
Frequency-Based Adaptive Interpolation Filter in Intra Prediction


Abstract
1. Introduction
2. Previous Works
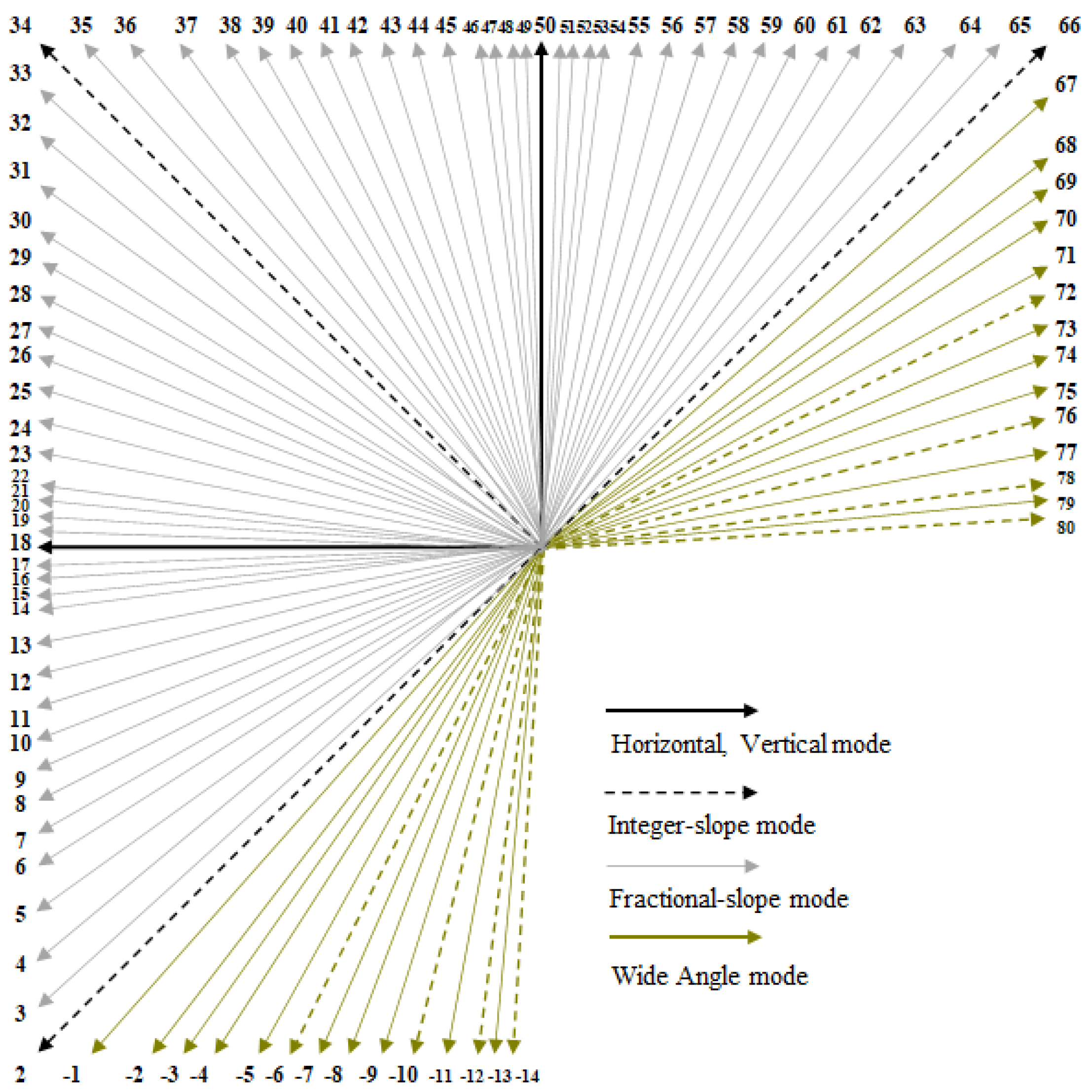
2.1. An Overview of Reference Sample Filtering for Video Coding Standards
2.2. Related Studies
3. Proposed Method
3.1. Design of 8-Tap Interpolation Filter
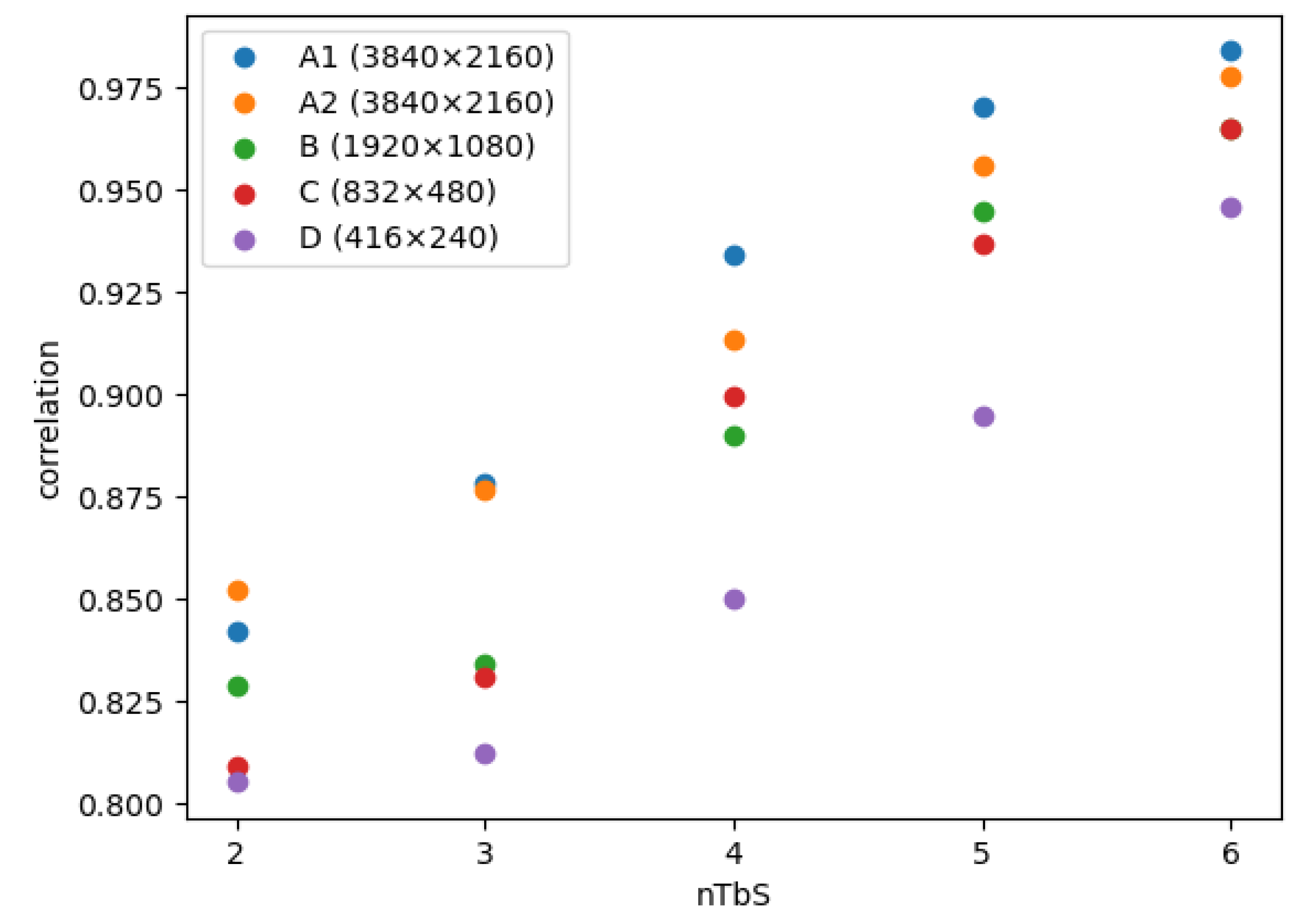
3.2. Frequency-Based Adaptive Interpolation Filter Selection
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bross, B.; Chen, J.; Liu, S.; Wang, Y.-K. Versatile Video Coding (Draft 10), document JVET-T2001, Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29. In Proceedings of the 20th JVET Meeting, Online, 7–16 October 2020. [Google Scholar]
- H.264 and ISO/IEC 14496-10; Advanced Video Coding (AVC), Standard ITU-T Recommendation. ITU-T: Geneva, Switzerland, 2003. Available online: https://www.itu.int/ITU-T/recommendations/rec.aspx?rec=6312 (accessed on 20 January 2023).
