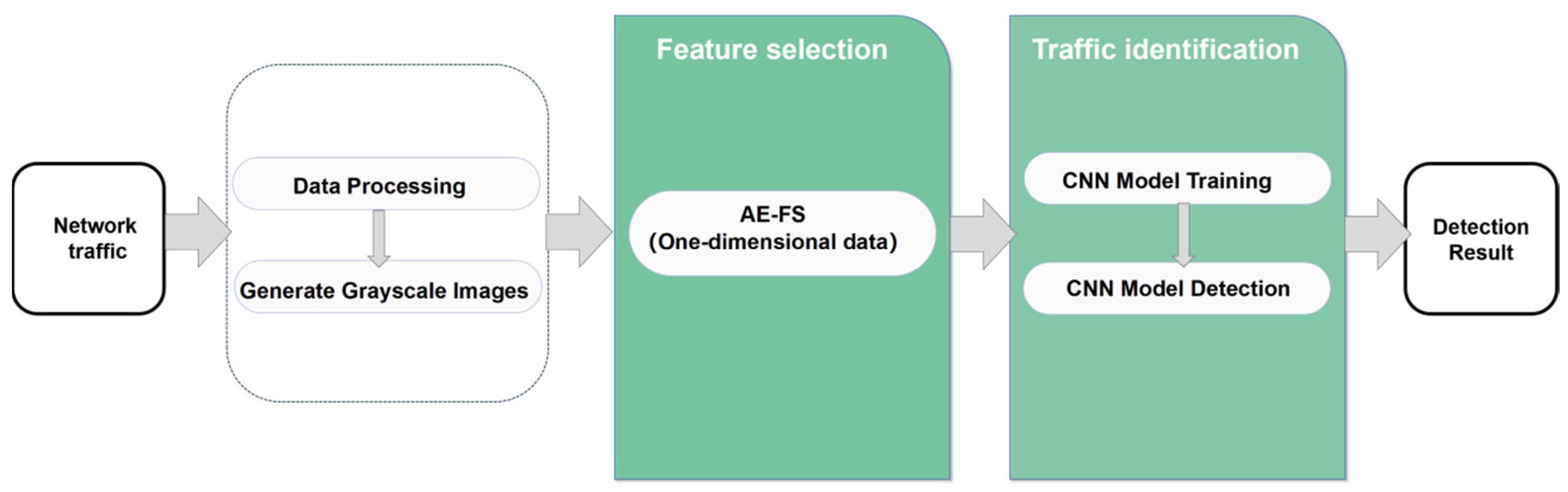
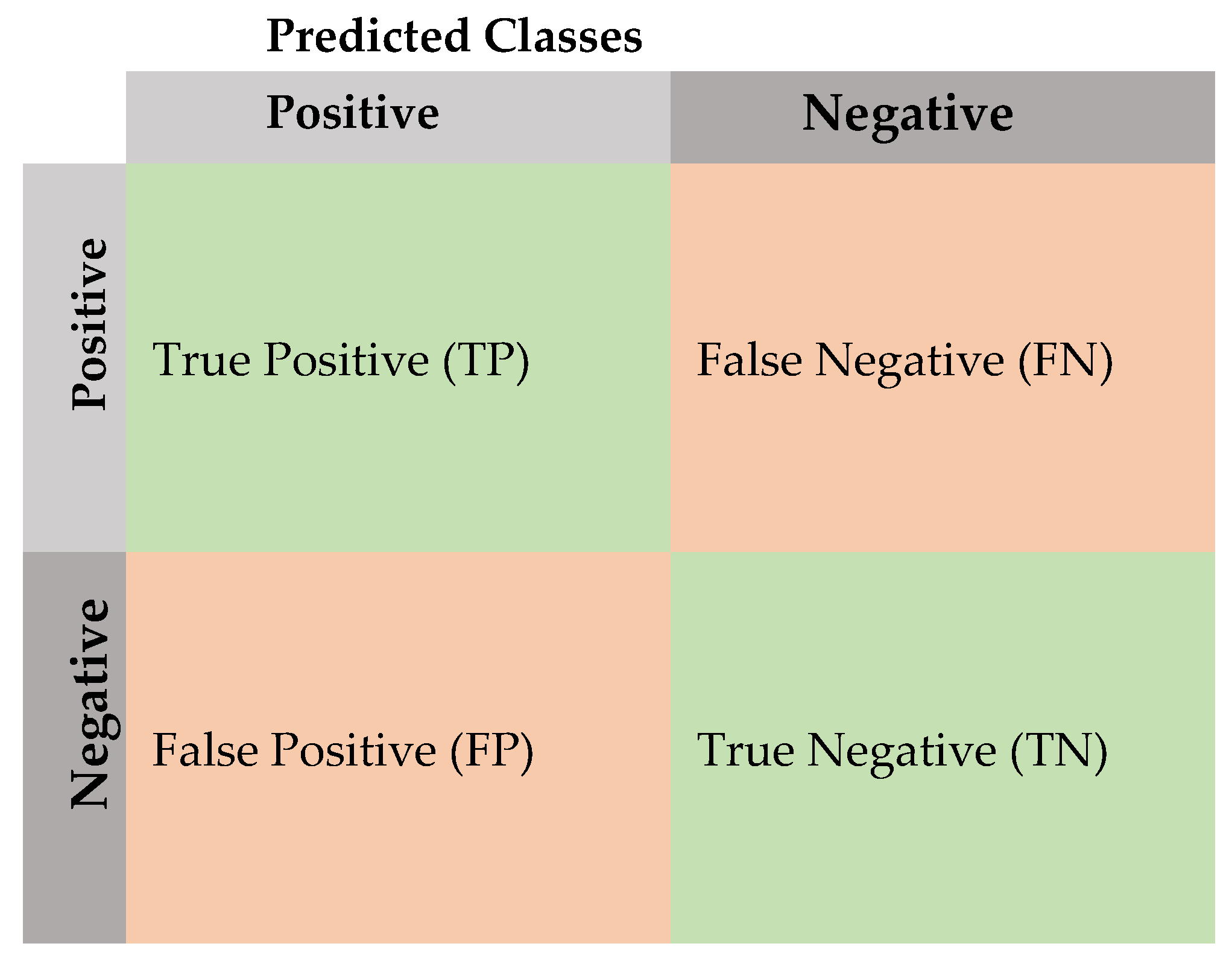
In this section, multiple groups of comparative experiments are conducted to verify the effectiveness of the AE-DTI method.
