Estimation of Daily Actual Evapotranspiration of Tea Plantations Using Ensemble Machine Learning Algorithms and Six Available Scenarios of Meteorological Data


 , ,
, , 
Abstract
:1. Introduction
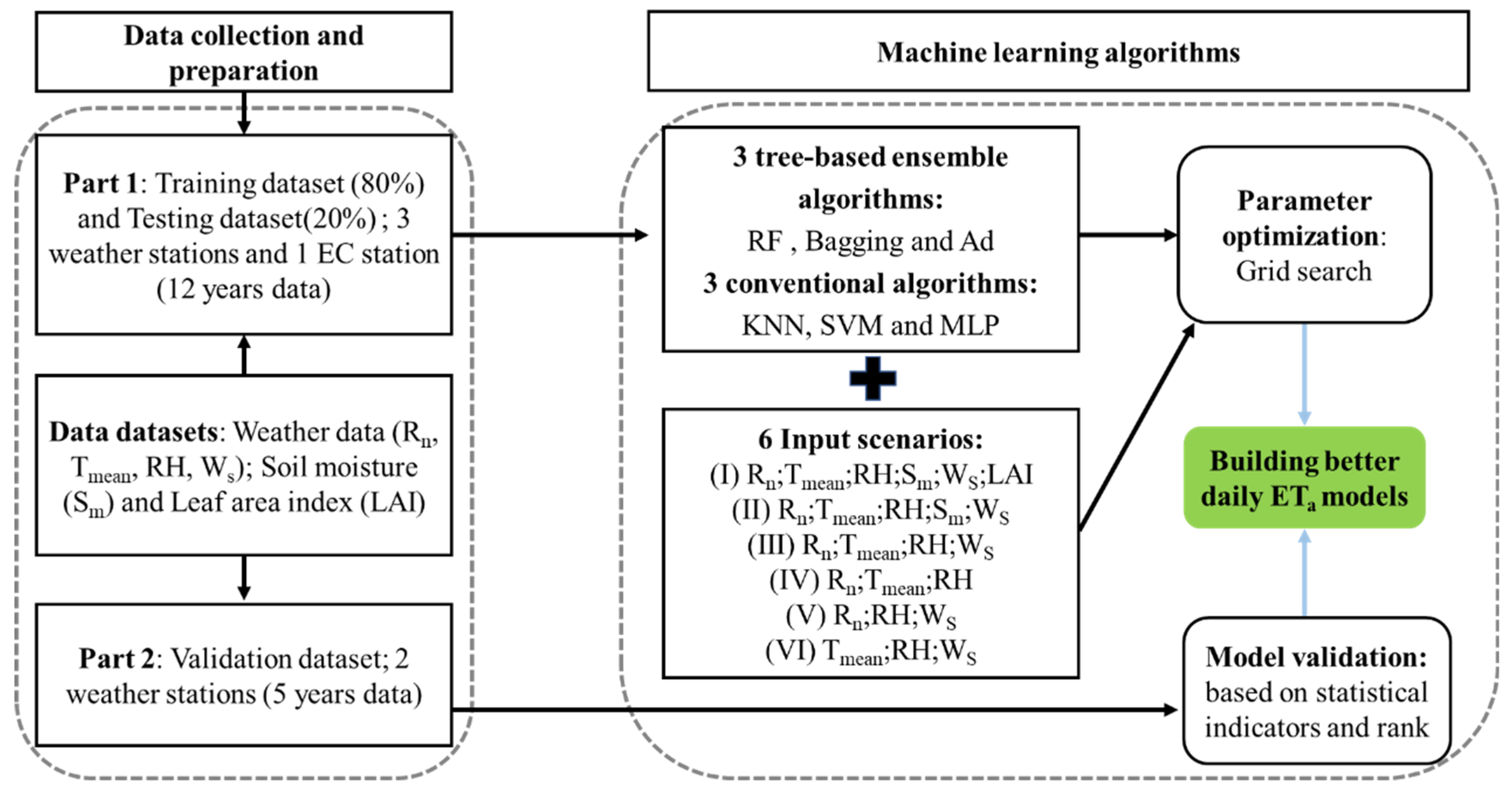
2. Materials and Methods
2.1. Study Area Description
2.2. Data Sources and Meteorological Scenarios
2.3. Machine Learning Methods
2.3.1. K-Nearest Neighbor (KNN)
2.3.2. Support Vector Machine (SVM)
2.3.3. Random Forest (RF)
2.3.4. Multilayer Perceptron (MLP)
2.3.5. Adaptive Boosting (AdaBoost)
2.3.6. Bagging
2.4. Performance Comparison Criteria
3. Results and Discussion
3.1. Climate and Evapotranspiration Characteristics
3.2. Performance of Machine Learning Models
3.3. Stability Appraisal and Uncertainty of Machine Learning Models
3.4. Contribution of Influencing Factors to the Predicted Daily ETa of Tea Plantation
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- FAO. FAO Stat Data. 2017. Available online: http://faostat.fao.org (accessed on 27 December 2017).
