
LGViT: A Local and Global Vision Transformer with Dynamic Contextual Position Bias Using Overlapping Windows


Abstract
1. Introduction
- We propose a novel Local and Global Vision Transformer (LGViT) with a well-designed window-based self-attention mechanism. It contains a local self-attention module (LSA) based on overlapping windows to promote local interactions and a global self-attention module (GSA) with multi-scaled dilated pooling to obtain global contextual information.
- We also design a dynamic contextual positional encoding module (DCPE) to make the relative position embedding more flexible and effective, i.e., applying to variable input size and changing with the input queries.
- Extensive experiments strongly demonstrate that our proposed LGViT achieves outperformance on various visual tasks to state-of-the-art approaches.
2. Related Work
2.1. Vision Transformers
2.2. Self-Attention Mechanisms
2.3. Position Encoding
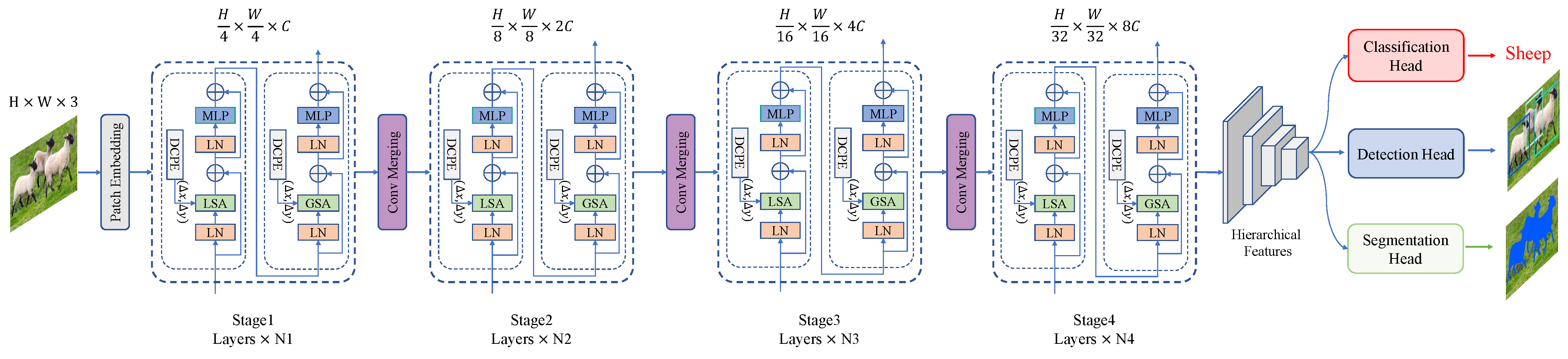
3. Proposed Method
3.1. Overall Architecture
3.2. LGViT Blocks
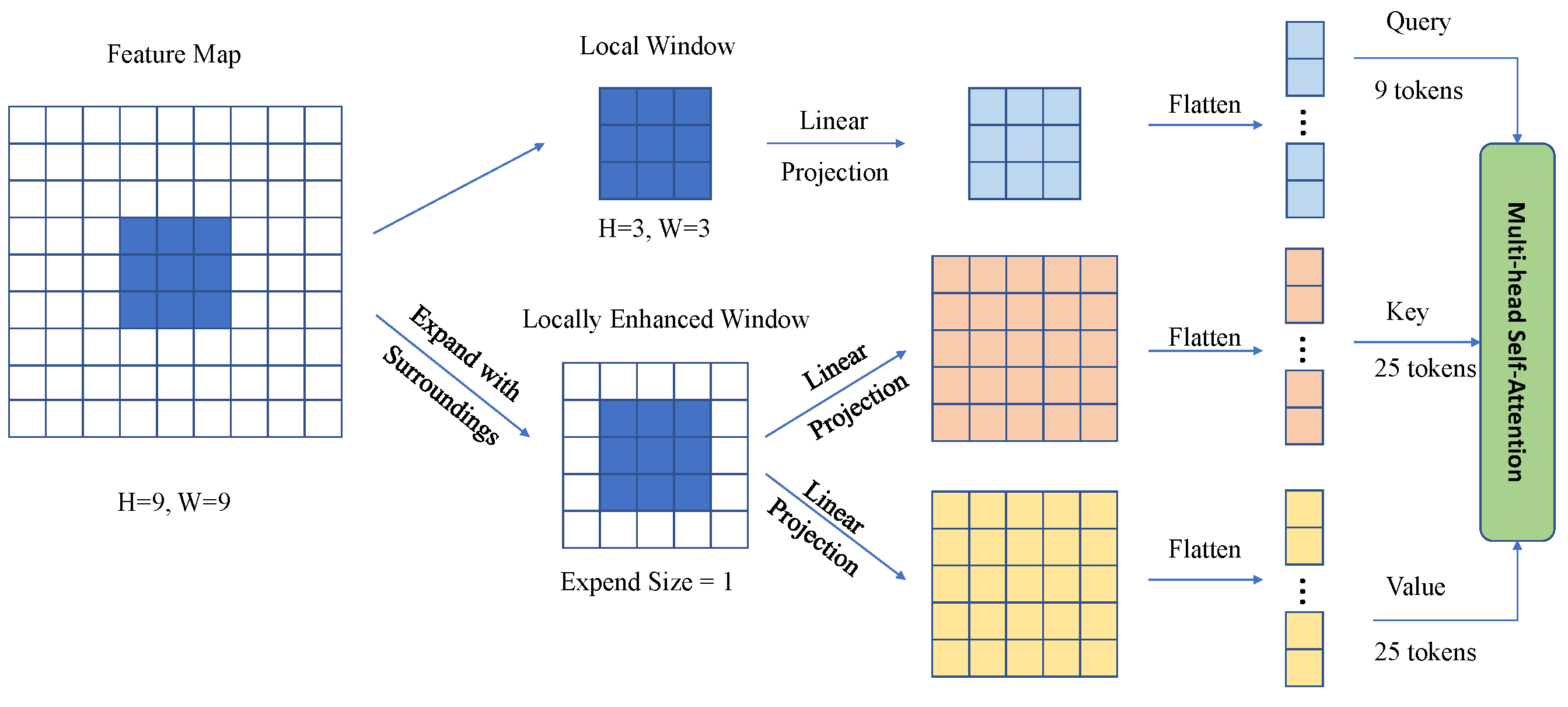
3.2.1. Local Self-Attention (LSA) with Overlapping Windows
3.2.2. Global Self-Attention (GSA) with Multi-Scale Dilated Pooling
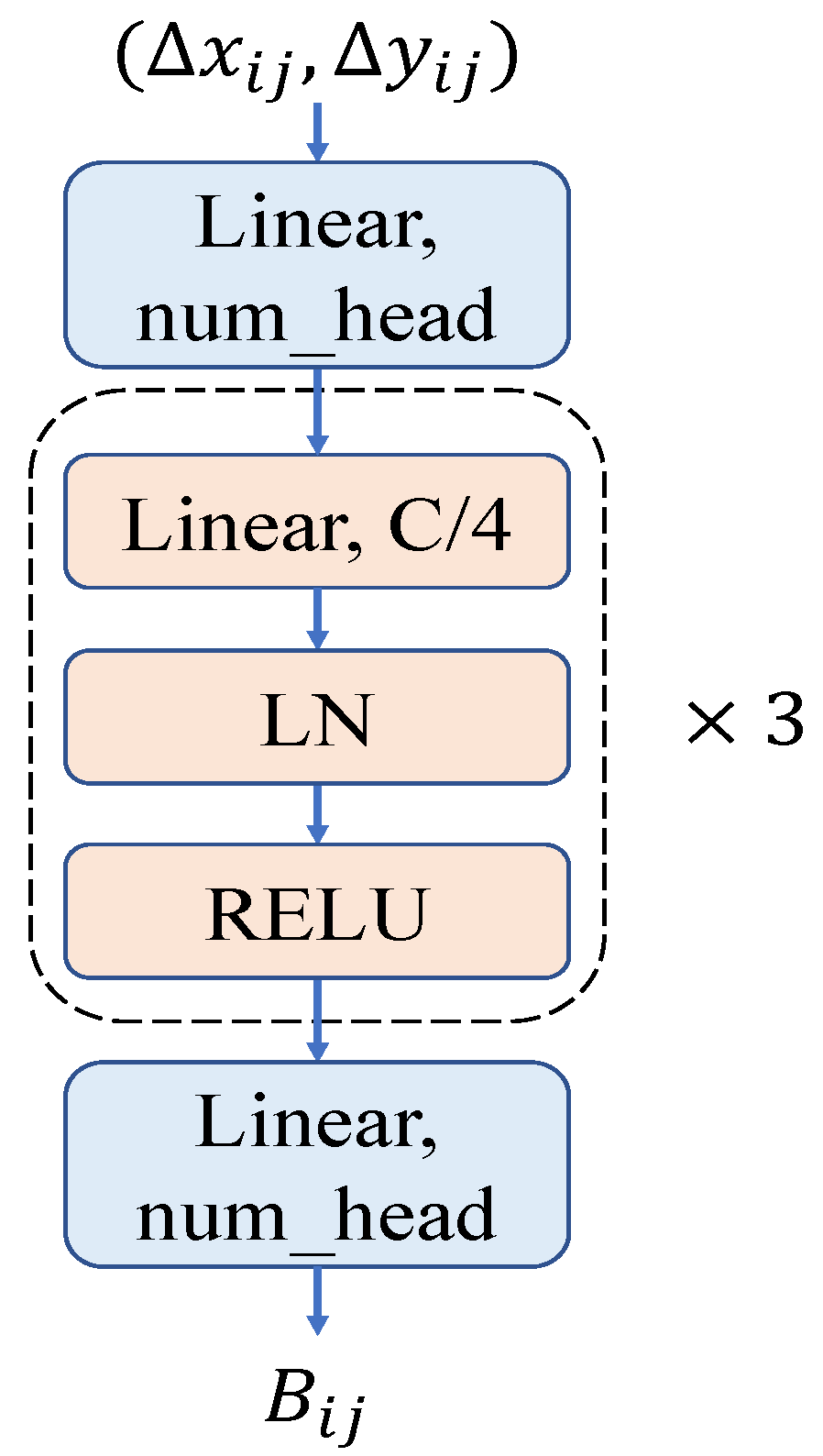
3.3. Contextual Positional Bias
3.4. Configurations of LGViT
3.5. Complexity Analysis
4. Experiments
4.1. Image Classification on the ImageNet1K Dataset
4.2. Object Detection on the COCO Dataset
