
A Novel Deep Reinforcement Learning Approach to Traffic Signal Control with Connected Vehicles †

 ,
,  , , , and
, , , and
Abstract
1. Introduction
- A new traffic signal control framework using deep reinforcement learning (DRL) is proposed, by incorporating a novel convolutional autoencoder network to reduce the dimensionality of the input traffic states. As a result, a concise representation of comprehensive traffic information is obtained and utilized to facilitate the learning of effective SPaT plans.
- The action space is extended by including both phase duration and cycle length, allowing for increased adaptability to dynamic traffic flow. With the combinatorial action space of multiple phase durations and cycle lengths, our method can effectively handle unbalanced traffic flow with varying traffic volumes.
- The effectiveness and performance of our method are demonstrated by comparing to several existing traffic signal control methods through simulations on the widely used Simulation of Urban MObility (SUMO) traffic simulator.
2. Related Work
2.1. Optimization-Based Approaches
2.2. Data-Driven Approaches
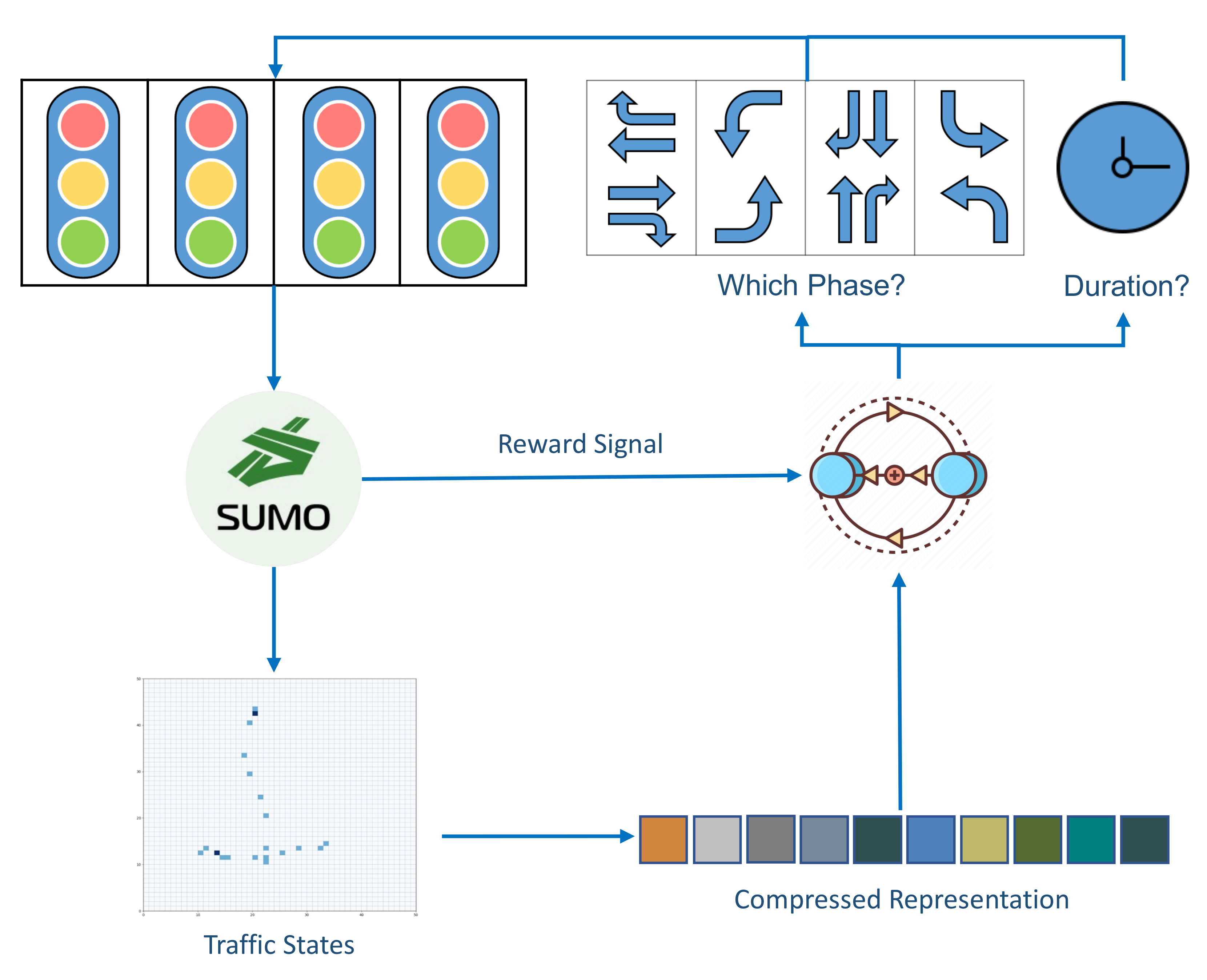
3. Methodology
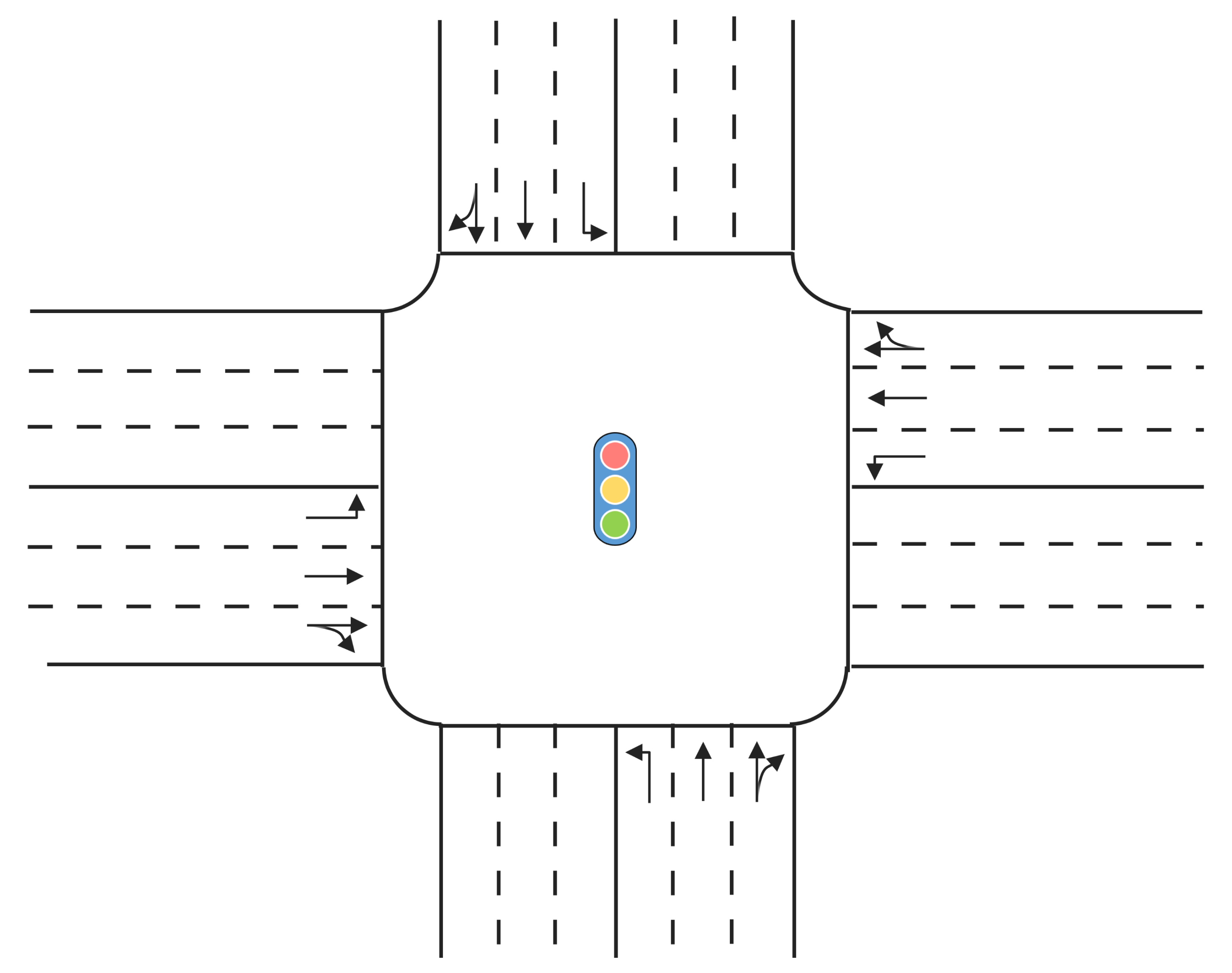
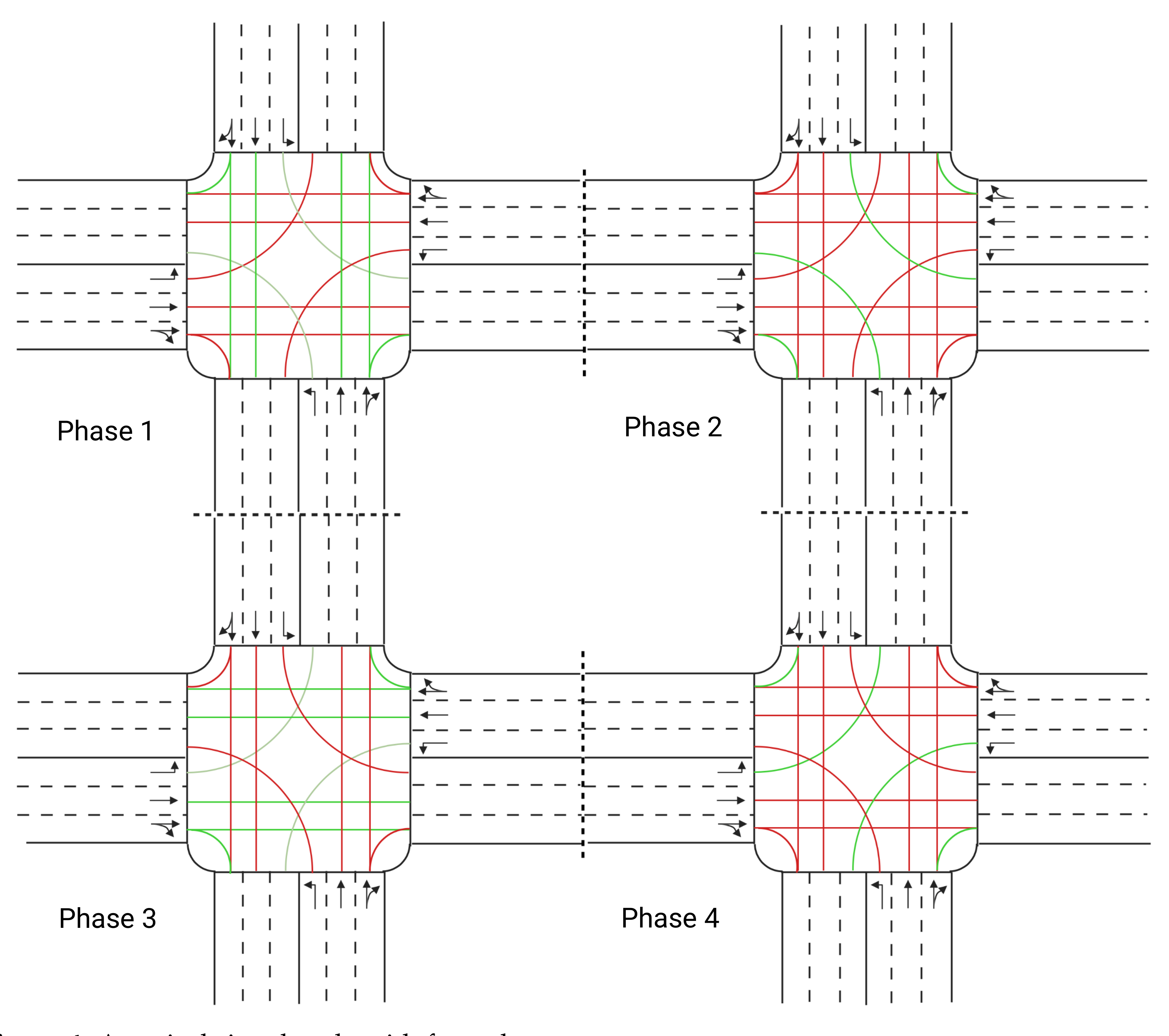
3.1. Scenario and Simulation Environment
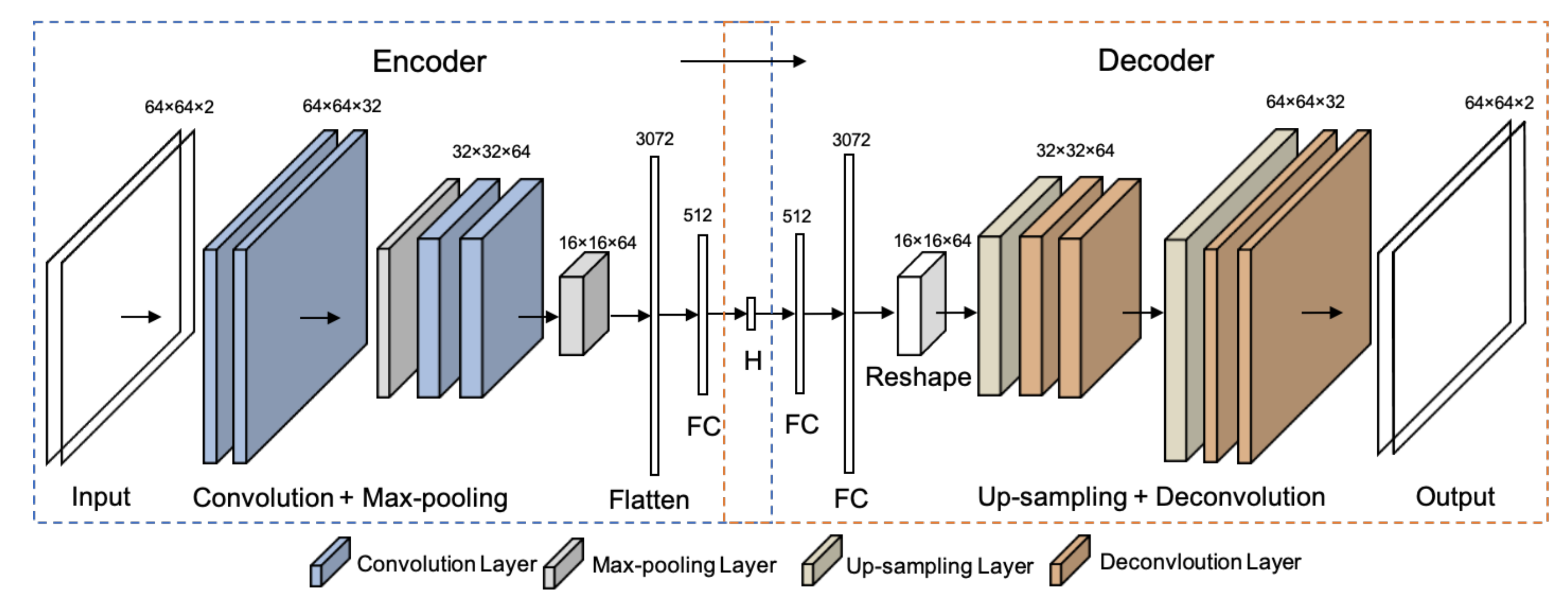
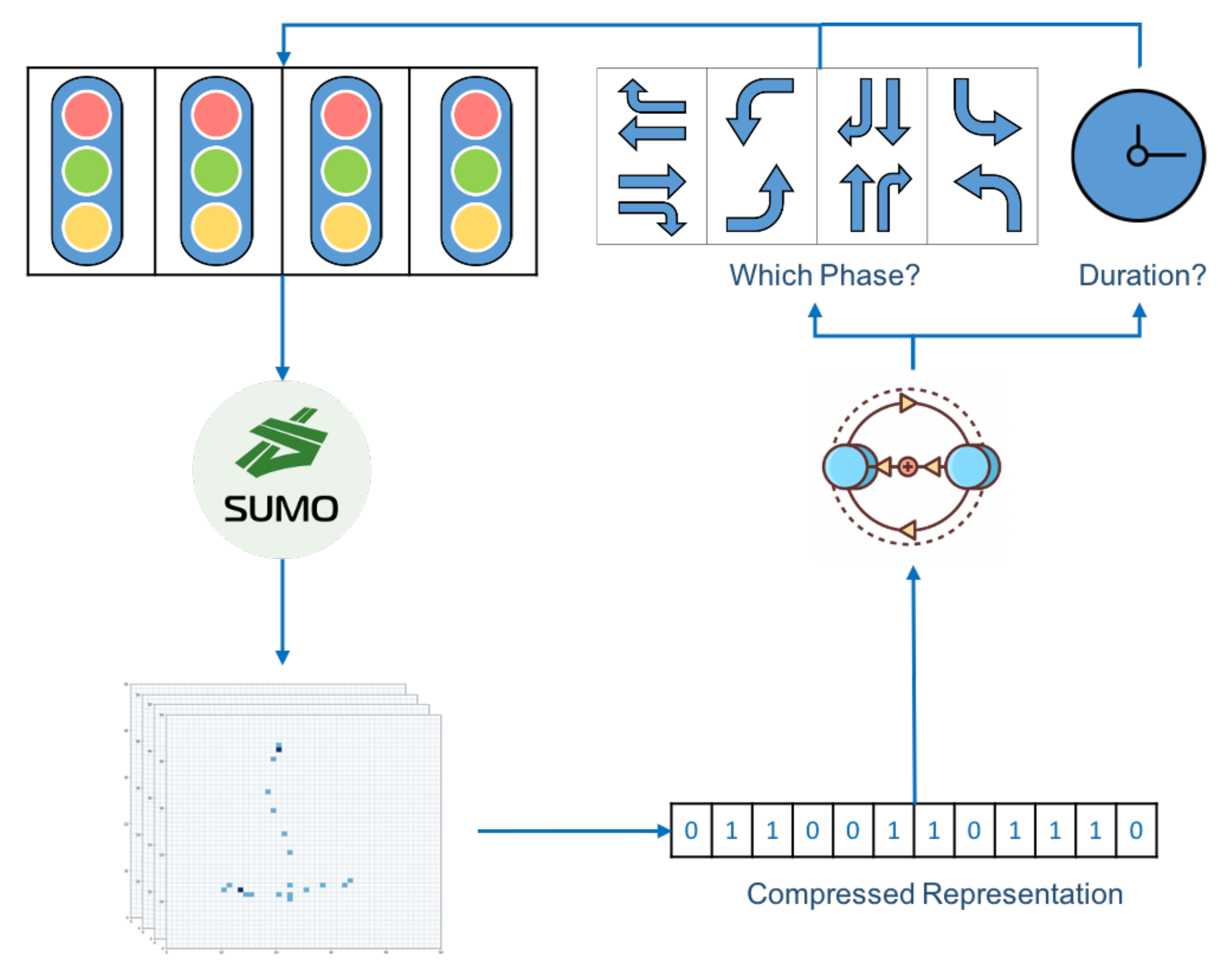
3.2. Compressed Representation of Traffic States
3.3. Deep Reinforcement Learning Structure
| Algorithm 1: Pseudo-code for training algorithm of DRL-based agent |
| Input: mini batch size B, pre-train step , training episode length N, |
| learning rate , greedy , discount factor , target network update |
| rate , target network update frequency K |
| Initialize primary network , target network , replay memory D with |