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H.264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef]
- High Efficient Video Coding (HEVC), Standard ITU-T Recommendation, H.265 and ISO/IEC 23008-2, April 2013. Available online: https://www.itu.int/rec/T-REC-H.265 (accessed on 28 April 2022).
- Sze, V.; Budagavi, M.; Sullivan, G.J. High Efficiency Video Coding: Algorithms and Architectures; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Wien, M. High Efficiency Video Coding: Coding Tools and Specification; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Sullivan, G.J.; Ohm, J.; Han, W.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Bossen, F.; Li, X.; Suehring, K. AHG Report: Test Model Software Development (AHG3), document JVET-S0003, Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11. In Proceedings of the 19th JVET Meeting, Online, 22 June–1 July 2020. [Google Scholar]
- Browne, A.; Chen, J.; Ye, Y.; Kim, S.H. Algorithm description for Versatile Video Coding and Test Model 14 (VTM 14), document JVET-W2002, Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29. In Proceedings of the 23rd JVET Meeting, Online, 7–16 July 2021. [Google Scholar]
- Bross, B.; Wang, Y.-K.; Ye, Y.; Liu, S.; Chen, J.; Sullivan, G.J.; Ohm, J.-R. Overview of the Versatile Video Coding (VVC) Standard and its Applications. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3736–3764. [Google Scholar] [CrossRef]
- Huang, Y.-W.; An, J.; Haung, H.; Li, X.; Hsiang, S.-T.; Zhang, K.; Gao, H.; Ma, J.; Chubach, O. Block Partitioning Structure in the VVC Standard. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3818–3833. [Google Scholar] [CrossRef]
- Pfaff, J.; Filippov, A.; Liu, S.; Zhao, X.; Chen, J.; De-Luxán-Hernández, S.; Wiegand, T.; Rufitskiy, V.; Ramasubramonian, A.K.; Van der Auwera, G. Intra Prediction and Mode Coding in VVC. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3834–3847. [Google Scholar] [CrossRef]
- Chien, W.-J.; Zhang, L.; Winken, M.; Li, X.; Liao, R.-L.; Gao, H.; Hsu, C.-W.; Liu, H.; Chen, C.-C. Motion Vector Coding and Block Merging in the Versatile Video Coding Standard. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3848–3861. [Google Scholar] [CrossRef]
- Yang, H.; Chen, H.; Chen, J.; Esenlik, S.; Sethuraman, S.; Xiu, X.; Alshina, E.; Luo, J. Subblock-Based Motion Derivation and Inter Prediction Refinement in the Versatile Video Coding Standard. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3862–3877. [Google Scholar] [CrossRef]
- Zhao, X.; Kim, S.-H.; Zhao, Y.; Egilmez, H.E.; Koo, M.; Liu, S.; Lainema, J.; Karczewicz, M. Transform Coding in the VVC Standard. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3878–3890. [Google Scholar] [CrossRef]
- Schwarz, H.; Coban, M.; Karczewicz, M.; Chuang, T.-D.; Bossen, F.; Alshin, A.; Lainema, J.; Helmrich, C.R.; Wiegand, T. Quantization and Entropy Coding in the Versatile Video Coding (VVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3891–3906. [Google Scholar] [CrossRef]
- Ugur, K.; Alshin, A.; Alshina, E.; Bossen, F.; Han, W.-J.; Park, J.-H.; Lainema, J. Interpolation filter design in HEVC and its coding efficiency-complexity analysis. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Lainema, J.; Bossen, F.; Han, W.-J.; Min, J.; Ugur, K. Intra coding of the HEVC standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1792–1801. [Google Scholar] [CrossRef]
- Filippov, A.; Rufitskiy, V. Non-CE3: Cleanup of Interpolation Filtering for Intra Prediction, document JVET-P0599, Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11. In Proceedings of the 16th JVET Meeting, Geneva, Switzerland, 1–11 October 2019. [Google Scholar]
