Optimal Training Dataset Preparation for AI-Supported Multilanguage Real-Time OCRs Using Visual Methods




Abstract
:1. Introduction
- RQ 1: What are the most effective strategies for creating a synthetic training dataset that accurately captures the intricacies of multilanguage OCR, particularly when dealing with context-sensitive languages alongside Latin and Anglo-Saxon language families? Rationale: This RQ addresses the fundamental challenge of preparing an optimal training dataset that accommodates a diverse set of languages, including those with varying contextual dependencies. Based on our research experiments conducted using a convolutional recurrent neural network (CRNN) and scene text recognition with a single visual model for scene text recognition (SVTR) models with PaddleOCR, the need for specific strategies to capture nuances in languages such as Chinese or Japanese (context-sensitive) and English/Hungarian (Anglo-Saxon/Latin) was recognized within a single OCR system for collaborative on-screen solutions.
- RQ 2: How can the variability of fonts, writing styles, and document layouts be systematically incorporated into the generation of synthetic training data to ensure the robustness of a multilanguage OCR system? Rationale: This question delves into the critical issue of accommodating diversity in fonts, writing styles, and document layouts within a synthetic dataset. Addressing this challenge is crucial for training an OCR system that can effectively handle visual heterogeneity across languages and document types.
- RQ 3: What are the optimal techniques for metadata-based quality control in the context of a multilanguage OCR training dataset, and how can these techniques be applied efficiently for languages with distinct linguistic features? Rationale: This question focuses on the often overlooked aspect of the advanced level of quality control in multilanguage OCR training datasets. It emphasizes the need for tailored techniques that consider the linguistic peculiarities of each language, ensuring high-quality annotation methods across diverse linguistic backgrounds.
- RQ 4: What methods and standards can be set up to thoroughly test the precision, dependability, and effectiveness of AI-powered real-time multilanguage OCR systems, taking into account the complexity of synthesized languages and different language families? Rationale: This question addresses the crucial aspect of evaluation in the context of multilanguage OCR systems. It stresses the need for standardized testing methods and standards that take into account the difficulties that come with mixed languages and different types of language so that the performance evaluations of OCR systems can be trusted and compared.
- RQ 5: What are the effective adaptation and fine-tuning techniques for deep learning models, specifically SVTR and CRNNs, to address the challenges of multilanguage OCR? Furthermore, what strategies can be employed to optimize the performance of these models for real-time on-screen OCR in collaborative environments? The purpose of this inquiryis to examine the process of adapting and optimizing deep learning models, namely SVTR and CRNN, for the purpose of performing multilanguage OCR jobs. The statement recognizes the necessity of adapting models to suit the complexities of various languages and the demands of real-time, collaborative on-screen OCR applications.
1.1. Steps of Training Dataset Generation
- Text Generation Process: The first step is to generate the text that will be used in the synthetic images. This can be done by using natural language processing techniques such as language models or by collecting and curating text datasets for each language.
- Font Generation Process: To generate realistic synthetic images, it is important to use fonts that are representative of the languages and writing systems. There are several methods for creating fonts, including the use of generative adversarial networks (GANs) [12,13] or variational autoencoders (VAEs) [14] or simply choosing fonts from libraries that already exist.
- Image Generation Process: Once the text and fonts have been generated, the synthetic images can be created. This can be done using image manipulation techniques such as rotation, scaling, and translation and by adding various types of noise, such as blur, salt-and-pepper noise [15,16,17,18], or Gaussian noise.
- Augmentation Process: The generated images can be enhanced by using a variety of ways to further diversify the training dataset. This includes techniques such as random cropping, flipping, and color jittering.
- Labeling Process: Finally, the synthetic images must be labeled with the correct character or text sequence that they represent. This can be accomplished by either manually labeling the photos or by utilizing optical character recognition techniques to extract the text from the artificial images.
1.2. Alternative Approaches and Differences
- Focus on OCR training data preparation: Our approach primarily focuses on the preparation of synthetic training datasets for OCR tasks. It addresses the challenges associated with creating datasets that encompass multiple languages, including context-sensitive languages and those from the Latin and Anglo-Saxon language families. The primary goal is to optimize OCR system training, ensuring high accuracy across diverse languages and visual contexts.
- Visual methods: The presented method emphasizes the incorporation of visual elements such as fonts, writing styles, and document layouts into the synthetic dataset generation process. This visual aspect is particularly relevant for OCR, where the recognition of characters and text from images is critical. Traditional NLP techniques like word embeddings and TF-IDF do not directly address these visual considerations.
- Multimodal data considerations: OCR involves the analysis of both textual and visual information. The suggested method takes into account both linguistic and visual features in the training dataset. This lets OCR systems handle documents that are written in more than one language or format.
- Language-specific challenges: Our method recognizes the linguistic and contextual differences among languages, especially when dealing with context-sensitive languages and synthesized languages. It aims to tailor the dataset preparation process to address these language-specific challenges, ensuring that the OCR system performs optimally across diverse linguistic backgrounds.
- Application in near-real-time collaborative on-screen OCR: The proposed approach targets real-time OCR applications within collaborative on-screen solutions. This context imposes stringent requirements on processing speed and accuracy, and the approach is designed to meet these specific demands.
1.3. Convergence Method of Optimal Dataset Preparation
1.4. Rationale behind the New Approach
1.5. Proposed Improvements
- Dynamic Dataset Augmentation [24,25]: The training dataset should be continually updated and expanded to include new text samples (using the Sobel filter [26]), variations in language, and emerging writing styles. This can be achieved through techniques such as synthetic data generation [27], web scraping, and crowd sourcing. Dynamic dataset augmentation ensures that the OCR system remains accurate and up-to-date with evolving language trends.
- Adaptive Vocabulary Selection [28]: To cater to the diverse nature of languages and scripts, an adaptive vocabulary selection method is crucial. This approach enables the identification and selection of the most relevant and frequently occurring words, characters, or n-grams in each language, providing an optimal basis for training the OCR system.
- Domain-specific Adaptation [29]: To enhance the OCR system’s performance in specific industries or use cases, the training dataset should be enriched with domain-specific data. For example, incorporating legal, medical, or technical jargon can help improve the system’s performance in those respective fields.
- Cross-lingual Pretraining [30]: Leveraging transfer learning from a pretrained multilingual model [31] can aid in raising OCR system’s efficiency for low-resource languages. By training on a large, diverse, and high-quality dataset, the OCR model learns to identify common patterns and structures across different languages, leading to better generalization.
