
Open-Set Specific Emitter Identification Based on Prototypical Networks and Extreme Value Theory


Abstract
1. Introduction
- A one-dimensional CNN integrating an attention mechanism was designed. Meanwhile, group convolution and channel shuffle were introduced into the network, which reduced the complexity and overfitting and effectively improved the recognition performance.
- Prototype learning was combined with the one-dimensional CNN. Distance-based cross-entropy loss and prototype loss were used to train the network to complete the separation of inter-class signals and the aggregation of intra-class signals in the feature space.
- Combining EVT, Weibull models were fitted for each known class based on the distance from the sample features to the mean features. The open-set recognition was completed based on the Weibull models and the distance between the features of the test samples and the mean features of known classes.
2. Prototypical Networks and Extreme Value Theory
2.1. Prototypical Networks
2.2. Extreme Value Theory
3. Recognition Model
3.1. Model Framework
3.2. Network Structure
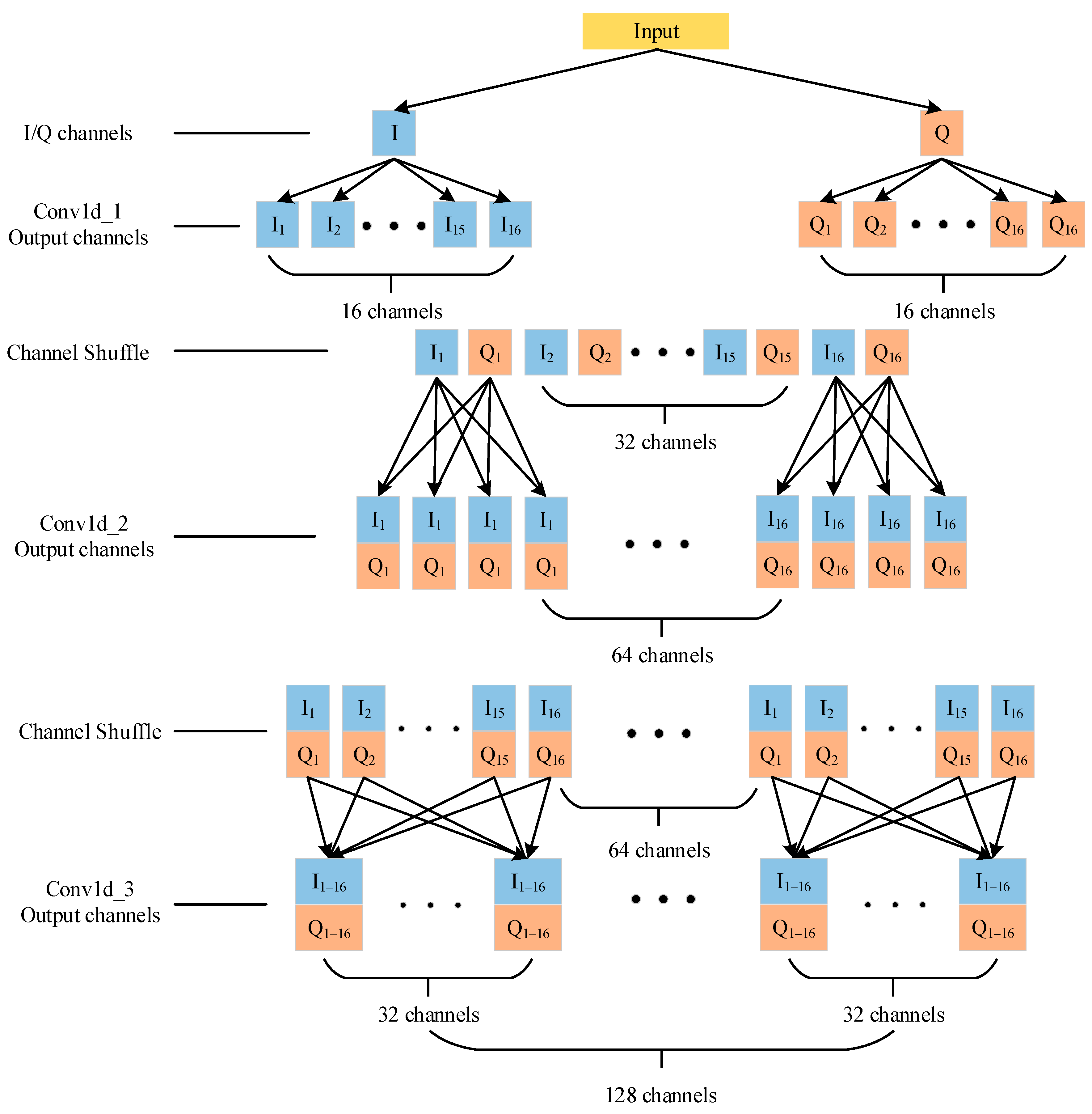
3.2.1. Group Convolution and Channel Shuffle
3.2.2. Attention Mechanism
3.3. Loss Functions
3.3.1. Distance-Based Cross-Entropy Loss (DCEL)
3.3.2. Prototype Loss (PL)
3.3.3. Joint Loss
3.4. Classification Algorithm
3.4.1. Training the Network and Fitting the Weibull Model
| Algorithm 1 Training the network and fitting the Weibull model |
|
|
|
|
|
|
| Compute mean features |
| Fit Weibull model |
| end for |
| Return mean features and Weibull model |
3.4.2. Testing and Recognition
| Algorithm 2 Testing and Recognition |
|
|
|
|
| for do |
| end for |
|
|
|
|
4. Experimental Results Analysis
4.1. Experimental Platform and Data Preprocessing
4.2. Comparison of Recognition Performance under Different Parameters
4.2.1. Comparison of Recognition Accuracy under Different Loss Functions
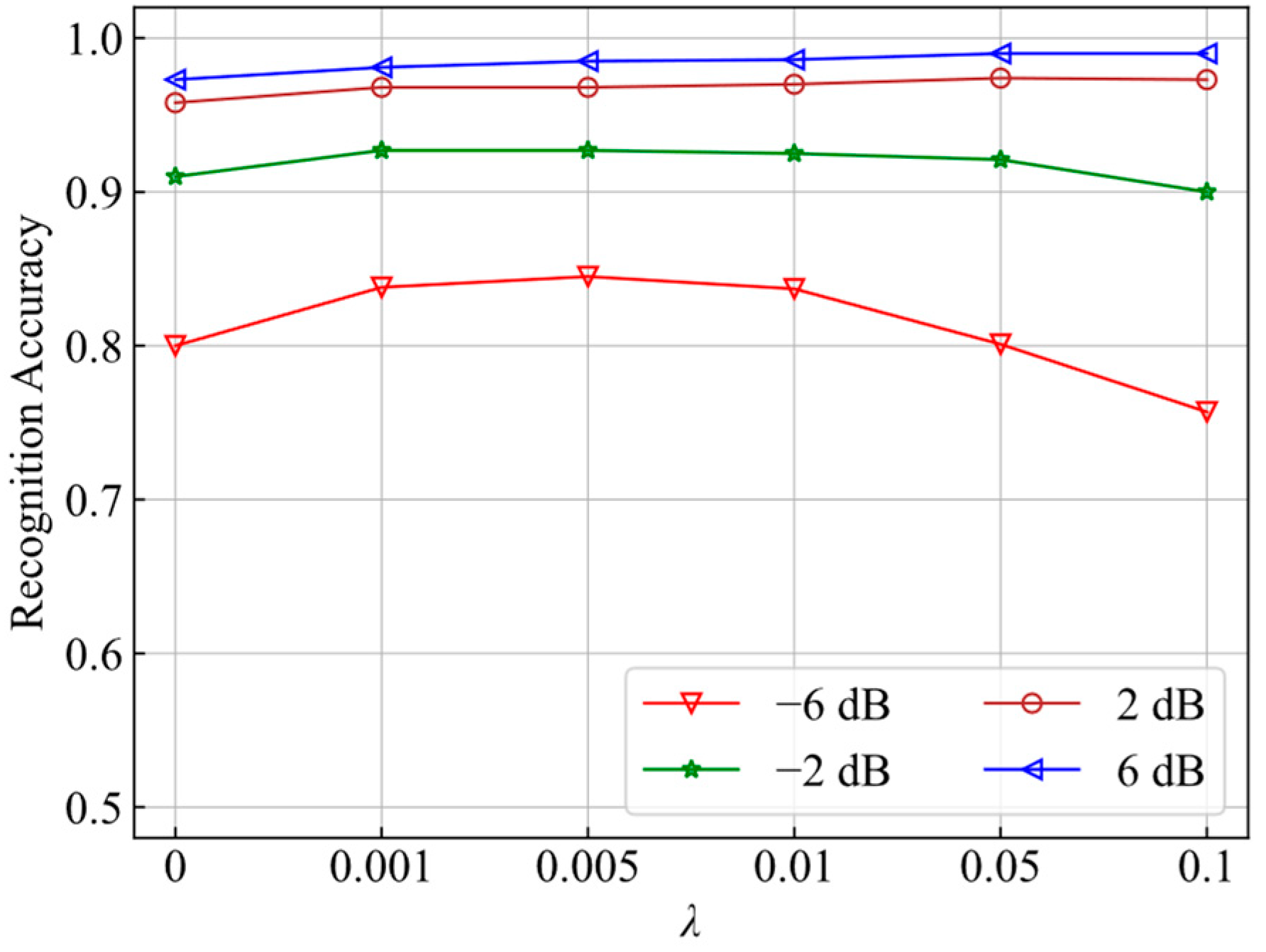
4.2.2. Comparison of Recognition Accuracy for Different r Values
4.2.3. Comparison of Recognition Accuracy with Different Feature Dimensions
4.3. Comparison of Recognition Performance of Different Models
4.3.1. Comparison of Recognition Accuracy
4.3.2. Comparison of Robustness