- NBSC. China Statistical Yearbook, Annual Publication; National Bureau of Statistics of China: Beijing, China, 2017. Available online: http://www.stats.gov.cn/tjsj/ndsj/2017/indexch.htm (accessed on 1 July 2018).
- Chiu, Y.C.; Chen, B.J.; Su, Y.S.; Huang, W.D.; Chen, C.C. A Leaf Disc Assay for Evaluating the Response of Tea (Camellia sinensis) to PEG-Induced Osmotic Stress and Protective Effects of Azoxystrobin against Drought. Plants 2021, 10, 546. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.C.; Wu, H.H.; Chen, J.G.; Chen, L.M.; Chang, N.; Ge, G.F.; Wan, X. Higher ROS scavenging ability and plasma membrane H+-ATPase activity are associated with potassium retention in drought tolerant tea plants. J. Plant Nutr. Soil Sci. 2020, 183, 406–415. [Google Scholar] [CrossRef]
- Geng, J.W.; Li, H.P.; Pang, J.P.; Zhang, W.S.; Shi, Y.J. The effects of land-use conversion on evapotranspiration and water balance of subtropical forest and managed tea plantation in Taihu Lake Basin, China. Hydrol. Process. 2022, 36, e14652. [Google Scholar] [CrossRef]
- Geng, J.; Li, H.; Pang, J.; Zhang, W.; Chen, D. Dynamics and environmental controls of energy exchange and evapotranspiration in a hilly tea plantation, China. Agric. Water Manag. 2020, 241, 106364. [Google Scholar] [CrossRef]
- Zheng, S.H.; Ni, K.; Ji, L.F.; Zhao, C.G.; Chai, H.L.; Yi, X.Y.; He, W.; Ruan, J. Estimation of Evapotranspiration and Crop Coefficient of Rain-Fed Tea Plants under a Subtropical Climate. Agronomy 2021, 11, 2332. [Google Scholar] [CrossRef]
- Liu, B.H.; Xu, M.; Henderson, M.; Qi, Y. Observed trends of precipitation amount, frequency, and intensity in China, 1960–2000. J. Geophys. Res. Atmos. 2005, 110, D8. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.-Q.; Li, Y.-F.; Zhang, L. Comparison of four Adaboost algorithm based artificial neural networks in wind speed predictions. Energy Convers. Manag. 2015, 92, 67–81. [Google Scholar] [CrossRef]
- Ma, S.M.; Zhou, T.J.; Dai, A.G.; Han, Z.Y. Observed Changes in the Distributions of Daily Precipitation Frequency and Amount over China from 1960 to 2013. J. Clim. 2015, 28, 6960–6978. [Google Scholar] [CrossRef]
- Kirkham, R.R.; Gee, G.W.; Jones, T.L. Weighing lysimeters for long-term water-balance investigations at remote sites. Soil Sci. Soc. Am. J. 1984, 48, 1203–1205. [Google Scholar] [CrossRef]
- Qiu, J.; Chen, H.; Wang, P.; Liu, Y.; Xia, X. Recent progress in atmospheric observation research in China. Adv. Atmos. Sci. 2007, 24, 940–953. [Google Scholar] [CrossRef]
- Varmaghani, A.; Eichinger, W.E.; Prueger, J.H. Modification of FAO Penman-Monteith equation for minor components of energy. Hydrol. Res. 2019, 50, 607–615. [Google Scholar] [CrossRef]
- Xiao, J.; Sun, G.; Chen, J.; Chen, H.; Chen, S.; Dong, G.; Gao, S.; Guo, H.; Guo, J.; Han, S.; et al. Carbon fluxes, evapotranspiration, and water use efficiency of terrestrial ecosystems in China. Agric. For. Meteorol. 2013, 182, 76–90. [Google Scholar] [CrossRef]
