1. Introduction
Music Information Retrieval (MIR) deals with extracting, processing, and organizing meaningful features from music material [
1]. From the analysis of audio signals to symbolic representations and musical blueprints (score), MIR focuses on many challenging tasks such as content-based search, music tagging, automatic transcription, feature detection, music recommendation, and much more [
2]. MIR methods significantly impact the Music Performance Analysis (MPA) field [
3], providing more accurate detectors and possibilities for automated music analysis. In the case of classical music, a performance affects how listeners perceive a piece of music. Each interpretation may be special thanks to, for example, modifying information from the score and converting various musical ideas into musical renditions [
1]. The communication between members of ensembles also shapes a performance [
4,
5,
6]. Classification tasks, such as the classification of music genres [
7,
8], mood [
9], music structures [
10], or composers [
11,
12], are examples of interdisciplinary approaches—a combination of MIR techniques with MPA, musicology, and music analysis.
Music-related classification problems are common [
8,
13], but only the minimum deals with the classification of origin-based or music school-related differences of interpretations. In this paper, we combine MIR techniques with MPA goals. We focus on identifying the differences between interpretations of the same musical composition. In other words, we aim to create a classifier that could differentiate music performances based on the origin of a given composer. If it is possible to train a classifier, we can conclude that there are noticeable differences. To our best knowledge, there is only one study [
14] with a similar goal using machine learning besides studies with a phylogenetic approach [
10] or comparative music analysis [
15,
16,
17]. However, many studies combine MIR and MPA disciplines and focus on expressive performances [
18,
19]. Machine learning models have been researched in the MPA community to, for example, model nuances of dynamics and timing of expressive performances using inter-onset-intervals with Hidden Markov Models [
20] and linear regression [
21], or to perform score following tasks [
22]. Many other approaches to computational modeling of expressive performance also include neural networks [
21,
23,
24].
We focus on string quartet music from Czech composers Antonín Dvořák, Leoš Janáček, and Bedřich Smetana. First, we collect a large dataset (compared to the average size of MPA datasets, see [
3]) and label each recording to create two classes: Czech and non-Czech interpretations. The underlying hypothesis is that the Czech performers may play the piece differently, for example, considering the same cultural background and tradition shared with the composers of the analyzed music. We can address this problem quantitatively thanks to the increasing number of available recordings and the accuracy of synchronization methods [
25,
26]. We extract relevant timing-related features from all interpretations that may cover information about the expressiveness of a given performance and construct feature matrices to train and test a machine learning classifier.
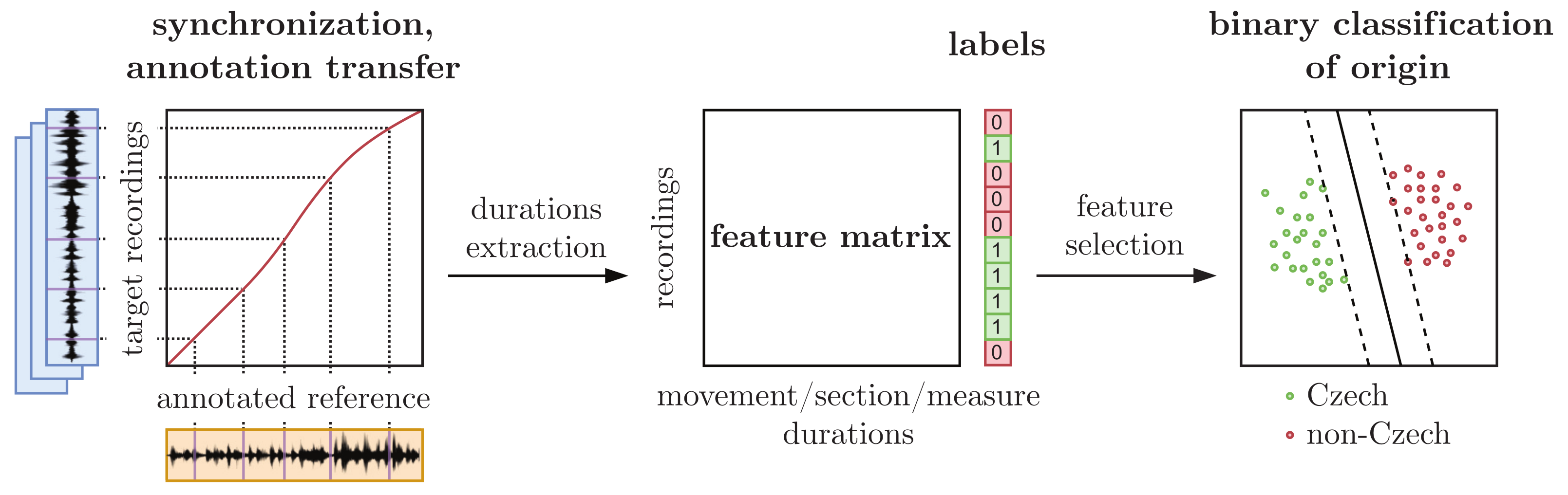
Figure 1 shows the overview of our classification approach.