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Talbot, K.I.; Duley, P.R.; Hyatt, M.H. Specific emitter identification and verification. Technol. Rev. 2003, 113, 113–130. [Google Scholar]
- Nouichi, D.; Abdelsalam, M.; Nasir, Q.; Abbas, S. IoT Devices security using RF fingerprinting. In Proceedings of the 2019 Advances in Science and Engineering Technology International Conferences (ASET), Dubai, United Arab Emirates, 26 March–10 April 2019; pp. 1–7. [Google Scholar]
- Bihl, T.J.; Bauer, K.W.; Temple, M.A. Feature selection for RF fingerprinting with multiple discriminant analysis and using ZigBee device emissions. IEEE Trans. Inf. Secur. 2016, 11, 1862–1874. [Google Scholar] [CrossRef]
- Patel, H.J.; Temple, M.A.; Baldwin, R.O. Improving ZigBee device network authentication using ensemble decision tree classifiers with radio frequency distinct native attribute fingerprinting. IEEE Trans. Rel. 2015, 64, 221–233. [Google Scholar] [CrossRef]
- Ramsey, B.W.; Temple, M.A.; Mullins, B.E. PHY foundation for multi-factor ZigBee node authentication. In Proceedings of the 2012 IEEE Global Communications Conference (GLOBECOM), Anaheim, CA, USA, 3–7 December 2012; pp. 795–800. [Google Scholar]
- Danev, B.; Capkun, S. Transient-based identification of wireless sensor nodes. In Proceedings of the 2009 International Conference on Information Processing in Sensor Networks, San Francisco, CA, USA, 13–16 April 2009; pp. 25–36. [Google Scholar]
- Mohamed, I.; Dalveren, Y.; Catak, F.O.; Kara, A. On the Performance of Energy Criterion Method in Wi-Fi Transient Signal Detection. Electronics 2022, 11, 269. [Google Scholar] [CrossRef]
- Yang, Y.S.; Guo, Y.; Li, H.G.; Sui, P. Fingerprint feature recognition of frequency hopping based on high order cumulant estimation. In Proceedings of the 2018 IEEE 3rd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 October 2018; pp. 2175–2179. [Google Scholar]
- Xu, S.H.; Huang, B.X.; Xu, L.N.; Xu, Z.G. Radio transmitter classification using a new method of stray features analysis combined with PCA. In Proceedings of the MILCOM 2007-IEEE Military Communications Conference, Orlando, FL, USA, 29–31 October 2007; pp. 1–5. [Google Scholar]