- Corbari, C.; Paleari, R.; Mantovani, F.; Tarro, S.; Mancini, M. A weighting lysimeter for a laboratory experiment on water and energy fluxes measurements and hydrological models verification. In EGU General Assembly Conference Abstracts; EGU: Vienna, Austria, 2017. [Google Scholar]
- Irmak, S. Nebraska water and energy flux measurement, modeling, and research network (NEBFLUX). Trans. ASABE 2010, 53, 1097–1115. [Google Scholar] [CrossRef]
- Hu, S.; Zhao, C.; Li, J.; Wang, F.; Chen, Y. Discussion and reassessment of the method used for accepting or rejecting data observed by a Bowen ratio system. Hydrol. Process. 2014, 28, 4506–4510. [Google Scholar] [CrossRef]
- Huang, G.; Wu, L.; Ma, X.; Zhang, W.; Fan, J.; Yu, X.; Zeng, W.; Zhou, H. Evaluation of CatBoost method for prediction of reference evapotranspiration in humid regions. J. Hydrol. 2019, 574, 1029–1041. [Google Scholar] [CrossRef]
- Huang, M.F.; Liu, S.M.; Guo, X.Y.; Zhu, Q.J.; Li, J.T. Analysis of the factors influencing surface sensible heat fluxes with large aperture scintillometers. In Proceedings of the IGARSS 2004: IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004; pp. 4281–4284. [Google Scholar]
- Li, Z.Q.; Yu, G.R.; Wen, X.F.; Zhang, L.M.; Ren, C.Y.; Fu, Y.L. Energy balance closure at ChinaFLUX sites. Sci. China Ser. D Earth Sci. 2005, 48, 51–62. [Google Scholar]
- Wilson, K.; Goldstein, A.; Falge, E.; Aubinet, M.; Baldocchi, D.; Berbigier, P.; Bernhofer, C.; Ceulemans, R.; Dolman, H.; Field, C.; et al. Energy balance closure at FLUXNET sites. Agric. For. Meteorol. 2002, 113, 223–243. [Google Scholar] [CrossRef]
- Gelybo, G.; Barcza, Z.; Kern, A.; Kljun, N. Effect of spatial heterogeneity on the validation of remote sensing based GPP estimations. Agric. For. Meteorol. 2013, 174, 43–53. [Google Scholar] [CrossRef]
- Farahani, H.J.; Howell, T.A.; Shuttleworth, W.J.; Bausch, W.C. Evapotranspiration: Progress in measurement and modeling in agriculture. Trans. ASABE 2007, 50, 1627–1638. [Google Scholar] [CrossRef]
- Howell, T. Enhanceing water use efficiency in irrigated agriculture. Agron. J. 2001, 93, 281–289. [Google Scholar] [CrossRef]
- Lecina, S.; Martínez-Cob, A.; Pérez, P.J.; Villalobos, F.J.; Baselga, J.J. Fixed versus variable bulk canopy resistance for reference evapotranspiration estimation using the Penman–Monteith equation under semiarid conditions. Agric. Water Manag. 2003, 60, 181–198. [Google Scholar] [CrossRef]
- Tang, D.; Feng, Y.; Gong, D.; Hao, W.; Cui, N. Evaluation of artificial intelligence models for actual crop evapotranspiration modeling in mulched and non-mulched maize croplands. Comput. Electron. Agric. 2018, 152, 375–384. [Google Scholar] [CrossRef]
- Azzam, A.; Zhang, W.; Akhtar, F.; Shaheen, Z.; Elbeltagi, A. Estimation of green and blue water evapotranspiration using machine learning algorithms with limited meteorological data: A case study in Amu Darya River Basin, Central Asia. Comput. Electron. Agric. 2022, 202, 107403. [Google Scholar] [CrossRef]
