1. Introduction
The number of internet users is increasing worldwide. This presents a chance for attackers to escalate their attacks and continue to infringe upon the resources and capabilities of network and computer systems. This places additional strain on networks in relation to their security requirements. Consequently, there is an increasing demand for network security systems and applications that aid in enhancing the availability of networks, bolstering their reliability, lessening the vulnerability and potential misuse of network and computer systems, and decreasing the frequency and severity of malicious attacks.
Thus, various methods have been developed for the detection of illegal access and probing attack attempts that enable end users to reject or accept incoming malicious requests [
1]. Common means of attack detection include firewalls and intrusion detection systems (IDSs). Both approaches have been widely used to preclude undesirable incoming and outgoing data [
2]. In general, IDSs focus on an intruder who can change a user’s system data or steal it [
3].
In 1980, Anderson [
4] formulated the concept of IDSs by developing an application that monitors a computer system that operates by tracking and identifying a user’s behavior for the detection of any anomalous behaviors [
4]. In 2014, Garden et al. [
5] clarified that IDSs can be classified based on their detection methods or data sources. IDSs that are based on data sources encompass the host-based intrusion detection system (HIDS), which is a system that receives information from individual hosts and traces and checks the system records. The monitoring tool is installed on all monitored hosts, allowing us to analyze event logs, key system files, and network activity for any suspicious changes or patterns that may signal malicious activity [
5]. Network-based intrusion detection systems (NIDS) control traffic based on network requests and packets. These systems analyze network packets, isolate those that seem to be unordinary packets, and flag them accordingly. NIDSs can also be applied to data collected from various hosts to identify signs of intrusion [
5].
Generally, NIDSs perform two types of intrusion detection (ID): misuse and anomaly ID. Misuse ID, also known as signature-based ID, is based on the signatures of attacks that are established in NIDSs as alarms of intrusion. Attack signatures include patterns of specific activities or movements that differ from established patterns of normal movements or activities, which define whether a particular activity is a normal or intrusive activity [
6]. Anomaly ID, on the other hand, identifies new types of intrusions and infusions in the normal use of system resources.
Anomaly detection methods are useful for unknown counterattacks and new attacks because of the lack of previous knowledge regarding the necessary steps for dealing with these types of intrusions [
6]. Anomaly IDSs were classified according to the detection method employed. IDSs generally apply numerous detection methods, such as machine learning methods, reinforcement learning (RL) [
7], neural networks (NNs) [
8], fuzzy logic [
9], and support vector machines (SVMs) [
10].
To provide a safe and secure network environment, numerous artificial intelligence techniques have been employed to detect intrusions. In this respect, several measures of ID efficiency have been used, the most common of which are the detection rate (DR), accuracy (AC), and the false alarm rate (FAR).
The development of a high-performance IDS model poses substantial obstacles, particularly when dealing with network packets that consist of a diverse array of features. This gives rise to the feature selection dilemma, which plays a crucial role in the development of IDS. Utilizing optimized feature sets aids in reducing computational demands and processing duration, ultimately resulting in improved classification precision and a reduction in the false alarm rates. A considerable number of research efforts have been devoted to addressing the feature selection issue, which entails the selection of a vast spectrum of features [
11]. In this regard, various approaches to feature selection can be broadly categorized as supervised and unsupervised methods. The former group of methods is divided into wrapper, filter, and embedded methods. The wrapper-based algorithm [
12] uses a classifier to assess the relevance of the selected data subsets to ultimately specify the optimal set of features that contribute to higher accuracy. Filter-based feature selection approaches [
13,
14], on the other hand, are based on careful selection of appropriate feature combinations to be used in training the IDS. Compared to the wrapper approach, filter-based methods are more efficient in computing. Embedded methods [
11] can be defined as combinations of the filter and wrapper methods. In these methods, the classifier specifies the weights and importance of the features during training.
The significance of this study lies in the identification of an IDS through the utilization of contemporary machine learning techniques for the purpose of enhancing cybersecurity. The proposed work addresses two primary concerns: feature filtration and the intelligent detection system. The process of feature filtration is an important matter as it aims to identify the most suitable set of network features in order to enhance the accuracy of detection and mitigate the occurrence of false detections. The intelligent detection system integrates intelligent approaches, namely the extended classifier system (XCS) and the genetic algorithm (GA). The GA assumes the responsibility of generating new classifiers within the system, which serves as the central component of the XCS during the process of rule matching. Based on the preceding discourse, it can be asserted that feature filtration is adequate for managing extensive volumes of data, such as those found in the KDD99 dataset.
This paper presents fuzzy clustering using the local approximation of membership (FLAME) algorithm as an effective feature filtration approach for detecting cyberattacks in networks with high-volume traffic, such as KDD99 data. Thus, the proposed detection system is based on feature filtration using FLAME and a detection model using the XCS, with the entire enhancement of GA by applying the cuckoo search algorithm (CS).
The main contributions of the proposed work are as follows:
Recap the state-of-the-art works concerning feature selection algorithms utilized in ID.
Developing a new feature filtration method based on FLAME to specify the optimal subset of features that affect attacks detection and eliminate the features that raise a false alarm.
Propose a novel modification of the GA that integrates the cuckoo search algorithm as a selection method, aiming to improve the efficiency of the IDS classifier and attack detection.
Evaluate the proposed feature selection for IDS using KDD99.
Evaluate the proposed IDS and compare its results with the state-of-the-art works in terms of the detection rate (DR), accuracy (AC), and the false alarm rate (FAR) using KDD99.
