
Formula-Driven Supervised Learning in Computer Vision: A Literature Survey



Abstract
1. Introduction
- A detailed review of recent supervised learning schemes with respect to formula-driven supervised learning is presented.
- Extensive manual data collection and annotation methods for training large-data models based on FDSL are discussed using synthetic datasets.
- The state-of-the-art, the advantages and disadvantages, and the limitations and future potential of the techniques are considered.
2. Deep-Learning Schemes
2.1. Brief Discussion
2.1.1. Supervised Learning
2.1.2. Semi-Supervised Learning
2.1.3. Weakly Supervised Learning
2.1.4. Unsupervised Learning
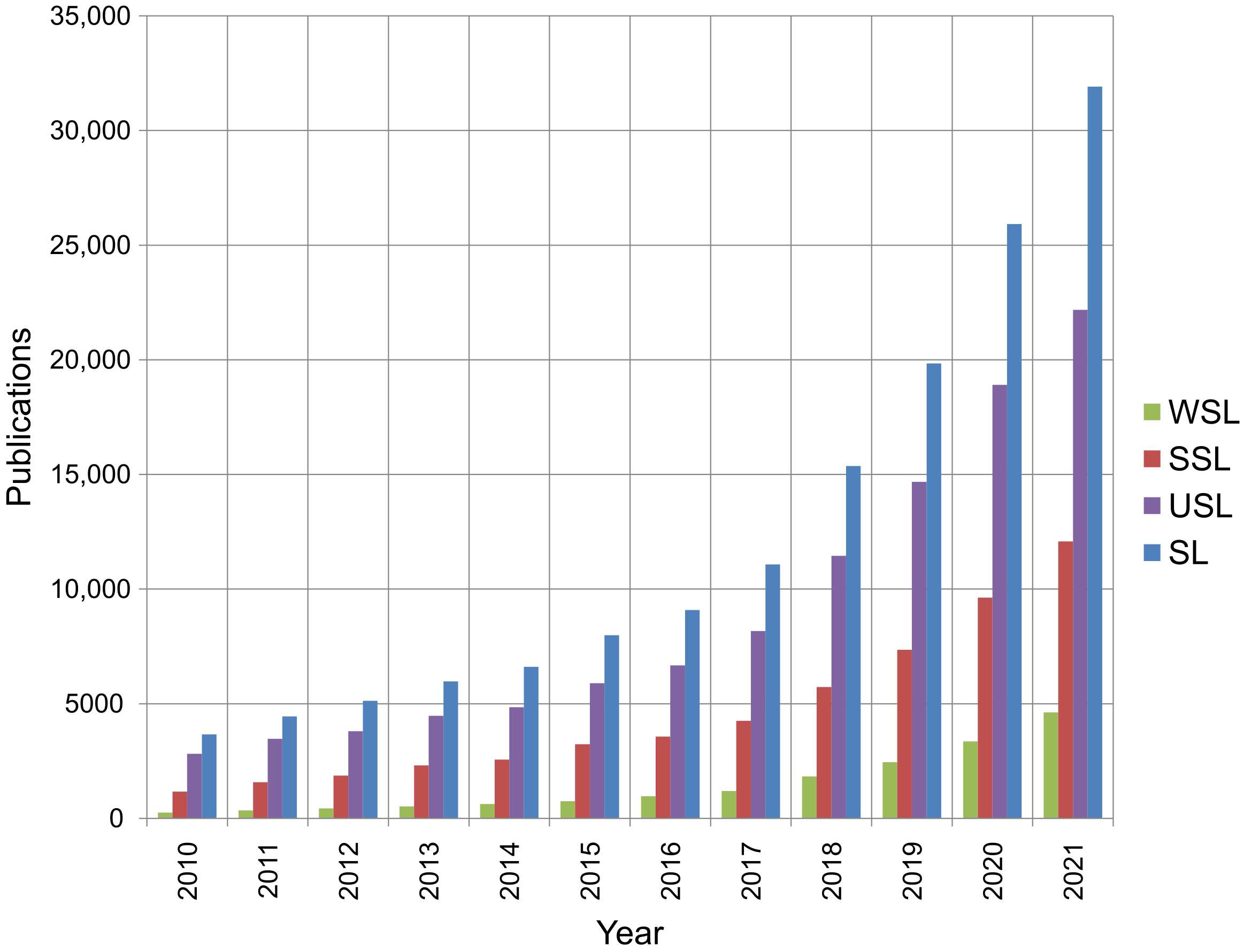
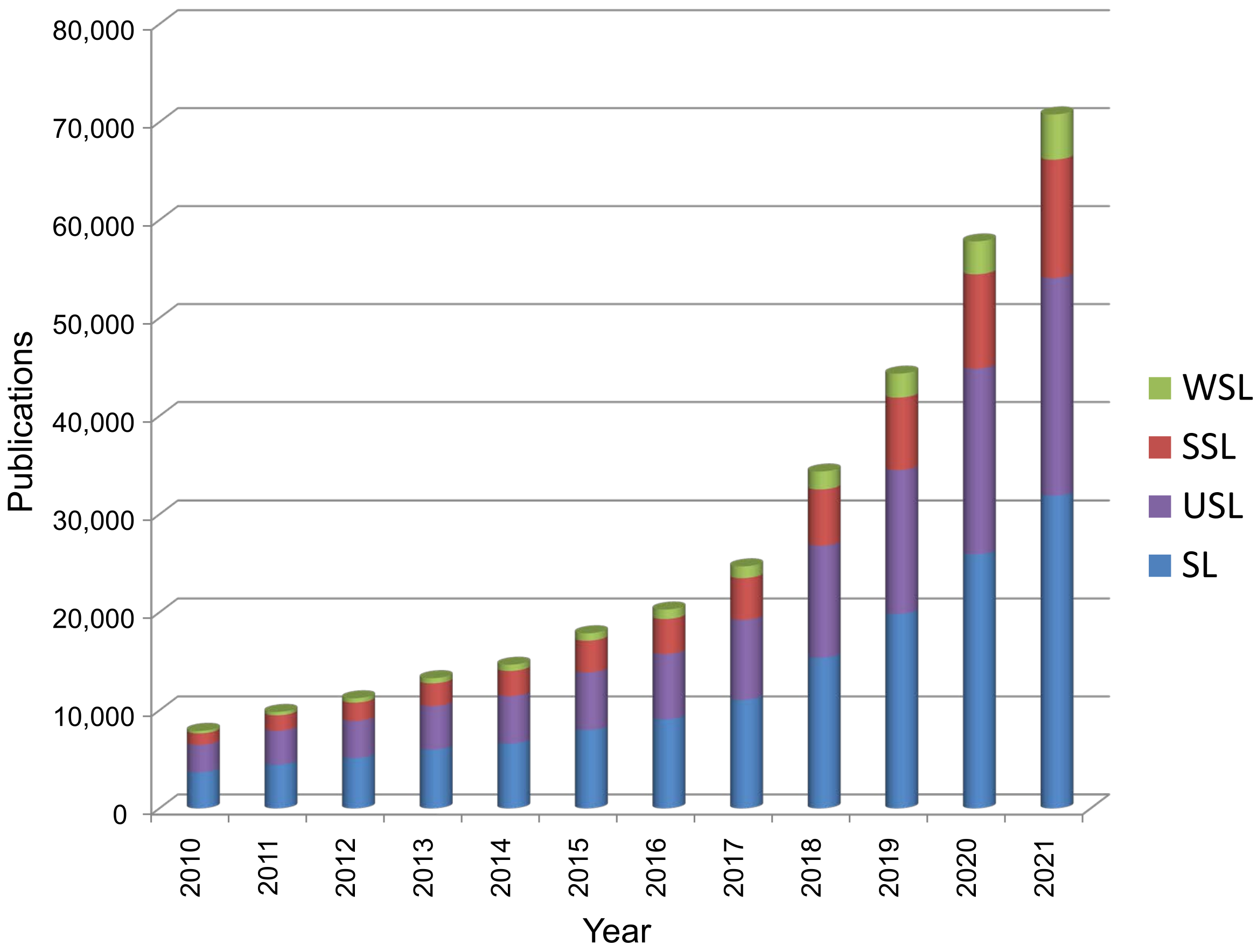
2.2. Recent Trends in Deep-Learning Schemes
3. Formula-Driven Supervised Learning
3.1. Background of FDSL
3.2. Learning Frameworks
3.3. Formula Based Projection of Images
3.4. FDSL Datasets
3.4.1. Fractal DataBase
3.4.2. MV-FractalDB
3.4.3. Other Notable FDSL Databases
4. Issues and Future Scope
4.1. Issues
4.2. Future Scope
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hassaballah, M.; Awad, A.I. Deep Learning in Computer Vision: Principles and Applications; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23-28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Sajid, F.; Javed, A.R.; Basharat, A.; Kryvinska, N.; Afzal, A.; Rizwan, M. An Efficient Deep Learning Framework for Distracted Driver Detection. IEEE Access 2021, 9, 169270–169280. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef]
- Hafiz, A.M.; Bhat, G.M. A survey on instance segmentation: State of the art. Int. J. Multimed. Inf. Retr. 2020, 9, 171–189. [Google Scholar] [CrossRef]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE Computer Society: Los Alamitos, CA, USA, 2015; pp. 3156–3164. [Google Scholar] [CrossRef]
- Amanat, A.; Rizwan, M.; Javed, A.R.; Abdelhaq, M.; Alsaqour, R.; Pandya, S.; Uddin, M. Deep Learning for Depression Detection from Textual Data. Electronics 2022, 11, 676. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-Supervised Visual Feature Learning With Deep Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4037–4058. [Google Scholar] [CrossRef]
- Hafiz, A.M.; Bhat, G.M. Deep Network Ensemble Learning applied to Image Classification using CNN Trees. arXiv 2020, arXiv:2008.00829. [Google Scholar]
- Hafiz, A.M.; Hassaballah, M. Digit Image Recognition Using an Ensemble of One-Versus-All Deep Network Classifiers. In Proceedings of the Information and Communication Technology for Competitive Strategies (ICTCS 2020), Jaipur, Rajasthan, India, 11–12 December 2020; Kaiser, M.S., Xie, J., Rathore, V.S., Eds.; Springer: Singapore, 2021; pp. 445–455. [Google Scholar]