As this paper’s main contribution, we show a general trend in the rhythmic conception (duratas) of given string quartets based on the proposed binary classes. Although various music schools, cultures, and traditions influence musicians, we can train a classifier to identify Czech and non-Czech interpretations of given string quartets with relatively high accuracy in most cases. To better understand the features and classification results (and why it is possible to train such a classifier), we split our experiments into three scenarios, each applying a different time resolution of features. Unlike the approach in the Ref. [
14], we use various string quartets, more recordings, and extract features based on a semi-automated approach instead of relying on automated systems with a possibility of significant misdetection. Furthermore, we support our feature selection with MPA principles (see
Section 3.1) to focus only on timing parameters that may show the expressiveness of music performances (third scenario). We can achieve high classification accuracy if the selected features, derived from ground-truth (GT) data and a synchronization strategy, capture local tempo deviations. We understand the controversial nature of defining the “origin” of musicians and splitting our dataset into two binary classes; however, we want to show that the interpretation differences may be significant when using a machine learning method, even though they would not be qualitatively noticeable by music experts. We do not claim that a difference in interpretation has any quality to it—we only show that there is a difference. To provide additional data, we share a GitHub repository (
github.com/xistva02/Classification-of-interpretation-differences, accessed on 10 March 2023).
The rest of the paper is organized as follows.
Section 2 introduces the string quartet dataset, annotation, labeling process, and audio-to-audio synchronization and compares automated and semi-automated approaches for measure detection.
Section 3 describes a feature selection, visualization method, dimensionality reduction, and design of experiments. The results are reported in
Section 4, followed by a discussion in
Section 5 and conclusions with prospects for future work in
Section 6.
2. Methods
This section introduces our string quartet dataset, annotation process, and audio-to-audio synchronization strategy to obtain transferred measure positions. We show the validity of synchronization accuracy by comparing the automated downbeat tracking systems with the semi-automated synchronization procedure.
2.1. Dataset
We collected string quartets of Antonín Dvořák, Leoš Janáček, and Bedřich Smetana from various sources, such as Naxos Music Library, Czech Museum of Music, and Masaryk University, Faculty of Arts. Each composition is divided into four movements—in the following text, each movement is regarded as a separate recording. The composers, compositions, and movements (roman numerals) are divided as follows.
Antonín Dvořák:
- -
String Quartet No. 12 in F major, Op. 96
- I.
Allegro ma non troppo
- II.
Lento
- III.
Molto vivace
- IV.
Vivace ma non troppo
- -
String Quartet No. 13 in G major, Op. 106
- I.
Allegro moderato
- II.
Adagio ma non troppo
- III.
Molto vivace
- IV.
Andante sostenuto
- -
String Quartet No. 14 in A♭ major, Op. 105
- I.
Adagio ma non troppo
- II.
Molto vivace
- III.
Lento e molto cantabile
- IV.
Allegro non tanto
Leoš Janáček:
- -
String Quartet No. 1, “Kreutzer Sonata”, JW 7/8
- I.
Adagio con moto
- II.
Con moto
- III.
Con moto – Vivace – Andante – Tempo I
- IV.
Con moto
- -
String Quartet No. 2, “Intimate Letters”, JW 7/13
- I.
Andante
- II.
Adagio
- III.
Moderato
- IV.
Allegro
Bedřich Smetana:
- -
String Quartet No. 1 in E minor, “From My Life”, JB 1:105
- I.
Allegro vivo appassionato
- II.
Allegro moderato à la Polka
- III.
Largo sostenuto
- IV.
Vivace
- -
String Quartet No. 2 in D minor, JB 1:124
- I.
Allegro
- II.
Allegro moderato
- III.