This paper is organized into six sections.
Section 2 reviews the previous literature on feature selection in IDSs.
Section 3 outlines the research background, and
Section 4 describes the proposed IDS.
Section 5 presents the experimental results and evaluations.
Section 6 concludes this paper by highlighting future research directions.
2. Related Work
Many researchers have investigated network attack detection and conducted experiments to enable network systems and users to communicate online in a stable and secure environment. The efficiency of existing IDS is assessed by accuracy, the detection rate, the false alarm rate, and number of features used.
Selecting appropriate network features has a positive impact on improving ID performance. In 2016, researchers [
15] developed a hybrid model for an IDS based on machine learning methods that operates by analyzing the behavior of network data and comparing it with the behavior of prior features. By reducing the number of network features to process from 41 to 29, this system achieved a detection accuracy of 88.23%.
In 2019, researchers [
16] applied a feature filtration method called “wrapper” that is based on the linear correlation coefficient algorithm (FGLCC) and the cuttlefish algorithm (CFA). This method uses a decision tree as the classifier. Experiments revealed that this method achieves an intrusion detection accuracy of 95.03% and a low FAR of 1.65%. In the same year, Boonyopakornin [
17] proposed an IDS based on fuzzy logic and genetic network programming (GNP), which he abbreviated as FLGNP. The main role of the proposed system is features filtration. Consequently, this system selected 24 features to process out of the 41 input features. The test results revealed that this system had a detection accuracy of 94.8%.
Researchers [
8] have proposed group convolutional neural networks (CNNs) for filtering network features by finding correlations between features. Three steps were performed to accomplish this task. Initially, correlation coefficients were computed to identify and quantify the relationships between the features. To analyze the correlation coefficients, they were first sorted in descending order and grouped into columns. A one-dimensional convolutional neural network model (CNN) with convolution kernels and pooling filters was then used to process the grouped data. Subsequently, the reconstructed network features are fed into shadow machine learning models to predict network attacks. The results revealed that the features generated by the group CNN model could reduce the dimensionality of the data and maximize performance. Subsequently, a machine learning model that relied on the constructed features as inputs was applied. To evaluate the performance of this feature filtration method, experiments were conducted on the KDD99 and CICMalDroid2020 datasets, which were categorized as modest datasets. Data subsets corresponding to varying proportions of the original datasets were employed in the network feature filtration experiments using group CNNs. The results showed that the proposed feature filtration method performed better on the KDD99 dataset than on the CICMalDroid2020z dataset in terms of accuracy for all studied data proportions (subsets). The highest accuracy achieved by this system when applied to the KDD99 and CICMalDroid2020 datasets was 97.64% and 81.1%, respectively.
Alsharafat [
13] presented a cuckoo method for feature filtration (cuckoo-ID) to trim irrelevant features. Nineteen filtered features were used in the XCS. Experiments were conducted on the KDD99 dataset, and the results revealed that the DR of the proposed system was 98.9% and that the FAR was 0.09%.
In 2022, Geo [
18] proposed an ID method that depended on feature learning and combined a CNN with a BiLSTM. This method was tested using the KDD99 dataset. Both CNN and BiLSTM were used to extract information on the features that influence the detection accuracy, rather than feature filtration. For intrusion classification, a C5.0 classifier was employed to improve the ID by increasing the DR and reducing the FAR. Experiments revealed that this method could increase the mean detection accuracy to 95.50% and reduce the false positive rate to 4.24%.
In 2019, Vinayakumar et al. [
19] explored the possibility of using a deep neural network (DNN) to develop a flexible and effective IDS for detecting unexpected and unpredictable attacks. In addition, they compared multiple layers of DNN with six classifiers: DT, RF, LR, NB, KNN, and SVM-rbfto. Furthermore, they tested three subsets of the KDD99 dataset containing four, eight, and eleven features. The experimental results revealed that the proposed system performed better with eleven- and eight-feature subsets than with the four-feature subset. Additionally, this system demonstrated slightly better performance with the eleven-feature subset than with the eight-feature subset, as evidenced by the finding that the average detection accuracy was approximately 93.2% in both cases. In addition, a new deep neural network intrusion detection model (NDNN) developed with four hidden layers [
20] depending on 41 features. The test results revealed that this system had a detection accuracy of 99.9%, a DR of 99.95% and a FAR of 0.03%.
Nimbalkar et al. [
21] proposed an IDS that performs ID using three main processes: data preprocessing, feature selection, and rule-based JRip classification. Data preprocessing is aimed at removing noise, network traffic, and features that provide the same information in text format (.txt). In this system, the missing and NaN values of the features are set to zero. Then, two new reduced feature subsets (RFSs), RFS-1 and RFS-2, perform intersection and union operations. Subsequently, the RFS-1 and RFS-2 subsets were introduced into the classifier system using Jrip rule-based classification. This IDS was evaluated using the KDD99 and IoT-BoT datasets. The testing results indicated that the same detection accuracy (99.99%) could be achieved by this system when applied to the KDD99 and IoT-BoT datasets and that the best subset of features, which they labeled RFS-1, contains 16 features.
Deng and Yang [
22] proposed an ID model based on an autoencoder (BP) and improved GA (IGA-BP). The BP autoencoder was used in this model to eliminate redundant network feature information, whereas IGP-BP was employed to breed the system with a new population after selecting the best parents to perform crossover and mutation and replace the worst parent. All the experiments were conducted on 41 network features of the KDD99 dataset. The experimental results indicated the effectiveness of the IGP-BP model in detecting attacks, as the detection accuracy reached 98.27% and the FAR was 0.87.
