
Sports Risk Prediction Model Based on Automatic Encoder and Convolutional Neural Network


Abstract
:1. Introduction
- (1)
- The sample size is small. The application of machine learning to the study of sports risk requires a sufficient sample size. If the sample size is small, it is easy to have problems such as difficulty obtaining data features and poor generalization ability of the model [11]. However, the research in this field has just begun, and there are still few domestic studies in this field. There are factors such as insufficient investment in project funds and manpower, a lack of a unified risk information management system in sports team management, and a poor connection between athletes’ training and the working modes of coaches and team doctors that lead to difficulties in data collection and the failure to obtain a sufficient sample size.
- (2)
- The integration of disciplines is insufficient. At present, the research in this field in China is relatively weak. Because the discipline connection is not close enough, scientific researchers with computer discipline backgrounds know very little about professional knowledge in the field of sports science, and scholars with sports discipline backgrounds cannot complete complex programming, which leads to problems such as the lack of interpretation of risk factors [12], making the development of machine learning in this field slow. Promoting the development of multidisciplinary cooperation will further promote the development of sports science and sports medicine.
- (3)
- The practical application rate is low. Using machine learning to analyze and mine the data generated in the training process of athletes can reveal the development trend of athletes’ physical functions, assist coaches and team doctors in making decisions based on data, timely adjust the intensity and capacity of training, and avoid risks [13]. However, due to the late development of research in this field and the lack of research reports, it is not possible to better combine other application technologies to generate applications and apply them to practice.
2. Overview of Relevant Theories
2.1. Concept of Sports Risk
2.2. Introduction to Relevant Algorithms and Technologies
2.2.1. Resampling Method
2.2.2. Information Gain
2.2.3. Automatic Encoder
- (1)
- Input layer
- (2)
- Encoder
- (3)
- Decoder
- (4)
- Loss calculation
- (5)
- Potential spatial representation
2.2.4. Convolution Neural Network
- (1)
- Input layer
- (2)
