
Named Entity Recognition Networks Based on Syntactically Constrained Attention


Abstract
:1. Introduction
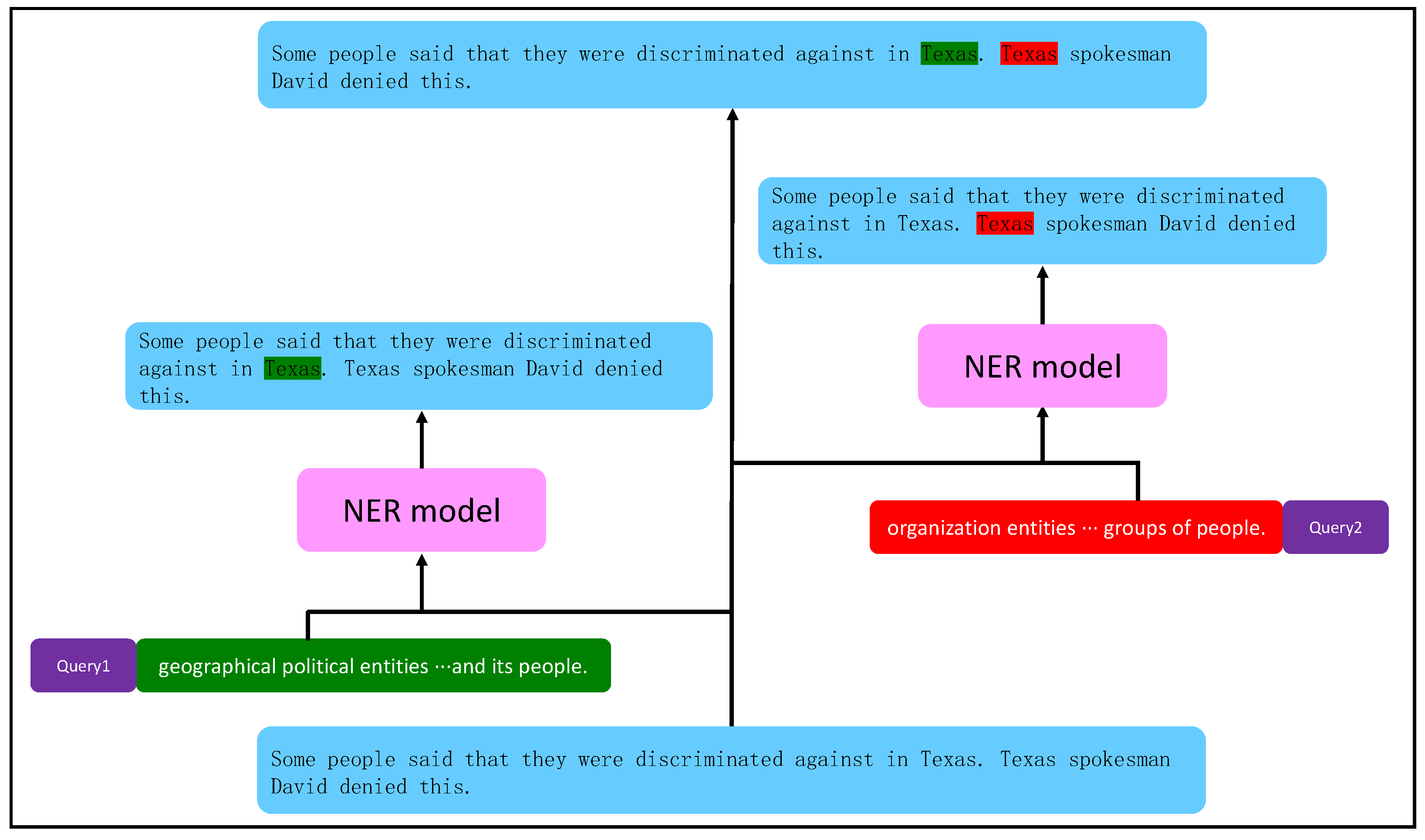
- For NER tasks, we propose a new Syntactic Constrained Dual Context Aggregation Network (SCAN-Net) model. SCAN-Net is the first model that uses a syntactic dependency tree to apply the dependency of a single word in a sentence, as a constraint, to the NER task.
- To make relatively better use of syntactic information for the model to understand the text, we propose two syntactic constraint strategies.
- Numerous experiments have been conducted on the ACE2004, ACE2005, and GENIA datasets, and the results have demonstrated the effectiveness of SCAN-Net model.