- Dou, X.; Yang, Y. Evapotranspiration estimation using four different machine learning approaches in different terrestrial ecosystems. Comput. Electron. Agric. 2018, 148, 95–106. [Google Scholar] [CrossRef]
- Zhang, C.; Brodylo, D.; Rahman, M.; Rahman, M.A.; Douglas, T.A.; Comas, X. Using an object-based machine learning ensemble approach to upscale evapotranspiration measured from eddy covariance towers in a subtropical wetland. Sci. Total Environ. 2022, 831, 154969. [Google Scholar] [CrossRef] [PubMed]
- Fan, J.; Yue, W.; Wu, L.; Zhang, F.; Cai, H.; Wang, X.; Lu, X.; Xiang, Y. Evaluation of SVM, ELM and four tree-based ensemble models for predicting daily reference evapotranspiration using limited meteorological data in different climates of China. Agric. For. Meteorol. 2018, 263, 225–241. [Google Scholar] [CrossRef]
- Gonzalo-Martin, C.; Lillo-Saavedra, M.; Garcia-Pedrero, A.; Lagos, O.; Menasalvas, E. Daily Evapotranspiration Mapping Using Regression Random Forest Models. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 5359–5368. [Google Scholar] [CrossRef]
- Salam, R.; Islam, A.R.M.T. Potential of RT, bagging and RS ensemble learning algorithms for reference evapotranspiration prediction using climatic data-limited humid region in Bangladesh. J. Hydrol. 2020, 590, 125241. [Google Scholar] [CrossRef]
- Shao, G.; Han, W.; Zhang, H.; Liu, S.; Wang, Y.; Zhang, L.; Cui, X. Mapping maize crop coefficient Kc using random forest algorithm based on leaf area index and UAV-based multispectral vegetation indices. Agric. Water Manag. 2021, 252, 106906. [Google Scholar] [CrossRef]
- Wang, Y.; Zou, Y.; Cai, H.; Zeng, Y.; He, J.; Yu, L.; Zhang, C.; Saddique, Q.; Peng, X.; Siddique, K.H.; et al. Seasonal variation and controlling factors of evapotranspiration over dry semi-humid cropland in Guanzhong Plain, China. Agric. Water Manag. 2022, 259, 107242. [Google Scholar] [CrossRef]
- Zhang, H.; Hu, Y.; Cai, J.; Li, X.; Tian, B.; Zhang, Q.; An, W. Calculation of evapotranspiration in different climatic zones combining the long-term monitoring data with bootstrap method. Environ. Res. 2020, 191, 110200. [Google Scholar] [CrossRef] [PubMed]
- Lood, C.; Boeckaerts, D.; Stock, M.; De Baets, B.; Lavigne, R.; van Noort, V.; Briers, Y. Digital phagograms: Predicting phage infectivity through a multilayer machine learning approach. Curr. Opin. Virol. 2022, 52, 174–181. [Google Scholar] [CrossRef] [PubMed]
- Rawson, A.; Brito, M.; Sabeur, Z.; Tran-Thanh, L. A machine learning approach for monitoring ship safety in extreme weather events. Saf. Sci. 2021, 141, 105336. [Google Scholar] [CrossRef]
- Sirsat, M.S.; Fermé, E.; Câmara, J. Machine Learning for Brain Stroke: A Review. J. Stroke Cerebrovasc. Dis. 2020, 29, 105162. [Google Scholar] [CrossRef] [PubMed]
- Waring, J.; Lindvall, C.; Umeton, R. Automated machine learning: Review of the state-of-the-art and opportunities for healthcare. Artif. Intell. Med. 2020, 104, 101822. [Google Scholar] [CrossRef]
