1. Introduction
Speech signals are information rich and extend the content of written messages via the speakers’ identity, their emotional state, and their intonation patterns [
1]. They are easier to capture compared to other physiological signals [
2].
Speech recognition technology grants machines the ability to express emotions and enables them to recognize human emotions. A lot of research has been conducted on speech emotion recognition (SER), and its applications are increasingly popular in the field of human–computer interaction, distance education, and emotional therapy. However, significant work is still required to make the applications more natural. In fact, the factors that affect a person’s emotions are complex and diverse. Individuals experience various psychological changes in different emotional states. These changes lead them to associate emotional fluctuations with speech, and provide key emotional information for SER. Speech features are extracted to describe this information.
Emotion recognition relies on extracting meaningful features from speech signals. Currently, these features mainly include intonation features, spectrum features, voice quality features, and other acoustic features. Many features are used in speech recognition, and excellent results can be achieved through training with various machine learning methods. However, speech features introduce redundancy, and negatively impact recognition results.
Feature selection achieves dimensionality reduction by removing irrelevant and redundant features [
3,
4]. This is widely used in SER to reduce processing time and enhance recognition efficiency. Differential evolution (DE) mimics the natural concept of survival of the fittest, and gradually converges towards an optimal or near-optimal solution [
5,
6,
7]. DE is known for its computational efficiency in optimizing feature subsets. It explores search space effectively, and it shows significant advantages in single- and multi-objective feature selection [
8,
9,
10,
11].
While multi-objective DE is fast, it has a few drawbacks. For example, it has trouble with unstable convergence and may lose population diversity. In this study, we investigated multi-objective DE to recognize speech emotion through feature selection, and the main contributions of this paper are summarized as follows:
We propose a model for speech emotion recognition;
We propose a feature extraction approach from speech signals;
We propose a multi-objective feature selection algorithm based on DE in which the number of selected features (NSF) guides the initialization, crossover, and mutation of DE;
We validated the performance of the proposed algorithm on K-nearest neighbor (KNN) and random forest (RF) classifiers with four English speech emotion datasets.
The structure of this paper is organized as follows.
Section 2 introduces the related works of SER.
Section 3 describes the proposed algorithm.
Section 4 represents the experimental results with discussions, and
Section 5 provides the conclusions.
2. Related Works
Existing research in speech emotion recognition is classified into single- and multi-objective optimization according to different goals.
Sun et al. proposed a SER method based on decision tree (DT), support vector machine (SVM), and Fisher feature selection [
12]. The Fisher criterion is employed to filter out feature parameters with a high discrimination ability. The DT and SVM framework is first established by calculating the confusion of emotions, and then features with high discrimination are selected for each SVM in the DT according to the Fisher’s criterion. Finally, SER is realized based on the model. Partila et al. discussed the impact of classification methods and feature selection on the accuracy of SER, and found the best combination of methods and feature sets for stress detection in human speech [
13]. Selecting appropriate parameters for a classifier is an important part of reducing computational complexity, especially for systems intended for real-time applications. The classification accuracy of an artificial neural network, KNN, and Gaussian mixture model is measured considering the selection of foreground, spectral, and speech quality features. Traditional feature selection methods often rely on supervised learning, where emotion labels are used to guide the selection of relevant features. However, these methods may not be efficient when labeled data are scarce or expensive to obtain. To address this challenge, Bandela et al. proposed a novel approach that leverages unsupervised feature selection algorithms to identify the most informative and discriminative features from speech data without using emotion labels [
14]. They explore various unsupervised feature selection algorithms, such as principal component analysis (PCA), independent component analysis (ICA), and clustering-based methods. Akinpelu and Viriri integrated robust feature selection and deep transfer learning to improve the performance and robustness of speech emotion classification [
15]. The robust feature selection chooses features that are less affected by noise and irrelevant variations in data. The deep transfer learning employs knowledge learned from a pre-trained neural network model on a large dataset. Transfer learning allows the model to benefit from knowledge gained from one domain (e.g., a large general speech dataset) and apply it to a related but different domain (e.g., speech emotion classification). Li et al. addressed the problem of recognizing emotions from speech signals [
16]. Speech features are extracted from signals that may carry emotional cues, and these features include acoustic features (pitch, intensity, and spectrum), prosodic features (speaking rate and pitch contour), and linguistic features (lexical content and sentiment-related words). The research involves a comprehensive analysis of the extracted speech features to identify their relevance and importance for emotion recognition.
In addition to recognition accuracy, there are several studies on emotion recognition from computational efficiency, classifier optimization, and unity. Brester et al. proposed a novel approach that combines heuristic feature selection methods with a multi-objective optimization framework [
17], aiming to maximize classification accuracy and minimize computational complexity. They optimize computational efficiency by working in parallel and incorporating a technique for exchanging subsets of data. Furthermore, the approach uses a beneficial pre-processing step when combined with an ensemble of classifiers. It not only streamlines the feature selection process but also enhances the overall classification performance. Daneshfar and Kabudian combined discriminative dimension reduction and a modified quantum-behaved particle swarm optimization (QPSO) algorithm to implement SER and optimize the Gaussian mixture model (GMM) classifier’s parameters [
18]. The dimension reduction method preserves emotion-specific features and improves the discriminative power of the extracted features. The modified QPSO algorithm enhances the optimization process for feature selection in SER. Li et al. presented a novel approach for enhancing emotion recognition through multiple data sources [
19]. The proposed model utilizes a sophisticated multi-objective optimization algorithm to create the multi-modal system, which effectively combines voice and facial information with the goal of simultaneously improving recognition accuracy and consistency. Yildirim et al. introduced a modified feature selection method that employs metaheuristic algorithms to identify the most important features for SER [
20]. Various metaheuristic algorithms, such as NSGA-II and cuckoo search, are applied to optimize the feature selection process. These algorithms efficiently explore feature space and converge to optimal feature subsets.
Drawing from previous research, multi-objective speech emotion recognition mainly includes classification accuracy and the number of selected features. Although the research achieved good results, it usually considers recognition accuracy when searching for the optimal solutions. It neglects the fact that the number of features is also the main factor affecting multi-objective algorithms, resulting in a loss of population diversity. Compared to other evolutionary algorithms, the popularity of DE as a competitive optimization algorithm is due to its efficiency, simplicity, robustness, and global search ability. We utilize it as a feature selection technique for multi-objective speech emotion recognition.