4.3. Semantic Segmentation on the ADE20K Dataset
4.4. Ablation Study
4.4.1. Effectiveness of Overlapping Windows for Key and Value Set in the LSA Module
4.4.2. Effectiveness of Multi-Scaled Dilated Pooling in the GSA Module
4.4.3. Dynamic Contextual Positional Encoding
5. Discussion
5.1. Peformance of LGViT for Different Visual Tasks
5.2. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. More Architecture Details
Appendix A.1. Architecture of DCPE

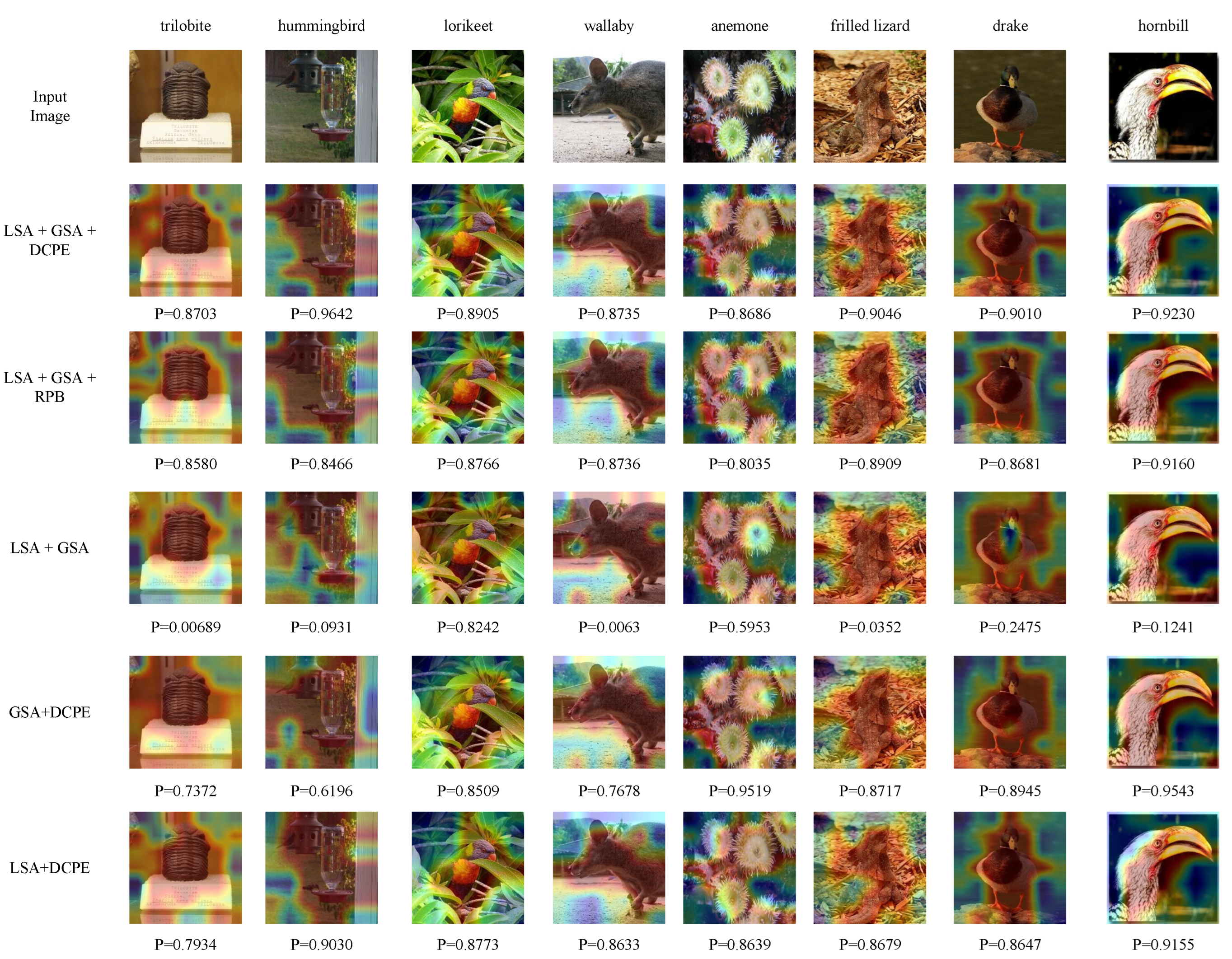
Appendix A.2. Importance of LSA and GSA

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Modules | #Params | FLOPs | Metrics |
|---|---|---|---|---|
| Imagenet1K | LSA&GSA | 30 M | 4.75 G | 82.1 |
| LSA&LSA | 30 M | 4.76 G | 81.9 | |
| GSA&GSA | 30 M | 4.74 G | 81.8 | |
| LSA&WSA | 30 M | 4.64 G | 81.8 | |
| WSA&GSA | 30 M | 4.63 G | 81.7 | |
| COCO2017 | LSA&GSA | 40 M | 261.0 G | 43.4 |
| LSA&LSA | 40 M | 261.09 G | 43.1 | |
| GSA&GSA | 40 M | 260.91 G | 42.8 | |
| LSA&WSA | 40 M | 256.9 G | 42.9 | |
| WSA&GSA | 40 M | 257.3 G | 42.5 | |
| ADE20K | LSA&GSA | 63 M | 946.2 G | 47.1 |
| LSA&LSA | 63 M | 944.2 G | 46.9 | |
| GSA&GSA | 63 M | 948.2 G | 46.7 | |
| LSA&WSA | 63 M | 943.3 G | 46.8 | |
| WSA&GSA | 63 M | 945.1 G | 46.4 |
Appendix B. More Visualization Results
Appendix B.1. Visualization of Heat Maps


Appendix B.2. Visualization of Features


Appendix B.3. Comparison of DCPE to RPB
References