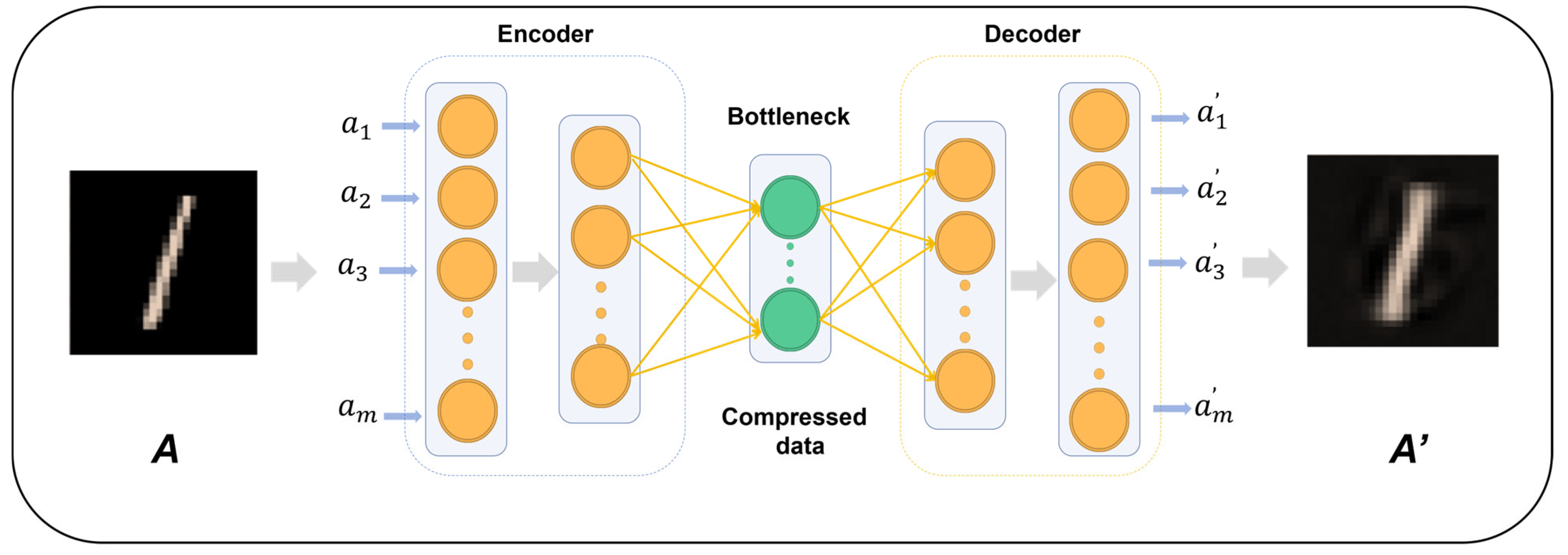
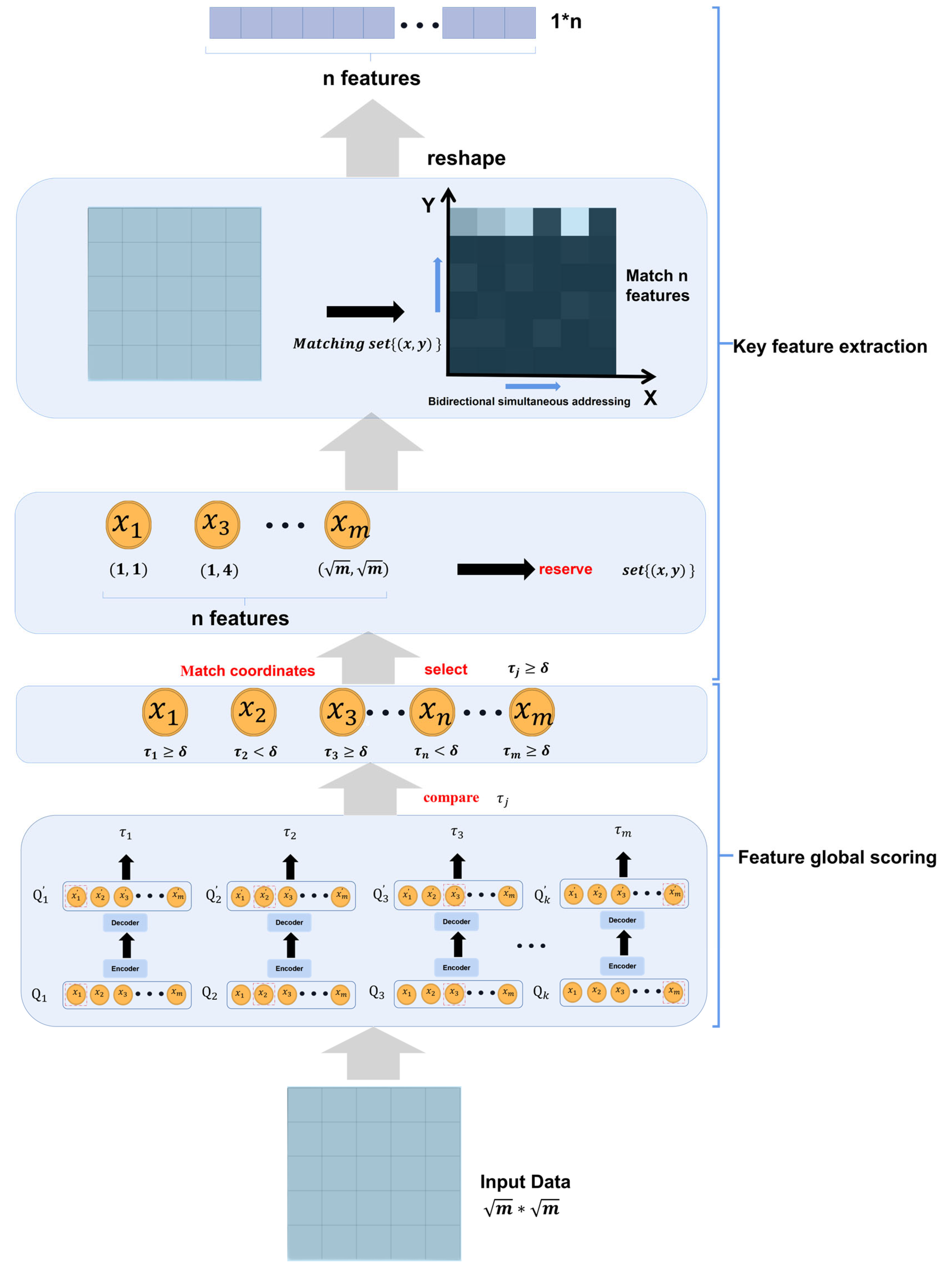
First, AE-FS, along with several dimensionality reduction techniques such as Principal Component Analysis (PCA) [
25], Locally Linear Embedding (LLE) [
26], Isometric Mapping (ISOMAP) [
27] and autoencoder [
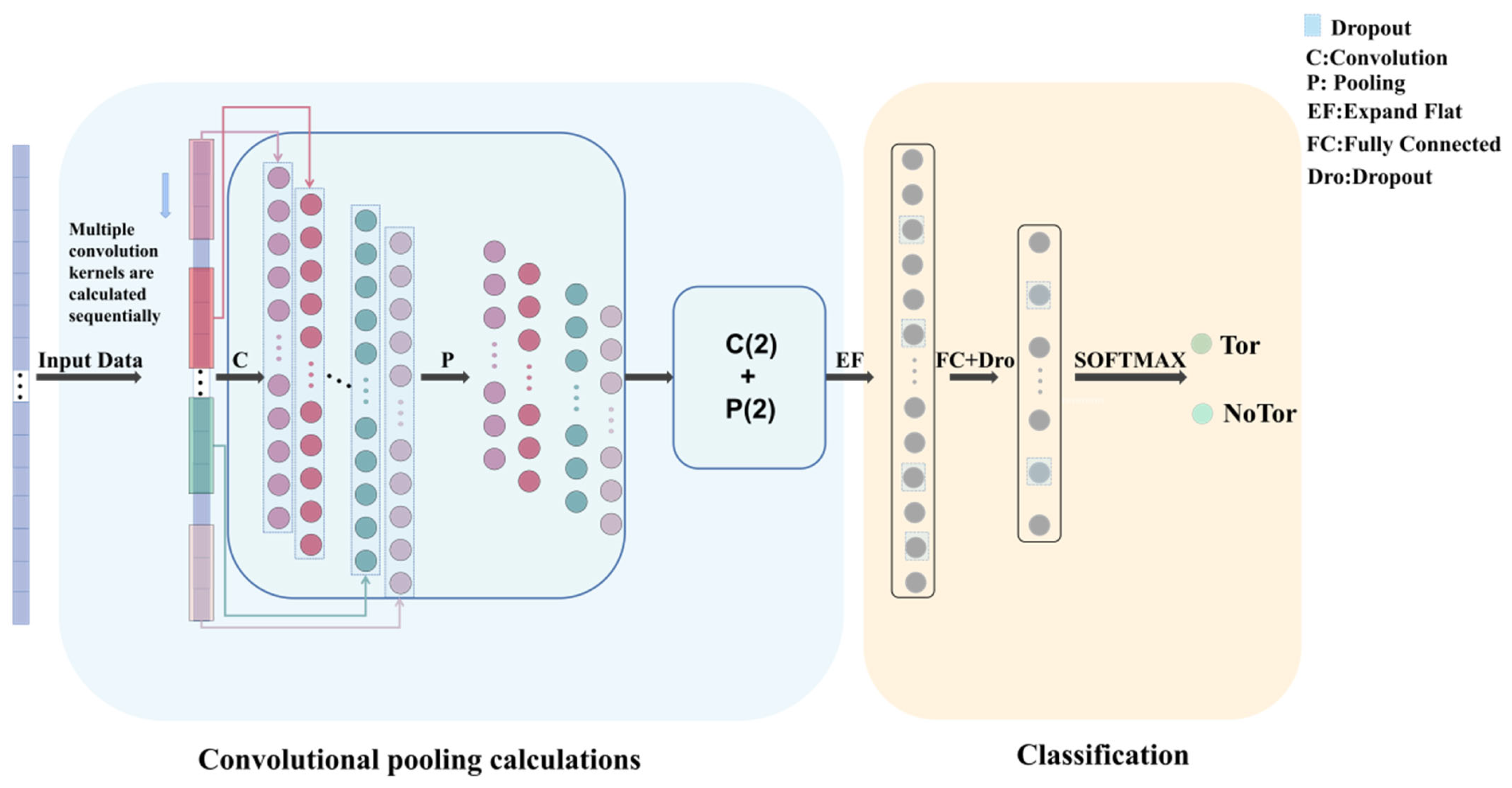
28] are employed to reduce the dimensionality of the ISCXTor2016 dataset and to use the reduced dimensionality dataset to train a one-dimensional convolutional neural network with 100 rounds for each experiment. This experiment aims to verify the performance advantages of the AE-FS method.
Second, to assess the overall performance of AE-DTI, we compare it with existing methods proposed by other researchers. This comparative analysis allows us to evaluate the effectiveness of AE-DTI and discern its advantages when applied to similar tasks.
Finally, the effectiveness of AE-DTI is tested on the CSE-CIC-IDS2018 and CIC-Darknet2020 datasets to assess its generalization capabilities and evaluate its performance across various application scenarios.