3. Materials and Method
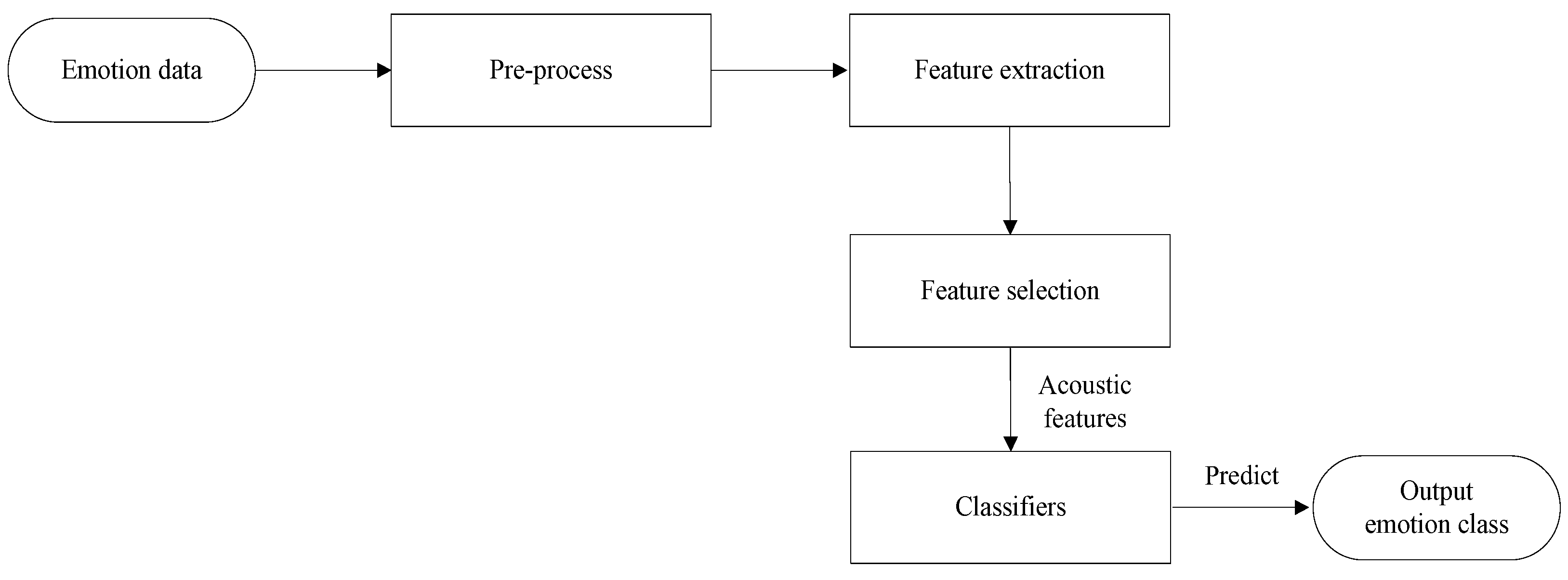
The whole process consists of several main steps: firstly, preparing the data (pre-process); secondly, extracting important information (feature extraction); thirdly, selecting the most relevant features (feature selection); and finally, using classifiers for making predictions, as shown in
Figure 1.
3.1. Emotion Data
Four different English speech emotion datasets were used in this study. eNTERFACE05 is known for capturing spontaneous emotional expressions in unscripted scenarios, while the Ryerson audio-visual database of emotional speech and song (RAVDESS) focuses on emotional speech and song data. The Surrey audio-visual expressed emotion (SAVEE) dataset collects posed emotional expressions, and the Toronto emotional speech set (TESS) specializes in scripted emotional speech. Each database has unique characteristics that suit different research needs in the domain of emotion analysis and recognition. Through these datasets, the pros and cons of the algorithms can be more comprehensively evaluated.
eNTERFACE05: eNTERFACE05 is a well-known European research project and dataset that focuses on the development of technologies for human–computer interaction, particularly in the fields of facial and emotional expression recognition [
21]. The eNTERFACE05 dataset contains emotional expressions such as happiness, sadness, anger, fear, disgust, and surprise;
Ryerson audio-visual database of emotional speech and song: RAVDESS is a valuable resource for studying emotions in speech and music because it includes both acted and natural emotional expressions performed by professional actors [
22]. RAVDESS encompasses a wide range of emotions such as calm, happiness, sadness, anger, fear, surprise, and disgust;
Surrey audio-visual expressed emotion: SAVEE is a dataset containing audio and video recordings that display emotional expressions by English native speakers [
23]. This dataset covers various emotions including happiness, anger, disgust, sadness, fear, and neutral;
Toronto emotional speech set: TESS consists of professionally acted and recorded speech segments spoken by North American English speakers [
24]. TESS includes expressions of anger, disgust, fear, happiness, pleasant surprise, sadness, and neutral.
3.2. Pre-Process
Pre-emphasis, framing, and windowing are important pre-process steps often applied to raw speech audio data. These steps ensure that speech data are cleaned, transformed, and organized in a way that allows machine learning algorithms to effectively learn and recognize emotional patterns.
Pre-emphasis is a filtering technique that is applied to raw speech signals before further analysis. It accentuates high frequencies in signals and improves the signal-to-noise ratio. Speech signals tend to have more energy in low frequencies, and pre-emphasis can balance this by boosting high-frequency components.
Framing involves dividing continuous speech signals into shorter overlapping segments (frames). The reason for this is that speech characteristics, such as pitch and spectral content, can change rapidly in short time intervals. By analyzing these frames individually, we capture variations more accurately. Each frame typically contains about 20–30 ms of speech data.
After framing, a windowing function is applied to each frame. Windowing reduces sudden changes at the edges of frames and prevents artifacts during the subsequent analysis, such as the Fourier transform. Common windowing functions include the Hamming, Hanning, and Blackman windows. These functions smoothly taper signals within frames, and decrease the effects of spectral leakage.
3.3. Feature Extraction
In this study, we extracted Mel-frequency cepstral coefficient (MFCC) features and pitch features from raw audios. A total of 141 values were extracted, and
Table 1 describes their details.
Pitch features: Pitch features are important elements extracted from speech signals that provide information about the fundamental frequency (F0) and tonal characteristics of the human voice. They are extracted using autocorrelation, cepstral analysis, and wavelet transform. By analyzing these features, SER systems can better understand and interpret the emotional nuances and linguistic characteristics of spoken language;
MFCC features: MFCC features capture the essential characteristics of speech signals, and ignore redundant or less important information. They mimic how human auditory systems process sounds by converting their frequency spectrum into a representation that’s easier for computers to understand.