- Hafiz, A.M.; Bhat, G.M. Fast training of deep networks with one-class CNNs. In Modern Approaches in Machine Learning and Cognitive Science: A Walkthrough: Latest Trends in AI; Gunjan, V.K., Zurada, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2021; Volume 2, pp. 409–421. [Google Scholar] [CrossRef]
- Hafiz, A.M.; Parah, S.A.; Bhat, R.U.A. Attention mechanisms and deep learning for machine vision: A survey of the state of the art. arXiv 2021, arXiv:2106.07550. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Pereira, F., Burges, C., Bottou, L., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE Computer Society: Los Alamitos, CA, USA, 2015; pp. 1–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The open images dataset v4. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- Hassaballah, M.; Khalid M., H. Recent Advances in Computer Vision: Theories and Applications; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features With 3D Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Hafiz, A.M.; Bhat, G.M. A Survey of Deep Learning Techniques for Medical Diagnosis. In Proceedings of the Information and Communication Technology for Sustainable Development, Goa, India, 23–24 July 2020; Tuba, M., Akashe, S., Joshi, A., Eds.; Springer: Singapore, 2020; pp. 161–170. [Google Scholar]
- Hafiz, A.M.; Bhat, R.U.A.; Parah, S.A.; Hassaballah, M. SE-MD: A Single-encoder multiple-decoder deep network for point cloud generation from 2D images. arXiv 2021, arXiv:2106.15325. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Yang, X.; Song, Z.; King, I.; Xu, Z. A Survey on Deep Semi-supervised Learning. arXiv 2021, arXiv:2103.00550. [Google Scholar] [CrossRef]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Li, Y.F.; Liang, D.M. Safe semi-supervised learning: A brief introduction. Front. Comput. Sci. 2019, 13, 669–676. [Google Scholar] [CrossRef]
- Yalniz, I.Z.; Jégou, H.; Chen, K.; Paluri, M.; Mahajan, D. Billion-scale semi-supervised learning for image classification. arXiv 2019, arXiv:1905.00546. [Google Scholar]
- Sohn, K.; Zhang, Z.; Li, C.L.; Zhang, H.; Lee, C.Y.; Pfister, T. A Simple Semi-Supervised Learning Framework for Object Detection. arXiv 2020, arXiv:2005.04757. [Google Scholar]
- Jeong, J.; Lee, S.; Kim, J.; Kwak, N. Consistency-based Semi-supervised Learning for Object detection. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Jiang, B.; Zhang, Z.; Lin, D.; Tang, J.; Luo, B. Semi-Supervised Learning With Graph Learning-Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Oliver, A.; Odena, A.; Raffel, C.A.; Cubuk, E.D.; Goodfellow, I. Realistic Evaluation of Deep Semi-Supervised Learning Algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Li, Q.; Han, Z.; Wu, X.M. Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence—AAAI’18/IAAI’18/EAAI’18, New Orleans Riverside, NO, USA, 2–7 February 2018. [Google Scholar]