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–14 August 2021; pp. 10347–10357. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12124–12134. [Google Scholar]
- He, J.; Chen, J.N.; Liu, S.; Kortylewski, A.; Yang, C.; Bai, Y.; Wang, C. Transfg: A transformer architecture for fine-grained recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 28 February–1 March 2022; Volume 36, pp. 852–860. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Yuan, Z.; Song, X.; Bai, L.; Wang, Z.; Ouyang, W. Temporal-Channel Transformer for 3D Lidar-Based Video Object Detection for Autonomous Driving. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2068–2078. [Google Scholar] [CrossRef]
- Sun, P.; Tan, M.; Wang, W.; Liu, C.; Xia, F.; Leng, Z.; Anguelov, D. Swformer: Sparse window transformer for 3d object detection in point clouds. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2022; pp. 426–442. [Google Scholar]
- Chen, H.; Li, C.; Wang, G.; Li, X.; Rahaman, M.M.; Sun, H.; Hu, W.; Li, Y.; Liu, W.; Sun, C.; et al. GasHis-Transformer: A multi-scale visual transformer approach for gastric histopathological image detection. Pattern Recognit. 2022, 130, 108827. [Google Scholar] [CrossRef]
- Chen, W.; Du, X.; Yang, F.; Beyer, L.; Zhai, X.; Lin, T.Y.; Chen, H.; Li, J.; Song, X.; Wang, Z.; et al. A Simple Single-Scale Vision Transformer for Object Detection and Instance Segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2022; pp. 711–727. [Google Scholar]