3.4. Improved Multi-Objective Differential Evolution for Feature Selection
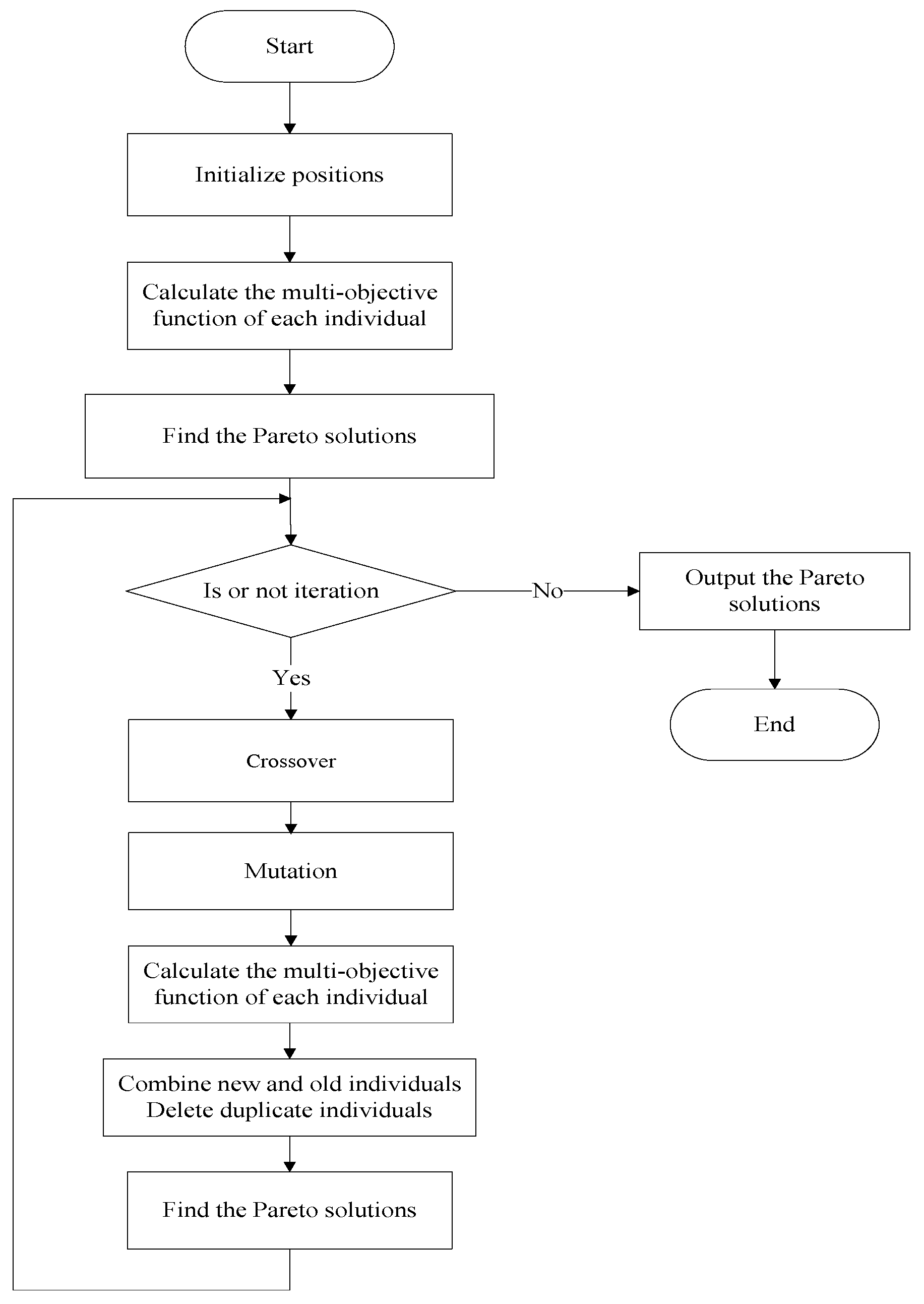
The proposed MODE-NSF, shown in
Figure 2, includes four new schemes. Firstly, the initialization is defined by the NSF. Then, this NSF is adopted to adjust crossover. Third, the NSF-based mutation strategy is introduced to balance exploration and exploitation. Finally, MODE-NSF combines new and old solutions, and deletes duplicate individuals. In our speech emotion recognition model, MODE-NSF implements the feature selection operation shown in
Figure 1.
3.4.1. Multi-Objective Feature Selection
Multi-objective algorithms are designed to find solutions for multiple objectives in decision space. Because these objectives are in conflict, a significant challenge is comparing two potential solutions. If solution S1 outperforms solution S2 in all objectives, we say that S1 dominates S2. Non-dominated solutions, like S1, are not outperformed by any other solution, and they are called Pareto solutions. The set of all non-dominated solutions forms a Pareto set, and their corresponding objective values make up the Pareto front.
A binary string represents a solution of multi-objective feature selection, where 0/1 represents the unselected/selected feature. Feature selection mainly involves two objectives: maximizing classification accuracy and minimizing the number of selected features [
25], as shown in Equation (
1).
where
is the number of feature sets (
x), and
denotes the classification accuracy of
x.
In multi-objective feature selection, the number of selected features () defines an optimization objective, so we utilize it to implement a search.
3.4.2. Initialization
Random initialization is not employed to expand feature search space. MODE-NSF randomly generates the NSF and determines the initial positions using it. MODE-NSF defines a counter to store the usage frequency of the NSF, and Algorithm 1 provides the details of the novel initialization.
| Algorithm 1: The initialization based on the NSF |
![Applsci 13 12262 i001]() |
3.4.3. Crossover
Crossover operators are crucial because they enhance exploration ability. This process, similar to reproduction in nature, ensures the survival of species. In DE, crossover generates new offspring, and it explores search space more effectively. During crossover, two or more individuals from the population act as parents to create children. These children inherit genetic information from their parents, which improves the algorithm’s chances of finding the global optimal solution.
MODE-NSF utilizes Equations (
2) and (
3) to implement crossover. In addition,
and
are two random individuals, and
comes from Pareto solutions with the minimum NSF difference of
i. Moreover,
and
are called the scale factor and crossover probability, respectively. The NSF difference between
and
i is the smallest. It prompts
i to quickly approach
and increases the convergence of the algorithm. However, if
is a local optimum, it may cause the algorithm to fall into a local trap, which can be solved by the mutation operation.
3.4.4. Mutation
Mutation is the process of introducing a small random change into a solution. This change promotes diversity and exploration within solutions. In essence, mutation prevents the algorithm from getting stuck in local optima and can lead to the discovery of better solutions. Algorithm 2 presents the procedure of the proposed mutation, and
means a random integer value between the maximum NSF of Pareto solutions and the minimum NSF of Pareto solutions. Lines 2–6 of the algorithm represent reducing the NSF, and lines 7–12 represent increasing the NSF.
| Algorithm 2: The mutation based on NSF |
![Applsci 13 12262 i002]() |
3.5. Classifiers
K-nearest neighbor: KNN is a simple classification algorithm that is easy to comprehend and implement [
26]. It is non-parametric, and it does not make strong assumptions about the distribution of data. This can be useful when dealing with diverse and complex emotional speech data;
Random forest: Random forest is an ensemble method that consists of multiple decision trees [
27]. The ensemble approach tends to produce results that are robust and accurate, which reduces the risk of overfitting and improves generalization. RF is a suitable option for speech data that contain various types of noise in real-world scenarios.