- Filippov, A.; Rufitskiy, V.; Chen, J.; Van der Auwera, G.; Ramasubramonian, A.K.; Seregin, V.; Hsieh, T.; Karczewicz, M. CE3: A Combination of Tests 3.1.2 and 3.1.4 for Intra Reference Sample Interpolation Filter, document JVET-L0628, Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11. In Proceedings of the 12th JVET Meeting, Macao, China, 3–12 October 2018. [Google Scholar]
- Filippov, A.; Rufitskiy, V.; Chen, J.; Alshina, E. Intra prediction in the emerging VVC video coding standard. In Proceedings of the 2020 Data Compression Conference (DCC), Snowbird, UT, USA, 24–27 March 2020. [Google Scholar]
- Matsuo, S.; Takamura, S.; Jozawa, H. Improved intra angular prediction by DCT-based interpolation filter. In Proceedings of the 2012 Proceedings of the 20th European Signal Processing Conference (EUSIPCO), Bucharest, Romania, 27–31 August 2012. [Google Scholar]
- Kim, M.; Lee, Y.-L. Discrete Sine Transform-Based Interpolation Filter for Video Compression. Symmetry 2017, 9, 257. [Google Scholar] [CrossRef]
- Zhao, X.; Seregin, V.; Karczewicz, M. Six tap intra interpolation filter, document JVET-D0119, Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11. In Proceedings of the 4th JVET Meeting, Chengdu, China, 15–21 October 2016. [Google Scholar]
- Chang, Y.-J.; Chen, C.-C.; Chen, J.; Dong, J.; Egilmez, H.E.; Hu, N.; Haung, H.; Karczewicz, M.; Li, J.; Ray, B.; et al. Compression efficiency methods beyond VVC, document JVET-U0100, Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29. In Proceedings of the 21st JVET Meeting, Online, 6–15 January 2021. [Google Scholar]
- Kim, J.; Kim, Y.-H. Adaptive Boundary Filtering Strategies in VVC Intra-Prediction for Depth Video Coding. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Gangwon, Korea, 1–3 November 2021. [Google Scholar]
- Henkel, A.; Zupancic, I.; Bross, B.; Winken, M.; Schwarz, H.; Marpe, D.; Wiegand, T. Alternative Half-Sample Interpolation Filters for Versatile Video Coding. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Kidani, Y.; Kawamura, K.; Unno, K.; Naito, S. Blocksize-QP Dependent Intra Interpolation Filters. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019. [Google Scholar]
- Chiang, C.-H.; Han, J.; Vitvitskyy, S.; Mukherjee, D.; Xu, Y. Adaptive interpolation filter scheme in AV1. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Pham, C.D.-K.; Zhou, J. Deep Learning-Based Luma and Chroma Fractional Interpolation in Video Coding. IEEE Access 2019, 7, 112535–112543. [Google Scholar] [CrossRef]
- Yan, N.; Liu, D.; Li, H.; Li, B.; Li, L.; Wu, F. Invertibility-Driven Interpolation Filter for Video Coding. IEEE Trans. Image Process. 2019, 28, 4912–4925. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.; Chen, J.; Sun, H.; Katto, J.; Jing, M. A Fast QTMT Partition Decision Strategy for VVC Intra Prediction. IEEE Access 2020, 8, 107900–107911. [Google Scholar] [CrossRef]
- Li, W.; Fan, C.; Ren, P. Fast Intra-Picture Partitioning for Versatile Video Coding. In Proceedings of the 2020 IEEE 5th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 23–25 October 2020. [Google Scholar]
- Saldanha, M.; Sanchez, G.; Marcon, C.; Agostini, L. Analysis of VVC Intra Prediction Block Partitioning Structure. In Proceedings of the 2021 International Conference on Visual Communications and Image Processing (VCIP), Munich, Germany, 5–8 December 2021. [Google Scholar]
- Bjøntegaard, G. Calculation of Average PSNR Differences Between RD-Curves, document VCEG-M33, ITU-T SG 16 Q 6 Video Coding Experts Group (VCEG). In Proceedings of the 13th VCEG Meeting, Austin, TX, USA, 2–4 April 2001. [Google Scholar]
- Bjøntegaard, G. Improvements of the BD-PSNR Model, document VCEG-AI11, ITU-T SG 16 Q 6 Video Coding Experts Group (VCEG). In Proceedings of the 35th VCEG Meeting, Berlin, Germany, 16–18 July 2008. [Google Scholar]
- Versatile Video Coding Test Model (VTM-14.2) Reference Software. Available online: https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware_VTM/tags/VTM-14.2 (accessed on 9 November 2021).
