
Self-Supervised Spatio-Temporal Graph Learning for Point-of-Interest Recommendation



Abstract
:1. Introduction
- To the best of our knowledge, this is the first attempt to design a self-supervised learning-based framework to improve GNN-based POI recommendation algorithms.
- We propose data augmentation strategies and pre-text tasks of the proposed framework, which model spatial or temporal prior knowledge from different perspectives.
- We conducted experiments on three POI recommendation datasets and verified that our model could improve GNN-based POI recommendations and outperform existing state-of-the-art methods.
2. Related Works
2.1. Point-of-Interest Recommendation
2.2. Self-Supervised Learning
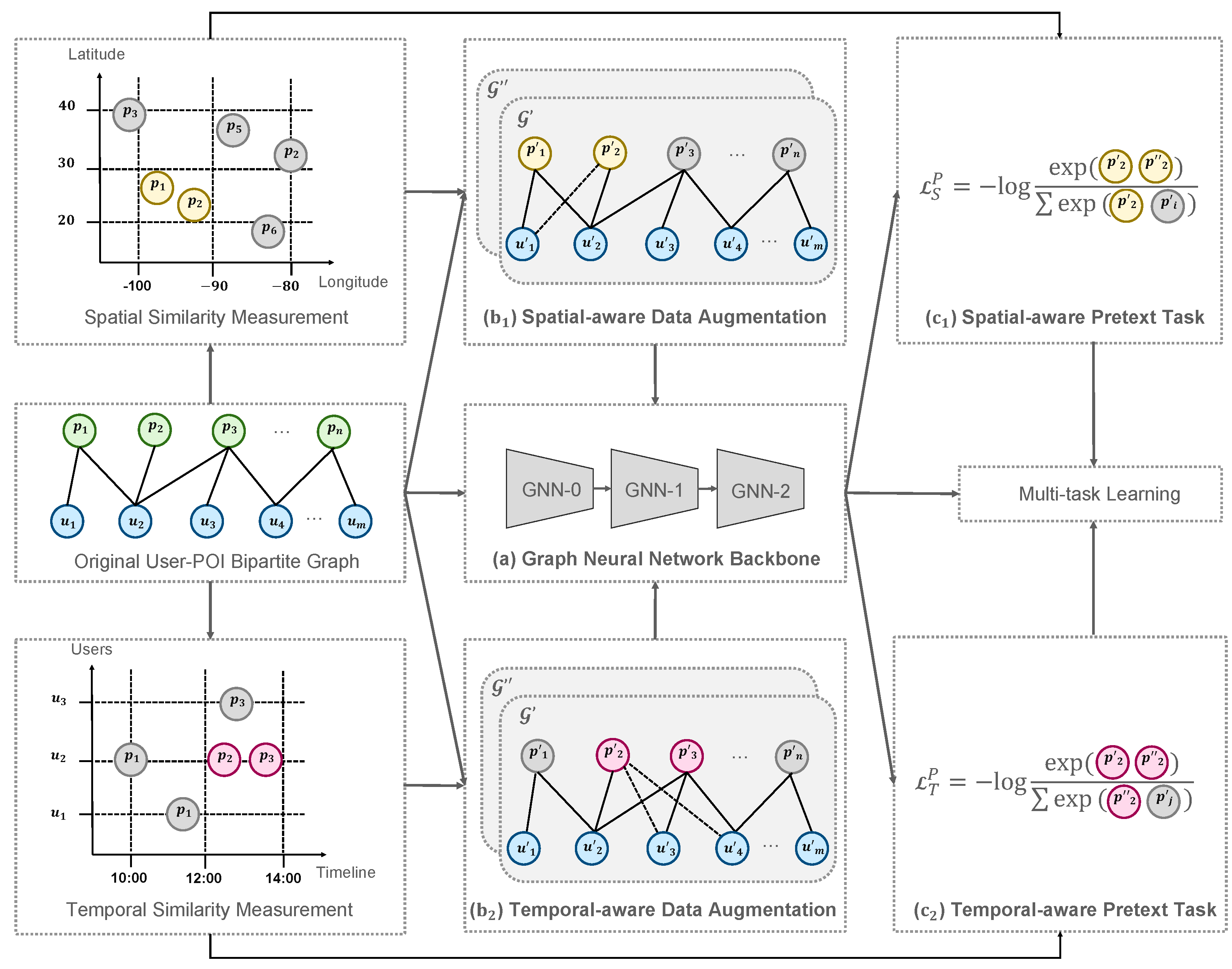
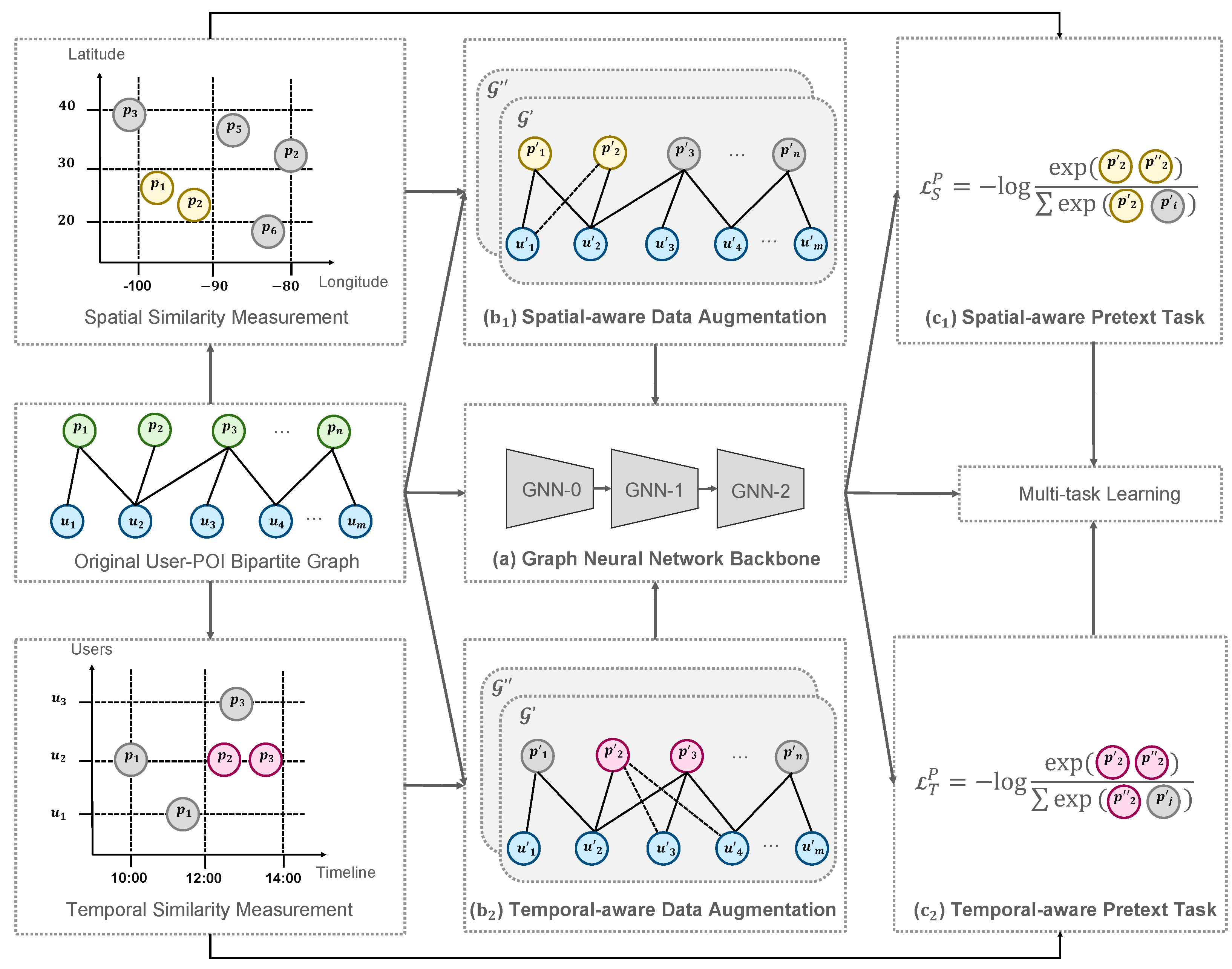
3. Methodology
3.1. Problem Definition and GNN Backbone
3.2. Spatio-Temporal-Aware Data Augmentation
- Spatial similarity matrix : when the distance between two POIs is less than a certain threshold , then the similarity of these two POIs is 1; otherwise, it is 0.
- Temporal similarity matrix : when two POIs have interacted with the same user in a period , then the similarity of these two POIs is 1; otherwise, it is 0.
- Spatial-aware edge perturbation (SEP): It adds multiple implicit edges based on the spatial similarity to the original user–POI edges:where , and are perturbation vectors that pick elements from a in some ratio and add it to b.
- Temporal-aware edge perturbation (TEP): It adds multiple implicit edges based on temporal similarity to the original user–POI edges:
3.3. Spatio-Temporal-Aware Pre-Text Task
- Spatial-aware pre-text task (SPT): We took nodes with the highest spatial similarity in to the target node as positive examples and nodes with the lowest spatial similarity as negative examples.
- Temporal-aware pre-text task (TPT): We took nodes with the highest temporal similarity in to the target node as positive examples and nodes with the lowest temporal similarity as negative examples.
- Spatial-aware contrastive learning (SCL): Maximizes the MI between spatial-aware positive POI pairs and minimizes the MI between spatial-aware negative POI pairs:where is a similarity measure function, which is set as a dot product; is the temperature in softmax; and and represent different embeddings obtained from data augmentation.