Okay et al. [
14] proposed a new feature selection approach (FSAP) that reduces the number of KDD99 features to process from 41 to 10 features. The FSAP performs two processes: feature selection and ID. For feature selection, the most appropriate features were selected based on the threshold values. Subsequently, all features greater than the threshold value were selected. For ID, this approach uses a signature-based method to recognize anomalous or suspicious behavior. As a result, this approach demonstrated high detection performance, corresponding to a detection accuracy of 99.81% and a FAR of 0.056.
Researchers [
23] have developed a framework that depends on deep learning and metaheuristic (MH) optimization algorithms for extracting and selecting network features. A CNN is then used to extract the most appropriate network features. A new MH optimization algorithm called the Reptile Search Algorithm (RSA), which can select the most important network features, was used. The proposed framework then used 10 features from the KDD99 dataset. Testing revealed that the detection accuracy of this framework was 92.344%. Also, in [
24], two novel deep learning methodologies for network intrusion detection were presented. Tang et al. [
24] introduced a self-taught learning (STL) approach, successfully reducing feature count from 41 to 5, while achieving a high accuracy of 97.9% and a low false alarm rate (FAR) of 0.5%. Wang [
25], on the other hand, employed stacked autoencoders to process raw network traffic data directly, resulting in a reduction in features from 41 to 22. The accuracy in this case reached 97.85%, although with a slightly higher FAR of 2.15%.
ASLAM KHAN and his colleagues [
26] introduced a novel two-stage deep learning (TSDL) model that utilizes a stacked autoencoder with a softmax classifier. The model consists of two decision stages: (1) an initial stage that classifies network traffic as normal or abnormal using a probability score; and (2) a final decision stage that differentiates between the normal state and other attack classes. By employing this approach, the required number of network features is reduced from 41 to 10. Comparative simulation results reveal that our TSDL model achieves high detection rates reaches to 99.996% and decreases the false alarm rate to a mere 0.0001.
Zehong et al. [
7] proposed a novel ensemble for feature selection using a DNN (EFS-DNN) to handle high-volume traffic data. A light gradient boosting machine (LightGBM) was used to specify the optimal set of features. In addition, these researchers employed DNNs, batch normalization, and embedded techniques as classifiers to improve the detection accuracy, which reached 99.92% upon reducing the number of network features from 41 to 14.
Xiao et al. [
27] utilized an autoencoder (AE) to diminish interference features and employed a convolutional neural network (CNN) for ID. Staude-Meyer [
28] introduced long short-term memory (LSTM) to examine the correlation of intrusion information, which ultimately reduced false alarms. Zhang et al. [
29] proposed an ID model based on genetic algorithms (GA) and extreme learning machine (ELM) to determine the optimal set of model parameters. In addition, the researchers in [
30] have presented a model for ID by combining very deep convolutional neural networks (VDCNN) and Gated Recurrent Unit (GRU). Within this model, the data are processed using One-Hot encoding and normalization. Subsequently, the VDCNN and GRU models are employed to extract data features. Eventually, these two types of features are combined to form new data features, which are then passed to the Softmax classifier. The experiment was conducted using KDD99. The results of the experiment demonstrate that the accuracy of detection was 98.73%.
Moreover, researchers [
31] proposed an IDS that applies an ensemble feature selection (EFS) technique and an SVM (SVM-IDS). After conducting experiments on the KDD99 dataset, the number of network features was reduced to 20, and the proposed SVM-IDS achieved an AC of 98.95%. Furthermore, the researchers in [
32] have proposed the IFMN model as a deep learning architecture for ID in IoT networks, which focuses on using a feature selection model and a decision tree classification method. The model for selecting features utilizes a Hybrid Yellow saddle goatfish algorithm and a particle swarm optimization algorithm (HYFSPSO) in order to discern the most advantageous features. The efficacy of the chosen features is evaluated via performance matrices, and the proposed HYSGPSO-DL based IDS approach achieves high accuracy reaches 99.53% on benchmark datasets such as KDD-CUP99.
These researchers have made significant contributions in the field of ID, particularly by demonstrating the suitability of the KDD99 dataset for evaluating various ID methods. However, there is often an overemphasis on detection accuracy without sufficient consideration of false alarms. To improve the efficiency and effectiveness of detection systems, it is crucial to select relevant features that accurately indicate potential intrusions. In addition, optimization techniques such as genetic algorithms (GA) combined with novel selection methods like cuckoo selection can be employed to fine-tune the entire detection process using the XCS.
In the present study, the XCS has been implemented, tested, and evaluated using the KDD99 dataset since no standard dataset is available. The conducted experiments aimed to select relevant features and improve detection accuracy, resulting in a satisfactory rate of correct detections while minimizing false alarms.
3. Research Background
This section outlines the background of the present study in four subsections. The first subsection introduces the XCS, whereas the second subsection describes the GA. The cuckoo search is described in the third subsection. The fourth subsection describes FLAME clustering.
3.1. The XCS
The XCS is a system that is commonly employed to perform ID, and the FLAME algorithm is typically used for feature filtering. Thus, the XCS is the most common learning classifier system (LCS). They are broadly employed in various applications, including IDSs. Wilson introduced this classifier system in 1998. It is categorized as a rule-based system, in which rules are designated as classifiers [
33]. Each rule consists of two parts: a condition and an action. The condition (“the body of the rule” [
34]) is represented using binary format as {0,1, #}, where # refers to “do not care.” The action part is “the fired classifier” [
34], which is often represented as a variable (0, 1) [
34].
