
A Corpus-Based Word Classification Method for Detecting Difficulty Level of English Proficiency Tests




Abstract
1. Introduction
2. Literature Review
2.1. Lexical Threshold
2.2. TCEEC Word List
3. Methodology
3.1. Set Word Classification Criteria
3.1.1. The Function Word List
3.1.2. CEFR A2 Level Word List
3.1.3. CEFR B1 Level Word List
3.2. Data Processing and Analysis
- (1)
- Remove the overlapping parts between word classification criteria
- (2)
- Explore the composition of the off-list words
- (3)
- Calculate word types proportion and lexical coverage of each word classification criterion
4. Results
4.1. Overview of the MOEPT at Taiwan Military Academy
4.2. Composition of the Off-List Words
- (1)
- Other EGP words: When an EGP word belongs neither to CEFR A2 level nor to B1 level word lists, it is regarded as a high-intermediate- or advanced-level noun (1-1), verb (1-2), adjective (1-3), adverb (1-4), proper noun (1-5), and contemporary gadget (1-6).
- 1-1 How do you reduce carbon emissions? [retrieved from TEST-03].
- 1-2 Most researchers attributed the soaring price to the greater use of American corn for making biofuel. [retrieved from TEST-06].
- 1-3 His report is incomprehensible. [retrieved from TEST-08].
- 1-4 They met coincidently. [retrieved from TEST-11].
- 1-5 In an El Niño phenomenon, the surface water in the eastern Pacific Ocean, near the coast of Peru, gets unusually warm. [retrieved from TEST-1].
- 1-6 Does the iPhone 5 carry any guarantee? [retrieved from TEST-6].
- (2)
- Names: The function of a name is to make the test questions have situational effects so that test-takers can understand the conditions and timing to properly use vocabularies (2-1, 2-2). Additionally, some test questions also adopted celebrities’ biographies or short introductions as contents of short reading comprehension passages (2-3).
- 2-1 Why did you break up with John? [retrieved from TEST-6].
- 2-2 James doesn’t live with his family. He lives alone in Taipei. [retrieved from TEST-10].
- 2-3 Margaret Thatcher, also known as the Iron Lady, lived from 1925 until 2013. [retrieved from TEST-5].
- (3)
- Countries/Locations: The categories of countries/locations and names have a similar function. Countries/locations are used to increase the situational effects in test questions, so that test-takers can understand the geographical cultures (3-1), national characteristics (3-2), and usage of geographical locations (3-3).
- 3-1 Margaret is deep into Chinese calligraphy. [retrieved from TEST-7].
- 3-2 A lot of people in Africa are suffering from famine. [retrieved from TEST-10].
- 3-3 I do not live in Kaohsiung so I have to commute from Pingtung to Kaohsiung every day. It takes me about 40 min. [retrieved from TEST-2].
- (4)
- Military: As mentioned earlier, in order to cultivate English communication abilities among cadets to enable them to handle global affairs during their future careers, military-domain English vocabulary is an important issue in English curricula in the Taiwan military academy. Hence, the functions of the military are included in test questions to enable cadets to acquire U.S. military English usages, such as military ranks and branches (1-1), units (1-1, 1-2), and weapon systems nomenclatures (1-3).
- 4-1 Caption Murphy is in charge of the infantry company. [retrieved from TEST-9].
- 4-2 Who is your new platoon leader? [retrieved from TEST-3].
- 4-3 Which do you think is one of the most widely used anti-tank guided missiles? Javelin. [retrieved from TEST-9].
- (5)
- Medical: Proper medical nouns are included in MOEPT to make test questions resemble real-world usages (5-1, 5-2) and to increase the diversity of MOEPT questions and the degree of difficulty by embedding medical professional information into short reading comprehension passages (5-3).
- 5-1 Nancy works in an ICU in a nearby hospital. [retrieved from TEST-12].
- 5-2 Those who fall victim to Alzheimer’s disease often cannot find their way home when they go out. [retrieved from TEST-9].
- 5-3 Ebola is a viral disease of which the initial symptoms can include a sudden fever, intense fatigue, muscle pain, and a sore throat, according to the World Health Organization (WHO). [retrieved from TEST-7].
