Abstract
Heatmap-based traditional approaches for estimating human pose usually suffer from drawbacks such as high network complexity or suboptimal accuracy. Focusing on the issue of multi-person pose estimation without heatmaps, this paper proposes an end-to-end, lightweight human pose estimation network using a multi-scale coordinate attention mechanism based on the Yolo-Pose network to improve the overall network performance while ensuring the network is lightweight. Specifically, the lightweight network GhostNet was first integrated into the backbone to alleviate the problem of model redundancy and produce a significant number of effective feature maps. Then, by combining the coordinate attention mechanism, the sensitivity of our proposed network to direction and location perception was enhanced. Finally, the BiFPN module was fused to balance the feature information of different scales and further improve the expression ability of convolutional features. Experiments on the COCO 2017 dataset showed that, compared with the baseline method YOLO-Pose, the average accuracy of the proposed network on the COCO 2017 validation dataset was improved by 4.8% while minimizing the amount of network parameters and calculations. The experimental results demonstrated that our proposed method can improve the detection accuracy of human pose estimation while ensuring that the model is lightweight.
1. Introduction
Key point estimation tasks, which have evolved to be among the most difficult and intensively researched fundamental challenges in the area of computer vision, include tasks like human posture estimation as a typical class of sub-tasks. At the same time, as preprocessing work to understand the challenges of human behavior, human pose estimation is crucial in many different application sectors, including behavior recognition, human-computer interaction, autonomous driving, and video enhancement.
Due to the rapid advancement of deep convolution neural networks (CNN), numerous great enhanced algorithm frameworks in the field of two-dimensional multi-person pose estimation have appeared in recent years [1]. Gong et al. [2] carried out a comprehensive survey of human pose estimation in monocular images, including landmark work and recent progress. Gadhiya et al. [3] analyzed the Openpose, BlazePose, DeepPose, and Hourglass architectures and implemented OpenPose and BlazePose models to locate landmarks on the human push-up posture. Liu et al. [4] systematically summarized the differences and connections between several methods in recent years and further analyzed the solutions of some challenging cases. For example, Nie et al. [5] proposed a graded structured pose representation (SPR), which unifies the person instance and position information. Tang et al. [6] proposed a part-based branching network (PBN) for part of their model to learn the specific representation of each group instead of predicting all joint heatmaps for a branch. Then, the model divided the data-driven part groups by estimating the mutual information of the joints. A fast posture distillation training strategy was used by Zhang et al. [7] to train the complete teacher hourglass network using a lightweight variation of the hourglass network [8]. Huang et al. [9] introduced a regularization method for information loss by dropping the appearance information of key points with a certain probability during the training process in order to avoid only fitting the appearance information and ignoring the constraint information during the training process. By using transformer’s multi-head attention mechanism, Li et al. [10] minimized the location relationship of network learning and the correlation between several critical points, drastically lowering the number of parameters and model calculations [11]. However, most of the above methods cannot avoid heatmap operation and often require a variety of complex post-processing to improve network accuracy. Numerous helpful ideas have also emerged in a variety of fields for the further development of neural networks. The application of CNN for feature extraction and fusion at various scales for the interaction problem in automated driving was mentioned by Ma et al. [12]. Liang et al. [13] used an attention mechanism to improve the accuracy of the network in the identification of traffic signs. In this paper, we took the Yolo-Pose [14] framework as inspiration to study human pose estimation without heatmaps. Since the problems of multi-scale, occlusion, and illumination problems in object detection tasks are consistent with those in human pose estimation tasks, a good framework to solve the above problems in object detection tasks should also be able to handle similar issues in the field of pose estimation. Therefore, based on the above research, we present an end-to-end, lightweight human pose estimation network based on multi-scale coordinate attention based on Yolo-Pose. The contributions of this paper are as follows:
- (1)
- First, the ghost bottleneck module in the lightweight network GhostNet built for tiny CNN networks was used to replace the common convolution layer in the original model in order to output more flexible and effective feature map information with fewer computing resources.
- (2)
- Second, to locate and identify the location of the human body more accurately, a coordinate attention mechanism (CA) module was integrated at the end of the backbone network. This module can obtain cross-channel, direction-aware and location-sensitive feature information, which enhances the robustness of the network in densely occluded scene tasks.
- (3)
- Finally, since the resolutions of the various input features vary and their contributions to the output features are not all equal, we attempt to add the bi-directional feature pyramid network (BiFPN) module to the feature fusing branch. For learning the significance of different input features, this module includes learnable weights that can repeatedly execute top-down and bottom-up multi-scale feature fusion.
The first section of this paper gives an overview of the overall network structure, then we introduce the lightweight network GhostNet, coordinate attention mechanism, and bidirectional feature pyramid network. The details of our method’s experimental findings using the COCO datasets are discussed in Section 2. The conclusion of the experiment proves the validity and efficacy of our suggested approach. Section 3 summarizes our work in this paper, analyzes the next improvement points, and provides prospects for future work.
2. Related Work
Existing deep learning-based, two-dimensional, multi-person pose estimation methods can be divided into two types: two-stage and one-stage methods. In the two-stage approach, based on the starting point of the prediction, there are two types of strategies: top-down and bottom-up strategies.
