Abstract
Recently, convolutional neural networks (CNNs) have become the main drivers in many image recognition applications. However, they are vulnerable to adversarial attacks, which can lead to disastrous consequences. This paper introduces ShuffleDetect as a new and efficient unsupervised method for the detection of adversarial images against trained convolutional neural networks. Its main feature is to split an input image into non-overlapping patches, then swap the patches according to permutations, and count the number of permutations for which the CNN classifies the unshuffled input image and the shuffled image into different categories. The image is declared adversarial if and only if the proportion of such permutations exceeds a certain threshold value. A series of 8 targeted or untargeted attacks was applied on 10 diverse and state-of-the-art ImageNet-trained CNNs, leading to 9500 relevant clean and adversarial images. We assessed the performance of ShuffleDetect intrinsically and compared it with another detector. Experiments show that ShuffleDetect is an easy-to-implement, very fast, and near memory-free detector that achieves high detection rates and low false positive rates.
1. Introduction
Convolutional neural networks (CNNs) trained on large sets of examples are dominant tools for object recognition [1]. Although CNNs are capable of accurately classifying new images into object categories, they can nevertheless be deceived by adversarial attacks [2], whose strategies generally consist of altering inputs with perturbations that lead to classification errors.
These attacks can be classified in terms of the amount of information that the attackers have at their disposal. Gradient-based attacks (e.g., [3,4,5,6]) require information about the CNN’s architecture and weights. Transfer-based attacks (e.g., [7,8,9]) require less insider knowledge about the CNN but query the CNN for a set of inputs, and the collected information is used to create a substitute model, similar to the targeted CNN. This substitute model is attacked by gradient-based methods, leading to adversarial images that also fool the target CNN. Score-based attacks (see [10]) are even less demanding. They do not have access to the training data, model architecture, or CNN parameters. They only make use of the CNN’s predicted output probabilities for all or a subset of object classes.
Ideally, security issues posed by adversarial attacks are prevented by methods that detect malicious input images, potentially exclude them from further processing by the CNN, and alert the user. Such detectors may be tailor-made for a specific type of attack or applied efficiently to a large variety of attacks. Their performances are encompassed by a series of indicators that assess how far their outputs can be trusted, and the memory overhead, time, or complexity required to finish their tasks.
These detectors can be classified as supervised and unsupervised. On the one hand, supervised techniques have knowledge of adversarial images, and may attempt to reinforce CNNs by adding adversarial images to the training set [4]. These techniques are particularly effective when attacks are known in advance. On the other hand, unsupervised techniques [11,12,13,14] operate without prior access to adversarial images. Instead, they apply transformations to the input image and analyze the consistency of predictions between the input image and its transformed versions. These techniques operate on the premise that CNNs maintain consistent predictions for clean images.
This paper introduces ShuffleDetect as a new unsupervised method for the detection of adversarial images; it is simple to implement and works efficiently against adversarial images created by a series of 8 different attacks applied to 10 different ImageNet-trained CNNs.
To summarize, given image , ShuffleDetect assesses whether (resized to a square image, if necessary, to fit the CNN’s input size) is adversarial or not for a given CNN . Firstly, the algorithm extracts the dominating category in which classifies . Secondly, the algorithm essentially “splits” into non-overlapping patches of an equal size . Thirdly, for each permutation of a set of t permutations of these patches, the algorithm creates a shuffled image , and requires from the dominating category in which classifies the shuffled image. Lastly, the algorithm compares the outcome with . The detector classifies an input image as “adversarial” if the proportion of permutations among t permutations is such that the dominant categories of and differ by more than a certain threshold value .
The remainder of this paper is organized as follows. Section 2 provides an overview of how CNNs perform image classification, defines the attack scenarios and adversarial image requisites, and fixes some concepts and notations used throughout the article. Section 3 is devoted to related works, provides the topography of detection methods, and lists the main evaluation criteria used to assess their performances. The design of the ShuffleDetect method is detailed in Section 4, where the pseudo-code of the algorithm is also given explicitly.
To evaluate the reliability of our ShuffleDetect method, we tested it against a large set of adversarial attacks deceiving a significant series of CNNs. Section 5 lists the 10 selected CNNs trained on ImageNet, as well as the reasons for their choices, the 100 clean ancestor images, and the specific scenarios used in our experiments. Section 6 lists the 8 attacks that are considered in this paper, seven of which are “white-box”, while one is “black-box”. Whenever applicable, we performed both the targeted and untargeted versions of the attacks. A total of 15,000 attack runs led to 9580 relevant adversarial images: 2975 adversarial images for the targeted scenario and 6505 adversarial images for the untargeted scenario, as described in Section 7.
Section 8 specifies the parameters used by our detector for images handled by CNNs trained on ImageNet. This section essentially amounts to measuring the outcomes of individually for each permutation , each CNN , each clean image, and each image adversarial for , obtained by each attack for each scenario. The results lead to the selection of candidates for the threshold value . The performance of the detector is then assessed in Section 9 against the indicators given in Section 3 for the candidate values of . Beyond this intrinsic performance assessment, ShuffleDetect is compared with the well-known detector Feature Squeezing in Section 10.
Section 11 summarizes our findings, specifies our recommendations for the values of the parameters relevant to ShuffleDetect, and indicates some directions for future work.
Additional figures, tables, and relevant data are provided in the Appendix, including the original clean images, the permutations used, and individual performances of ShuffleDetect per CNN per attack per scenario.
Algorithms and experiments were implemented using Python 3.8 [15] with NumPy 1.19 [16] and PyTorch 1.9 [17] (including in particular the Adversarial Robustness Toolbox Python library used in Section 6). In addition, we used Maple 2022 to create the permutations used in Section 8 and Section 9. The main computations were performed on nodes using Nvidia Tesla V100 GPUs, which are part of the IRIS HPC Cluster at the University of Luxembourg [18].
2. CNNs and Adversarial Images
A CNN, which is expected to perform image classification, is first trained on a large dataset of images. Training consists of sorting the given images into a finite set of predefined categories. The categories , their number ℓ, and the images used in the process are associated with , and are common to any CNN trained on . The training phase of a CNN consists of two phases. Firstly, the CNN is given the training images, and, for each training image, a vector of length ℓ, where each real-value component assesses the probability that the training image represents an object in the corresponding category. Secondly, CNN is challenged against a validation set of images that assesses its ability to sort images accurately. Once trained, a CNN can be exposed to an arbitrary image, and perform its classification according to ℓ categories.
An important, albeit technical, issue involves the sizes of the images. While the sizes of the images of are arbitrary and may vary from one image to another, a CNN handles images of a fixed input size. Therefore, a resizing process is usually necessary to adapt a given image to the input size of the CNN before classification. To simplify the notation, we consider that this resizing process has been performed, and the input size handled by the CNN is square (Section 5 specifies which resizing function is used in the experiments). We also often identify image with its resized version, which fits the input size of the CNN.
Image classification and label values. Concretely, given an input image , the trained CNN produces a classification output vector
where for , and . Each component defines the -label value measuring the probability that image belongs to the category . Consequently, the CNN classifies image as belonging to the category if . One denotes this outcome, and the dominating category in which classifies . The higher the label value , the higher the confidence that represents an object of the category .
Adversarial image requisites. Assume that we are given a trained CNN, a category among the ℓ possible categories, and an image classified by as belonging to , with its -label value.
For any attack scenario that we consider in this paper (namely the target or the untargeted scenario, as made precise below), we assume that the attack aims at creating a new adversarial image , which remains so close to the ancestor’s clean image that a human would not be able to distinguish between and . The quantity , which controls (or restricts) the global maximum amplitude allowed for the value modification of each individual pixel of to obtain , numerically assesses this human perception.
In the untargeted scenario, is only required to classify the adversarial image as any class . In the target scenario, one selects, a priori, a target category . One would expect the adversarial image to be classified by as belonging to the target category , without any requirements on the -label value beyond it being strictly dominant among all label values (this coincides with the concept of a good enough adversarial image introduced in [19]; see [19] for variants of the target scenario involving -strong adversarial images).
Throughout the remainder of this article, any attack leading to the creation of adversarial images will be referred to as .
3. Related Works and Evaluation Criteria
As pointed out in the Introduction (Section 1), addressing the security issues posed by adversarial attacks often requires some warning that an attack is indeed taking place. The role of detectors is key in this process because their principal role is to decide whether an image is clean or not. Such detectors can be categorized into two groups: supervised and unsupervised detectors (see [20]).
Supervised detectors are designed and trained with images known to be adversarial and obtained from one or more attacks. In contrast, unsupervised detectors require no prior access to adversarial images and are, therefore, not limited to any particular type of attack. This suggests that unsupervised methods, which are more resource-efficient because they do not require any training for new attacks, may be more robust against new adversarial attacks than supervised attacks.
Numerous detection methods from both categories have been introduced (some of which aim at detecting adversarial images for ImageNet-trained CNNs). One can mention the following four detection methods referred to in [20]: the supervised LID [21], the unsupervised NIC [22], ANR [14], and FS [13].
The supervised Local intrinsic dimensionality (LID) method extracts intermediate layer activations from the CNN when fed with either clean or adversarial inputs. At each layer, the activations stemming from the image (clean or adversarial) and the activations stemming from a limited number of clean neighbors of the image are used to compute the local intrinsic dimensionality. The authors of [21] found that adversarial images tend to have higher local intrinsic dimensionality values. This property is exploited using the extracted values as features to train a binary classifier that declares an image as clean or adversarial.