- Convolutional layer
- (3)
- Pooling layer
- (4)
- Fully connected layer
- (5)
- Activation function layer
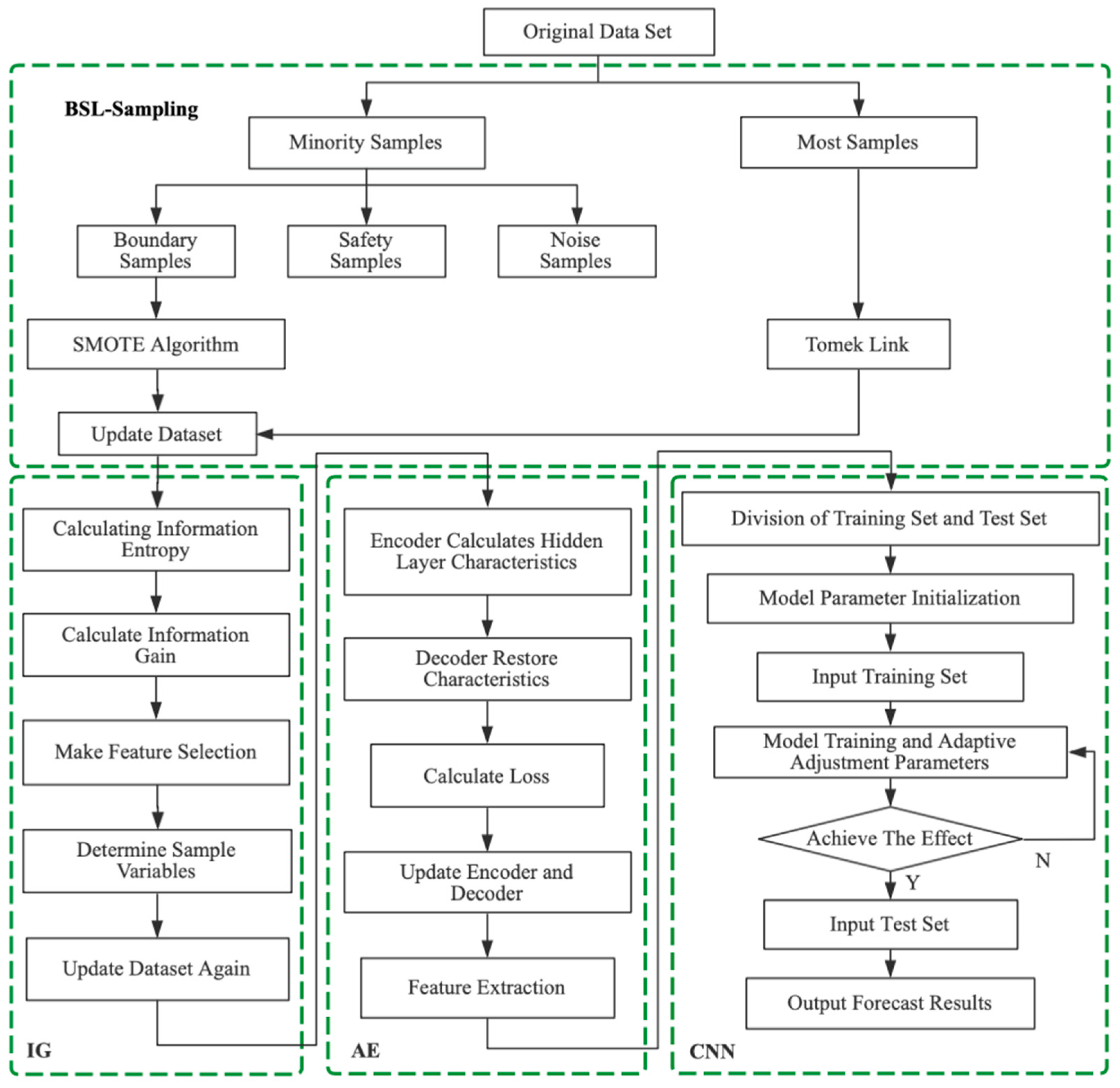
3. Sports Risk Prediction Model Based on Automatic Encoder and Convolutional Neural Network
3.1. Determination of Sports Risk Variables and Categories
3.2. Data Preprocessing
3.2.1. Feature Coding
3.2.2. Data Standardization
3.2.3. Data Set Division
3.2.4. Balanced Dataset
| Algorithm 1. BSL-Sampling | |
| Input: original sample set D, number of nearest neighbor samples K | |
| Output: new sample set | |
| Step 1 | Divide the original sample set D into training set T1 and test set T2 according to 4:1 |
| Step 2 | Calculate the Euclidean distance between each sample point of minority samples and all training samples in T1 according to , and obtain K nearest neighbor samples of this sample point |
| Step 3 | Divide a few samples. Among the K nearest neighbors, there are ≤ K) samples belonging to most categories: If = K, is defined as a noise sample; If K/2 ≤ ≤ K is defined as boundary sample; If 0 ≤ < K/2, is defined as a safety sample; The boundary samples are marked as {}, and num represents the number of minority boundary samples |
| Step 4 | Calculate the K-nearest neighbor between the boundary sample point and the minority sample , and perform linear interpolation according to the sampling ratio N and |
| Step 5 | The synthesized minority sample is combined with the original training sample T to form a new sample |
| Step 6 | Perform Tomek link data cleaning for the whole sample to complete the undersampling, delete most types of samples in the Tomek link pair, and update the training set to |
3.2.5. Feature Selection
3.3. Construction of Sports Risk Prediction Model
3.3.1. AE Model Construction
3.3.2. CNN Model Construction
3.3.3. AE-CNN Sports Risk Prediction Algorithm Flow
4. Results and Discussion
4.1. Model Evaluation Indicators
- (1)
- Accuracy (ACC)
- (2)
- Recall
- (3)
- Specificity
- (4)
- Precision
- (5)
- F1-score
4.2. Data Set Introduction
4.3. Analysis of Experimental Results
4.3.1. Sports Risk Prediction Results Based on AE-CNN
4.3.2. Comparison Experiment
5. Conclusions
- (1)
- This paper combines AE and CNN to analyze and predict the characteristics of sports risk categories. The algorithm model can effectively extract the characteristics of sports risk, analyze the risk factors, and use AE to extract the characteristics, thus completing the efficient representation of sports risk.