4.3. Word Types Proportion and Lexical Coverage of Each Word Classification Criteria
- (1)
- The function words
- (2)
- CEFR A2 level words
- (3)
- CEFR B1 level words
- (4)
- Off-list words
4.4. Overall Difficulty Level of the Target Corpus
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Brooks, M.D. What does it mean? EL-identified adolescents’ interpretations of testing and course placement. Tesol Q. 2022, 56, 1218–1241. [Google Scholar] [CrossRef]
- Chan, S.; Taylor, L. Comparing writing proficiency assessments used in professional medical registration: A methodology to inform policy and practice. Assess. Writ. 2020, 46, 100493. [Google Scholar] [CrossRef]
- MacGregor, D.; Yen, S.J.; Yu, X. Using multistage testing to enhance measurement of an English language proficiency test. Lang. Assess. Q. 2022, 19, 54–75. [Google Scholar] [CrossRef]
- Yuksel, D.; Soruc, A.; Altay, M.; Curle, S. A longitudinal study at an English medium instruction university in Turkey: The interplay between English language improvement and academic success. Appl. Linguist. Rev. 2021, 5, 387–402. [Google Scholar] [CrossRef]
- Culbertson, G.; Andersen, E.; Christiansen, M.H. Using utterance recall to assess second language proficiency. Lang. Learn. 2020, 70, 104–132. [Google Scholar] [CrossRef]
- Yeom, S.; Jun, H. Young Korean EFL learners’ reading and test-taking strategies in a paper and a computer-based reading comprehension tests. Lang. Assess. Q. 2020, 17, 282–299. [Google Scholar] [CrossRef]
- Lestari, S.B. English language proficiency testing in Asia: A new paradigm bridging global and local contexts. RELC J. 2021, 53, 757–759. [Google Scholar] [CrossRef]
- Isbell, D.R.; Kremmel, B. Test review: Current options in at-home language proficiency tests for making high-stakes decisions. Lang. Test. 2020, 37, 600–619. [Google Scholar] [CrossRef]
- Ockey, G.J. Developments and challenges in the use of computer-based testing for assessing second language ability. Mod. Lang. J. 2009, 93, 836–847. [Google Scholar] [CrossRef]
- Clark, T.; Endres, H. Computer-based diagnostic assessment of high school students’ grammar skills with automated feedback–An international trial. Assess. Educ. 2021, 28, 602–632. [Google Scholar] [CrossRef]
- Fehr, C.N.; Davison, M.L.; Graves, M.F.; Sales, G.C.; Seipel, B.; Sekhran-Sharma, S. The effects of individualized, online vocabulary instruction on picture vocabulary scores: An efficacy study. Comput. Assist. Lang. Learn. 2012, 25, 87–102. [Google Scholar] [CrossRef]
- Min, S.C.; Aryadoust, V. A systematic review of item response theory in language assessment: Implications for the dimensionality of language ability. Stud. Educ. Eval. 2021, 68, 100963. [Google Scholar] [CrossRef]
- Chang, H.H. Psychometrics behind computerized adaptive testing. Psychometrika 2015, 80, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Kaya, E.; O’Grady, S.; Kalender, I. IRT-based classification analysis of an English language reading proficiency subtest. Lang. Test. 2022, 39, 4. [Google Scholar] [CrossRef]
- Mizumoto, A.; Sasao, Y.; Webb, S.A. Developing and evaluating a computerized adaptive testing version of the word part levels test. Lang. Test. 2019, 36, 101–123. [Google Scholar] [CrossRef]
- Guilera, G.; Gomez, J. Item response theory test equating in health sciences education. Adv. Health Sci. Educ. 2008, 13, 3–10. [Google Scholar] [CrossRef]
- Settles, B.; LaFlair, G.T.; Hagiwara, M. Machine learning-driven language assessment. Trans. Assoc. Comput. Linguist. 2020, 8, 247–263. [Google Scholar] [CrossRef]
- He, L.Z.; Min, S.C. Development and validation of a computer adaptive EFL test. Lang. Assess. Q. 2017, 14, 160–176. [Google Scholar] [CrossRef]
- Brezina, V.; Gablasova, D. Is there a core general vocabulary? Introducing the new general service list. Appl. Lingusit 2015, 36, 1–22. [Google Scholar] [CrossRef]
- Enayat, M.J.; Derakhshan, A. Vocabulary size and depth as predictors of second language speaking ability. System 2021, 99, 102521. [Google Scholar] [CrossRef]
- West, M.P. A General Service List of English Words: With Semantic Frequencies and a Supplementary Word-List for the Writing Of Popular Science and Technology; Longman Green: London, UK, 1953. [Google Scholar]
- Coxhead, A. A new academic word list. Tesol Q. 2000, 34, 213–238. [Google Scholar] [CrossRef]
- Browne, C.; Culligan, B.; Phillips, J. The New General Service List. [Corpus Data]. Available online: http://www.newgeneralservicelist.org (accessed on 10 November 2022).