These classifiers offer a balance between simplicity and effectiveness, which is important in the context of speech emotion recognition. Both KNN and RF have demonstrated their utility in emotion recognition, making them reasonable choices for this study;
K-fold cross validation: K-fold cross validation prevents overfitting and provides a more precise depiction of a model’s true performance [
28]. By dividing a dataset into multiple subsets, it continuously trains and evaluates a model on different combinations of these subsets.
In this study, we used 5-Nearest Neighbor and RF (with 20 decision trees) classifiers to create models, and then assessed the performance of these models using 10-fold cross-validation.
4. Experimental Results and Analysis
4.1. Approaches Used for Comparisons
The proposed MODE-NSF’s superiority was verified by comparing its classification performance with MOGA [
17], MODE [
29], and NSGA-II [
20].
Table 2 provides more details concerning the algorithms.
The algorithms had a maximum number of iterations of 100 with 20 runs, and the population size was 20. Wilcoxon rank sum and Frideman test were employed to determine whether there were any significant differences in the experimental results. The significant level was chosen to be 0.05, which means that if p-value <= 0.05, an algorithm was significantly superior to the compared algorithms at a 95% confidence.
4.2. Experimental Analysis
4.2.1. Simulation Results on the KNN Classifier
1. Hypervolume (HV)
Table 3 provides the HV of the algorithms where
and
denote the average and variance of the HV, respectively. MODE-NSF outperformed MOGA, MODE, and NSGA-II using eNTERFACE05, RAVDESS, and SAVEE, while NSGA-II obtained the best HV value using TESS. The algorithms achieved low HV values using eNTERFACE05 and RAVDESS, but high values using TESS. The multi-objective algorithms performed poorly in the Pareto optimal solutions for the eNTERFACE05 and RAVDESS datasets, while the optimal solutions for TESS were close to the ideal value. The Wilcoxon rank sum revealed that MOGA, MODE, NSGA-II, and MODE-NSF performed well on 0, 0, 3, and 4 datasets. MODE-NSF and NSGA-II produced similar experimental data for RAVDESS, SAVEE, and TESS. According to the Friedman test, their average ranks were 3, 4, 1.75, and 1.25, respectively, proving that MODE-NSF performed the best, followed by NSGA-II, MOGA, and MODE. The NSF improves the multi-objective solution ability of DE.
2. Inverted generational distance (IGD)
Table 4 shows the IGD of the algorithms, along with their Wilcoxon rank-sum and Friedman test results. MODE-NSF exhibited the best performance using eNTERFACE05, RAVDESS, SAVEE, and TESS. MODE-NSF’s values were lower than those of the other algorithms, but its solutions were almost the same as the Pareto solutions obtained by them. The Wilicion rank sum indicates that MOGA, MODE, and NSGA-II did not share similar statistical data with MODE-NSF on the four datasets. The average ranks obtained by the Frideman test were 3, 4, 2, and 1, and the
p-value was 1.12 × 10
−2. Experimental data and non-parameter validation show that MODE-NSF outperformed MOGA, MODE, and NSGA-II in terms of IGD.