- Greener, J.G.; Kandathil, S.M.; Moffat, L.; Jones, D.T. A guide to machine learning for biologists. Nat. Rev. Mol. Cell Biol. 2022, 23, 40–55. [Google Scholar] [CrossRef]
- Khalid, M.; Wang, L.; Wang, K.; Pan, C.; Aslam, N.; Cao, Y. Deep Reinforcement Learning-Based Long-Range Autonomous Valet Parking for Smart Cities. Sustain. Cities Soc. 2021, 89, 104311. [Google Scholar] [CrossRef]
- Condran, S.; Bewong, M.; Islam, M.Z.; Maphosa, L.; Zheng, L. Machine Learning in Precision Agriculture: A Survey on Trends, Applications and Evaluations Over Two Decades. IEEE Access 2022, 10, 73786–73803. [Google Scholar] [CrossRef]
- Zhang, S.; Li, X.; Zong, M.; Zhu, X.; Wang, R. Efficient kNN Classification with Different Numbers of Nearest Neighbors. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 1774–1785. [Google Scholar] [CrossRef]
- Shamshirband, S.; Hashemi, S.; Salimi, H.; Samadianfard, S.; Asadi, E.; Shadkani, S.; Kargar, K.; Mosavi, A.; Nabipour, N.; Chau, K.W. Predicting Standardized Streamflow index for hydrological drought using machine learning models. Eng. Appl. Comput. Fluid Mech. 2020, 14, 339–350. [Google Scholar] [CrossRef]
- Kang, J.; Fernandez-Beltran, R.; Hong, D.; Chanussot, J.; Plaza, A. Graph Relation Network: Modeling Relations Between Scenes for Multilabel Remote-Sensing Image Classification and Retrieval. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4355–4369. [Google Scholar] [CrossRef]
- Chitralekha, G.; Roogi, J.M. A Quick Review of ML Algorithms. In Proceedings of the 2021 6th International Conference on Communication and Electronics Systems (ICCES), Coimbatre, India, 8–10 July 2021. [Google Scholar]
- Karmani, P.; Chandio, A.A.; Korejo, I.A.; Chandio, M.S. A Review of Machine Learning for Healthcare Informatics Specifically Tuberculosis Disease Diagnostics. In Proceedings of the Intelligent Technologies and Applications: First International Conference, INTAP 2018, Bahawalpur, Pakistan, 23–25 October 2018; Springer: Berlin/Heidelberg, Germany, 2019; Volume 932, pp. 50–61. [Google Scholar]
- Granata, F.; Gargano, R.; de Marinis, G. Artificial intelligence based approaches to evaluate actual evapotranspiration in wetlands. Sci. Total Environ. 2020, 703, 135653. [Google Scholar] [CrossRef] [PubMed]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [PubMed]
- Liao, Y.; Han, L.; Wang, H.; Zhang, H. Prediction Models for Railway Track Geometry Degradation Using Machine Learning Methods: A Review. Sensors 2022, 22, 7275. [Google Scholar] [CrossRef] [PubMed]
- Bektaş, J. EKSL: An effective novel dynamic ensemble model for unbalanced datasets based on LR and SVM hyperplane-distances. Inf. Sci. 2022, 597, 182–192. [Google Scholar] [CrossRef]
- Moosaei, H.; Ganaie, M.A.; Hladík, M.; Tanveer, M. Inverse free reduced universum twin support vector machine for imbalanced data classification. Neural Netw. 2022, 157, 125–135. [Google Scholar] [CrossRef]
