1. Introduction
Korea is one of the countries in the world with a large share of the e-commerce market. E-commerce is a familiar and common consumption pattern, with online shopping transactions accounting for more than 26% of total retail sales. In addition, the coronavirus outbreak in recent years has accelerated the expansion of the e-commerce market. According to a report published by the United Nations Conference on Trade and Development, South Korea had the largest share of e-commerce among the seven countries surveyed, growing by about 5% during the COVID-19 pandemic [
1]. As the e-commerce market has grown, so has the number of companies supporting electronic payment services. When a product is ordered and paid for online, a payment message is generated whether the payment is successful or not; however, the format and type of these messages are inconsistent. As a result, it is difficult for e-commerce companies to automatically detect the cause of payment failure or the type of failure that occurred through system information unless someone checks it each time. As artificial intelligence (AI) technology continues to evolve, the dominant approach today is to detect payment information through intelligent methods. AI technology can automatically process and analyse large amounts of payment information and make decisions quickly, providing greater efficiency and accuracy than manually reviewing payment information, and can use big data and machine learning algorithms to detect fraud and anomalous behaviour. This can effectively prevent fraud, reduce payment risk and protect user funds.
Detecting anomalies in payment information is critical to the operations of financial institutions. Traditional approaches to solving this problem require sophisticated monitoring methods and significant manpower. The most commonly used approach today is the [
2] log anomaly detection model, which is based on natural language processing techniques. The model uses part-of-speech (PoS) and named entity recognition (NER) techniques to modify the template vector using the weight vector from NER and analysing the PoS attributes of each word in the log template, thus reducing the cost of manual tagging and helping to better assign weights. Template words tagged with PoS attributes have different importance for anomaly detection. Template words with high importance in the template PoS attributes are found by NER, while template words identified as important by NER are assigned higher weights. Then, the initial template vector is multiplied by this weight vector to generate a composite template vector and fed into the DNN model to obtain the final anomaly detection results. However, this model is computationally expensive, and the log data is usually unstructured and may contain different text formats and noise, so the selection of appropriate clustering algorithms and models requires iterative experimentation and tuning. For example, if log data contains unstructured textual information and structured information such as timestamps and user IDs, a clustering algorithm must be selected that is applicable to the mixed data types. However, in practical applications, there is no universal clustering algorithm that can be adapted to all cases, so it may be necessary to try several algorithms to determine the best choice. Therefore, operations such as text cleaning, word separation, and normalization in the preprocessing stage require complex rules and algorithms to handle log data of different types and formats.
To solve the problem that different data types require different detection methods, a natural language processing-based LSTM model is proposed to detect the payment status, and an optimized LSTM model is designed to determine the current error state of the transaction information and evaluate its performance. The model can help system administrators, software developers, and cybersecurity experts to quickly detect and resolve abnormal events in payments, reduce the workload and time cost of manual processing, and improve system reliability and security. Furthermore, compared with some deep learning models, the results of LSTM models are easier to interpret and understand, and the decision process of the model can be understood by looking at its intermediate states and weights. However, it still needs to be used with caution to ensure data privacy and security, and proper monitoring and auditing to reduce false positives and protect users’ rights.
In
Section 2, we present related work and illustrate the advantages and disadvantages of the aforementioned model; in
Section 3, we describe the data collection, data labelling, and model implementation process in detail; in
Section 4, we evaluate the experimental results and verify the utility and accuracy of the model; finally, in
Section 5, we summarize the main ideas of the optimized LSTM and discuss the advantages and disadvantages of the approach, the application areas, and future research directions.