The XCS was composed from two concepts: reinforcement learning (RL) and GA. RL, or reinforcement learning, is a method used to determine the optimal behavior of a machine in a given environment. This behavior is learned through continuous interaction with the environment while observing how it responds. To maximize the reward, the machine will adjust its behavior over time, learning from each interaction. The XCS is a reward-driven classifier system that allocates rewards from the classifier environment [
35]. It is designed to recognize how the classifier will be beneficial in the future and provide feedback for improving the rules [
36]. Additionally, GA can discover new elements in the search space by creating new rules [
34]. After creating a new rule, the population is inspected to determine whether the new classifier is a duplicate. Otherwise, it is added to the current population, and the total number of rules is increased by one. The primary components of the XCS, as shown in
Figure 1, are [
33,
34,
35,
36,
37]:
The detector receives input from messages coming from the environment, which reveals the features of the network traffic. Subsequently, the features that play a significant role in the detection of attacks are designated as important features and selected. The irrelevant features were substituted with #.
Match set [M] is a classifier composed of conditional and action parts. A part of the condition must correspond to the feature input of the classifier from the environment.
Action set [A] supports an action selected by the [M] classifier.
The prediction array consists of [M] actions depending on the suitability-weighted average of the prediction rules in [A].
The effector fires the rule action in the environment. The outcome can be normal activity/behaviour or an attack.
3.2. The Genetic Algorithm (GA)
The GA is a search algorithm inspired by natural selection. This is a breeding process [
38,
39]. Initially, a GA is composed of individuals called populations, which represent possible solutions to specific problems. Subsequently, through selection, crossover, and mutation, the GA iteratively creates new individuals, called generations, from the old population [
38,
39]. Each generated individual was evaluated using a fitness value that reflected the quality of the new individual in detecting intrusions.
In the IDS proposed in the current study, the XCS employs two algorithms, the GA and a cuckoo search algorithm, to boost ID accuracy. The fundamental improvement introduced in the present study to the GA is the use of the XCS to select individuals to perform crossover and mutation to produce new individuals who replace their precursors.
The basic elements and processes of the GA involved in the production of new individuals, which include the proposed modification of the GA [
38,
39].
Population
Populations are defined as individuals and classifiers that represent the possible solutions. Initially, all individuals are randomly generated to represent the current generation, which is considered the initial search space of the GA.
Fitness functions are used to evaluate the accuracy of detection for each individual.
Encoding is one of the most important features of a GA because it represents the solutions. The correct representation method is the best way to improve the effectiveness of GA in solving problems. In the IDS proposed herein, binary encoding was applied.
One of the main contributions of the proposed IDS is the adaptation of a selection method to improve detection accuracy. Thus, the XCS is used instead of traditional and popular selection methods such as roulette wheel selection (RWS), rank selection, and tournament selection. The CS successfully selects individuals for crossover and mutation to increase the intrusion of the DR and accuracy. In addition, it represents an alternative selection method that helps overcome the rapid convergence and slow termination problems.
Crossover is the process by which individuals exchange the values of their features to produce new individuals who have the characteristics of their parents [
40]. The probability of crossover (Pc) determines how often the crossover is performed. If Pc is set to zero, the new individuals will have identical copies of their parents.
The chromosomes were compared to determine the best one. Popular replacement methods include binary and triple tournament methods. The binary tournament method uses two chromosomes. Subsequently, it chooses the best chromosome based on its function and ignores the second chromosome. The triple tournament method replaces the worst two chromosomes and considers only the chromosome with the highest functional value.
Furthermore, the GA comprises two operators employed to reproduce new individuals over subsequent generations: crossover and mutation.
Crossover is one of the features of the GA that distinguishes it from other revolutionary algorithms. It is the process of the exchange of chromosomes (genes) between two individuals to reproduce new chromosomes that inherit the behaviors of their parents. The implementation of the crossover for all chromosomes is dependent on Pc. This probability specifies the frequency at which crossover is performed. However, when no crossover occurs, the offspring are exact copies of their parents. Several crossover methods are known, including uniform, single crossover, and two-point crossover.
In the mutation process, the feature value is changed randomly to avoid local maxima and to generate new individuals that are different from the existing ones to further explore the search space. The decision to implement mutations for all feature values depended on the mutation probability (Pm).
3.3. The Cuckoo Search
MH algorithms were inspired by natural phenomena. For example, the particle swarm optimization (PSO) algorithm is inspired by the intelligence of fish and swarms, and the search for the cuckoo exhibits egg parasitism in the cuckoo bird [
41]. The two main features of MH algorithms are (i) fitness-based selection, which is achieved by searching for existing solutions and selecting the optimal solutions, and (ii) adaptation to the environment, which is a process through which the algorithm explores the search space for appropriate solutions.
The CS algorithm is an evolutionarily optimized algorithm. It was first developed by Yang and Deb in 2009 [
41]. This algorithm copied the breeding behavior of cuckoo birds and the flight behavior of Lévy birds. These birds leave their eggs in the host nests and imitate the outer characteristics of the host eggs, such as color. Thus, the host can throw away cuckoo eggs or leave the nest elsewhere [
41]. CS has two types of behavior: cuckoo breeding and Lévy flight.
In cuckoo breeding, the process of generating the CS algorithm depends on the following three rules [
41,
42,
43]:
Each cuckoo chooses a random nest where it will lay a single egg.