- Temporal-aware contrastive learning (TCL): Maximizes the MI between temporal-aware positive POI pairs and minimizes the MI between temporal-aware negative POI pairs.
3.4. Model Training
3.5. Complexity Analyses of SSTGL
| Algorithm 1 The framework of SSTGL |
| Require:
Given the original user-POI graph , the layer L of GNN model.
Ensure: The similarity scores .
|
4. Experiments
- RQ1: How does the proposed SSTGL method perform when compared with the start-of-the-art baselines?
- RQ2: How does each component of the SSTGL contribute to the overall performance?
- RQ3: How do different hyper-parameters influence the performance of SSTGL?
4.1. Experimental Setup
4.1.1. Datasets
- Foursquare [19]: The Foursquare dataset consists of check-in data generated on Foursquare from April 2012 to September 2013. Following [19], we removed users with less than 10 interactions and POIs with less than 10 interactions. After preprocessing, it contained 1,196,248 check-ins between 24,941 users and 28,593 POIs.
- Gowalla [19]: The Gowalla dataset consists of check-in data generated on Gowalla from February 2009 to October 2010. As was done in [19], we removed users with less than 15 interactions and POIs with less than 10 interactions. After preprocessing, it contained 1,278,274 check-ins between 18,737 users and 32,510 POIs.
- Meituan “https://www.biendata.xyz/competition/smp2021_1/ (accessed on 28 July 2023)”: The Meituan dataset consists of check-in data generated on the Meituan APP from 1st March 2021 to 28th March 2021. We removed users with less than 10 interactions and POIs without location information. After preprocessing, it contained 602,331 check-ins between 38,904 users and 3182 POIs.
4.1.2. Baselines
- NeuMF [20]: NeuMF is a classical MF-based model that combines matrix factorization and multi-layer perceptron to learn both low-dimensional and high-dimensional embeddings.
- NGCF [21]: NGCF is a GNN-based model capturing high-order information through message passing and aggregation.
- DGCF [22]: DGCF is a GNN-based model, which models different relationships and separates user intents in the representation.
- LightGCN [23]: LightGCN is a GNN-based recommendation model, which simplifies the aggregation step by deleting the weight matrix and activation function.
- SGL [12]: SGL is a graph-based self-supervised method that proposes three data augmentation strategies based on the graph structure.
- NCL [13]: NCL is a graph-based contrastive learning method that improves neural graph collaborative filtering by considering structural and semantic neighbors.
- LGLMF [3]: LGLMF is an MF-based POI recommendation model, which combines logistic matrix factorization with a region-based geographical model.
- STACP [5]: STACP is also an MF-based POI recommendation model, which combines matrix factorization with a spatio-temporal activity-centers algorithm.
- GPR [9]: GPR is a GNN-based model designed for POI recommendation that uses an extra POI–POI graph to learn item embeddings and improve performance.
- MPGRec [24]: MPGRec is the newest GNN-based POI recommendation model, which uses a dynamic memory module to store global information for spatial consistency.
4.1.3. Evaluation Metrics
4.1.4. Implementation Details
4.2. Performance Comparison (RQ1)
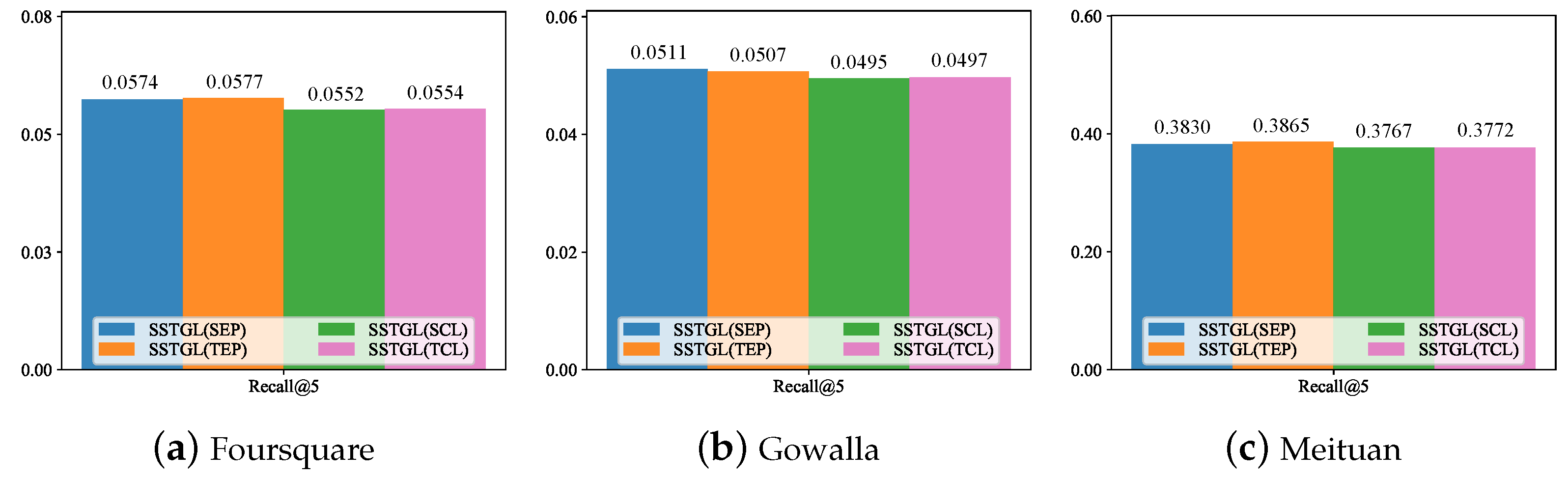
- SSTGL(SEP): uses spatial-aware edge perturbation and non-spatio-temporal pre-text tasks.