The network invariant approach (NIC) is an unsupervised method that declares an image to be adversarial if it is out-of-distribution, and clean if it is in distribution. This notion refers to the distribution observed for the ImageNet training set, which consists of only clean images, for each CNN layer activation. For a given image, one obtains a collection of layer-level declarations, indicating whether the image is in distribution or not for that particular layer. The detector’s final declaration is an aggregation of all the layer-level declarations.
The adaptive noise reduction (ANR) algorithm is an unsupervised method that uses scalar quantization and smoothing spatial image filters to squeeze input images. The detector compares the categories predicted by the CNN for an image and for its squeezed version. If these categories are not identical, the image is considered to be adversarial.
The feature squeezing (FS) algorithm is an unsupervised method that applies depth reduction to an image color bit, a median image filter for local smoothing, and a variant of the Gaussian kernel for non-local spatial smoothing, leading to a squeezed image. The detector compares the output vectors predicted by the CNN for squeezed and unsqueezed images. The distance between the two vectors is measured, and if it exceeds a certain threshold, the image is considered adversarial.
Remark. Ideally, we compare ShuffleDetect with well-known detectors, among which NIC, LID, ANR, and FS, are introduced above. However, our attempt to do so led us to face several highly challenging issues, among which the following: The codes of most of these detectors are not available, the claimed performances are on CNNs different from ours (Inception V3 trained on ImageNet for instance), or on CNNs trained on different datasets than ImageNet (such as CIFAR10 or MNIST for instance, which also implies that these CNNs use images of smaller sizes than ours), the used attacks are not systematically and clearly documented, the definitions of the used performance indicators vary from one paper to another. A thorough comparison would require implementing all relevant alternative detectors essentially from scratch, and challenging them under the same conditions as ShuffleDetect. We do not undertake this complete task here and keep it for future work. Nevertheless, we provide in Section 10 a limited comparison between ShuffleDetect and FS.
Evaluation criteria. In the present paper, the performance of the detector is evaluated with the following indicators [20]:
- Detection rate (DR) represents the percentage of adversarial images that are correctly identified as such by the detector.
- False positive rate (FPR) represents the percentage of clean ancestor images that are identified as adversarial by the detector.
- Complexity refers to the time required to train a supervised detector.
- Overhead refers to the overall memory and computation resources necessary to use the detector (supervised or not). It depends on the number of parameters and size of the architecture of the detector, when applicable.
- Inference time latency is the amount of time required by the detector to run on an image. If the method is supervised, the inference time latency does not take into account the time needed to train the detector (this part is already taken into account in the Complexity measurements).
- Precision, Recall, and F1 scores used to quantify the detection performance are defined by the following formulae:where TP (true positive) is the number of correctly detected adversarial images, FN (false negative) is the number of adversarial images that escaped the detector, and FP (false positive) is the number of clean images declared adversarial by the detector. These formulae are pertinent whenever the number of clean images is equal to the number of adversarial images created by a given attack for a given CNN. This aspect is taken into account in Section 9.
4. ShuffleDetect
The general goal of the shuffling process is to interchange different parts of an image. We noticed in [23] that if one shuffles a clean image, CNNs usually classify the shuffled image into the same category as the unshuffled clean image. We also noticed that the situation differs from an adversarial image because CNNs usually tend to classify the shuffled adversarial image that is no longer in the same category as the unshuffled adversarial image, at least for those created by the two attacks of [23] (which are considered again in Section 6).
These findings, valid for the two attacks, led to the detection method exposed below, which is based on the assumption that shuffling affects the adversarial noise more than it affects the image’s original components, whichever the attack.
Shuffling an image. One is given image of fixed (square) size fitting the CNN’s input size, and an integer s, such that patches of size create a partition in the mathematical meaning of the term, or a grid in the more visual meaning of the term, of . This latter condition requires that s divides n since the number of patches is the integer . It is convenient in practice to label the patch , positioned in the column and row of the grid, as , where for (see Table A2 in Appendix B for an example, which is used in our experiments actually).
The set of possible scrambles of an image of size is essentially parametrized by the symmetric group of permutations of letters since operate on the set of patches. Indeed, a permutation is represented as a finite product of cycles, each of the form , these cycles having two-by-two disjoint supports. Each cycle symbolizes that the M patches , associated to , respectively, are rotated in a circular way: takes the position of , and so on until takes the position of .
The group is of order , and is non-trivial provided s is a strict divisor of n, which we assume from now on.
Given , one denotes by the image obtained from by swapping its patches according to . Both the unshuffled image and the shuffled image are given to the CNN for classification. Figure 1 illustrates the process with the partition of an image into 4 patches : The permutation , selected among the altogether elements of , is defined as the product of two cycles of length 2, which actually amounts to interchanging the patches on the diagonals.
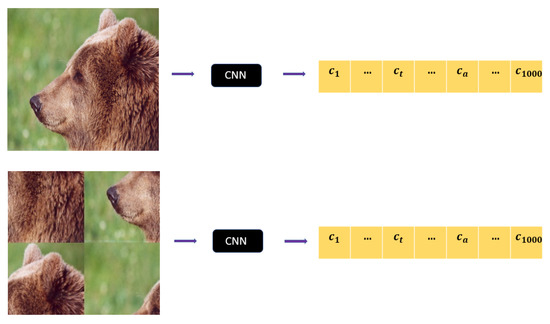
Figure 1.
A image is divided into 4 patches of size (top picture). The patches are shuffled around according to the permutation , leading to (bottom picture). Both and are sent to the CNN to extract the output vector.
ShuffleDetect. To some extent, the global design of the algorithm ShuffleDetect mimics the design of classical probabilistic primality tests (such as those of Fermat, Solovay–Strassen, or Miller–Rabin, see [24], chapter 7 for instance), where the validity of an equation, which should be satisfied if a given integer p is a prime, is checked for a series of rounds until either one has gained confidence (parameterized by the number of rounds) that p is probably a prime or the equation is not satisfied for one of the rounds, in which case one knows that p is not a prime. In our context, the equation, which assesses the detection of whether image is adversarial or not, consists of comparing the dominating categories, given by a given CNN , before and after shuffling, for many permutations.
With consistent notations, one round of this detection method for image is as follows. One picks at random a permutation , with . Unless all of the patches of addressed by are identical (what happens if all patches of are identical, which occurs, for instance, a fortiori if is absolutely monochrome throughout all its pixels), ensures that . The output of ShuffleDetect for for the specific permutation , denoted by , is:
The image is said -adversarial if , and -clean if .
For the full ShuffleDetect algorithm, written as for the considered CNN and image , one chooses a fixed number of rounds. For obvious practical reasons, t should remain relatively small, in particular far smaller than . Then one selects at random t two-by-two distinct permutations , with for all . One performs the successive t rounds .
The threshold ratio is fixed as a percentage at will. For any number t of permutations, the threshold ratio defines the integer , which is the number of permutations, such that .
The algorithm declares image :
- as “adversarial” for if the output of is -adversarial for more than of the t permutations ,
- and as “clean” otherwise.
In more algorithmic terms, on image works as described in the pseudo-code Algorithm 1. The user decides on the CNN , the degree of trust , and the number of permutations t that index the rounds of the loop composing Steps (7) to (13). Once these parameters are chosen, Steps (1), (2), (3) are essentially setups, defined by the choices made for the parameters , while Steps (4), (5), (6) are essentially an initializing phase, depending only on and . The choice of clearly determines the values of the indicators assessing the performance of the ShuffleDetect method (see Section 8 for a discussion on this issue and a recommended value).
| Algorithm 1 pseudo-code |
|
Remarks. (1) Note that the process of comparing dominant categories does not require a precise assessment of their actual label values. Even in the case where an image is considered -clean for a given permutation , it is likely that, although the same category dominates both in the unshuffled and shuffled versions of the image, its label values differ strongly between both images.
(2) Although there is some flexibility a priori in setting the value of parameter s at will, there are choices that turn out to be more appropriate for a given CNN’s input size (see Section 8 for the choice of s and its rationals for the experiments performed in this paper).
(3) When assessing many images of the same size, even if one fixes the number (t) of rounds once and for all, which is convenient in practice, there is still some flexibility in when to select the permutations. One option is to “reset” the random choice of t permutations for each image to be tested. Another option is to proceed to the choice of the permutations at the same time as one chooses the value t, so that both t and the set of t random permutations are decided once for all images to test. There are pros and cons for both options, the former being (slightly) more time-consuming and (slightly) more memory-consuming but less biased, the latter saving time, allowing for an easier comparison and reproduction of the experiments, but providing a possible security leak because an attacker may ultimately guess what the t-selected permutations are and adapt to them accordingly. See Section 8 for the choices made in our experiments.
(4) Although there are theoretical measures and bounds of the proportion of composite numbers declared probably primes after t rounds of a probabilistic test, there is no such thing regarding the proportion of adversarial images that are declared clean after t rounds of ShuffleDetect. Therefore, for the time being, our choice of parameters is purely experimental.
(5) One can generalize the ShuffleDetect method thanks to the group of symmetries that preserve the square, namely the (non-abelian) dihedral group of order 8. Indeed, with consistent notations, and since each patch is a square, one could add to the action of a cycle of a permutation a randomly chosen sequence of elements , which will act on the respective corresponding patches as well. We do not further explore this direction here, and stick to the exposed design of ShuffleDetect, which actually amounts to taking the identity for all symmetries .
5. The CNNs, the Scenarios, the Ancestor Images
The selection of CNNs used in our experiments followed three criteria involving practicality, stability, and comparability. First, we required the availability of the pre-trained versions of the CNNs in the PyTorch [17] library. Moreover, we required the CNNs to have stable architecture. Finally, to allow comparisons, despite their diversity in terms of architecture (number of layers, number of parameters, etc.), we required all CNNs to have the same image input size, and for this input size to be square (note that this later requirement is fulfilled by most CNNs in general).
This led us to select the following 10 well-known CNNs, trained on ImageNet [25], and with an input size of , namely VGG16 [26], VGG19 [26], ResNet50 [27], ResNet101 [27] and ResNet152 [27], DenseNet121 [28], DenseNet169 [28], DenseNet201 [28], MobileNet [29], and MNASNet [30].
Then, from the 1000 categories of ImageNet, we picked at random 10 ancestor classes and 10 corresponding target classes, as shown in Table 1.