- (2)
- The algorithm uses CNN to realize the prediction of sports risk categories. Considering the size and characteristics of the dataset, this paper adopts the topology structure of a double convolution layer and a double pool layer to complete the CNN modeling.
- (3)
- The comparison of prediction results of different classification algorithms, that is, the verification of model evaluation indicators, shows that this model can effectively predict sports risk categories, reduce the impact of redundant data, and effectively improve the accuracy of sports risk prediction.
- (4)
- At present, the research on the application of machine learning in the field of sports risk is still in its infancy, and there are still many problems due to the great differences in various aspects of research in this field at home and abroad. The application of machine learning in the field of sports injury still has great development potential, and more research on its model algorithm and calculation is needed.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Quatman, C.E.; Quatman, C.C.; Hewett, T.E. Prediction and prevention of musculoskeletal injury: A paradigm shift in methodology. Br. J. Sport. Med. 2009, 43, 1100–1107. [Google Scholar] [CrossRef] [PubMed]
- Meeuwisse; Willem, H.; Tyreman; Hugh; Hagel; Brent. A dynamic model of etiology in sport injury: The recursive nature of risk and causation. Clin. J. Sport Med. 2007, 17, 215–219. [Google Scholar] [CrossRef]
- Talukder, H.M.; Stowell, T.B. Pneumatic hammer in an externally pressurized orifice-compensated air journal bearing. Tribol. Int. 2003, 36, 585–591. [Google Scholar] [CrossRef]
- Luu, B.C.; Wright, A.L.; Haeberle, H.S.; Karnuta, J.M.; Schickendantz, M.S.; Makhni, E.C. Machine learning outperforms logistic regression analysis to predict next season NHL player injury: An analysis of 2322 players from 2007 to 2017. Orthop. J. Sport. Med. 2020, 8. [Google Scholar] [CrossRef]
- Jauhiainen, S.; Kauppi, J.P.; Leppnen, M.; Pasanen, K.; Parkkari, J.; Vasankari, T. New machine learning approach for detection of injury risk factors in young team sport athletes. Int. J. Sport. Med. 2021, 42, 175–182. [Google Scholar] [CrossRef]
- Rossi, A.; Pappalardo, L.; Cintia, P.; Iaia, M.; Fernandez, J.; Medina, D. Effective injury forecasting in soccer with GPS training data and machine learning. PLoS ONE 2018, 13, e0201264. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, X.L.; Shi, Y.J.; Yang, H.J. A study on the prediction of injury risk of Chinese rugby players by multilayer perceptron neural network model. In Proceedings of the 11th National Sports Science Conference, Nanjing, China, 1–3 November 2019; pp. 5797–5799. [Google Scholar] [CrossRef]
- Rommers, N.; Roland, R.; Verhagen, E.; Vandecasteele, F.; Verstockt, S.; Vaeyens, R. A machine learning approach to assess injury risk in elite youth football players. Med. Sci. Sport. Exerc. 2020, 8, 1. [Google Scholar] [CrossRef]
- Orlando, A. AI for Sport in the EU Legal Framework. In Proceedings of the 2022 IEEE International Workshop on Sport, Technology and Research (STAR), Cavalese, Italy, 6–8 July 2022; pp. 100–105. [Google Scholar] [CrossRef]
- McManus, K.; Greene, B.R.; Ader, L.G.M.; Caulfield, B. Development of Data-Driven Metrics for Balance Impairment and Fall Risk Assessment in Older Adults. IEEE Trans. Biomed. Eng. 2022, 69, 2324–2332. [Google Scholar] [CrossRef]