- Feng, W.; Zhang, J.; Dong, Y.; Han, Y.; Luan, H.; Xu, Q.; Yang, Q.; Kharlamov, E.; Tang, J. Graph Random Neural Networks for Semi-Supervised Learning on Graphs. In Proceedings of the Advances in Neural Information Processing Systems, (Virtual-only Conference), 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc: Red Hook, NY, USA; Volume 33, pp. 22092–22103. [Google Scholar]
- Saito, S.; Yang, J.; Ma, Q.; Black, M.J. SCANimate Weakly Supervised Learning of Skinned Clothed Avatar Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2886–2897. [Google Scholar]
- Li, Y.F.; Guo, L.Z.; Zhou, Z.H. Towards Safe Weakly Supervised Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 334–346. [Google Scholar] [CrossRef]
- Ahn, J.; Cho, S.; Kwak, S. Weakly Supervised Learning of Instance Segmentation With Inter-Pixel Relations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhang, M.; Zhou, Y.; Zhao, J.; Man, Y.; Liu, B.; Yao, R. A survey of semi-and weakly supervised semantic segmentation of images. Artif. Intell. Rev. 2020, 53, 4259–4288. [Google Scholar] [CrossRef]
- Baldassarre, F.; Smith, K.; Sullivan, J.; Azizpour, H. Explanation-Based Weakly-Supervised Learning of Visual Relations with Graph Networks. In Proceedings of the Computer Vision—ECCV 2020 (Online Conference), 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 612–630. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised Representation Learning by Predicting Image Rotations. arXiv 2018, arXiv:1803.07728. [Google Scholar]
- Srivastava, N.; Mansimov, E.; Salakhutdinov, R. Unsupervised Learning of Video Representations Using LSTMs. In Proceedings of the 32nd International Conference on International Conference on Machine Learning—ICML’15, Lille, France, 6–11 July 2015; Volume 37, pp. 843–852. [Google Scholar]
- Wang, X.; Gupta, A. Unsupervised Learning of Visual Representations using Videos. arXiv 2015, arXiv:1505.00687. [Google Scholar]
- Lee, H.Y.; Huang, J.B.; Singh, M.; Yang, M.H. Unsupervised Representation Learning by Sorting Sequences. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Misra, I.; Zitnick, C.L.; Hebert, M. Shuffle and Learn: Unsupervised Learning Using Temporal Order Verification. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 527–544. [Google Scholar]