Top-down approaches require first locating the human body and then estimating the individual pose within the corresponding bounding box area. G-RMI was proposed by Papandreou et al. [15], who used a unique form of confidence estimation based on key points in place of scoring based on a target box and a new non-maximum suppression (NMS) based on key points in place of the coarser NMS based on the human body. To lessen network redundancy, Fang et al. [16] used the symmetric spatial transformer network (SSTN) and parametric pose non-maximum suppression (PNMS). The CPN method was proposed by Chen et al. [17], who also included the OHKM (online hard key points mining) approach. These authors used GlobalNet and RefineNet, respectively, for various key points. An innovative high-resolution network with multi-scale feature fusion was proposed by Sun et al. [18], which considerably improved the precision of human pose estimates. Top-down approaches are popular due to their high accuracy, but they are still constrained by the complexity of the detection network, which does not support the expansion and implementation of real-time tasks.
Bottom-up approaches detect identity-free key points in images and then divide them into individuals via grouping operations. To create a bigger receptive field using a large convolution kernel, Cao et al. [19] introduced the OpenPose approach. They also suggested that part affinity fields (PAFs) increased the grouping speed of human important spots. Then, they put forward the PeronLab [20] approach and a novel circular method, which significantly enhanced the predictability of two distant keypoints. Part association field (PAF) and part intensity field (PIF) were proposed by Kreiss et al. [21] to map the locations of human joint points and the connections between them. In order to lower the computational burden, Cheng et al. [22] incorporated an effective deconvolution module into the high-resolution network (HRNet) and developed a higher resolution network (HigherHRNet), which included multi-resolution training and a heatmap aggregation technique in the training stage. To generate the convolution kernel standard deviation for each human key point, Luo et al. [23] developed the scale adaptive heatmap regression (SAHR) approach, and they proposed the weighted adaptive heatmap regression (WAHR) method to balance the foreground and background. Bottom-up approaches run stably and quickly, but they rely on heatmaps and complex post-processing grouping algorithms, resulting in unavoidable quantification errors.
For single-shot methods, in order to achieve the correlation and feature fusion of context information between channels, Su et al. [24] incorporated the channel shuffle module (CSM) and attention mechanism into the network. Mao et al. [25] used FCOS for multi-person attitude estimation and used CondConv to generate different convolution kernel parameters for different human instances. Single-stage methods can directly output the location of human key points, thus avoiding grouping operations, but they often do not perform as well as top-down methods and require additional post-processing steps to improve accuracy.
To further prevent the key point detection network’s complexity and duplicate post-processing activity brought on by heatmaps, this paper was committed to enhancing the human pose estimate method without heatmaps. We propose a lightweight human pose estimation network based on multi-scale coordinate attention, which integrates the lightweight GhostNet module [26] and adds the coordinate attention mechanism. BiFPN is employed concurrently to achieve bidirectional, multi-scale feature fusion.
3. The Proposed Method
3.1. Overview
The proposed network is improved with Yolo-Pose network as the framework, and Figure 1 displays the architecture. Based on Yolov5, a classic efficient network in object detection, four components make up the entire network: backbone network, feature extraction and fusion module, detection module, and multi-scale prediction output module. The backbone network was constructed by CSP-darknet. We integrated GhostNet into this section to increase the network’s effectiveness. The BiFPN module was introduced in the feature fusing module to achieve two-way fusion of extracted multi-scale characteristics from the backbone. Then, four various scales of detection heads were connected. At the end of the network, each detection head connected two decoupled prediction heads to output the human regression box and human skeleton key point information.
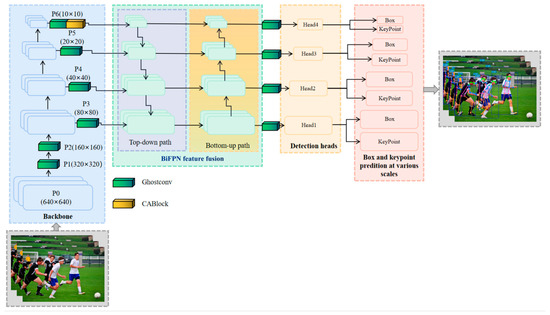
Figure 1.
Lightweight Multi-scale Coordinate Attention Structure.
3.2. Lightweight Network—GhostNet
To address the problem of lightweight network architecture, previous research has proposed numerous compression methods, such as pruning, quantification, knowledge distillation, and so on. Other approaches have focused on efficient network design, such as MobileNet [27], ShuffleNet [28], and so on. Considering the redundancy of the feature map of the neural network, GhostNet designed a phased operation calculation module similar to depthwise separable convolution. The specific idea was to perform a general convolution (convolution batch normalization non-linear activation), output only a few feature maps to save computational resources, and then output intrinsic and other ghost feature maps through a linear transformation (convolution operation) on this basis. The process is shown in Figure 2 below.
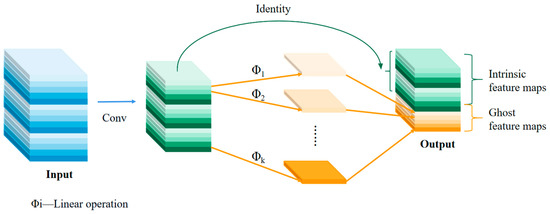
Figure 2.
GhostNet Module.
The details of this process can be described below.
M intrinsic feature maps can be obtained by the convolution operation:
where refers to the kernel and m ≤ n. To further obtain the required n feature maps and generate ghost feature maps, a series of low-cost linear operations were applied to each original feature in :
where is the original characteristic graph in , and is the linear operation used to generate the ghost feature map , that is, can have one or more ghost feature maps . The final was used to preserve the identity mapping of the intrinsic feature maps. By using cheap operations, we could obtain characteristic graphs as the ghost module’s output. The computation cost of a linear operation Φ running on each channel was much lower than that of an ordinary convolution.