- Udit, S.; Nikita, T.; Gagarin, B. Specific emitter identification based on variational mode decomposition and spectral features in single hop and relaying scenarios. IEEE Trans. Inf. Secur. 2018, 14, 581–591. [Google Scholar]
- Lecun, Y.; Bottou, L. Gradient-Based Learning Applied to Document Recognition; IEEE: New York, NY, USA, 1998; Volume 86, pp. 2278–2324. [Google Scholar]
- Pan, Y.W.; Yang, S.H.; Peng, H.; Li, T.Y.; Wang, W.Y. Specific emitter identification based on deep residual networks. IEEE Access 2019, 7, 54425–54434. [Google Scholar] [CrossRef]
- Peng, L.N.; Zhang, J.Q.; Liu, M.; Hu, A.Q. Deep learning based RF fingerprint identification using Differential Constellation Trace Figure. IEEE Trans. Veh. Technol. 2019, 69, 1091–1095. [Google Scholar] [CrossRef]
- Ding, L.D.; Wang, S.L.; Wang, F.G.; Zhang, W. Specific emitter identification via convolutional neural networks. IEEE Commun. Lett. 2018, 22, 2591–2594. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, X.; Lei, Y. Emitter Identification of Digital Modulation Transmitter Based on Nonlinearity and Modulation Distortion of Power Amplifier. Sensors 2021, 21, 4362. [Google Scholar] [CrossRef]
- Merchant, K.; Revay, S.; Stantchev, G.; Nousain, B. Deep learning for RF device fingerprinting in cognitive communication networks. IEEE J. Sel. Top. Signal Process. 2018, 12, 160–167. [Google Scholar] [CrossRef]
- Sankhe, K.; Belgiovine, M.; Zhou, F.; Angioloni, L.; Restuccia, F.; D’Oro, S.; Melodia, T.; Ioannidis, S.; Chowdhury, K. No Radio Left Behind: Radio fingerprinting through deep learning of Physical-Layer hardware impairments. IEEE Trans. Cogn. Commun. Netw. 2019, 6, 165–178. [Google Scholar] [CrossRef]
- Qing, G.W.; Wang, H.F.; Zhang, T.P. Radio frequency fingerprinting identification for Zigbee via lightweight CNN. Phys. Commun. 2021, 44, 101250. [Google Scholar] [CrossRef]
- Liu, Y.H.; Xu, H.; Qi, Z.S.; Shi, Y.H. Specific emitter identification against unreliable features interference based on Time-Series classification network structure. IEEE Access 2020, 8, 200194–200208. [Google Scholar] [CrossRef]
- Wang, Y.; Gui, G.; Gacanin, H.; Ohtsuki, T.; Dobre, O.A.; Poor, H.V. An efficient specific emitter identification method based on Complex-Valued neural networks and network compression. IEEE J. Sel. Areas Commun. 2021, 39, 2305–2317. [Google Scholar] [CrossRef]