Table 1.
For , the second column lists the ancestor category and its ordinal among the categories of ImageNet. Mutatis mutandis in the third column with the target category and ordinal .
For each of the 10 ancestor classes (), we randomly selected 10 () ancestor images from the ImageNet validation set, classified as belonging to by the 10 CNNs. Whenever necessary, these ancestor images were resized to the CNNs common input size , thanks to the bilinear interpolation function [31]. Figure A1 and Table A1 in Appendix A present the 100 ancestor images and their original sizes.
Starting with these 100 ancestor images, for each of the 10 CNNs listed above, the attacks, described in Section 6, were aimed at creating adversarial images either for the target scenario of Table 1 (all CNNs produced negligible -label values for the ancestors as a starting point) or for the untargeted scenario (in which case, it does not matter which category becomes dominant).
6. The 8 Attacks
This section presents the main features of the attacks employed in this paper and provides the chosen values for their parameters. Except for the EA attack, all attacks were applied using the Adversarial Robustness Toolbox (ART) [32], which is a Python library that includes several attack methods. ART functions and parameters used are specified in italics.
6.1. EA
Reference [19] is a black-box evolutionary algorithm-based attack that creates an initial population consisting of copies of the ancestor X and modifies their pixels over generations. The goal of the EA is encoded in its fitness function, , where is a population individual and is the individual’s probability given by the CNN. The population size is set to 40, the magnitude by which a pixel could be mutated in one generation is , the maximum mutation magnitude is , and the maximum number of generations is 10,000. We run both the targeted and untargeted versions of this attack. In the targeted case, for all CNNs, the threshold that dictates the adversarial image’s minimum probability was set to meet the good enough requirements of [19].
6.2. FGSM
Reference [4], a white-box attack, is a one-step algorithm that calculates the gradient of the loss function with respect to input X, to find the direction in which to modify X. In its untargeted version, the adversarial image is
while in its targeted version, it is
In the above equations, is the perturbation size, defined in the implementation by , and is the gradient function, as used in [4]. We use the FastGradientMethod function with the default value . We run both and , corresponding to targeted and untargeted attacks, respectively.
6.3. BIM
Reference [3], a white-box attack, is an iterative version of FGSM. The adversarial image is initialized with X and is gradually updated for a given number of steps N, as follows:
in its untargeted version and
in its targeted version, where is the step size at each iteration and (which coincides with the ART function eps) is the maximum perturbation magnitude of . We use the BasicIterativeMethod function with the default values , , and . We run with both and , corresponding to targeted and untargeted attacks, respectively.
6.4. PGD Inf
Reference [33], a white-box attack, is similar to the attack, with the difference that the image at the first attack iteration is not initialized with X, but rather with a random point situated within an -ball around X. The distance between X and is measured using and the parameter represents the maximum perturbation magnitude. We use the ProjectedGradientDescent function with , and the default values , , and . We run with both and , corresponding to targeted and untargeted attacks, respectively.
6.5. PGD
Reference [33], a white-box attack, is similar to PGD Inf, with the difference that is replaced with . We use the ProjectedGradientDescent function with , and the default values , , and . We run with both and , corresponding to targeted and untargeted attacks, respectively.
6.6. PGD
Reference [33], a white-box attack, is similar to PGD Inf, with the difference that is replaced with . We use the ProjectedGradientDescent function with , and the default values , , and . We run with both and , corresponding to targeted and untargeted attacks, respectively.
6.7. CW Inf
Reference [5], a white-box attack, solves the following optimization problem in its untargeted version:
and is the pre-softmax classification output. The measure used to evaluate the difference between the ancestor X and adversarial is . We use the CarliniLInfMethod function with the default values of the parameters. We ran with both and , corresponding to targeted and untargeted attacks, respectively.
6.8. DeepFool
Reference [34], a white-box attack, is an untargeted attack that calculates the minimum perturbation with which to modify X such that its classification label changes, where , , . The attack solves the following optimization problem:
The algorithm stops immediately after the label is changed, and . We use the DeepFool function with the default values of the parameters.
The seven attacks EA, FGSM, BIM, PGD Inf, PGD L1, PGD L2, and CW Inf are used both in the untargeted and in the target scenario, and the remaining DeepFool attack is used only in the context of the untargeted scenario. Apart from the black-box EA attack, all others are white-box attacks.
7. The Adversarial Images Obtained by the 8 Attacks
For each CNN provided in Section 5, we run each of the 8 attacks given in Section 6, either for the untargeted scenario or for the target scenario whenever applicable, for the (potentially resized) 100 ancestor images , referred to in Section 5, and pictured in Figure A1, Appendix A. A successful attack for the untargeted scenario results in the image , adversarial for for that specific scenario. Mutatis mutandis with an adversarial image for the target scenario.
Since there are 8 untargeted and 7 targeted attacks, this amounts to attacks CNNs ancestor classes images per ancestor class. Out of these altogether 15,000 attack runs, 9746 were successful. More precisely, 6727 out of the 8000 untargeted attacks were successful, and there were 3019 successful targeted attacks out of the 7000 attempts, as detailed in Table 2.
Table 2.
For each attack , and each , the number of successful runs performed on the 100 ancestors are presented. The results are given as a pair or as a single value , depending on whether is performed for both the untargeted and the targeted scenarios (assessed, respectively, by the values of in the pair), or only the untargeted scenario (assessed by the single value of ). The successful attacks on each individual CNN are given in the last row with obvious notations.
Clearly, the number of successful attacks should be statistically relevant. We define this condition as satisfied if an attack succeeds in at least of the cases for a given CNN (this value appears as a reasonable trade-off based on the experiments leading to Table 2). This leads us to disregard the targeted attacks performed by FGSM and CW Inf for all CNNs, as well as all attacks (untargeted and targeted) performed by PGD L1 and the untargeted attack of FGSM on . The remaining 9580 statistically relevant successful attacks are listed in Table 3. The corresponding 2975 adversarial images for the target scenario and 6505 adversarial images for the untargeted scenario are considered in subsequent experiments.
Table 3.
For each attack , and each , the number of successful runs performed on the 100 ancestors are presented, for which at least were terminated successfully. The results are given as a pair or as a single value , depending on whether is performed for both the untargeted and the targeted scenarios (assessed, respectively, by the values of in the pair), or only the untargeted scenario (assessed by the single value of ). The statistically relevant successful attacks on each individual CNN are given in the last row with obvious notations.
8. Parameters and Experiments Performed on
In what follows, we essentially consider for each individual permutation , each CNN , each clean image, and each image that is adversarial against . Altogether, the method is applied to all (resized if necessary) ancestors on the one hand, as well as to all 2975 successful adversarials and all 6505 successful adversarials that compose Table 3 on the other hand. The ShuffleDetect parameters are specified below.
Size of patches, number of permutations, and . Firstly, we selected based on experiments detailed in [23]. Indeed, Table 4, extracted from [23], shows the average outcome for adversarial images obtained from 84 common ancestor images (of size ) for the same 10 CNNs considered here. The shuffling process was performed in [23] only for one permutation per value of s (hence in this case) to obtain the values of Table 4.
Table 4.
Percentages of shuffled images (first percentage), (second percentage), and (third percentage) for which the predicted class is c.
The experiments performed in [23] show that among the four considered possibilities, provides an optimal balance between the proportion of clean ancestors that are correctly declared “clean” (), and the proportion of adversarial images that are correctly declared “adversarial” ( for the adversarial images created by the EA, and for those created by BIM) by our method. The choice of being made, there are consequently patches of size , and the symmetric group has different permutations.
Secondly, to keep the computations manageable, we selected at random 100 permutations (they are given in Table A3 in Appendix B). For , one defines as the set of the first t permutations. One has if . In particular, the first permutation is common to all sets , the second permutation is common to all sets for , etc.
Given a set of images and a CNN, one defines the function as the proportion of images in declared -adversarial for s out of the first t permutations. In other words, for t and s such that , one has:
Geometrically, and being fixed, defines a discrete surface. For a given , this function provides an assessment of the FPR value of the ShuffleDetect method for by choosing for a set of images known to be clean. This function also provides an assessment of the DR value by choosing for a set of images known to be adversarial for .
As already stated in Section 4, the actual values of FPR and DR are determined by the choice of the threshold ratio . Its value is fixed as a consequence of the experiments performed on clean images, on the one hand, and adversarial images, on the other hand.
Assessment of the clean images. In the first step, we take for the set of 100 clean ancestors represented in Figure A1 (Appendix A). For , one computes for all 100 permutations . This leads to the 10 histograms represented in Figure A2 in Appendix C. An example of the outcomes is illustrated in Figure 2a for = VGG16, where each vertical bar assesses the number of clean images classified as adversarial for a number of permutations given on the x-axis, out of the 100 possible permutations. The notations and indicate that the number of permutations is between a and b, with both included in the former case and a excluded in the latter case. The average outcome (mutatis mutandis) for 10 CNNs is shown in Figure 2b.
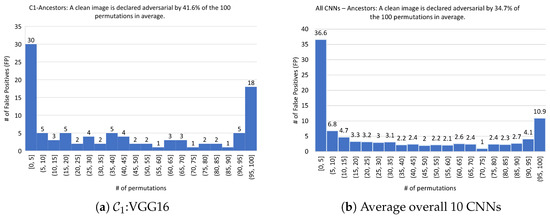
Figure 2.
ShuffleDetect performed on 100 clean (ancestor) images with 100 permutations.
Over the 100 clean images, on average, over the 10 CNNs, an image is declared adversarial by of the 100 considered permutations, as indicated in Figure 2b. Table 5 shows that this percentage varies between (for ) and (for ).
Table 5.
For each , the number (=percentage) of clean ancestors declared adversarial for s out of 100 permutations. The first row shows the average number of permutations for which this occurs. The last row, the sum of the two previous ones, provides an estimate of the FPR, which serves as a lower bound for ShuffleDetect per CNN via the assessment of .