Allegro non più moderato, ma agitato e con fuoco
- IV.
Presto
For more details about compositions, we refer to the International Music Score Library Project (IMSLP) (
https://imslp.org/, accessed on 10 March 2023). Most versions are studio recordings, but we also keep the live versions.
Table 1 shows the composers, musical compositions, the number of recordings, binary labels (classes) of the performer’s origin (1 refers to the Czech class and 0 to the non-Czech class), and the total duration of all interpretations of the given composition combined. Our dataset consists of 1315 string quartet recordings with a total duration of roughly six days. We focused on the well-known string quartets of Czech composers, increasing the probability of gathering enough data for the proposed analysis.
We understand this labeling is problematic (performers may study abroad and be inspired by many composers, teachers, musicians, and interpretations). However, Czech musicians may play the string quartets of Czech composers differently, inheriting a specific style or carrying on the music tradition that led to the compositions in the first place. Such labeling could be later changed (such as Europe/rest of the world or Central Europe/Western Europe) with different aims of the analysis. As we show in this study, specific details in the tempo of measures may differentiate performers, perhaps even without their prior intention.
Based on the open-source policy, we would like to contribute with string quartet data to the performance datasets (see [
3,
27]). However, the vast majority of recordings are not under a CC license. Therefore, we share at least measure information (annotations) of each interpretation and composition in the GitHub repository.
2.2. Annotation
To characterize or evaluate differences in interpretations, we want to obtain or extract reliable timing information from each recording (see
Section 3.1). First, we used automated methods with little success (see
Section 2.4). We manually annotated one interpretation (chosen as a reference recording) per composition to obtain GT data and acquire annotations for all other interpretations based on the audio-to-audio synchronization strategy [
25].
We considered the sequence of beats or measures as our timing parameter. Both can describe a given piece’s local and global tempo and can be connected to the underlying score material. However, we chose measures to easily segment sections based on the score and reduce the time needed to annotate each reference recording. Time positions of measures may provide sufficient resolution and valuable information for further evaluation [
28]. If the goal of analysis or required time resolution changes, one can annotate and synchronize, for example, beats instead (see
Section 2.3).
We annotated GT measure positions (obtaining reference measure positions) for each reference recording based on a corresponding score. Furthermore, we annotated sections—meaningful segments of each movement usually marked by numbers or letters.
Table 2 shows the number of sections and measures for all compositions and movements. We did not annotate sections of Smetana’s String Quartet No. 2 as they were not included in the score.
2.3. Synchronization
To obtain measure positions for each interpretation, we resample all recordings to 22,050 Hz and compute the time alignment of the reference and all target recordings following the sync-toolbox pipeline in [
25]. First, a variant of chroma vectors, also known as Chroma Energy Normalized Statistics (CENS) features [
29], is computed. The tuning is estimated to shift CENS accordingly, and the Memory-restricted Multiscale DTW algorithm (MrMsDTW) [
30] is applied to find the optimal alignment between both recordings (chroma representations). Measure positions are then transferred from the reference to each target recording based on the warping path and final interpolation. Following this strategy, one can obtain any time-related annotation (onsets, beats, measures, regions) if both reference and target recordings follow the same harmonic and melodic structure and at least one set of GT data is available.