Specifically, this module contained linear operations and identity mapping, with an average kernel size for each linear operation. Supposedly, utilizing the ghost module to enhance ordinary convolution would result in a speedup ratio of .
where the amplitude of is comparable to and . Similarly, the parametric compression ratio rc, which is roughly equivalent to the acceleration ratio, can be calculated as follows [29]:
As seen in Figure 3 below, by taking the advantage of the ghost module, our network selected the ghost bottleneck (G-bneck) module, which is provided for tiny CNNs. The G-bneck was primarily made up of two stacked ghost modules. The first ghost module acted as an extension layer, thus increasing the total number of channels. To match the shortcut path, the second ghost module decreased the number of channels. Finally, the inputs and outputs of the two ghost modules were connected using a shortcut. According to the characteristics of the network structure of our work, the initial network’s convolution module was substituted by a G-bneck with two stages [30].
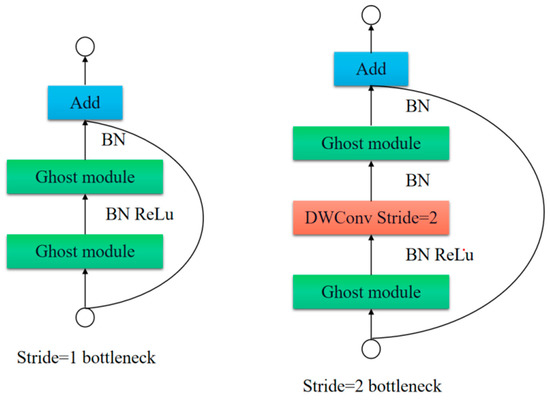
Figure 3.
Ghost Bottleneck.
3.3. Coordinate Attention Mechanism
Attention mechanisms are often used to tell networks what they need to pay more attention to and where, and they have been widely used to enhance model performance in deep neural networks. However, most attention mechanisms often require additional parameters, which increases the burden of network computing overhead. The most popular attention mechanisms include the SE (squeeze and excitation) module [31], CBAM (convolutional block attention module) [32], etc. Unfortunately, the SE module only stresses information encoding between two different channels and neglects the significance of the location feature. By lowering the number of channels and then performing massive convolution, CBAM and other techniques leverage location data. However, as convolution can only detect local correlation [33], it is unable to address the issue of long-term dependence in complex deep networks.
The coordinate attention (CA) module breaks down channel attention into a one-dimensional feature encoding process that aggregates feature information in two directions: horizontal and vertical [34]. Long-term dependencies are captured in a single spatial direction, while another direction is used to retain precise location information. The resulting feature map is then coded to create a couple of direction-aware and location-sensitive feature maps that are applied in ways that are compatible with the input data to improve the target representation of interest. Figure 4 depicts the specific CA module’s network architecture. In detail, the CA module is composed of two phases: coordinate information embedding and coordinate attention generation [35].
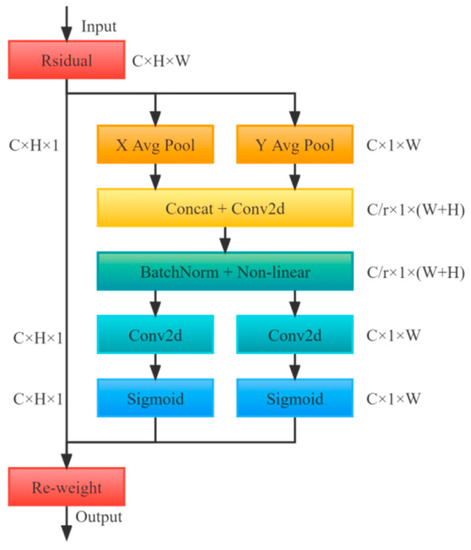
Figure 4.
Coordinate Attention Module.
3.3.1. Coordinate Information Embedding
For channel attention, global pooling is commonly used to encode spatial information. However, it is difficult to preserve location information during compression. To attain the desired spatial long-range dependency information for more precise location information, global pooling is disintegrated into a one-to-one encoding process. Specifically, for input X, each channel is encoded horizontally and vertically using pooled kernels of dimensions and . Therefore, the output of the channel with a height of H can be expressed as below:
Correspondingly, for the channel with a width of , the output can be expressed as follows:
The above transformations combine features along two different spatial directions, resulting in a couple of direction-sensitive and location-sensitive attention maps that benefit the ability of the network to track down the target object more accurately.
3.3.2. Coordinate Attention Generation
To utilize previously collected location information more efficiently, this part concatenated the above transformations and used a shared convolution for the transformation operation:
The obtained is a transitional feature map of spatial information in both horizontal and vertical directions, in which represents the down-sampling scale. The following step was to divide into two distinct tensors along the spatial dimensions and [36]. Then, it reused two convolutions and to covert the feature maps and to the same number of channels as input , yielding the formulas below:
Then, as attention weights, and were expanded. The CA module’s ultimate output can be summed up as follows:
3.4. Bidirectional Feature Pyramid Network
Multi-scale feature fusion is intended to combine features with varying resolutions. Mathematically, it can be expressed as follows:
where reflects the characteristics of the layer, “” symbolizes the input, and “” symbolizes the output. The objective is to determine a transformation function f that successfully gathers various features and produces a set of new features. A complete feature fusion network can be separated into two different segments: cross-scale connections and feature fusion.