4.4.1. Comparison Experiments of Different Dimensionality Reduction Methods
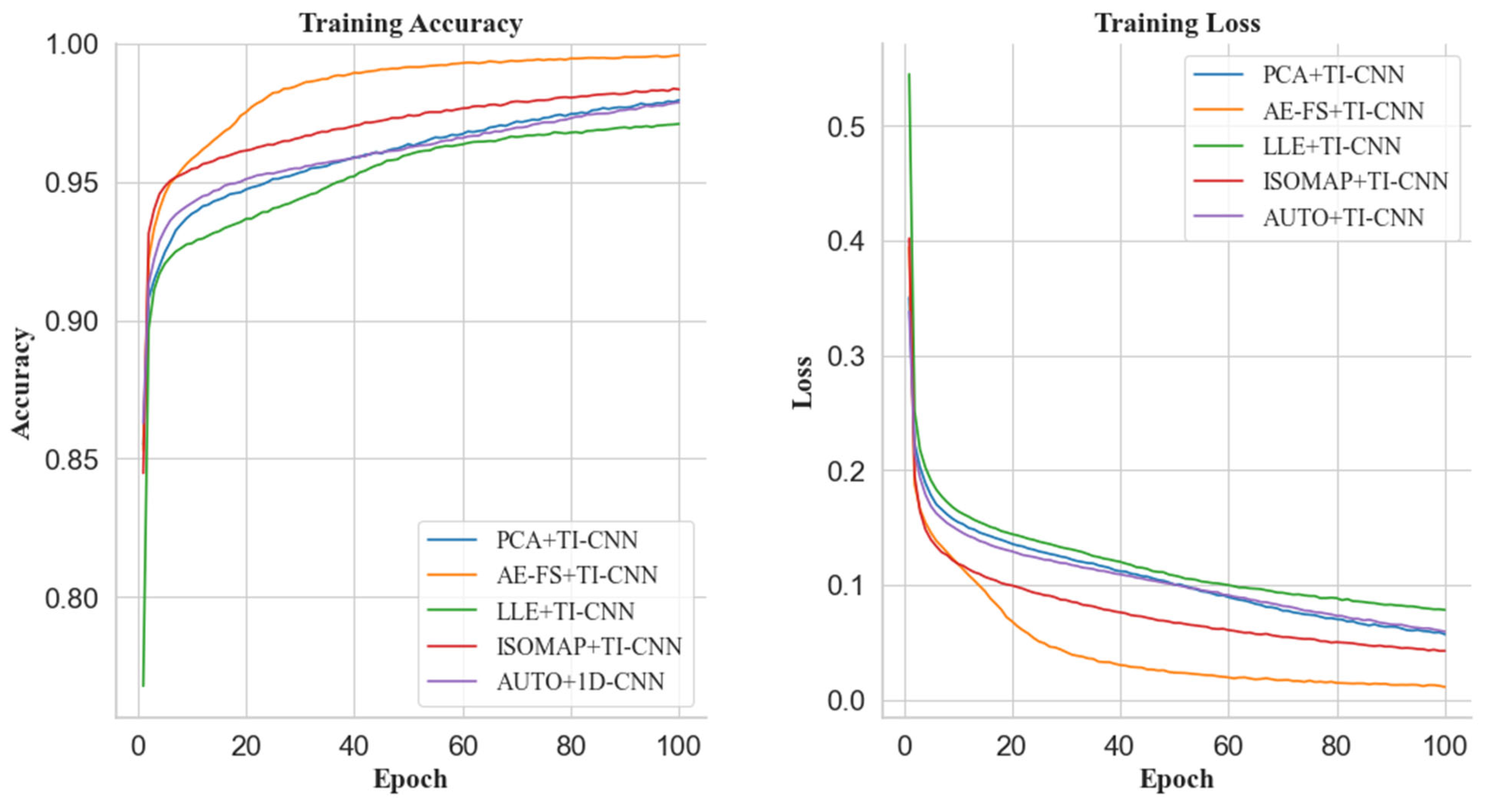
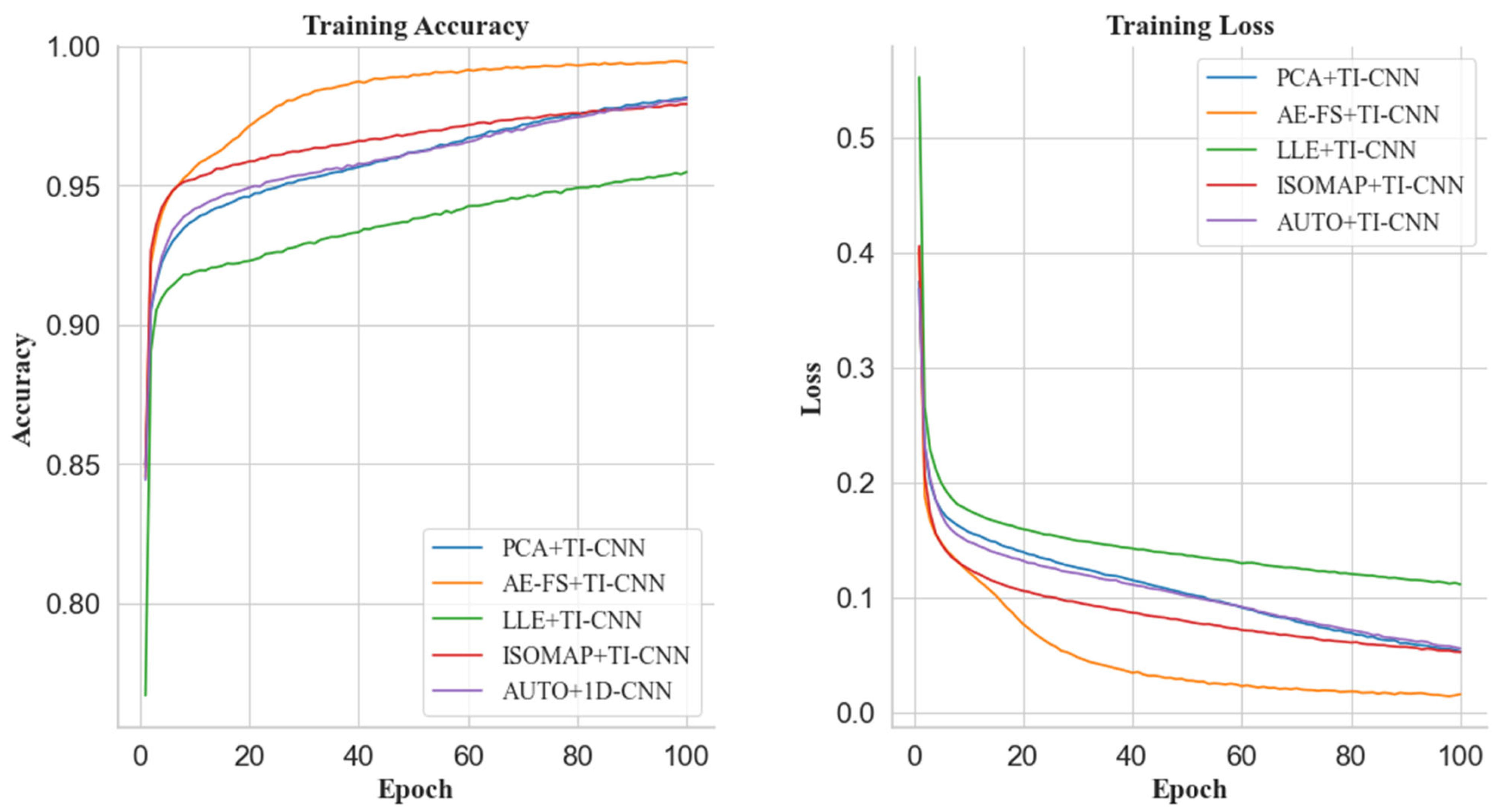
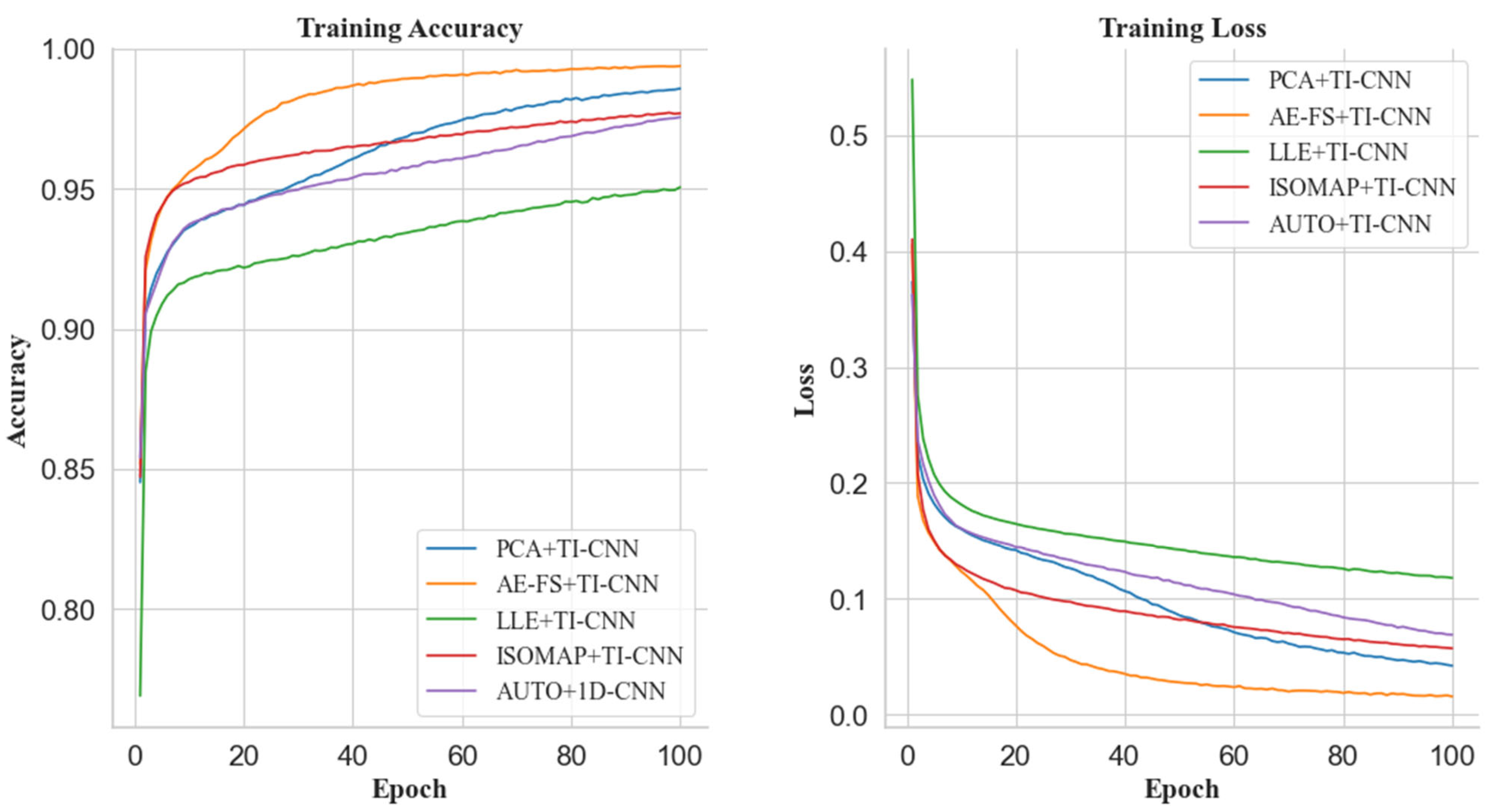
In this section, different dimensionality reduction methods (AE-FS, PCA, LLE, ISOMAP, and autoencoder) are used to reduce the dimensionality of the dataset to 25, 20, 18, and 16 dimensions and then perform model training by comparing the performance of the model in terms of training time, training accuracy, and loss rate. The experimental results are as follows:
Figure 7,
Figure 8,
Figure 9 and
Figure 10 show the training accuracy and loss rate of the model, and
Figure 10 shows the training time of the model. In addition, the one-dimensional convolutional neural network classification experiment is carried out on the dataset after AE-FS dimension reduction and the original dataset without dimension reduction, and the experimental results shown in
Figure 11 were obtained.