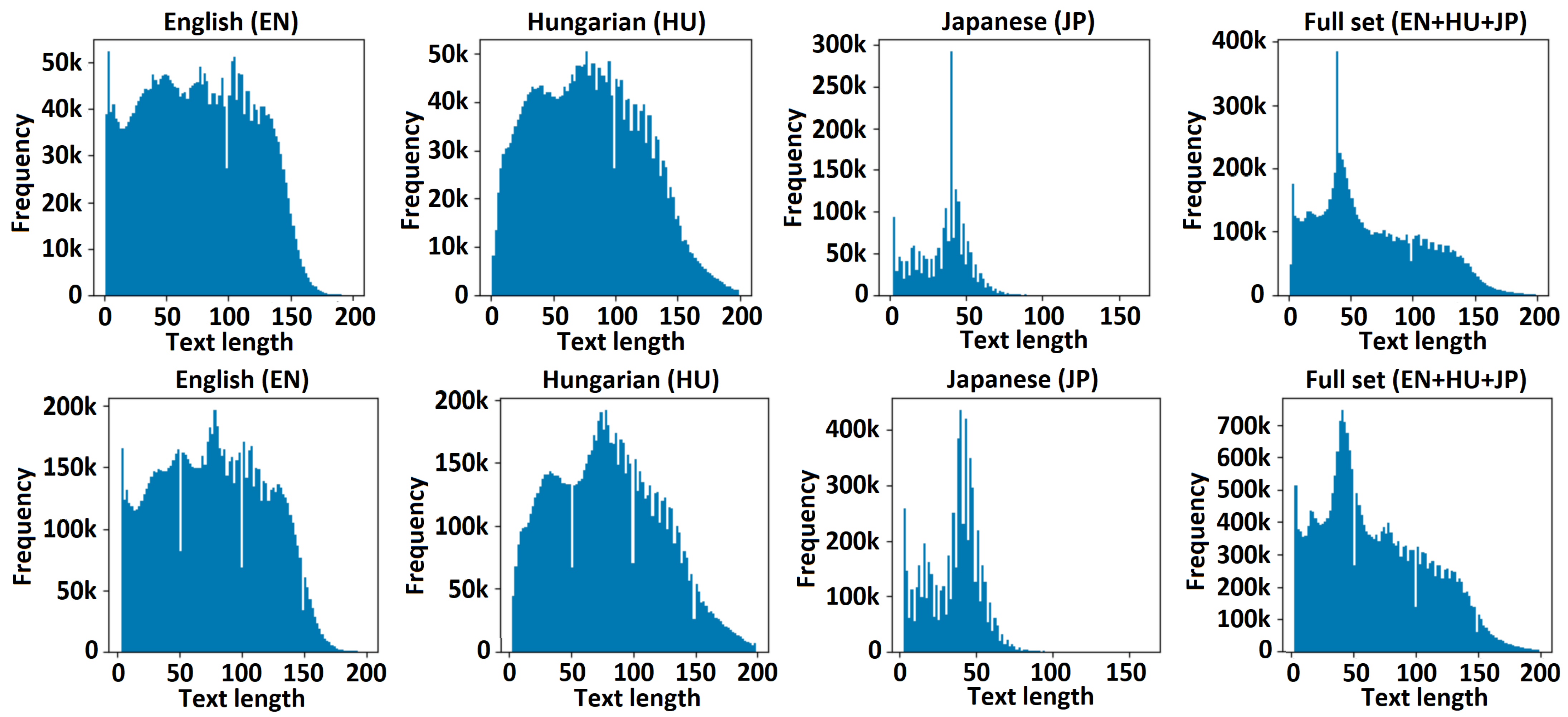
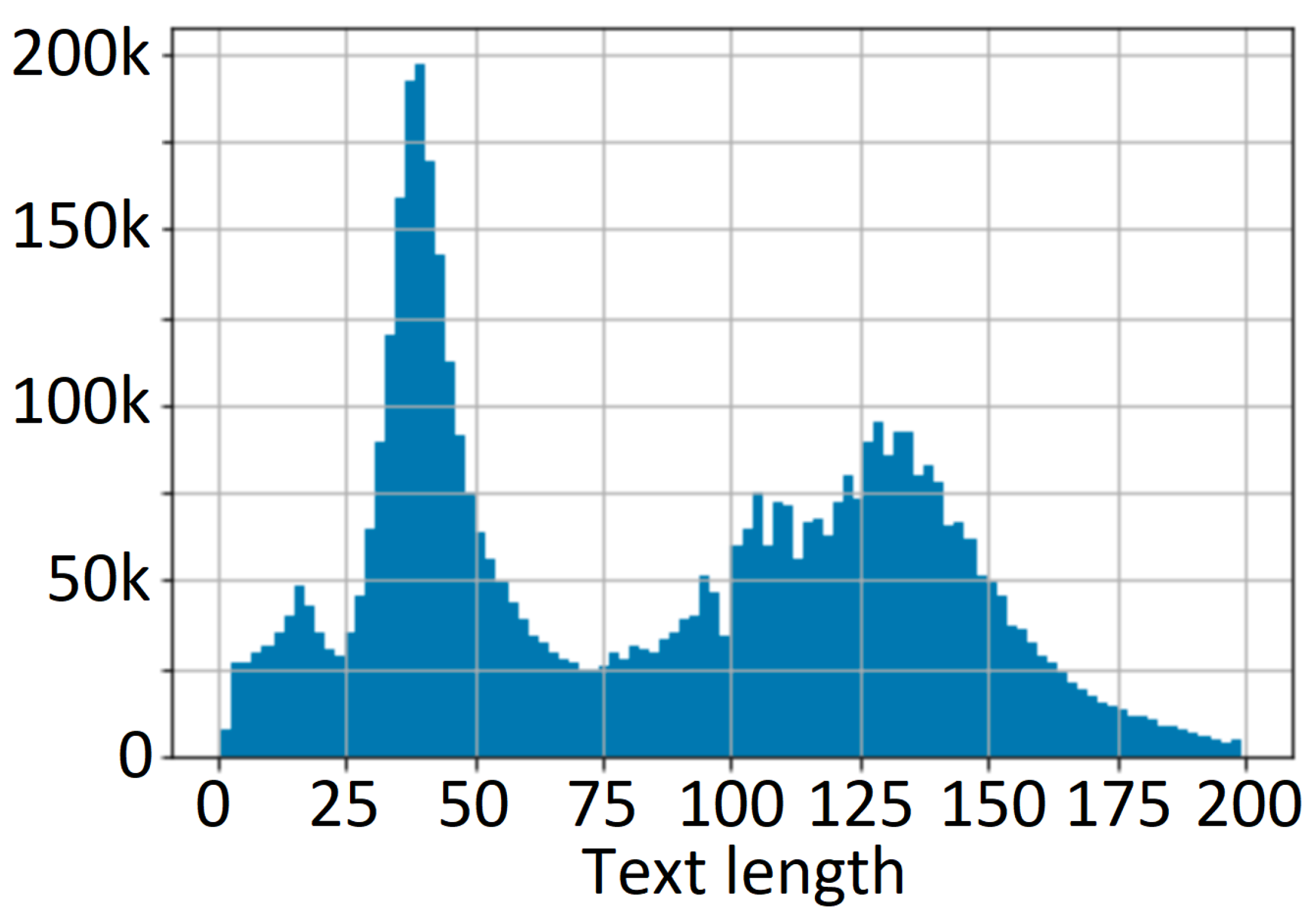
- Data Imbalance Mitigation [32]: A balanced dataset (Figure 2) is essential in training a robust multilingual OCR system. This involves addressing class imbalances by oversampling underrepresented classes or undersampling over-represented classes. Additionally, incorporating data augmentation techniques [33] such as rotation, scaling, and noise addition can help increase the variability of the training data.In the case of multilanguage training involving Japanese, English, and Hungarian at the same time, the character occurrence frequency must be evaluated per domain and per targeted solution.
- Evaluation Metrics and Benchmarks [34]: Establishing appropriate evaluation metrics and benchmarks for multilingual OCR systems [35] is vital for assessing performance, identifying areas for improvement, and facilitating model comparison. These metrics should include character- and word-level recognition rates, language identification accuracy, and domain-specific evaluation measures.
- Multimodal Learning [36]: Incorporating additional contextual information such as domain-specific metadata can improve the OCR system’s ability to recognize text within different contexts. Multimodal learning enables the model to leverage multiple sources of information to enhance its understanding of the text.
2. Objectives
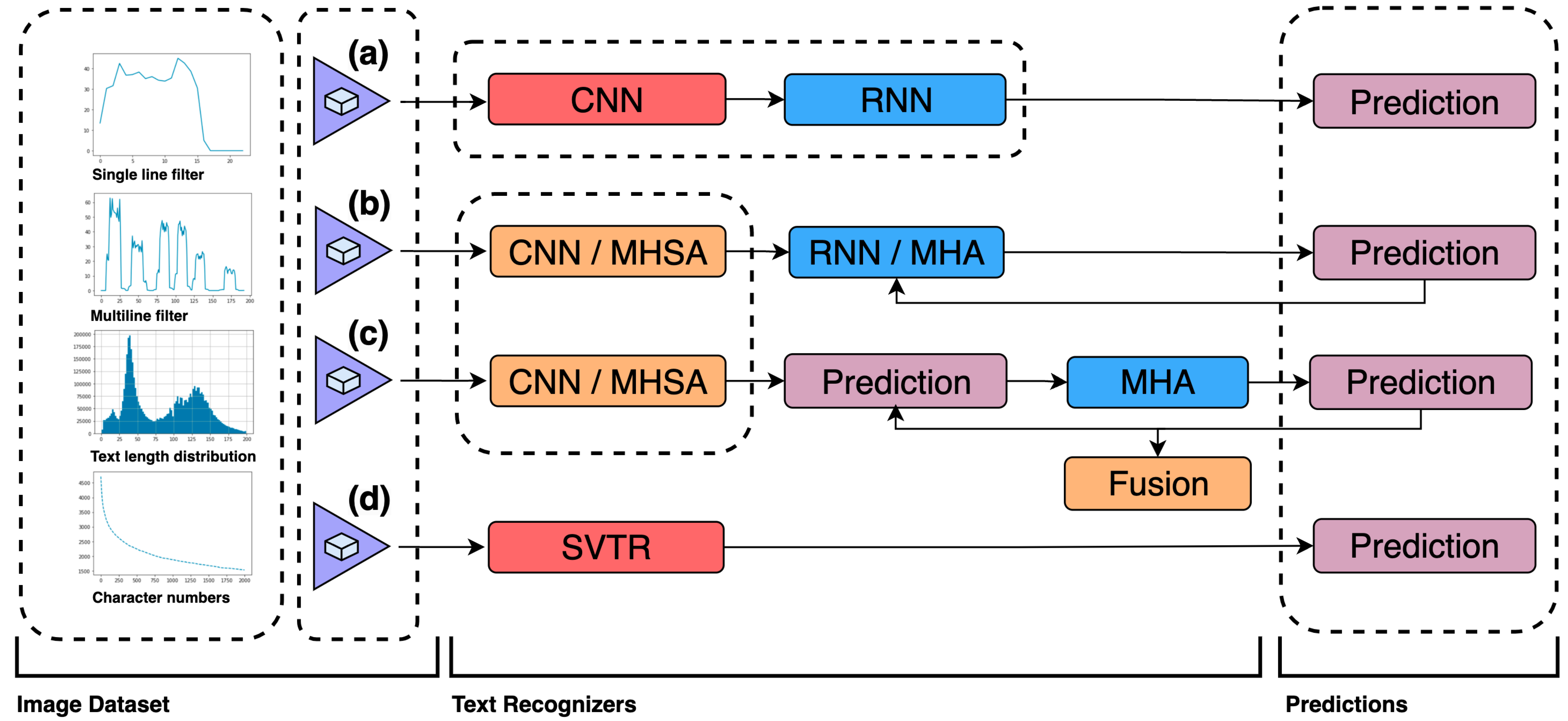
- To develop an optimal vocabulary-based training dataset for multilingual, AI-powered, real-time OCR systems, fostering technical excellence and pushing the boundaries of the research field. Several modern text recognizers are presented in Figure 3, all of which not only have high accuracy but also represent fast inference speeds: (a) CNN-RNN-based models [37]; (b) encoder–decoder models [38] involving multihead self-attention (MHSA) [39] and multihead attention (MHA) mechanisms [40]; (c) vision-language models [41]; and (d) SVTR [42], which recognizes scene text by using a single visual model built with cross-lingual capability [7] in mind.