3.4.1. Cross-Scale Connections
Many cross-scale connection methods have been put forward in previous studies, the most classic of which is the pyramid network FPN (feature pyramid network). There have been several FPN-based improvement methods, such as PANet [37] and NAS-FPN [38]. Regrettably, the above strategies either have significant computational cost or fail to fuse the features effectively. BiFPN (bidirectional feature pyramid network) [39] first removes nodes with a degree of 1 from PANet. Then, a jump connection is built at the identical scale between the input and output nodes. Finally, each two-way (top-down and bottom-up) path is considered a feature network layer (repeated blocks) and the same layer is repeated multiple times to achieve a higher level of feature fusion [40]. The network structure of the BiFPN module is compared with other feature fusion modules, as depicted in Figure 5.
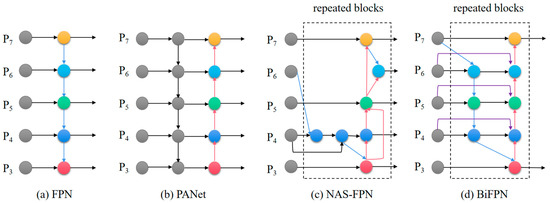
Figure 5.
Structure Comparison of BiFPN Module and Other Feature Fusion Modules.
3.4.2. Weighted Feature Fusion
A familiar technique for fusing features with various resolutions is to initially resize them to an identical resolution and then sum them up. Most prior studies regarded all input features uniformly and without distinction. However, because the resolutions of the various input features vary, they typically provide unequal contributions to the output. To deal with this problem, BiFPN employs a fast, normalized fusion weighting method that boosts detection speed by adding extra weight to each input during feature fusion to make sure the network can understand the value of each input feature [41]. It can be written as follows in mathematical notation:
where is guaranteed to be greater than or equal to 0 by using a Relu activation function after each . Based on experience, the learning rate is set as a small value to prevent numerical uncertainty. Equally, each normalized weight has a value between 0 and 1. This method is much more effective given that it does not use Softmax.
In this way, BiFPN integrates two-way cross-scale connections and fast normalization fusion.
4. Experiments
4.1. Dataset
Our experiment used the COCO 2017 dataset for training and validation. This dataset is one of the most popular benchmark datasets in the domain of human key point detection. It contains more than 20,000 human images, totaling more than 250,000 sets of key point labels. There are 17 key points on each person’s body, namely nose, right eye, left eye, stone ear, left ear, right shoulder, right elbow, right wrist, left shoulder, left elbow, left wrist, right hip, right knee, right ankle, left arm, left knee, and left ankle. Our proposed model was trained on the training 2017 dataset (57,000 images and 150,000 people’s instances) and validated on the validation 2017 dataset (5000 images).
4.2. Details
The experimental environment was based on the Ubuntu 18.04.1 operating system with Linux kernel, and the GPU was a NVIDIA Geforce 3090. The experiment was based on the PyTorch framework with Python version 3.10.1, PyTorch version 1.12.1, and CUDA version 11.4. The optimizer used in this network was SGD (stochastic gradient descent), with a batch size of 32, an initial learning rate of 1 × 10−2, a weight decay rate of 0.0005, and a momentum value of 0.937. The network conducted 300 iterations of learning. The specific hyper-parameter settings are shown in Table 1 below.

Table 1.
Hyperparameter Settings.
4.3. Validation and Analysis
4.3.1. Data Preprocessing
This paper used the same data preprocessing method as the underlying network Yolo-Pose. Methods for data enhancement included random scaling, horizontal flipping, random displacement transformation, mosaic enhancement, and color enhancement [42]. The size of the input data was uniformly resized to 640 × 640 pixels.
4.3.2. Loss
The original Yolo-Pose network used CIoU (complete intersection over union) [43] as the loss function. It considered the boundary box regression’s overlapping area, center point distance, and aspect ratio. At the same time, it also added the scale loss of the detection box based on DIOU (distance intersection over union) [43] and added the loss of length and width to make the prediction box better conform to the true box. The V in the formula, on the other hand, reflected the disparity in aspect ratio rather than the true difference between width and height and their level of confidence, which may impede effective model optimization similarity. To address this issue, we tried to replace it with EIOU (efficient intersection over union) [44]. Unlike CIOU, EIOU separates the aspect ratio influence factors to measure the length and width of the target and anchor frames respectively. EIOU can be described as below:
The loss function is divided into three parts: overlapping loss, center distance loss, and width height loss. The first two components are identical to those used in CIOU, but the width-height loss immediately lowers the width and height discrepancy between the target box and anchor box, allowing for faster convergence. Where and are the minimum bounding box’s width and height, respectively, for the two boxes [45].
4.3.3. Evaluation Metric
The validation standard in our work adopted the mean average accuracy (mAP) metric based on the object key similarity (OKS) validation standard officially given by MS COCO. The OKS is expressed as follows:
where is the Euclidean metric between the labeled and predicted joint points; is the target scale; is the control attenuation constant of each keypoint ( is the standard deviation); indicates whether the key point of the actual human body may be seen ( indicates that the key point position can be observed, indicates that the keypoint position cannot be observed). The similarity value of each joint point is . Theoretically, a perfect prediction will result in TOKS = 1. TOKS will tend to equal 0 when the difference between the predicted and true value is too large.