The highest-quality egg nest will be transferred to the next generation.
The host nest remained constant, and each host could detect a strange egg with a certain probability, Pa, where Pa ∈ [0, 1]. In addition, host birds can throw eggs, leave their nests, and build new ones.
Lévy flight behavior was introduced by Benoit Mandelbrot through the formulation of a special definition of the distribution of step sizes. This behavior is considered as a random walk that depends on step size. Typically, step size manifests a heavy-tailed probability distribution [
44,
45]. This behavior is used to specify a separate network rather than a continuous space [
34]. Let the new solution be x
(t+1) and the cuckoo be i. Then, Levy flight is defined mathematically in (1) [
46]:
where X represents the current solution; α expresses the step size, which should ideally be appropriate for the scales of the problem under consideration, α should be equal to or greater than 0; and ⊕ has the meaning of entrywise multiplication [
46].
Lévy Flight is a random walk. The length of the random step is obtained from the Levy distribution as in (2) [
33]:
where t is the number of current generations (time) and λ is a constant whose value ranges from 1 to 3 [
35].
Levy distributions have infinite diversity and average values. Moreover, the size of the power line steps of heavy tails exhibits infinite diversity [
45]. However, the Levy walk creates new solutions around the best solution obtained in the time required to accelerate the local search [
46]. However, much of the new solution must be generated by the random distribution of distant fields, where the location is sufficiently far from the best solution currently available. This in turn ensures that the system is not trapped at the local optima [
41].
3.4. FLAME Clustering
The fundamental goal of data clustering is to reduce the data dimensionality and size by combining similar data points through grouping or classification. To date, there have been many algorithms for data clustering, such as FLAME. This algorithm was used to determine the clusters in the data based on their density. The algorithm is based on neighborhood relations between objects employed to force the memberships of neighboring objects in a fuzzy membership space [
47]. The FLAME algorithm performs clustering in three steps [
48]:
Step 1. Extracting the structure information:
Create a neighborhood graph to link every object with its k-nearest neighbors (kNNs).
Estimating the density for every object based on its distance from the kNNs, and
Classifying the objects. In general, the objects are of three kinds:
Cluster-supporting objects (CSOs) have densities greater than those of any of their neighbors.
Cluster outliers are objects with densities are smaller than the density of any of their neighbors, and are even smaller than the predefined threshold.
The remainder of the objects.
Step 2. Assigning the fuzzy membership by local approximation through:
Initialization of fuzzy membership:
Every CSO is allotted full and fixed membership with itself so that it will represent one cluster.
Outliers receive full and fixed membership of the outlier group.
The remaining objects are allotted memberships that equal the memberships of all the clusters and the outlier group.
The fuzzy members of the three object types were adjusted using the local/neighbourhood approximation of the fuzzy membership. This iterative process updates the fuzzy membership of each object using a linear combination of the fuzzy membership of its closest neighbor.
Step 3. The clusters were constructed using fuzzy membership. In this regard, two clustering types are common.
One-to-one object clustering involves allocating every object to the cluster with the highest membership.
One-to-multiple object clustering entails assigning every object to a cluster with a higher threshold than the preset threshold.
4. Proposed Work
Many IDSs faced several limitations and concerns about:
Managing the high volume of alerts.
The lack of a standard dataset and an unbalanced dataset.
Several IDSs still suffer from high false alarms that minimize the entire system’s accuracy.
The use of relevant and valuable network features can alleviate the entire system’s performance. Thus, every IDS relies on 41 features or applies feature selection methods that influence system accuracy.
Considering the limitations of IDS, the proposed work implements machine learning algorithms, the XCS, that focus on updating classifiers to handle variety and changeable patterns of attacks to distinguish between benign and malicious activities. In addition, the XCS demonstrates a remarkable capacity to withstand significant imbalances in the distribution of dataset class examples. However, when this disproportion becomes extreme, the balance between the need for generalization and the pursuit of precision deteriorates, resulting in the neglect of classes with limited instances. This issue is prevalent in automated learning, and while the XCS exhibits considerable resilience to such effects, it is not entirely impervious. Furthermore, the XCS enhanced by modifying the existing classifier breeding engine, GA, by implementing a novel selection method called cuckoo selection. This innovative approach aims to improve the robustness of the XCS algorithm, making it more efficient when handling imbalances of several extra orders of magnitude.
From another perspective, a new feature filtration method was implemented; FLAME, to eliminate irrelevant features that had a negative effect on system performance. Consequently, the FAR will be minimized, and maximized the detection rate and accuracy. It is worth mentioning that the network features were reduced to determine the optimal set of features that improve the performance of the IDS.
The proposed IDS performs two main operations: feature filtration and detecting system. First, the FLAME algorithm is applied to select features that substantially influence the accuracy of the IDS. The detecting system was based on the XCS, different modifications were made to improve the overall system performance. These modifications involve the use of a GA and CS. CS acts as a new selection operator in place of traditional selection methods. The modified GA acts as a classifier generator to update existing classifiers and attack patterns, on a regular basis.
Figure 2 provides the flow of the proposed model.
4.1. Feature Filtration
The KDD99 dataset consists of 41 features. The proposed IDS used 10% of this dataset for training and testing purposes. The features are regarded as a condition part that holds the values of the features and as an action part of the rule that carries the attack label. The FLAME algorithm was employed to reduce the number of features to be processed by selecting the optimum set of features.
