
Pixelwise Complex-Valued Neural Network Based on 1D FFT of Hyperspectral Data to Improve Green Pepper Segmentation in Agriculture




Abstract
1. Introduction
- We propose a lightweight pixelwise complex-valued neural network (CVNN) assisted by 1D Fourier transform to address hyperspectral classification problems.
- We provide an efficient way for green pepper automatic picking in agriculture using small datasets.
2. Related Work
2.1. Green Pepper Automatic Picking
2.2. Complex-Valued Neural Network (CVNN)
3. Method
3.1. Dataset and Pre-Processing
3.2. Discrete Fourier Transform
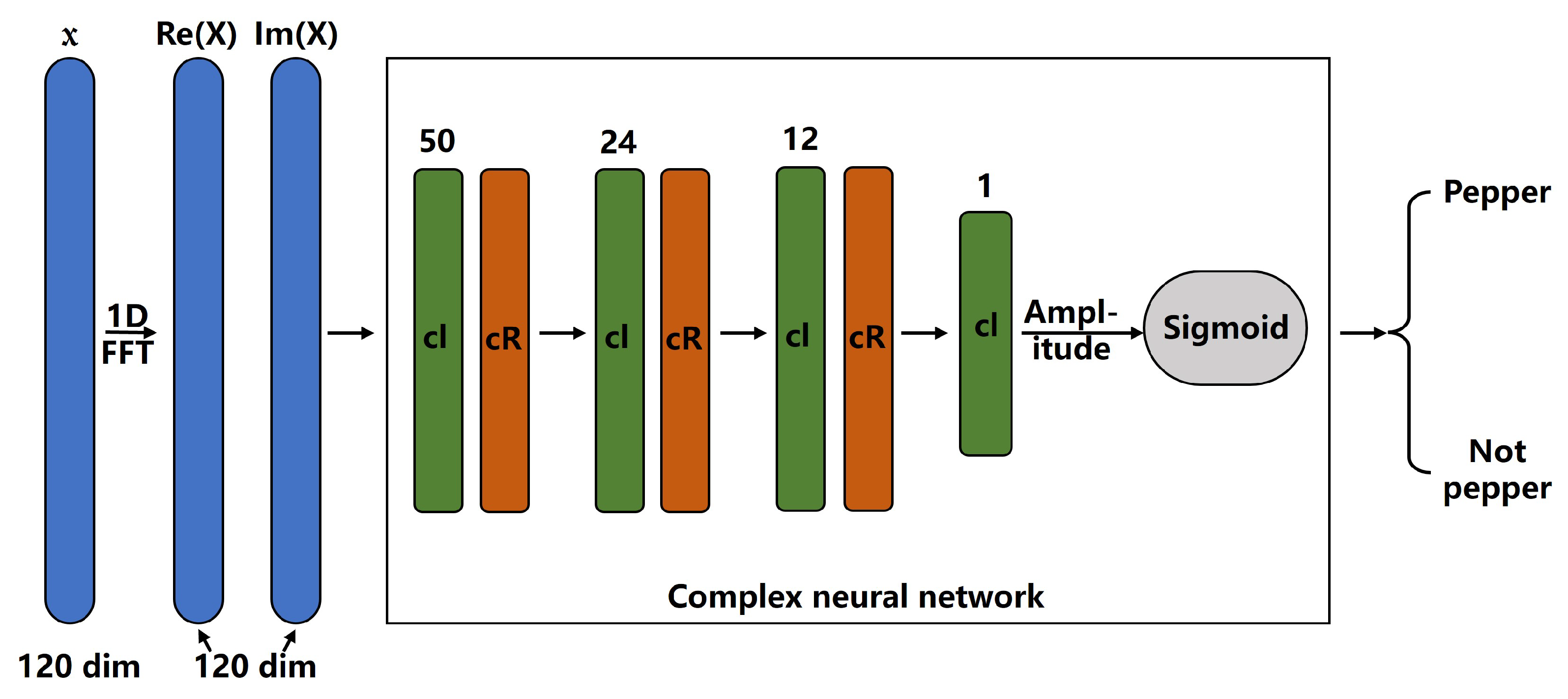
3.3. Complex Neural Network
3.4. The Whole Pipeline
4. Experiments
4.1. Training Details
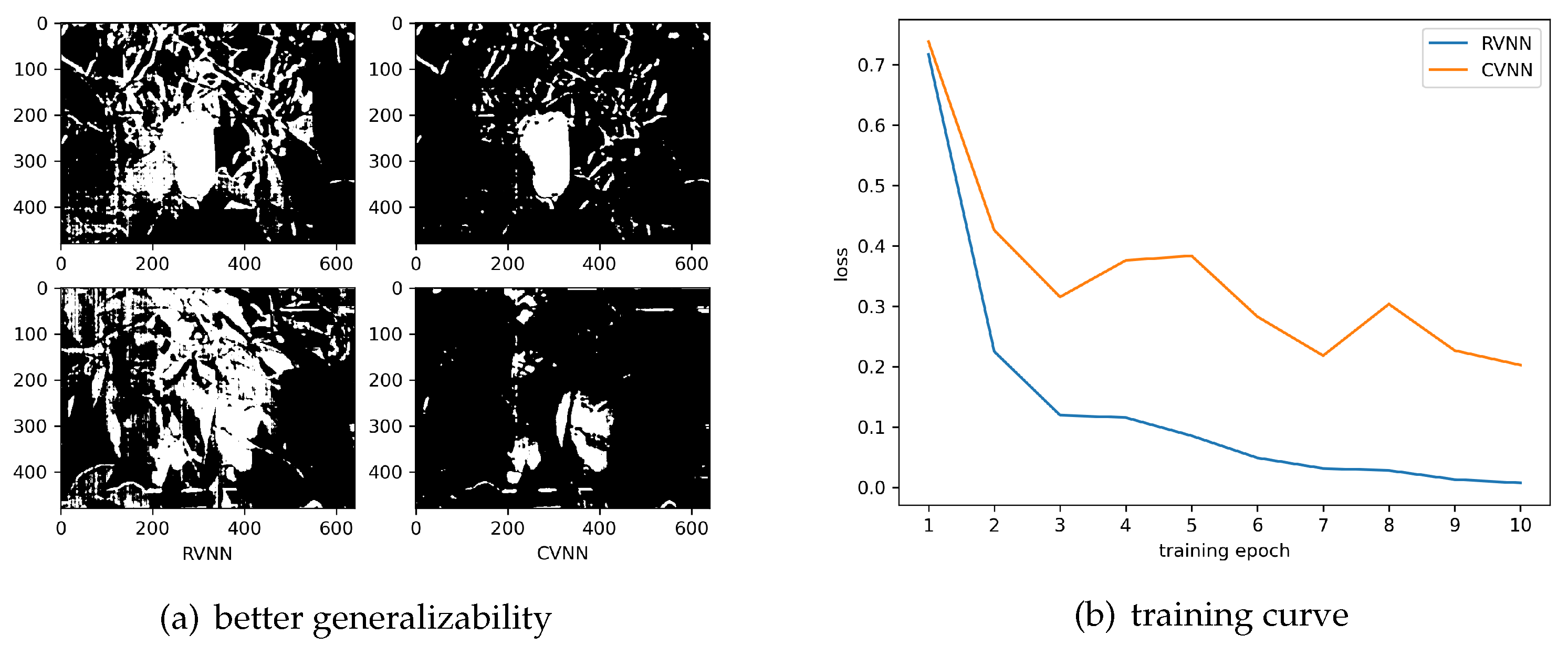
4.2. Real vs. Complex
4.3. Half of Frequencies vs. Quarter of Frequencies
4.4. Overfitting Problem
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fu, Z.; Pun, C.-M.; Gao, H.; Lu, H. Endmember extraction of hyperspectral remote sensing images based on an improved discrete artificial bee colony algorithm and genetic algorithm. Mob. Netw. Appl. 2018, 25, 1033–1041. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Xie, C.; Yang, C.; He, Y. Hyperspectral imaging for classification of healthy and gray mold diseased tomato leaves with different infection severities. Comput. Electron. Agric. 2017, 135, 154–162. [Google Scholar] [CrossRef]
- Ishida, T.; Kurihara, J.; Viray, F.A.; Namuco, S.B.; Paringit, E.C.; Perez, G.J.; Takahashi, Y.; Marciano, J.J., Jr. Tetsuro Ishida, Junichi Kurihara, Fra Angelico Viray, et.al. A novel approach for vegetation classification using UAV-based hyperspectral imaging. Comput. Electron. Agric. 2018, 144, 80–85. [Google Scholar] [CrossRef]
- Hiros, A. Complex-valued neural networks. Stud. Comput. Intell. 2006, 32, 1–160. [Google Scholar]
- Hirose, A. Complex-valued neural networks: The merits and their origins. In Proceedings of the International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009. [Google Scholar]
- Aburaed, N.; Alkhatib, M.Q.; Marshall, S.; Zabalza, J.; Al Ahmad, H. Complex-valued neural networks for hyperspectral single image super resolution. Photonex 2023, 12338, 102–109. [Google Scholar]
- Eizentals, P.; Oka, K. 3D pose estimation of green pepper fruit for automated harvesting. Comput. Electron. Agric. 2016, 128, 127–140. [Google Scholar] [CrossRef]