- Bossen, F.; Boyce, J.; Suehring, K.; Li, X.; Seregin, V. JVET common test conditions and software reference configurations for SDR video, document JVET-T2010, Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29. In Proceedings of the 20th JVET Meeting, Online, 7–16 October 2020. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index i | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 0/32-pixel filter[i] | 0 | 64 | 0 | 0 |
| 1/32-pixel filter[i] | −1 | 63 | 2 | 0 |
| 2/32-pixel filter[i] | −2 | 62 | 4 | 0 |
| 3/32-pixel filter[i] | −2 | 60 | 7 | −1 |
| 4/32-pixel filter[i] | −2 | 58 | 10 | −2 |
| 5/32-pixel filter[i] | −3 | 57 | 12 | −2 |
| 6/32-pixel filter[i] | −4 | 56 | 14 | −2 |
| 7/32-pixel filter[i] | −4 | 55 | 15 | −2 |
| 8/32-pixel filter[i] | −4 | 54 | 16 | −2 |
| 9/32-pixel filter[i] | −5 | 53 | 18 | −2 |
| 10/32-pixel filter[i] | −6 | 52 | 20 | −2 |
| 11/32-pixel filter[i] | −6 | 49 | 24 | −3 |
| 12/32-pixel filter[i] | −6 | 46 | 28 | −4 |
| 13/32-pixel filter[i] | −5 | 44 | 29 | −4 |
| 14/32-pixel filter[i] | −4 | 42 | 30 | −4 |
| 15/32-pixel filter[i] | −4 | 39 | 33 | −4 |
| 16/32-pixel filter[i] | −4 | 36 | 36 | −4 |
| Index i | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 0/32-pixel filter[i] | 16 | 32 | 16 | 0 |
| 1/32-pixel filter[i] | 16 | 32 | 16 | 0 |
| 2/32-pixel filter[i] | 15 | 31 | 17 | 1 |
| 3/32-pixel filter[i] | 15 | 31 | 17 | 1 |
| 4/32-pixel filter[i] | 14 | 30 | 18 | 2 |
| 5/32-pixel filter[i] | 14 | 30 | 18 | 2 |
| 6/32-pixel filter[i] | 13 | 29 | 19 | 3 |
| 7/32-pixel filter[i] | 13 | 29 | 19 | 3 |
| 8/32-pixel filter[i] | 12 | 28 | 20 | 4 |
| 9/32-pixel filter[i] | 12 | 28 | 20 | 4 |
| 10/32-pixel filter[i] | 11 | 27 | 21 | 5 |
| 11/32-pixel filter[i] | 11 | 27 | 21 | 5 |
| 12/32-pixel filter[i] | 10 | 26 | 22 | 6 |
| 13/32-pixel filter[i] | 10 | 26 | 22 | 6 |
| 14/32-pixel filter[i] | 9 | 25 | 23 | 7 |
| 15/32-pixel filter[i] | 9 | 25 | 23 | 7 |
| 16/32-pixel filter[i] | 8 | 24 | 24 | 8 |
| nTbS | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|
| intraHorVerDistThres[nTbS] | 24 | 14 | 2 | 0 | 0 |
| Index i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 0/32-pixel filter[i] | 0 | 0 | 0 | 128 | 0 | 0 | 0 | 0 |
| 1/32-pixel filter[i] | 0 | 1 | −3 | 127 | 4 | −2 | 1 | 0 |
| 2/32-pixel filter[i] | −1 | 3 | −7 | 127 | 8 | −4 | 2 | 0 |
| 3/32-pixel filter[i] | −1 | 4 | −10 | 126 | 13 | −6 | 3 | −1 |
| 4/32-pixel filter[i] | −1 | 5 | −12 | 124 | 17 | −7 | 3 | −1 |
| 5/32-pixel filter[i] | −2 | 6 | −15 | 122 | 23 | −9 | 4 | −1 |
| 6/32-pixel filter[i] | −2 | 7 | −17 | 120 | 28 | −11 | 5 | −2 |
| 7/32-pixel filter[i] | −2 | 8 | −19 | 117 | 33 | −13 | 6 | −2 |