- Doersch, C.; Gupta, A.; Efros, A.A. Unsupervised Visual Representation Learning by Context Prediction. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–15 July 2017. [Google Scholar]
- Li, D.; Hung, W.C.; Huang, J.B.; Wang, S.; Ahuja, N.; Yang, M.H. Unsupervised Visual Representation Learning by Graph-Based Consistent Constraints. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 678–694. [Google Scholar]
- Caron, M.; Bojanowski, P.; Joulin, A.; Douze, M. Deep Clustering for Unsupervised Learning of Visual Features. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hoffer, E.; Hubara, I.; Ailon, N. Deep unsupervised learning through spatial contrasting. arXiv 2016, arXiv:1610.00243. [Google Scholar]
- Bojanowski, P.; Joulin, A. Unsupervised Learning by Predicting Noise. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; Volume 70, pp. 517–526. [Google Scholar]
- Li, Y.; Paluri, M.; Rehg, J.M.; Dollar, P. Unsupervised Learning of Edges. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Purushwalkam, S.; Gupta, A. Pose from Action: Unsupervised Learning of Pose Features based on Motion. arXiv 2016, arXiv:1609.05420. [Google Scholar]
- Mahendran, A.; Thewlis, J.; Vedaldi, A. Cross Pixel Optical Flow Similarity for Self-Supervised Learning. arXiv 2018, arXiv:1807.05636. [Google Scholar]
- Sayed, N.; Brattoli, B.; Ommer, B. Cross and Learn: Cross-Modal Self-Supervision. arXiv 2018, arXiv:1811.03879. [Google Scholar]
- Korbar, B.; Tran, D.; Torresani, L. Cooperative Learning of Audio and Video Models from Self-Supervised Synchronization. In Proceedings of the 32nd International Conference on Neural Information Processing Systems—NIPS’18, Montréal, QC, Canada, 2–8 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 7774–7785. [Google Scholar]
- Owens, A.; Efros, A.A. Audio-Visual Scene Analysis with Self-Supervised Multisensory Features. arXiv 2018, arXiv:1804.03641. [Google Scholar]
- Kim, D.; Cho, D.; Kweon, I.S. Self-Supervised Video Representation Learning with Space-Time Cubic Puzzles. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence—AAAI’19/IAAI’19/EAAI’19, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar] [CrossRef]
- Jing, L.; Yang, X.; Liu, J.; Tian, Y. Self-Supervised Spatiotemporal Feature Learning via Video Rotation Prediction. arXiv 2018, arXiv:1811.11387. [Google Scholar]
- Fernando, B.; Bilen, H.; Gavves, E.; Gould, S. Self-Supervised Video Representation Learning with Odd-One-Out Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 5729–5738. [Google Scholar] [CrossRef]
- Ren, Z.; Lee, Y. Cross-Domain Self-Supervised Multi-task Feature Learning Using Synthetic Imagery. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; IEEE Computer Society: Los Alamitos, CA, USA, 2018; pp. 762–771. [Google Scholar] [CrossRef]