2. Related Works
The underlying models chosen for this study are SRN (simple recurrent network) [
3], LSTM (long short-term memory) [
4], and GRU (gate recurrent unit) [
5]. The SRN proposed by Elman is an recurrent neural network (RNN) with three layers, only one of which is the hidden layer, which may face the problem of gradient disappearance or gradient explosion when dealing with complex long-term dependencies, resulting in degraded model performance. In 1997, Hochreiter et al. proposed LSTM, a special type of RNN, which effectively controls information flow and memory updates through a gating mechanism, overcomes the problem of gradient disappearance and gradient explosion, can better handle long-term dependencies, and has contributed to many breakthroughs in natural language processing, such as anomaly detection [
6], text state representation [
7], multi-label document classification [
8], etc. In 2014, Junyoung Chung et al. proposed GRU, which has a simpler structure and fewer parameters, converges faster, takes less time compared to LSTM, and can speed up the iterative process.
The online payment model of e-commerce has increased the risk of online fraud. Due to the increase in fraud rate, researchers have started to use various machine learning methods to detect and analyse fraud in online transactions. Dornadula et al. proposed a novel fraud detection method [
9] for streaming transaction data with the aim of analysing the details of customers’ past transactions and extracting behavioural patterns. Cardholders are clustered into different groups based on the amount of their transactions. The transaction information of cardholders in different groups is then aggregated using a sliding window strategy to extract behavioural patterns for each group separately, using features such as maximum, minimum, and average transaction amounts. The different classifiers are then trained separately to extract the fraud characteristics, and the classifier with the better scores is selected as the best fraud prediction method. However, this method has some drawbacks. In credit card fraud detection, fraudulent transactions are usually very rare, so the dataset usually suffers from category imbalance, i.e., the number of normal transaction samples far exceeds the number of fraudulent transaction samples. This can lead to poor performance of the model in detecting fraudulent transactions. Extracting useful features from the raw transaction data is also a challenge. Proper feature selection and construction is critical to the performance of the model. Improper feature selection can result in the model failing to capture key characteristics of fraudulent transactions.
Mehbodniya et al. used various machine learning and deep learning methods to detect credit card fraud [
10], different algorithms such as naive Bayes, logistic regression, K-nearest neighbour (KNN), random forest, and sequential convolutional neural network are used to train other standard and unusual transaction features to detect credit card fraud. All algorithms go through data collection, data preprocessing, data analysis, training with different classifiers separately, and data testing before generating classifiers. In the preprocessing phase, the data are converted into a usable format using a mixture of undersampling (negative class) and oversampling (positive class) techniques. In the training phase, the preprocessed data are fed into the classifier and the test data are evaluated to assess the accuracy of fraud detection, and different models are evaluated based on accuracy and best performance. The results show that KNN performs best. However, the disadvantage of this approach is that the initialization of the weights is very random, which can affect the training process.
Fraud is dynamic and patternless, and therefore not easy to detect. Raghavan et al. tested several machine learning methods [
11], such as support vector machines (SVM), and deep learning methods, such as autoencoders, convolutional neural networks (CNN), restricted Boltzmann machines (RBM), and deep belief networks (DBN), using area under the ROC curve (AUC), Mathews correlation coefficient (MCC), and failure cost as evaluation metrics to compare different machine learning and deep learning models on different datasets to detect fraudulent transactions. The study showed that for larger datasets, the best approach to fraud detection is to use SVM and possibly combine it with CNN for a more reliable performance. For smaller datasets, the ensemble approach of SVMs, random forests, and KNNs can provide good improvements. Convolutional neural networks (CNNs) typically outperform other deep learning methods such as autoencoders, RBMs, and DBNs. However, a limitation of this study is that it only dealt with fraud detection in a supervised learning context. Although supervised learning methods such as CNN, KNN, and random forest produce good results, they do not work well in dynamic environments. Fraud patterns tend to change over time and are difficult to detect. New datasets must be collected and machine learning models must be retrained.