The hypervolume, inverted generational distance, and non-parametric statistical analysis verified that MODE-NSF has a remarkable distribution and convergence, and it balances exploration and exploitation.
3. Pareto solutions
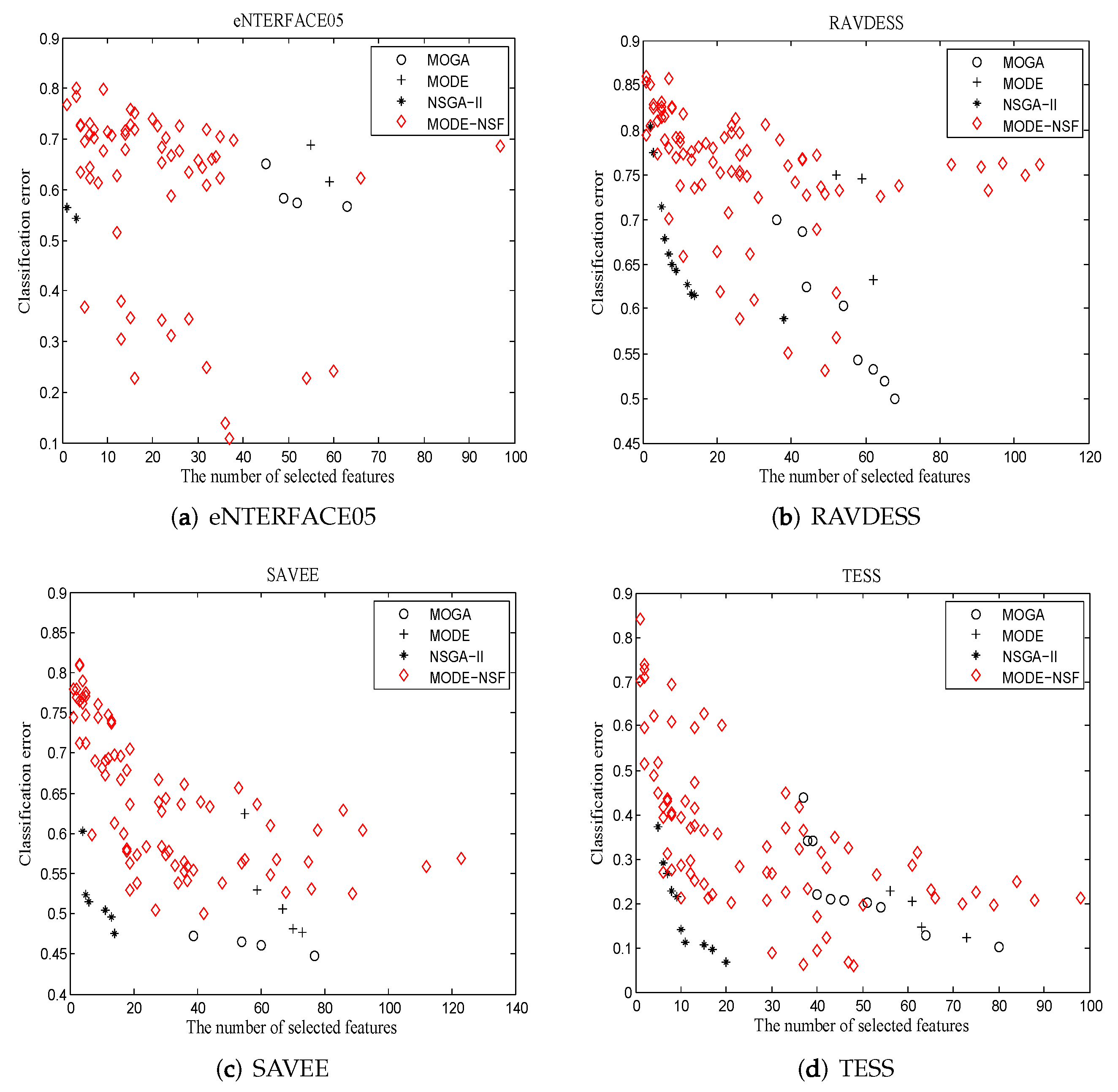
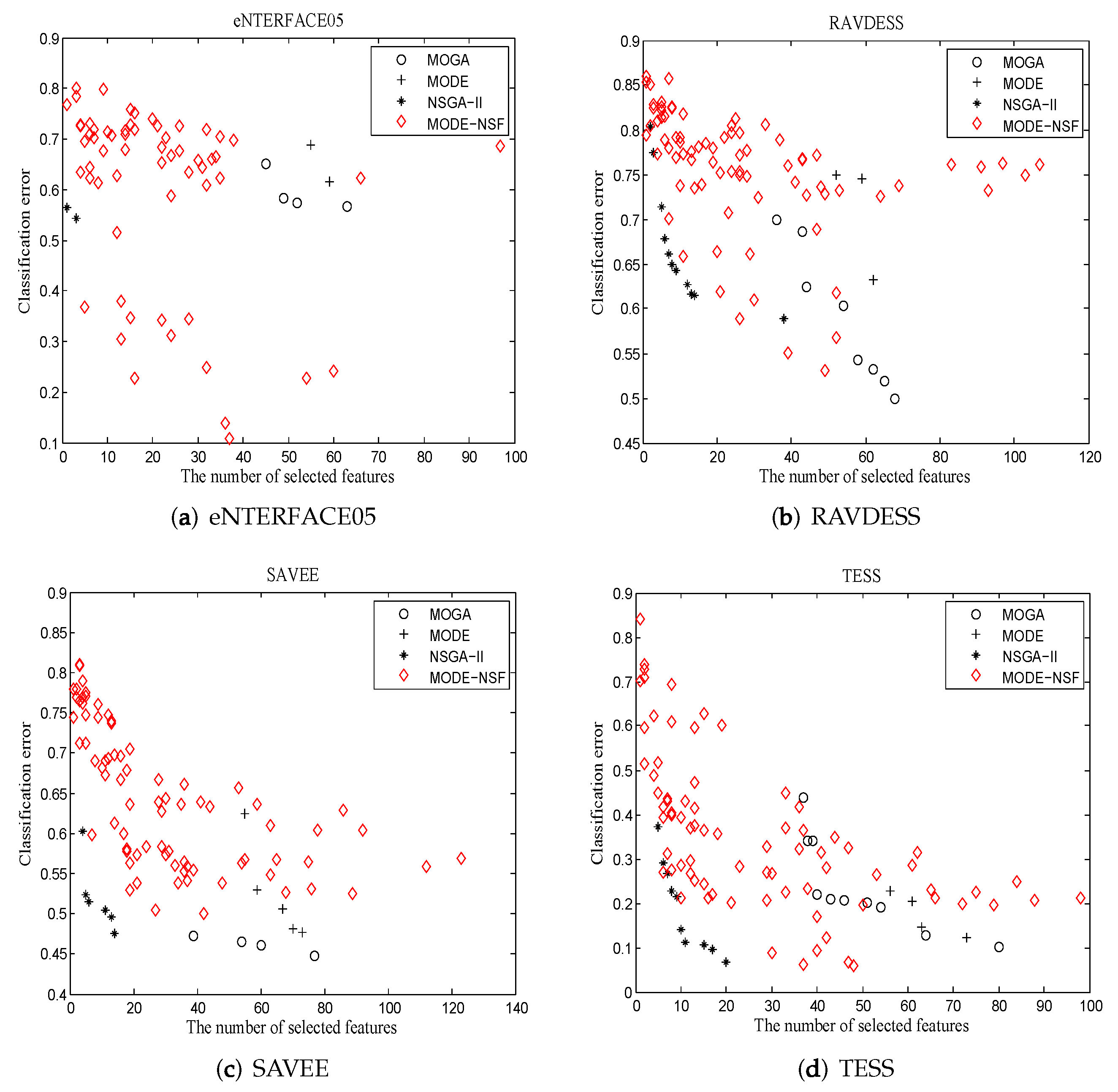
Figure 3 shows the final Pareto optimal solutions acquired by the algorithms in which Pareto solutions were the solutions that were non-dominated and obtained from all algorithms after 20 runs.
For eNTERFACE05, MODE-NSF obtained more solutions than MOGA, MODE, and NSGA-II. Furthermore, it achieved the highest recognition accuracy of 49%, which was superior to the other algorithms. The solutions of NSGA-II were located in a low dimension, and the solutions of MOGA and MODE were mainly in a medium dimension. For RAVDESS, the solutions of MODE-NSF were distributed over the entire feature space. The solutions of NSGA-II remained in a low dimension, and the solutions of MOGA and MODE were located in a middle dimension. Although MODE did not achieve as many optimal solutions as MODE-NSF, it outperformed MODE-NSF in obtaining an optimal recognition accuracy. For SAVEE, MODE-NSF presented with diverse characteristics. The solutions of NSGA-II were in a low dimension, and the solutions of MOGA and MODE were in a medium dimension. The recognition accuracy of the Pareto optimal solutions obtained by NSGA-II, MOGA, and MODE was better than that obtained by MODE-NSF. For TESS, MODE-NSF excelled in terms of diversity and accuracy. NSGA-II achieved an accuracy of 90% using a small number of features, and MOGA acquired a better accuracy in the middle dimension than MODE. From the Pareto optimal solutions, it was found that MODE-NS utilized the NSF-guided mutation to enhance the solution’s diversity and balances exploration and exploitation.
Table 5 presents the running time of the algorithms. MODE had the shortest computation time using eNTERFACE05, and MODE-NSF exhibited the quickest execution time using RAVDESS, SAVEE, and TESS. The proposed algorithm exhibited a fast execution and low time complexity. It is worth noting that the algorithms required less time to execute using eNTERFACE05 and SAVEE compared to TESS. This is because TESS contains a larger number of samples, which impacted the execution of the algorithms.
4.2.2. Simulation Results on the RF Classifier
1. Hypervolume
Table 6 shows the HV values of the multi-objective algorithms. The data obtained by the algorithms using eNTERFACE05, RAVDESS, SAVEE, and TESS were better than those obtained using the KNN classifier. MODE-NSF outperformed the other algorithms on four datasets, especially TESS, where it achieved a value of 0.8101, a result close to the theoretical optimal value. The Friedman test showed that their average ranks were 2.75, 3.75, 2.5, and 1. The Wilcoxon rank sum revealed that they performed well on 2, 1, 3, and 4 datasets. MODE-NSF and MOGA produced consistent statistical data using eNTERFACE05 and RAVDESS. Additionally, MODE-NSF and MODE exhibited a similar performance using RAVDESS, while MODE-NSF and NSGA-II achieved similar experimental results using eNTERFACE05, RAVDESS, and SAVEE.