- Kisi, O. Pan evaporation modeling using least square support vector machine, multivariate adaptive regression splines and M5 model tree. J. Hydrol. 2015, 528, 312–320. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Xu, T.; Guo, Z.; Liu, S.; He, X.; Meng, Y.; Xu, Z.; Xia, Y.; Xiao, J.; Zhang, Y.; Ma, Y.; et al. Evaluating Different Machine Learning Methods for Upscaling Evapotranspiration from Flux Towers to the Regional Scale. J. Geophys. Res. Atmos. 2018, 123, 8674–8690. [Google Scholar] [CrossRef]
- Deng, K.; Zhao, H.; Li, N.; Wei, W. Identification of minerals in hyperspectral imagery based on the attenuation spectral absorption index vector using a multilayer perceptron. Remote Sens. Lett. 2021, 12, 449–458. [Google Scholar] [CrossRef]
- Huang, X.; Li, Z.; Jin, Y.; Zhang, W. Fair-AdaBoost: Extending AdaBoost method to achieve fair classification. Expert Syst. Appl. 2022, 202, 117240. [Google Scholar] [CrossRef]
- Landesa-Vazquez, I.; Luis Alba-Castro, J. Shedding light on the asymmetric learning capability of AdaBoost. Pattern Recognit. Lett. 2012, 33, 247–255. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, X.; Yin, J. Adaptive boosting-based computational model for predicting potential miRNA-disease associations. Bioinformatics 2020, 36, 330. [Google Scholar] [CrossRef] [PubMed]
- Ngo, G.; Beard, R.; Chandra, R. Evolutionary bagging for ensemble learning. Neurocomputing 2022, 510, 1–14. [Google Scholar] [CrossRef]
- Tavassoli, S.; Koosha, H. Hybrid ensemble learning approaches to customer churn prediction. Kybernetes 2022, 51, 1062–1088. [Google Scholar] [CrossRef]
- Hong, H.; Liu, J.; Zhu, A.X. Modeling landslide susceptibility using LogitBoost alternating decision trees and forest by penalizing attributes with the bagging ensemble. Sci. Total Environ. 2020, 718, 137231. [Google Scholar] [CrossRef]
- Granger, R.J.; Gray, D.M. Evaporation from natural nonsaturated surfaces. J. Hydrol. 1989, 111, 21–29. [Google Scholar] [CrossRef]
- Feng, Y.; Cui, N.; Zhao, L.; Hu, X.; Gong, D. Comparison of ELM, GANN, WNN and empirical models for estimating reference evapotranspiration in humid region of Southwest China. J. Hydrol. 2016, 536, 376–383. [Google Scholar] [CrossRef]
- Buttar, N.A.; Yongguang, H.; Shabbir, A.; Lakhiar, I.A.; Ullah, I.; Ali, A.; Aleem, M.; Yasin, M.A. Estimation of evapotranspiration using Bowen ratio method. IFAC-PapersOnLine 2018, 51, 807–810. [Google Scholar] [CrossRef]
- Taylor, K.E. Summarizing multiple aspects of model performance in a single diagram. J. Geophys. Res. Atmos. 2001, 106, 7183–7192. [Google Scholar] [CrossRef]
- Venkatram, A. Computing and displaying model performance statistics. Atmos. Environ. 2008, 42, 6862–6868. [Google Scholar] [CrossRef]
- Hu, X.; Shi, L.; Lin, G.; Lin, L. Comparison of physical-based, data-driven and hybrid modeling approaches for evapotranspiration estimation. J. Hydrol. 2021, 601, 126592. [Google Scholar] [CrossRef]