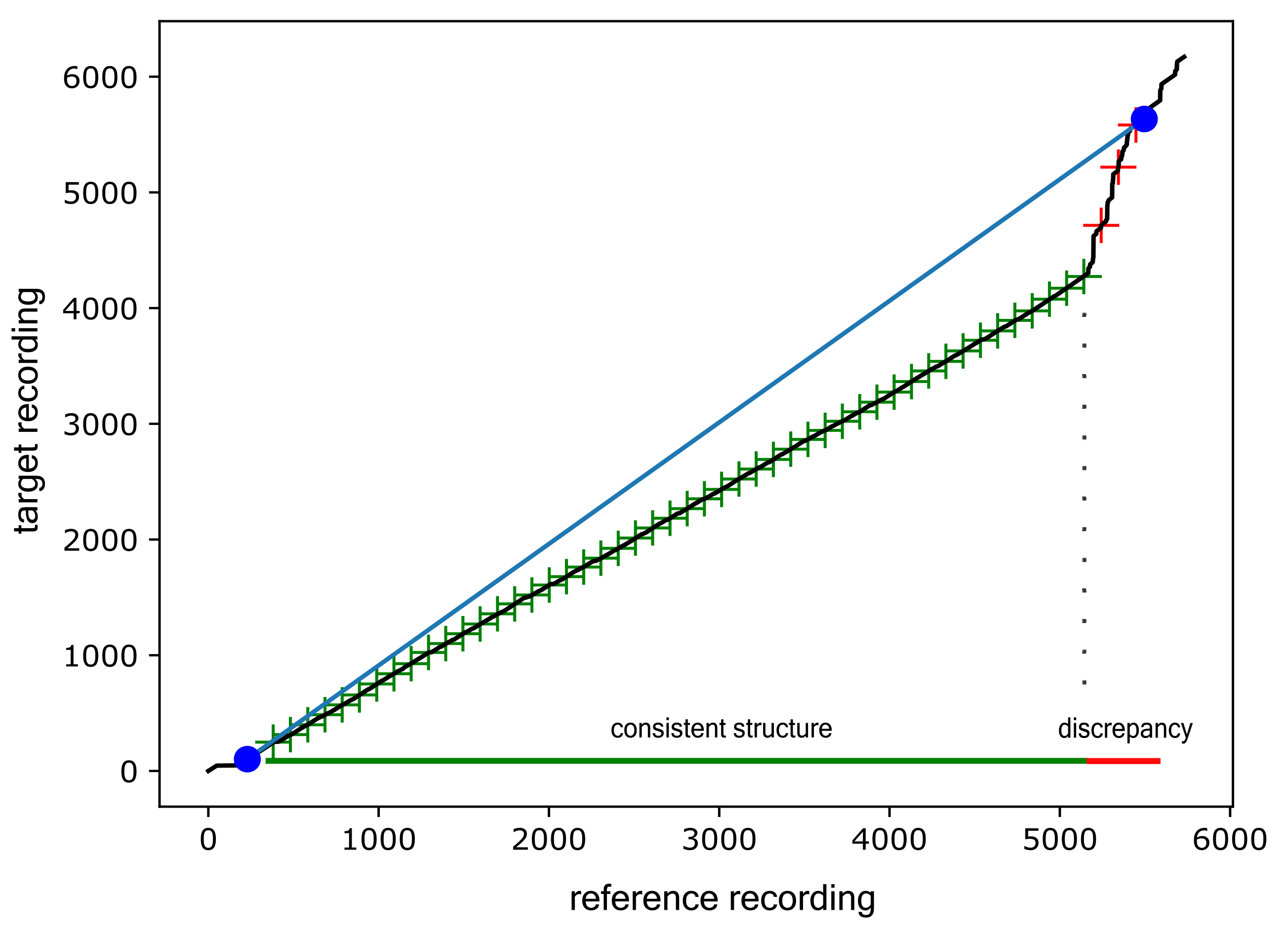
In the case of string quartets, there may be problems with repetitions and, for example, codas. As a pre-processing step, we check the structure differences first. We compute anchor points (the first 10% and the last 90% of the duration of a given recording), test points projected on the warping path (approximately one point every two seconds), and connect the anchor points to form a line (see
Figure 2). We consider only 10–90% of the warping path to avoid possible applause at the beginning or end of a recording. Furthermore, we compute the relative slope
(the difference between the slope of the projected line and consecutive points on the warping path) and absolute slope
(the projected line is not taken into consideration). If
> 3 or
< 0.13, we suspect a structural change in the musical content (see
Figure 2). In other words, if the slope of the projected consecutive points is too steep or too flat, the target recording is not valid for further processing. For example,
= 3 corresponds to the situation when the given time segment of the target recording is played three times faster than the reference recording. Based on our observations and dataset, it is unlikely for longer time segments even with expressive music, such as string quartets. Following this strategy, we should automatically select all interpretations that follow the same score. The threshold values
and
were set empirically. If both reference and target recordings are duplicates, the slope of all consecutive points on the warping path is ideally 1. We discarded all duplicates and proceeded only with recordings that followed the same structure as a reference recording. The final number of all interpretations for the classification is given
Appendix A,
Table A1–
Table A3, depending on the composer.
Interestingly, we encountered a situation where two recordings were duplicates even though they had different duration and audio qualities. One was the original copy from the phonograph recording; the second was a newer CD release. They differed in the source (database), metadata, duration, and thus global tempo, audio quality, and the presence of noise. Audio fingerprinting and image hashing methods would probably struggle with this case (their goal is slightly different), but the proposed synchronization technique detected the duplicates correctly. The limitation of this approach, and the reason why it is not commonly used on big datasets, is in its computational time that grows with the number of input recordings (synchronization pairs) even with optimized DTW methods. The number of all combinations C is , where n is the number of recordings. By adding one track to the dataset, one must run all possible combinations with a given recording again.