| capacity M |
| Loop for each episode: |
| Initialize simulator environment |
| Initialize time step |
| Observe current state |
| while time step : |
| With probability select action randomly |
| otherwise select |
| Execute action then observe next state and reward |
| Store in replay memory D |
| if current step t > pre-training step : |
| Sample a minibatch of B experience tuples |
| from D |
| Compute target Q values for each experience: |
| Perform a gradient descent step with loss: |
| Update target network every K steps: |
4. Simulation Results
4.1. Simulation Parameters
4.2. Hyper-Parameter of Deep Reinforcement Learning Network
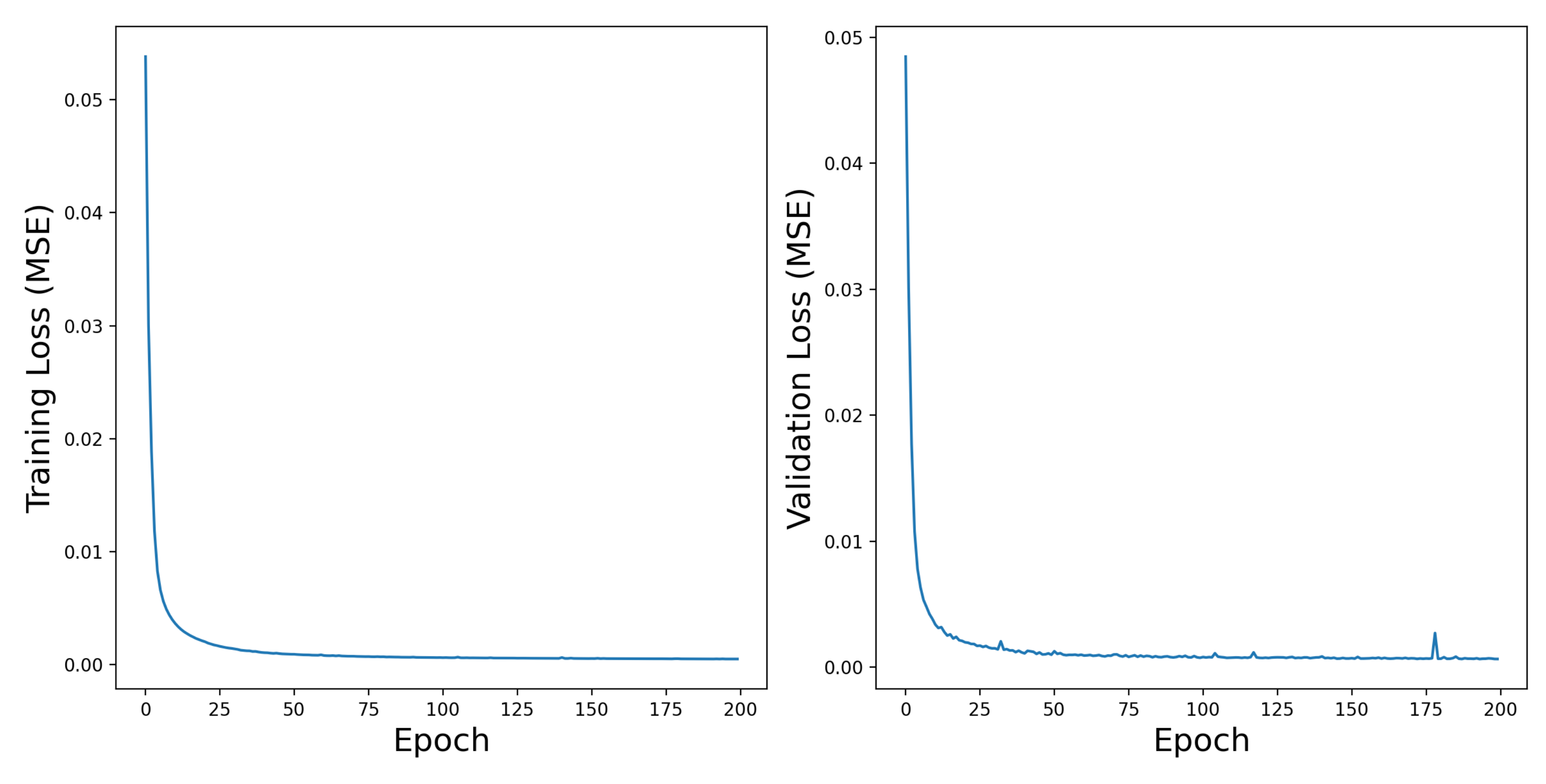
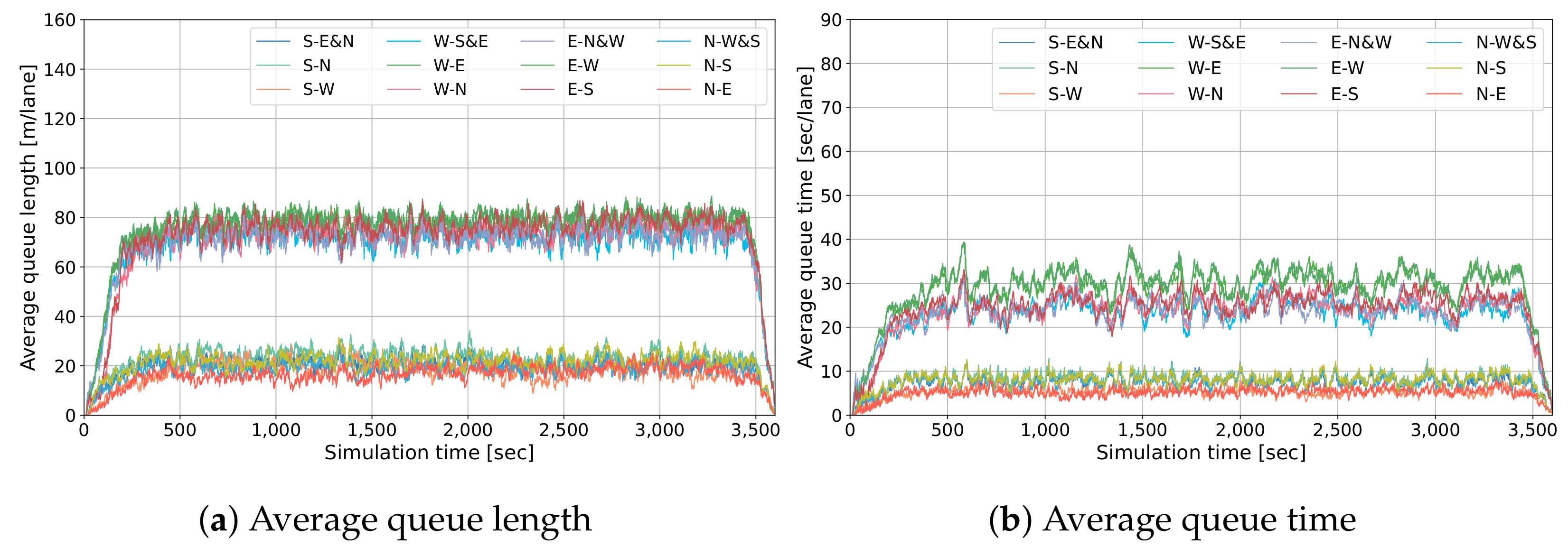
4.3. Convergence of DRL-Based Signal Controller Training
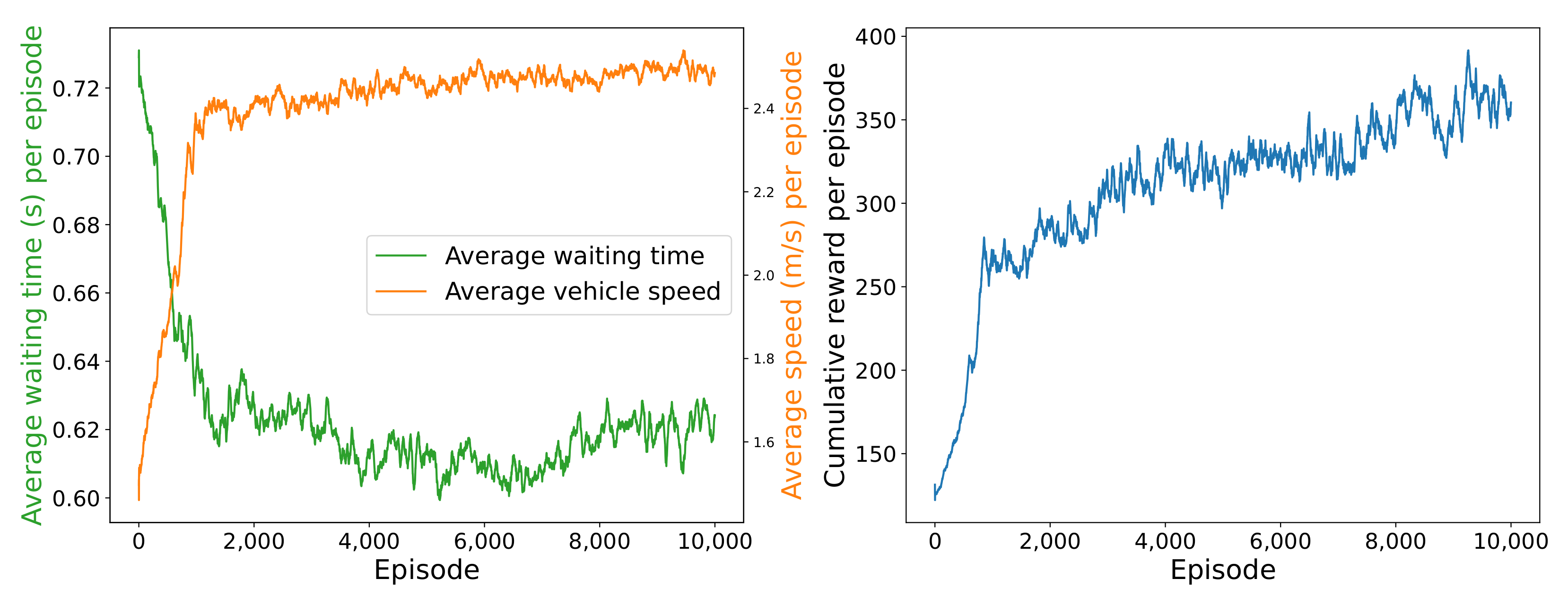
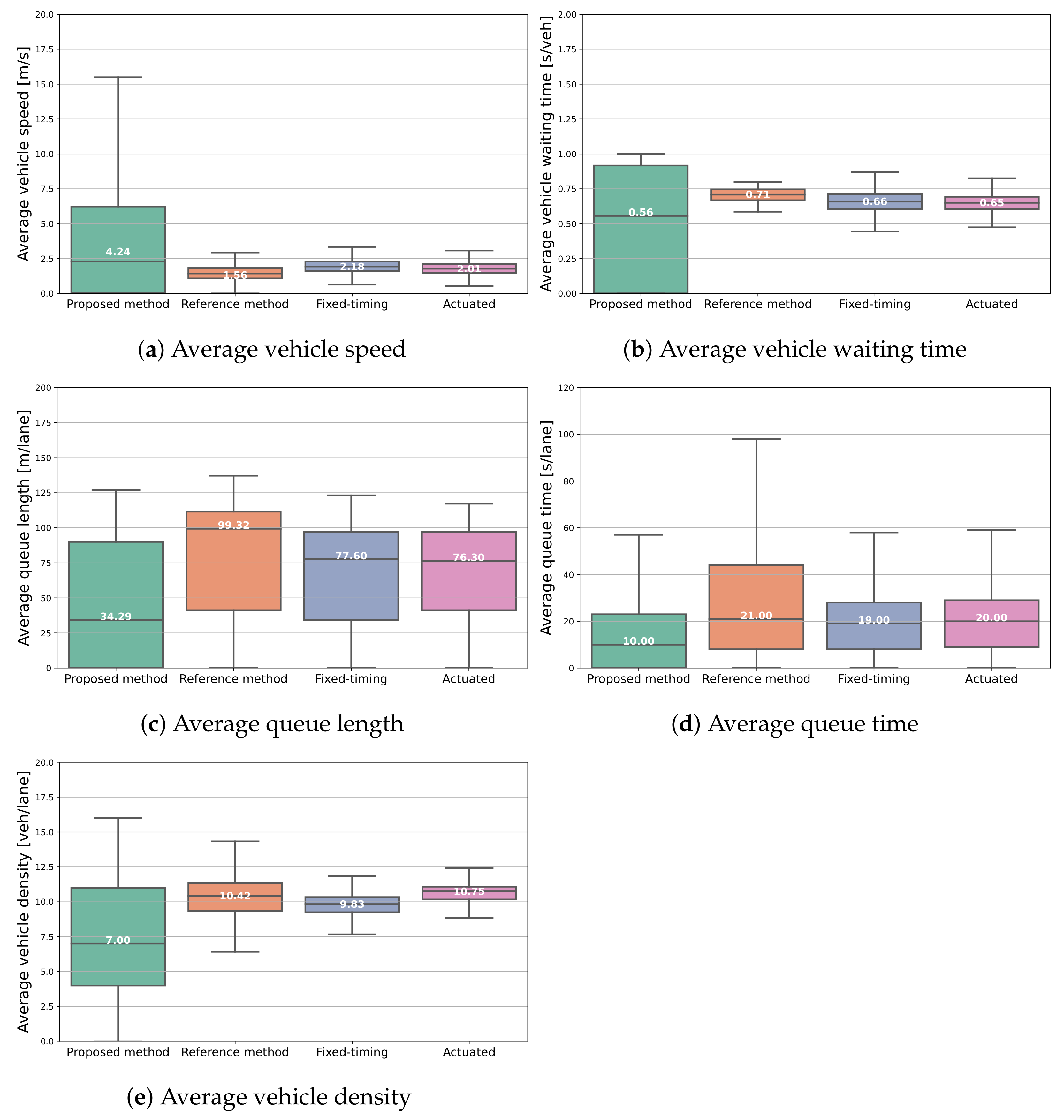
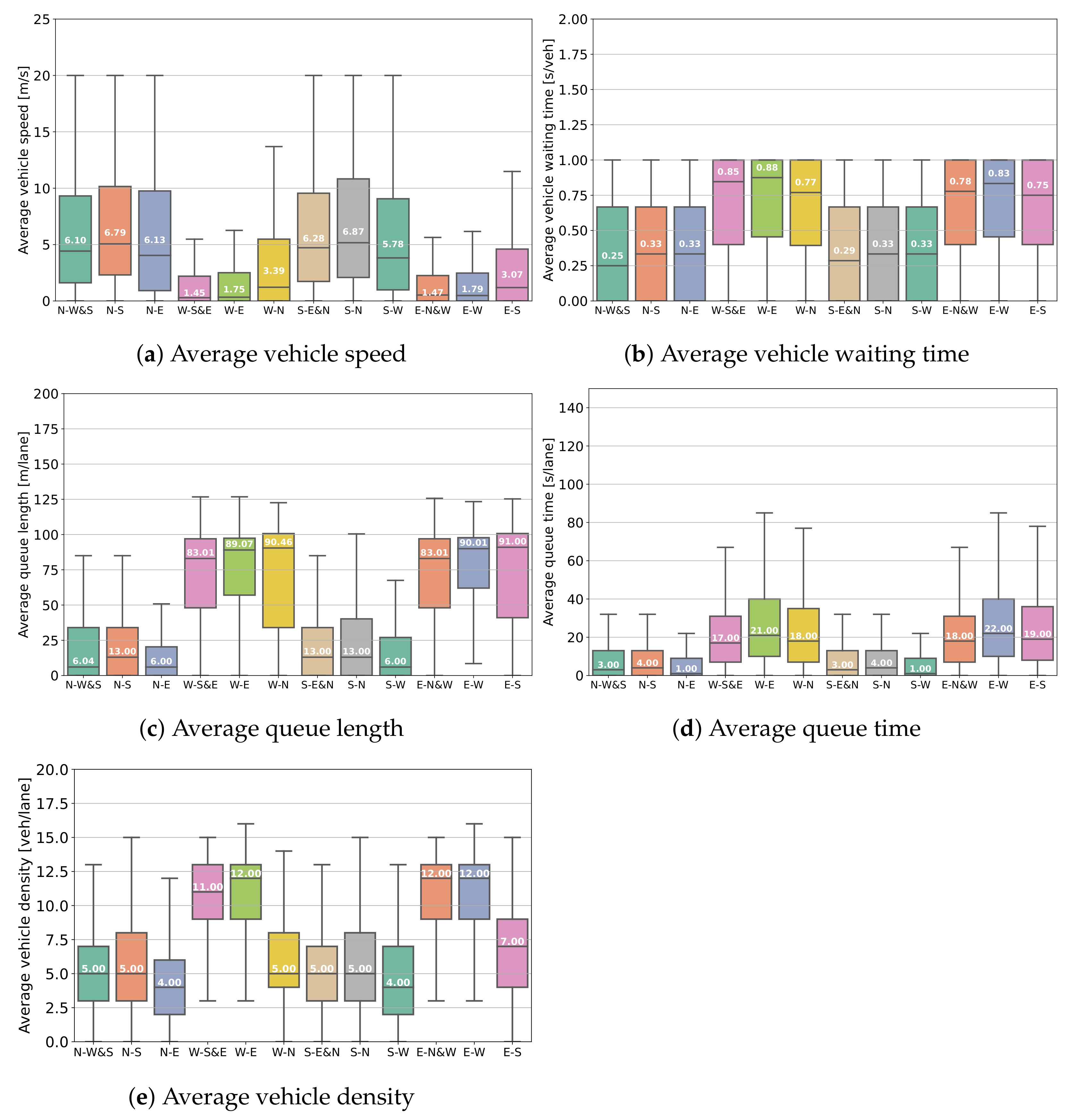
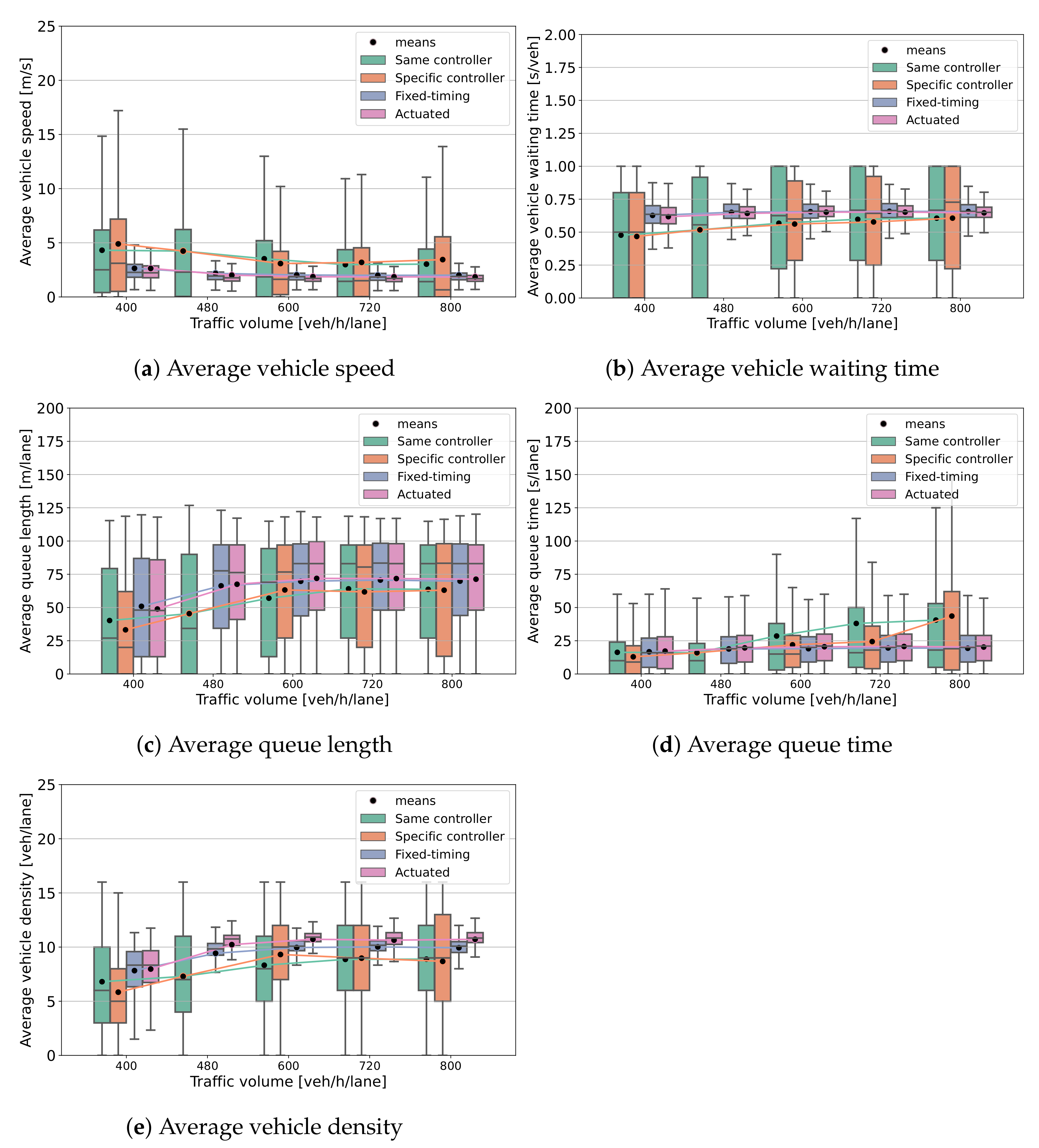
4.4. Comparison with Baselines
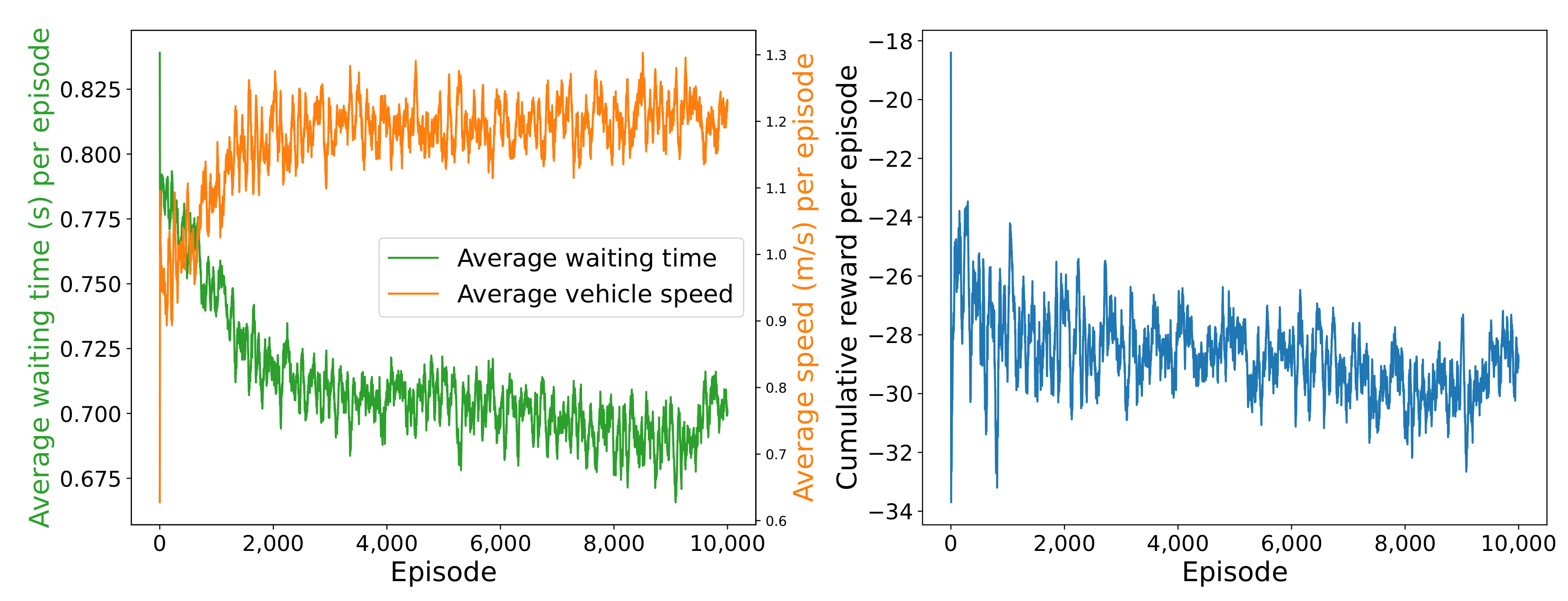
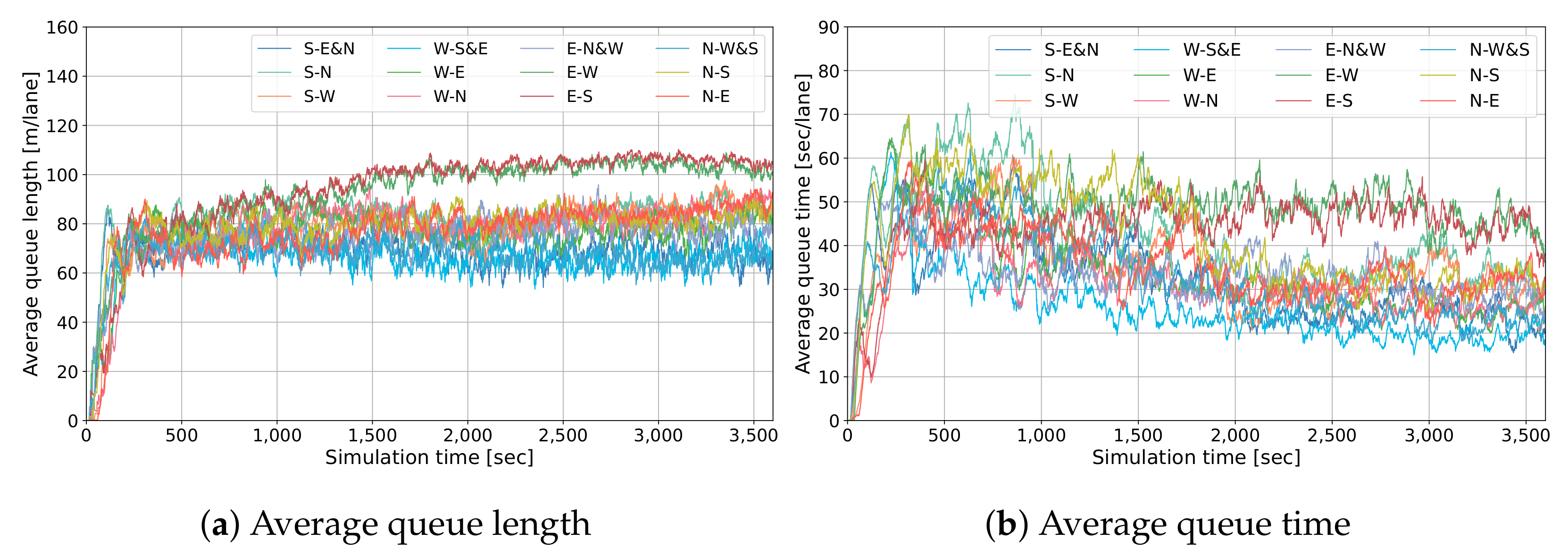
4.5. Robustness Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aziz, H.A.; Wang, H.; Young, S.; Sperling, J.; Beck, J.M. Synthesis Study on Transitions in Signal Infrastructure and Control Algorithms for Connected and Automated Transportation; Technical Report; Oak Ridge National Laboratory Report, ORNL/TM-2017/280; Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2017. [Google Scholar]
- Wünsch, G. Coordination of Traffic Signals in Networks. Ph.D. Thesis, Technische Universität Berlin, Berlin, Germany, 2008. [Google Scholar]