- To ensure comprehensive language representation in existing (e.g., PaddleOCR) and future custom OCR systems, with an initial focus on English, Hungarian, and Japanese as representative languages but with the flexibility to extend the methodology to any existing or synthesized languages.
- To secure and control the requirements of high-quality and diverse data samples, maintaining a balanced dataset that can effectively support the development of accurate, efficient, and versatile OCR systems.
- To enhance contextual understanding and facilitate domain-specific adaptation in OCR systems (e.g., health care, IT, and industrial or cross-domain topics), enabling them to adapt to a myriad of real-world scenarios.
- To promote robustness and noise tolerance in OCR systems, enhancing their reliability and performance in diverse environmental conditions.
- To enable scalability and extensibility in OCR systems, demonstrating the potential of AI to grow and adapt with evolving societal needs (e.g., real-time, multilingual, cross-domain interpreter systems).
- Through the use of methods like CNN, RNN, CRNN, and SVTR, it is possible to find a visually controlled solution that streamlines the creation of training datasets and vocabulary for real-time OCR projects (such as PaddleOCR).
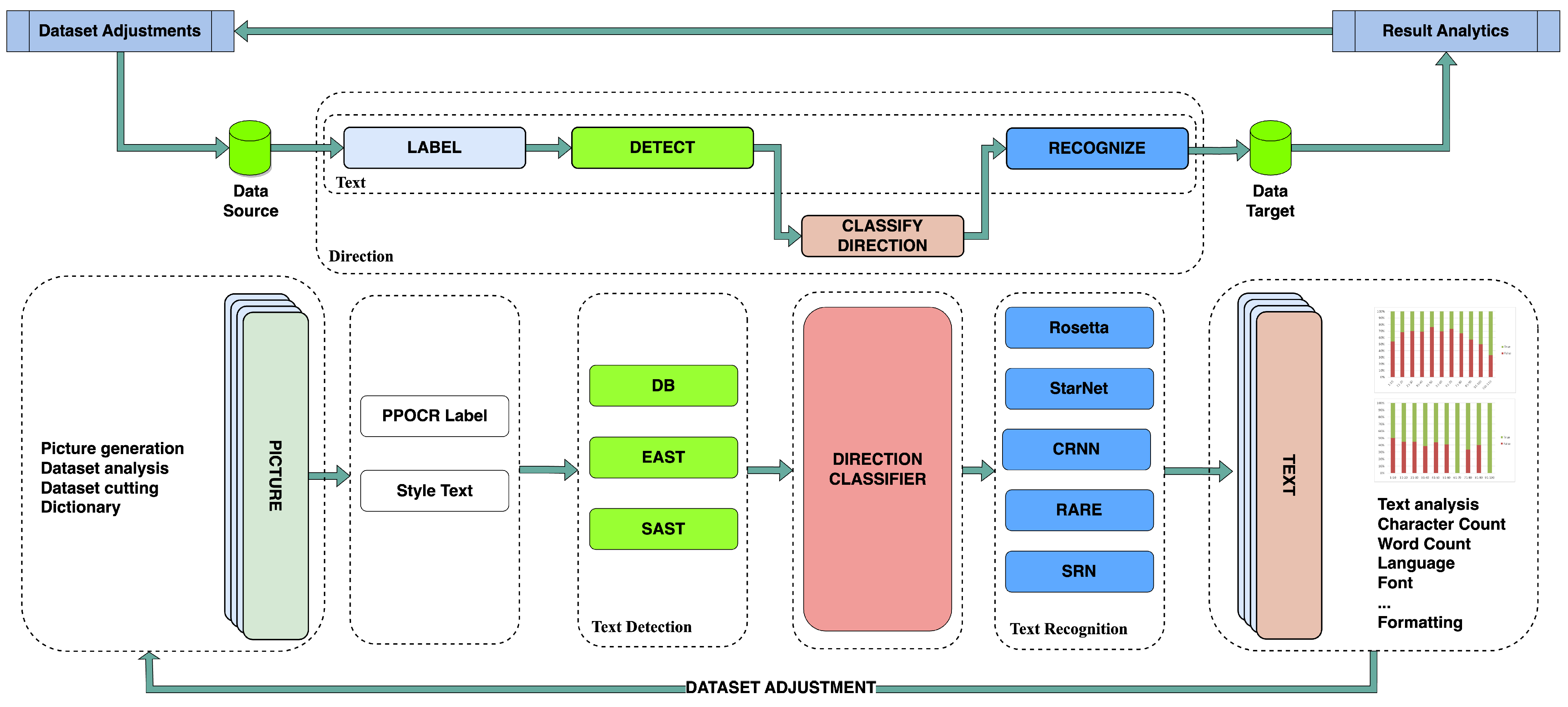
2.1. Optimal Training Dataset Preparation
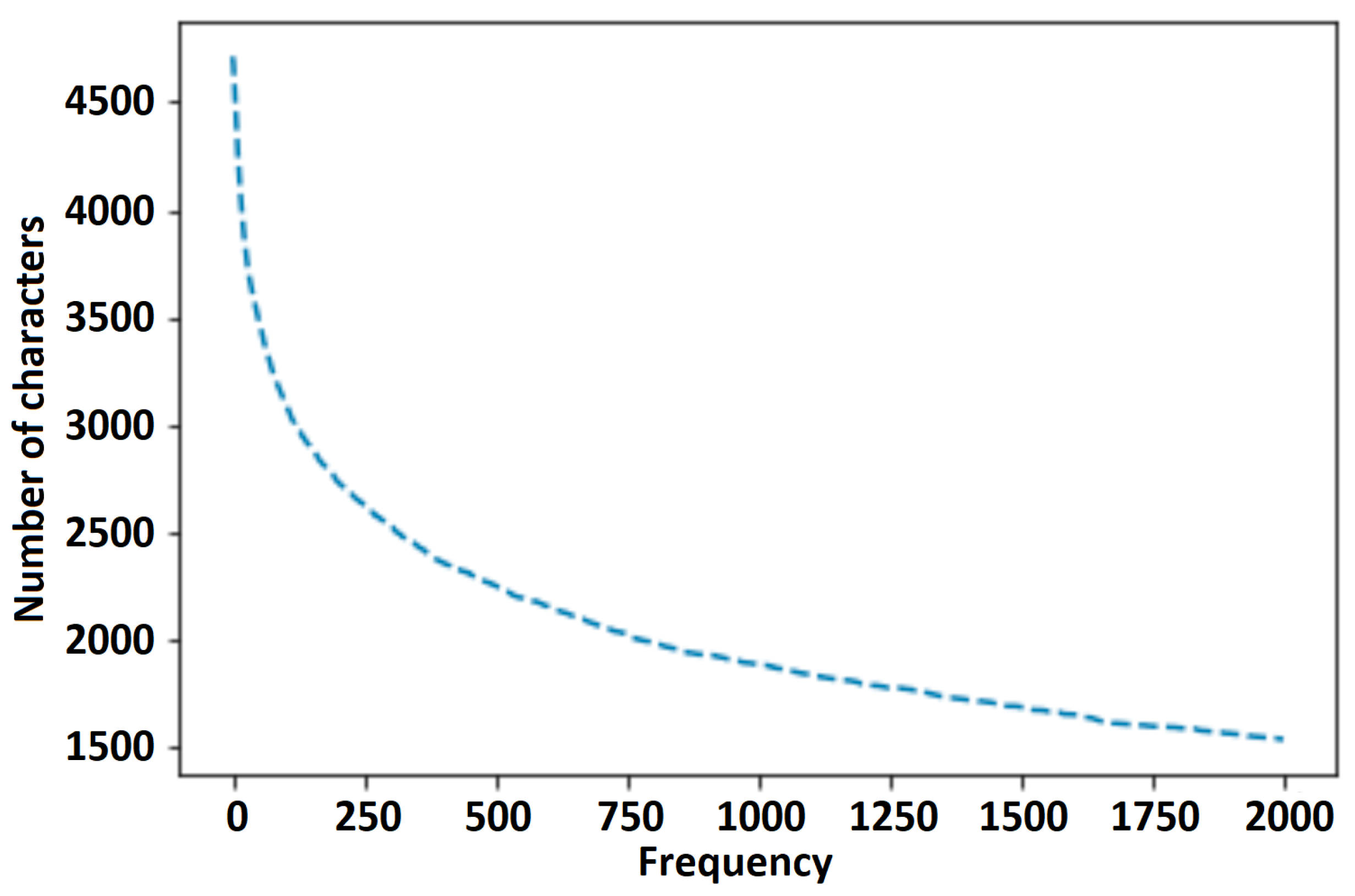
2.2. Novelty of Distribution Analysis and Vocabulary Management
3. Materials and Methods
3.1. Single-Line/Multiline Regularization
3.2. Optimal Data Distribution Calculation
3.2.1. Data Preprocessing
3.2.2. Feature Extraction
3.2.3. Model Training
3.2.4. Data Distribution Calculation
3.3. Training Dataset
3.4. Exploratory Data Analysis
3.5. Vocabulary Generation
4. Experiments

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Vocabulary Name | Size | Type |
|---|---|---|---|
| 15M_enhujp_v2_1 | training9-200_vocab_min200.txt | 2737 | Generated |
| 30M_enhujp_v2_4 | dashboard_vocab.txt | 1441 | Generated |
| 50M_enhujp_v2_2 | training_min250_nQA.txt | 3964 | Generated |
| 3M_dashboard_eng_V1 | training9-200_vocab_min9500.txt | 803 | Generated |
| 3M_dashboard_hun_v1 | 186k_extended_vocab.txt | 112 | Unified |
| 3M_dashboard_enhujp_v2_1 | jpn_latin_dict.txt | 4444 | Unified |
| 10M_enhujp_v2_1 | jpn_latin_dict.txt | 4444 | Unified |
| 30M_enhujp_v2_1 | dashboard_vocab.txt | 1441 | Generated |
| Project | Name | Vocabulary Name | Size | Vocabulary Type |
|---|---|---|---|---|
| OCR_hun | 155k_hu_v2_2 | 606k_hun_vocab.txt | 112 | Generated |
| OCR_hun | 155k_hu_v2_1 | 606k_hun_vocab.txt | 112 | Generated |
| OCR_enhu | SVTR | extended_vocab.txt | 201 | Unified |
| OCR_enhu | CRNN | extended_vocab.txt | 201 | Unified |
| OCR_multilang | 5M_enhujp_v2_8 | training9200_vocab_min9500.txt | 803 | Generated |
