1. Introduction
Smart poultry progresses firmly following the industry 3.5 and 4.0 frameworks [
1,
2,
3]. The current trends in smart poultry are focused on monitoring parameters (by using various sensors) that affect egg/meat production, animal welfare, behaviour, and growth [
4,
5,
6,
7]. The objective of these observations is to increase the overall production’s quantity and quality. In addition, according to various poultry-related regulations and directives of the European Union [
8,
9,
10], the maintenance of greenhouse gases should be one of the primary tasks associated with achieving the said objective. Any successful activity with observation analysis requires systematic data acquisition and processing. This can be solved by implementing a smart poultry management system. There are various commercially available solutions (such as [
11,
12]); however, they are designed for medium and large farms, are typically expensive, and require assistance from the management of the solution providers to be successfully used.
Our previous work includes the analysis and proposal of the smart poultry farm management system’s design [
13], the development of the cyber–physical model for data acquisition and processing [
14], and the evaluation of egg production process in regard to production efficiency and greenhouse gas emissions [
15]. The cyber–physical model in this context is a three-component system: a set of sensors to obtain measurements, data exchange controllers that fulfil the role of an intermediary between sensors and data centre, and a data centre as an analytical hub with decision making capabilities. The term cyber–physical model can be used for almost any digitally and automatically driven production system [
3,
16]. Our smart poultry management system’s design focuses on decision making regarding the most appropriate feeding process while simultaneously optimising the levels of CO
2 and NH
3. The cyber–physical model was built for the proposed management system and includes three data groups—data to satisfy specific regulations, monitoring data and business-related data. In this context, data were grouped according to their sources and purposes. For example, regulations provide requirements and recommendations in the form of minimal values for environmental parameters, such as CO
2 and NH
3, whereas monitoring data encapsulates all data obtained using sensory equipment. The data of two last groups underwent complementary data fusion processing. Lastly, the implementation of the said cyber–physical model provided enough data to analyse the impact factors on the hen eggs’ production.