| 8/32-pixel filter[i] | −3 | 9 | −21 | 114 | 38 | −14 | 7 | −2 |
| 9/32-pixel filter[i] | −3 | 9 | −22 | 111 | 43 | −16 | 8 | −2 |
| 10/32-pixel filter[i] | −3 | 10 | −23 | 107 | 49 | −18 | 8 | −2 |
| 11/32-pixel filter[i] | −3 | 10 | −24 | 104 | 54 | −19 | 9 | −3 |
| 12/32-pixel filter[i] | −3 | 11 | −24 | 99 | 59 | −20 | 9 | −3 |
| 13/32-pixel filter[i] | −3 | 11 | −25 | 95 | 65 | −22 | 10 | −3 |
| 14/32-pixel filter[i] | −3 | 11 | −25 | 90 | 70 | −22 | 10 | −3 |
| 15/32-pixel filter[i] | −3 | 11 | −24 | 85 | 75 | −23 | 10 | −3 |
| 16/32-pixel filter[i] | −3 | 11 | −24 | 80 | 80 | −24 | 11 | −3 |
| Index i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 0/32-pixel filter[i] | 4 | 24 | 60 | 80 | 60 | 24 | 4 | 0 |
| 1/32-pixel filter[i] | 4 | 24 | 60 | 80 | 60 | 24 | 4 | 0 |
| 2/32-pixel filter[i] | 4 | 23 | 58 | 79 | 61 | 26 | 5 | 0 |
| 3/32-pixel filter[i] | 4 | 23 | 58 | 79 | 61 | 26 | 5 | 0 |
| 4/32-pixel filter[i] | 3 | 21 | 58 | 78 | 62 | 28 | 6 | 0 |
| 5/32-pixel filter[i] | 3 | 21 | 58 | 78 | 62 | 28 | 6 | 0 |
| 6/32-pixel filter[i] | 3 | 20 | 53 | 76 | 64 | 31 | 8 | 1 |
| 7/32-pixel filter[i] | 3 | 20 | 53 | 76 | 64 | 31 | 8 | 1 |
| 8/32-pixel filter[i] | 3 | 19 | 51 | 75 | 65 | 33 | 9 | 1 |
| 9/32-pixel filter[i] | 3 | 19 | 51 | 75 | 65 | 33 | 9 | 1 |
| 10/32-pixel filter[i] | 3 | 18 | 49 | 74 | 66 | 35 | 10 | 1 |
| 11/32-pixel filter[i] | 3 | 18 | 49 | 74 | 66 | 35 | 10 | 1 |
| 12/32-pixel filter[i] | 3 | 17 | 47 | 73 | 67 | 37 | 11 | 1 |
| 13/32-pixel filter[i] | 3 | 17 | 47 | 73 | 67 | 37 | 11 | 1 |
| 14/32-pixel filter[i] | 2 | 15 | 44 | 71 | 69 | 40 | 13 | 2 |
| 15/32-pixel filter[i] | 2 | 15 | 44 | 71 | 69 | 40 | 13 | 2 |
| 16/32-pixel filter[i] | 2 | 14 | 42 | 70 | 70 | 42 | 14 | 2 |
| nTbS | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|
| Filter Selection Method | high_freq_ratio | VVC Method | VVC Method | high_freq_ratio | high_freq_ratio |
| high_freq_ratio < THR | 4-tap SIF | - | - | 8-tap SIF | 8-tap SIF |
| high_freq_ratio ≥ THR | 8-tap DCT-IF | - | - | 4-tap DCT-IF | 4-tap DCT-IF |
| Class | Sequence Name | Picture Size | Picture Count | Picture Rate | Bit Depth |
|---|---|---|---|---|---|
| A1 | Tango2 | 3840 × 2160 | 294 | 60 | 10 |
| FoodMarket4 | 3840 × 2160 | 300 | 60 | 10 | |
| Campfire | 3840 × 2160 | 300 | 30 | 10 | |
| A2 | CatRobot1 | 3840 × 2160 | 300 | 60 | 10 |
| DaylightRoad2 | 3840 × 2160 | 300 | 60 | 10 | |
| ParkRunning3 | 3840 × 2160 | 300 | 50 | 10 | |
| B | MarketPlace | 1920 × 1080 | 600 | 60 | 10 |
| RitualDance | 1920 × 1080 | 600 | 60 | 10 | |
| Cactus | 1920 × 1080 | 500 | 50 | 8 | |
| BasketballDrive | 1920 × 1080 | 500 | 50 | 8 | |
| BQTerrace | 1920 × 1080 | 600 | 60 | 8 | |
| C | RaceHorses | 832 × 480 | 300 | 30 | 8 |