- Hespeler, S.C.; Nemati, H.; Dehghan-Niri, E. Non-destructive thermal imaging for object detection via advanced deep learning for robotic inspection and harvesting of chili peppers. Artif. Intell. Agric. 2021, 5, 102–117. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Li, W.; Fan, Z.; Li, H. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef]
- Shi, C.; Pun, C.-M. Superpixel-based 3D deep neural networks for hyperspectral image classification. Pattern Recognit. 2018, 74, 600–616. [Google Scholar] [CrossRef]
- Yu, J.; Kurihara, T.; Zhan, S. Optical Filter Net: A Spectral-Aware RGB Camera Framework for Effective Green Pepper Segmentation. IEEE Access 2021, 9, 90142–90152. [Google Scholar] [CrossRef]
- Wisdom, S.; Powers, T.; Hershey, J.; Le Roux, J.; Atlas, L. Full-capacity unitary recurrent neural networks. Adv. Neural Inf. Process. Syst. 2016, 29, 4880–4888. [Google Scholar]
- Nitta, T. On the critical points of the complex-valued neural network. In Proceedings of the 9th International Conference on Neural Information Processing, Penang, Malaysia, 19–21 December 2002; Volume 3, pp. 1009–1103. [Google Scholar]
- Arjovsky, M.; Shah, A.; Bengio, Y. Unitary evolution recurrent neural networks. In Proceedings of the International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; pp. 1120–1128. [Google Scholar]
- Hirose, A.; Yoshida, S. Generalization Characteristics of Complex-Valued Feedforward Neural Networks in Relation to Signal Coherence. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 541–551. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Ma, Y. CGHA for principal component extraction in the complex domain. IEEE Trans. Neural Netw. 1997, 85, 1031–1036. [Google Scholar] [CrossRef] [PubMed]
- Birx, D.L.; Pipenberg, S.J. A complex mapping network for phase sensitive classification. IEEE Trans. Neural Netw. 1993, 41, 127–135. [Google Scholar] [CrossRef] [PubMed]
- Aizenberg, I.N.; Paliy, D.; Zurada, J.M.; Astola, J. Blur Identification by Multilayer Neural Network Based on Multivalued Neurons. IEEE Trans. Neural Netw. 2008, 19, 883–898. [Google Scholar] [CrossRef]
- Trabelsi, C.; Bilaniuk, O.; Zhang, Y. Deep Complex Networks. In Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2016. [Google Scholar]