2.4. Validity of Synchronization Accuracy
In MPA, many timing parameters (onsets, beats, measures, and tempo) may be derived from GT annotations. In the case of classical music or string quartets, the automated systems (onset, beat, and downbeat trackers/detectors) still need to be improved for fully automated analysis. To demonstrate this, we apply a well-known RNN-based downbeat detector [
31] and WaveBeat downbeat detector [
32] to one of the reference recordings with GT data available and compare the results with the semi-automated synchronization approach. For this purpose, we manually annotated the second reference recording in the same way described in
Section 2.2. We did not use the latest downbeat detector based on Temporal Convolutional Networks (TCN), introduced in the Ref. [
33], because the pre-trained neural network models are not publicly available.
Table 3 shows the results for both downbeat detectors and a synchronization strategy. In addition to classical scores for comparing the accuracy of detectors (F-measure, continuity-based evaluation scores CMLc, CMLt, AMLc, AMLt, and Information Gain (D) that represents the entropy of measure error histogram), we computed the absolute mean (
) and median (
) difference in seconds between GT positions of the first reference and the transferred measure positions from the second reference recording. To compute the F-measure, we used a window size of
(instead of default
for beat tracking tasks) to compensate for the nature of soft onsets produced by string instruments and a coarser time resolution of measures. For further details and information about metrics, we refer to [
34,
35].
and
are computed only for the synchronization method as the number of references and estimated measures are always the same condition, which cannot be satisfied using automated methods.
Results suggest that the synchronization approach is, as expected, more robust and reliable (F-measure = 0.927 and