2. Inverted generational distance
Table 7 provides the IGD of the algorithms and their corresponding Wilcoxon rank-sum and Friedman test results. The IGD value of MODE-NSF was significantly smaller than that of the other algorithms, which means that the multi-objective solutions obtained by it were close to the Pareto front composed of all algorithms. The performance of MODE-NSF was better than the others. The Wilcoxon rank sum indicates that MOGA produced similar statistics to MODE-NSF using eNTERFACE05; in addition, MOGA, MODE, NSGA-II, and MODE-NSF performed well on 1, 0, 0, and 4 datasets. Their average ranks were 2.25, 3.5, 3.25, and 1, and the
p-value was less than 0.05.
Table 6 and
Table 7 confirm that the proposed MODE-NSF demonstrates exceptional distribution and convergence, and it is suitable for multi-objective feature selection.
3. Pareto solutions
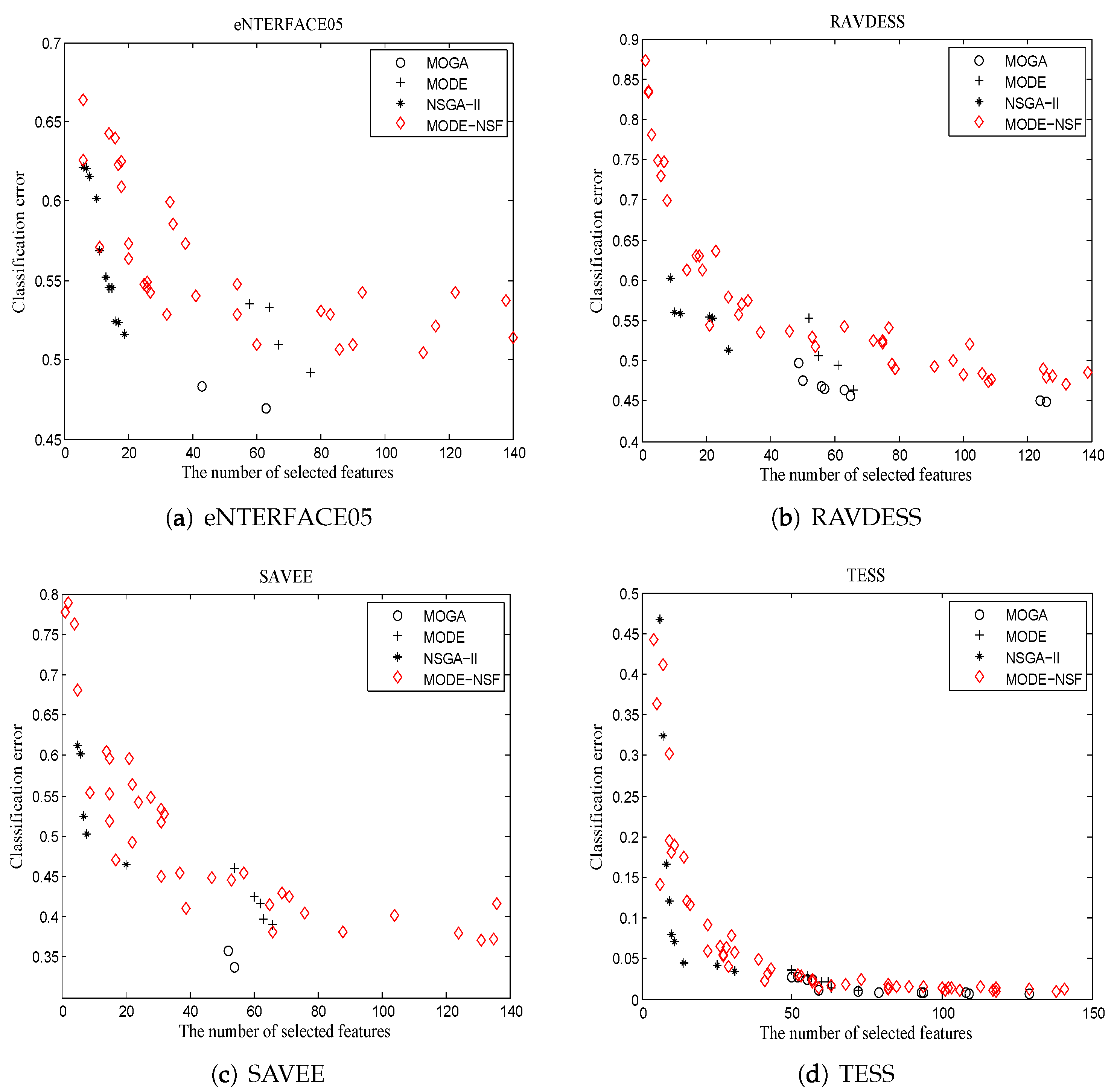
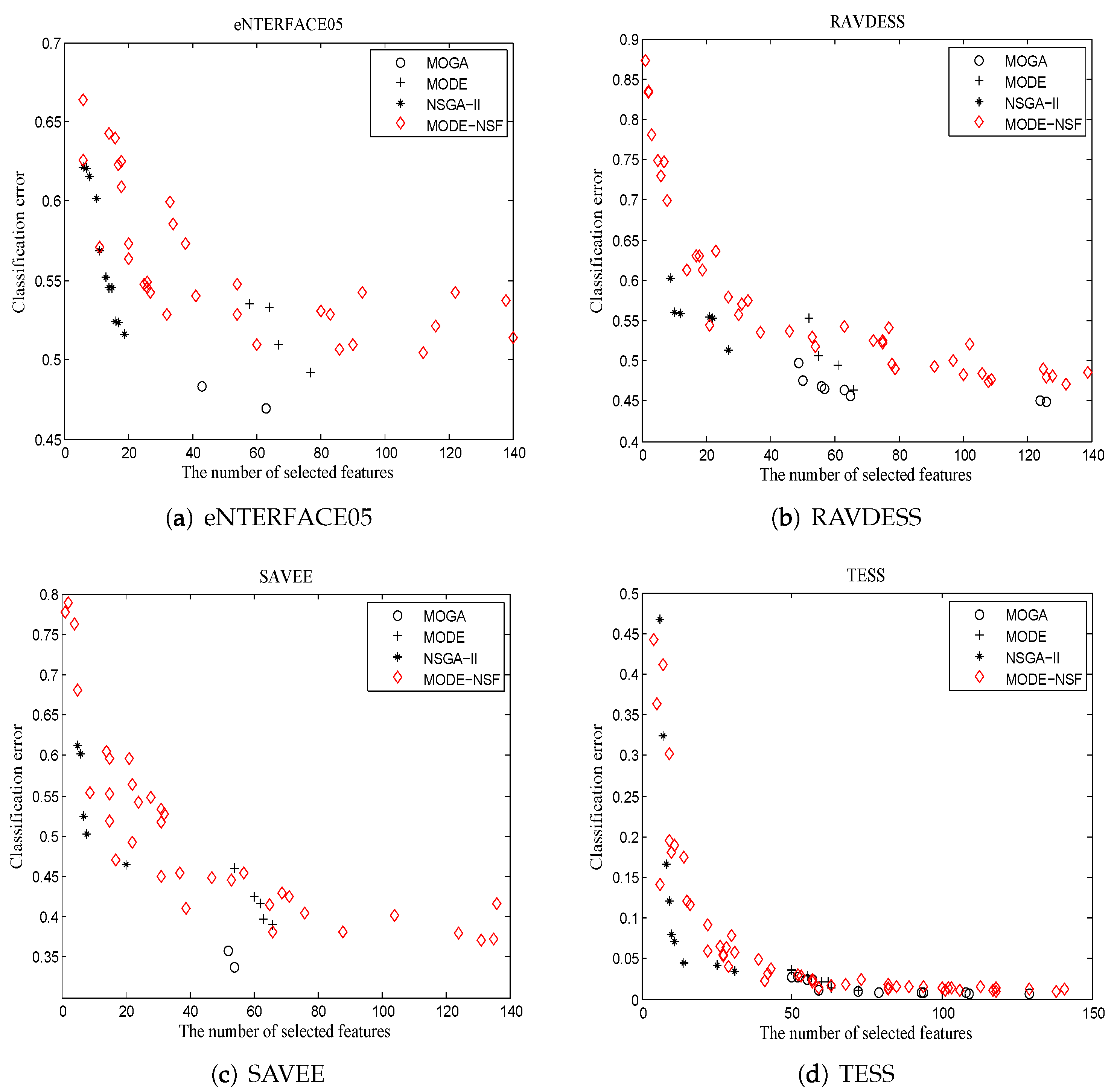
Figure 4 illustrates the Pareto optimal solutions acquired by the algorithms.