During the phases of the research and development of the egg production forecasting solution, the focus shifted more on evaluating and predicting egg production. Hen egg production by itself requires an in-depth understanding of the processes involved in such aspects as food formula management [
17,
18] and animal welfare condition management [
19,
20]. The egg production dynamics are typically expressed in a graphical form as a curve. According to [
21,
22,
23], the curve applied in egg production is nonlinear and represents the number of eggs laid during a specific time frame.
In general, it is considered appropriate to apply nonlinear models in order to both analyse the historical egg production data and to predict future trends. However, based on literature analysis [
4,
24,
25,
26] and our previous work, it was concluded that the development of a smart poultry management system must incorporate multiple functional interpreters based on different types of models.
In essence, these studies lead to the necessity to assess the usefulness of generally accepted nonlinear and novel machine learning (ML) models in order to (1) determine the potential level of knowledge acquired in result of their application and (2) to incorporate the appropriate models into the framework of a developed smart poultry management system.
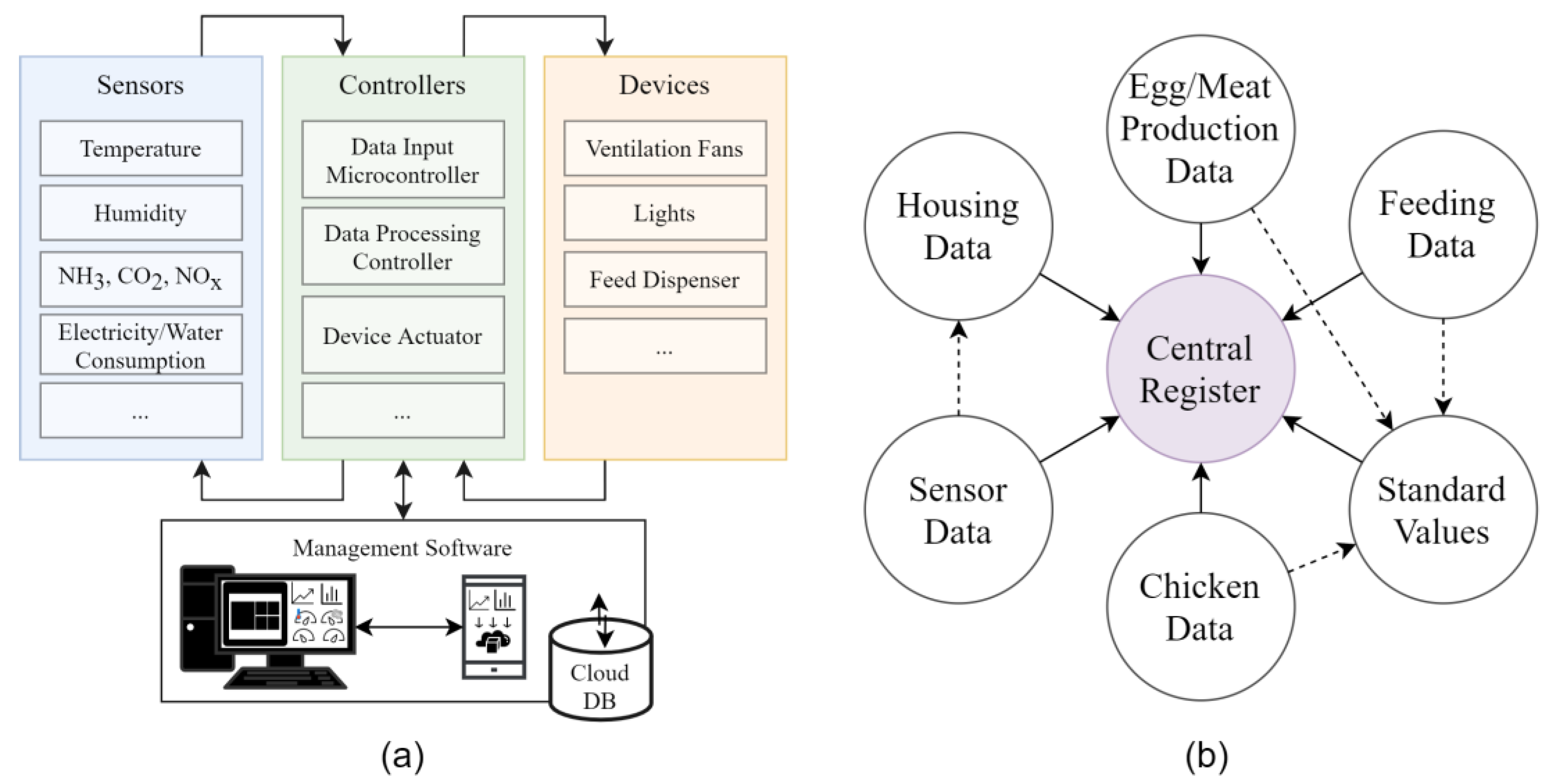
The framework itself includes: the monitoring of production-related data, a solution for data processing and analysis that incorporates adaptable database design for data storage, and a collection of models for data analysis and decision support mechanism to optimise the production processes. As stated previously—the concept of a cyber–physical model (see
Figure 1a) as a basis is built upon the idea of data fusing, whereas the result of data fusion should be used for analysis of historical data and forecasting of the following short- and long-term trends in production. However, it was found [
14] that current data fusion solutions on the market cannot be implemented into a framework as is, and, as a result, a multi-level data fusion approach must be taken. The architecture of the system, in turn, dictates the requirements for the number and types of such levels. Therefore, the smart poultry management system must use a data structure that (1) is sophisticated enough to encapsulate all possible data needs and (2) has a level of adaptability that is convenient for both management and farm owners. A previously proposed data structure [
14] has a simplified centralised design based on one single main register and various production-related satellite tables containing parameters contributing to the final result.