FLAME assumes a noteworthy function in the process of filtering features by serving as the bedrock for cluster construction. Through the calculation of similarities between features and the identification of nearest features based on CSO, FLAME extracts pertinent information regarding local structure. This process allows for the determination of significant features that positively impact the accuracy of detection. Conversely, any features deemed insignificant are classified as outliers.
Clusters of the FLAME algorithm are of three types:
Inner clusters represent objects with densities higher than those of their neighbors.
Outer clusters are objects with densities lower than those of their neighbors, and a preset threshold.
The rest of the clusters are objects with density values that fall between the densities of the outer and inner objects and are close to the threshold value.
According to the simulation results, the number of features has a positive effect on the DR, accuracy, and the FAR when using an inner cluster.
4.2. The Detection System
The XCS is a detection system that processes the network features chosen by the FLAME algorithm. This classifier contains a set of elements necessary for ID.
The detector receives messages from the environment and classifies data. Then, it presents the messages in real form. Each message is composed of conditions and actions. Using the FLAME algorithm, the messages are filtered by removing repetitions and noise from them. Subsequently, the most important features are identified.
- 2.
Population
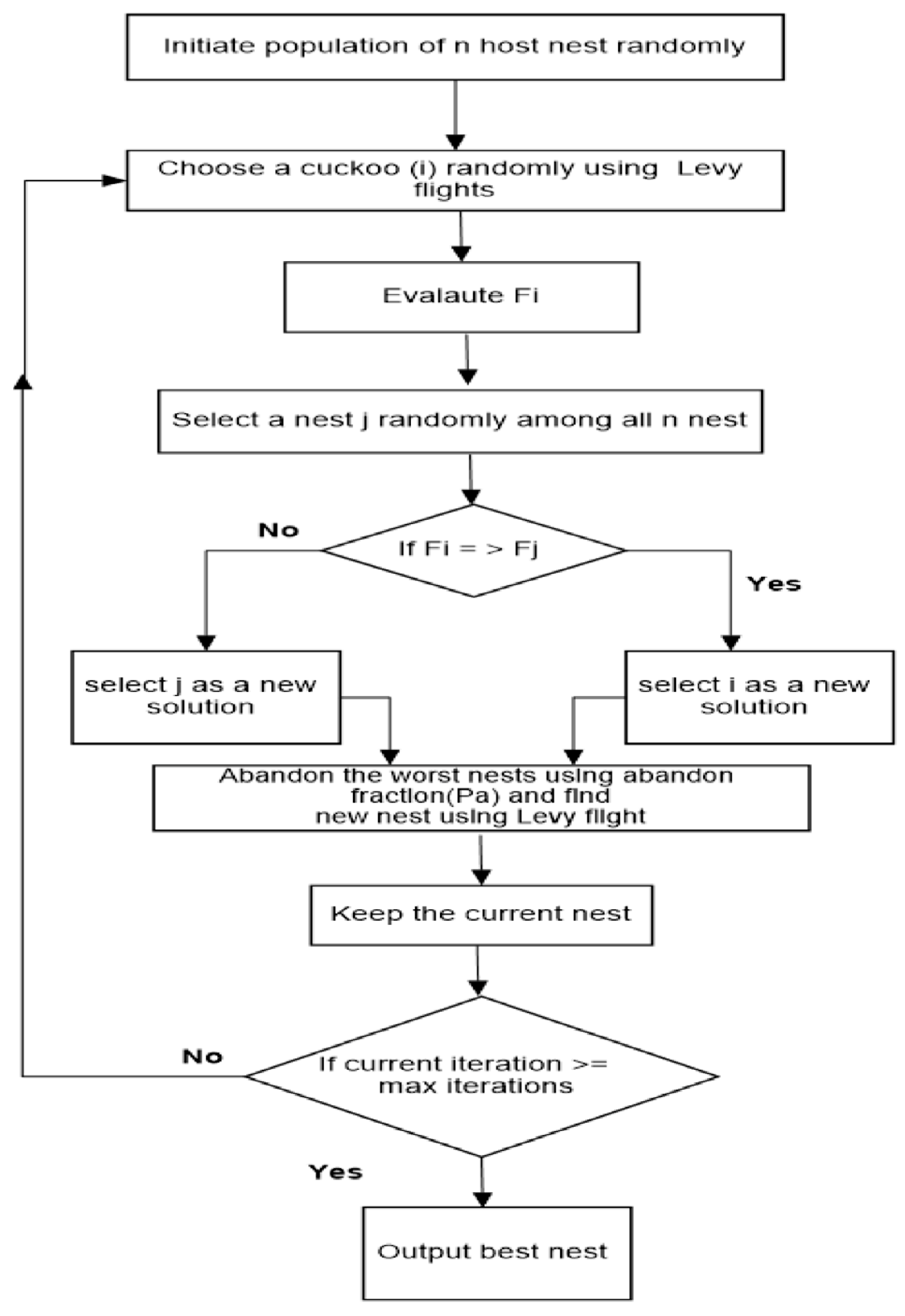
GA was used to create a new classification based on an existing classification. In the present study, the performance of the GA was enhanced by integrating the CS with it as a selection method. In CS, host nests represent a population, and each cuckoo egg represents a solution. The classification generated by the CS selection of the GA is stored in the classification, rule, and pool used in the proposed IDS. CS was used for feature selection to implement uniform crossover and random mutations to achieve better ID results. The following
Figure 3 represents the cuckoo search [
41,
42,
43,
44,
45,
46] as a selection method that was applied in GA.
- 3.