- Wang, X.; He, K.; Gupta, A. Transitive Invariance for Self-Supervised Visual Representation Learning. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 1338–1347. [Google Scholar] [CrossRef]
- Doersch, C.; Zisserman, A. Multi-task Self-Supervised Visual Learning. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 2070–2079. [Google Scholar] [CrossRef]
- Mundhenk, T.; Ho, D.; Chen, B.Y. Improvements to Context Based Self-Supervised Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; IEEE Computer Society: Los Alamitos, CA, USA, 2018; pp. 9339–9348. [Google Scholar] [CrossRef]
- Noroozi, M.; Vinjimoor, A.; Favaro, P.; Pirsiavash, H. Boosting Self-Supervised Learning via Knowledge Transfer. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; IEEE Computer Society: Los Alamitos, CA, USA, 2018; pp. 9359–9367. [Google Scholar] [CrossRef]
- Büchler, U.; Brattoli, B.; Ommer, B. Improving Spatiotemporal Self-supervision by Deep Reinforcement Learning. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 797–814. [Google Scholar]
- Liu, Y.; Jin, M.; Pan, S.; Zhou, C.; Zheng, Y.; Xia, F.; Yu, P. Graph Self-Supervised Learning A Survey. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Baevski, A.; Hsu, W.N.; Xu, Q.; Babu, A.; Gu, J.; Auli, M. data2vec A General Framework for Self-supervised Learning in Speech, Vision and Language. arXiv 2022, arXiv:2202.03555. [Google Scholar]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised Learning Generative or Contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar] [CrossRef]
- Li, C.L.; Sohn, K.; Yoon, J.; Pfister, T. CutPaste Self-Supervised Learning for Anomaly Detection and Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (Online Conference), 19–25 June 2021; pp. 9664–9674. [Google Scholar]
- Xie, Y.; Xu, Z.; Zhang, J.; Wang, Z.; Ji, S. Self-Supervised Learning of Graph Neural Networks A Unified Review. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef] [PubMed]
- Akbari, H.; Yuan, L.; Qian, R.; Chuang, W.H.; Chang, S.F.; Cui, Y.; Gong, B. VATT Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text. In Proceedings of the Advances in Neural Information Processing Systems, (Online Conference), 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 24206–24221. [Google Scholar]
- Kataoka, H.; Okayasu, K.; Matsumoto, A.; Yamagata, E.; Yamada, R.; Inoue, N.; Nakamura, A.; Satoh, Y. Pre-training without Natural Images. In Proceedings of the Asian Conference on Computer Vision (ACCV), (Online Conference), 30 November–4 December 2020. [Google Scholar]