| BQMall | 832 × 480 | 600 | 60 | 8 | |
| PartyScene | 832 × 480 | 500 | 50 | 8 | |
| BasketballDrill | 832 × 480 | 500 | 50 | 8 | |
| D | RaceHorses | 416 × 240 | 300 | 30 | 8 |
| BQSquare | 416 × 240 | 600 | 60 | 8 | |
| BlowingBubbles | 416 × 240 | 500 | 50 | 8 | |
| BasketballPass | 416 × 240 | 500 | 50 | 8 |
| nTbS | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|
| Method A | 8-tap DCT-IF | 4-tap DCT-IF, 4-tap SIF | 4-tap DCT-IF, 4-tap SIF | 4-tap SIF | 4-tap SIF |
| Method B | 4-tap DCT-IF | 4-tap DCT-IF, 4-tap SIF | 4-tap DCT-IF, 4-tap SIF | 8-tap SIF | 8-tap SIF |
| Filter Selection Method | VVC Method | VVC Method | VVC Method | VVC Method | VVC Method |
| Method C | 8-tap DCT-IF, 4-tap SIF | 4-tap DCT-IF, 4-tap SIF | 4-tap DCT-IF, 4-tap SIF | 4-tap SIF | 4-tap SIF |
| Filter Selection Method | high_freq_ratio | VVC Method | VVC Method | VVC Method | VVC Method |
| Method D | 4-tap DCT-IF | 4-tap DCT-IF, 4-tap SIF | 4-tap DCT-IF, 4-tap SIF | 8-tap SIF, 4-tap DCT-IF | 8-tap SIF, 4-tap DCT-IF |
| Filter Selection Method | VVC Method | VVC Method | VVC Method | high_freq_ratio | high_freq_ratio |
| Sequence | All Intra Main 10 | |||||
|---|---|---|---|---|---|---|
| Method A | Method B | |||||
| Y | Cb | Cr | Y | Cb | Cr | |
| Class A1 | 0.01% | −0.06% | 0.06% | −0.08% | −0.20% | −0.15% |
| Class A2 | 0.02% | −0.03% | −0.02% | −0.01% | 0.00% | −0.04% |
| Class B | −0.01% | 0.04% | −0.01% | −0.01% | 0.05% | −0.05% |
| Class C | −0.33% | −0.22% | −0.27% | 0.00% | −0.02% | 0.07% |
| Class D | −0.28% | −0.32% | −0.15% | −0.01% | −0.07% | 0.03% |
| Overall | −0.13% | −0.12% | −0.08% | −0.02% | −0.03% | −0.02% |
| Sequence | All Intra Main 10 | |||||
|---|---|---|---|---|---|---|
| Method C | Method D | |||||
| Y | Cb | Cr | Y | Cb | Cr | |
| Class A1 | 0.01% | −0.18% | 0.05% | −0.09% | −0.10% | −0.02% |
| Class A2 | 0.02% | 0.08% | 0.00% | 0.00% | 0.04% | −0.04% |
| Class B | 0.01% | 0.09% | 0.01% | 0.01% | 0.02% | 0.05% |
| Class C | −0.40% | −0.22% | −0.36% | 0.01% | 0.03% | 0.02% |
| Class D | −0.30% | −0.25% | −0.23% | −0.01% | −0.06% | 0.08% |
| Overall | −0.14% | −0.09% | −0.11% | −0.01% | −0.01% | 0.03% |
| All Intra Main 10 | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| W | VVC Anchor | VVC Anchor with MRL and ISP | Adaptive Filter Method Based on high_freq_ratio (Proposed Method) | |||||||||||||
| H | 4 | 8 | 16 | 32 | 64 | 4 | 8 | 16 | 32 | 64 | 4 | 8 | 16 | 32 | 64 | |
| 4 | 100.00 | 100.00 | 85.67 | 94.70 | — | 100.00 | 100.00 | 82.25 | 89.16 | — | 97.16 | 95.80 | 91.11 | 97.27 | — | |
| 8 | 100.00 | 87.89 | 81.99 | 25.68 | — | 100.00 | 91.35 | 81.42 | 44.36 | — | 96.77 | 91.36 | 86.69 | 53.43 | — | |