4. Performance Evaluation and Discussion
4.1. Performance Evaluation
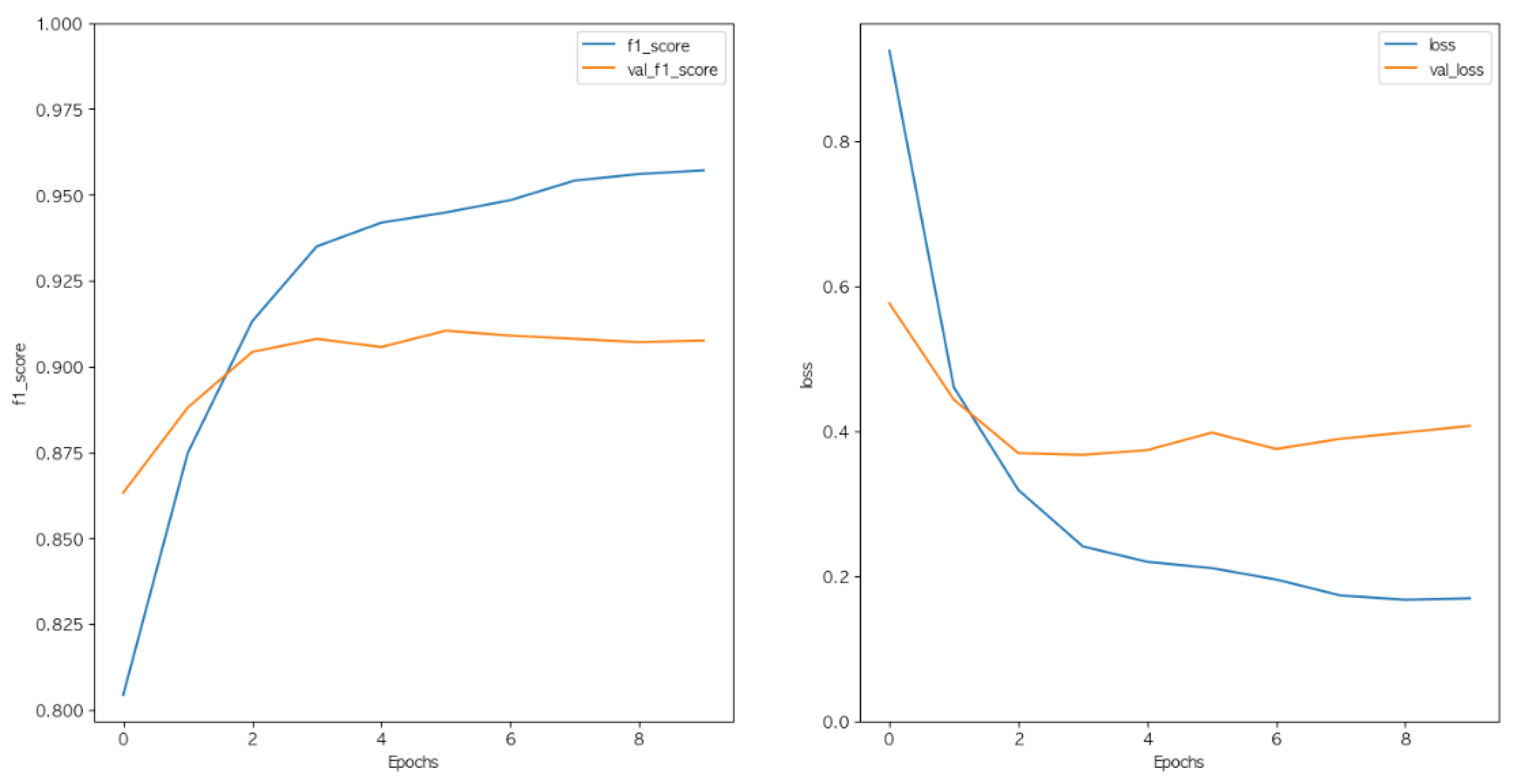
Comparing the experimental models together, there was no increase in validation F1-score or significant change in validation loss even when the learning parameters were simply increased, but there was a significant improvement in performance when the attention layer was added.