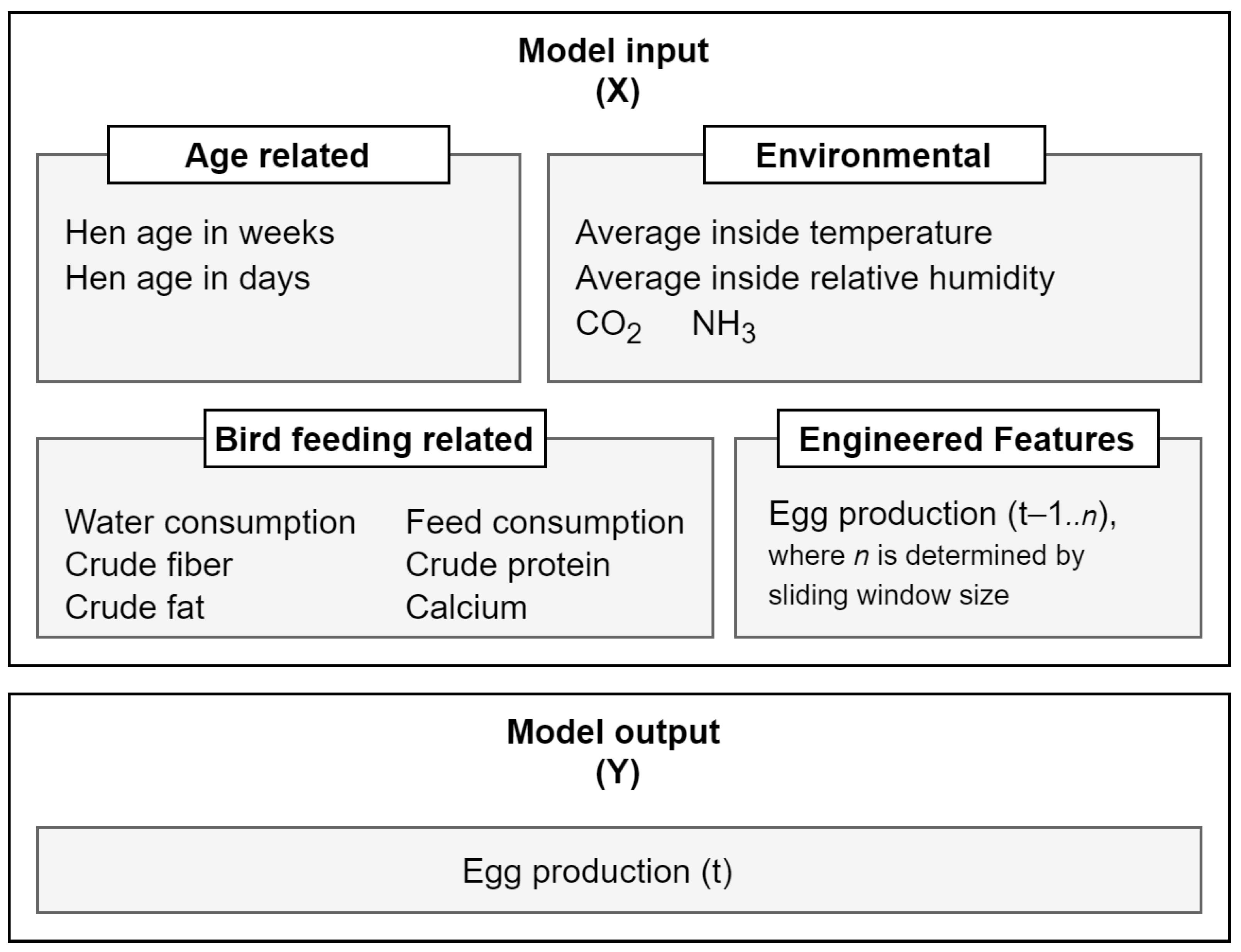
The collection of multiple models is meant to provide an appropriate choice—either algorithmic, i.e., decided by the system when the data are loaded in, or manual—by a system operator—both in order to address the cases when the number of parameters between training and testing sets differ. This also partly alleviates the issues caused by imperfect data—when one model does not provide satisfactory performance and/or output, this model can be substituted with other implemented models. This assumes that all models are trained or fitted on the same data. For the purpose of encapsulating different kinds of factors and the potential results of their processing, two main types of models are included—nonlinear models and machine learning models. These types of models are further analysed in detail using scientific literature and practical experiments with real data.
The aim of this study was to cross-compare multiple models that could be used in scenarios with limited data sets to provide forecasting of egg productivity of laying hens at a sufficient level to timely point farmers towards accurate decision making.
This paper is structured as follows: first, we provide a literature review about the methods and techniques (mostly focusing on traditional nonlinear and modern machine learning models) used in the poultry industry to forecast egg production; then we describe the data sets used for practical experiments, the selected methods for hen egg production forecasting, and the training process of the selected models; after which, we describe the metrics used for evaluation and depict the results of performance cross-comparison. Finally, we discuss the obtained results and potential improvements.