2. Related Work
2.1. Named Entity Recognition Task
2.2. NLP Tasks Based on the MRC Approach
2.3. Application of Syntactic Information to NLP Tasks
3. Methodology
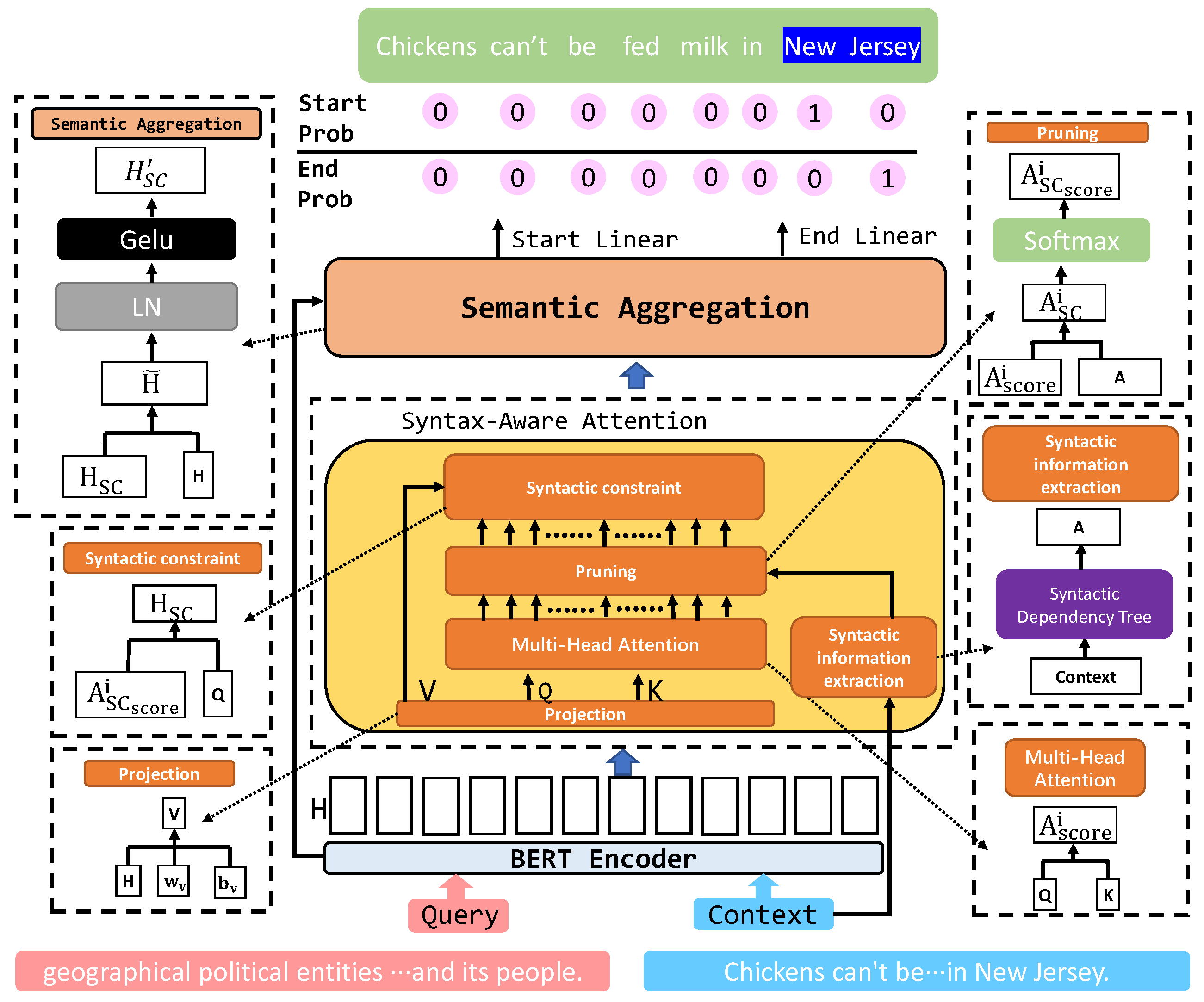
3.1. Overview
3.2. Formalization of Tasks
3.3. Coding Layer
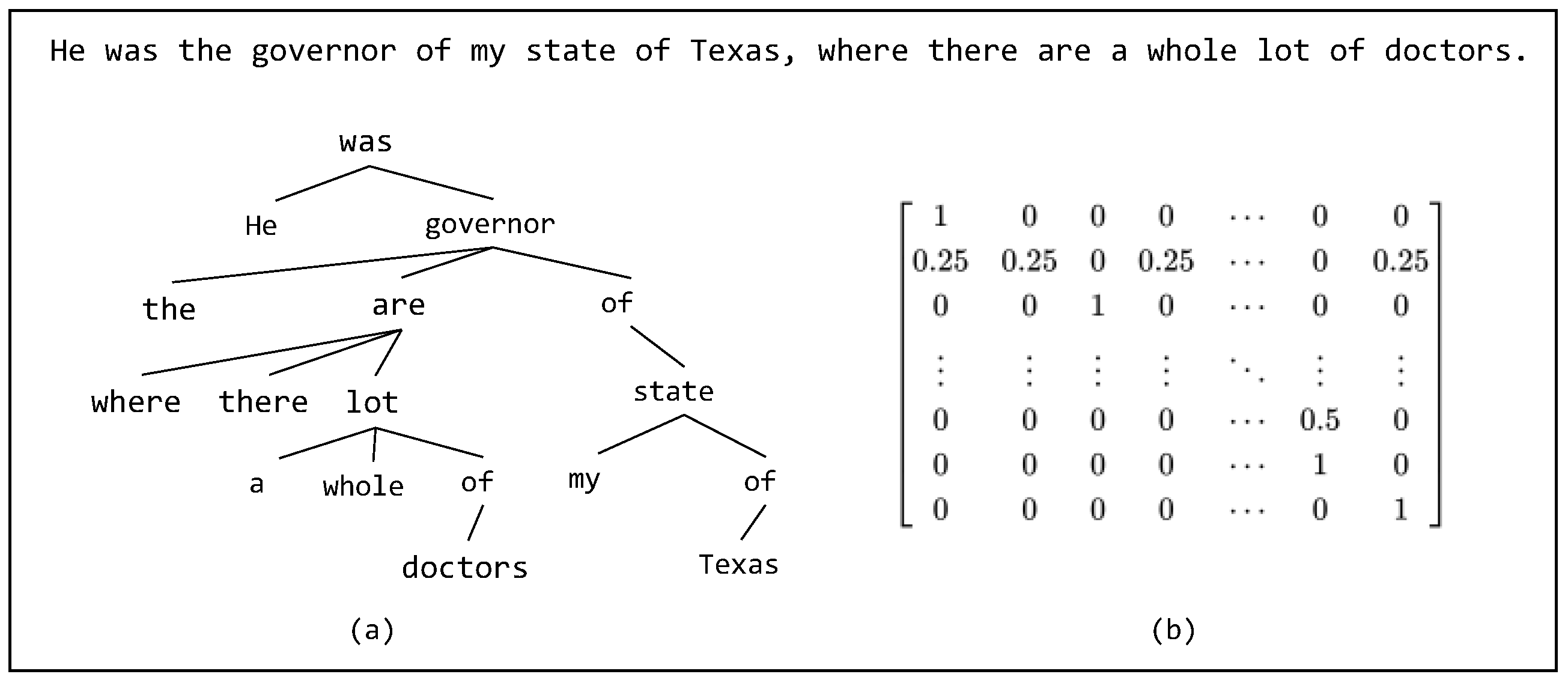
3.4. Syntactically Constrained Attention Networks
3.5. Semantic Aggregation Layer
3.6. Decoding Layer
3.7. Loss Functions
4. Materials and Methods
4.1. Datasets
4.2. Experimental Setups
4.3. Results
4.4. Analysis and Discussion
4.4.1. Analysis of the Validity of Syntactic Information
4.4.2. The Impact of Semantic Dependencies on NER
4.5. Case Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, X.; Feng, J.; Meng, Y.; Han, Q.; Wu, F.; Li, J. A unified mrc framework for named entity recognition. arXiv 2019, arXiv:1910.11476. [Google Scholar]
- Zhang, Z.; Wu, Y.; Zhou, J.; Duan, S.; Zhao, H.; Wang, R. Sg-net: Syntax-guided machine reading comprehension. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9636–9643. [Google Scholar]
- Liu, L.; Shang, J.; Xu, F.; Xiang, R.; Han, J. Empower sequence labeling with task-aware neural language model. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Lin, Y.; Liu, L.; Ji, H.; Yu, D.; Han, J. Reliability-aware dynamic feature composition for name tagging. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 165–174. [Google Scholar]
- Cao, Y.; Hu, Z.; Chua, T.-S.; Liu, Z.; Ji, H. Low-resource name tagging learned with weakly labeled data. arXiv 2019, arXiv:1908.09659. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML 2001), Williamstown, MA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Finkel, J.R.; Grenager, T.; Manning, C. Incorporating non-local information into information extraction systems by gibbs sampling. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Ann Arbor, MI, USA, 25–30 June 2005; pp. 363–370. [Google Scholar]