| OCR_multilang | 5M_enhujp_v2_6 | training9200_vocab_min200.txt0 | 2737 | Generated |
| OCR_multilang | 5M_enhujp_v2_5 | training9200_vocab_min9500.txt | 803 | Generated |
| OCR_multilang | 5M_enhujp_v2_4 | training9200_vocab_min200.txt | 2737 | Generated |
| OCR_multilang | 5M_enhujp_v2_3 | jpn_latin_dict.txt | 4444 | Unified |
| OCR_multilang | 5M_enhujp_v2_2 | jpn_latin_dict.txt | 4444 | Unified |
| OCR_multilang | 5M_enhujp_v2_1 | jpn_latin_dict.txt | 4444 | Unified |
| OCR_multilang | 10M_enhujp_v3_ 1 | jpn_latin_dict.txt | 4444 | Unified |
| OCR_multilang | 5M_enhujp_v3_4 | jpn_latin_dict.txt | 4444 | Unified |
| OCR_multilang | 5M_enhujp_v3_3 | jpn_latin_dict.txt | 4444 | Unified |
| OCR_multilang | 5M_enhujp_v3_2 | jpn_latin_dict.txt | 4444 | Unified |
| OCR_multilang | 4M_enhujp_pre_v3_1 | jpn_latin_dict.txt | 4444 | Unified |
| OCR_multilang | 4M_enhujp_pre_v3_1 | jpn_latin_dict.txt | 4444 | Unified |
| OCR_multilang | 4M_enhujp_v3_5 | 4M_vocab.txt | 4721 | Generated |
| OCR_multilang | 4M_enhujp_v3_4 | 4M_min20_vocab.txt | 3980 | Generated |
| OCR_multilang | 2M_enhujp_v2_2 | 2M_min2k_vocab.txt | 968 | Generated |
| OCR_hun | 186k_hu_v2_1 | 186k_extended_vocab.txt | 112 | Unified |
| Name | Steps | Epochs | Best_Acc | Distribution | Vocab Size |
|---|---|---|---|---|---|
| 15M_enhujp_v2_1 | 1.32 M | 100 | 85% | Figure 7 | 2737 |
| 30M_enhujp_v2_4 | 0.7 M | 10 | 98.76% | Figure 8 | 1441 |
| 50M_enhujp_v2_2 | 1.71 M | 10 | 94% | Figure 9 | 3964 |
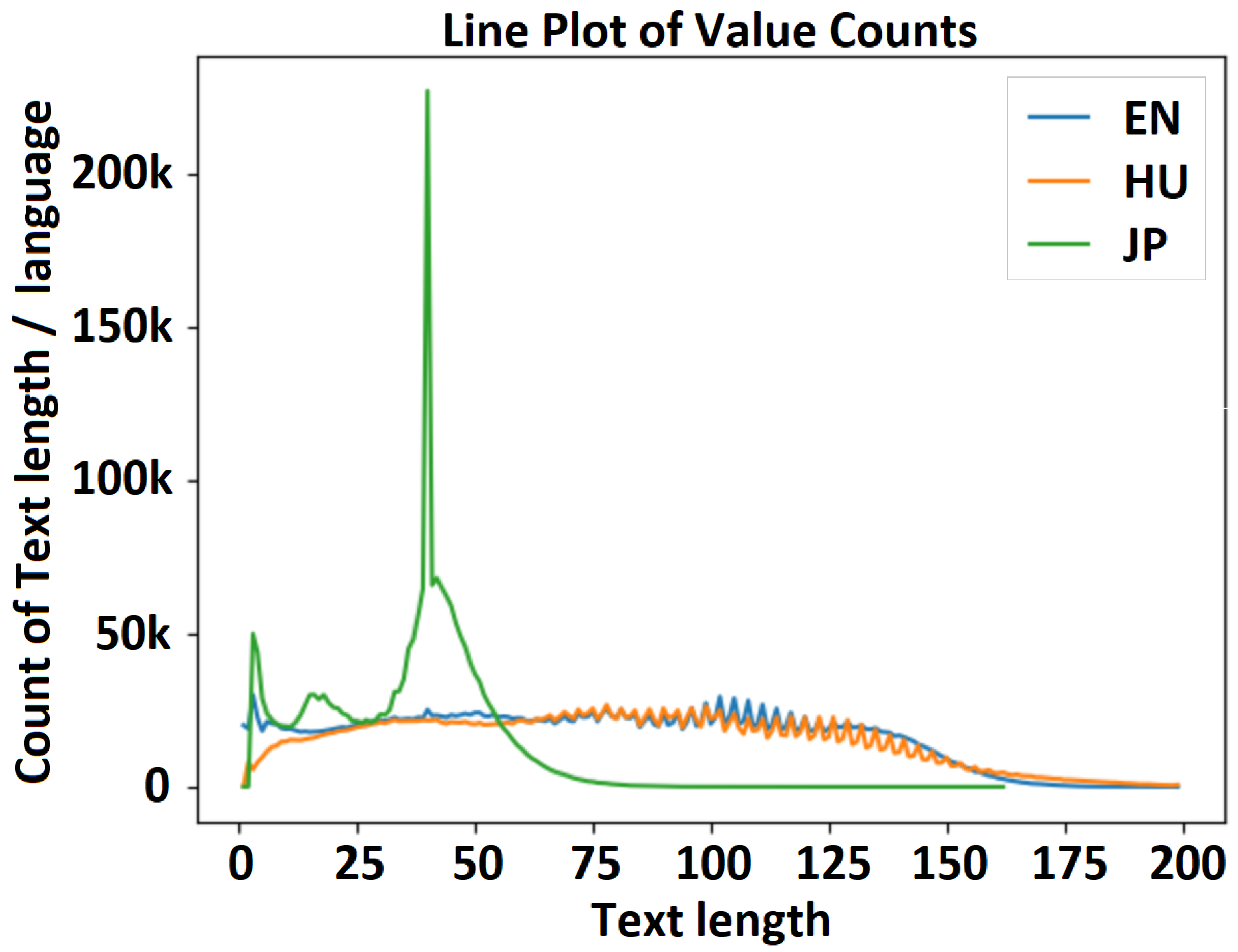
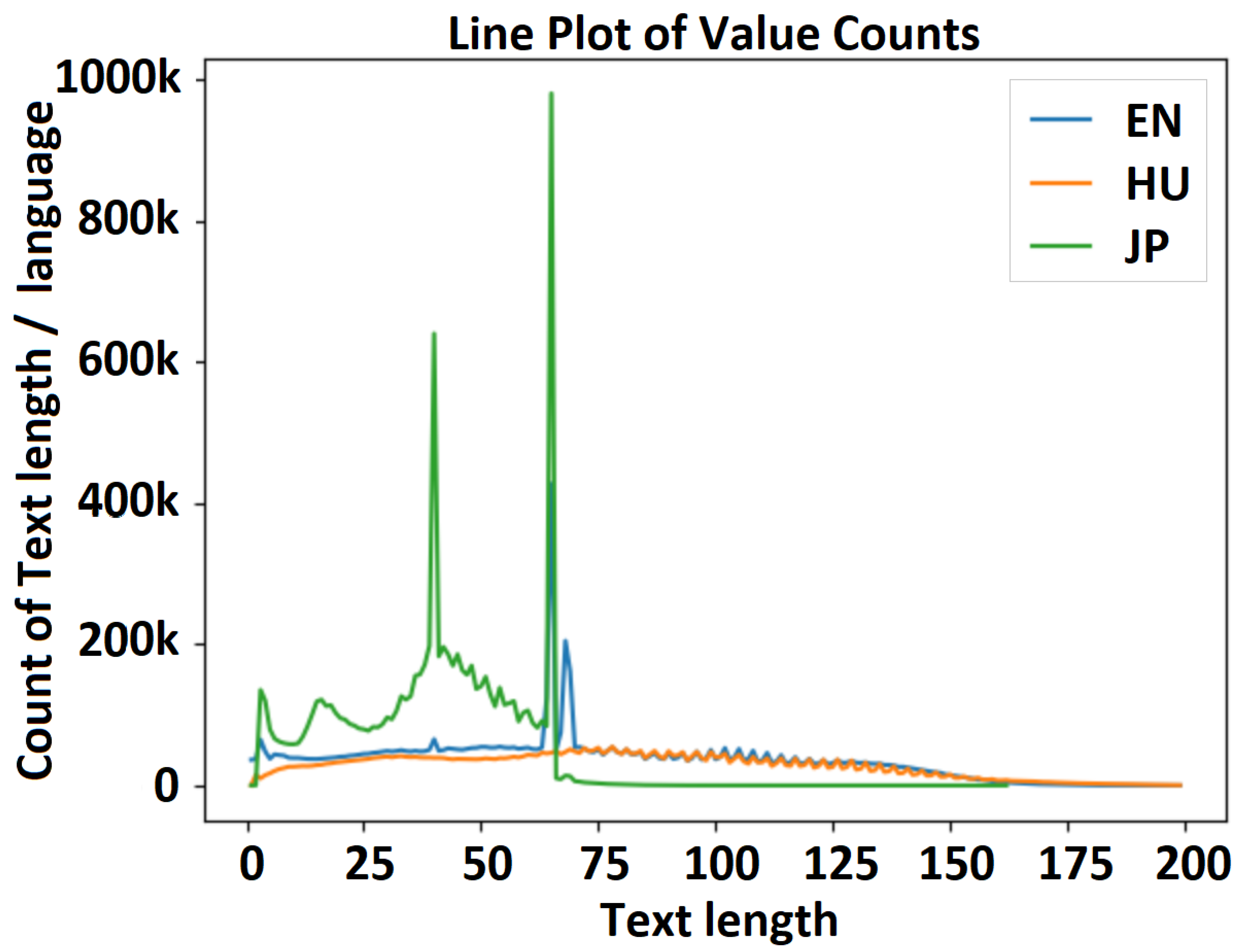

| Name | Steps | Epochs | Best_Acc | Dataset | Vocab Size |
|---|---|---|---|---|---|
| 3M_dashboard_eng_V1 | 1.83 M | 90 | 91% | 3 M | 803 |
| 3M_dashboard_hun_v1 | 0.96 M | 47 | 89% | 3 M | 112 |
| 3M_dashboard_enhujp_v2_1 | 1.61 M | 100 | 90% | 3 M | 4444 |
| 10M_enhujp_v2_1 | 3.96 M | 100 | 85% | 8.5 M | 4444 |
| 15M_enhujp_v2_1 | 1.32 M | 100 | 85% | 15 M | 2737 |
| 30M_enhujp_v2_4 | 0.7 M | 10 | 98.76% | 30 M | 1441 |
| 30M_enhujp_v2_1 | 0.15 M | 10 | 95.87% | 30 M | 1441 |
| 50M_enhujp_v2_2 | 1.71 M | 10 | 94% | 50 M | 3964 |
| Project | Name | Dictionary | Epochs | Text | Training | Evaluation | Image | Learning | Train | Training | Evaluation |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Type | Length | Batch Size | Batch Size | Shape | Rate | Best Acc | Size | Size | |||
| Single language | 155k_hu_v2_2 | 606k_hun_vocab.txt | 2000 | 100 | 128 | 128 | [3, 32, 512] | 0.0050 | 0.949 | 77 k | 15 k |
| Single language | 155k_hu_v2_1 | 606k_hun_vocab.txt | 2000 | 100 | 600 | 256 | [3, 32, 128] | 0.0050 | 0.301 | 77 k | 15 k |
| Multilanguage | SVTR | extended_vocab.txt | 100 | 150 | 128 | 128 | [3, 48, 320] | 0.0010 | 0.055 | 66 k | 33 k |
| Multilanguage | CRNN | extended_vocab.txt | 100 | 250 | 768 | 256 | [3, 32, 100] | 0.0005 | 0.003 | 66 k | 33 k |