- Al Islam, S.B.; Hajbabaie, A. Distributed coordinated signal timing optimization in connected transportation networks. Transp. Res. Part C Emerg. Technol. 2017, 80, 272–285. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Van Hasselt, H.; Lanctot, M.; De Freitas, N. Dueling network architectures for deep reinforcement learning. arXiv 2015, arXiv:1511.06581. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Guo, Q.; Li, L.; Ban, X.J. Urban traffic signal control with connected and automated vehicles: A survey. Transp. Res. Part C Emerg. Technol. 2019, 101, 313–334. [Google Scholar] [CrossRef]
- He, Q.; Head, K.L.; Ding, J. PAMSCOD: Platoon-based arterial multi-modal signal control with online data. Transp. Res. Part C Emerg. Technol. 2012, 20, 164–184. [Google Scholar] [CrossRef]
- Feng, Y.; Head, K.L.; Khoshmagham, S.; Zamanipour, M. A real-time adaptive signal control in a connected vehicle environment. Transp. Res. Part C Emerg. Technol. 2015, 55, 460–473. [Google Scholar] [CrossRef]
- Zhao, J.; Li, W.; Wang, J.; Ban, X. Dynamic traffic signal timing optimization strategy incorporating various vehicle fuel consumption characteristics. IEEE Trans. Veh. Technol. 2015, 65, 3874–3887. [Google Scholar] [CrossRef]
- Ma, C.; Liu, P. Intersection signal timing optimization considering the travel safety of the elderly. Adv. Mech. Eng. 2019, 11, 1687814019897216. [Google Scholar] [CrossRef]
- Mohebifard, R.; Hajbabaie, A. Optimal network-level traffic signal control: A benders decomposition-based solution algorithm. Transp. Res. Part B Methodol. 2019, 121, 252–274. [Google Scholar] [CrossRef]
- Daganzo, C.F. The cell transmission model: A dynamic representation of highway traffic consistent with the hydrodynamic theory. Transp. Res. Part B Methodol. 1994, 28, 269–287. [Google Scholar] [CrossRef]
- BnnoBRs, J. Partitioning procedures for solving mixed-variables programming problems. Numer. Math. 1962, 4, 238–252. [Google Scholar]
