
Leveraging Adversarial Samples for Enhanced Classification of Malicious and Evasive PDF Files


Abstract
1. Introduction
- 1.
- Building a robust malware classifier by performing the training on a mix of evasive and non-evasive data.
- 2.
- Building a hierarchical system that first classifies if a PDF is evasive or not, and then, checks for malware by forwarding the PDF to a model that deals exclusively with evasive data or another model that deals only with non-evasive data.
- 3.
- Building a multi-label classifier that detects evasion and maliciousness simultaneously and independently instead of relying on two dependent models as in the second approach. This classifier is also trained on a combination of evasive and non-evasive data.
- To the best of our knowledge, this work is the first (1) to apply adversarial retraining for PDF malware classifiers to enhance their robustness against evasion attacks and (2) to develop a standalone model capable of detecting evasion attacks in PDF files with a high accuracy, which lays the foundation for future extensions.
- We proposed two systems that can simultaneously detect evasion and maliciousness in PDF files.
- We generated a large dataset of 500,000 PDF samples with evasive-like signatures and made it publicly available, providing researchers with a valuable resource for building and testing evasion detection systems, as well as enhancing the robustness of malware detection systems.
2. Background and Preliminaries
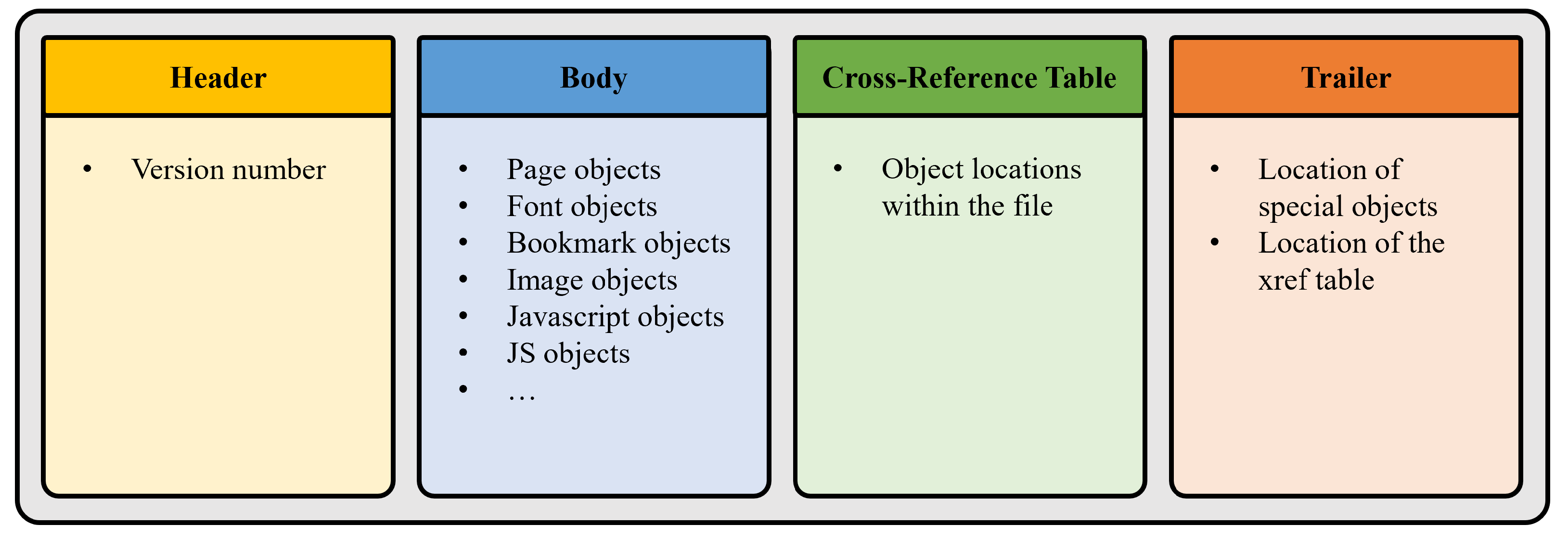
2.1. Portable Document Format
- The Header: it is the first line of a PDF. It specifies the version of the PDF used when the document was produced. The format of the header is given by %PDF-a.b where a.b represents the version.
- The Body: it holds the main content of the PDF file represented as objects, which are the basic building blocks of a PDF, with multiple types depending on the element they hold. Note that any type of object can be obfuscated in the file structure and only de-obfuscated at runtime. This makes obfuscation an option that attackers could exploit to evade classic signature-based malware detection software.
- The cross-reference table (xref table): it lists the byte offsets of all the objects in the main body. The xref table is used to quickly access a certain object without having to search.
- The trailer: it gives the location of the xref table and the root object in the body. The trailer ends with the format %%EOF, which marks the end of the document as well.
2.2. PDF to Deliver Malware
2.3. PDF Evasion Attacks
- (a)
- EvadeML [16]: this is an evasion technique that allows object insertion, deletion, and swapping. It is stronger than other realizable attacks in the literature, which normally just permit insertion to ensure that malicious functionality is kept. This technique assumes that the adversary has black-box access to the classifier, and can only obtain the classification scores of PDF files provided as input. This technique uses genetic programming to automatically find instances that can evade the classifier while maintaining the malicious behavior, and all of this by adding, removing, and swapping objects.
- (b)
- Mimicry [18]: this attack presupposes that an attacker is fully aware of all the features that the target classifier is using. A malicious PDF file is then modified as part of the mimicking attack to closely resemble a selected, benign PDF. Mimicry can be applied easily and without the use of a specific classification model.
- (c)
- Reverse Mimicry [17]: this attack assumes that an attacker has zero knowledge (knows nothing) about the malware classifier. The goal of this attack is to create malware samples that have a structure similar to benign ones (which we call targets). To reduce the structural difference between the produced samples and targets, the primary idea is to inject malicious payloads into target benign files.