- Hassan, M.A.; Khalil, A.; Kaseb, S.; Kassem, M.A. Exploring the potential of tree-based ensemble methods in solar radiation modeling. Appl. Energy 2017, 203, 897–916. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 23, 18–22. [Google Scholar]
- Hu, D.; Zhang, C.; Cao, W.; Lv, X.; Xie, S. Grain Yield Predict Based on GRA-AdaBoost-SVR Model. J. Big Data 2021, 3, 65. [Google Scholar] [CrossRef]
- Yamaç, S.S.; Todorovic, M. Estimation of daily potato crop evapotranspiration using three different machine learning algorithms and four scenarios of available meteorological data. Agric. Water Manag. 2020, 228, 105875. [Google Scholar] [CrossRef]
- Pang, J.; Li, H.; Yu, F.; Geng, J.; Zhang, W. Environmental controls on water use efficiency in a hilly tea plantation in southeast China. Agric. Water Manag. 2022, 269, 107678. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Longitude | Latitude | Elevation (m) | MAP (mm) | MAT (°C) | Period | LULC |
|---|---|---|---|---|---|---|---|
| SSY | 119.316 | 31.268 | 55 | 1249.3 | 15.8 | 2010–2017 | 3–10 years old tea |
| TMXM | 119.397 | 31.313 | 39 | 1507.4 | 17.8 | 2020–2021 | 5–6 years old tea |
| TMHS | 119.411 | 31.269 | 28 | 1371.3 | 16.7 | 2016–2021 | 5–10 years old tea |
| Tea plantation flux site | 119.453 | 31.269 | 103 | 1216.3 | 16.2 | 2014–2021 | 4–11 years old tea |
| HB | 119.432 | 31.237 | 91 | 1237.6 | 15.9 | 2014–2017 | 5–8 years old tea |
| PQ | 119.446 | 31.217 | 94 | 1109.5 | 16.3 | 2017–2021 | 6–10 years old tea |
| Rn | Tmean | Ws | RH | Sm | ETa | |
|---|---|---|---|---|---|---|
| Rn | 1 | |||||
| Tmean | 0.65 | 1 | ||||
| Ws | 0.08 | −0.06 | 1 | |||
| RH | −0.37 | 0.13 | −0.29 | 1 | ||
| Sm | −0.13 | −0.35 | −0.04 | 0.06 | 1 | |
| ETa | 0.83 | 0.71 | 0.18 | −0.17 | −0.22 | 1 |
| Scenario | Input Data | |||||
|---|---|---|---|---|---|---|
| Rn | Tmean | Ws | RH | LAI | Sm | |
| Scenario 1 | √ | √ | √ | √ | √ | √ |
| Scenario 2 | √ | √ | √ | √ | √ | |
| Scenario 3 | √ | √ | √ | √ | ||
| Scenario 4 | √ | √ | √ | |||
| Scenario 5 | √ | √ | √ | |||
| Scenario 6 | √ | √ | √ | |||
| Algorithm | Model | Scenario | MAE | RMSE | NSE | Slope | R2 |
|---|---|---|---|---|---|---|---|
| (mm day−1) | (mm day−1) | ||||||
| K-Nearest Neighbor | kNN6 | Scenario 1 | 0.3630 | 0.4910 | 0.872 | 0.841 | 0.872 |
| kNN5 | Scenario 2 | 0.3799 | 0.5216 | 0.766 | 0.824 | 0.856 | |
| kNN4 | Scenario 3 | 0.3756 | 0.5192 | 0.857 | 0.839 | 0.857 | |
| kNN3a | Scenario 4 | 0.3843 | 0.5213 | 0.856 | 0.836 | 0.856 | |
| kNN3b | Scenario 5 | 0.4486 | 0.6008 | 0.808 | 0.786 | 0.808 | |
| kNN3c | Scenario 6 | 0.5709 | 0.7799 | 0.677 | 0.682 | 0.671 | |
| Support Vector Machine | SVM6 | Scenario 1 | 0.3213 | 0.4602 | 0.887 | 0.871 | 0.887 |
| SVM5 | Scenario 2 | 0.3360 | 0.4772 | 0.804 | 0.845 | 0.879 | |
| SVM4 | Scenario 3 | 0.3483 | 0.4902 | 0.873 | 0.872 | 0.873 | |
| SVM3a | Scenario 4 | 0.3581 | 0.5223 | 0.855 | 0.829 | 0.855 | |
| SVM3b | Scenario 5 | 0.3885 | 0.5403 | 0.845 | 0.816 | 0.845 | |
| SVM3c | Scenario 6 | 0.5333 | 0.7407 | 0.709 | 0.694 | 0.710 | |