The standard average accuracy and recall rate is used to represent the test results; mAP represents the average detection accuracy when TOKS is 0.50, 0.55, 0.60,…, 0.90, 0.95, respectively. AP50 represents the detection accuracy when TOKS = 0.50. AR represents the average recall rate when TOKS is 0.50, 0.55, 0.60,…, 0.90, 0.95, respectively.
4.3.4. Result Analysis
Table 2 displays the experimental performance comparison of human pose estimation between our approach and some other current advanced methods on the COCO 2017 validation dataset. Our model experiment data are specifically displayed in the bold font. The results showed that when the input data size was fixed at 640 × 640 pixels, compared with the original baseline Yolo-Pose model, our proposed network reduced the parameter amount by 0.8 M, decreased the calculation cost by 6.0 GFLOPs, achieved 5.7% improvement on mAP, and showed a 5.7% significant improvement on AP50. In the case of images with the same input size, compared to large, high-resolution bottom-up human pose estimation networks such as HigherHRNet and DEKR, which have approximately 40 times the computation cost and 10 times the number of parameters, the method we put forward also had 1.8% and 0.6% improvements on AP50. The results of the experiment on the COCO 2017 validation dataset demonstrated that our approach can greatly enhance the previous Yolo-Pose network’s precision and convergence speed, providing an excellent alternative to complex and large-scale human pose estimation methods and enhancing further research and exploration of human keypoint detection methods without heatmaps [46].
Table 2.
Comparison of Accuracy of Different Methods on COCO 2017.
Figure 6 shows the AP50 comparison of human posture estimation methods with various network computations on the COCO 2017 validation dataset. The figure shows that, when compared to bottom-up key point detection methods using large networks with higher accuracy and high complexity, such as HigherHRNet and DEKR, the proposed network retained a pretty high level of human key point detection accuracy while simultaneously offering significant improvements for a lightweight network. Compared to the low complexity network, the performance of our model was not inferior and even had higher detection accuracy.
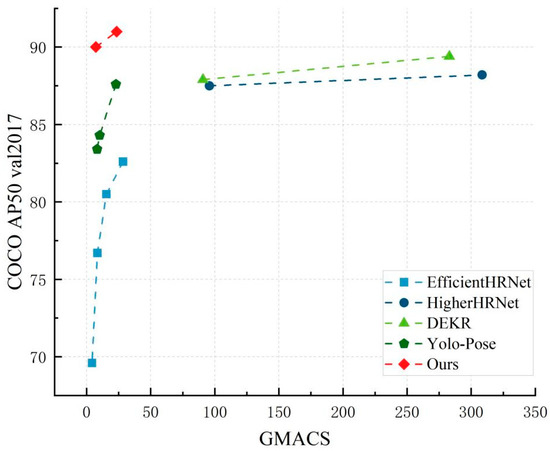
Figure 6.
AP50 vs. GMACS on COCO 2017 Validation Dataset.
As a member of the lightweight human posture estimation networks, the model detection accuracy and experimental effect of our proposed network were compared with other lightweight networks in the same task. Table 3 and Figure 7 show the average accuracy comparison between the improved network in this paper and other network models with less than 30 GMACS in the COCO2017 validation dataset. Data from our model experiment are explicitly displayed in bold font in Table 3. It can be concluded from the results that, with lower input size, the performance of our model was far higher than that of state-of-the-art models such as EfficientHRNet. Our presented method had less computational cost than the original Yolo-Pose network but also had much higher average accuracy.
Table 3.
Comparison of Network Complexity and Average Accuracy between Our Model and Other Lightweight Models on COCO 2017.
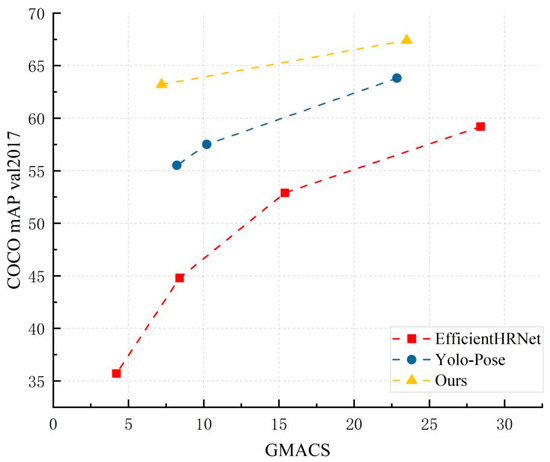
Figure 7.
mAP vs. GMACS for Low Complexity Models on COCO 2017 Validation Dataset.
To further investigate the performance and operational efficiency of our method, we compared the inference speed and corresponding average accuracy of the proposed model with other classical human keypoint detection methods on the COCO 2017 validation dataset, especially for some lightweight models. FPS (frames per second) served to quantify the inference speed. The experimental comparison results are shown in Table 4 and Figure 8. The bold text in Table 4 shows the results of our model experiment. According to the data, our approach not only had higher detection accuracy than the original network, but it also sped up inference. HigherHRNet employs HRnet as its backbone. Its network structure features numerous branches and parallelism, which have a detrimental impact on the network’s actual inference performance. Not only that, but our approach retained a comparable inference speed and significantly outperformed lightweight human posture estimation networks such as EfficientHRNet in terms of detection accuracy. The experimental results demonstrated that our method greatly improved the performance of the model by fusing the lightweight module GhostNet, improving the feature fusion module, and introducing the coordinate attention mechanism, which can thus meet the requirements of real-time deployment.