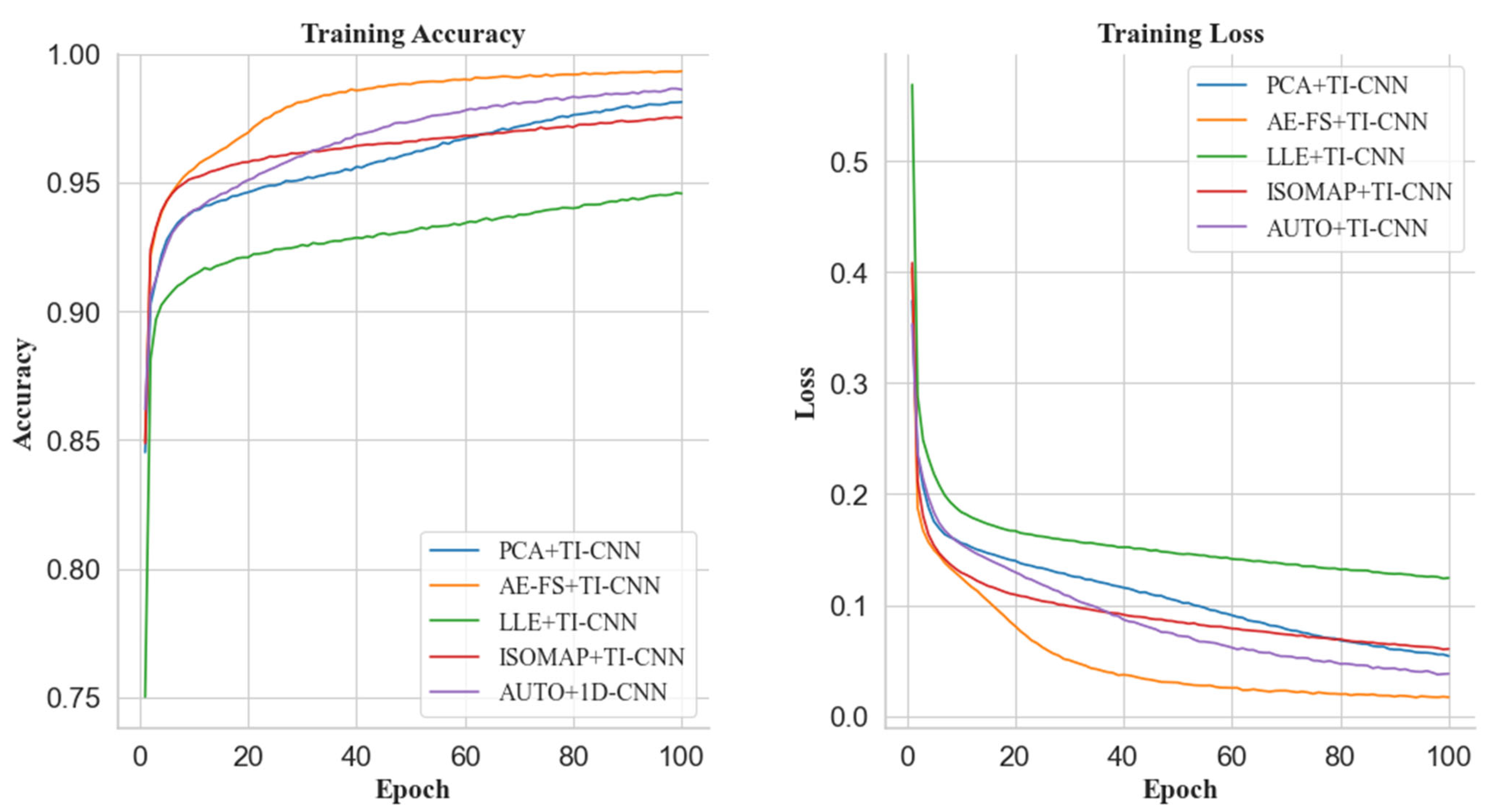
Regarding the training accuracy of the training model, the AE-FS dimensionality reduction dataset shows apparent advantages in the training process. For example, when the dataset is reduced to 25 dimensions, the feature reduction rate is 10.8% (as shown in
Figure 7). The AE-FS+TI-CNN model first reaches the fitting state at the beginning of training and reaches the highest at the end of training. The training accuracy rate is about 98%. Similarly, when the dataset is reduced to 20 dimensions, the feature reduction rate is 28.6% (as shown in
Figure 8). The FS+TI-CNN model has a clear advantage in training accuracy, which is higher than that of the PCA+TI-CNN model by 2.5%. In addition, when the dataset is reduced to 18 dimensions, the feature reduction rate is 35.7% (as shown in
Figure 9), and the training accuracy of the FS+TI-CNN model is 0.8% higher than that of the PCA+TI-CNN model. Finally, when the dataset is reduced to 16 dimensions, the feature reduction rate is about 42.9% (as shown in
Figure 10). The AE-FS+TI-CNN model also has a clear advantage in training accuracy. Compared with AUTO+TI-CNN the model is 0.5% higher. In summary, the AE-FS dimensionality reduction method shows excellent performance and advantages when dealing with high-dimensional datasets, and its model quickly reaches the fitting state during the training process and achieves the highest training accuracy at the end of the training.
Regarding model training loss rate, when the dataset is reduced to 25 dimensions (as shown in
Figure 7), the AE-FS+TI-CNN model performs best, which is 3% lower than the ISOMAP+TI-CNN model training loss rate. Meanwhile, the loss rate of the LLE+TI-CNN model converges the slowest. When the dataset is reduced to 20 dimensions (as shown in
Figure 8), the loss rate of the AE-FS+TI-CNN model is 4% lower than that of the ISOMAP+TI-CNN model, and the loss rate of the LLE+TI-CNN model also converges the slowest. When the dataset is reduced to 18 and 16 dimensions (as shown in
Figure 9 and
Figure 10), the loss rate of the AE-FS+TI-CNN model also performs best. Compared with the PCA+TI-CNN model and AUTO+, the TI-CNN model is about 2.5% and 2% lower, respectively, and the loss rate convergence of the LLE+TI-CNN model is still the slowest.