- Guberman, N. On complex valued convolutional neural networks. arXiv 2016, arXiv:1602.09046. [Google Scholar]
- Liu, X.; Yu, J.; Kurihara, T.; Xu, L.; Niu, Z.; Zhan, S. Hyperspectral imaging for green pepper segmentation using a complex-valued neural network. Optik 2022, 265, 169527. [Google Scholar] [CrossRef]
- Zhang, Y.M.; Wang, P.; Bai, J.R.; Dong-Ya, M.A. Establishment of Identification and Classification Model of PE, PP and PET Based on Near Infrared Spectroscopy; Modern Chemical Industry: Mumbai, India, 2016. [Google Scholar]
- Guo, Z.; Zhao, C.; Huang, W.; Peng, Y.; Li, J.; Wang, Q. Intensity correction of visualized prediction for sugar content in apple using hyperspectral imaging. Trans. Chin. Soc. Agric. Mach. 2015, 46, 227–232. [Google Scholar]
- Bac, C.W.; Hemming, J.; van Henten, E.J. Robust pixel-based classification of obstacles for robotic harvesting of sweet-pepper. Comput. Electron. Agric. 2013, 96, 148–162. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | Recall Rate | F1 Score | |
|---|---|---|---|
| RVNN | 90.99% | 83.21% | 86.92% |
| CVNN | 94.89% | 82.48% | 88.25% |
| CVNN () | 94.49% | 82.97% | 88.36% |
| CVNN () | 93.71% | 85.73% | 89.55% |
| CVNN () | 72.75% | 64.83% | 68.56% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Yu, J.; Kurihara, T.; Wu, C.; Niu, Z.; Zhan, S. Pixelwise Complex-Valued Neural Network Based on 1D FFT of Hyperspectral Data to Improve Green Pepper Segmentation in Agriculture. Appl. Sci. 2023, 13, 2697. https://doi.org/10.3390/app13042697
Liu X, Yu J, Kurihara T, Wu C, Niu Z, Zhan S. Pixelwise Complex-Valued Neural Network Based on 1D FFT of Hyperspectral Data to Improve Green Pepper Segmentation in Agriculture. Applied Sciences. 2023; 13(4):2697. https://doi.org/10.3390/app13042697
Chicago/Turabian StyleLiu, Xinzhi, Jun Yu, Toru Kurihara, Congzhong Wu, Zhao Niu, and Shu Zhan. 2023. "Pixelwise Complex-Valued Neural Network Based on 1D FFT of Hyperspectral Data to Improve Green Pepper Segmentation in Agriculture" Applied Sciences 13, no. 4: 2697. https://doi.org/10.3390/app13042697
APA StyleLiu, X., Yu, J., Kurihara, T., Wu, C., Niu, Z., & Zhan, S. (2023). Pixelwise Complex-Valued Neural Network Based on 1D FFT of Hyperspectral Data to Improve Green Pepper Segmentation in Agriculture. Applied Sciences, 13(4), 2697. https://doi.org/10.3390/app13042697