- SSTGL(TEP): uses temporal-aware edge perturbation and non-spatio-temporal pre-text task.
- SSTGL(SCL): uses spatial-aware contrastive learning and non-spatio-temporal data augmentation.
- SSTGL(TCL): use temporal-aware contrastive learning and non-spatio-temporal data augmentation.
- SSTGL outperformed all baseline methods in most cases. In particular, the relative improvements from the strongest baselines were 6.32% (Foursquare), 13.27% (Gowalla), and 9.68% (Meituan) using the Recall@50 metric. Note that SSTGL not only worked better than the existing POI recommendation methods, but also better than the existing self-supervised graph learning methods. This demonstrates the ability of our model to use self-supervised learning to alleviate the data sparsity problem in the POI recommendation task. Although MPGRec performed better in some cases, it relies on a dynamic memory module, which requires a large memory overhead.
- For the baseline models, the GNN models did not always outperform the MF models, which was related to the datasets and model architectures. For example, we found that the NeuMF model performed better than some GNN-based methods for the Meituan dataset. This may be due to the low sparsity of the Meituan dataset and the more personalized interests of the users in the take-out scenario, so aggregating higher-order neighborhood information would instead reduce the performance.
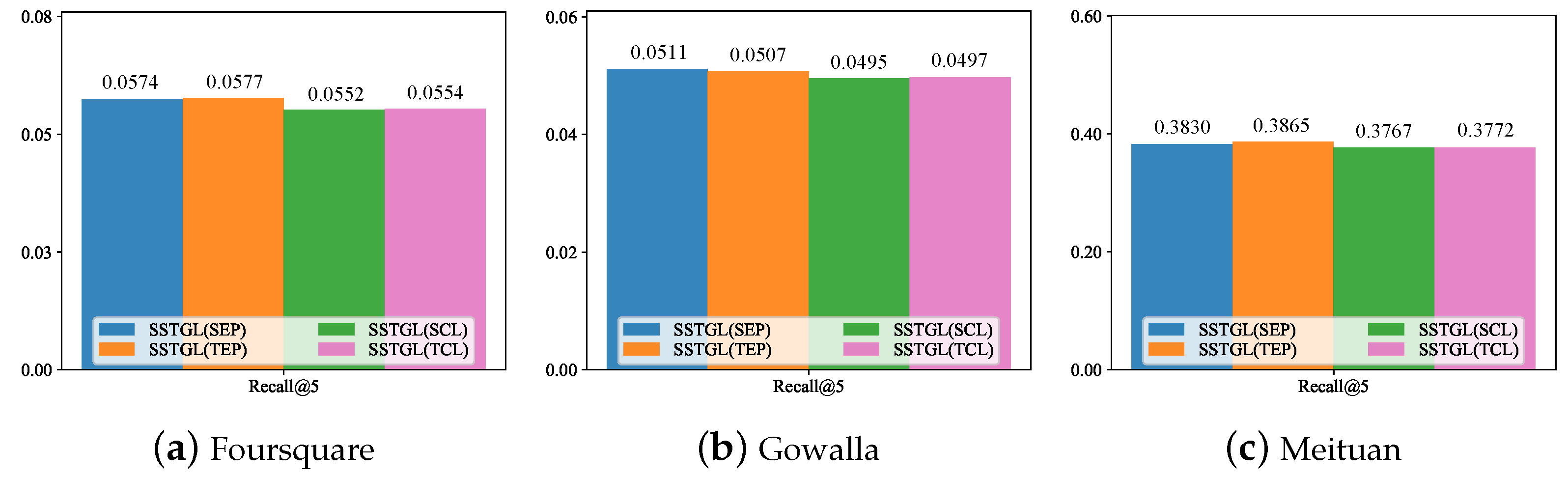
4.3. Ablation Study (RQ2)
- In the strategies we designed, the temporal-based approaches (i.e., TEP and TCL) worked better on the Foursquare and Gowalla datasets, and the spatial-aware approaches (i.e., SEP and SCL) performed better on the Meituan dataset. This may indicate that the spatial factor has a greater influence on the Meituan dataset compared with other datasets.