- Prangemeier, T.; Reich, C.; Koeppl, H. Attention-based transformers for instance segmentation of cells in microstructures. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Republic of Korea, 16–19 December 2020; pp. 700–707. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Gu, J.; Kwon, H.; Wang, D.; Ye, W.; Li, M.; Chen, Y.H.; Lai, L.; Chandra, V.; Pan, D.Z. Multi-scale high-resolution vision transformer for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12094–12103. [Google Scholar]
- Zhang, W.; Huang, Z.; Luo, G.; Chen, T.; Wang, X.; Liu, W.; Yu, G.; Shen, C. TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12083–12093. [Google Scholar]
- Wang, W.; Yao, L.; Chen, L.; Lin, B.; Cai, D.; He, X.; Liu, W. CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention. In Proceedings of the International Conference on Learning Representations, ICLR, Virtual, 25–29 April 2022. [Google Scholar]
- Vaswani, A.; Ramachandran, P.; Srinivas, A.; Parmar, N.; Hechtman, B.; Shlens, J. Scaling local self-attention for parameter efficient visual backbones. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12894–12904. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-Attention with Relative Position Representations. In Proceedings of the NAACL-HLT (2), New Orleans, LO, USA, 2–4 June 2018. [Google Scholar]
- Naushad, R.; Kaur, T.; Ghaderpour, E. Deep transfer learning for land use and land cover classification: A comparative study. Sensors 2021, 21, 8083. [Google Scholar] [CrossRef]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5791–5800. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 1833–1844. [Google Scholar]
- Souibgui, M.A.; Biswas, S.; Jemni, S.K.; Kessentini, Y.; Fornés, A.; Lladós, J.; Pal, U. DocEnTr: An end-to-end document image enhancement transformer. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022. [Google Scholar]
- Boudiaf, A.; Guo, Y.; Ghimire, A.; Werghi, N.; De Masi, G.; Javed, S.; Dias, J. Underwater Image Enhancement Using Pre-trained Transformer. In Proceedings of the International Conference on Image Analysis and Processing, Trento, Italy, 9–13 September 2022; pp. 480–488. [Google Scholar]
- Sun, J.; Dong, J.; Lv, Q. Swin transformer and fusion for underwater image enhancement. In Proceedings of the International Workshop on Advanced Imaging Technology (IWAIT) 2022, SPIE, Hong Kong, China, 4–6 January 2022; Volume 12177, pp. 627–631. [Google Scholar]
- Zhang, X.; Han, L.; Sobeih, T.; Lappin, L.; Lee, M.A.; Howard, A.; Kisdi, A. The Self-Supervised Spectral–Spatial Vision Transformer Network for Accurate Prediction of Wheat Nitrogen Status from UAV Imagery. Remote Sens. 2022, 14, 1400. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 568–578. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT (1), Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: file:///C:/Users/MDPI/Downloads/radford2018improving.pdf (accessed on 1 February 2023).
