multiplicative Vector Fusion Model for Detecting Deepfake News in Social Media" Applied Sciences 13, no. 7: 4207. https://doi.org/10.3390/app13074207
APA StyleSalini, Y., & Harikiran, J. (2023). Multiplicative Vector Fusion Model for Detecting Deepfake News in Social Media. Applied Sciences, 13(7), 4207. https://doi.org/10.3390/app13074207