| Multilayer Perceptron | MLP6 | Scenario 1 | 0.3630 | 0.5616 | 0.837 | 0.745 | 0.833 |
| MLP5 | Scenario 2 | 0.4181 | 0.5812 | 0.704 | 0.716 | 0.819 | |
| MLP4 | Scenario 3 | 0.4095 | 0.5680 | 0.815 | 0.724 | 0.828 | |
| MLP3a | Scenario 4 | 0.4191 | 0.5809 | 0.823 | 0.729 | 0.821 | |
| MLP3b | Scenario 5 | 0.4728 | 0.6246 | 0.791 | 0.677 | 0.793 | |
| MLP3c | Scenario 6 | 0.6330 | 0.8590 | 0.609 | 0.517 | 0.610 | |
| Adaptive boosting | AdaBoost6 | Scenario 1 | 0.4072 | 0.5197 | 0.854 | 0.772 | 0.849 |
| AdaBoost5 | Scenario 2 | 0.3936 | 0.5292 | 0.846 | 0.762 | 0.851 | |
| AdaBoost4 | Scenario 3 | 0.4122 | 0.5452 | 0.848 | 0.761 | 0.842 | |
| AdaBoost3a | Scenario 4 | 0.4157 | 0.5564 | 0.831 | 0.753 | 0.835 | |
| AdaBoost3b | Scenario 5 | 0.4805 | 0.6241 | 0.803 | 0.735 | 0.793 | |
| AdaBoost3c | Scenario 6 | 0.5991 | 0.7734 | 0.682 | 0.606 | 0.683 | |
| Bagging | Bg6 | Scenario 1 | 0.3275 | 0.4368 | 0.887 | 0.869 | 0.893 |
| Bg5 | Scenario 2 | 0.3514 | 0.4778 | 0.870 | 0.842 | 0.878 | |
| Bg4 | Scenario 3 | 0.3638 | 0.4841 | 0.871 | 0.836 | 0.876 | |
| Bg3a | Scenario 4 | 0.3872 | 0.5158 | 0.858 | 0.843 | 0.842 | |
| Bg3b | Scenario 5 | 0.4238 | 0.5593 | 0.818 | 0.813 | 0.833 | |
| Bg3c | Scenario 6 | 0.5676 | 0.7720 | 0.694 | 0.703 | 0.684 | |
| Random Forest | RF6 | Scenario 1 | 0.3186 | 0.4102 | 0.897 | 0.870 | 0.906 |
| RF5 | Scenario 2 | 0.3407 | 0.4645 | 0.815 | 0.856 | 0.886 | |
| RF4 | Scenario 3 | 0.3504 | 0.4717 | 0.877 | 0.851 | 0.882 | |
| RF3a | Scenario 4 | 0.3758 | 0.5138 | 0.861 | 0.841 | 0.860 | |
| RF3b | Scenario 5 | 0.4170 | 0.5570 | 0.836 | 0.810 | 0.835 | |
| RF3c | Scenario 6 | 0.5441 | 0.7319 | 0.713 | 0.705 | 0.710 | |
| GG model | [63] | 0.3412 | 0.4900 | 0.837 | 0.846 | 0.870 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Geng, J.; Li, H.; Luan, W.; Shi, Y.; Pang, J.; Zhang, W. Estimation of Daily Actual Evapotranspiration of Tea Plantations Using Ensemble Machine Learning Algorithms and Six Available Scenarios of Meteorological Data. Appl. Sci. 2023, 13, 12961. https://doi.org/10.3390/app132312961
Geng J, Li H, Luan W, Shi Y, Pang J, Zhang W. Estimation of Daily Actual Evapotranspiration of Tea Plantations Using Ensemble Machine Learning Algorithms and Six Available Scenarios of Meteorological Data. Applied Sciences. 2023; 13(23):12961. https://doi.org/10.3390/app132312961
Chicago/Turabian StyleGeng, Jianwei, Hengpeng Li, Wenfei Luan, Yunjie Shi, Jiaping Pang, and Wangshou Zhang. 2023. "Estimation of Daily Actual Evapotranspiration of Tea Plantations Using Ensemble Machine Learning Algorithms and Six Available Scenarios of Meteorological Data" Applied Sciences 13, no. 23: 12961. https://doi.org/10.3390/app132312961
APA StyleGeng, J., Li, H., Luan, W., Shi, Y., Pang, J., & Zhang, W. (2023). Estimation of Daily Actual Evapotranspiration of Tea Plantations Using Ensemble Machine Learning Algorithms and Six Available Scenarios of Meteorological Data. Applied Sciences, 13(23), 12961. https://doi.org/10.3390/app132312961