- Ruddy, J.D.; Shield, A.J.; Maniar, N.; Williams, M.D.; Duhig, S.; Timmins, R.G.; Hickey, J.; Bourne, M.N.; Opar, D.A. Predictive modeling of hamstring strain injuries in elite Australian footballers. Med. Sci. Sport. Exerc. 2018, 50, 906–914. [Google Scholar] [CrossRef] [Green Version]
- Ayala, F.; López-Valenciano, A.; Gámez Martín, J.A.; Mark, D.S.C.; Vera-Garcia, F.; García-Vaquero, M. A preventive model for hamstring injuries in professional soccer: Learning Algorithms. Int. J. Sport. Med. 2019, 40, 344. [Google Scholar] [CrossRef] [PubMed]
- Claudino, J.G.; Capanema, D.D.O.; Souza, T.V.D.; Julio, C.S.; Nassis, G.P. Current approaches to the use of artificial intelligence for injury risk assessment and performance prediction in team sports: A systematic review. Sport. Med. 2019, 5, 28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, C.; Zhou, T.; Guo, Q.; Cui, H.L. Compressive Beamforming Based on Multiconstraint Bayesian Framework. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9209–9223. [Google Scholar] [CrossRef]
- Ciprian, C.; Masychev, K.; Ravan, M.; Reilly, J.P.; Maccrimmon, D. A Machine Learning Approach Using Effective Connectivity to Predict Response to Clozapine Treatment. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 2598–2607. [Google Scholar] [CrossRef]
- Berta, M.; Renes, J.M.; Wilde, M.M. Identifying the Information Gain of a Quantum Measurement. IEEE Trans. Inf. Theory 2014, 60, 7987–8006. [Google Scholar] [CrossRef] [Green Version]
- Gao, H.; Zhang, X.; Wen, J.; Yuan, J.; Fang, Y. Autonomous Indoor Exploration via Polygon Map Construction and Graph-Based SLAM Using Directional Endpoint Features. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1531–1542. [Google Scholar] [CrossRef]
- Si, W.; Fu, C.; Yuan, P. An Integrated Sensor with AE and UHF Methods for Partial Discharges Detection in Transformers Based on Oil Valve. IEEE Sens. Lett. 2019, 3, 1–3. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, S.; Kim, W.; Park, J.; Cho, S.H. Radar-Based Air-Writing Gesture Recognition Using a Novel Multistream CNN Approach. IEEE Internet Things J. 2022, 9, 23869–23880. [Google Scholar] [CrossRef]
- Karlsson, K.; Hendeby, G. Speed estimation from vibrations using a deep learning CNN approach. IEEE Sens. Lett. 2021, 5, 1–4. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Huang, Y.Q.; Li, Y.R.; Gui, Y.H. Machine learning: A new way to prevent sports injury. Fujian Sport. Sci. Technol. 2021, 40, 12–18. [Google Scholar]
- Zhang, Y.; Luo, L. Thoughts on the classification system of sports risk. J. Sport. Adult Educ. 2012, 28, 20–21. [Google Scholar] [CrossRef]
- Blanch, P.; Gabbett, T.J. Has the athlete trained enough to return to play safely? The acute:chronic workload ratio permits clinicians to quantify a player’s risk of subsequent injury. Br. J. Sport. Med. 2016, 50, 471–475. [Google Scholar] [CrossRef] [PubMed]
- Yza, B.; Sl, A.; Tx, C.; Tao, W.C. Application of convolutional neural network in random structural damage identification. Structures 2021, 29, 570–576. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Risk Factor | Characteristic Name | Characteristic Range |
|---|---|---|
| Personal factors | Sex | {male, female} |
| Age | 11–95 | |
| Height | 140 cm–190 cm | |
| Weight | 37.8 kg–86.4 kg | |
| Shape | {Y-type, H-type, S-type, A-type} | |