3. Results
The parameters (see
Table 6) of the Modified Compartmental model were estimated using R programming language [
51] to fit the egg production curve (1st cycle). From
Table 6, all parameters are significant (
p < 0.001, represented with three ’*’ in the last column of the table) and are applicable for this forecasting task.
The model parameters then can be filled with the estimated values (2), where the only input parameter is t, representing the number of weeks laying:
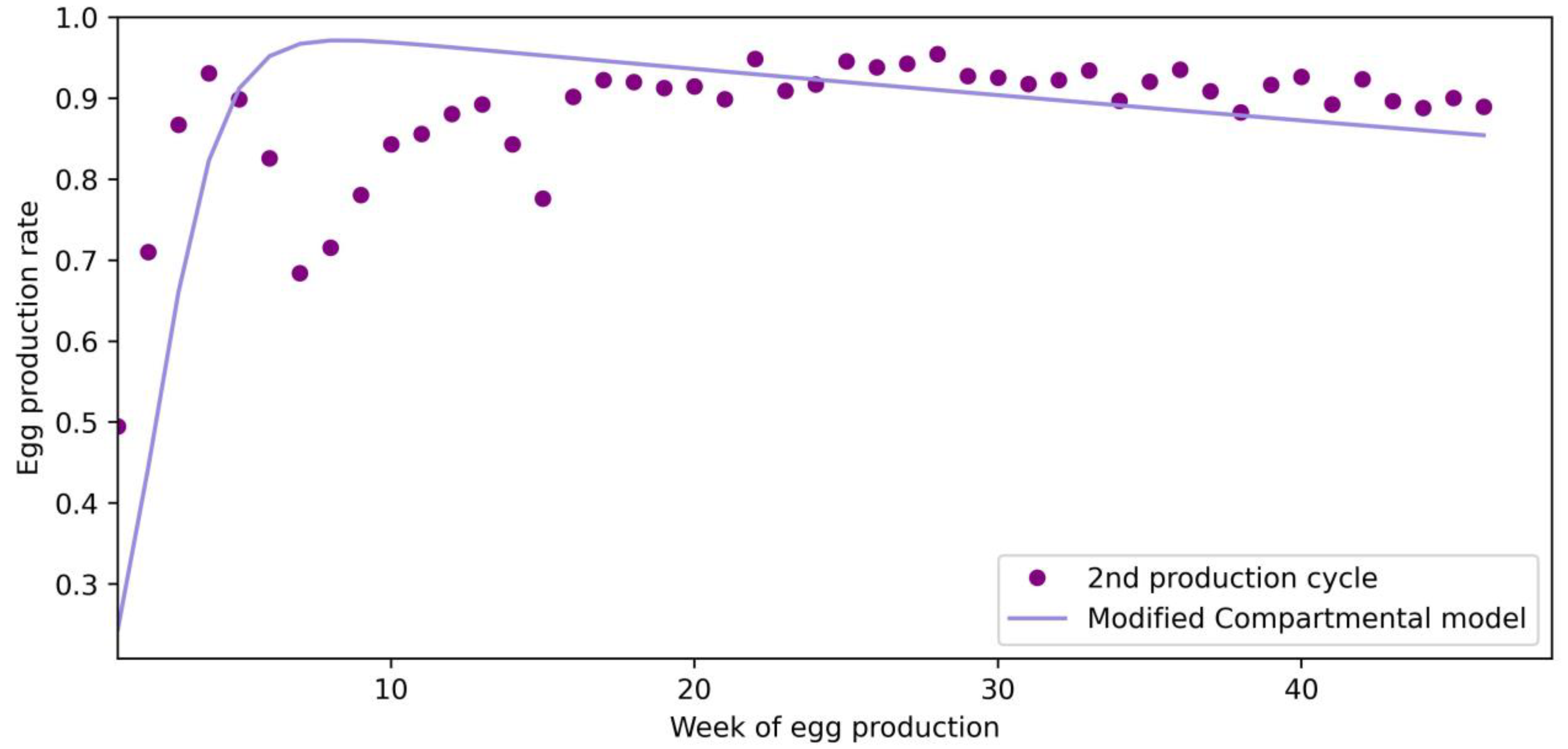
The fitted curve on the test egg production data set using the Modified Compartmental model can be seen in
Figure 5.