- Liu, X.; Zhang, S.; Wei, F.; Zhou, M. Recognizing named entities in tweets. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 359–367. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 2227–2237. [Google Scholar]
- Alan, A.; Duncan, B.; Roland, V. Contextual string embeddings for sequence labeling. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 21–25 August 2018. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Finkel, J.R.; Manning, C.D. Nested named entity recognition. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009. [Google Scholar]
- Lu, W.; Dan, R. Joint mention extraction and classification with mention hypergraphs. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Muis, A.O.; Lu, W. Labeling gaps between words: Recognizing overlapping mentions with mention separators. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017. [Google Scholar]
- Katiyar, A.; Cardie, C. Nested named entity recognition revisited. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1. [Google Scholar]
- Wang, B.; Wei, L. Neural segmental hypergraphs for overlapping mention recognition. arXiv 2018, arXiv:1810.01817. [Google Scholar]
- Luan, Y.; Wadden, D.; He, L.; Shah, A.; Osten-dorf, M.; Hajishirzi, H. A general framework for information extraction using dynamic span graphs. arXiv 2019, arXiv:1904.03296. [Google Scholar]
- Yu, J.; Bohnet, B.; Poesio, M. Named entity recognition as dependency parsing. arXiv 2020, arXiv:2005.07150. [Google Scholar]
- Hou, F.; Wang, R.; He, J.; Zhou, Y. Improving entity linking through semantic reinforced entity embed-dings. arXiv 2021, arXiv:2106.08495. [Google Scholar]
- Yan, H.; Gui, T.; Dai, J.; Guo, Q.; Zhang, Z.; Qiu, X. A unified generative framework for various ner subtasks. arXiv 2021, arXiv:2106.01223. [Google Scholar]