- Xing, C.; Zhou, Y.; Peng, Y.; Hao, J.; Li, S. Specific Emitter Identification Based on Ensemble Neural Network and Signal Graph. Appl. Sci. 2022, 12, 5496. [Google Scholar] [CrossRef]
- Gutierrez del Arroyo, J.A.; Borghetti, B.J.; Temple, M.A. Considerations for Radio Frequency Fingerprinting across Multiple Frequency Channels. Sensors 2022, 22, 2111. [Google Scholar] [CrossRef] [PubMed]
- Tian, Q.; Lin, Y.; Guo, X.; Wang, J.; AlFarraj, O.; Tolba, A. An Identity Authentication Method of a MIoT Device Based on Radio Frequency (RF) Fingerprint Technology. Sensors 2020, 20, 1213. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Wen, H.; Wu, J.; Xu, A.; Jiang, Y.; Song, H.; Chen, Y. Radio Frequency Fingerprint-Based Intelligent Mobile Edge Computing for Internet of Things Authentication. Sensors 2019, 19, 3610. [Google Scholar] [CrossRef] [PubMed]
- Aneja, S.; Aneja, N.; Bhargava, B.; Chowdhury, R.R. Device fingerprinting using deep convolutional neural networks. Int. J. Comm. Netw. Distr. Syst. 2022, 28, 171–198. [Google Scholar] [CrossRef]
- Hanna, S.; Karunaratne, S.; Cabric, D. Open set wireless transmitter authorization: Deep learning approaches and dataset considerations. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 59–72. [Google Scholar] [CrossRef]
- Chen, W.; Wang, Y.H.; Song, J.; Li, Y. Open set HRRP recognition based on convolutional neural network. J. Eng. 2019, 2019, 7701–7704. [Google Scholar] [CrossRef]
- Bendale, A.; Boult, T. Towards open set deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1563–1572. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A Discriminative Feature Learning Approach for Deep Face Recognition. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 499–515. [Google Scholar]
- Draganov, A.; Brown, C.; Mattei, E.; Dalton, C.; Ranjit, J. Open set recognition through unsupervised and class-distance learning. In 2nd ACM Workshop on Wireless Security and Machine Learning; ACM: New York, NY, USA, 2020; pp. 7–12. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical networks for few-shot learning. arXiv 2017, arXiv:1703.05175. [Google Scholar]
- Yang, H.M.; Zhang, X.Y.; Yin, F.; Liu, C.L. Robust classification with convolutional prototype learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3474–3482. [Google Scholar]