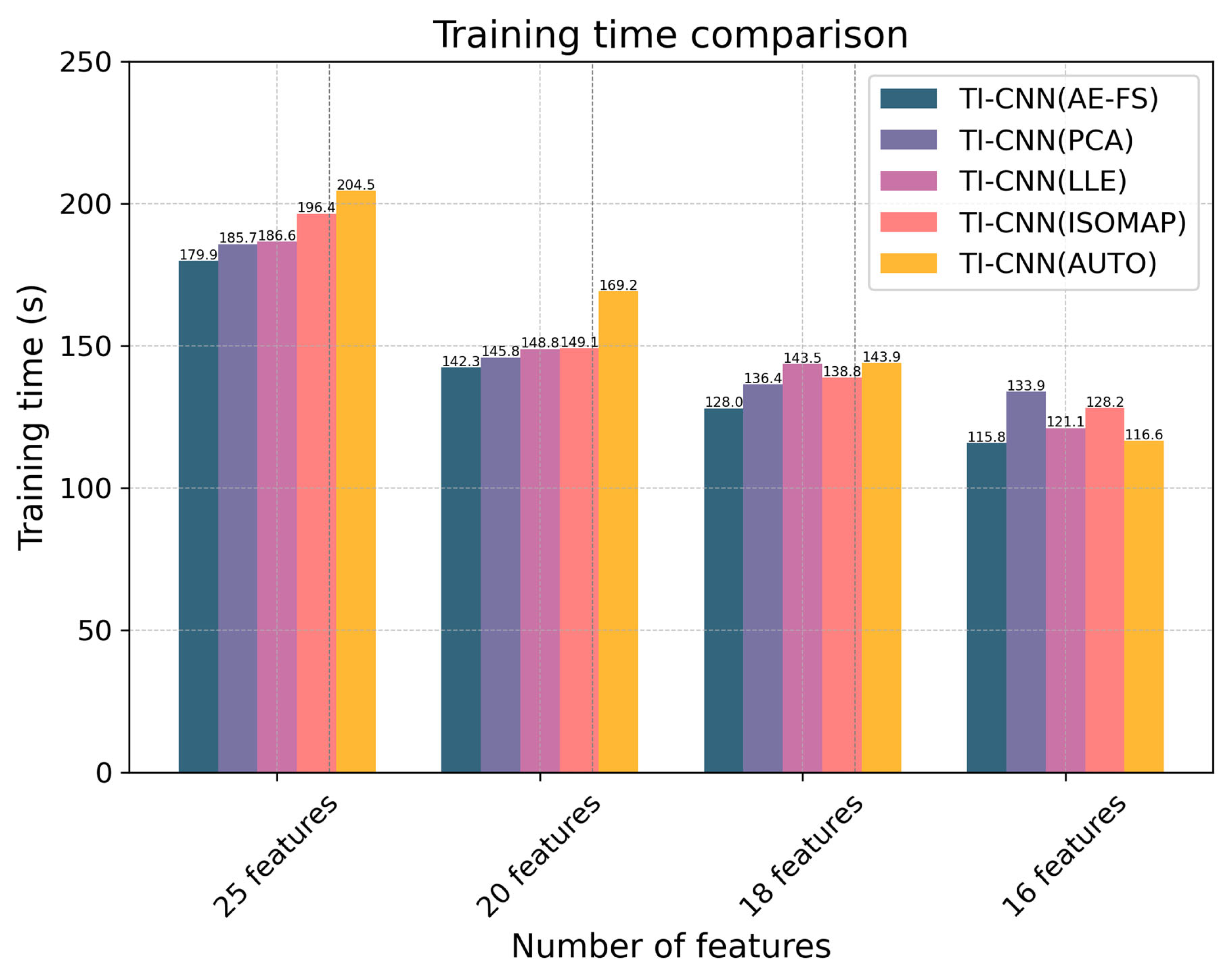
Regarding model training time, the experimental results are shown in
Figure 11. In general, the less dimensionality of the dataset, the shorter the training time of the model. When reducing the dataset to 25 dimensions, the AUTO+TI-CNN model exhibits the longest training time of approximately 204.5 s, whereas the AE-FS+TI-CNN model shows the shortest training time of about 179.9 s. The difference between the two is approximately 25 s, with a relative difference rate of around 12.2%. When the dataset is reduced to 20 dimensions, the AUTO+TI-CNN model requires the longest training time, about 169.2 s; the AE-FS+TI-CNN model requires the shortest training time, about 142.3 s. Similarly, when the dataset is reduced to 18 dimensions, the AUTO+TI-CNN model requires the longest training time, about 143.9 s, and the AE-FS+TI-CNN model requires the shortest training time, about 128 s. Furthermore, when the dataset is reduced to 16 dimensions, the training time required for the AUTO+TI-CNN model is the shortest, which is 115.8 s. Therefore, it can be concluded that the AE-FS dimensionality reduction method can significantly reduce the training time of the model while maintaining a high training accuracy.
From
Table 4, we implemented five different dimensionality reduction techniques to decrease the number of dimensions in the dataset to 25, 20, 18, and 16. The dimension re-duction time for LLE and ISOMAP is considerably longer compared to PCA, AUTO, and AE_FS. This is because LLE and ISOMAP take into account more local information and the relationships between data points during the calculation process, resulting in increased dimension reduction time. AE_FS takes slightly longer than PCA and AUTO for data dimensionality reduction, but it outperforms them in terms of model training time and classification accuracy. It is important to note that the data dimensionality reduction process can be performed offline, which helps mitigate the impact of dimensionality re-duction time on the overall model performance. Therefore, considering data dimension reduction time, model training time, and classification accuracy, it is evident that AE-FSS still holds significant advantages over other methods. In practical applications, AE-FSS offers the dual advantages of efficiency and accuracy in data processing.