- Chen, L.C.; Chang, K.H.; Chung, H.Y. A novel statistic-based corpus machine processing approach to refine a big textual data: An ESP case of COVID-19 news reports. Appl. Sci. 2020, 10, 5505. [Google Scholar] [CrossRef]
- TCEEC. The TCEEC Word List [Corpus data]. Available online: https://www.ceec.edu.tw/SourceUse/ce37/ce37.htm (accessed on 10 November 2022).
- Chen, Y.Z. Comparing incidental vocabulary learning from reading-only and reading-while-listening. System 2021, 97, 102442. [Google Scholar] [CrossRef]
- Laufer, B. Lexical thresholds for reading comprehension: What they are and how they can be used for teaching purposes. Tesol Q. 2013, 47, 867–872. [Google Scholar] [CrossRef]
- Nation, I.S.P. How large a vocabulary is needed for reading and listening? Can. Mod. Lang. Rev. 2006, 63, 59–82. [Google Scholar] [CrossRef]
- Du, G.H.; Hasim, Z.; Chew, F.P. Contribution of English aural vocabulary size levels to L2 listening comprehension. IRAL-Int. Rev. Appl. Linguist. Lang. Teach. 2021, 60, 937–956. [Google Scholar] [CrossRef]
- Masrai, A. The development and validation of a lemma-based yes/no vocabulary size test. SAGE Open 2022, 12, 21582440221074355. [Google Scholar] [CrossRef]
- McLean, S.; Stewart, J.; Batty, A.O. Predicting L2 reading proficiency with modalities of vocabulary knowledge: A bootstrapping approach. Lang. Test. 2020, 37, 389–411. [Google Scholar] [CrossRef]
- Fan, N. Strategy use in second language vocabulary learning and its relationships with the breadth and depth of vocabulary knowledge: A structural equation modeling study. Front. Psychol. 2020, 11, 752. [Google Scholar] [CrossRef]
- Chen, L.C.; Chang, K.H.; Yang, S.C. An integrated corpus-based text mining approach used to process military technical information for facilitating EFL troopers’ linguistic comprehension: US anti-tank missile systems as an example. J. Natl. Sci. Found. Sri Lanka 2021, 49, 403–417. [Google Scholar] [CrossRef]
- Qian, D.D. Investigating the relationship between vocabulary knowledge and academic reading performance: An assessment perspective. Lang. Learn. 2002, 52, 513–536. [Google Scholar] [CrossRef]
- Nation, I.S.P. Learning Vocabulary in Another Language; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Hsu, W.H. The vocabulary thresholds of business textbooks and business research articles for EFL learners. Engl. Specif. Purp. 2011, 30, 247–257. [Google Scholar] [CrossRef]
- Nation, I.S.P.; Heatley, A. RANGE [Computer software]. Available online: http://www.vuw.ac.nz/lals/staff/paul-nation/nation.aspx (accessed on 15 November 2022).
- Durrant, P. To what extent is the academic vocabulary list relevant to university student writing? Engl. Specif. Purp. 2016, 43, 49–61. [Google Scholar] [CrossRef]