- Mahajan, D.; Girshick, R.; Ramanathan, V.; He, K.; Paluri, M.; Li, Y.; Bharambe, A.; van der Maaten, L. Exploring the Limits of Weakly Supervised Pretraining. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 185–201. [Google Scholar]
- Li, W.; Wang, L.; Li, W.; Agustsson, E.; Van Gool, L. WebVision Database: Visual Learning and Understanding from Web Data. arXiv 2017, arXiv:1708.02862. [Google Scholar]
- Schmarje, L.; Santarossa, M.; Schröder, S.M.; Koch, R. A Survey on Semi-, Self- and Unsupervised Learning for Image Classification. IEEE Access 2021, 9, 82146–82168. [Google Scholar] [CrossRef]
- Song, X.; Yang, H. A Survey of Unsupervised Learning in Medical Image Registration. Int. J. Health Syst. Transl. Med. (IJHSTM) 2022, 2. [Google Scholar] [CrossRef]
- Abukmeil, M.; Ferrari, S.; Genovese, A.; Piuri, V.; Scotti, F. A Survey of Unsupervised Generative Models for Exploratory Data Analysis and Representation Learning. ACM Comput. Surv. 2021, 54, 3450963. [Google Scholar] [CrossRef]
- Liu, T.; Yu, H.; Blair, R.H. Stability estimation for unsupervised clustering: A Review. WIREs Comput. Stat. 2022, 14, e1575. [Google Scholar] [CrossRef]
- Aoun, M.; Salloum, R.; Dfouni, A.; Sleilaty, G.; Chelala, D. A formula predicting the effective dose of febuxostat in chronic kidney disease patients with asymptomatic hyperuricemia based on a retrospective study and a validation cohort. Clin. Nephrol. 2020, 94, 61. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful Image Colorization. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 649–666. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Noroozi, M.; Favaro, P. Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 69–84. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 5987–5995. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Noroozi, M.; Pirsiavash, H.; Favaro, P. Representation Learning by Learning to Count. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5899–5907. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, (Online Conference), 6–10 June 2020; III, H.D., Singh, A., Eds.; Volume 119, pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (Online Conference), 14–19 June 2020; pp. 9726–9735. [Google Scholar] [CrossRef]
- Mandelbrot, B.B.; Wheeler, J.A. The Fractal Geometry of Nature. Am. J. Phys. 1983, 51, 286–287. [Google Scholar] [CrossRef]
- Landini, G.; Murray, P.I.; Misson, G.P. Local connected fractal dimensions and lacunarity analyses of 60 degrees fluorescein angiograms. Investig. Ophthalmol. Vis. Sci. 1995, 36, 2749–2755. Available online: https://arvojournals.org/arvo/content_public/journal/iovs/933408/2749.pdf (accessed on 14 December 2022).