- (d)
- Parser Confusion Attack [19]: this attack simply consists of obfuscating malicious Javascript code inside a PDF. This way, PDF malware classifiers would be evaded and the malicious behavior would still be executed when the files are opened.
2.4. Related Work
- Perform adversarial learning instead of active learning for PDF malware detectors, where we train the malware classifier on data containing evasive and non-evasive samples.
- Build standalone models that detect evasion instead of relying on the certainty of the malware classifier’s predictions.
3. Materials and Methods
3.1. Methodology
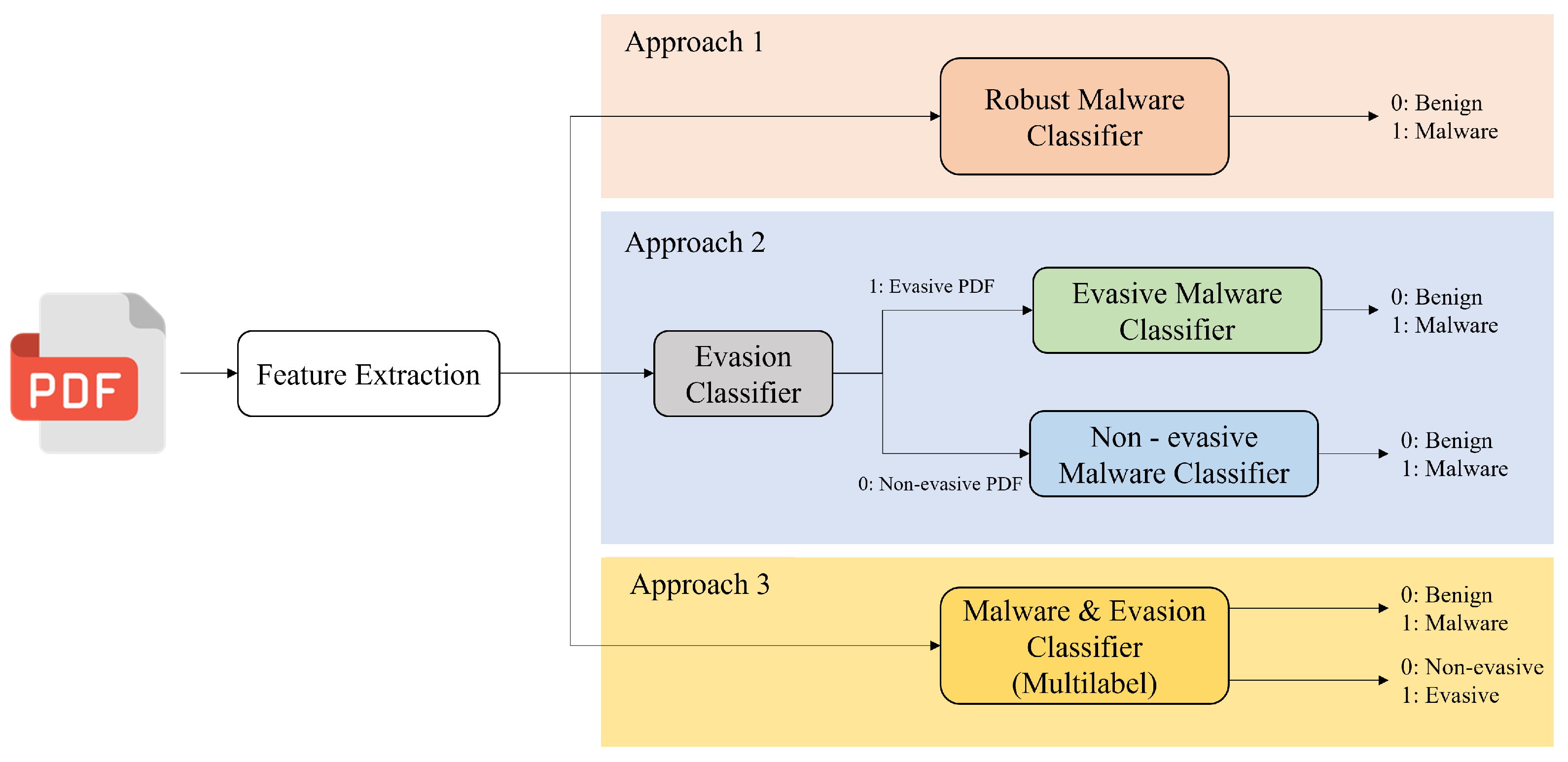
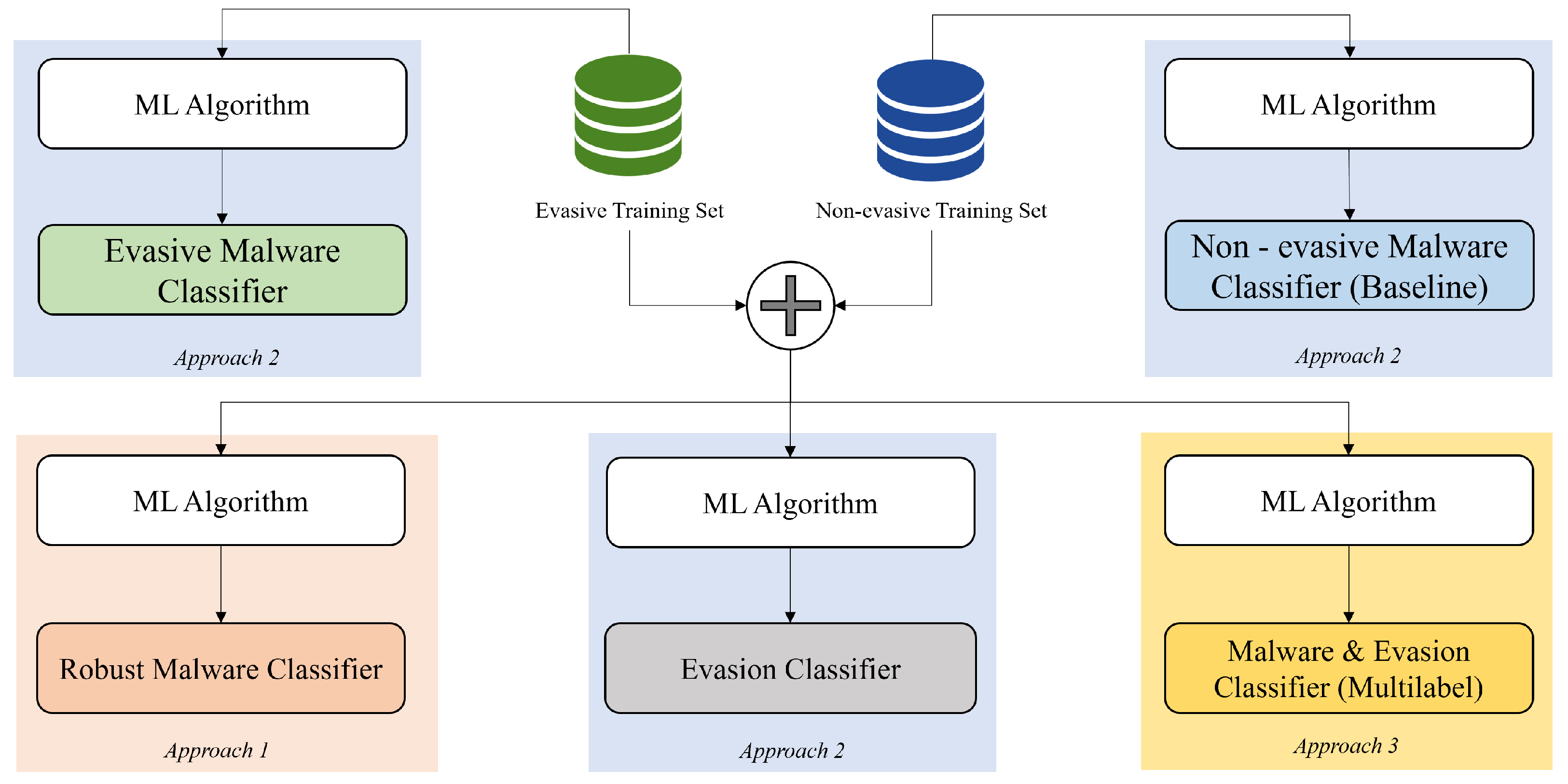
3.1.1. Approach 1
3.1.2. Approach 2
- 1.
- Evasion Classifier: This model is trained on a dataset containing evasive and non-evasive samples. The goal is to detect whether a PDF is evasive or not by analyzing its features.
- 2.