- Gardner, D.; Davies, M. A new academic vocabulary list. Appl. Lingusit 2014, 35, 305–327. [Google Scholar] [CrossRef]
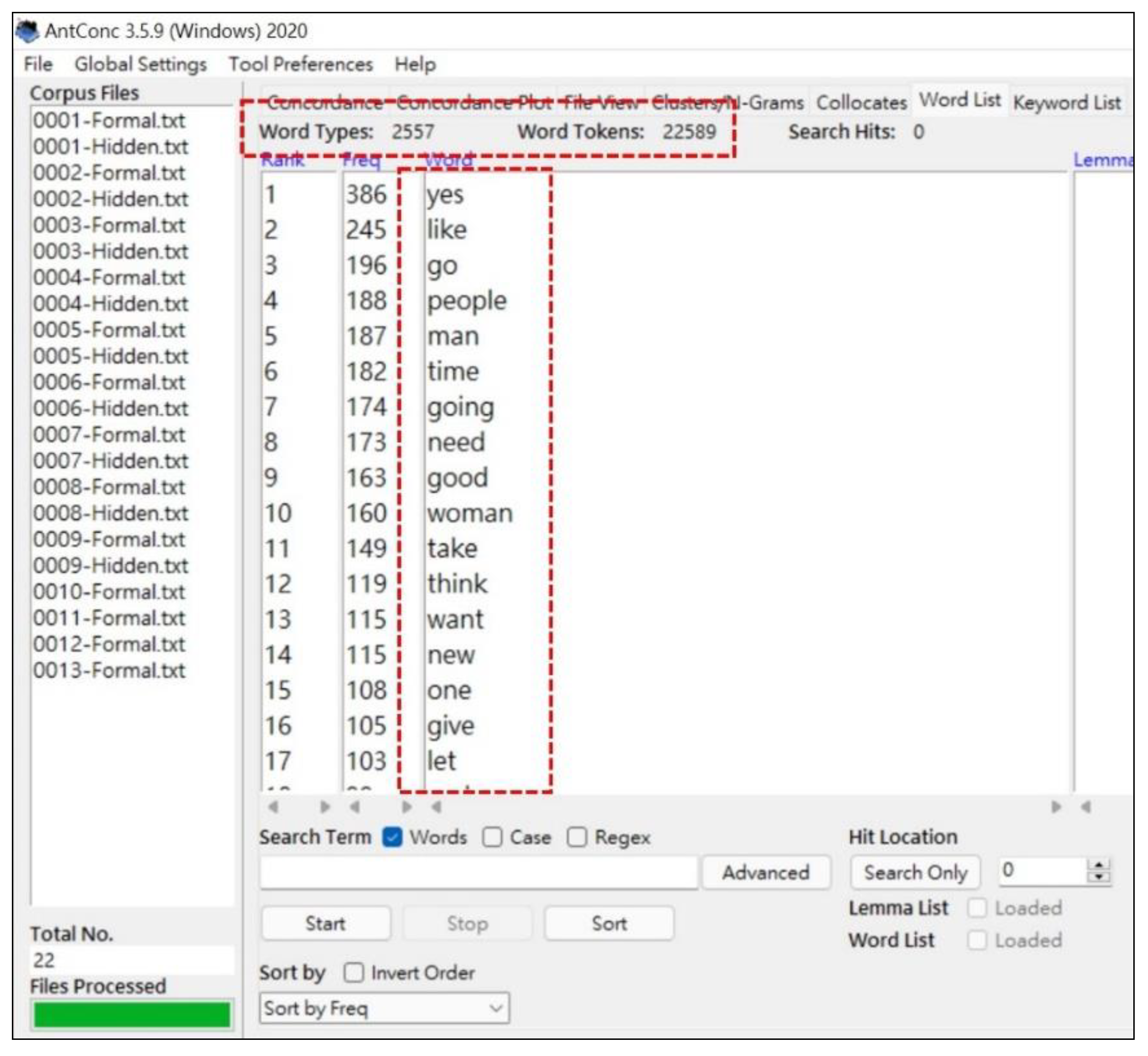
- Anthony, L. AntConc (Version 3.5.9) [Computer Software]. Available online: https://www.laurenceanthony.net/software/antconc/ (accessed on 1 November 2022).
- Munoz, V.L. The vocabulary of agriculture semi-popularization articles in English: A corpus-based study. Engl. Specif. Purp. 2015, 39, 26–44. [Google Scholar] [CrossRef]
- Chen, L.C.; Chang, K.H. A novel corpus-based computing method for handling critical word ranking issues: An example of COVID-19 research articles. Int. J. Intell. Syst. 2021, 36, 3190–3216. [Google Scholar] [CrossRef]
- Shih, C.M. The general English proficiency test. Lang. Assess. Q. 2008, 5, 63–76. [Google Scholar] [CrossRef]
- Kim, C.; Lee, S.Y.; Park, S.H. Is Korea ready to be a key player in the medical tourism industry? An English education perspective. Iran J. Public Health 2020, 49, 267–273. [Google Scholar] [CrossRef]
- Nguyen, V.T. Towards a New Paradigm for English Language Teaching: English for Specific Purposes in Asia and Beyond; Routledge: Oxfordshire, UK, 2022. [Google Scholar]
- Pu, S.; Yan, Y.; Zhang, L. Peers, study effort, and academic performance in college education: Evidence from randomly assigned roommates in a flipped classroom. Res. High. Educ. 2020, 61, 248–269. [Google Scholar] [CrossRef]
- Skrabankova, J.; Popelka, S.; Beitlova, M. Students’ ability to work with graphs in physics studies related to three typical student groups. J. Balt. Sci. Educ. 2020, 19, 298–316. [Google Scholar] [CrossRef]
- Cheng, J.Y.; Matthews, J. The relationship between three measures of L2 vocabulary knowledge and L2 listening and reading. Lang. Test. 2018, 35, 3–25. [Google Scholar] [CrossRef]
- Dong, Y.; Tang, Y.; Chow, B.W.Y.; Wang, W.S.; Dong, W.Y. Contribution of vocabulary knowledge to reading comprehension among Chinese students: A meta-analysis. Front. Psychol. 2020, 11, 525369. [Google Scholar] [CrossRef] [PubMed]
- Ali, M.M.; Hamid, M.O. Teaching English to the test: Why does negative washback exist within secondary education in Bangladesh? Lang. Assess. Q. 2020, 17, 129–146. [Google Scholar] [CrossRef]
- Chen, Y.C. Assessing the lexical richness of figurative expressions in Taiwanese EFL learners’ writing. Assess. Writ. 2020, 43, 7–18. [Google Scholar] [CrossRef]
- Jiang, L.J.; Yu, S.L. Appropriating automated feedback in L2 writing: Experiences of Chinese EFL student writers. Comput. Assist. Lang. Learn. 2020, 35, 1329–1353. [Google Scholar] [CrossRef]
- Nghia, T.L.H. “It is complicated!”: Practices and challenges of generic skills assessment in Vietnamese universities. Educ. Stud. 2018, 44, 230–246. [Google Scholar] [CrossRef]