As
Figure 5 shows, the result of the model shows only the trend in the production rate, based on the previously trained data, but does not incorporate input values that could influence the prediction and point to potential problems. This production cycle demonstrates that it is not enough to base conclusions only on the week of egg production alone to achieve high accuracy, rather it allows the farmers to see the deviations from the trend.
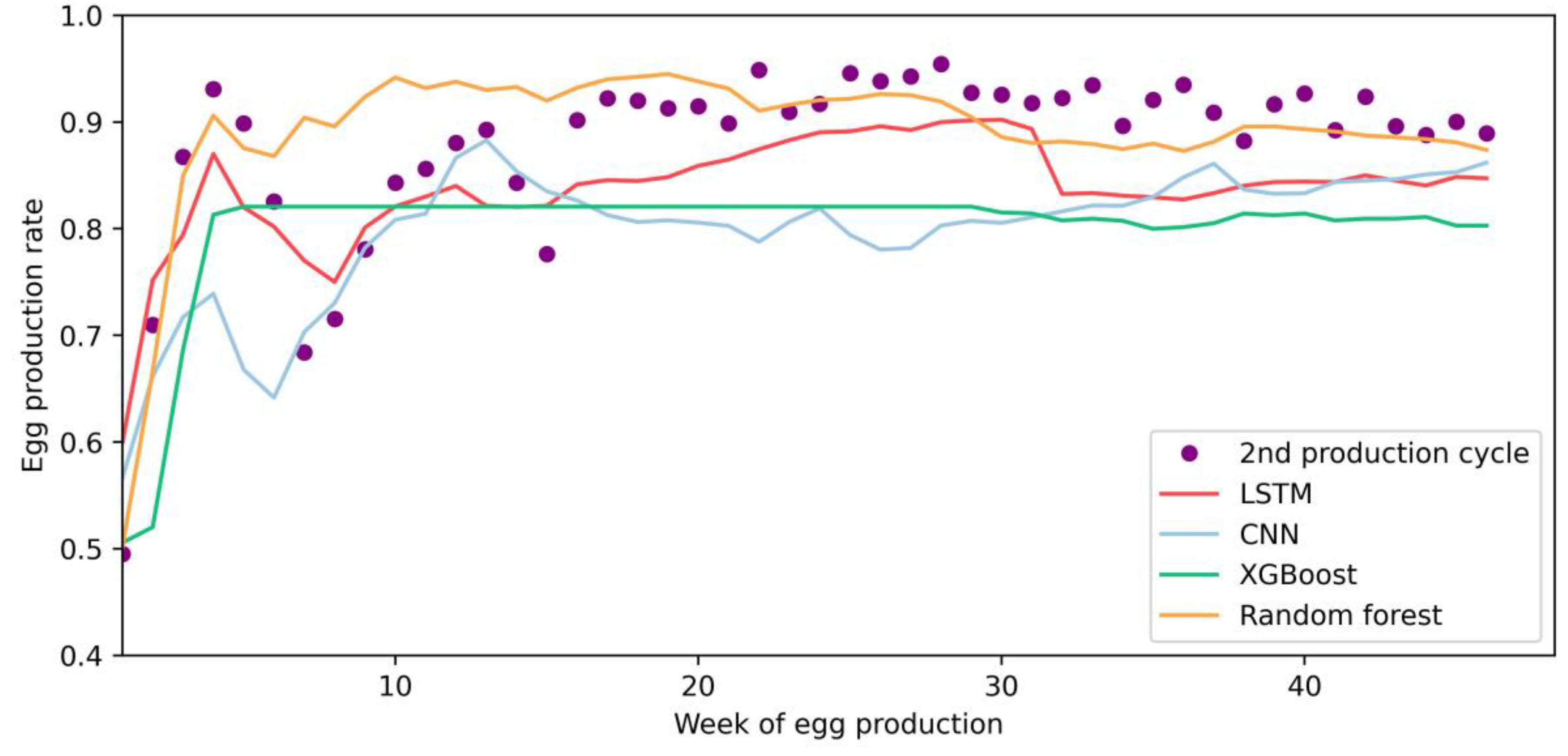
The ML model’s results and observed egg production rate with a sliding window of size two are depicted in
Figure 6.