The last row of Table 5 provides an estimate of a realistic FPR, which serves as a lower bound, or an “incompressible” FPR, whatever the choice of the parameter . On average, over the 10 CNNs, , and its value varies between (for ) and (for and ). In this context, we noticed that some individual clean images were declared adversarial by for all CNNs by a large number (and, therefore, a proportion) of permutations . Indeed, the 7 clean images , , , , , , and are declared adversarial for all CNNs by more than 91 permutations. Whatever the ratio threshold , these 7 images contribute substantially to the FPR of for a specific CNN individually, and a fortiori for the FPR average taken over all CNNs.
Assessment of the adversarial images. In the second step, for , we take for the set of adversarial images as of Table 3. One computes the values of for these images for all 100 permutations , and one defines
which captures the optimum index that makes sure that , where is the maximum possible detection rate of adversarial images created by the given attack on the given CNN. Clearly if there are no adversarial images for which
for all 100 permutations . While this eventuality does not occur in our experiments with the target scenario, we shall see that it does for the untargeted scenario for many attacks and many CNNs.
We proceed firstly with the target scenario. This leads to the 40 histograms (obtained from 4 targeted attacks performed on the 10 CNNs) represented in Figure A3, Figure A4, Figure A5 and Figure A6 in Appendix C. The following Figure 3 shows the average behavior over the 10 CNNs of the ShuffleDetect method for all 100 permutations in the adversarial images created by each targeted attack. Note that the y-axis indicates the average number of adversarial images for a given attack, and all CNNs are taken together, as derived from Table 3. For example, there are adversarial images on average for the target scenario for BIM.
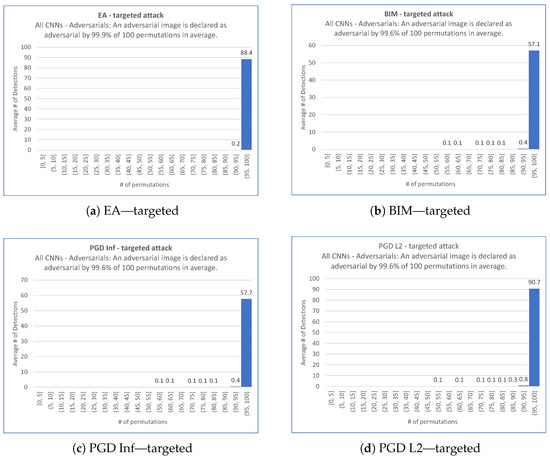
Figure 3.
Average outcome over the 10 CNNs of ShuffleDetect performed with 100 permutations on the adversarial images created for the target scenario by EA, BIM, PGD Inf, and PGD L2.
Table 6 details the outcomes for each CNN individually, and provides an assessment of the detection rate DR of the ShuffleDetect method for the detection of adversarial images for the target scenario created by each of the four attacks. More precisely, for each , for each targeted attack , the table first provides the percentage s of the 100 permutations for which the shuffled-by image of an adversarial image, namely , is declared adversarial on average. Consistently with assessments performed on the clean images, Table 6 provides . Note that the number of elements of used to compute these values is equal to the corresponding value from Table 3. Finally, Table 6 provides the values of and of .
Table 6.
For each , for each targeted attack , percentage s of the 100 permutations for which the shuffled-by image of an adversarial image, namely , is declared adversarial on average, assessment of , of the maximum possible detection rate , and of .
We proceed with the untargeted scenario. This leads to the 69 histograms (derived from 6 untargeted attacks performed on the 10 CNNs, and from the FGSM untargeted attack performed on 9 CNNs) represented in Figure A7, Figure A8, Figure A9, Figure A10, Figure A11, Figure A12 and Figure A13 in Appendix C. The following Figure 4 provides the average behavior over the 10 (or 9 in the case of FGSM) CNNs of the ShuffleDetect method for all 100 permutations on the adversarial images created by each untargeted attack. Note that the y-axis indicates the average number of adversarial images for a given attack, all relevant CNNs taken together, derived from Table 3. For instance, there are adversarial images on average for the untargeted scenario for FGSM.
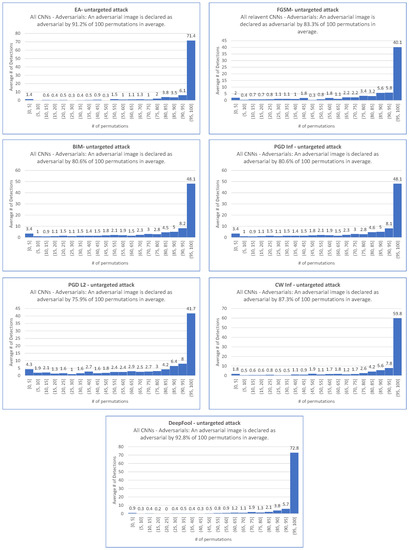
Figure 4.
Average outcome over all relevant CNNs of ShuffleDetect performed with 100 permutations on the adversarial images created for the untargeted scenario by EA, FGSM, BIM, PGD Inf, PGD L2, CW Inf, and DeepFool.
With notations consistent with the already handled case of targeted attacks, Table 7 details the outcome for each CNN individually, and provides an assessment of the DR of the ShuffleDetect method applied to adversarial images for the untargeted scenarios created by each of the seven attacks. The number of elements of used to compute the values of is equal to the corresponding value from Table 3.
Table 7.
For each , for each untargeted attack , the percentage s of the 100 permutations for which the shuffled-by image of an adversarial image, namely , is declared adversarial on average, the assessment of , of the maximum possible detection rate , and of .
9. Intrinsic Performance of
Indicators and performance. Since is an unsupervised detector, the complexity criterion does not apply. The values of the remaining indicators do depend on the number t of permutations to be considered, and most of them are determined by the selected threshold ratio .
To assess the inference time latency, the creation of permutations (Step 1 of Algorithm 1) took s using the command SymmetricGroup(16) and 100 calls of the command RandomElement on Maple 2022 (this timing could certainly be optimized). Running for a single permutation (Steps 8 to 12 of Algorithm 1) takes s/permutation on average (over 100 considered permutations, overall 10 CNNs, and over 100 random clean images because considering them is sufficient to assess this average). The time required by Steps 2, 3, 6, and 14 (all of which are outside the loop of the t permutations) is negligible. The overall inference time latency of ShuffleDetect performed on an image with permutations amounts to s/image on average. On the one hand, the prediction process performed by the CNN (one time in Steps 4 and 5 for the unshuffled image, and times in Steps 9 and 10 for the shuffled images) contributes to of this time consumption. On the other hand, the shuffling process (Step 8, called times) contributes to of this time consumption. See Appendix B, Table A4 for detailed information on all CNNs.
One should take into account two positive aspects of the proposed detector. Firstly, the s consumed by the creation of the 100 permutations can be mutualized over several calls of the detector for different input images. Secondly, the tasks performed iteratively (Steps (7) to (13)) can be easily distributed; thus, apart from the time required for the creation of the 100 permutations, the algorithm would require only , plus some minor time due to the gathering of the distributed information, and the final computation and comparison.
The Overhead is very limited (and can be optimized). Algorithm 1 shows that the “permanent storage” is limited to the permutations expressed as products of cycles as in Table A3, Appendix B (which actually can be called upon if the permutations are computed once for all images to handle as we do in our experiments), the integer , and the extracted dominating category (which amounts to a numbering among the 1000 categories of ImageNet in our case). The “incremental storage” is made of the value 0 or 1 as progresses throughout the t permutations, hence (at most) t such Boolean values if one wants to keep the whole information. A memory-saving alternative is to keep only the updated N as progresses throughout the t permutations. The “ephemeral storage” (deleted after each run) is composed of the running images and . The computation resources are essentially limited to the creation of t permutations (to be done once at the beginning, as recommended), to calls to the CNN for the classification of and , and to the creation of the (up to) t shuffled images . Finding the dominant category, as is necessary once for and (at most) t times for the shuffled images, amounts to looking for the largest value in the classification output category, which is immediate in a set of 1000 values, as is the case here.
Note that in what precedes, we mention “at most” a few times since one could stop the loop before its natural end. This is the case if after some rounds the running threshold reaches such a value that the remaining rounds, whatever happens, cannot ensure that the threshold ratio will not be reached.
The specific value chosen for clearly impacts the different indicators of the ShuffleDetect algorithm (but, foremost, FPR and DR). To summarize, the smaller the , the higher the DR and FPR. However, our experiments show that a high leads to a very good DR and a moderate FPR. A b-moll to this statement is that the situation differs according to the nature of the “targeted” or “untargeted” attack, as we shall see now.
For targeted attacks, Table 6 together with Figure A2 led us to consider (for permutations) four choices for the value for :
- matches the requirement that most permutations declare an image as adversarial.
- is motivated by the fact that the smallest among the 100 permutations and the four targeted attacks is .
- is motivated by the fact that the average of the among the 100 permutations and the four targeted attacks is .
- as a demanding ratio compromise.
For untargeted attacks, Table 7 together with Figure A7, Figure A8, Figure A9, Figure A10, Figure A11, Figure A12 and Figure A13 (Appendix C) show that (for permutations) using is irrelevant for the selection of . Indeed, is usually small. More precisely, in all cases, and is on average, as opposed to what occurs for the target scenario, where in all cases, and is on average. Therefore, we limit the selection of to two values:
- for the same reason as for the target case.
- because it makes sense to keep the same demanding value for the detector independently on the scenario of the attack, hence the same value for the targeted attack.
The values of FP and FPR depend only on the value of (since no attack is considered for their computation), and on the CNN. Note that for permutations. One writes and for their respective average values over the 10 considered CNNs. Table 8 provides the corresponding values for , and (the four values used in the context of the target scenario also contain the two values used in the context of the untargeted scenario) for permutations.
Table 8.
Table of FP per CNN for each selected value of ; FPR is deduced from FP by the formula .
Remark. The number of adversarial images against each CNN, created either by targeted or untargeted attacks, is in all cases strictly less than the number of clean ancestor images from which these attacks started. As mentioned at the end of Section 3, this imbalance should be considered to have a fair comparison basis and sound values for the indicators (what we measure is the performance of the indicator, not of the attack). Therefore, in Table 9, Table 10, Table 11 and Table 12 the clean images selected are those that correspond to the adversarial images obtained from them. For instance, since the EA-targeted attack succeeded to create “only” 91 images adversarial against , we consider only the exact 91 clean images from which these adversarial images were obtained to assess the FP value.
Table 9.
Targeted attacks—DR as a percentage, and TP, FP, FN, precision, recall, F1 scores for CNN, per attack, for selected values of and , and their corresponding averages.
Table 10.
Targeted attacks—DR as a percentage, and TP, FP, FN, precision, recall, F1 scores per CNN per attack for each selected value of and , and their corresponding averages.
Table 11.
Untargeted attacks—DR as a percentage, and TP, FP, FN, precision, recall, F1 scores per CNN per attack for each selected value of , and their corresponding averages.
Table 12.
Untargeted attacks—DR as a percentage, and TP, FP, FN, precision, recall, F1 scores per CNN per attack for each selected value of , and their corresponding averages.
For targeted attacks, Table 9 and Table 10 show (for permutations) the DR (which coincides with ), TP, FN, precision, recall, and F1 score values per CNN per targeted attack for each of the four selected values of , as well as their average values.
For untargeted attacks, Table 11 and Table 12 show (for permutations) the DR (which coincides with ), TP, FP, FN, precision, recall, F1 scores per CNN per untargeted attack for each selected value of , as well as their average values.