- Bin Al Islam, S.M.A.; Abdul Aziz, H.M.; Hajbabaie, A. Stochastic Gradient-Based Optimal Signal Control with Energy Consumption Bounds. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3054–3067. [Google Scholar] [CrossRef]
- Hong, W.; Tao, G.; Wang, H.; Wang, C. Traffic Signal Control With Adaptive Online-Learning Scheme Using Multiple-Model Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–13. [Google Scholar] [CrossRef]
- Li, W.; Ban, X.J. Traffic signal timing optimization in connected vehicles environment. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 1330–1335. [Google Scholar]
- Goodall, N.J.; Smith, B.L.; Park, B. Traffic signal control with connected vehicles. Transp. Res. Rec. 2013, 2381, 65–72. [Google Scholar] [CrossRef]
- Noaeen, M.; Mohajerpoor, R.; Far, B.H.; Ramezani, M. Real-time decentralized traffic signal control for congested urban networks considering queue spillbacks. Transp. Res. Part C Emerg. Technol. 2021, 133, 103407. [Google Scholar] [CrossRef]
- Islam, S.B.A.; Hajbabaie, A.; Aziz, H.A. A real-time network-level traffic signal control methodology with partial connected vehicle information. Transp. Res. Part C Emerg. Technol. 2020, 121, 102830. [Google Scholar] [CrossRef]
- Liang, X.J.; Guler, S.I.; Gayah, V.V. An equitable traffic signal control scheme at isolated signalized intersections using Connected Vehicle technology. Transp. Res. Part C Emerg. Technol. 2020, 110, 81–97. [Google Scholar] [CrossRef]
- Beak, B.; Head, K.L.; Feng, Y. Adaptive coordination based on connected vehicle technology. Transp. Res. Rec. 2017, 2619, 1–12. [Google Scholar] [CrossRef]
- Qiao, Z.; Ke, L.; Wang, X.; Lu, X. Signal Control of Urban Traffic Network Based on Multi-Agent Architecture and Fireworks Algorithm. In Proceedings of the 2019 IEEE Congress on Evolutionary Computation (CEC), Wellington, New Zealand, 10–13 June 2019; pp. 2199–2206. [Google Scholar]