Table 4.
Comparison of Network FPS and Average Accuracy between Our Model and Other Models on COCO 2017.
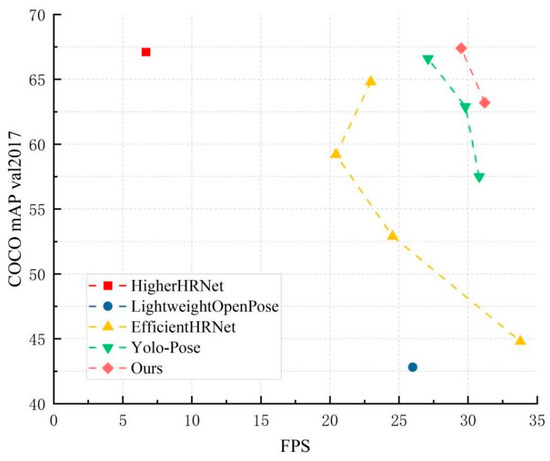
Figure 8.
FPS vs. mAP of Different Methods on COCO 2017 Validation Dataset.
4.4. Ablation Experiment
In this paper, the COCO dataset was selected for the ablation experiment. First, the GhostNet, coordinate attention mechanism (CA), and BiFPN modules were separately used on the baseline network to evaluate each component’s effect on Yolo-Pose.
The size of the input data was fixed at 640 × 640 pixels. The pre-training model was not applicable. The initial learning rate was 1 × 10−2. The SGD optimizer was used to update the network parameters. All models were trained from the beginning with the same configuration, and each training iteration was 50 times. Table 5 displays the respective experimental configuration and results.
Table 5.
Ablation Experiment Configuration and Results. √ and - denotes “with” and “without” the module respectively.
In method (1), as the control group, the network was based on the original Yolo-Pose method, which is constructed by CSP-darknet53-s. Methods (2) to (5) respectively integrated the GhostNet, CA mechanism, and BiFPN modules into the basic Yolo-Pose network.
Comparing methods (1) and (2), as we can see, the GhostNet module essentially cut the original network’s computation capacity by 5.6 GFLOPs. At the same time, network accuracy mAP increased by 2.3% and a 2.6% increase in AP50 was achieved. These results showed that the GhostNet module can significantly lighten the network while extracting more effective features, thus enhancing the network precision and confirming the practicability of the GhostNet module.
Comparing methods (1) and (3), it can be seen that using the coordinate attention mechanism boosted the network precision mAP and AP50 by 1.1% and 0.8%, respectively [29]. These results proved the CA module’s capability to accurately extract the position information of the human body, thereby improving the accuracy of the network.
Comparing methods (1) and (4), it can be seen that after replacing the original PANet multi-scale feature fusion module with the BiFPN module, 1.7% and 2.6% improvements were achieved in the original network accuracy mAP and AP50. These results demonstrates that the weighted bidirectional feature pyramid module could obtain and fuse multi-scale feature information in the network more proficiently, improving the accuracy and robustness of the network and validating the effectiveness of our approach.
The results of the ablation experiments showed that the GhostNet, coordinate attention mechanism (CA), and bi-directional feature pyramid network (BiFPN) modules contributed significantly to the enhancement of our model’s performance.
To more accurately assess each enhanced module’s contribution to the overall network model, Figure 9 shows the comparison of AP50 of the five methods in the above ablation experiment based on different network computations and on the COCO 2017 validation set. First of all, it is clear from the comparative data in the figure that each enhanced module reduced the computational complexity of the original network to varying degrees, which significantly boosted the accuracy of the network. According to the data of the first 50 iterations, among the GhostNet, coordinate attention mechanism, and BiFPN modules, the GhostNet module contributed the most to the improvement of network lightweight and accuracy. This demonstrated that by breaking down the convolution process and linear transformation operations, GhostNet may considerably improve network accuracy while lowering the computing cost of convolution networks and producing more useful feature maps. Although the BiFPN module did not significantly reduce the amount of model calculations, it made a greater contribution in terms of enhancing the model’s accuracy, which showed that the module could effectively use the features extracted from the previous network through bi-directional fusion and perform weighted evaluation of features of different scales in the network, thus enhancing the model’s precision for human keypoint detection.
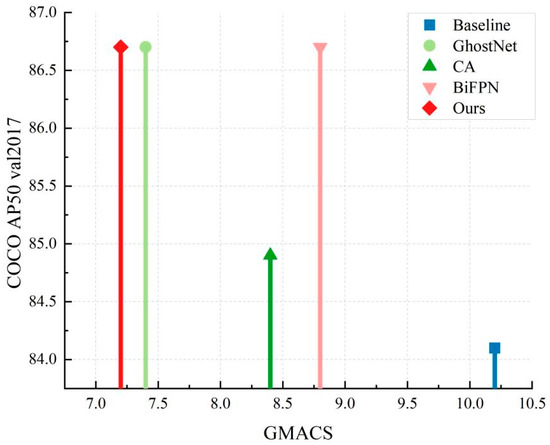
Figure 9.
Comparison of Parameters and Accuracy of Each Model in the Ablation Experiment.