| Multilanguage | 5M_enhujp_v2_8 | training9-200_vocab_min9500.txt | 100 | 200 | 48 | 48 | [3, 32, 1024] | 0.0005 | 0.958 | 5 M | 101 k |
| Multilanguage | 5M_enhujp_v2_6 | training9-200_vocab_min200.txt | 100 | 200 | 64 | 64 | [3, 32, 1024] | 0.0050 | 0.938 | 5 M | 101 k |
| Multilanguage | 5M_enhujp_v2_5 | training9-200_vocab_min9500.txt | 100 | 200 | 48 | 48 | [3, 32, 1024] | 0.0050 | 0.885 | 5 M | 101 k |
| Multilanguage | 5M_enhujp_v2_4 | training9-200_vocab_min200.txt | 100 | 200 | 64 | 64 | [3, 32, 1024] | 0.0050 | 0.922 | 5 M | 101 k |
| Multilanguage | 5M_enhujp_v2_3 | jpn_latin_dict.txt | 100 | 200 | 50 | 50 | [3, 32, 1024] | 0.0050 | 0.780 | 8.5 M | 170 k |
| Multilanguage | 5M_enhujp_v2_2 | jpn_latin_dict.txt | 100 | 200 | 30 | 30 | [3, 32, 2048] | 0.0050 | 0.767 | 8.5 M | 170 k |
| Multilanguage | 5M_enhujp_v2_1 | jpn_latin_dict.txt | 100 | 100 | 50 | 50 | [3, 32, 1024] | 0.0050 | 0.920 | 5 M | 100 k |
| Multilanguage | 10M_enhujp_v3_1 | jpn_latin_dict.txt | 50 | 200 | 60 | 60 | [3, 32, 1024] | 0.0010 | 0.483 | 8.5 M | 170 k |
| Multilanguage | 5M_enhujp_v3_4 | jpn_latin_dict.txt | 50 | 100 | 50 | 50 | [3, 32, 512] | 0.0001 | 0.750 | 5 M | 100 k |
| Multilanguage | 5M_enhujp_v3_3 | jpn_latin_dict.txt | 50 | 100 | 50 | 50 | [3, 32, 512] | 0.0001 | 0.690 | 5 M | 100 k |
| Multilanguage | 5M_enhujp_v3_2 | jpn_latin_dict.txt | 50 | 110 | 50 | 50 | [3, 32, 512] | 0.0001 | 0.300 | 5 M | 100 k |
| Multilanguage | 4M_enhujp_pre_v3_1 | jpn_latin_dict.txt | 50 | 200 | 24 | 24 | [3, 32, 768] | 0.0005 | 0.500 | 4.4 M | 88 k |
| Multilanguage | 4M_enhujp_pre_v3_1 | jpn_latin_dict.txt | 50 | 200 | 28 | 28 | [3, 32, 768] | 0.0005 | 0.429 | 4.4 M | 88 k |
| Multilanguage | 4M_enhujp_v3_5 | 4M_vocab.txt | 50 | 200 | 28 | 28 | [3, 32, 768] | 0.0010 | 0.429 | 4.4 M | 88 k |
| Multilanguage | 4M_enhujp_v3_4 | 4M_min20_vocab.txt | 50 | 200 | 28 | 28 | [3, 32, 768] | 0.0005 | 0.464 | 4.4 M | 88 k |
| Multilanguage | 2M_enhujp_v2_2 | 2M_min2k_vocab.txt | 100 | 200 | 64 | 64 | [3, 32, 1024] | 0.0050 | 0.672 | 2 M | 220 k |
| Single language | 186k_hu_v2_1 | 186k_extended_vocab.txt | 2000 | 100 | 128 | 128 | [3, 32, 512] | 0.0050 | 0.961 | 186 k | 34 k |
Challenges and Mitigation Strategies
- Single-line and/or multiline approach: One of the important technical questions was the capacity of PaddleOCR to handle multiple lines of text. During the experimental phase, it was seen that the system exhibited restricted multiline capabilities under certain conditions. Specifically, this limitation became apparent when the vocabulary size was sufficiently short (ranging from 100 to 200 characters) and the training examples were meticulously chosen. During multilingual experimentation, it was out of scope to provide sufficient time for the manual review of training data that involved character-based multiline analysis. As a result, we opted for the single-line solution offered by PaddleOCR.