- Tan, Y.; Yu, C.; Zheng, S.; Ding, K. Introduction to fireworks algorithm. Int. J. Swarm Intell. Res. (IJSIR) 2013, 4, 39–70. [Google Scholar] [CrossRef]
- Ma, C.; Zhou, J.; Xu, X.D.; Xu, J. Evolution regularity mining and gating control method of urban recurrent traffic congestion: A literature review. J. Adv. Transp. 2020, 2020, 5261580. [Google Scholar] [CrossRef]
- Bala Subramaniyan, A.; Wang, C.; Shao, Y.; Li, W.; Wang, H.; Guohui, Z.; Ma, T. Hybrid Recurrent Neural Network Modeling for Traffic Delay Prediction at Signalized Intersections Along an Urban Arterial. IEEE Trans. Intell. Transp. Syst. 2022, 24, 1384–1394. [Google Scholar] [CrossRef]
- Liang, X.; Du, X.; Wang, G.; Han, Z. A deep reinforcement learning network for traffic light cycle control. IEEE Trans. Veh. Technol. 2019, 68, 1243–1253. [Google Scholar] [CrossRef]
- Ma, C.; Zhao, Y.; Dai, G.; Xu, X.; Wong, S.C. A Novel STFSA-CNN-GRU Hybrid Model for Short-Term Traffic Speed Prediction. IEEE Trans. Intell. Transp. Syst. 2022, 2022, 3117835. [Google Scholar] [CrossRef]
- Al Islam, S.B.; Aziz, H.A.; Wang, H.; Young, S.E. Minimizing energy consumption from connected signalized intersections by reinforcement learning. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 1870–1875. [Google Scholar]
- Du, Y.; ShangGuan, W.; Rong, D.; Chai, L. RA-TSC: Learning Adaptive Traffic Signal Control Strategy via Deep Reinforcement Learning. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3275–3280. [Google Scholar]
- Chen, P.; Zhu, Z.; Lu, G. An Adaptive Control Method for Arterial Signal Coordination Based on Deep Reinforcement Learning. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3553–3558. [Google Scholar]