- Yang, H.M.; Zhang, X.Y.; Yin, F.; Yang, Q.; Liu, C.L. Convolutional prototype network for open set recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2358–2370. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.L.; Nakagawa, M. Evaluation of prototype learning algorithms for nearest-neighbor classifier in application to handwritten character recognition. Pattern Recognit. 2001, 34, 601–615. [Google Scholar] [CrossRef]
- Fisher, R.A.; Tippett, L.H.C. Limiting forms of the frequency distribution of the largest or smallest member of a sample. In Mathematical Proceedings of the Cambridge Philosophical Society; Cambridge University Press: Cambridge, UK, 1928; Volume 24, pp. 180–190. [Google Scholar]
- Scheirer, W.J.; Rocha, A.R.; Micheals, R.J.; Boult, T.E. Meta-recognition: The theory and practice of recognition score analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1689–1695. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Albanie, S.; Wu, E.H. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Zhou, X.Y.; Lin, M.X.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | EVT_PN_Shuffle | OpenMax | CPN | Center_Loss |
|---|---|---|---|---|
| Recognition Accuracy | 90.3% | 85.8% | 78% | 81.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Wang, Y.; Zhang, Y.; Xu, H.; Zhang, Z. Open-Set Specific Emitter Identification Based on Prototypical Networks and Extreme Value Theory. Appl. Sci. 2023, 13, 3878. https://doi.org/10.3390/app13063878
Wang C, Wang Y, Zhang Y, Xu H, Zhang Z. Open-Set Specific Emitter Identification Based on Prototypical Networks and Extreme Value Theory. Applied Sciences. 2023; 13(6):3878. https://doi.org/10.3390/app13063878
Chicago/Turabian StyleWang, Chunsheng, Yongmin Wang, Yue Zhang, Hua Xu, and Zixuan Zhang. 2023. "Open-Set Specific Emitter Identification Based on Prototypical Networks and Extreme Value Theory" Applied Sciences 13, no. 6: 3878. https://doi.org/10.3390/app13063878
APA StyleWang, C., Wang, Y., Zhang, Y., Xu, H., & Zhang, Z. (2023). Open-Set Specific Emitter Identification Based on Prototypical Networks and Extreme Value Theory. Applied Sciences, 13(6), 3878. https://doi.org/10.3390/app13063878