- Smith, T.; Lange, G.; Marks, W. Fractal methods and results in cellular morphology - dimensions, lacunarity and multifractals. J. Neurosci. Methods 1996, 69, 123–136. [Google Scholar] [CrossRef] [PubMed]
- Barnsley, M.F. Fractals Everywhere; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Monro, D.; Dudbridge, F. Rendering algorithms for deterministic fractals. IEEE Comput. Graph. Appl. 1995, 15, 32–41. [Google Scholar] [CrossRef]
- Chen, Y.Q.; Bi, G. 3-D IFS fractals as real-time graphics model. Comput. Graph. 1997, 21, 367–370. [Google Scholar] [CrossRef]
- Pentland, A.P. Fractal-Based Description of Natural Scenes. IEEE Trans. Pattern Anal. Mach. Intell. 1984, PAMI-6, 661–674. [Google Scholar] [CrossRef]
- Varma, M.; Garg, R. Locally Invariant Fractal Features for Statistical Texture Classification. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Xu, Y.; Ji, H.; Fermüller, C. Viewpoint Invariant Texture Description Using Fractal Analysis. Int. J. Comput. Vision 2009, 83, 85–100. [Google Scholar] [CrossRef]
- Larsson, G.; Maire, M.; Shakhnarovich, G. FractalNet: Ultra-Deep Neural Networks without Residuals. In Proceedings of the 5th International Conference on Learning Representations—ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Falconer, K. Fractal Geometry: Mathematical Foundations and Applications; Wiley & Sons Ltd.: Hoboken, NJ, USA, 2004. [Google Scholar]
- Farin, G. Curves and Surfaces for Computer-Aided Geometric Design: A Practical Guide; Academic Press: Cambridge, MA, USA, 1993. [Google Scholar]
- Perlin, K. Improving Noise . ACM Trans Graph 2002, 21, 681–682. [Google Scholar] [CrossRef]
- Yamada, R.; Takahashi, R.; Suzuki, R.; Nakamura, A.; Yoshiyasu, Y.; Sagawa, R.; Kataoka, H. MV-FractalDB: Formula-driven Supervised Learning for Multi-view Image Recognition. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 2076–2083. [Google Scholar] [CrossRef]
- Xie, J.; Zheng, Z.; Gao, R.; Wang, W.; Zhu, S.C.; Wu, Y.N. Learning Descriptor Networks for 3D Shape Synthesis and Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Kanezaki, A.; Matsushita, Y.; Nishida, Y. RotationNet for Joint Object Categorization and Unsupervised Pose Estimation from Multi-View Images. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2021, 43, 269–283. [Google Scholar] [CrossRef]
- Kanezaki, A.; Matsushita, Y.; Nishida, Y. RotationNet: Joint Object Categorization and Pose Estimation Using Multiviews from Unsupervised Viewpoints. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Kataoka, H.; Matsumoto, A.; Yamada, R.; Satoh, Y.; Yamagata, E.; Inoue, N. Formula-driven Supervised Learning with Recursive Tiling Patterns. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), (Online Conference), 11–17 October 2021; pp. 4081–4088. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–21. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the 38th International Conference on Machine Learning, (Online Conference), 18–24 July 2021; Meila, M., Zhang, T., Eds.; Volume 139, pp. 10347–10357. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 Million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2009. Available online: https://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 8 April 2009).