- Wu, K.; Peng, H.; Chen, M.; Fu, J.; Chao, H. Rethinking and improving relative position encoding for vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10033–10041. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. Hrformer: High-resolution vision transformer for dense predict. Adv. Neural Inf. Process. Syst. 2021, 34, 7281–7293. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Ccomputer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3588–3597. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Hu, H.; Zhang, Z.; Xie, Z.; Lin, S. Local relation networks for image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3464–3473. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F.; Wang, W.; Yang, N.; Liu, X.; Wang, Y.; Gao, J.; Piao, S.; Zhou, M.; et al. Unilmv2: Pseudo-masked language models for unified language model pre-training. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 642–652. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the ICML, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Yang, J.; Li, C.; Zhang, P.; Dai, X.; Xiao, B.; Yuan, L.; Gao, J. Focal Attention for Long-Range Interactions in Vision Transformers. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021; Volume 34, pp. 30008–30022. [Google Scholar]
- Huang, Z.; Ben, Y.; Luo, G.; Cheng, P.; Yu, G.; Fu, B. Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer. arXiv 2021, arXiv:2106.03650. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the design of spatial attention in vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 9355–9366. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Xiao, T.; Fidler, S.; Barriuso, A.; Torralba, A. Semantic understanding of scenes through the ade20k dataset. Int. J. Comput. Vis. 2019, 127, 302–321. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13001–13008. [Google Scholar]
- Huang, G.; Sun, Y.; Liu, Z.; Sedra, D.; Weinberger, K.Q. Deep networks with stochastic depth. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 646–661. [Google Scholar]
- Zhang, P.; Dai, X.; Yang, J.; Xiao, B.; Yuan, L.; Zhang, L.; Gao, J. Multi-scale vision longformer: A new vision transformer for high-resolution image encoding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2998–3008. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10428–10436. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.H.; Tay, F.E.; Feng, J.; Yan, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 558–567. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 357–366. [Google Scholar]
- Chu, X.; Tian, Z.; Zhang, B.; Wang, X.; Wei, X.; Xia, H.; Shen, C. Conditional positional encodings for vision transformers. arXiv 2021, arXiv:2102.10882. [Google Scholar]
- Zhang, Z.; Zhang, H.; Zhao, L.; Chen, T.; Pfister, T. Aggregating nested transformers. arXiv 2021, arXiv:2105.12723. [Google Scholar]
- Lin, H.; Cheng, X.; Wu, X.; Shen, D. Cat: Cross attention in vision transformer. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Chen, C.F.; Panda, R.; Fan, Q. RegionViT: Regional-to-Local Attention for Vision Transformers. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Contributors, M. MMSegmentation: OpenMMLab Semantic Segmentation Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 1 February 2023).
- Wu, C.; Wu, F.; Qi, T.; Huang, Y.; Xie, X. Fastformer: Additive attention can be all you need. arXiv 2021, arXiv:2108.09084. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]





| Dataset | Layer Name | Imagenet-1K | COCO2017 | ADE20K |
|---|---|---|---|---|
| InputSize | ||||
| Window Size | 7 | 8 | 8 | |
| Stage1 | Patch Embedding | Conv2d (in = 3, out = 96, kernel = 4, padding = 0, stride = 4) | ||
| LSA | expand_size = 3 | expand_size = 4 | expand_size = 4 | |
| GSA | pooling = [(7,1,7), (3, 3, 6)] | pooling = [(32,1,32), (16, 2,31)] | pooling = [(16,1,16), (8, 2,15)] | |