- Mike, L.; Yinhan, L.; Naman, G.; Marjan, G.; Abdelrahman, M.; Omer, L.; Ves, S.; Luke, Z. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Li, F.; Lin, Z.; Zhang, M.; Ji, D. A Span-Based Model for Joint Overlapped and Discontinuous Named Entity Recognition. arXiv 2021, arXiv:2106.14373. [Google Scholar]
- Yang, S.; Tu, K. Bottom-up constituency parsing and nested named entity recognition with pointer networks. arXiv 2021, arXiv:2110.05419. [Google Scholar]
- Li, X.; Yin, F.; Sun, Z.; Li, X.; Yuan, A.; Chai, D.; Zhou, M. Entity-relation extraction as multiturn question answering. arXiv 2019, arXiv:1905.05529. [Google Scholar]
- Zhao, T.; Yan, Z.; Cao, Y.; Li, Z. Asking effective and diverse questions: A machine reading comprehension based framework for joint entity-relation extraction. In Proceedings of the Twenty-Ninth International Conference on Inter-national Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 3948–3954. [Google Scholar]
- Yang, P.; Cong, X.; Sun, Z.; Liu, X. Enhanced language representation with label knowledge for span extraction. arXiv 2021, arXiv:2111.00884. [Google Scholar]
- Huang, B.; Carley, K.M. Syntax-aware aspect level sentiment classification with graph attention networks. arXiv 2019, arXiv:1909.02606. [Google Scholar]
- Zhang, C.; Li, Q.; Song, D. Aspect-based sentiment classification with aspect-specific graph convolutional networks. arXiv 2019, arXiv:1909.03477. [Google Scholar]
- Hou, X.; Huang, J.; Wang, G.; Qi, P.; Zhou, B. Selective attention based graph convolutional networks for aspect-level sentiment classification. arXiv 2021, arXiv:1910.10857. [Google Scholar]
- Li, R.; Chen, H.; Feng, F.; Ma, Z.; Hovy, E. Dual graph convolutional networks for aspect-based sentiment analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021; Volume 1. [Google Scholar]