Using eNTERFACE05, MODE-NSF obtained a large number of solutions, while the solutions of NSGA-II were concentrated in a low dimension. MOGA acquired four feasible solutions in a middle dimension. MODE only obtained two optimal solutions, but their classification accuracy was superior to the other algorithms. Using RAVDESS, the solutions of MODE-NSF were distributed throughout the entire feature space, while the solutions of NSGA-II were primarily in a low dimension. The solutions of MOGA and MODE were located in a middle dimension. Using SAVEE, MODE-NSF had a better diversity than the other algorithms. The solutions of NSGA-II were distributed in the region [0, 20], while the solutions of MOGA were in the region [50, 70]. Although MODE obtained fewer solutions compared to the other algorithms, it had the highest classification accuracy. Using TESS, MODE-NSF exhibited excellent abilities in diversity and classification accuracy, and MODE and MOGA also used more features to achieve a low amount of recognition errors. NSGA-II outperformed the other algorithms in low dimensional solutions. From the Pareto optimal solutions of MODE-NSF on the four datasets, it can be seen that the NSF-guided mutation is able to search for solutions in more emotional space and improve the population’s diversity.
Table 8 presents the running time of the algorithms. The maximum time complexity of RF was larger than that of KNN, resulting in a longer run time for the algorithms compared to KNN. MODE-NSF had a superior operational efficiency. The algorithms ran longer for TESS than they did for eNTERFACE05 and SAVEE.
4.3. Discussion
The running time of MODE-NSF using the KNN classifier in the four datasets was 268.8662, 295.3447, 178.7590, and 543.2745 respectively, while the running time on the RF classifier was 4008.0458, 11,584.3484, 3997.2735, and 16,545.7497. It is also reported in [
30,
31] that RF has a large time complexity, while KNN has a small workload. Ref. [
31] achieved a recognition accuracy of 41% for eNTERFACE05, while MONDE-NSF acquired an accuracy of 49%. In [
32,
33], they obtained an accuracy of 75% using MFCCs on RAVDESS, while MODE-NSF only exhibited an accuracy of 53%. Both the results reported in [
34] and those of MODE-NSF exhibited an accuracy of 76% for SAVEE. Ref. [
15] achieved a 97% accurate classification for TESS, compared to 98% for MODE-NSF. The algorithms acquired a high recognition accuracy using TESS and a low value for eNTERFACE05. MODE-NSF showed excellent performance for eNTERFACE05, SAVEE, and TESS, which illustrates that the NSF-guided method is suitable for speech emotion recognition.
5. Conclusions
Humans intentionally or unintentionally engage in emotional recognition when they interact with others. Speech signals can be extracted and used to classify emotions, and significant progress has been made in the field of emotion recognition. However, there is still a need for research in multi-objective emotion recognition. For this reason, pre-processing and feature selection are important for SER. In this paper, we propose a speech emotion recognition model based on DE as a feature selection method, using KNN and RF for emotion classification. First, feature extraction is applied to speech data, and then MFCCs and pitch features undergo DE to acquire the most relevant emotion features and discard redundant features. An accurate and robust SER is achieved through the reconstruction of input data with meaningful acoustic features. The NSF-guided multi-objective DE algorithm is responsible for efficiently exploring the emotional feature space and identifying the features for emotion classification. In English speech emotion datasets, the proposed MODE-NSF achieved a higher recognition accuracy with fewer features compared to the other multi-objective algorithms. MODE-NSF demonstrated a great execution efficiency because the number of features is the main factor affecting the running time of feature selection algorithms.
In the future, the proposed MODE-NSF algorithm can be applied in other popular research applications, especially in customer service, voice assistants, and English education. Furthermore, this algorithm can employ more acoustic features such as LPC, LSF, and DWT.