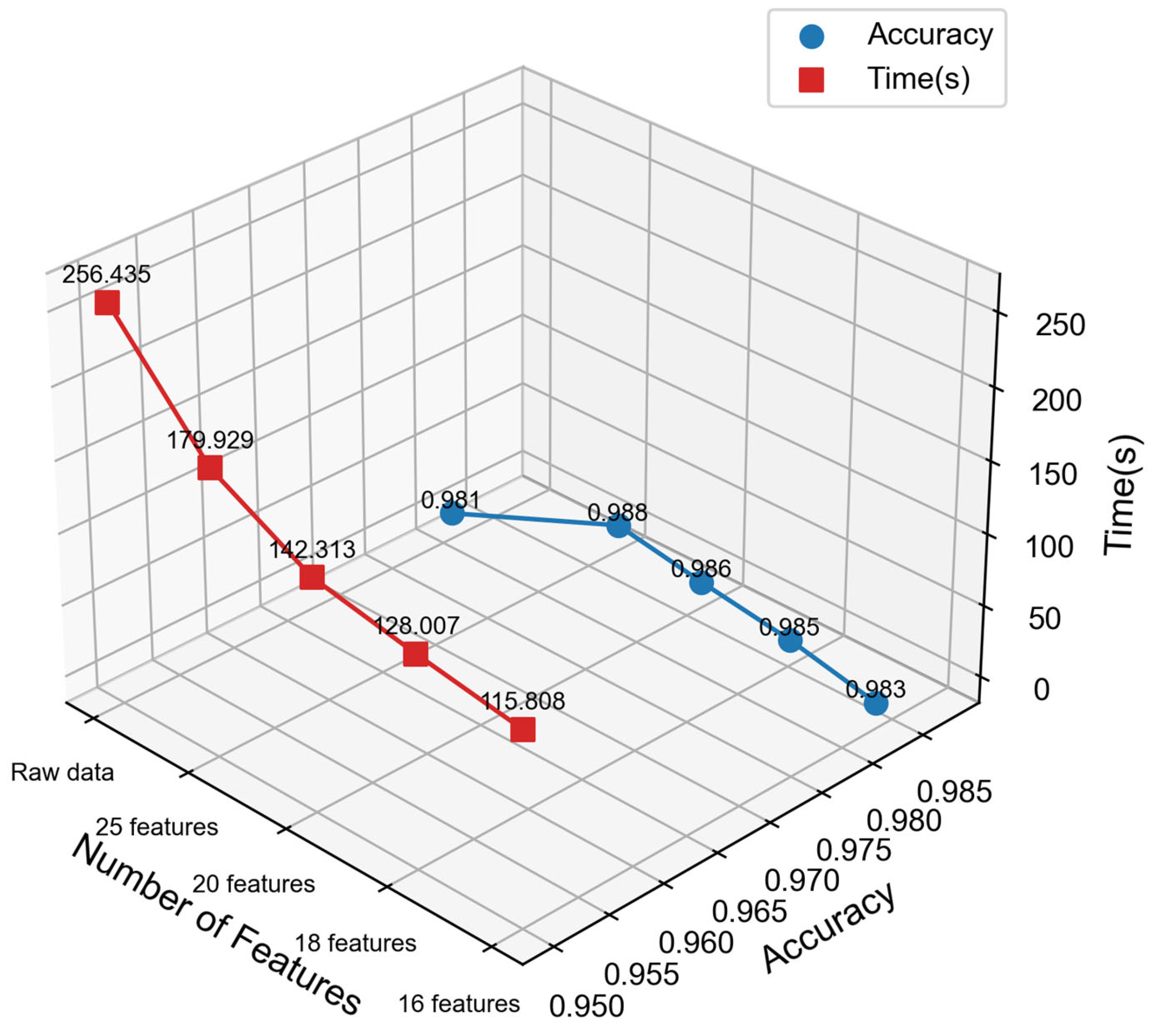
According to the results in
Figure 12, it can be observed that the training time of the model is significantly reduced through the AE-FS dimensionality reduction dataset. Especially when the dataset is reduced to 16 dimensions, the time reduction is the most significant, with a drop of up to 54.3%. At the same time, the classification accuracy of the AE-FS+TI-CNN model is the same as that of the original dataset, the highest training accuracy is 98.8%, and the lowest is 98.3%. Compared with the original dataset. The classification accuracy of the AE-FS+TI-CNN model increased by about 0.7% and 0.2%. Therefore, it shows that dimensionality reduction through AE-FS not only fully preserves the key features of the dataset, but also dramatically reduces the training time of the model.
4.4.2. Comparison of AE-DTI with Other Methods
This section examines the classification performance and effectiveness of four models. These models include the following: Lashkari et al. [
21] utilized time-based features extracted from 15-s Tor traffic to train a random forest model; Yan, H et al. [
29] employed sliding time windows to segment network traffic and calculated the relative entropy of traffic within the time window to identify Tor traffic; Haoyu Ma et al. [
30] proposed a deep-learning-based scheme for detecting dark web traffic (Tor traffic); and this paper presents a darknet traffic identification method based on autoencoder (AE-DTI). All of these models were trained on the ISCXTor dataset.
The experimental results are presented in
Table 5. With the exception of Lashkari et al.’s method, the accuracy of the other methods exceeds 90%, and the accuracy of AE-DTI surpasses 98%. Particularly, when the dataset is reduced to 16 dimensions by AE-FS, AE-DTI requires minimal features for training. However, AE-DTI performs better than other methods in every evaluation index. Consequently, AE-DTI not only enhances the efficiency of traffic identification but also significantly improves classification accuracy. This is of substantial importance in enhancing the efficiency and accuracy of traffic identification, and it can serve as a valuable reference for research and practical applications in related fields.
4.4.3. AE-DTI Generalization Experiment
To verify the generalization of AE-DTI, this paper conducts comparative experiments on the CSE-CIC-IDS2018 dataset and the CIC-Darknet2020 dataset. Various dimensionality reduction methods (PCA, LLE, ISOMAP, autoencoder, and AE-FS) were used to reduce the dimensionality of the two datasets to 49 and 64 dimensions, and then model training and classification experiments were performed, respectively. The experimental results are shown in
Table 6 and
Table 7.
According to the results in
Table 6, when the dataset is downscaled to 49 dimensions, for in the CSE-CIC-IDS2018 dataset, the model trained by the dataset downscaled by AE-FS outperforms the other methods, with Acc, F1 value, and Recall improving by 1.5%, 0.8%, and 1.5% compared with PCA downscaling. It is slightly lower than the model trained on the dataset via ISOMAP dimensionality reduction in Pre, with a difference of about 0.1%. For the CIC-Darknet2020 dataset, the model trained on the dataset downscaled by AE-FS outperforms the other methods in Acc, Pre, F1 value, and Recall. At the same time, it is worth noting that for unbalanced datasets such as CIC-Darknet2020, AE-IDT still shows good classification results.
According to the results in
Table 7, when the dataset is downscaled to 64 dimensions, for the CSE-CIC-IDS2018 dataset, the models trained on the dataset downscaled by AE-FS outperform the other methods, with the Acc, F1 value, Pre, and Recall improving by 3.9%, 3.6%, 3.5%, and 3.8% compared with PCA downscaling. For the CIC-Darknet2020 dataset, the models trained on the dataset with AE-FS dimensionality reduction also outperformed the other methods in terms of Acc, F1 value, Pre, and Recall. At the same time, it is worth noting that for unbalanced datasets such as CIC-Darknet2020, AE-IDT still shows good classification results.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}