- Fu, T.J.; Li, P.H.; Ma, W.Y. Graphrel: Modeling text as relational graphs for joint entity and re-lation extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Tian, Y.; Chen, G.; Song, Y.; Wan, X. Dependency-driven relation extraction with attentive graph convolu-tional networks. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021; Volume 1. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Lin, H.; Lu, Y.; Han, X.; Sun, L. Sequence-to-nuggets: Nested entity mention detection via anchor-region networks. arXiv 2019, arXiv:1906.03783. [Google Scholar]
- Straková, J.; Straka, M.; Hajič, J. Neural architectures for nested ner through linearization. arXiv 2019, arXiv:1908.06926. [Google Scholar]
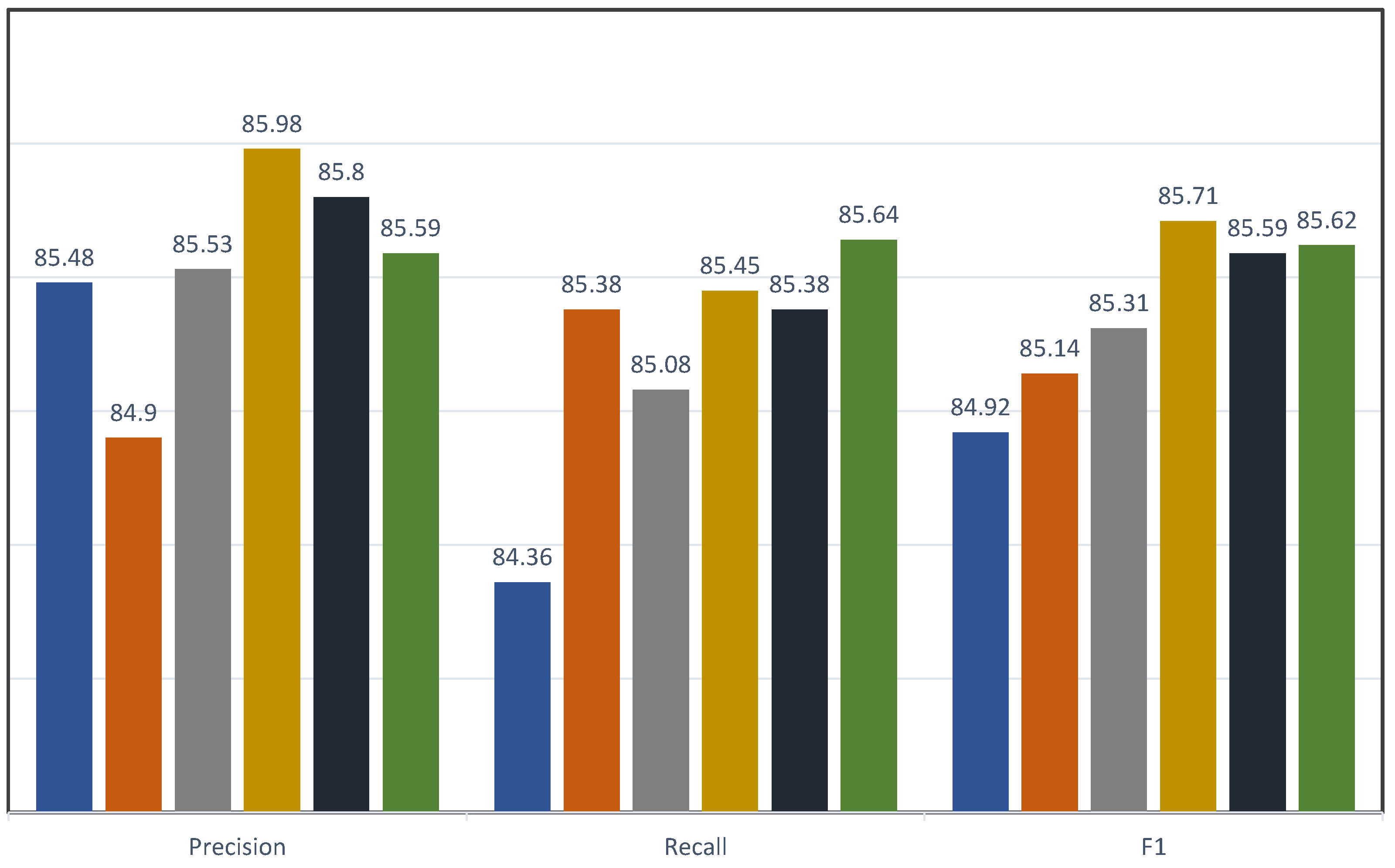


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity Type | Query | |
|---|---|---|
| ACE2005 | GPE | geographical political entities are geographical regions defined by political and or social groups, such as countries, nations, regions, cities, states, and the government and its people. |
| LOC | location entities are limited to geographical entities, such as geographical areas and landmasses, mountains, bodies of water, and geological formations. | |
| PER | a person entity is limited to humans, including a single individual or a group. | |
| GENIA | cell_line | find all cell line entities in the context. |
| DNA | find all DNA entities in the context | |
| protein | find all protein entities in the context. |
| Sentences | |||
|---|---|---|---|
| # Train | # Dev | # Test | |
| ACE2004 | 6200 | 745 | 812 |
| ACE2005 | 7294 | 971 | 1057 |
| GENIA | 18,546 | 15,023 | 1669 |
| Hyper-Parameter | Value |
|---|---|
| Weight Initialization | BERT |
| Batch-size | 16 |
| Learning rete | 2.00 × 10 |
| Warmup Proportion | 0.1 |
| Optimizer | AdamW |
| epoch | 20 |
| Dropout rate | 0.2–0.4 |
| Max Sequence Length | 300 |
| ACE2004 | |||
|---|---|---|---|
| Model | P | R | F1 |
| Straková et al. [35] | - | - | 84.4 |
| Luan et al. [17] | - | - | 84.7 |
| Yu et al. [18] * | 85.42 | 85.92 | 85.67 |
| Li et al. [1] * | 86.38 | 85.07 | 85.72 |