4.5. Visual Analysis
In this section, some human image samples from the COCO dataset were randomly selected for pose estimation visualization, according to Figure 10. The visualization outcomes demonstrated that the suggested technique was capable of accurately detecting the location of human skeleton joint sites in a variety of situations, including dark light, dense people, obstacle occlusion, and shooting fuzzy pictures. As a result of the advantages of the coordinated attention mechanism and the weighted bidirectional feature pyramid module, multi-scale features could be learned by the network, more effectively accounting for both local and global feature information in the image. As a result, excellent performance was displayed in a variety of challenging environments, proving the dependability and robustness of our proposed method.

Figure 10.
Pose estimation results on COCO 2017.
5. Conclusions
This paper proposes a lightweight, end-to-end human pose estimate approach based on multi-scale coordinate attention that does not have the quantization error issue of earlier heatmap-based methods. Our method ensures a lightweight network and only a few parameters and computation costs are added, which enables more efficient representation of the features of various scales and improves the performance of the network. By replacing the convolution layer with GhostNet, the model becomes more effective and lightweight. The backbone network incorporates the coordinate attention mechanism to more accurately extract the human body position information. Effective multi-scale feature fusion is achieved using the BiFPN module. Finally, network convergence is sped up by using EIoU as the loss function. Experiments on the COCO 2017 dataset showed that the proposed method can effectively extract human key point features and improve the original network performance. At the same time, there are certain deficiencies in our work. For example, the network was not ideal for detecting key points in some highly crowded images or small human targets. The accuracy and speed of high-resolution picture detection still have room for improvement. How to further increase the network accuracy of multi-person pose estimates will be addressed during the next work and implementing the method in real application scenarios is the follow-up research direction.
Author Contributions
Conceptualization, X.L. and Y.G.; methodology, X.L. and Y.G.; software, X.L.; validation, X.L. and Y.G.; formal analysis, W.P. and H.L.; investigation, W.P. and H.L.; data curation, X.L. and Y.G.; writing—original draft preparation, X.L. and Y.G.; writing—review and editing, W.P. and H.L.; visualization, B.X.; supervision, W.P. and H.L.; project administration, W.P. and H.L.; funding acquisition, B.X. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Beijing Natural Science Foundation (4232026); National Natural Science Foundation of China (grant nos. 62006020, 62272049, 62171042, 61871039, 62102033); Key Project of Science and Technology Plan of Beijing Municipal Education Commission (KZ202211417048); Academic Research Projects of Beijing Union University (ZK10202202); and the Premium Funding Project for Academic Human Resources Development in Beijing Union University (BPHR2020DZ02).
Informed Consent Statement
Not applicable.
Data Availability Statement
Data availability on request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yang, B.; Wang, J. An Improved Helmet Detection Algorithm Based on YOLO V4. Int. J. Found. Comput. Sci. 2022, 33, 887–902. [Google Scholar] [CrossRef]
- Gong, W.; Zhang, X.; Gonzàlez, J.; Sobral, A.; Bouwmans, T.; Tu, C.; Zahzah, E.-h. Human pose estimation from monocular images: A comprehensive survey. Sensors 2016, 16, 1966. [Google Scholar] [CrossRef] [PubMed]
- Gadhiya, R.; Kalani, N. Analysis of deep learning based pose estimation techniques for locating landmarks on human body parts. In Proceedings of the 2021 International Conference on Circuits, Controls and Communications (CCUBE), Bangalore, India, 23–24 December 2021; pp. 1–4. [Google Scholar]
- Liu, W.; Bao, Q.; Sun, Y.; Mei, T. Recent advances of monocular 2d and 3d human pose estimation: A deep learning perspective. ACM Comput. Surv. 2022, 55, 1–41. [Google Scholar] [CrossRef]
- Nie, X.; Feng, J.; Zhang, J.; Yan, S. Single-stage multi-person pose machines. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 6951–6960. [Google Scholar]
- Tang, W.; Wu, Y. Does learning specific features for related parts help human pose estimation? In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 1107–1116. [Google Scholar]
- Zhang, F.; Zhu, X.; Ye, M. Fast human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 3517–3526. [Google Scholar]
- Chen, Y.; Tian, Y.; He, M. Monocular human pose estimation: A survey of deep learning-based methods. Comput. Vis. Image Underst. 2020, 192, 102897. [Google Scholar] [CrossRef]
- Huang, J.; Zhu, Z.; Huang, G.; Du, D. AID: Pushing the Performance Boundary of Human Pose Estimation with Information Dropping Augmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.T.; Zhou, E. TokenPose: Learning Keypoint Tokens for Human Pose Estimation. In Proceedings of the 2021 IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 11293–11302. [Google Scholar]
- Wang, W.; Zhang, K.; Ren, H.; Wei, D.; Gao, Y.; Liu, J. UULPN: An ultra-lightweight network for human pose estimation based on unbiased data processing. Neurocomputing 2022, 480, 220–233. [Google Scholar] [CrossRef]