= 25 ms) and, in contrast to the automated detectors, always outputs the correct number of measures. Unlike downbeat detectors, the evident and problematic limitation is the necessity of at least one manual reference annotation. The downbeat trackers are not trained on string quartets and expressive music in general. This problem is partly addressed in, for example, [
36] or [
37], where the evaluation is based on user-driven metrics [
38].
5. Discussion
This study aimed to train a machine learning classifier that predicts the performer’s origin (Czech and non-Czech classes) of any interpretation given well-known string quartets of Czech composers. We propose feature matrices based on duration information, ignoring dynamics or timbre parameters as the acoustics, recording environment and equipment, instruments, and post-processing may make the input features of classification unreliable. Contrary to the Ref. [
14], we use only suitable timing information.
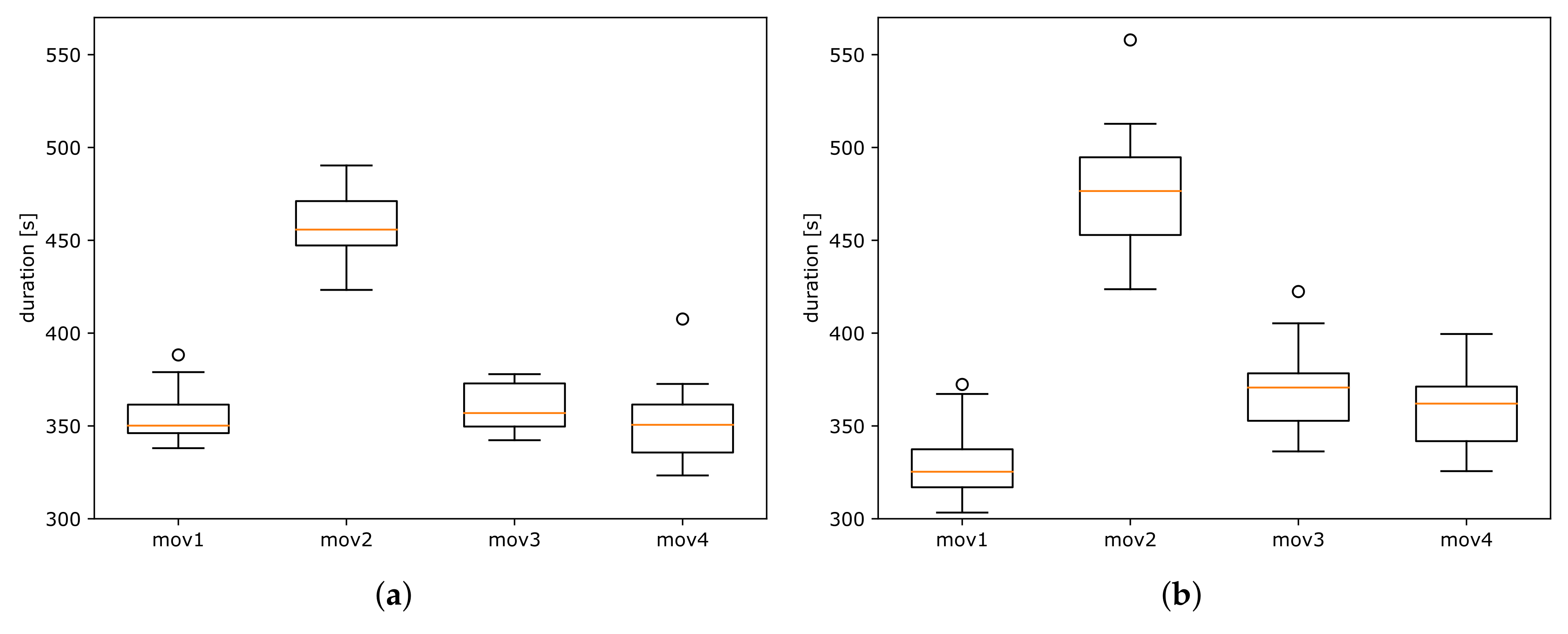
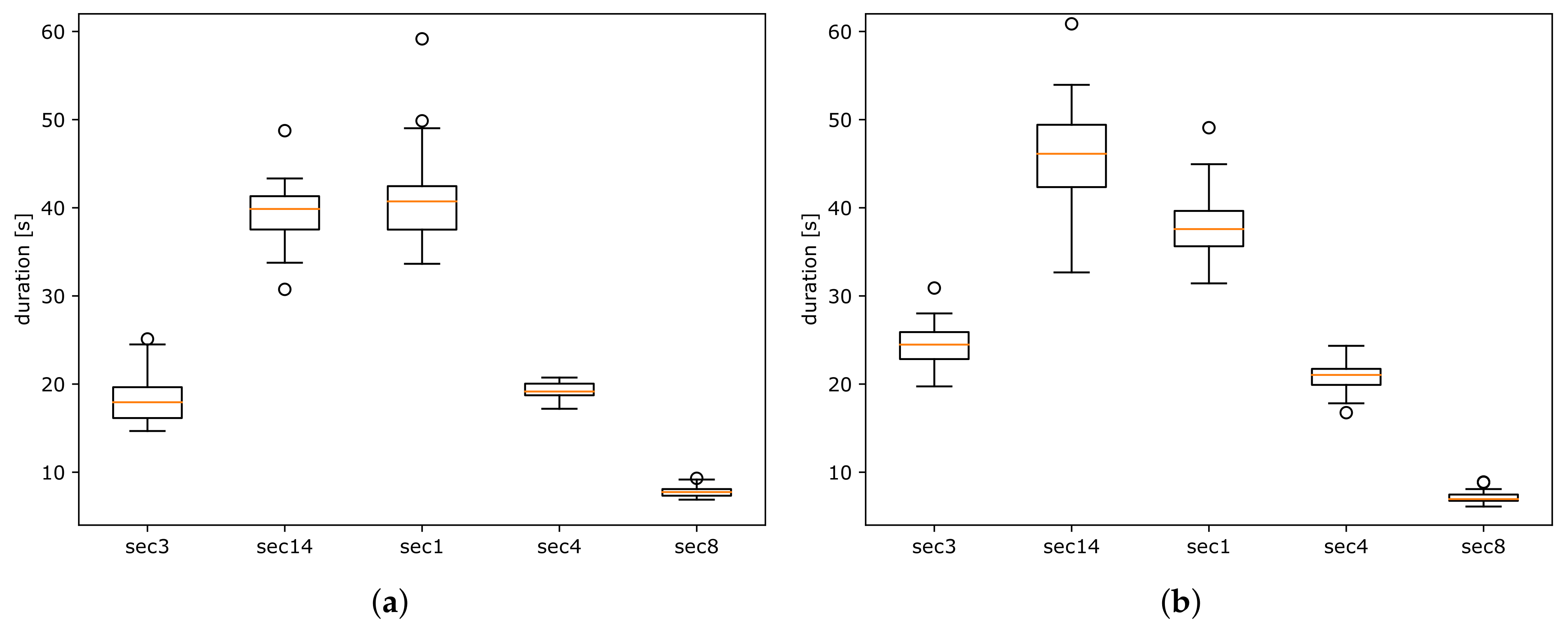
All features might describe specific qualities of a given performance, but in this paper, we chose only robust timing information for the origin classification. The duration of small time segments (such as measures) provides information about musical expressiveness and interpretive differences. If we choose larger segments, such as the duration of whole movements or sections composed of many measures, the significant differences and the accuracy of the potential classification decrease (compare
Table 13 with
Table 8 or
Table 10). The exception is Janáček’s String Quartet No. 2, where we achieved F-measure = 0.87. Converting the duration to tempo values does not affect the classifier; it might only serve as a more intuitive visualization. We chose measures for a few reasons: firstly, measures are well-defined by the corresponding score; secondly, they are easier to annotate manually than, for example, beats; and thirdly, they can be used to segment recordings to sections or other logical structures (while ignoring the metrical structure of a given composition).