Conclusion for the intrinsic performance of ShuffleDetect. Regarding targeted attacks, Table 9 and Table 10 show that the difference in values of the indicators obtained when versus (respectively, versus ) remains marginal.
If one knows the nature of “targeted” and “untargeted” attacks, and/or if one knows which specific attack to expect, one can choose the most appropriate threshold ratio value . However, one rarely has access to this intelligence in practice.
Consequently, it makes sense to consider a priori only or whatever the attack (hence, a fortiori whatever its targeted or untargeted nature). Table 13 provides the values of all indicators per CNN on average over the 4 targeted attacks. It also provides the worst value as a proxy of the worst case for our detector. Similar information for untargeted attacks is given in Table 14.
Table 13.
Average for all indicators (worst case for F1) per CNN over all 4 targeted attacks.
Table 14.
Average for all indicators (worst case for F1) per CNN over all 7 untargeted attacks.
Table 13 and Table 14 show that our detector achieves very good results. For instance (when both and are considered) for the two highly significant indicators made of the detection rate and the values:
- For all targeted attacks, the detection rate is , the value is , and the average values of these indicators are and , respectively.
- For untargeted attacks, the detection rate is , the value is , and the average values are and , respectively.
Recall that a defender does not know the nature (targeted or untargeted) of an attack he is exposed to. For the sake of completeness, Table 15 provides the values of all indicators per CNN in the average overall attacks, targeted and not targeted, for the two values and .
Table 15.
Average for all indicators (worst case for F1) per CNN over all attacks.
Now, as a defender, it is wise to consider the values of the indicators given in Table 14 for untargeted attacks, since then one is also “on the safe side” for targeted attacks as well.
A remaining issue is whether one can achieve results as those given in Table 14 (allowing one to be “on the safe side”, as pointed out above), say for DR, precision, recall, and F1, with less than 100 permutations. For instance for , can one achieve (DR, precision, recall, F1) = (77.5, 0.7, 0.8, 0.7) in less than 100 permutations? Indeed, doing so would clearly speed up the process (see Table A4 to assess time savings per spared permutation).
We performed a series of tests with increasing values of the number of permutations, aimed at indicator values, as those of Table 14. More precisely, we fixed the indicator values as those of Table 14, and we added permutations one by one (following their numbering, as given in Table A3), and stopped when we achieved those fixed indicator values. Note that the minimal number of permutations, with which it makes sense, from a mathematical point of view, to start this process, depends on the value of .
For , it makes sense to consider , while for , it makes sense to consider . Therefore, for each CNN , for each attack , targeted or untargeted accordingly, starting with the first 3 permutations for (respectively, the first 12 permutations for ), we added the subsequent permutations whenever appropriate, and stopped the process when the minimal number of permutations fulfilling the above criteria was achieved. Table 16 provides the outcome of this experiment.
Table 16.
For and , the optimal number of permutations per CNN and attack, and the optimal number of permutations per CNN valid for all tested attacks (potentially relevant to assess unknown attacks).
Finally, which value for do we privilege? We considered the DR indicator as the most significant one to make our choice. With this indicator, we concluded that the “democratic” value is an appropriate and reasonable choice for most applications of ShuffleDetect. In terms of the number of permutations, one can use the number , defined for in Table 16, according to the CNN considered. This value is convenient for the relevant 4 targeted attacks and 7 untargeted attacks studied here. However, especially in view of the low time and memory price to pay for additional permutations, we consider that a defender who uses 100 permutations is better prepared against unknown attacks. Refinements in this regard are still possible, especially since ShuffleDetect is on the defender’s side, the defender knows which CNNs to protect so that he can adapt accordingly.
10. Performance Comparison of ShuffleDetect and Feature Squeezer (FS)
To assess the extrinsic performance of ShuffleDetect, we compared it with the FS detector [13]. We selected this detector since, similar to ShuffleDetect, it is an unsupervised detector, which also presents no significant complexity issues. The comparison between ShuffleDetect and FS is performed only according to the detection rate, and not according to the other indicators mentioned in Section 3, since, for instance, the value of FPR in [13] is determined by the behavior of FS as compared to another detector (MagNet [35]); hence, it is not an intrinsic value, to the difference of what we do in Section 9 for ShuffleDetect. Therefore, the comparisons of the detectors are performed on the 9480 images of Table 3, adversarial against the 10 considered CNNs (Section 7).
In our experiments, we used multiple squeezers for FS as suggested in [13] (we keep their notations in what follows). The norm is used to measure the difference between the prediction by the CNN of the input image and the prediction of the squeezed input image:
where x is the input image and is the classification vector of the CNN according to the different categories. Multiple feature squeezers are combined in the FS detector. In practice, one computes the maximum distance:
The values of the parameters of the FS squeezers are chosen as the optimal values recommended in [13]:
- Color depth reduction: the image color depth is decreased to 5 bits.
- Median smoothing: the filter size is set to .
- Non-local means: the search window size is set to , the patch size is set to , and the filter strength is set to 4.
- The threshold is set to .
The image is declared by the FS detector as adversarial if and is declared clean otherwise.
For , consistently with the outcomes of Section 9, we set , for all CNNs in the experiments (note that the size of the patches is kept to for the images considered here).
Table 17 compares the detection rates of ShuffleDetect and FS for the 9480 adversarial images referred to. For the 2975 adversarial images for the targeted scenario, both detectors demonstrate high success rates. Even if FS achieves DR over , it is outperformed by ShuffleDetect, which achieves in all cases. For the 6505 adversarial images for the untargeted scenario, the success rates of both detectors experience a decline. FS achieves slightly better results than ShuffleDetect for DeepFool and CW Inf, and significantly better results for PGD Inf, BIM, PGD, and L2; it is outperformed by ShuffleDetect, slightly for FGSM, and highly significant for EA. Regarding the overall performance (see the last row of Table 17), ShuffleDetect achieves a higher success rate than FS on average (both scenarios and all CNNs considered).
Table 17.
Performance comparison of ShuffleDetect and FS regarding detection rates.
11. Conclusions
In this paper, we presented ShuffleDetect as a new unsupervised method for the detection of image adversarials against trained CNNs. We provided a complete design and recommendations for the selection of the values of its parameters. Given a CNN and an image potentially resized to fit the CNN’s input size, the steps that essentially compose this new detection method are fairly simple. During the initiation phase, the dominant category in which the CNN sorts the input image is required, the image is split into non-overlapping patches (of fixed sizes, depending on the CNN’s own input size), and a fixed set of appropriate permutations is selected at random. Then a loop is performed according to the successive permutations, where the patches are shuffled with the running permutation, and the dominant category in which the CNN sorts the shuffled image is compared with the outcome for the unshuffled image, leading to a Boolean value. Finally, one assesses the proportion of permutations for which the CNN classifies the shuffled image into a different category than the unshuffled input image. ShuffleDetect declares the image as adversarial if this proportion exceeds a threshold value and declares the image clean otherwise.
Our extensive experiments with 10 diverse and state-of-the-art CNNs, trained on ImageNet with images usually resized to , with 8 attacks (one ’black-box’ and seven ’white-box’), and with 9500 clean and adversarial images for the targeted or untargeted scenario led us to recommend a size of for the altogether 16 patches, and the “democratic” value . Although running ShuffleDetect with 100 permutations is perfectly feasible and could be considered a safe option, a smaller number of permutations, varying between 12 and 68 according to the considered CNN, may also lead to a satisfactory detection rate. Additionally, if the defender has more information about the type of attack expected, the number of permutations can be fine-tuned accordingly. This said, and since this type of knowledge occurs rarely, we recommend taking at least 100 permutations.
Apart from the time needed for the creation of a fixed set of permutations, namely s to obtain 100 permutations, which can be performed once for all (at least in our implementation), the intrinsic performance of ShuffleDetect on our computers shows an inference time latency of s per image per permutation. The algorithm can be easily parallelized so that the required time for a complete run of the algorithm can be significantly less than the s/image when this task is not distributed. Out of this time-consuming process, the classification process of an image by the CNN is ; therefore, the shuffling process itself requires only . The overhead is very limited since its main part, the “permanent storage”, is required essentially only for the 100 permutations (the storage per permutation is a sequence of groups of distinct integers between 1 and 16 in our case), and the dominating category of the unshuffled image. Among the main indicators of a detector, the most relevant ones are the false positive rate and the detection rate. With and 100 permutations, as well as the average overall considered CNNs and images, ShuffleDetect achieves an average FPR of , an average DR of for the adversarial images obtained by targeted attacks, and of those obtained by untargeted attacks. Our study also provides the scores of the other relevant indicators, i.e., TP, FP, FN, precision, recall, and F1.
While performing a thorough comparison with other detectors requires overcoming the difficult challenges outlined in Section 3, in order to make sound comparisons under the same conditions, we performed this task for one detector, namely FS, and showed that, on average, ShuffleDetect achieves better detection rates than FS.
Independent of the outcome of any comparison process with other detectors, our ShuffleDetect method could be used as a first line of defense before applying more sophisticated, time-consuming, and overhead-consuming detection methods than ShuffleDetect.
As a potential area for future research, it would be worthwhile to assess the effectiveness of ShuffleDetect using CNNs trained on Cifar10 and MNIST datasets. This could result in determining the optimal patch size as a ratio to the image size. Additionally, it would be beneficial to explore the optimal patch size for images containing very small or very large objects.
Author Contributions
All authors: writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors thank Uli Sorger for the fruitful discussions on this subject.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A