- Evasive Malware Classifier: This model is trained on the evasive dataset solely, and, therefore, it expects to receive an evasive sample to classify whether it carries malware or not.
- 3.
- Non-evasive Malware Classifier: This model is trained using only the non-evasive dataset and it expects to receive a non-evasive sample to classify whether it carries malware or not.
3.1.3. Approach 3
3.2. Experimental Setup
3.2.1. Dataset
- 1.
- The Contagio malware dump dataset [20]
- 2.
- Public datasets that were the result of different evasion attacks in previous studies: evadeML [16], mimicry [18], reverse mimicry [17], and the parser confusion attack [19]. The common about these datasets is that they only contain evasive samples that are malicious. Even though some of these datasets targeted the evasion of a particular classifier (like evadeML for instance), these datasets can conserve their evasive characteristics when dealing with other models because of the evasion transferability discussed in Section 2.3.
- EvasivePDFMal2022: a real evasive dataset that was used to test the robustness of a malware detection model in [9]. This dataset is not focused on a specific kind of attack like the previous ones. It contains real samples that hold an evasive signature. Moreover, the difference about this dataset is that it contains some samples that are evasive, yet benign, which means that these benign files will trick a classifier into considering them malicious. The kind of attack used to create such samples is not provided by the authors, but such attacks can increase the false positive rate of a malware detection system, which makes it less reliable in practice.
3.2.2. Machine Learning Models
4. Results and Discussion
4.1. Training and Validation Experiments
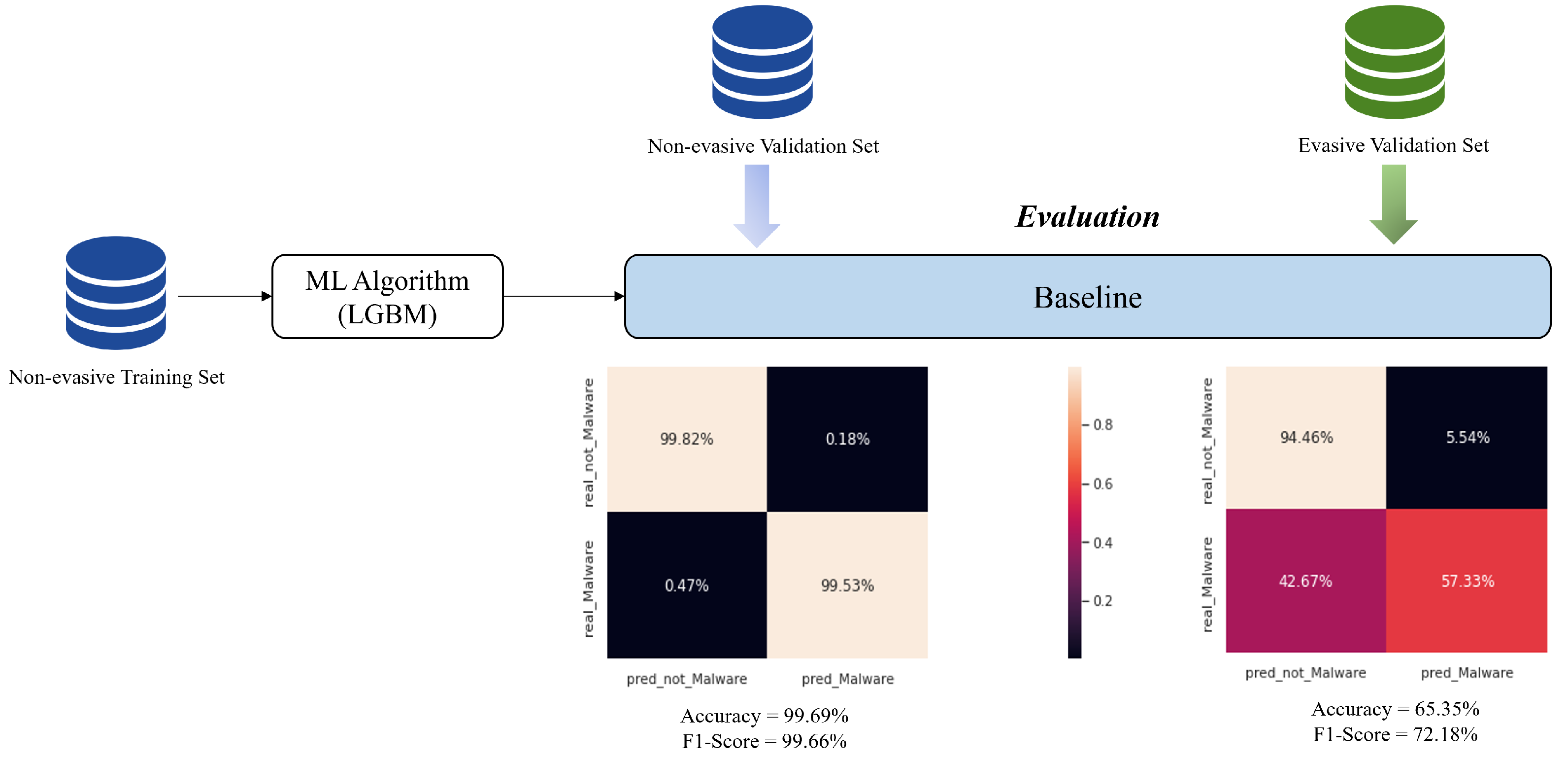
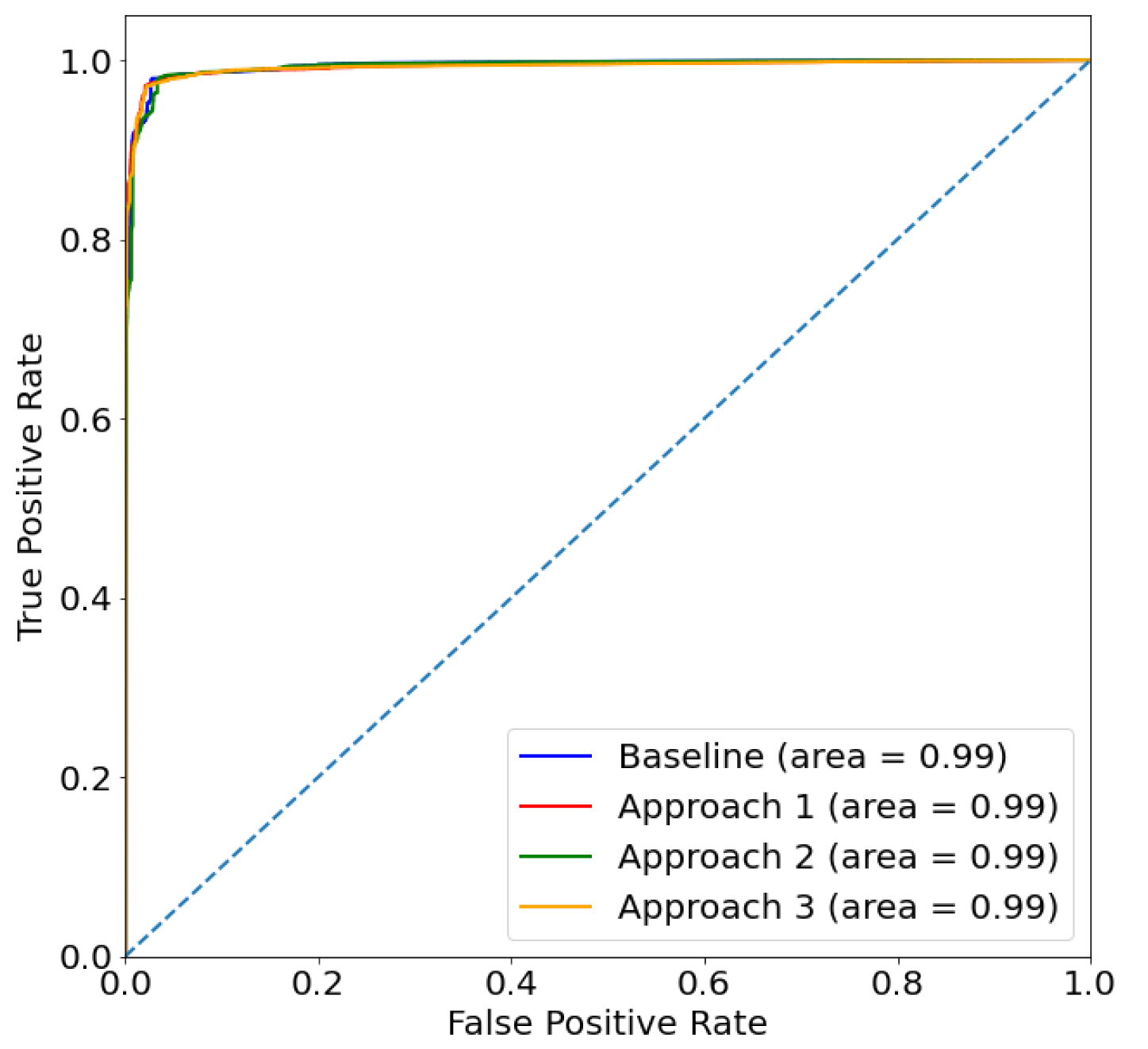
4.1.1. Experiment 0: Illustrating the Problem and Establishing a Baseline
4.1.2. Experiment 1
4.1.3. Experiment 2
- 1.