| Stage2 | Conv Merging | Conv2d (in = 96, out = 192, kernel = 3, padding = 1, stride = 2) | ||
| LSA | expand_size = 2 | expand_size = 3 | expand_size = 3 | |
| GSA | pooling = [(7,1,7), (3, 3, 5)] | pooling = [(8,1,8), (8, 2,15)] | pooling = [(8,1,8), (4, 2,7)] | |
| Stage3 | Conv Merging | Conv2d (in = 192, out = 384, kernel = 3, padding = 1, stride = 2) | ||
| LSA | expand_size = 1 | expand_size = 2 | expand_size = 2 | |
| GSA | pooling = [(7,1,7), (3, 3, 4)] | pooling = [(8,1,8), (4, 2,7)] | pooling = [(8,1,8), (4, 2,6)] | |
| Stage4 | Conv Merging | Conv2d (in = 384, out = 768, kernel = 3, padding = 1, stride = 2) | ||
| LSA | expand_size = 0 | expand_size = 1 | expand_size = 1 | |
| GSA | — | pooling = [(8,1,8), (4, 2,6)] | pooling = [(8,1,8), (4, 2,5)] | |
| Method | Complexity |
|---|---|
| ViT [5] | |
| DeiT [6] | |
| PvT [50] | |
| CvT [7] | |
| Twins [51] | |
| Swin-T [23] | |
| LGViT (ours) |
| Method | #Params | FLOPs | Top-1 Acc |
|---|---|---|---|
| ResNet-50 [3] | 25 M | 4.1 G | 76.2 |
| Reg-4G [62] | 21 M | 4.0 G | 80.0 |
| DeiT-S [6] | 22 M | 4.6 G | 79.8 |
| PVT-S [33] | 25 M | 3.8 G | 79.8 |
| T2T-14 [63] | 22 M | 5.2 G | 81.5 |
| ViL-S [61] | 25 M | 4.9 G | 82.0 |
| TNT-S [64] | 24 M | 5.2 G | 81.3 |
| CViT-15 [65] | 27 M | 5.6 G | 81.0 |
| CPVT-S [66] | 23 M | 4.6 G | 81.5 |
| NesT-T [67] | 17 M | 5.8 G | 81.5 |
| CAT-S [68] | 37 M | 5.9 G | 81.8 |
| CvT-13 [7] | 20 M | 4.5 G | 81.6 |
| Swin-T [23] | 29 M | 4.3 G | 81.3 |
| LGViT (ours) | 30 M | 4.8 G | 82.1 |
| Method | #Params | FLOPs | |||
|---|---|---|---|---|---|
| ResNet-50 [3] | 37.7 M | 234.0 G | 36.3 | 55.3 | 38.6 |
| CAT-B [68] | 62.0 M | 337.0 G | 41.4 | 62.9 | 43.8 |
| ViL-M [61] | 50.8 M | 338.9 G | 42.9 | 64.0 | 45.4 |
| RegionViT-B [71] | 83.4 M | 308.9 G | 43.3 | 65.2 | 46.4 |
| Swin-T [23] | 38.5 M | 245.0 G | 41.5 | 62.1 | 44.2 |
| LGViT (ours) | 40 M | 261 G | 43.4 | 65.3 | 46.9 |
| Method | #Params | FLOPs | mIoU |
|---|---|---|---|
| ResNet-101 [3] | 86 M | 1029 G | 44.9 |
| Shuffle-T [50] | 60 M | 949 G | 46.6 |
| TwinsP-S [51] | 54.6 M | 919 G | 46.2 |
| Twins-S [51] | 54.4 M | 901 G | 46.2 |
| Swin-T [23] | 60 M | 945 G | 44.5 |
| LGViT (ours) | 62 M | 946 G | 47.1 |
| Dataset | Overlap? | #Params | FLOPs | Metrics |
|---|---|---|---|---|
| Imagenet1K | √ | 30 M | 4.8 G | 82.1 |
| × | 30 M | 4.6 G | 81.7 | |
| COCO2017 | √ | 40 M | 261 G | 43.4 |
| × | 40 M | 257 G | 42.5 | |
| ADE20K | √ | 62 M | 946 G | 47.1 |
| × | 62 M | 945 G | 46.4 |
| Dataset | MS? | #Params | FLOPs | Metrics |
|---|---|---|---|---|
| Imagenet1K | √ | 30 M | 4.8 G | 82.1 |
| × | 30 M | 4.6 G | 81.8 | |
| COCO2017 | √ | 40 M | 261 G | 43.4 |
| × | 40 M | 257 G | 42.9 | |
| ADE20K | √ | 63 M | 946 G | 47.1 |
| × | 63 M | 943 G | 46.8 |
| Dataset | Method | #Params | FLOPs | Metrics |
|---|---|---|---|---|
| Imagenet1K | DCPE | 30M | 4.8G | 82.1 |
| RPB | 30M | 4.7G | 82.0 | |
| COCO2017 | DCPE | 40M | 261G | 43.4 |
| RPB | 40M | 261G | 43.2 | |
| ADE20K | DCPE | 63M | 946G | 47.1 |
| RPB | 63M | 946G | 47.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Q.; Zou, H.; Wu, H. LGViT: A Local and Global Vision Transformer with Dynamic Contextual Position Bias Using Overlapping Windows. Appl. Sci. 2023, 13, 1993. https://doi.org/10.3390/app13031993
Zhou Q, Zou H, Wu H. LGViT: A Local and Global Vision Transformer with Dynamic Contextual Position Bias Using Overlapping Windows. Applied Sciences. 2023; 13(3):1993. https://doi.org/10.3390/app13031993
Chicago/Turabian StyleZhou, Qian, Hua Zou, and Huanhuan Wu. 2023. "LGViT: A Local and Global Vision Transformer with Dynamic Contextual Position Bias Using Overlapping Windows" Applied Sciences 13, no. 3: 1993. https://doi.org/10.3390/app13031993
APA StyleZhou, Q., Zou, H., & Wu, H. (2023). LGViT: A Local and Global Vision Transformer with Dynamic Contextual Position Bias Using Overlapping Windows. Applied Sciences, 13(3), 1993. https://doi.org/10.3390/app13031993