Figure A1.
The 100 ancestor images used in the experiments. pictured in the qth row and qth column () is randomly chosen from the ImageNet validation set of the ancestor category specified on the left of the qth row.
Figure A1.
The 100 ancestor images used in the experiments. pictured in the qth row and qth column () is randomly chosen from the ImageNet validation set of the ancestor category specified on the left of the qth row.

Table A1.
The original sizes of the 100 ancestor images before resizing with the bilinear interpolation function.
Table A1.
The original sizes of the 100 ancestor images before resizing with the bilinear interpolation function.
| Ancestor Images and Their Original Size | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| abacus | 1 | (206, 250) | (960, 1280) | (262, 275) | (598, 300) | (377, 500) | (501, 344) | (375, 500) | (448, 500) | (500, 500) | (150, 200) | |
| acorn | 2 | (374, 500) | (500, 469) | (375, 500) | (500, 375) | (500, 500) | (500, 500) | (375, 500) | (374, 500) | (461, 500) | (333, 500) | |
| baseball | 3 | (398, 543) | (240, 239) | (180, 240) | (333, 500) | (262, 350) | (310, 310) | (404, 500) | (344, 500) | (375, 500) | (285, 380) | |
| broom | 4 | (113, 160) | (150, 150) | (333, 500) | (500, 333) | (497, 750) | (336, 500) | (188, 250) | (375, 500) | (334, 500) | (419, 640) | |
| brown bear | 5 | (500, 333) | (286, 490) | (360, 480) | (298, 298) | (413, 550) | (366, 500) | (400, 400) | (348, 500) | (346, 500) | (640, 480) | |
| canoe | 6 | (500, 332) | (450, 600) | (500, 375) | (375, 500) | (406, 613) | (600, 400) | (1067, 1600) | (333, 500) | (1536, 2048) | (375, 500) | |
| hippopotamus | 7 | (375, 500) | (1200, 1600) | (333, 500) | (450, 291) | (525, 525) | (375, 500) | (500, 457) | (424, 475) | (500, 449) | (339, 500) | |
| llama | 8 | (500, 333) | (618, 468) | (500, 447) | (253, 380) | (500, 333) | (333, 500) | (375, 500) | (375, 500) | (290, 345) | (375, 500) | |
| maraca | 9 | (375, 500) | (375, 500) | (470, 627) | (151, 220) | (250, 510) | (375, 500) | (99, 104) | (375, 500) | (375, 500) | (500, 375) | |
| mountain bike | 10 | (375, 500) | (500, 375) | (375, 500) | (333, 500) | (500, 375) | (300, 402) | (375, 500) | (446, 500) | (375, 500) | (500, 333) | |
Appendix B
Table A2.
For a image, grid of its 16 patches of size , represented as (left grid), and as (right grid) as used by the permutations .
Table A2.
For a image, grid of its 16 patches of size , represented as (left grid), and as (right grid) as used by the permutations .
| Left Grid | Right Grid | ||||||
|---|---|---|---|---|---|---|---|
Table A3.
For t up to 100 rounds, the list of random permutations for . Each is represented as the product of cycles operating on 16 patches of a image.
Table A3.
For t up to 100 rounds, the list of random permutations for . Each is represented as the product of cycles operating on 16 patches of a image.
| t = 100 | |||
|---|---|---|---|
| Round | Permutation | Round | Permutation |
| 1 | (1,13,4,6)(2,14,10)(3,11,12,5,9)(7,16,15,8) | 51 | (1,9,10,8,13,6,2,15,5,14,4,7,11)(3,16) |
| 2 | (1,8,9,2,6,11,15,12)(3,4,5,10,7)(14,16) | 52 | (1,11,15,4,10,2,3,5,12,9,13,8,16,7)(6,14) |
| 3 | (1,2,10,12)(3,11,16,15)(4,6,13,7,14,9,5) | 53 | (1,12,3,7,2,5,6,15,16,14,4,10)(8,13)(9,11) |
| 4 | (1,12,7,6,9,5,13,16)(2,4,14,10)(3,11,15,8) | 54 | (1,2,13,12,7)(3,6,4,8)(9,10)(11,15) |
| 5 | (3,5,14,16,7,4,12,6,13,11)(8,15,9,10) | 55 | (1,6,3)(2,12,14,4,15,7)(5,9)(8,13,10,11,16) |
| 6 | (1,7,4,9,2,5)(3,14)(6,16,8,13,10,15,12,11) | 56 | (1,8,3,4,13,10,9,16,5,2,7,11,12)(6,15) |
| 7 | (1,7,15,5,10,4,2,13,14,12,6,9)(3,11,16,8) | 57 | (1,5,12,9,15,4,7,11,2,10,6,16,8,3,14) |
| 8 | (1,2,5)(3,11,16,10,12,9,7,6,15,4,13,8) | 58 | (1,12)(2,6,13,10,7,8)(3,15,5,16,11,9)(4,14) |
| 9 | (1,7,15,8,13,5,9,11)(2,12)(3,16,14,4)(6,10) | 59 | (2,11,13,6)(3,12,10,7,16,4)(5,8)(9,15,14) |
| 10 | (1,16,8,15,4,5,6)(3,14,13)(7,12)(9,10,11) | 60 | (1,13,15,8,4,14,5,9,12,7,10,11,16,3,6,2) |
| 11 | (1,8,10,13,9,6,2)(3,12,5,15,14,4,7)(11,16) | 61 | (1,2,14,6,10,7)(4,5,12,9,8,16,11) |
| 12 | (1,4,14,16,5,6,11,13,15,9)(2,12,10,3,8) | 62 | (1,11)(2,7,4,5,10,12,14,9)(3,6,8,13,15,16) |
| 13 | (1,5,14,13,10)(2,6,7,4,8)(3,15,11,9,16,12) | 63 | (1,9,14,15,11,5,8,10,2,4,3,12,16,13,6,7) |
| 14 | (1,16,9,4,3,2,5,7,6,11,12,10,8,15,14,13) | 64 | (2,11,12,10,5)(3,16,14,13,4,8,6,15)(7,9) |