- Yoon, J.; Ahn, K.; Park, J.; Yeo, H. Transferable traffic signal control: Reinforcement learning with graph centric state representation. Transp. Res. Part C Emerg. Technol. 2021, 130, 103321. [Google Scholar] [CrossRef]
- Zeng, J.; Hu, J.; Zhang, Y. Training Reinforcement Learning Agent for Traffic Signal Control under Different Traffic Conditions. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 4248–4254. [Google Scholar]
- Aslani, M.; Mesgari, M.S.; Wiering, M. Adaptive traffic signal control with actor-critic methods in a real-world traffic network with different traffic disruption events. Transp. Res. Part C Emerg. Technol. 2017, 85, 732–752. [Google Scholar] [CrossRef]
- Chu, T.; Wang, J.; Codecà, L.; Li, Z. Multi-agent deep reinforcement learning for large-scale traffic signal control. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1086–1095. [Google Scholar] [CrossRef]
- Li, Z.; Yu, H.; Zhang, G.; Dong, S.; Xu, C.Z. Network-wide traffic signal control optimization using a multi-agent deep reinforcement learning. Transp. Res. Part C Emerg. Technol. 2021, 125, 103059. [Google Scholar] [CrossRef]
- Wang, T.; Cao, J.; Hussain, A. Adaptive Traffic Signal Control for large-scale scenario with Cooperative Group-based Multi-agent reinforcement learning. Transp. Res. Part C Emerg. Technol. 2021, 125, 103046. [Google Scholar] [CrossRef]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- Lopez, P.A.; Behrisch, M.; Bieker-Walz, L.; Erdmann, J.; Flötteröd, Y.P.; Hilbrich, R.; Lücken, L.; Rummel, J.; Wagner, P.; WieBner, E. Microscopic traffic simulation using sumo. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2575–2582. [Google Scholar]
- Genders, W.; Razavi, S. Using a deep reinforcement learning agent for traffic signal control. arXiv 2016, arXiv:1611.01142. [Google Scholar]