The ML models tended to follow an abnormal decrease in production (see
Figure 6), thus indicating their ability to adjust to these kinds of situations. The possible reasons for the egg production variations in the 2nd production cycle were described in
Section 3. Although further data inspection showed that the environmental factors did not change dramatically to have an impact on production decrease, the models forecasted the drop, due to the fact that the previous day (depending on the sliding window size) production data served as inputs.
Regarding the ML models, several window sizes were tested to determine the one that provided best prediction results. The window sizes of 1, 2, 3, 5, 7, and 14 were considered. The results of model performance per different window sizes to predict egg production for the next day are presented in
Table 7. Regarding the size of the sliding window, the results showed that the LSTM performed best when using a sliding window size of two, having the smallest MAPE and RMSPE values 5.390% and 7.751%, respectively. There was also not a large difference between the models’ performances when using the window size lengths three and five, except for the CNN model that performed the worst and could be explained as potential model overfitting.
Table 8 summarizes the best results obtained from the model evaluation. We can conclude that the LSTM, RF, and XGBoost models overall showed the best performances. The results of the evaluation, taking the best metric values for different sliding window sizes (for machine learning models), showed that the performances varied. In general, all models provided accurate enough results to detect problems and make changes in the production process; however, the results suggested that some models, LSTM for instance, showed a competitive performance across all sliding window sizes while having the best results when using a smaller number of historical production data. It could be concluded that machine learning models, especially LSTM, proved to be better than Modified Compartmental.
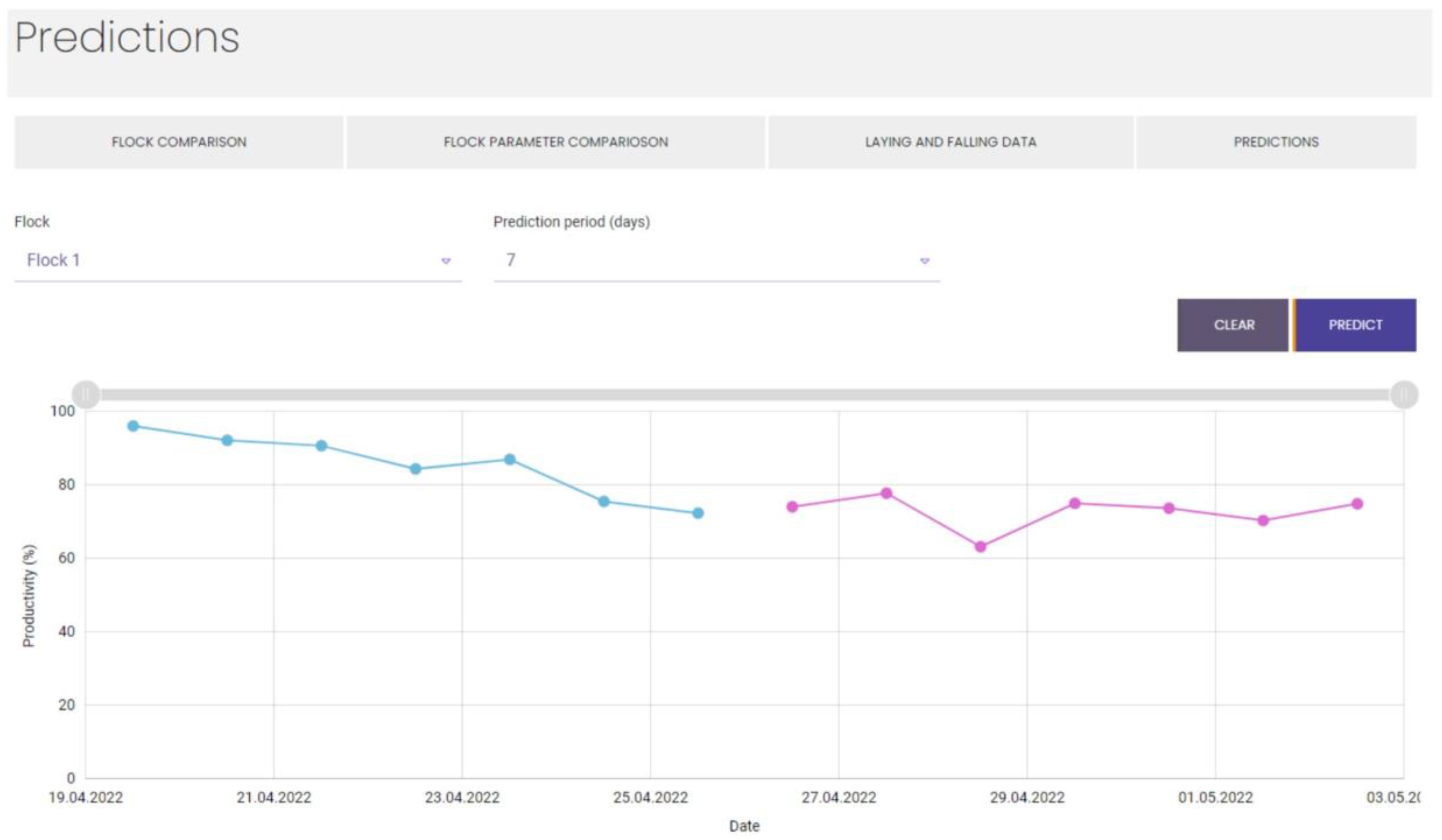
During the development stage, the developing models were implemented into the existing poultry management platform Aihen as a submodule for hen egg production forecasting [