- Ma, N.; Li, D.; He, W.; Deng, Y.; Li, J.; Gao, Y.; Bao, H.; Zhang, H.; Xu, X.; Liu, Y.; et al. Future vehicles: Interactive wheeled robots. Sci. China Inf. Sci. 2021, 64, 56101:1–156101:3. [Google Scholar] [CrossRef]
- Liang, T.; Bao, H.; Pan, W.; Pan, F. Traffic Sign Detection via Improved Sparse R-CNN for Autonomous Vehicles. J. Adv. Transp. 2022, 2022, 1–16. [Google Scholar]
- Maji, D.; Nagori, S.; Mathew, M.; Poddar, D. YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 2637–2646. [Google Scholar]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards accurate multi-person pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4903–4911. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Honolulu, HI, USA, 21–26 July 2017; pp. 2334–2343. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 27 October 2019–02 November 2019; pp. 5693–5703. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Papandreou, G.; Zhu, T.; Chen, L.C.; Gidaris, S.; Tompson, J.; Murphy, K. Personlab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 269–286. [Google Scholar]
- Kreiss, S.; Bertoni, L.; Alahi, A. Pifpaf: Composite fields for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 11977–11986. [Google Scholar]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 5386–5395. [Google Scholar]
- Luo, Z.; Wang, Z.; Huang, Y.; Wang, L.; Tan, T.; Zhou, E. Rethinking the heatmap regression for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13264–13273. [Google Scholar]
- Su, K.; Yu, D.; Xu, Z.; Geng, X.; Wang, C. Multi-person pose estimation with enhanced channel-wise and spatial information. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 5674–5682. [Google Scholar]
- Mao, W.; Tian, Z.; Wang, X.; Shen, C. Fcpose: Fully convolutional multi-person pose estimation with dynamic instance-aware convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 9034–9043. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Wenjun, W.; Tobias, W.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Kong, L.; Wang, J.; Zhao, P. YOLO-G: A Lightweight Network Model for Improving the Performance of Military Targets Detection; IEEE Access: Piscataway, NJ, USA, 2022. [Google Scholar]
- Hu, Q.; Li, R.; Pan, C.; Bao, Y.; Zhang, H. Aircraft Targets Detection in Remote Sensing Images with Feature Optimization. In Proceedings of the 2021 IEEE 4th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 18–20 June 2021; IEEE: Piscataway, NJ, USA, 2021; Volume 4, pp. 1542–1549. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Bao, W.; Cheng, T.; Zhou, X.G.; Guo, W.; Yuanyuan, W.; Xuan, Z.; Hongbo, Q.; Dongyan, Z. An improved DenseNet model to classify the damage caused by cotton aphid. Comput. Electron. Agric. 2022, 203, 107485. [Google Scholar] [CrossRef]
- Ma, Z.; Zeng, Y.; Zhang, L.; Li, J. The Workpiece Sorting Method Based on Improved YOLOv5 For Vision Robotic Arm. In Proceedings of the 2022 IEEE International Conference on Mechatronics and Automation (ICMA), Guilin, China, 7–10 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 481–486. [Google Scholar]
- Tu, G.; Qin, J.; Xiong, N.N. Algorithm of Computer Mainboard Quality Detection for Real-Time Based on QD-YOLO. Electronics 2022, 11, 2424. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, F.; Wang PS, P.; Li, X.; Meng, Z. Multi-scale spatial-spectral fusion based on multi-input fusion calculation and coordinate attention for hyperspectral image classification. Pattern Recognit. 2022, 122, 108348. [Google Scholar] [CrossRef]
- Mei, Y.; Fan, Y.; Zhang, Y.; Jiahui, Y.; Yuqian, Z.; Ding, L.; Yun, F.; Thomas, S.H.; Humphrey, S. Pyramid attention networks for image restoration. arXiv 2020, arXiv:2004.13824. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 7036–7045. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10778–10787. [Google Scholar]
- Guo, H.; Zhang, R.; Li, Y.; Cheng, Y.; Xia, P. Research on human-vehicle gesture interaction technology based on computer visionbility. In Proceedings of the 2022 IEEE 6th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Beijing, China, 3–5 October 2022; pp. 1161–1165. [Google Scholar]
- Pang, L.; Sun, J.; Chi, Y.; Yang, Y.; Zhang, F.; Zhang, L. CD-TransUNet: A Hybrid Transformer Network for the Change Detection of Urban Buildings Using L-Band SAR Images. Sustainability 2022, 14, 9847. [Google Scholar] [CrossRef]
- Yi, K.; Luo, K.; Chen, T.; Hu, R. An Improved YOLOX Model and Domain Transfer Strategy for Nighttime Pedestrian and Vehicle Detection. Appl. Sci. 2022, 12, 12476. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; Volume 506, pp. 146–157. [Google Scholar]
- Jin, H.; Liao, S.; Shao, L. Pixel-in-Pixel Net: Towards Efficient Facial Landmark Detection in the Wild. Int. J. Comput. Vision 2021, 129, 3174–3194. [Google Scholar] [CrossRef]
- Qiang, B.; Zhang, S.; Zhan, Y.; Xie, W.; Zhao, T. Improved convolutional pose machines for human pose estimation using image sensor data. Sensors 2019, 19, 718. [Google Scholar] [CrossRef] [PubMed]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 483–499. [Google Scholar]
- Geng, Z.; Sun, K.; Xiao, B.; Zhang, Z.; Wang, J. Bottom-up human pose estimation via disentangled keypoint regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14676–14686. [Google Scholar]
- Neff, C.; Sheth, A.; Furgurson, S.; Tabkhi, H. Efficienthrnet: Efficient scaling for lightweight high-resolution multi-person pose estimation. arXiv 2020, arXiv:2007.08090. [Google Scholar]
- Osokin, D. Real-time 2d multi-person pose estimation on cpu: Lightweight openpose. arXiv 2018, arXiv:1811.12004. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).