- Everingham, M.; Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vision 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lake, B.M.; Salakhutdinov, R.; Tenenbaum, J.B. The Omniglot challenge: a 3-year progress report. Curr. Opin. Behav. Sci. 2019, 29, 97–104. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pretraining | Learning | ModelNet40 | ModelNet40 | MIRO |
|---|---|---|---|---|
| Technique | Method | (12 Views) | (20 Views) | (20 Views) |
| — | — | 84.0 | 91.5 | 91.7 |
| ImageNet | SL | 88.1 | 96.1 | 100.0 |
| SimCLR | SFSL | 88.1 | 95.1 | 100.0 |
| MoCo | SFSL | 86.4 | 95.3 | 100.0 |
| FractalDB1k | FDSL | 87.4 | 94.9 | 100.0 |
| MV-FractalDB1k | FDSL | 87.6 | 95.7 | 100.0 |
| Dataset | Cifar-10 | Cifar-100 | Cars | Flowers |
|---|---|---|---|---|
| — | 78.3 | 57.7 | 11.6 | 77.1 |
| PerlinNoiseDB | 94.5 | 77.8 | 62.3 | 96.1 |
| BeizerCurveDB | 96.7 | 80.3 | 82.8 | 98.5 |
| FractalDB1k | 96.8 | 81.6 | 86.0 | 98.3 |
| Technique | Image Type | Method | C-10 | C-100 | ImNt-1k | P-365 | VOC-12 | OG |
|---|---|---|---|---|---|---|---|---|
| — | – | – | 87.6 | 62.7 | 76.1 | 49.9 | 58.9 | 1.1 |
| DC | Natural | SFSL | 89.9 | 66.9 | 66.2 | 51.5 | 67.5 | 15.2 |
| Places30 | Natural | SL | 90.1 | 67.8 | 69.1 | – | 69.5 | 6.4 |
| Places365 | Natural | SL | 94.2 | 76.9 | 71.4 | – | 78.6 | 10.5 |
| ImageNet100 | Natural | SL | 91.3 | 70.6 | – | 49.7 | 72.0 | 12.3 |
| ImageNet1k | Natural | SL | 96.8 | 84.6 | – | 50.3 | 85.8 | 17.5 |
| TileDB | Synthetic | FDSL | 92.5 | 73.7 | – | – | 71.4 | – |
| FractalDB1k | Synthetic | FDSL | 93.4 | 75.7 | 70.3 | 49.5 | 58.9 | 20.9 |
| FractalDB10k | Synthetic | FDSL | 94.1 | 77.3 | 71.5 | 50.8 | 73.6 | 29.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hafiz, A.M.; Hassaballah, M.; Binbusayyis, A. Formula-Driven Supervised Learning in Computer Vision: A Literature Survey. Appl. Sci. 2023, 13, 723. https://doi.org/10.3390/app13020723
Hafiz AM, Hassaballah M, Binbusayyis A. Formula-Driven Supervised Learning in Computer Vision: A Literature Survey. Applied Sciences. 2023; 13(2):723. https://doi.org/10.3390/app13020723
Chicago/Turabian StyleHafiz, Abdul Mueed, Mahmoud Hassaballah, and Adel Binbusayyis. 2023. "Formula-Driven Supervised Learning in Computer Vision: A Literature Survey" Applied Sciences 13, no. 2: 723. https://doi.org/10.3390/app13020723
APA StyleHafiz, A. M., Hassaballah, M., & Binbusayyis, A. (2023). Formula-Driven Supervised Learning in Computer Vision: A Literature Survey. Applied Sciences, 13(2), 723. https://doi.org/10.3390/app13020723