| SCAN-Net (ours) | 86.91 | 85.11 | 86.0 |
| ACE2005 | |||
| Model | P | R | F1 |
| Straková et al. [35] | - | - | 84.33 |
| Li et al. [1] * | 85.48 | 84.36 | 84.92 |
| Yu et al. [18] * | 84.5 | 84.72 | 84.61 |
| Hou et al. [19] | 83.95 | 85.39 | 84.66 |
| Yan et al. [20] | 83.16 | 86.38 | 84.74 |
| Li et al. [22] | - | - | 84.30 |
| Yang et al. [23] | 84.61 | 86.43 | 85.53 |
| SCAN-Net (ours) | 85.98 | 85.45 | 85.71 |
| GENIA | |||
| Model | P | R | F1 |
| Straková et al. [35] | - | - | 76.44 |
| Li et al. [1] * | 79.62 | 76.8 | 78.19 |
| Yu et al. [18] * | 79.43 | 78.32 | 78.87 |
| Hou et al. [19] | 79.45 | 78.94 | 79.19 |
| Yan et al. [20] | 78.87 | 79.6 | 79.23 |
| Li et al. [22] | - | - | 78.30 |
| Yang et al. [23] | 78.08 | 78.26 | 78.16 |
| SCAN-Net (ours) | 79.95 | 79.52 | 79.73 |
| Model | P | R | F1 |
|---|---|---|---|
| Baseline | 85.48 | 84.36 | 84.92 |
| +Attention | 84.97 | 85.08 | 85.03 |
| +Syntax Attention † | 84.91 | 85.78 | 85.34 |
| +Syntax Attention ‡ | 85.98 | 85.45 | 85.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, W.; Liu, S.; Liu, Y.; Kong, L.; Jian, Z. Named Entity Recognition Networks Based on Syntactically Constrained Attention. Appl. Sci. 2023, 13, 3993. https://doi.org/10.3390/app13063993
Sun W, Liu S, Liu Y, Kong L, Jian Z. Named Entity Recognition Networks Based on Syntactically Constrained Attention. Applied Sciences. 2023; 13(6):3993. https://doi.org/10.3390/app13063993
Chicago/Turabian StyleSun, Weiwei, Shengquan Liu, Yan Liu, Lingqi Kong, and Zhaorui Jian. 2023. "Named Entity Recognition Networks Based on Syntactically Constrained Attention" Applied Sciences 13, no. 6: 3993. https://doi.org/10.3390/app13063993
APA StyleSun, W., Liu, S., Liu, Y., Kong, L., & Jian, Z. (2023). Named Entity Recognition Networks Based on Syntactically Constrained Attention. Applied Sciences, 13(6), 3993. https://doi.org/10.3390/app13063993