| 15 | (1,16,5,13,8,6)(2,15,14,10,11,12,9,3,7,4) | 65 | (1,5,12,3,2,6,11,13,16,14)(7,10,15) |
| 16 | (1,14,12,2,13,7,10,8,3,15,11,6,16,4) | 66 | (1,15,7,11,12,2)(3,10,4,14,5,8,6,16,9,13) |
| 17 | (1,2,5,13)(4,11,8,10,16,14,15)(6,7)(9,12) | 67 | (1,4)(2,6,15,11,12,16)(3,5,14)(7,8)(9,10) |
| 18 | (1,12,13,16,3,8,10,2,11,14,7,4,15,6) | 68 | (1,13,6,14,2,10,5,15,11,9,4,12,8,3,7,16) |
| 19 | (1,8,4,16,3,13,6,7,15)(2,12)(5,14,11)(9,10) | 69 | (1,9,15,6,8,10,11,2,12,16,4,13,14,7)(3,5) |
| 20 | (1,14,15,5)(2,4,12,13)(3,8,16,11)(6,7)(9,10) | 70 | (1,2,6,8,3)(4,12)(5,7,13,10,15)(9,11,14,16) |
| 21 | (1,2,6)(3,8,14,10,13,12)(5,9,16,15) | 71 | (2,10,16,6,13,3,14,12)(4,5,8,15,7,9,11) |
| 22 | (1,3,11,14,2,10)(4,12,6,7,15,5,16,9)(8,13) | 72 | (1,8,13,7)(2,10,15,6,14,9,3,16,5,11) |
| 23 | (1,4,11,9,14,7,2,5,3,8,6)(10,15) | 73 | (1,5,16,12,6,2,8,11,4,10,9,13,14)(7,15) |
| 24 | (1,12,8,7)(2,4,5,14,6,9,3,13,16)(10,15,11) | 74 | (1,6,16,13,11,5,14,4,3,9,15,2,8,10,7) |
| 25 | (1,14,6,4,10,16,5,13,12,2,8,15,9,3,7,11) | 75 | (1,12,9,6,15,4,5,14,2,3)(7,11,16)(8,13) |
| 26 | (1,15,5)(2,13,4,9,16,8,11,12,3,6,10,14,7) | 76 | (1,11,15,16,9)(2,12,5,3,8,13,6)(7,10,14) |
| 27 | (1,10,8,12,14,7,2)(3,13,11,5,6)(4,15) | 77 | (2,8,15,10,16,9,12,7,4)(3,5,11,14)(6,13) |
| 28 | (1,8,11,7,16,5,6,12,4,14)(2,15,3,10,9) | 78 | (1,15,11,8,16,5,2,12,3,13,6,10,14)(4,9) |
| 29 | (1,5,3,12,15,11)(2,14,10,6,8,9,7,13,16) | 79 | (1,16,13,5,3,10,6,4,15,2,11)(7,14,9) |
| 30 | (1,10,8,15)(3,9,7,4,12)(5,11,6) | 80 | (2,10,13,11,15,6,5,8,3,16,4,7,9,14) |
| 31 | (1,3,10,6,9,7,16,2,8)(4,5,14)(12,13) | 81 | (1,5,15,2,16,10,9,14,11,4,12,6,3) |
| 32 | (1,2,11,16,10,15)(3,14,6,5,9)(4,7,13,12) | 82 | (1,13,5,10,2,15,11,4,16,7,12,9,14,3,8,6) |
| 33 | (1,16,14,13,10,7,12,3,6,11,9,5)(2,4) | 83 | (1,14,8,9,15,3,5,2,7,10,4,12,6,11,16) |
| 34 | (1,6,14)(2,10,3,15,9,12,11,4,16,13,8,7) | 84 | (1,15,8,9,4,3,16,6,7,14,5,12,2,10,13,11) |
| 35 | (1,2)(3,15,16,13,12,4,5,6,7,9,10,11)(8,14) | 85 | (1,9,3,13)(4,11,15,12)(5,16,6,10,7,8,14) |
| 36 | (3,12,8,6,7,10,16,5,15,13)(4,9) | 86 | (1,9,15,8,13,14,6,11,7)(2,10,12,3,16,5,4) |
| 37 | (1,3,10,4,15,8,16,12,13,7,14,9,2) | 87 | (1,3,9,7,6,4,5)(10,12,14,16,11)(13,15) |
| 38 | (1,4,16)(2,9,5,13,10,14,3,11,8,7)(12,15) | 88 | (1,9,8,12,14,5,10,6,15,4,3)(2,11,16,13) |
| 39 | (1,4,5,2,11,10,12,9,14,15,3,16,13)(7,8) | 89 | (1,13,2,9,16)(3,14,11,8,7,15,6)(5,12,10) |
| 40 | (1,9,8,15,5,10,11,12,4,14,2,3,13,16,6,7) | 90 | (1,8,16,2,6,3,10,14,7,13,4,9,12,5,11) |
| 41 | (1,8,9,11,16,4)(2,13,14,15,7,12)(3,10,5) | 91 | (1,5,16,6,10,3,11,15,9,12,14,8,7,2,4) |
| 42 | (1,9,4,15,14,5)(2,11,12,3,6,10,13)(7,8,16) | 92 | (1,10,16,11,4,8,5,12,13,3,14,9)(2,7,15) |
| 43 | (2,8,14,9,7,16,12,10,13,6,15,3,11,4,5) | 93 | (1,4,2,13,6,9,14,3,10,8,16,11,15,7) |
| 44 | (1,11,12,14,2,13,8,9,3,10,6)(5,15,16) | 94 | (1,16,15,3,9,2,6,7,11,4)(5,8,14,12)(10,13) |
| 45 | (1,3,16,4)(2,5,6,15,7,11)(8,9,10)(13,14) | 95 | (3,10,13,15,12,9,14,16,7,5,4,6,8,11) |
| 46 | (1,6,12,10,8,15,5)(2,4,16,3,13)(7,14,9,11) | 96 | (1,6,15,4,5,3,16,13,9,10,12,2,8,7) |
| 47 | (1,7,14,3,4,16,8,13)(2,9)(5,12,6,11)(10,15) | 97 | (1,14,2,7,3,13,8,16,5,11,15,4,6,10,9,12) |
| 48 | (1,8,14,6,11,13,3,10,12,16,2,15,5,7,4) | 98 | (1,13,3,16)(2,11,6,14,5)(4,9,10,7,12,8,15) |
| 49 | (1,8,12,10,11,6,9,15)(3,13,4,7)(5,16,14) | 99 | (1,6,13,5,12,15,2)(3,14,8)(7,11)(9,16,10) |
| 50 | (1,5,16,2,11,4,13,15,12,3,8,7,14,6) | 100 | (1,12,11,8,2,3)(4,14,16,7,10,6)(5,13,15) |
Table A4.
The duration, in s, of each of the main steps of Algorithm 1 for each CNN.
Table A4.
The duration, in s, of each of the main steps of Algorithm 1 for each CNN.
| Per Permutation | |||||
|---|---|---|---|---|---|
| Steps: 8–12 | Shuffling | Predicting | Shuff% | Pred% | |
| Step: 8 | Steps: 9–10 | ||||
| 0.0955 | 0.0014 | 0.0941 | 1.483 | 98.511 | |
| 0.1176 | 0.0014 | 0.1162 | 1.228 | 98.767 | |
| 0.0578 | 0.0016 | 0.0563 | 2.727 | 97.264 | |
| 0.0933 | 0.0016 | 0.0917 | 1.664 | 98.330 | |
| 0.1262 | 0.0016 | 0.1246 | 1.233 | 98.763 | |
| 0.0660 | 0.0016 | 0.0644 | 2.449 | 97.542 | |
| 0.0844 | 0.0017 | 0.0828 | 1.975 | 98.018 | |
| 0.1017 | 0.0017 | 0.1000 | 1.678 | 98.316 | |
| 0.0213 | 0.0015 | 0.0198 | 6.930 | 93.047 | |
| 0.0196 | 0.0015 | 0.0182 | 7.563 | 92.411 | |
| AVG | 0.0784 | 0.0015 | 0.077 | 1.978 | 98.015 |
Appendix C