| 16 | 87.38 | 83.20 | 8.32 | 17.24 | — | 86.26 | 82.59 | 19.35 | 27.85 | 100.00 | 92.62 | 86.76 | 19.83 | 33.13 | 0.04 | |
| 32 | 94.01 | 19.98 | 14.73 | 0.00 | — | 90.45 | 36.35 | 23.17 | 10.59 | — | 97.06 | 42.55 | 27.34 | 0.07 | — | |
| 64 | — | — | — | — | 0.00 | — | — | 100.00 | — | 5.56 | — | — | 0.07 | — | 0.07 | |
| Adaptive Filter Method Based on high_freq_ratio (Proposed Method) | ||||||
|---|---|---|---|---|---|---|
| Class | Sequence Name | Y | Cb | Cr | EncT | DecT |
| A1 | Tango2 | −0.11% | −0.36% | −0.09% | 102% | 103% |
| FoodMarket4 | −0.11% | −0.06% | −0.22% | 102% | 106% | |
| Campfire | 0.02% | 0.01% | 0.17% | 102% | 103% | |
| A2 | CatRobot1 | −0.01% | 0.03% | 0.07% | 101% | 106% |
| DaylightRoad2 | 0.03% | 0.34% | 0.13% | 103% | 105% | |
| ParkRunning3 | −0.01% | −0.01% | 0.01% | 101% | 103% | |
| B | MarketPlace | −0.01% | −0.02% | −0.13% | 102% | 108% |
| RitualDance | −0.01% | 0.08% | 0.02% | 103% | 104% | |
| Cactus | 0.00% | −0.02% | 0.27% | 102% | 105% | |
| BasketballDrive | 0.03% | 0.04% | −0.05% | 102% | 108% | |
| BQTerrace | 0.06% | 0.00% | 0.10% | 102% | 108% | |
| C | BasketballDrill | −1.20% | −0.78% | −0.68% | 101% | 110% |
| BQMall | −0.18% | −0.26% | −0.12% | 101% | 106% | |
| PartyScene | −0.16% | −0.21% | −0.16% | 102% | 109% | |
| RaceHorses | −0.08% | −0.04% | −0.20% | 103% | 103% | |
| D | BasketballPass | −0.29% | −0.25% | −0.42% | 102% | 104% |
| BQSquare | −0.55% | −0.62% | −0.21% | 101% | 105% | |
| BlowingBubbles | −0.19% | −0.02% | −0.14% | 101% | 104% | |
| RaceHorses | −0.23% | −0.26% | 0.03% | 101% | 103% | |
| Class A1 | −0.07% | −0.14% | −0.05% | 102% | 104% | |
| Class A2 | 0.00% | 0.12% | 0.07% | 102% | 105% | |
| Class B | 0.02% | 0.01% | 0.04% | 102% | 107% | |
| Class C | −0.41% | −0.32% | −0.29% | 101% | 107% | |
| Class D | −0.31% | −0.29% | −0.18% | 101% | 104% | |
| Overall | −0.16% | −0.13% | −0.09% | 102% | 105% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, S.-Y.; Choi, M.-K.; Lee, Y.-L. Frequency-Based Adaptive Interpolation Filter in Intra Prediction. Appl. Sci. 2023, 13, 1475. https://doi.org/10.3390/app13031475
Lim S-Y, Choi M-K, Lee Y-L. Frequency-Based Adaptive Interpolation Filter in Intra Prediction. Applied Sciences. 2023; 13(3):1475. https://doi.org/10.3390/app13031475
Chicago/Turabian StyleLim, Su-Yeon, Min-Kyeong Choi, and Yung-Lyul Lee. 2023. "Frequency-Based Adaptive Interpolation Filter in Intra Prediction" Applied Sciences 13, no. 3: 1475. https://doi.org/10.3390/app13031475
APA StyleLim, S.-Y., Choi, M.-K., & Lee, Y.-L. (2023). Frequency-Based Adaptive Interpolation Filter in Intra Prediction. Applied Sciences, 13(3), 1475. https://doi.org/10.3390/app13031475