- Jeong, J.; Shen, Y.; Oh, T.; Céspedes, S.; Benamar, N.; Wetterwald, M.; Härri, J. A comprehensive survey on vehicular networks for smart roads: A focus on IP-based approaches. Veh. Commun. 2021, 29, 100334. [Google Scholar] [CrossRef]
- Transportation Research Board and National Academies of Sciences, Engineering, and Medicine. Signal Timing Manual, 2nd ed.; The National Academies Press: Washington, DC, USA, 2015. [Google Scholar]
- Baldi, P. Autoencoders, Unsupervised Learning, and Deep Architectures. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning; Guyon, I., Dror, G., Lemaire, V., Taylor, G., Silver, D., Eds.; Proceedings of Machine Learning Research; PMLR: Bellevue, DC, USA, 2012; Volume 27, pp. 37–49. [Google Scholar]
- Hakenes, S.; Glasmachers, T. Boosting Reinforcement Learning with Unsupervised Feature Extraction. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2019: Theoretical Neural Computation; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 555–566. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 31 January 2022).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, H.; Zhu, M.; Hong, W.; Wang, C.; Tao, G.; Wang, Y. Optimizing Signal Timing Control for Large Urban Traffic Networks Using an Adaptive Linear Quadratic Regulator Control Strategy. IEEE Trans. Intell. Transp. Syst. 2022, 23, 333–343. [Google Scholar] [CrossRef]
- Krauß, S. Microscopic Modeling of Traffic Flow: Investigation of Collision Free Vehicle Dynamics. Master’s Thesis, Universität zu Köln, Köln, Germany, 1998. [Google Scholar]
- Bu, L.; Babu, R.; De Schutter, B. A comprehensive survey of multiagent reinforcement learning. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2008, 38, 156–172. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Lane length | 160 m |
| Vehicle length | 5 m |
| Time step | 1 s |
| Maximum vehicle speed | 20 |
| Maximum vehicle acceleration | 3 |