- Although both consider spatio-temporal information, the data augmentation-based approach outperformed the pre-text-task-based approach. This may be due to the direct modification of the graph structure using the self-supervised method of data augmentation, which allows the node representation of the GNN output to make better use of spatio-temporal prior knowledge.
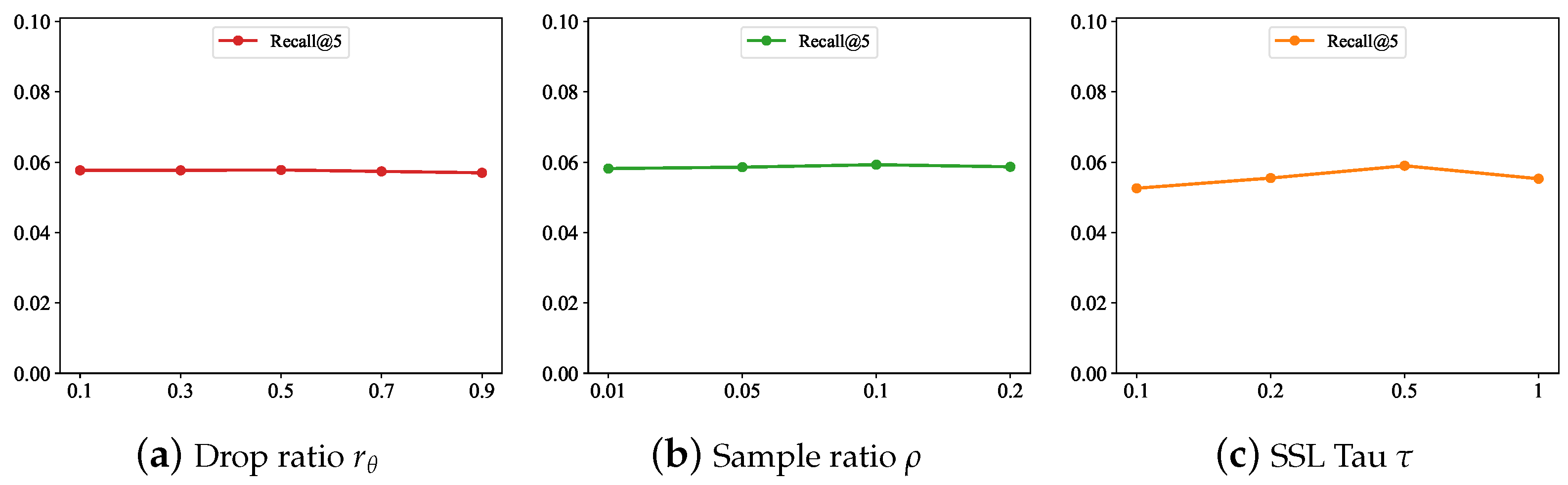
4.4. Influence of Hyper-Parameters (RQ3)
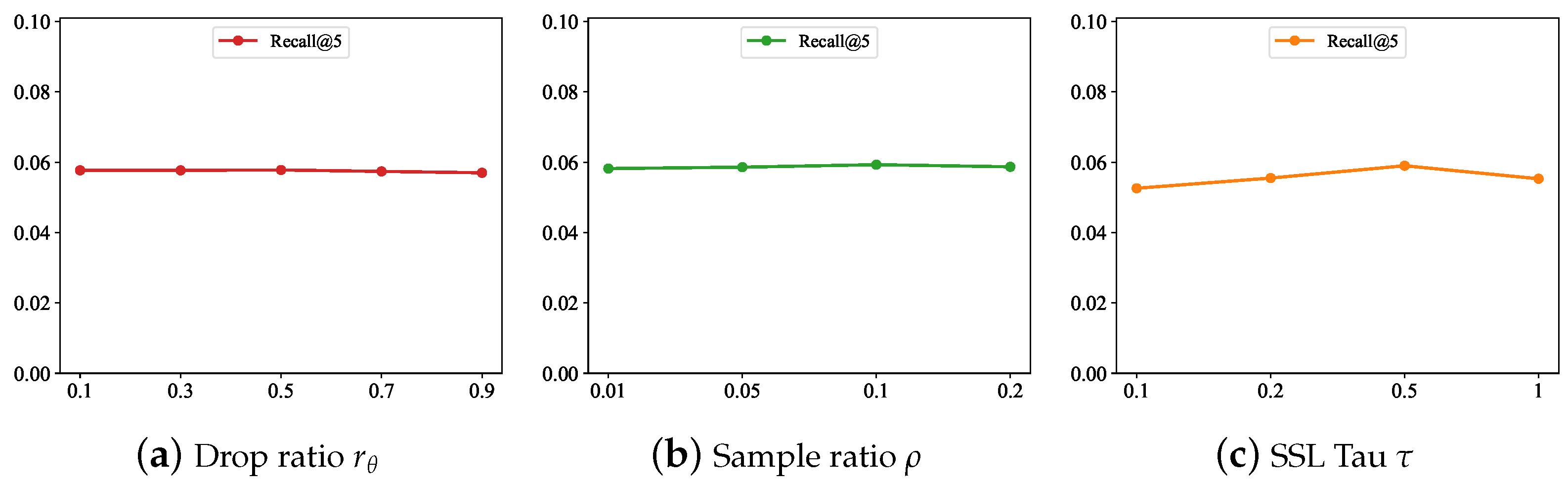
- Overall, the different drop ratio and sample ratio had little effect on the model results, which indicates the robustness of the model.