- Vocabulary generation: PaddleOCR currently lacks an in-process vocabulary-generating tool. The process of vocabulary formation necessitates manual management. There are two methods by which a lexicon or dictionary can be generated for training. (1) One potential approach is the development of a cohesive and standardized lexicon, commonly referred to as a “golden” vocabulary, which is meticulously overseen and curated by knowledgeable human specialists. (2) An alternative approach involves generating language based on the training data. With this approach, we can guarantee that the vocabulary only includes characters that are found in the training sample, eliminating any extraneous characters.
- SVTR vs. CRNN: During the course of the investigation, PaddleOCR introduced a novel iteration of its software (PaddleOCRv2.5.0 with PP-OCRv3) [56], which incorporates the SVTR paradigm. According to PaddleOCR, the newly proposed model architecture exhibits superior performance compared to its predecessor, CRNN. Numerous experiments were conducted on the novel model architecture, consistently revealing its inferior performance compared to the capabilities exhibited by the prior architecture. Following a thorough analysis of the results obtained using the SVTR, it was determined that reverting back to the utilization of CRNN models is the most appropriate course of action. In the high-performance computing (HPC) environment, we intend to conduct a comprehensive examination of both methodologies.
- Word spacing and segmentation issues: Japanese texts had improper word spacing during the experiments. Using a tiny-segmenter Japanese text tokenizer improved the performance. Setting up tiny segmenters and tokenizing/segmenting Japanese or Chinese requires expertise. Japanese vs. Unicode character coding is another issue. High-level OCR engines work in a straightforward manner. The model looks at each character to identify it. This may lead to errors. Imagine identical characters with different character codes. In this example, the model will recognize the character as one of two options during training. If this character belongs to another character code, the model returns the information that it made a mistake because it is not that character. This causes training and inference mistakes for the model. The solution is to identify these homoglyphs and change them all to the selected character. For Latin characters, dictionaries solve the problem, but for Japanese or Chinese literature, homoglyphs require further study and depend on the domain. A custom dataset-generating tool handled homoglyphs that way. The ’normalizeHomoglyps’ attribute works with a predefined homoglyph table to handle characters/symbols that seem similar but have various character encodings for text sources. The latest version provides automatic Unicode normalization for each text source using the NFKC method.
5. Results
6. Discussion
Limitations of the Current Approach
- Synthesized Languages: Investigating synthesized languages (like health language, legal language, and IT language), which may not have well-established linguistic resources or standardized writing systems, introduces an additional layer of complexity. The availability of reliable linguistic references and textual corpora for such languages may be limited, potentially hampering the completeness and authenticity of the synthetic training data.
- Computational Resources: This research involves computationally intensive tasks, including the generation of synthetic data and the training of deep learning models. Depending on the scale of the dataset and the complexity of the models, substantial computational resources or a high-performance computing (HPC) environment is required. Access to such resources may impose constraints, particularly for researchers with limited access to HPC environments.
- Generalization: while this research seeks to optimize training datasets and models for multilanguage OCR, the extent to which the findings can be generalized to various OCR applications and domains may be limited. Factors such as document types, writing styles, and use cases may influence the transferability of the results.
- Evaluation Challenges: Establishing robust, metadata-based evaluation methodologies and benchmarks for multilanguage OCR systems that consider the complexities of synthesized languages is a formidable task. The creation of evaluation frameworks that adequately reflect real-world scenarios (like cross-domain or field cooperation) and effectively assess system performance across multiple languages is an ongoing challenge.
- Data Annotation: The generation of high-quality, linguistically accurate annotations for synthetic training datasets is a resource-intensive and time-consuming endeavor. The practicality of creating comprehensive annotations that encompass diverse linguistic features across multiple languages and/or domains (law, IT, health care, sports, and industry), especially for context-sensitive and synthesized languages, may present significant logistical challenges, even in HPC environments.
- Language Diversity Coverage: One prominent limitation pertains to the diverse nature of the languages involved. While this research aims to address multilingual challenges, each language possesses unique characteristics, scripts, and linguistic nuances. Consequently, the development of a single, universally applicable methodology for training dataset preparation may be challenging. The need for language-specific considerations may introduce complexity and complicate the generalization of findings across languages. Icluding Japanese language and synthesized language alongside Latin and Anglo-Saxon languages can limit the vocabulary to 5000–6500 characters if the language is limited to the IT domain, but in the case of the health domain, the vocabulary will have include than 10,000 characters.
7. Future Development
8. Open Challenges and Problems
9. Conclusions
- Preparing an optimal dataset directly contributes to improved model performance by providing diverse, high-quality, and representative samples for each language, enabling the OCR systems to learn and generalize better; however, this process needs continuous process control.
- Preparing a specific dataset that includes noisy samples, such as low-quality images, occlusions, or distortions, ensures that the OCR system is robust and can perform accurately even in challenging real-world conditions.
- By incorporating multiple languages or hybrid languages, the training dataset enables the OCR system to cater to a broader audience, increasing its applicability and utility in various real-world scenarios. This model could be interesting not only for multilanguage use cases but also for training with technical and/or domain-specific languages. Moreover, by incorporating domain-specific data and contexts, the OCR system can be tailored to different industries or use cases, improving its performance in specialized fields such as the legal, medical, or technical domains.
- Preparing a dataset that includes multimodal information such as images or audio helps the OCR system leverage additional contextual information to enhance its understanding and interpretation of the text. This process may make the preparation stage more complicated, but the results will compensate for that.
- The dataset should include variations in writing styles, dialects, and colloquialisms for each language, ensuring that the OCR system is adaptable and can handle various linguistic nuances.
- Multilingual societies frequently engage in “code switching”, the act of switching between two or more languages within a single conversation or document. An optimal dataset should account for code-switching scenarios, allowing the OCR system to seamlessly recognize and process text that contains multiple languages.