Author Contributions
Conceptualization, L.Y. and P.H.; formal analysis, L.Y. and S.-C.C.; methodology, L.Y., S.-C.C. and J.-S.P.; software, L.Y. and P.H.; writing—original draft, L.Y.; writing—review & editing, P.H., S.-C.C. and J.-S.P. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the Henan Provincial Philosophy and Social Science Planning Project (2022BJJ076), and the Henan Province Key Research and Development and Promotion Special Project (Soft Science Research) (222400410105).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available in the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hasija, T.; Kadyan, V.; Guleria, K.; Alharbi, A.; Alyami, H.; Goyal, N. Prosodic feature-based discriminatively trained low resource speech recognition system. Sustainability 2022, 14, 614. [Google Scholar] [CrossRef]
- Arslan, R.S.; Barışçı, N. Development of output correction methodology for long short term memory-based speech recognition. Sustainability 2019, 11, 4250. [Google Scholar] [CrossRef]
- Zhao, Z.D.; Zhao, M.S.; Lu, H.L.; Wang, S.H.; Lu, Y.Y. Digital Mapping of Soil pH Based on Machine Learning Combined with Feature Selection Methods in East China. Sustainability 2023, 15, 12874. [Google Scholar] [CrossRef]
- Song, D.; Huang, D.; Li, L.; He, H.L. Biomedical Named Entity Recognition Based on Feature Selection and Word Representations. J. Inf. Hiding Multim. Signal Process. 2016, 7, 729–740. [Google Scholar]
- Yuan, S.; Ji, Y.; Chen, Y.; Liu, X.; Zhang, W. An Improved Differential Evolution for Parameter Identification of Photovoltaic Models. Sustainability 2023, 15, 13916. [Google Scholar] [CrossRef]
- Feleke, S.; Pydi, B.; Satish, R.; Kotb, H.; Alenezi, M.; Shouran, M. Frequency stability enhancement using differential-evolution-and genetic-algorithm-optimized intelligent controllers in multiple virtual synchronous machine systems. Sustainability 2023, 15, 13892. [Google Scholar] [CrossRef]
- Pan, Z.B.; Yang, L.; Xu, Z.X.; Wang, D.Y. A NEC-based parallel differential evolution algorithm with MKL/CUDA. J. Netw. Intell. 2022, 7, 114–128. [Google Scholar]
- Li, T.; Dong, H.; Sun, J. Binary differential evolution based on individual entropy for feature subset optimization. IEEE Access 2019, 7, 24109–24121. [Google Scholar] [CrossRef]
- Zhang, Y.; Gong, D.W.; Gao, X.Z.; Tian, T.; Sun, X.Y. Binary differential evolution with self-learning for multi-objective feature selection. Inf. Sci. 2020, 507, 67–85. [Google Scholar] [CrossRef]
- Hancer, E. Fuzzy kernel feature selection with multi-objective differential evolution algorithm. Connect. Sci. 2019, 31, 323–341. [Google Scholar] [CrossRef]
- Wang, P.; Xue, B.; Liang, J.; Zhang, M. Feature selection using diversity-based multi-objective binary differential evolution. Inf. Sci. 2023, 626, 586–606. [Google Scholar] [CrossRef]
- Sun, L.; Fu, S.; Wang, F. Decision tree SVM model with Fisher feature selection for speech emotion recognition. EURASIP J. Audio Speech Music Process. 2019, 2019, 1–14. [Google Scholar] [CrossRef]
- Partila, P.; Voznak, M.; Tovarek, J. Pattern recognition methods and features selection for speech emotion recognition system. Sci. World J. 2015, 2015, 573068. [Google Scholar] [CrossRef]
- Bandela, S.R.; Kumar, T.K. Speech emotion recognition using unsupervised feature selection algorithms. Radioengineering 2020, 29, 353–364. [Google Scholar] [CrossRef]
- Akinpelu, S.; Viriri, S. Robust Feature Selection-Based Speech Emotion Classification Using Deep Transfer Learning. Appl. Sci. 2022, 12, 8265. [Google Scholar] [CrossRef]
- Li, D.; Zhou, Y.; Wang, Z.; Gao, D. Exploiting the potentialities of features for speech emotion recognition. Inf. Sci. 2021, 548, 328–343. [Google Scholar] [CrossRef]
- Brester, C.; Semenkin, E.; Sidorov, M. Multi-objective heuristic feature selection for speech-based multilingual emotion recognition. J. Artif. Intell. Soft Comput. Res. 2016, 6, 243–253. [Google Scholar] [CrossRef]
- Daneshfar, F.; Kabudian, S.J. Speech emotion recognition using discriminative dimension reduction by employing a modified quantum-behaved particle swarm optimization algorithm. Multimed. Tools Appl. 2020, 79, 1261–1289. [Google Scholar] [CrossRef]
- Li, M.; Qiu, X.; Peng, S.; Tang, L.; Li, Q.; Yang, W.; Ma, Y. Multimodal emotion recognition model based on a deep neural network with multiobjective optimization. Wirel. Commun. Mob. Comput. 2021, 2021, 6971100. [Google Scholar] [CrossRef]
- Yildirim, S.; Kaya, Y.; Kılıç, F. A modified feature selection method based on metaheuristic algorithms for speech emotion recognition. Appl. Acoust. 2021, 173, 107721. [Google Scholar] [CrossRef]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The eNTERFACE’05 audio-visual emotion database. In Proceedings of the 22nd International Conference on Data Engineering Workshops (ICDEW’06), Atlanta, GA, USA, 3–7 April 2006; p. 8. [Google Scholar]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [PubMed]
- Vryzas, N.; Kotsakis, R.; Liatsou, A.; Dimoulas, C.A.; Kalliris, G. Speech emotion recognition for performance interaction. J. Audio Eng. Soc. 2018, 66, 457–467. [Google Scholar] [CrossRef]
- Dupuis, K.; Pichora-Fuller, M.K. Recognition of emotional speech for younger and older talkers: Behavioural findings from the toronto emotional speech set. Can. Acoust. 2011, 39, 182–183. [Google Scholar]
- Xue, Y.; Tang, Y.; Xu, X.; Liang, J.; Neri, F. Multi-objective feature selection with missing data in classification. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 6, 355–364. [Google Scholar] [CrossRef]
- Bansal, M.; Goyal, A.; Choudhary, A. A comparative analysis of K-nearest neighbor, genetic, support vector machine, decision tree, and long short term memory algorithms in machine learning. Decis. Anal. J. 2022, 3, 100071. [Google Scholar] [CrossRef]
- Zhou, J.; Huang, S.; Qiu, Y. Optimization of random forest through the use of MVO, GWO and MFO in evaluating the stability of underground entry-type excavations. Tunn. Undergr. Space Technol. 2022, 124, 104494. [Google Scholar] [CrossRef]
- Rabinowicz, A.; Rosset, S. Cross-validation for correlated data. J. Am. Stat. Assoc. 2022, 117, 718–731. [Google Scholar] [CrossRef]
- Ali, I.M.; Essam, D.; Kasmarik, K. Novel binary differential evolution algorithm for knapsack problems. Inf. Sci. 2021, 542, 177–194. [Google Scholar] [CrossRef]
- Das, A.; Guha, S.; Singh, P.K.; Ahmadian, A.; Senu, N.; Sarkar, R. A hybrid meta-heuristic feature selection method for identification of Indian spoken languages from audio signals. IEEE Access 2020, 8, 181432–181449. [Google Scholar] [CrossRef]
- Özseven, T. A novel feature selection method for speech emotion recognition. Appl. Acoust. 2019, 146, 320–326. [Google Scholar] [CrossRef]
- Shahin, I.; Hindawi, N.; Nassif, A.B.; Alhudhaif, A.; Polat, K. Novel dual-channel long short-term memory compressed capsule networks for emotion recognition. Expert Syst. Appl. 2022, 188, 116080. [Google Scholar] [CrossRef]
- Bhavan, A.; Chauhan, P.; Shah, R.R. Bagged support vector machines for emotion recognition from speech. Knowl.-Based Syst. 2019, 184, 104886. [Google Scholar] [CrossRef]
- Liu, Z.T.; Xie, Q.; Wu, M.; Cao, W.H.; Mei, Y.; Mao, J.W. Speech emotion recognition based on an improved brain emotion learning model. Neurocomputing 2018, 309, 145–156. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}
{kind=link}