| Medical history | {hypertension, hyperlipidemia, diabetes, coronary heart disease, cardiomyopathy, chronic atrial fibrillation, chronic heart failure, chronic kidney disease, nephrotic syndrome, chronic glomerulonephritis, tuberculosis, asthma, chronic obstructive pulmonary disease, chronic viral hepatitis, cirrhosis, peptic ulcer, rheumatoid arthritis, hypothyroidism, schizophrenia} | |
| BMI | {≤18.5, [18.5,23.9], [24,27], [28,32], >32} | |
| Whether cognitive impairment | {Yes, no} | |
| Sport state | {pleasure, relaxation, fatigue, tension, tiredness, excitement, disgust} | |
| Sleep quality | {poor, average, normal, good, very good} | |
| Whether to drink | {Yes, no} | |
| Whether to smoke | {Yes, no} | |
| Whether the diet is regular | {Yes, no} | |
| Vision | {normal, myopia, hyperopia, amblyopia} | |
| Exercise prescription factors | Sports event | {running, swimming, climbing stairs, cycling, skipping, basketball, football, volleyball, badminton, tennis, table tennis, gymnastics, mountain climbing, others} |
| Sports time | {0~0.5, 0.5~1, 1~1.5, 1.5~2, 2~2.5, 2.5~3, >3} | |
| Sports frequency | {1, 2, 3, 4, 5, 6, 7} | |
| Sports intensity | {ultra-low strength, low strength, medium strength, high strength, ultra-high strength} | |
| Sports ability factors | Endurance | {poor, relatively poor, average, relatively strong, strong} |
| Power | {weak, poor, relatively poor, average, normal, good} | |
| Flexibility | {very poor, poor, medium, good, excellent, super excellent} | |
| Balance | {poor, relatively poor, medium, good, excellent} | |
| External factors | Sports ground | {gymnasium, park, gym, campus, home, community, others} |
| Sports equipment | {treadmills, dynamic bicycles, bicycles, rope skipping, basketball, football, volleyball, badminton and badminton rackets, tennis and tennis rackets, table tennis and table tennis rackets, gymnastics equipment, mountain climbing equipment, others} | |
| Weather | {wind, rain, snow, high temperature, extremely cold, cloudy, sunny, other} |
| Sports Risk Category | Label |
|---|---|
| Muscle contusion | 1 |
| Falls | 2 |
| Dyspnea | 3 |
| Arrhythmia | 4 |
| Shock | 5 |
| Sudden death | 6 |
| Methods | ACC | Recall | Specificity | F1-Score | Precision |
|---|---|---|---|---|---|
| BN | 0.7837 ± 1.61 | 0.7344 ± 1.64 | 0.7956 ± 1.48 | 0.7660 ± 1.83 | 0.6973 ± 1.75 |
| KNN | 0.7581 ± 2.34 | 0.8166 ± 1.05 | 0.7836 ± 1.74 | 0.8420 ± 1.06 | 0.7562 ± 0.85 |
| SVM | 0.8327 ± 0.81 | 0.7490 ± 0.85 | 0.8864 ± 0.92 | 0.8310 ± 0.94 | 0.7817 ± 0.86 |
| MLP | 0.8763 ± 1.05 | 0.8650 ± 1.38 | 0.8800 ± 1.01 | 0.8420 ± 1.05 | 0.8084 ± 1.06 |
| AE-CNN | 0.9334 ± 0.21 | 0.9325 ± 0.26 | 0.9370 ± 0.30 | 0.9297 ± 0.19 | 0.9366 ± 0.20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Wang, L.; Jiang, Q.; Li, W.; Huang, R. Sports Risk Prediction Model Based on Automatic Encoder and Convolutional Neural Network. Appl. Sci. 2023, 13, 7839. https://doi.org/10.3390/app13137839
Li B, Wang L, Jiang Q, Li W, Huang R. Sports Risk Prediction Model Based on Automatic Encoder and Convolutional Neural Network. Applied Sciences. 2023; 13(13):7839. https://doi.org/10.3390/app13137839
Chicago/Turabian StyleLi, Bingyu, Lei Wang, Qiaoyong Jiang, Wei Li, and Rong Huang. 2023. "Sports Risk Prediction Model Based on Automatic Encoder and Convolutional Neural Network" Applied Sciences 13, no. 13: 7839. https://doi.org/10.3390/app13137839
APA StyleLi, B., Wang, L., Jiang, Q., Li, W., & Huang, R. (2023). Sports Risk Prediction Model Based on Automatic Encoder and Convolutional Neural Network. Applied Sciences, 13(13), 7839. https://doi.org/10.3390/app13137839