- Leveraging pretrained multilingual models or incorporating cross-lingual pretraining enables the OCR system to learn from the shared knowledge of multiple languages, resulting in better generalization and potentially improved performance for low-resource languages.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| OCR | Optical character recognition |
| GANs | Generative adversarial networks |
| VAEs | Variational autoencoders |
| CNN | convolutional neural network |
| RNN | Recurrent neural network |
| CRNN | Convolutional recurrent neural network |
| SVTR | Single Visual model for scene Text Recognition |
| IT | Information technology |
| MHSA | Multihead self-attention |
| MHA | Multihead attention |
| UX | User experience |
| HLP | High-performance computing |
| PC | Personal computer |
| CPU | Central processing unit |
| GB | Gigabyte |
| GPU | Graphics processing unit |
| VGA | Video graphics array |
References
- Biró, A.; Jánosi-Rancz, K.T.; Szilágyi, L.; Cuesta-Vargas, A.I.; Martín-Martín, J.; Szilágyi, S.M. Visual Object Detection with DETR to Support Video-Diagnosis Using Conference Tools. Appl. Sci. 2022, 12, 5977. [Google Scholar] [CrossRef]
- Benis, A.; Grosjean, J.; Billey, K.; Martins, J.; Dornauer, V.; Crișan-Vida, M.; Hackl, W.; Stoicu-Tivadar, L.; Darmoni, S. Medical Informatics and Digital Health Multilingual Ontology (MIMO): A tool to improve international collaborations. Int. J. Med. Inform. 2022, 167, 104860. [Google Scholar] [CrossRef] [PubMed]
- Shah, S.R.; Kaushik, A.; Sharma, S.; Shah, J. Opinion-Mining on Marglish and Devanagari Comments of YouTube Cookery Channels Using Parametric and Non-Parametric Learning Models. Big Data Cogn. Comput. 2020, 4, 3. [Google Scholar] [CrossRef]
- Shah, S.R.; Kaushik, A. Sentiment Analysis on Indian Indigenous Languages: A Review on Multilingual Opinion Mining. arXiv 2019, arXiv:1911.12848. [Google Scholar]
- Pathak, K.; Saraf, S.; Wagh, S.; Vishwanath, D. OCR Studymate. Int. J. Res. Appl. Sci. Eng. Technol. 2022, 10, 2241–2246. [Google Scholar] [CrossRef]
- Nuchkrua, T.; Leephakpreeda, T. Novel Compliant Control of a Pneumatic Artificial Muscle Driven by Hydrogen Pressure Under a Varying Environment. IEEE Trans. Ind. Electron. 2022, 69, 7120–7129. [Google Scholar] [CrossRef]
- Sharma, P. Advancements in OCR: A Deep Learning Algorithm for Enhanced Text Recognition. Int. J. Invent. Eng. Sci. 2023, 10, 1–7. [Google Scholar] [CrossRef]
- Subedi, B.; Yunusov, J.; Gaybulayev, A.; Kim, T.H. Development of a low-cost industrial OCR system with an end-to-end deeplearning technology. IEMEK J. Embed. Syst. Appl. 2020, 15, 51–60. [Google Scholar]
- Chen, Y.H.; Zhou, Y.L. Enhancing OCR Performance through Post-OCR Models: Adopting Glyph Embedding for Improved Correction. arXiv 2023, arXiv:2308.15262. [Google Scholar]
- Nieminen, H.; Kuosmanen, L.; Bond, R.; Vartiainen, A.-K.; Mulvenna, M.; Potts, C.; Kostenius, C. Coproducing multilingual conversational scripts for a mental wellbeing chatbot-where healthcare domain experts become chatbot designers. Eur. Psychiatry 2022, 65, S293. [Google Scholar] [CrossRef]
- Mao, A.X.Q.; Thakkar, I. Lost in Translation: The Vital Role of Medical Translation in Global Medical Communication. AMWA J. 2023, 38, 3. [Google Scholar]
- Yilmaz, B.; Korn, R. Understanding the mathematical background of Generative Adversarial Networks (GANs). Math. Model. Numer. Simul. Appl. 2023, 3, 234–255. [Google Scholar] [CrossRef]
- Moghaddam, M.M.; Boroomand, B.; Jalali, M.; Zareian, A.; Daeijavad, A.; Manshaei, M.H.; Krunz, M. Games of GANs: Game-theoretical models for generative adversarial networks. Artif. Intell. Rev. 2023, 56, 9771–9807. [Google Scholar] [CrossRef]
- Singh, A.; Ogunfunmi, T. An Overview of Variational Autoencoders for Source Separation, Finance, and Bio-Signal Applications. Entropy 2021, 24, 55. [Google Scholar] [CrossRef] [PubMed]
- Ebrahimnejad, J.; Naghsh, A.; Pourghasem, H. A robust watermarking approach against high-density salt and pepper noise (RWSPN) to enhance medical image security. IET Image Proc. 2023. [Google Scholar] [CrossRef]
- Gao, J.Q.; Li, L.; Ren, X.; Chen, Q.; Abdul-Abbass, Y. An effective method for salt and pepper noise removal based on algebra and fuzzy logic function. Multim. Tools Appl. 2023. [Google Scholar] [CrossRef]
- Muthmainnah. Optimized the Performance of Super Resolution Images by Salt and pepper Noise Removal based on a Modified Trimmed Median Filter. Wasit J. Comput. Math. Sci. 2023, 2, 107–115. [Google Scholar] [CrossRef]
- Kumain, S.; Kumar, K. Quantifying Salt and Pepper Noise Using Deep Convolutional Neural Network. J. Inst. Eng. Ser. B 2022, 103, 1293–1303. [Google Scholar] [CrossRef]
- Tian, Y.; Wu, S.; Zeng, J.; Gao, M. PaddleOCR—An Elegant And Modular Architecture. DESOSA2021. 15 March 2021. Available online: https://2021.desosa.nl/projects/paddleocr/posts/paddleocr-e2/ (accessed on 10 October 2023).
- Monteiro, G.; Camelo, L.; Aquino, G.; Fernandes, R.; Gomes, R.; Printes, A.; Gondres, I.; Silva, H.; Parente de Oliveira, J.; Figueiredo, C. A Comprehensive Framework for Industrial Sticker Information Recognition Using Advanced OCR and Object Detection Techniques. Appl. Sci. 2023, 13, 7320. [Google Scholar] [CrossRef]
- Du, Y.N.; Li, C.X.; Guo, R.Y.; Cui, C.; Liu, W.W.; Zhou, J.; Lu, B.; Yang, Y.H.; Liu, Q.W.; Hu, X.G.; et al. PP-OCRv2:Bag of tricks for ultra lightweightOCR system. arXiv 2021, arXiv:2109.03144. [Google Scholar]
- Guo, Q.; Zhang, C.; Zhang, S.; Lu, J. Multi-model query languages: Taming the variety of big data. Distr. Paral. Databases. 2023. [Google Scholar] [CrossRef]
- Jain, P.; Taneja, K.; Taneja, H. Which OCR toolset is good and why? A comparative study. Kuwait J. Sci. 2021, 48, 1–12. [Google Scholar] [CrossRef]
- Jain, P.; Kumar, V.; Samuel, J.; Singh, S.; Mannepalli, A.; Anderson, R. Artificially Intelligent Readers: An Adaptive Framework for Original Handwritten Numerical Digits Recognition with OCR Methods. Information 2023, 14, 305. [Google Scholar] [CrossRef]
- Yoshimura, M.; Otsuka, J.; Irie, A.; Ohashi, T. Rawgment: Noise-Accounted RAW Augmentation Enables Recognition in a Wide Variety of Environments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14007–14017. [Google Scholar]
- Jadhav, G.; Jada, S.Y.; Triveni, R.; Khan, S.I. FPGA based Edge Detection using Sobel Filter. Int. J. Res. Appl. Sci. Eng. Technol. 2021, 9, 145–147. [Google Scholar]
- Le, H.; Kim, S.H.; Na, I.; Do, Y.; Park, S.C.; Jeong, S.H. Automatic Generation of Training Character Samples for OCR Systems. Int. J. Contents 2012, 8, 83–93. [Google Scholar] [CrossRef]
- Xu, Y.J. An Adaptive Learning System for English Vocabulary Using Machine Learning. Mobile Inform. Syst. 2022, 2022, 3501494. [Google Scholar] [CrossRef]
- März, L.; Schweter, S.; Poerner, N.; Roth, B.; Schütze, H. Data Centric Domain Adaptation for Historical Text with OCR Errors. In International Conference on Document Analysis and Recognition (ICDAR); Springer: Cham, Switzerland; Berlin/Heidelberg, Germany, 2021; Volume 12822, pp. 748–761. [Google Scholar]
- Blevins, T.; Gonen, H.; Zettlemoyer, L. Analyzing the Mono- and Cross-Lingual Pretraining Dynamics of Multilingual Language Models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 3575–3590. [Google Scholar]
- Nowakowski, K.; Ptaszynski, M.; Murasaki, K.; Nieuwazny, J. Adapting multilingual speech representation model for a new, underresourced language through multilingual fine-tuning and continued pretraining. Inform. Proc. Manag. 2023, 60, 103148. [Google Scholar] [CrossRef]
- Faizullah, S.; Ayub, M.S.; Hussain, S.; Khan, M.A. A Survey of OCR in Arabic Language: Applications, Techniques, and Challenges. Appl. Sci. 2023, 13, 4584. [Google Scholar] [CrossRef]
- Spruck, A.; Hawesch, M.; Maier, A.; Riess, C.; Seiler, J.; Kau, A. 3D Rendering Framework for Data Augmentation in Optical Character Recognition. In Proceedings of the International Symposium on Signals, Circuits and Systems (ISSCS), Iasi, Romania, 15–16 July 2021. [Google Scholar]
- Milyaev, S.; Barinova, O.; Novikova, T.; Kohli, P.; Lempitsky, V. Fast and accurate scene text understanding with image binarization and off-the-shelf OCR. Int. J. Doc. Anal. Recogn. (IJDAR) 2015, 18, 169–182. [Google Scholar] [CrossRef]