Figure A2.
Shuffling test results of 100 clean (ancestor) images on for over 100 permutations.
Figure A2.
Shuffling test results of 100 clean (ancestor) images on for over 100 permutations.


Figure A3.
ShuffleDetect results for adversarial images generated by the EA-targeted attack on for over 100 permutations.
Figure A3.
ShuffleDetect results for adversarial images generated by the EA-targeted attack on for over 100 permutations.


Figure A4.
ShuffleDetect results for adversarial images generated by the BIM-targeted attack on for over 100 permutations.
Figure A4.
ShuffleDetect results for adversarial images generated by the BIM-targeted attack on for over 100 permutations.


Figure A5.
ShuffleDetect results for adversarial images generated by the PGD Inf-targeted attack on for over 100 permutations.
Figure A5.
ShuffleDetect results for adversarial images generated by the PGD Inf-targeted attack on for over 100 permutations.


Figure A6.
ShuffleDetect results for adversarial images generated by the PGD L2-targeted attack on for over 100 permutations.
Figure A6.
ShuffleDetect results for adversarial images generated by the PGD L2-targeted attack on for over 100 permutations.


Figure A7.
ShuffleDetect results for adversarial images generated by the EA-untargeted attack on for over 100 permutations.
Figure A7.
ShuffleDetect results for adversarial images generated by the EA-untargeted attack on for over 100 permutations.


Figure A8.
ShuffleDetect results for adversarial images generated by the FGSM-untargeted attack on for over 100 permutations.
Figure A8.
ShuffleDetect results for adversarial images generated by the FGSM-untargeted attack on for over 100 permutations.


Figure A9.
ShuffleDetect results for adversarial images generated by the BIM-untargeted attack on for over 100 permutations.
Figure A9.
ShuffleDetect results for adversarial images generated by the BIM-untargeted attack on for over 100 permutations.


Figure A10.
ShuffleDetect results for adversarial images generated by the PGD Inf-untargeted attack on for over 100 permutations.
Figure A10.
ShuffleDetect results for adversarial images generated by the PGD Inf-untargeted attack on for over 100 permutations.


Figure A11.
ShuffleDetect results for adversarial images generated by the PGD L2-untargeted attack on for over 100 permutations.
Figure A11.
ShuffleDetect results for adversarial images generated by the PGD L2-untargeted attack on for over 100 permutations.


Figure A12.
ShuffleDetect results for adversarial images generated by the CW Inf-untargeted attack on for over 100 permutations.
Figure A12.
ShuffleDetect results for adversarial images generated by the CW Inf-untargeted attack on for over 100 permutations.


Figure A13.
ShuffleDetect results for adversarial images generated by the Deep Fool-untargeted attack on for over 100 permutations.
Figure A13.
ShuffleDetect results for adversarial images generated by the Deep Fool-untargeted attack on for over 100 permutations.

References
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Chakraborty, A.; Alam, M.; Dey, V.; Chattopadhyay, A.; Mukhopadhyay, D. Adversarial Attacks and Defences: A Survey. arXiv 2018, arXiv:1810.00069. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 99–112. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2015, arXiv:1810.00069. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), IEEE, San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Wiyatno, R.; Xu, A. Maximal Jacobian-based Saliency Map Attack. arXiv 2018, arXiv:1808.07945. [Google Scholar]
- Tramèr, F.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. The Space of Transferable Adversarial Examples. arXiv 2017, arXiv:1704.03453. [Google Scholar]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into Transferable Adversarial Examples and Black-box Attacks. arXiv 2016, arXiv:1611.02770. [Google Scholar]
- Ilyas, A.; Engstrom, L.; Athalye, A.; Lin, J. Black-box adversarial attacks with limited queries and information. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 2137–2146. [Google Scholar]
- Narodytska, N.; Kasiviswanathan, S.P. Simple Black-Box Adversarial Perturbations for Deep Networks. arXiv 2016, arXiv:1612.06299. [Google Scholar]
- Feinman, R.; Curtin, R.R.; Shintre, S.; Gardner, A.B. Detecting adversarial samples from artifacts. arXiv 2017, arXiv:1703.00410. [Google Scholar]
- Grosse, K.; Manoharan, P.; Papernot, N.; Backes, M.; McDaniel, P. On the (statistical) detection of adversarial examples. arXiv 2017, arXiv:1702.06280. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- Liang, B.; Li, H.; Su, M.; Li, X.; Shi, W.; Wang, X. Detecting adversarial image examples in deep neural networks with adaptive noise reduction. IEEE Trans. Dependable Secure Comput. 2018, 18, 72–85. [Google Scholar] [CrossRef]
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- Oliphant, T.E. A Guide to NumPy; Trelgol Publishing: Austin, TX, USA, 2006. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Varrette, S.; Bouvry, P.; Cartiaux, H.; Georgatos, F. Management of an Academic HPC Cluster: The UL Experience. In Proceedings of the 2014 International Conference on High Performance Computing & Simulation (HPCS 2014), IEEE, Bologna, Italy, 21–25 July 2014; pp. 959–967. [Google Scholar]
- Topal, A.O.; Chitic, R.; Leprévost, F. One evolutionary algorithm deceives humans and ten convolutional neural networks trained on ImageNet at image recognition. ASC, 2022; under review. [Google Scholar]
- Aldahdooh, A.; Hamidouche, W.; Fezza, S.A.; Déforges, O. Adversarial example detection for DNN models: A review and experimental comparison. Artif. Intell. Rev. 2022, 55, 4403–4462. [Google Scholar] [CrossRef]
- Ma, X.; Li, B.; Wang, Y.; Erfani, S.M.; Wijewickrema, S.N.R.; Houle, M.E.; Schoenebeck, G.; Song, D.; Bailey, J. Characterizing Adversarial Subspaces Using Local Intrinsic Dimensionality. arXiv 2018, arXiv:1801.02613. [Google Scholar]
- Ma, S.; Liu, Y. Nic: Detecting adversarial samples with neural network invariant checking. In Proceedings of the 26th Network and Distributed System Security Symposium (NDSS 2019), San Diego, CA, USA, 24–27 February 2019. [Google Scholar]
- Chitic, R.; Topal, A.O.; Leprévost, F. Empirical Perturbation Analysis of Two Adversarial Attacks: Black Box versus White Box. Appl. Sci. 2022, 12, 7339. [Google Scholar] [CrossRef]
- Leprévost, F. How Big is Big? How Fast is Fast? A Hands—On Tutorial on Mathematics of Computation; Amazon: New York, NY, USA, 2020. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. The ImageNet Image Database. 2009. Available online: http://image-net.org (accessed on 20 September 2022).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Le, Q.V. MnasNet: Platform-Aware Neural Architecture Search for Mobile. arXiv 2018, arXiv:1807.11626. [Google Scholar]
- Agrafiotis, D. Chapter 9—Video Error Concealment. In Academic Press Library in Signal Processing; Theodoridis, S., Chellappa, R., Eds.; Elsevier: Amsterdam, The Netherlands, 2014; Volume 5, pp. 295–321. [Google Scholar] [CrossRef]
- Nicolae, M.; Sinn, M.; Minh, T.N.; Rawat, A.; Wistuba, M.; Zantedeschi, V.; Molloy, I.M.; Edwards, B. Adversarial Robustness Toolbox v1.0.0. arXiv 2018, arXiv:1807.01069. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2019, arXiv:1706.06083. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2574–2582. [Google Scholar]
- Meng, D.; Chen, H. Magnet: A two-pronged defense against adversarial examples. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 135–147. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).