Finally, the LSTM model showed the best results after adding the attention layer to the dropout and bidirectional recursion layers and optimizing them, with a validation F1-score of 92.19% and a validation loss of 0.3433, the results are shown in
Figure 12. Compared to the basic LSTM model, both the validation F1-score and the validation loss improved, indicating that the model was improved. A comparison of this model with other methods is shown in
Table 8.
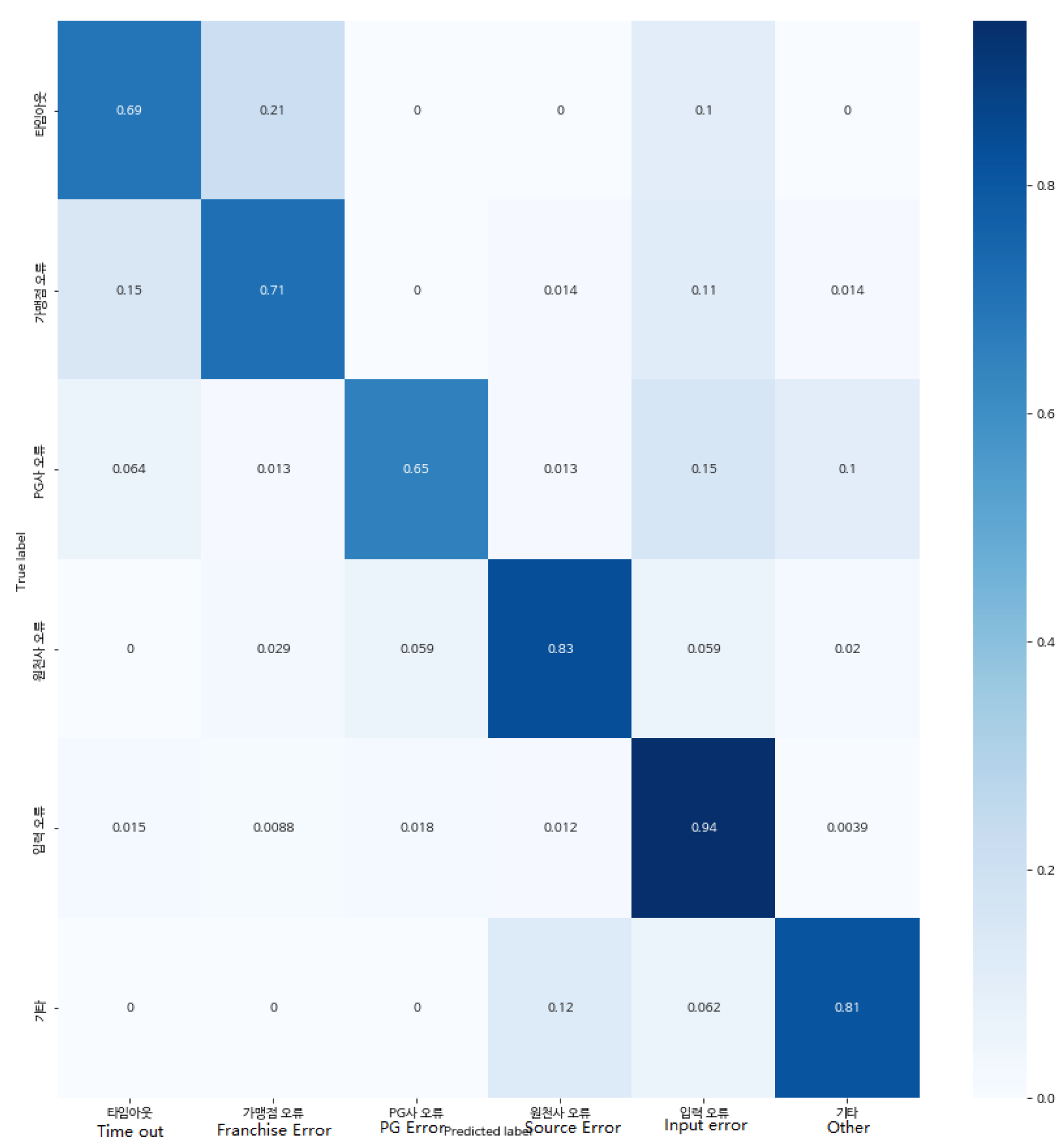
The confusion matrix of the best generated LSTM model is shown in
Figure 13. The detection of “input error” has the highest accuracy rate of 94%, followed by “merchant error for PG or financial company”, “other”, and “franchise store error for PG company”. The detection of “PG company error” has the lowest accuracy rate. This is almost of the same order as the distribution of labelled data observed earlier in
Figure 8. As the amount of data in the dataset increases, so does the accuracy of the resulting results. This also demonstrates the usability of the model, which will be more accurate in future detection tasks after training with a larger number of datasets.