- Santucci, V.; Santarelli, F.; Forti, L.; Spina, S. Automatic Classification of Text Complexity. Appl. Sci. 2020, 10, 7285. [Google Scholar] [CrossRef]
- Forti, L.; Bolli, G.G.; Santarelli, F.; Santucci, V.; Spina, S. MALT-IT2: A New Resource to Measure Text Difficulty in Light of CEFR Levels for Italian L2 Learning. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2016; The European Language Resources Association (ELRA): Paris, France, 2020; pp. 7204–7211. [Google Scholar]
- Santucci, V.; Bartoccini, U.; Mengoni, P.; Zanda, F. A Computational Measure for the Semantic Readability of Segmented Texts. In International Conference on Computational Science and Its Applications; Springer: Cham, Switzerland, 2022; pp. 107–119. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Word Classification Criteria | Word Types | Word Types Proportions | Tokens | Lexical Coverage |
|---|---|---|---|---|
| The function words | 237 | 4.34% | 49,190 | 61.85% |
| CEFR A2 level words | 2557 | 46.79% | 22,589 | 28.4% |
| CEFR B1 level words | 1937 | 35.44% | 5914 | 7.44% |
| Other EGP words | 405 | 7.41% | 760 | 1% |
| Name | 186 | 3.4% | 683 | 0.9% |
| Country/Location | 109 | 1.99% | 308 | 0.4% |
| Military | 27 | 0.49% | 70 | 0.09% |
| Medical | 7 | 0.13% | 12 | 0.02% |
| Total | 5465 | 100% | 79,526 | 100% |
| Word Classification Criteria | Word Types | Word Types Proportions | Tokens | Lexical Coverage |
|---|---|---|---|---|
| CEFR A2 level words | 2557 | 48.91% | 22,589 | 74.46% |
| CEFR B1 level words | 1937 | 37.05% | 5914 | 19.49% |
| Other EGP words | 405 | 7.75% | 760 | 2.51% |
| Name | 186 | 3.56% | 683 | 2.25% |
| Country/Location | 109 | 2.08% | 308 | 1.02% |
| Military | 27 | 0.52% | 70 | 0.23% |
| Medical | 7 | 0.13% | 12 | 0.04% |
| Total | 5228 | 100% | 30,336 | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.-C.; Chang, K.-H.; Yang, S.-C.; Chen, S.-C. A Corpus-Based Word Classification Method for Detecting Difficulty Level of English Proficiency Tests. Appl. Sci. 2023, 13, 1699. https://doi.org/10.3390/app13031699
Chen L-C, Chang K-H, Yang S-C, Chen S-C. A Corpus-Based Word Classification Method for Detecting Difficulty Level of English Proficiency Tests. Applied Sciences. 2023; 13(3):1699. https://doi.org/10.3390/app13031699
Chicago/Turabian StyleChen, Liang-Ching, Kuei-Hu Chang, Shu-Ching Yang, and Shin-Chi Chen. 2023. "A Corpus-Based Word Classification Method for Detecting Difficulty Level of English Proficiency Tests" Applied Sciences 13, no. 3: 1699. https://doi.org/10.3390/app13031699
APA StyleChen, L.-C., Chang, K.-H., Yang, S.-C., & Chen, S.-C. (2023). A Corpus-Based Word Classification Method for Detecting Difficulty Level of English Proficiency Tests. Applied Sciences, 13(3), 1699. https://doi.org/10.3390/app13031699