Matching Set
At this stage of ID using the proposed IDS, the system attempts to combine the conditional component of the classification system received from the environment with the existing data identification rules. The values of α and β were 0.3 and 0.2, respectively.
- 4.
Action Set
The classifier set of the matching set calls the action actually selected.
- 5.
Effector
Effector is the action triggers of the system. The effector performs desired actions in the environment.
5. Experimental Results
To assess the performance of the proposed IDS, experiments were performed to specify the optimal parameters and parameter settings conducive to the best intrusion of the DR and accuracy. The experiments were also intended to assess the performance of the proposed IDS before and after filtering network features.
All experiments were conducted using an Acer desktop computer running on Windows with the following characteristics: Intel Core i7, 6 GB of RAM, and 500-GB HDD. The Eclipse compiler for Java was used to run Java.
5.1. Performance Evaluation Metrics
To evaluate the performance of the proposed IDS and compare it with the performance levels of other IDSs, the following performance evaluation metrics were employed [
12,
13,
49]:
Accuracy was defined as “the ratio of correct predictions to the total number of predictions” as in (3):
- 2.
The Detection Rate (DR)
The DR is defined as “the ratio of the number of correctly detected attacks to the total number of attacks” as in (4):
- 3.
The False Alarm Rate (FAR)
The FAR is defined as “the ratio of the number of normal patterns that have been classified as attacks (false positives) to the total number of normal patterns” as in (5):
where
TP (true positive) is the number of correctly identified attacks.
TN (true negative) is the number of correctly identified normal patterns.
False positive (FP), also known as false alarm, is the number of normal patterns that have been erroneously classified as attacks.
False negative (FN) is the number of actual attacks that have been erroneously classified as normal patterns. These attacks can be detected by using an IDS.
To better assess the performance of the proposed IDS, researchers performed performance comparisons with IDSs that performed feature filtration using 41 features.
5.2. The KDD99 Dataset
The KDD99 dataset comprises 41 features, excluding the labels, and five classes: DoS, Normal, remote-to-local, user-to-root, and probe classes. The 10.0% variant of this dataset consisted of 494,021 records in the training subset and 311,029 records in the testing subset. Each of the 41 features is the result of a connection and has a label that specifies the status of the connection records, whether they are normal records or a specific type of attack [
50].
The KDD99 Cup dataset is the most suitable, and many researchers have used the reference dataset for ID experiments as a benchmark to validate their results. In this study, a 10% of the KDD99 dataset was used to train and test the proposed IDS. The KDD99 dataset comprises network packets, each of which is called a record. The records in this dataset contain information on 41 network features [
50].
5.3. Experiment 1: Intrusion Detection without Feature Filtration
In this experiment, forty-one features were used with GA and CS. Several parameters must be set and the optimal settings must be specified. These parameters include the following.
Crossover probability (Pc).
Mutation probability (Pm).
Number of generations (G).
Number of solutions (Nests).
Abandoned probability (Pa).
After studying various combinations of parameters and parameter settings, we determined the best values for these parameters that could produce the best DR and AC results (
Table 1).
Using all 41 features of the KDD99 dataset, we found that the best values for Pm, Pc, G, Pa, and Nests were 0.1, 0.7, 1000, 50, and 0.3, respectively (
Table 1). The associated DR, AC and FAR values were 93.70%, 84.33% and 6.3, respectively. Although these DR and AC values are somewhat good and the FAR needs an adjustment to gain better results. The researchers considered that reducing the number of features to process by identifying the most meaningful features and excluding the unimportant features can lead to ID results and minimize the FAR result.
5.4. Experiment 2: Intrusion Detection after Feature Filtration
This experiment focused on reducing the network features using the FLAME algorithm and exploring its impact on ID in terms of the DR, AC, and the FAR. Following the same approach adopted in Experiment 1, we first attempted to identify the best combination of parameter settings conducive to the highest DR and AC and the lowest FAR.
Three sets of features are produced by applying the FLAME algorithm. Internal comparisons between these feature sets were performed to select the most appropriate features. All sets were evaluated by calculating their DR, AC, and FAR values to avoid redundancy when only one measurement was applied.
The experimental results (
Table 2) show that the proposed IDS can produce a DR of 100% when the number of features is reduced from 41 to 20. Furthermore, the detection accuracy values are approximately the same for the three sets of features. However, the FAR value was used to differentiate the three sets. This value can help to specify the optimal set of features. The highest FAR value (4.9). This was associated with a set of 25 features (
Table 2). The second-highest FAR value was 1.6%. This is associated with 18 features. In contrast, the lowest FAR value (0.05% [
Table 2]) was associated with a set consisting of 20 features. As a result, the optimal number of features for the process was 20.
The results of the performance evaluation of the proposed IDS after feature filtration using the FLAME algorithm (
Table 2) reveal that feature filtration has a positive impact on the detection of accuracy. The ID results were the best for the 20-feature set, and deteriorated when the number of features was reduced to 18. This suggests that the optimum number of features in the KDD99 dataset for ID is 20 and that reducing the number further results in the deterioration of the ID performance. It can be concluded that the actual number of critical features in this dataset is 20. Reducing the number of features below this number (20) corresponds to the exclusion of meaningful features, which deteriorates system performance. For comparison, the IDS parameter settings and associated values of the three performance metrics adopted in this study are listed in
Table 3 for the ID experiments using the proposed IDS with and without feature filtration by the FLAME algorithm.
Table 3 lists the best ID results obtained in the performance tests of the proposed IDS, indicating that the values presented in the last column of this table pertain to the 20-feature set.