- Too large or too small SSL temperature values reduced the performance. This observation is consistent with the previous work [12]. The possible reason behind this is that, if the temperature is large, it is more difficult to distinguish negative examples. If the temperature is small, only a small number of negative cases affect the optimization.
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Werneck, H.; Silva, N.; Viana, M.; Pereira, A.C.; Mourão, F.; Rocha, L. Points of interest recommendations: Methods, evaluation, and future directions. Inf. Syst. 2021, 101, 101789. [Google Scholar] [CrossRef]
- Gao, H.; Tang, J.; Hu, X.; Liu, H. Exploring temporal effects for location recommendation on location-based social networks. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013. [Google Scholar]
- Rahmani, H.A.; Aliannejadi, M.; Ahmadian, S.; Baratchi, M.; Afsharchi, M.; Crestani, F. LGLMF: Local geographical based logistic matrix factorization model for POI recommendation. In Proceedings of the Asia Information Retrieval Symposium, Hong Kong, China, 7–9 November 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 66–78. [Google Scholar]
- Liu, Y.; Wei, W.; Sun, A.; Miao, C. Exploiting geographical neighborhood characteristics for location recommendation. In Proceedings of the 23rd ACM International Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014. [Google Scholar]
- Rahmani, H.A.; Aliannejadi, M.; Baratchi, M.; Crestani, F. Joint geographical and temporal modeling based on matrix factorization for point-of-interest recommendation. In Proceedings of the European Conference on Information Retrieval, Lisbon, Portugal, 14–17 April 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 205–219. [Google Scholar]
- Xie, M.; Yin, H.; Wang, H.; Xu, F.; Chen, W.; Wang, S. Learning graph-based poi embedding for location-based recommendation. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016. [Google Scholar]
- Yang, D.; Qu, B.; Yang, J.; Cudre-Mauroux, P. Revisiting user mobility and social relationships in lbsns: A hypergraph embedding approach. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Qian, T.; Liu, B.; Nguyen, Q.V.H.; Yin, H. Spatiotemporal representation learning for translation-based POI recommendation. ACM Trans. Inf. Syst. 2019, 37, 18. [Google Scholar] [CrossRef]
- Chang, B.; Jang, G.; Kim, S.; Kang, J. Learning graph-based geographical latent representation for point-of-interest recommendation. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020. [Google Scholar]
- Zhong, T.; Zhang, S.; Zhou, F.; Zhang, K.; Trajcevski, G.; Wu, J. Hybrid graph convolutional networks with multi-head attention for location recommendation. World Wide Web 2020, 23, 3125–3151. [Google Scholar] [CrossRef]
- Li, Z.; Cheng, W.; Xiao, H.; Yu, W.; Chen, H.; Wang, W. You Are What and Where You Are: Graph Enhanced Attention Network for Explainable POI Recommendation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual, 1–5 November 2021; pp. 3945–3954. [Google Scholar]
- Wu, J.; Wang, X.; Feng, F.; He, X.; Chen, L.; Lian, J.; Xie, X. Self-supervised graph learning for recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; pp. 726–735. [Google Scholar]
- Lin, Z.; Tian, C.; Hou, Y.; Zhao, W.X. Improving Graph Collaborative Filtering with Neighborhood-enriched Contrastive Learning. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022. [Google Scholar]
- Yu, J.; Yin, H.; Li, J.; Wang, Q.; Hung, N.Q.V.; Zhang, X. Self-supervised multi-channel hypergraph convolutional network for social recommendation. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 413–424. [Google Scholar]