In
Section 2.4, we show that automated downbeat tracking systems are not yet efficient for expressive string quartet music. Thus, the synchronization strategy (with available manual annotation) remains the preferable option. Feature selection explained in
Section 3.2 helped the chosen classifier achieve higher accuracy while ranking the importance of features for a given task. This information can be further used for music analysis and a detailed comparison of differences. Using general structures such as measures has one more advantage—it allows us to generalize the classification pipeline to arbitrary music compositions, instruments, and genres.
The limitation of this study is the number of interpretations for given compositions. We collected a large dataset of string quartet recordings, but only a portion was used (see
Section 2.3) due to the different music structures. To balance the data, we stratified the training and test subsets in each classification run, so there was always the same number of items in both classes. Considering compositions such as Janáček’s String Quartet No. 2, Dvořák’s String Quartet No. 13, or Smetana’s String Quartet No. 1, the classifier provides promising results, confirming the original idea that proposed classes (Czech and non-Czech interpretations) are distinguishable (see
Table 13). However, if we use random labels, binary classification based on the duration of specific measures (given by the composition and all available interpretations) already provides relatively high accuracy in some cases. This is expected, as the mRMR method chooses 10 relevant features that distinguish these classes the most. If we do not implement a feature selection method, the classifier cannot be trained using the proposed strategy. The classification accuracy increases overall when we use the CZ and non-CZ labels.
This study shows that origin-based differences in interpretations exist and are measurable. However, the proposed machine learning pipeline cannot be universally used—the reference measure positions are always needed for at least one recording of a given composition, and we train and test the classifier for each composition separately. Thus far, we cannot classify the origin of arbitrary recording without prior knowledge of the piece and other interpretations. In the future, we would like to test the strategy on string quartets from, for example, Joseph Hayden or Ludwig van Beethoven with Austrian/German labels and provide a more detailed analysis of interpretation differences.
6. Conclusions
In this paper, we investigated the possibilities of string quartet interpretation classification based on performers’ origin. We collected a large dataset of string quartets from Czech composers Dvořák, Janáček, and Smetana. We manually annotated ground-truth measure positions of reference recordings and applied a method of time alignment to transfer measure positions to all target recordings. Furthermore, we used measures to segment recordings into separate sections and split our experiments into three scenarios, each specified by different features. We trained and tested a machine learning classifier to distinguish Czech and non-Czech interpretations of string quartet pieces. We showed that it is possible to train such a classifier. The classifier achieved poor results when feature matrices contained the duration of whole movements, except for Janáček’s String Quartet No. 2 with F-measure = 0.87. Increasing the time resolution of features, from movements to sections and measures, improved the prediction accuracy. For the third scenario, where measure positions were used, we achieved F-measure = 0.99 for Dvořák’s String Quartet No. 13, movements 3 and 4, and up to 0.96 in the case of Janáček’s String Quartet No. 2. Using proposed labels, the accuracy increased compared to the baseline with random labels, which already provided relatively high accuracy. It seems that interpretation-based differences are already distinguishable, in some cases, even in random subsets. In the future, we will experiment with other string quartet composers, use more labels, and further describe and explain the interpretation differences. We plan to experiment even with finer time resolution, such as beats, to train classifiers and identify differences in various interpretations.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