The comparison reveals that feature filtration significantly improves the performance of the proposed IDS after processing only 20 meaningful network features. The DR increased from 93.7% to 100% and the accuracy increased significantly from 84.3% to 99.9%. In addition, the FAR decreased substantially from 6.3% to 0.5% (
Table 3). Moreover,
Table 3 points out that the crossover probability increased after applying the FLAME algorithm from 0.7 to 0.9 and that Pm increased from 0.1 to 0.3. Increases in Pc and Pm indicate the breeding of new classifiers with high crossover and mutation capabilities. Attempting different combinations of network records helped obtain the optimal DR, accuracy, and FAR values (
Table 3). In addition, the number of generations decreased after the application of the FLAME algorithm from 1000 to 100 generations, which reduced the execution time and helped obtain better than before the DR, accuracy, and FAR values.
5.5. Comparison with Different Systems without Feature Filtration
To assess the improvement in ID better, the performance of the proposed IDS was compared with the performance levels of the three IDSs applied to all 41 features of the KDD99 dataset, as illustrated in
Table 4. The comparison reveals that the proposed IDS exhibits moderate performance in comparison with CNN BiLSTM, IGP-BP, and Group CNN. The comparison results highlight the need for the modification and improvement of this system by applying feature filtration to discard unimportant features that deteriorate the ID performance of this system. In terms of the FAR, the comparison results indicate that both the CNN BiLSTM and the proposed IDS require improvement to reduce their FAR values.
Valuable insights can be gleaned based on the findings depicted in
Figure 4 and detailed in
Table 4. The proposed work needs more enhancement to improve detection accuracy compared with other systems as in NDNN. This lead us to spot the light on exploring significant factors that may improve detection accuracy and reduce false alarms. These factors include feature filtration and enhance the detection system as used in GA-ELM and NDNN.
5.6. Comparison with Different Systems with Feature Filtration
To further evaluate the improvement in the detection performance of the proposed IDS, its performance was compared with that of nine IDSs when applied to a reduced number of features of the KDD99 dataset after filtration using the FLAME algorithm, as listed in
Table 5.
Table 5 compares the performance of the proposed IDS after applying FLAME and the XCS to other IDSs when tested on the KDD99 dataset. The values of the ID performance metrics demonstrate that the proposed IDS outperforms all the previous IDSs. However, its performance was similar to that of RFS-1 and TSLD in terms of the AC which reaches to 100% of accuracy. Also, the proposed work stated at the top rank among listed methods in terms of the DR. Furthermore, the proposed work gained the third-best FAR. Thus, the proposed work gains remarkable achievements in terms of AC, the DR and the FAR. From another perspective, the number of features of the IDSs listed in
Table 5 was either equal to or lower than the number of features employed in the proposed IDS, except for Sasan and Sharma [
15], who extracted 29, not 20, features.
In summary,
Table 4 and
Table 5 confirm the importance of feature filtration, regardless of the method used to specify the features that increase the AC, the DR and reduce the FAR. Furthermore, there is no specific set of features to be used in all IDSs, and there is always a need to determine the best combination of features for each new IDS.
Figure 5 and
Figure 6 reveal the results shown in
Table 5.
Figure 5 shows a comparative analysis of accuracy among all different methods that applied feature filtration. The accuracy of the proposed IDS reaches with 99.99% that reside in top rank among other methods.
Also,
Figure 6 shows a comparative analysis of the FAR among different methods. The proposed IDS has the third-lowest received FAR with 0.05 and TSLD has the lowest received FAR. This indicate the outperform result of the proposed IDS in terms of the FAR compared with other methods. These findings imply that the proposed IDS not only outperforms its competitors but also attains the highest level of accuracy and approximately the lowest FAR among tested methods that employ feature filtration and apply different artificial intelligence algorithms for ID.
6. Conclusions
In recent years, there has been a significant increase in the importance of identifying abnormalities and malicious assaults in the network setting. With the ongoing rise in the frequency of these attacks, it has become essential to have powerful tools that can quickly and precisely detect intrusions.
The primary contribution of this study is the improvement of the XCS through the utilization of the FLAME algorithm to filter features and utilize CS in the GA. The results from the experiments demonstrate the exceptional performance of the proposed IDS in detecting intrusions when tested on the KDD99 dataset. The suggested method significantly enhances the accuracy of detection to approximately 99.99% and reduces the FAR to approximately 0.05%. Additionally, it reduces the number of features that need to be processed from 41 to 20 by incorporating the FLAME algorithm. Furthermore, a comparison (
Table 5) reveals that the proposed IDS outperforms other IDSs such as EFS-DNN, FGLCC, RSA, DNN, NIDS-CNNLSTM, and SVM-IDS.
Future research can consider various improvements to IDSs, such as applying different methods for feature filtration instead of the FLAME algorithm, investigating the impact of different filtration methods on the performance of IDSs, and extending recent studies to larger instances. Also, we plan to examine the performance of the IDS proposed here using different datasets, such as UNSWB-15 and CICID2022, to further scrutinize its performance with datasets consisting of different numbers and structures of network features and explore the impact of these datasets on detection accuracy and the FAR.
In conclusion, this paper aims to improve the effectiveness of ID by implementing FLAME and enhanced the XCS using GA and CS. Also, the comparative analysis reveals that there is no optimal method that can be implemented to specify specific set of features to all IDSs. Thus, IDSs are encouraged to focus only on the most important and relevant features that ensure detecting attacks with the highest performance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}