52].
Figure 7 depicts the example of an implementation when the data were actively gathered and analysed, including the testing phase of the model’s development.
4. Discussion
The egg production cycle used for model testing was atypical in terms of data quality characteristics—uniformity and completeness for instance—thus adding more complexity in the process of selecting the most viable model and forecasting egg production based on such data.
Regarding the importance of data quality, various measures can be taken. Applied techniques include outlier detection and removal and missing value generation (by interpolating neighbour values or association with another parameter). In general, data quality must take place as one of the steps of pre-processing: the distribution of data must be analysed, and either normalization or standardization might be applied; the data must be checked for noise (mostly sensor related data) and addressed accordingly. Therefore, additional duplicate sensors can be included in the farm. Unless the quality is at its lowest, the general techniques for improvement should be sufficient to reduce impact on ML prediction, and, whereas minor imperfections may affect ML parameters, the trendline of outcome should be roughly the same. All of this would require the re-training and re-testing of the model with different levels of data quality.
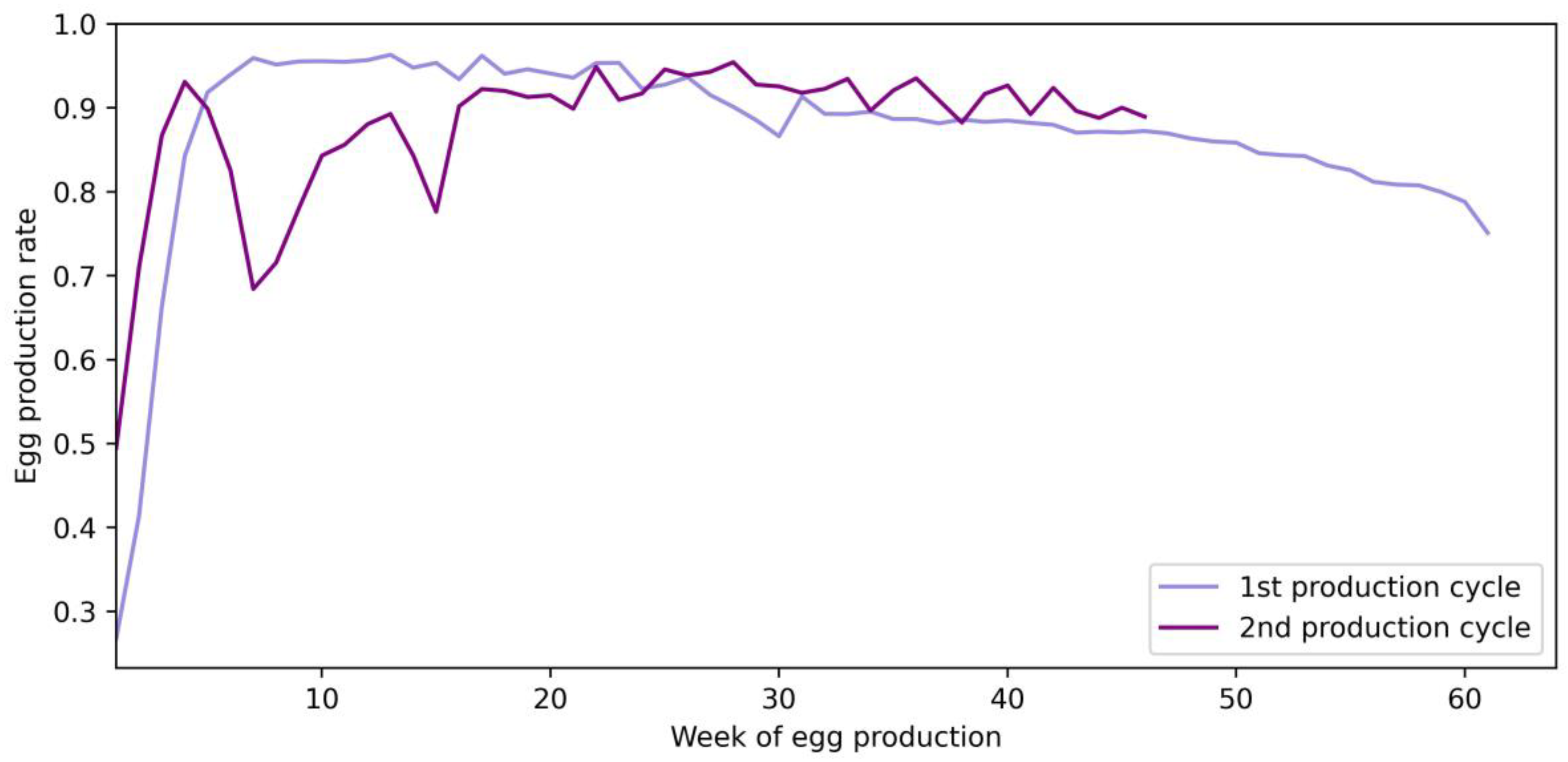
It must be noted that forecasting was performed for 1 day upfront only, which relatively limited the requirements for precision target. Additionally, while it was possible to forecast the production rate for longer periods, the results may have seen a rapid decrease in precision; thus, the appropriate forecasting length should be long enough to implement appropriate changes (i.e., adapt the ventilation algorithm for temperature changes) to the production process. In addition, the choice of forecasting only 1 day upfront was dictated by the consistency in the available training data. This also included differences between data of two separate cycles (as demonstrated in
Figure 2).