The high accuracy of 92% for the F1-score is due to the use of price information provided by the financial companies in the dataset. This is information that has a conservative bias compared to other industries and is therefore largely stereotyped, refined, and has the correct sentence structure, allowing for better accuracy than is possible with general linguistic questions. We can therefore expect similar accuracy for information about other financial institutions not used in this study, and if the model were applied to payment systems for e-commerce, we could set up real-time monitoring systems to determine which payment actions are failing based on response values.
In practice, however, an error rate of 8% would have a negative impact on many users. Since most of the data used for learning is automatically tagged data, this error rate could be the result of incorrect data being included in the learning data due to a lack of validation. If humans were directly involved in the data labelling process, constructing the correct learning data and refining the method, a higher level of accuracy could be achieved.
In addition, the more data, the higher the accuracy, so if the data is obtained from fewer cases such as “timeout” or “PG error”, the accuracy of the data will be as high as 94% due to the abundance of data, and it will be possible to create a model that shows a higher level of accuracy.
4.2. Analysis of Reliability and Risks
A reliability and risk analysis based on epistemic uncertainty was performed on the model [
17,
18,
19,
20]. Uncertainty modelling was performed using Monte Carlo simulations to model the uncertainty of payment failure by randomly sampling 5000 data from the statistics of payment failure reasons to obtain a sample set of random payment failure reasons. Furthermore, the uncertainty was propagated through the model by introducing randomness into the model, such as using Gaussian noise or random initialization parameters in the LSTM layer or other layers. By introducing randomness or noise, the robustness and stability of the model under different payment failure reasons could be tested and thus the reliability of the model evaluated. The results of the risk analysis are shown in
Table 9.
Based on the given probability distribution and risk metrics, a risk index was calculated for each cause of non-payment. The risk index is derived by multiplying the probability by the risk metric and reflects the extent to which each cause contributes to the overall risk. The higher the risk index, the greater the contribution of that cause to the overall risk.
According to the model output results, the risk measure for each cause can be calculated, and then the corresponding decision strategy can be developed based on the risk measure, such as developing a different payment failure handling process or adjusting the payment security policy.
4.3. Discussion
This model can automatically process and analyse a large number of different types of payment data, reducing the effort and time required for manual processing; it can handle variable-length sequence inputs and is suitable for processing payment information text of varying lengths. Furthermore, because the LSTM model models the sequence and time dependence of the input sequence, it is robust to noise and variation in the input data, enabling faster and more accurate detection of payment problem areas.
However, the performance of the model is highly dependent on the quality of the data and the accuracy of the annotations. The accuracy of the model can be affected if there is noise or incorrect annotations in the training dataset, and the distribution of samples in the payment information detection task can be unbalanced, leading to a lower prediction accuracy for models with fewer samples and require certain strategies to deal with the data imbalance.
Privacy and security are very important considerations when processing payment information. Appropriate security measures must be taken to protect users’ payment information to avoid potential data leakage or misuse. Future research should continue to explore how to design more secure and reliable models to prevent data leakage and misuse, introduce more sophisticated LSTM variants or use other model structures to better capture the semantics and context of payment information, and further explore and develop data expansion techniques for payment information detection tasks to extend the training data and improve the robustness of the models.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}