- Xia, X.; Yin, H.; Yu, J.; Wang, Q.; Cui, L.; Zhang, X. Self-supervised hypergraph convolutional networks for session-based recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Han, H.; Zhang, M.; Hou, M.; Zhang, F.; Wang, Z.; Chen, E.; Wang, H.; Ma, J.; Liu, Q. STGCN: A spatial-temporal aware graph learning method for POI recommendation. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020. [Google Scholar]
- Liu, Y.; Pham, T.A.N.; Cong, G.; Yuan, Q. An experimental evaluation of point-of-interest recommendation in location-based social networks. Proc. VLDB Endow. 2017, 10, 1010–1021. [Google Scholar] [CrossRef]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.S. Neural graph collaborative filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019. [Google Scholar]
- Wang, X.; Jin, H.; Zhang, A.; He, X.; Xu, T.; Chua, T.S. Disentangled graph collaborative filtering. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 1001–1010. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020. [Google Scholar]
- Yang, T.; Gao, H.; Yang, C.; Shi, C.; Xie, Q.; Wang, X.; Wang, D. Memory-Enhanced Period-Aware Graph Neural Network for General POI Recommendation. In Proceedings of the International Conference on Database Systems for Advanced Applications, Tianjin, China, 17–20 April 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 462–472. [Google Scholar]
- Acharya, M.; Yadav, S.; Mohbey, K.K. How can we create a recommender system for tourism? A location centric spatial binning-based methodology using social networks. Int. J. Inf. Manag. Data Insights 2023, 3, 100161. [Google Scholar] [CrossRef]
- Acharya, M.; Mohbey, K.K. Differential Privacy-Based Social Network Detection Over Spatio-Temporal Proximity for Secure POI Recommendation. SN Comput. Sci. 2023, 4, 252. [Google Scholar] [CrossRef]
- Lim, N.; Hooi, B.; Ng, S.K.; Wang, X.; Goh, Y.L.; Weng, R.; Varadarajan, J. STP-UDGAT: Spatial-temporal-preference user dimensional graph attention network for next POI recommendation. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Online, 19–23 October 2020. [Google Scholar]
- Li, Y.; Chen, T.; Yin, H.; Huang, Z. Discovering collaborative signals for next POI recommendation with iterative Seq2Graph augmentation. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI-21), Virtual, 19–26 August 2021. [Google Scholar]
- Zhou, F.; Wang, P.; Xu, X.; Tai, W.; Trajcevski, G. Contrastive trajectory learning for tour recommendation. In ACM Transactions on Intelligent Systems and Technology (TIST); Association for Computing Machinery: New York, NY, USA, 2021. [Google Scholar]
- Zhao, W.X.; Mu, S.; Hou, Y.; Lin, Z.; Chen, Y.; Pan, X.; Li, K.; Lu, Y.; Wang, H.; Tian, C.; et al. Recbole: Towards a unified, comprehensive and efficient framework for recommendation algorithms. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Online, 1–5 November 2021. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, Diego, CA, USA, 7–9 May 2015. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Dataset | #Check-Ins | #POI | #User | Sparsity | Time Span |
|---|---|---|---|---|---|
| Foursquare | 1,196,248 | 28,593 | 24,941 | 99.90% | April 2012–September 2013 |
| Gowalla | 1,278,274 | 32,510 | 18,737 | 99.87% | February 2009–October 2010 |
| Meituan | 602,331 | 3182 | 38,904 | 99.51% | 1st March 2021–28th March 2021 |
| MF-Based | GNN-Based | GNN and SSL-Based | |
|---|---|---|---|
| ST-unaware | NeuMF [20] | NGCF [21], DGCF [22], LightGCN [23] | SGL [12], NCL [13] |
| ST-aware | LGLMF [3], STACP [5] | GPR [9], MPGRec [24] | SSTGL(Ours) |
| Model | Recall@5 | Recall@10 | Recall@20 | Recall@50 | MAP@5 | MAP@10 | MAP@20 | MAP@50 |
|---|---|---|---|---|---|---|---|---|
| NeuMF | 0.0368 | 0.0610 | 0.0981 | 0.1727 | 0.0235 | 0.0241 | 0.0271 | 0.0310 |
| NGCF | 0.0390 | 0.0627 | 0.0980 | 0.1688 | 0.0249 | 0.0250 | 0.0278 | 0.0314 |