- Evasion Classifier: The goal of this classifier is to detect whether a PDF sample is evasive or not. Thus, this classifier would be trained on a mix of evasive and non-evasive data. To select a suitable model that can detect evasion, we test multiple algorithms. As an initial step, we keep their default hyperparameters as set by the sci-kit learn python’s library. We train the models on the mix of evasive and non-evasive training sets and then evaluate each of them on the mix of evasive and non-evasive validation sets. The results are summarized in Table 4.We can see that not all models perform very well on this data, and this is expected, because detecting evasion is not an easy task with the limited features we have, and this is what explains the low performance of simple models and the good performance of the more powerful models (Random Forest, AdaBoost, and LightGBM) that are based on ensemble techniques. From the results, we can see that the most promising models to detect evasion are the Random Forest Classifier and the LightGBM. We fine-tune both and we achieve the best performance (accuracy = 96.84%, TNR = 97.97%, TPR = 95.69%, and f1-score = 96.76%) using the LightGBM algorithm with the set of hyperparameters as described in the Experimental Setup section.
- 2.
- Evasive Malware Classifier: We trained the same baseline architecture on the evasive training set only. We evaluated this model on the evasive validation set, and the results we obtained are: accuracy = 99.45%, TNR = 99.31%, TPR = 99.49%, and f1-score = 99.65%.
- 3.
- Non-evasive Malware Classifier: Here we simply used the baseline that has been trained and evaluated on the non-evasive training set and the non-evasive validation set, respectively.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Logistic Regression | SVM (RBF) | SVM (Poly 1) | SVM (Poly 2) | Naïve Bayes | Random Forest | AdaBoost | LightGBM | |
|---|---|---|---|---|---|---|---|---|
| Accuracy | 76.53% | 80.59% | 77.12% | 78.75% | 73.97% | 96.28% | 84.48% | 95.19% |
| TNR | 93.34% | 98.18% | 97.70% | 96.88% | 83.10% | 97.82% | 90.32% | 97.82% |
| FPR | 6.66% | 1.82% | 2.30% | 3.12% | 16.90% | 2.18% | 7.99% | 2.18% |
| FNR | 40.78% | 37.51% | 44.07% | 39.91% | 35.42% | 5.31% | 23.28% | 7.53% |
| TPR | 59.22% | 62.49% | 55.93% | 60.09% | 64.58% | 94.69% | 76.72% | 92.47% |
| F1 Score | 71.31% | 76.04% | 70.67% | 73.60% | 70.98% | 96.17% | 82.86% | 94.98% |
4.1.4. Experiment 3
4.2. Testing Experiments
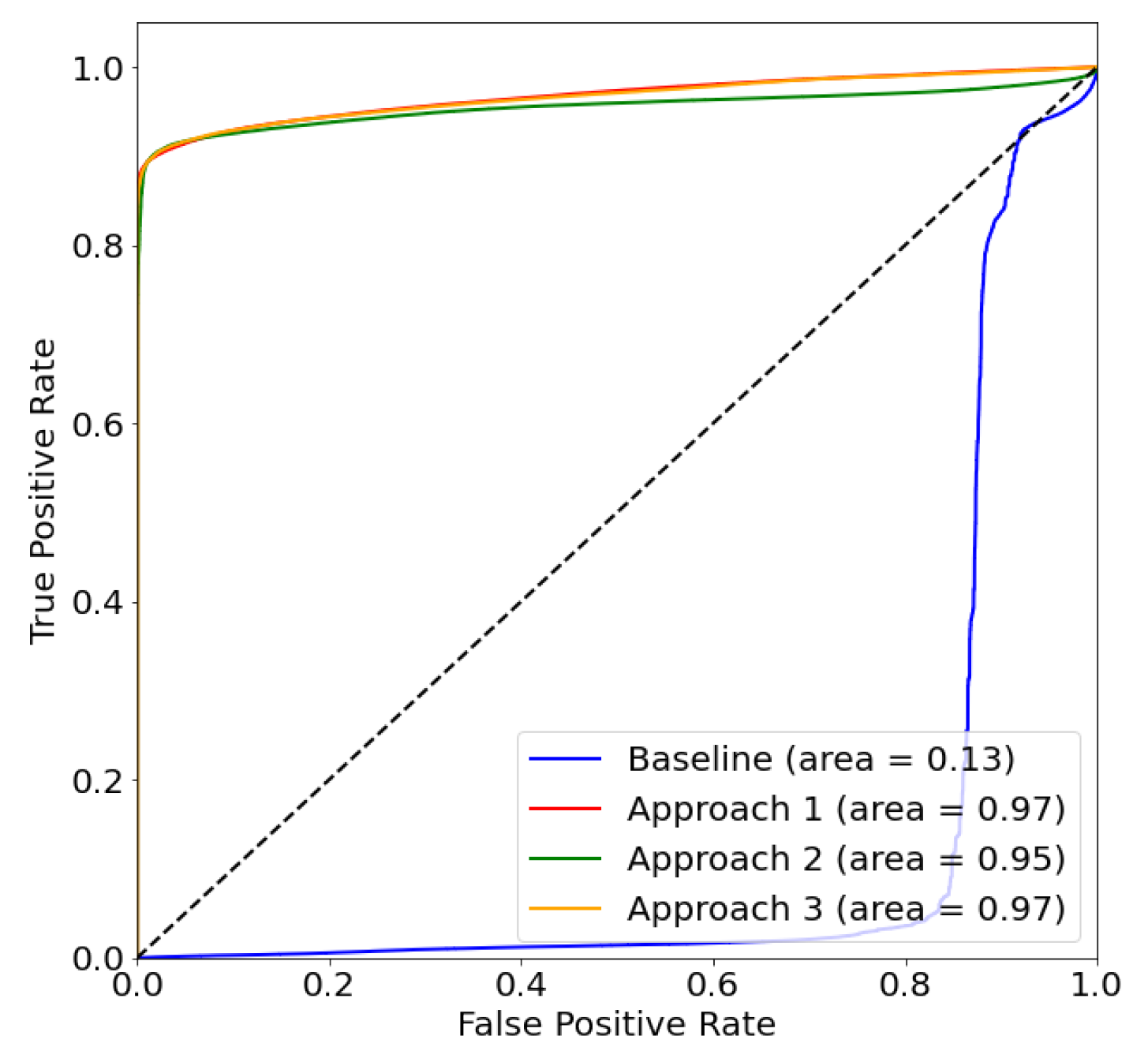
4.2.1. Experiment 1: Testing on a Real Dataset
4.2.2. Experiment 2: Generating an Evasive Dataset
- We feed all the evasive data collected to the baseline model. This classifier will correctly classify a portion of this data and will wrongly classify the other.