| Maximum vehicle deceleration | 4.5 |
| Minimum gap between vehicles | 2 m |
| Car following model | Krauss Following Model [51] |
| Duration of yellow phase | 3 s |
| Traffic volume | 480 vehicles per lane and per hour |
| Left turning vehicles ratio | 25% of total |
| Right turning vehicles ratio | 25% of total |
| Parameter | Value |
|---|---|
| Simulated time steps for each episode | 3600 |
| Replay memory size | 20,000 |
| Minibatch size | 64 |
| Pre-train steps | 2000 |
| Target network update interval | 64 control cycles |
| Target network update rate | 0.001 |
| Discount factor | 0.99 |
| Optimizer | Adam [49] |
| Learning rate | |
| Initial probability of exploration | 1 |
| Final probability of exploration | 0.01 |
| Ending step for exploration probability | 40,000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, Y.; Wang, Z.; LaClair, T.J.; Wang, C.; Shao, Y.; Yuan, J. A Novel Deep Reinforcement Learning Approach to Traffic Signal Control with Connected Vehicles. Appl. Sci. 2023, 13, 2750. https://doi.org/10.3390/app13042750
Shi Y, Wang Z, LaClair TJ, Wang C, Shao Y, Yuan J. A Novel Deep Reinforcement Learning Approach to Traffic Signal Control with Connected Vehicles. Applied Sciences. 2023; 13(4):2750. https://doi.org/10.3390/app13042750
Chicago/Turabian StyleShi, Yang, Zhenbo Wang, Tim J. LaClair, Chieh (Ross) Wang, Yunli Shao, and Jinghui Yuan. 2023. "A Novel Deep Reinforcement Learning Approach to Traffic Signal Control with Connected Vehicles" Applied Sciences 13, no. 4: 2750. https://doi.org/10.3390/app13042750
APA StyleShi, Y., Wang, Z., LaClair, T. J., Wang, C., Shao, Y., & Yuan, J. (2023). A Novel Deep Reinforcement Learning Approach to Traffic Signal Control with Connected Vehicles. Applied Sciences, 13(4), 2750. https://doi.org/10.3390/app13042750