- Englmeier, T.; Fink, F.; Springmann, U.; Schulz, K. Optimizing the Training of Models for Automated Post-Correction of Arbitrary OCR-ed Historical Texts. J. Lang. Technol. Comput. Linguist. 2022, 35, 1–27. [Google Scholar] [CrossRef]
- McKinzie, R.; Cheng, J.; Shankar, V.; Yang, Y.F.; Shlens, J.; Toshev, A. On robustness in multimodal learning. arXiv 2023, arXiv:2304.04385. [Google Scholar]
- Sansowa, R.; Abraham, V.; Patel, M.; Gajjar, R. OCR for Devanagari Script Using a Deep Hybrid CNN-RNN Network. Lect. Notes Electr. Eng. 2022, 952, 263–274. [Google Scholar]
- Okamoto, S.; Jin’no, K. A study on the role of latent variables in the encoder-decoder model using image datasets. Nonlin. Theor. Its Appl. (IEICE) 2023, 14, 652–676. [Google Scholar] [CrossRef]
- Zhang, M.; Duan, Y.; Song, W.; Mei, H.; He, Q. An Effective Hyperspectral Image Classification Network Based on Multi-Head Self-Attention and Spectral-Coordinate Attention. J. Imag. 2023, 9, 141. [Google Scholar] [CrossRef]
- Sang, D.V.; Cuong, L.T.B. Improving CRNN with EfficientNet-like feature extractor and multi-head attention for text recognition. In Proceedings of the 10th International Symposium on Information and Communication Technology (SoICT), Hanoi, Vietnam, 4–6 December 2019; pp. 285–290. [Google Scholar]
- Jaiswal, K.; Suneja, A.; Kumar, A.; Ladha, A.; Mishra, N. Preprocessing Low Quality Handwritten Documents for OCR Models. Int. J. Res. Appl. Sci. Eng. Technol. 2023, 11, 2980–2985. [Google Scholar] [CrossRef]
- Du, Y.; Chen, Z.; Jia, C.; Yin, X.; Zheng, T.; Li, C.; Du, Y.; Jiang, Y.-G. SVTR: Scene Text Recognition with a Single Visual Model. In Proceedings of the 31st International Joint Conference on Artificial Intelligence (IJCAI), Vienna, Austria, 23–29 July 2022; pp. 867–873. [Google Scholar]
- Goel, P.; Bansal, S. Comprehensive and Systematic Review of Various Feature Extraction Techniques for Vernacular Languages. In Proceedings of the Innovations in Bio-Inspired Computing and Applications (IBICA 2022), Online, 15–17 December 2022; pp. 350–362. [Google Scholar]
- Zulkifli, M.K.N.; Daud, P.; Mohamad, N. Multi Language Recognition Translator App Design Using Optical Character Recognition (OCR) and Convolutional Neural Network (CNN). In Proceedings of the International Conference on Data Science and Emerging Technologies (DaSET 2022), Online, 20–21 December 2022; pp. 103–116. [Google Scholar]
- Biten, A.F.; Tito, R.; Gomez, L.; Valveny, E.; Karatzas, D. OCR-IDL: OCR Annotations for Industry Document Library Dataset. In European Conference on Computer Vision (ECCV 2022); Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2023; Volume 13804, pp. 241–252. [Google Scholar]
- Feng, C.; Gong, M.; Deussen, O. A Balanced-Partitioning Treemapping Method for Digital Hierarchical Dataset. Virt. Real. Intell. Hardw. 2022, 4, 342–358. [Google Scholar] [CrossRef]
- Biró, A.; Cuesta-Vargas, A.I.; Martín-Martín, J.; Szilágyi, L.; Szilágyi, S.M. Synthetized Multilanguage OCR Using CRNN and SVTR Models for Realtime Collaborative Tools. Appl. Sci. 2023, 13, 4419. [Google Scholar] [CrossRef]
- Kim, G.; Hong, T.; Yim, M.; Nam, J.; Park, J.; Yim, J.; Hwang, W.; Yun, S.; Han, D.; Park, S. OCR-Free Document Understanding Transformer. In Proceedings of the European Conference on Computer Vision (ECCV 2022), Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Akasapu, A.; Sailaja, V.; Prasad, G. Implementation of Sobel filter using CUDA. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1045, 012016. [Google Scholar] [CrossRef]
- Eixelberger, T.; Wolkenstein, G.; Hackner, R.; Bruns, V.; Mühldorfer, S.; Geissler, U.; Belle, S.; Wittenberg, T. YOLO networks for polyp detection: A human-in-the-loop training approach. Curr. Dir. Biomed. Eng. 2022, 8, 277–280. [Google Scholar] [CrossRef]
- He, Y.; Yuan, J.L.; Li, L. Enhancing RNN Based OCR by Transductive Transfer Learning From Text to Images. AAAI Conf. Artif. Intell. 2018, 32, 8083–8084. [Google Scholar] [CrossRef]
- Dhanya, D.; Ramakrishnan, A.G. Optimal feature extraction for bilingual OCR. Lect. Notes Comp. Sci. 2002, 2423, 25–36. [Google Scholar]
- Kim, J.; Huh, J.; Park, I.; Bak, J.; Kim, D.; Lee, S. Small Object Detection in Infrared Images: Learning from Imbalanced Cross-Domain Data via Domain Adaptation. Appl. Sci. 2022, 12, 11201. [Google Scholar] [CrossRef]
- Rane, T.; Bhatt, A. A Deep Learning-Based Regression Scheme for Angle Estimation in Image Dataset. In Proceedings of the International Conference on Recent Trends in Image Processing and Pattern Recognition (RTIP2R 2022), Kingsville, TX, USA, 1–2 December 2023; pp. 282–296. [Google Scholar]
- Xin, F.F.; Zhang, H.P.; Pan, H.Q. Hybrid dilated multilayer faster RCNN for object detection. Vis. Comput. 2023. [Google Scholar] [CrossRef]
- PP-OCR. Available online: https://github.com/PaddlePaddle/PaddleOCR/blob/v2.5.0/doc/doc_en/ppocr_introduction_en.md#pp-ocrv3 (accessed on 6 December 2023).
- Komondor, One of the Greenest Supercomputers in the World, HPC Competence Center. Available online: https://hpc.kifu.hu/en/komondor-one-of-the-greenest-supercomputers-in-the-world (accessed on 13 October 2023).

| Topic | Classic AI Infrastructure | HPC Cluster Environment |
|---|---|---|
| Computational Power/Resources | In classic AI infrastructure, the user is limited by the computational resources available on a single machine or in a small cluster. Generating synthetic training data for multiple languages with a large dataset can be computationally intensive and time-consuming. | HPC clusters offer significantly more computational power, allowing the user to efficiently generate larger and more complex synthetic datasets for multilanguage OCR. |
| Scalability | Classic AI infrastructure may lack the scalability required to efficiently simultaneously generate synthetic datasets multiple languages. The user may need to create separate work flows for each language, which can be inefficient. | HPC clusters are designed for parallel processing, which means the user can distribute the workload across multiple nodes, enabling simultaneous dataset generation for multiple languages. This enhances efficiency and reduces time requirements. |
| Data Handling/Volume | Managing and storing large volumes of synthetic data for multiple languages can be challenging in a traditional setup. The user might encounter storage limitations and data management issues. | HPC environments provide advanced data storage and management capabilities. The handling and storage of large volumes of synthetic data are streamlined. |
| Parallelism/Distributed Computing | Implementing parallelism for data generation is more complex in classic infrastructure, making it harder to exploit multicore CPUs or GPUs efficiently. | HPC clusters are well-suited for distributed computing, enabling the user to distribute the dataset generation tasks across multiple nodes, which is especially beneficial for the generation of synthetic datasets for multiple languages. |
| Resource Management | — | HPC environments offer sophisticated resource management tools and job schedulers, allowing the user to optimize resource allocation and utilization for dataset generation tasks. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Biró, A.; Szilágyi, S.M.; Szilágyi, L. Optimal Training Dataset Preparation for AI-Supported Multilanguage Real-Time OCRs Using Visual Methods. Appl. Sci. 2023, 13, 13107. https://doi.org/10.3390/app132413107
Biró A, Szilágyi SM, Szilágyi L. Optimal Training Dataset Preparation for AI-Supported Multilanguage Real-Time OCRs Using Visual Methods. Applied Sciences. 2023; 13(24):13107. https://doi.org/10.3390/app132413107
Chicago/Turabian StyleBiró, Attila, Sándor Miklós Szilágyi, and László Szilágyi. 2023. "Optimal Training Dataset Preparation for AI-Supported Multilanguage Real-Time OCRs Using Visual Methods" Applied Sciences 13, no. 24: 13107. https://doi.org/10.3390/app132413107
APA StyleBiró, A., Szilágyi, S. M., & Szilágyi, L. (2023). Optimal Training Dataset Preparation for AI-Supported Multilanguage Real-Time OCRs Using Visual Methods. Applied Sciences, 13(24), 13107. https://doi.org/10.3390/app132413107