- We select the misclassified samples, and we consider them the most evasive samples.
- We used this model to generate 500,000 samples of evasive data out of which 450,000 samples are malicious and 50,000 samples are benign.
- To verify that the samples provided have a real aspect, we used TensorFlow Data Validator to make sure that the generated samples adhere to the original evasive dataset schema.
4.2.3. Experiment 3: Testing on the Generated Evasive Dataset
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kaur, J.; Ramkumar, K.R. The recent trends in cyber security: A review. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 5766–5781. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Q. A comprehensive review study of cyber-attacks and cyber security; Emerging trends and recent developments. Energy Rep. 2021, 7, 8176–8186. [Google Scholar] [CrossRef]
- Aslan, O.A.; Samet, R. A Comprehensive Review on Malware Detection Approaches. IEEE Access 2020, 8, 6249–6271. [Google Scholar] [CrossRef]
- Blonce, A.; Filiol, E.; Frayssignes, L. Portable Document Format (PDF) Security Analysis and Malware Threats. In Proceedings of the Europe BlackHat 2008 Conference, Amsterdam, The Netherlands, 24–28 March 2008; p. 20. [Google Scholar]
- Fleury, N.; Dubrunquez, T.; Alouani, I. PDF-Malware: An Overview on Threats, Detection and Evasion Attacks. arXiv 2021, arXiv:2107.12873. [Google Scholar]
- Iwamoto, M.; Oshima, S.; Nakashima, T. A Study of Malicious PDF Detection Technique. In Proceedings of the 2016 10th International Conference on Complex, Intelligent, and Software Intensive Systems (CISIS), Fukuoka, Japan, 6–8 July 2016; pp. 197–203. [Google Scholar] [CrossRef]
- Maiorca, D.; Biggio, B. Digital Investigation of PDF Files: Unveiling Traces of Embedded Malware. IEEE Secur. Priv. 2019, 17, 63–71. [Google Scholar] [CrossRef]
- Torres, J.; De los Santos, S. Malicious PDF Documents Detection using Machine Learning Techniques—A Practical Approach with Cloud Computing Applications. In Proceedings of the 4th International Conference on Information Systems Security and Privacy, Funchal, Portugal, 22–24 January 2018; SCITEPRESS—Science and Technology Publications: Funchal, Madeira, Portugal, 2018; pp. 337–344. [Google Scholar] [CrossRef]
- Issakhani, M.; Victor, P.; Tekeoglu, A.; Lashkari, A. PDF Malware Detection based on Stacking Learning. In Proceedings of the 8th International Conference on Information Systems Security and Privacy, Online, 9–11 February 2022; pp. 562–570. [Google Scholar] [CrossRef]
- Maiorca, D.; Biggio, B.; Giacinto, G. Towards Adversarial Malware Detection: Lessons Learned from PDF-based Attacks. ACM Comput. Surv. 2020, 52, 1–36. [Google Scholar] [CrossRef]
- Biggio, B.; Corona, I.; Maiorca, D.; Nelson, B.; Šrndić, N.; Laskov, P.; Giacinto, G.; Roli, F. Evasion Attacks against Machine Learning at Test Time. In Proceedings of the Machine Learning and Knowledge Discovery in Databases, Prague, Czech Republic, 23–27 September 2013; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 387–402. [Google Scholar] [CrossRef]
- Zhang, J. MLPdf: An Effective Machine Learning Based Approach for PDF Malware Detection. arXiv 2018, arXiv:1808.06991. [Google Scholar]
- Zhang, J. Machine Learning With Feature Selection Using Principal Component Analysis for Malware Detection: A Case Study. arXiv 2019, arXiv:1902.03639. [Google Scholar]
- Khorshidpour, Z.; Hashemi, S.; Hamzeh, A. Learning a Secure Classifier against Evasion Attack. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 295–302. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Shi, Z.; Zhang, R.; Xue, J.; Wang, Z. Boosting training for PDF malware classifier via active learning. Int. J. Intell. Syst. 2021, 37, 2803–2821. [Google Scholar] [CrossRef]
- Xu, W.; Qi, Y.; Evans, D. Automatically Evading Classifiers. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 21–24 February 2016; p. 15. [Google Scholar] [CrossRef]
- Maiorca, D.; Corona, I.; Giacinto, G. Looking at the bag is not enough to find the bomb: An evasion of structural methods for malicious PDF files detection. In Proceedings of the 8th ACM SIGSAC Symposium on Information, Computer and Communications Security, Hangzhou, China, 8–10 May 2013; pp. 119–130. [Google Scholar] [CrossRef]
- Šrndić, N.; Laskov, P. Practical Evasion of a Learning-Based Classifier: A Case Study. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 18–21 May 2014; pp. 197–211. [Google Scholar] [CrossRef]
- Carmony, C.; Zhang, M.; Hu, X.; Vasisht Bhaskar, A.; Yin, H. Extract Me If You Can: Abusing PDF Parsers in Malware Detectors. In Proceedings of the 2016 Network and Distributed System Security Symposium, San Diego, CA, USA, 21–24 February 2016. [Google Scholar] [CrossRef]
- Mila. 16,800 Clean and 11,960 Malicious Files for Signature Testing and Research. Contagio Dataset. 2013. Available online: http://contagiodump.blogspot.com/2013/03/16800-clean-and-11960-malicious-files.html (accessed on 18 April 2022).