| DGCF | 0.0435 | 0.0669 | 0.1028 | 0.1764 | 0.0291 | 0.0288 | 0.0316 | 0.0354 |
| LightGCN | 0.0469 | 0.0721 | 0.1076 | 0.1796 | 0.0317 | 0.0312 | 0.0341 | 0.0378 |
| SGL | 0.0452 | 0.0707 | 0.1080 | 0.1852 | 0.0300 | 0.0299 | 0.0330 | 0.0371 |
| NCL | 0.0463 | 0.0723 | 0.1083 | 0.1839 | 0.0313 | 0.0310 | 0.0338 | 0.0378 |
| STACP | 0.0274 | 0.0450 | 0.0700 | 0.1275 | 0.0187 | 0.0186 | 0.0206 | 0.0235 |
| LGLMF | 0.0284 | 0.0459 | 0.0729 | 0.1284 | 0.0192 | 0.0190 | 0.0212 | 0.0242 |
| GPR | 0.0316 | 0.0502 | 0.0763 | 0.1272 | 0.0183 | 0.0205 | 0.0224 | 0.0243 |
| MPGRec | 0.0592 | 0.0848 | 0.1200 | 0.1915 | 0.0366 | 0.0398 | 0.0425 | 0.0452 |
| SSTGL (Ours) | 0.0577 | 0.0851 | 0.1244 | 0.2036 | 0.0338 | 0.0374 | 0.0401 | 0.0427 |
| Model | Recall@5 | Recall@10 | Recall@20 | Recall@50 | Map@5 | Map@10 | Map@20 | Map@50 |
|---|---|---|---|---|---|---|---|---|
| NeuMF | 0.0302 | 0.0497 | 0.0808 | 0.1478 | 0.0227 | 0.0211 | 0.0231 | 0.0267 |
| NGCF | 0.0308 | 0.0500 | 0.0810 | 0.1458 | 0.0235 | 0.0216 | 0.0234 | 0.0268 |
| DGCF | 0.0332 | 0.0530 | 0.0834 | 0.1477 | 0.0266 | 0.0239 | 0.0254 | 0.0288 |
| LightGCN | 0.0352 | 0.0564 | 0.0897 | 0.1593 | 0.0271 | 0.0247 | 0.0267 | 0.0305 |
| SGL | 0.0338 | 0.0557 | 0.0911 | 0.1657 | 0.0259 | 0.0240 | 0.0262 | 0.0305 |
| NCL | 0.0344 | 0.0561 | 0.0902 | 0.1631 | 0.0267 | 0.0244 | 0.0264 | 0.0305 |
| STACP | 0.0176 | 0.0302 | 0.0509 | 0.0964 | 0.0142 | 0.0131 | 0.0143 | 0.0168 |
| LGLMF | 0.0241 | 0.0398 | 0.0646 | 0.1156 | 0.0209 | 0.0188 | 0.0201 | 0.0230 |
| GPR | 0.0302 | 0.0483 | 0.0766 | 0.1310 | 0.0183 | 0.0196 | 0.0216 | 0.0238 |
| MPGRec | 0.0471 | 0.0706 | 0.1050 | 0.1718 | 0.0308 | 0.0325 | 0.0349 | 0.0377 |
| SSTGL (Ours) | 0.0511 | 0.0786 | 0.1175 | 0.1946 | 0.0292 | 0.0329 | 0.0357 | 0.0383 |
| Model | Recall@5 | Recall@10 | Recall@20 | Recall@50 | MAP@5 | MAP@10 | MAP@20 | MAP@50 |
|---|---|---|---|---|---|---|---|---|
| NeuMF | 0.3540 | 0.4315 | 0.4631 | 0.5063 | 0.2339 | 0.2517 | 0.2562 | 0.2588 |
| NGCF | 0.3198 | 0.3952 | 0.4499 | 0.5177 | 0.2123 | 0.228 | 0.2349 | 0.2392 |
| DGCF | 0.3285 | 0.4046 | 0.4612 | 0.5335 | 0.2194 | 0.2353 | 0.2427 | 0.2472 |
| LightGCN | 0.3456 | 0.4221 | 0.4705 | 0.5315 | 0.2250 | 0.2417 | 0.2482 | 0.252 |
| SGL | 0.3373 | 0.4123 | 0.4674 | 0.5311 | 0.2432 | 0.2591 | 0.2664 | 0.2705 |
| NCL | 0.3466 | 0.4236 | 0.4667 | 0.5187 | 0.2222 | 0.2391 | 0.2451 | 0.2484 |
| STACP | 0.0054 | 0.0094 | 0.0203 | 0.0421 | 0.0022 | 0.0026 | 0.0034 | 0.0041 |
| LGLMF | 0.0005 | 0.0010 | 0.0030 | 0.0087 | 0.0002 | 0.0002 | 0.0004 | 0.0005 |
| GPR | 0.2984 | 0.3758 | 0.4573 | 0.5669 | 0.2066 | 0.2185 | 0.2253 | 0.2297 |
| MPGRec | 0.3930 | 0.4316 | 0.4655 | 0.5147 | 0.3170 | 0.3240 | 0.3272 | 0.3294 |
| SSTGL (Ours) | 0.3865 | 0.4388 | 0.4917 | 0.5645 | 0.3073 | 0.3146 | 0.3185 | 0.3209 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Gao, H.; Shi, C.; Cheng, H.; Xie, Q. Self-Supervised Spatio-Temporal Graph Learning for Point-of-Interest Recommendation. Appl. Sci. 2023, 13, 8885. https://doi.org/10.3390/app13158885
Liu J, Gao H, Shi C, Cheng H, Xie Q. Self-Supervised Spatio-Temporal Graph Learning for Point-of-Interest Recommendation. Applied Sciences. 2023; 13(15):8885. https://doi.org/10.3390/app13158885
Chicago/Turabian StyleLiu, Jiawei, Haihan Gao, Chuan Shi, Hongtao Cheng, and Qianlong Xie. 2023. "Self-Supervised Spatio-Temporal Graph Learning for Point-of-Interest Recommendation" Applied Sciences 13, no. 15: 8885. https://doi.org/10.3390/app13158885
APA StyleLiu, J., Gao, H., Shi, C., Cheng, H., & Xie, Q. (2023). Self-Supervised Spatio-Temporal Graph Learning for Point-of-Interest Recommendation. Applied Sciences, 13(15), 8885. https://doi.org/10.3390/app13158885