- VirusTotal. Virus Total Home Page. Available online: https://www.virustotal.com/gui/home/upload (accessed on 23 April 2022).
- Smutz, C.; Stavrou, A. Malicious PDF detection using metadata and structural features. In Proceedings of the 28th Annual Computer Security Applications Conference—ACSAC ’12, Orlando, FL, USA, 3–7 December 2012; p. 239. [Google Scholar] [CrossRef]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling Tabular data using Conditional GAN. arXiv 2019, arXiv:1907.00503. [Google Scholar]
- Patki, N.; Wedge, R.; Veeramachaneni, K. The Synthetic Data Vault. In Proceedings of the 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016; pp. 399–410. [Google Scholar] [CrossRef]
- ISO:32000-1:2008; Document Management—Portable Document Format—Part 1: PDF 1.7. ISO: Geneva, Switzerland, 2008. Available online: https://www.iso.org/cms/render/live/en/sites/isoorg/contents/data/standard/05/15/51502.html (accessed on 20 April 2022).
- Tzermias, Z.; Sykiotakis, G.; Polychronakis, M.; Markatos, E.P. Combining static and dynamic analysis for the detection of malicious documents. In Proceedings of the Fourth European Workshop on System Security, Salzburg, Austria, 11 April 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Adobe. Adobe® PDF (Portable Document Format) 1.7 Reference. 2006.
- Corona, I.; Maiorca, D.; Ariu, D.; Giacinto, G. Lux0R: Detection of Malicious PDF-embedded JavaScript code through Discriminant Analysis of API References. In Proceedings of the 2014 Workshop on Artificial Intelligent and Security Workshop, Scottsdale, AZ, USA, 7 November 2014; pp. 47–57. [Google Scholar] [CrossRef]
- Munson, M.; Cross, J. Deep PDF Parsing to Extract Features for Detecting Embedded Malware; OSTI: Oak Ridge, TN, USA, 2011. [Google Scholar] [CrossRef]
- Stevens, D. Malicious PDF Documents Explained. IEEE Secur. Priv. 2011, 9, 80–82. [Google Scholar] [CrossRef]
- Croce, F.; Hein, M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. arXiv 2020, arXiv:2003.01690. [Google Scholar]
- Brendel, W.; Rauber, J.; Bethge, M. Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models. arXiv 2018, arXiv:1712.04248. [Google Scholar]
- Brendel, W.; Rauber, J.; Kümmerer, M.; Ustyuzhaninov, I.; Bethge, M. Accurate, reliable and fast robustness evaluation. arXiv 2019, arXiv:1907.01003. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. DeepFool: A simple and accurate method to fool deep neural networks. arXiv 2016, arXiv:1511.04599. [Google Scholar]
- Chen, P.Y.; Sharma, Y.; Zhang, H.; Yi, J.; Hsieh, C.J. EAD: Elastic-Net Attacks to Deep Neural Networks via Adversarial Examples. arXiv 2018, arXiv:1709.04114. [Google Scholar] [CrossRef]
- Chen, J.; Jordan, M.I.; Wainwright, M.J. HopSkipJumpAttack: A Query-Efficient Decision-Based Attack. arXiv 2020, arXiv:1904.02144. [Google Scholar]
- Shafahi, A.; Najibi, M.; Ghiasi, M.A.; Xu, Z.; Dickerson, J.; Studer, C.; Davis, L.S.; Taylor, G.; Goldstein, T. Adversarial training for free! In Proceedings of the Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a Defense to Adversarial Perturbations Against Deep Neural Networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 582–597. [Google Scholar] [CrossRef]
- Xu, W.; Evans, D.; Qi, Y. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. In Proceedings of the 2018 Network and Distributed System Security Symposium, Internet Society, San Diego, CA, USA, 18–21 February 2018. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Sinha, A.; Wellman, M.P. SoK: Security and Privacy in Machine Learning. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy (EuroS&P), London, UK, 24–26 April 2018; pp. 399–414. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in Machine Learning: From Phenomena to Black-Box Attacks using Adversarial Samples. arXiv 2016, arXiv:1605.07277. [Google Scholar]
- Demontis, A.; Melis, M.; Pintor, M.; Jagielski, M.; Biggio, B.; Oprea, A.; Nita-Rotaru, C.; Roli, F. Why Do Adversarial Attacks Transfer? Explaining Transferability of Evasion and Poisoning Attacks. arXiv 2019, arXiv:1809.02861. [Google Scholar]
- Yusirwan, S.; Prayudi, Y.; Riadi, I. Implementation of Malware Analysis using Static and Dynamic Analysis Method. Int. J. Comput. Appl. 2015, 117, 975–8887. [Google Scholar] [CrossRef]
- Shafiq, M.Z.; Khayam, S.A.; Farooq, M. Embedded Malware Detection Using Markov n-Grams. In Detection of Intrusions and Malware, and Vulnerability Assessment; Zamboni, D., Ed.; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5137, pp. 88–107. [Google Scholar] [CrossRef]
- Smutz, C.; Stavrou, A. When a Tree Falls: Using Diversity in Ensemble Classifiers to Identify Evasion in Malware Detectors. In Proceedings of the 2016 Network and Distributed System Security Symposium, San Diego, CA, USA, 21–24 February 2016. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2015, arXiv:1412.6572. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]






| Evasive Data | Non-Evasive Data | Total | |
|---|---|---|---|
| Malicious | 15,723 | 9624 | 25,347 |
| Benign | 4336 | 11,023 | 15,359 |
| Total | 20,059 | 20,647 | 40,706 |
| Logistic Regression | SVM (RBF) | SVM (Poly 1) | SVM (Poly 2) | Naïve Bayes | Random Forest | AdaBoost | LightGBM | |
|---|---|---|---|---|---|---|---|---|
| Accuracy | 94.43% | 98.74% | 92.32% | 96.03% | 82.81% | 99.66% | 99.32% | 99.32% |
| TNR | 91.97% | 98.96% | 88.30% | 94.74% | 79.14% | 99.95% | 99.55% | 99.55% |
| FPR | 8.03% | 1.04% | 11.70% | 5.26% | 20.86% | 0.05% | 0.45% | 0.45% |
| FNR | 2.75% | 1.51% | 3.06% | 2.49% | 12.99% | 0.68% | 0.94% | 0.94% |
| TPR | 97.25% | 98.49% | 96.94% | 97.51% | 87.01% | 99.32% | 99.06% | 99.06% |
| F1 Score | 94.21% | 98.65% | 91.71% | 95.81% | 82.51% | 99.63% | 99.27% | 99.27% |
| Logistic Regression | SVM (RBF) | SVM (Poly 1) | SVM (Poly 2) | Naïve Bayes | Random Forest | AdaBoost | LightGBM | |
|---|---|---|---|---|---|---|---|---|
| Accuracy | 37.73% | 44.99% | 38.53% | 39.15% | 34.47% | 39.66% | 39.96% | 66.28% |
| TNR | 80.62% | 91.81% | 81.55% | 87.20% | 88.70% | 97.00% | 94.58% | 93.19% |
| FPR | 19.38% | 8.19% | 18.45% | 12.80% | 11.30% | 3.00% | 5.42% | 6.81% |
| FNR | 74.09% | 67.92% | 73.32% | 74.09% | 80.48% | 76.15% | 75.10% | 41.14% |
| TPR | 25.91% | 32.08% | 26.68% | 25.91% | 19.52% | 23.85% | 24.90% | 58.86% |
| F1 Score | 39.48% | 47.76% | 40.49% | 40.03% | 31.84% | 38.26% | 39.40% | 73.23% |
| Logistic Regression | SVM (RBF) | SVM (Poly 1) | SVM (Poly 2) | Naïve Bayes | Random Forest | AdaBoost | LightGBM | |
|---|---|---|---|---|---|---|---|---|
| Accuracy | 66.37% | 79.01% | 69.26% | 69.55% | 51.29% | 95.87% | 82.66% | 94.77% |
| Macro-Precision | 85.04% | 97.38% | 90.91% | 89.54% | 77.74% | 98.71% | 95.24% | 98.65% |
| Macro-Recall | 78.57% | 79.71% | 77.02% | 79.17% | 78.91% | 96.95% | 86.32% | 95.90% |
| Macro-F1 Score | 79.82% | 86.67% | 81.13% | 82.13% | 74.09% | 97.82% | 90.34% | 97.24% |
| Task | Accuracy | TNR | FPR | FNR | TPR | F1-Score | |
|---|---|---|---|---|---|---|---|
| Baseline | Malware Pred. | 83.21% | 97.95% | 2.05% | 25.72% | 74.28% | 84.64% |
| Approach 1 | Malware Pred. | 99.48% | 99.48% | 0.52% | 0.51% | 99.49% | 99.59% |
| Approach 2 | Malware Pred. | 99.44% | 99.45% | 0.55% | 0.57% | 99.43% | 99.55% |
| Evasion Pred. | 96.84% | 97.97% | 2.03% | 4.31% | 95.69% | 96.76% | |
| Approach 3 | Malware Pred. | 99.48% | 99.48% | 0.52% | 0.51% | 99.49% | 99.59% |
| Evasion Pred. | 96.60% | 98.21% | 1.79% | 5.06% | 94.94% | 96.49% |
| Accuracy | TNR | FPR | FNR | TPR | F1-Score | |
|---|---|---|---|---|---|---|
| Baseline | 95.51% | 99.26% | 0.74% | 9.02% | 90.98% | 94.84% |
| Approach 1 | 95.73% | 98.90% | 1.10% | 8.09% | 91.91% | 95.13% |
| Approach 2 | 95.32% | 98.84% | 1.16% | 8.93% | 91.07% | 94.64% |
| Approach 3 | 95.26% | 98.94% | 1.06% | 9.19% | 90.81% | 94.55% |
| Accuracy | TNR | FPR | FNR | TPR | F1-Score | |
|---|---|---|---|---|---|---|
| Baseline | 9.69% | 15.18% | 84.82% | 90.92% | 9.08% | 15.32% |
| Approach 1 | 92.37% | 91.93% | 8.07% | 7.58% | 92.42% | 95.61% |
| Approach 2 | 92.36% | 86.46% | 13.54% | 6.99% | 93.01% | 95.63% |
| Approach 3 | 92.49% | 91.52% | 8.48% | 7.40% | 92.60% | 95.68% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trad, F.; Hussein, A.; Chehab, A. Leveraging Adversarial Samples for Enhanced Classification of Malicious and Evasive PDF Files. Appl. Sci. 2023, 13, 3472. https://doi.org/10.3390/app13063472
Trad F, Hussein A, Chehab A. Leveraging Adversarial Samples for Enhanced Classification of Malicious and Evasive PDF Files. Applied Sciences. 2023; 13(6):3472. https://doi.org/10.3390/app13063472
Chicago/Turabian StyleTrad, Fouad, Ali Hussein, and Ali Chehab. 2023. "Leveraging Adversarial Samples for Enhanced Classification of Malicious and Evasive PDF Files" Applied Sciences 13, no. 6: 3472. https://doi.org/10.3390/app13063472
APA StyleTrad, F., Hussein, A., & Chehab, A. (2023). Leveraging Adversarial Samples for Enhanced Classification of Malicious and Evasive PDF Files. Applied Sciences, 13(6), 3472. https://doi.org/10.3390/app13063472