Another aspect that should be researched more is the number of factors needed to provide a reliable prediction. This could be important for smaller farms that might not have multi-sensor equipment to measure various parameters that affect hen egg production (such as CO
2, NH
3). A study carried out by [
42] was aimed to determine the environmental factors that influence the egg production of laying waterfowls’ (lion-head goose). The authors found that the optimal number of parameters was equal to four (i.e., laying rate, carbon dioxide, temperature, and dust) when forecasting, using a combination of LSTM and RF. While it may have some differences, the general guidelines of having limited parameters, which can be observed consistently, may be projected to laying hens as well, but further studies (larger datasets) and practical evidential assessments are still required to confirm this.
In the process of finding the optimal set of parameters, a lot of redundant and unimportant factors may be introduced that may lead the model astray; thus, we can assume that convoluting models with multiple parameters not only increase the difficulty for the data gathering step but may also lead to a decrease in the overall performance in regard to accurate forecasting.
5. Conclusions
The test data set that was significantly different demonstrated the limitations of the nonlinear model that used only one parameter (the number of weeks laying) and did not adjust to changes that also resulted in MAPE and RMSPE values—9.134% and 14.809%, respectively.
Although the calculated errors (MAPE and RMSPE) of the ML models were within the range of 5% to 10%, it was observed that they could better adjust to production changes than the tested nonlinear regression model.
As the ML models also used environmental data as inputs, sudden changes in those factors (e.g., temperature, CO2, NH3) affected productivity, which could be predicted in a timely manner.
The results showed that the ML models (LSTM, RF, and XGBoost, with a sliding window size of two) were able to forecast the drop-in production rate (2nd production cycle) at a satisfactory level.
The results suggested that the proposed solutions may also be applicable within farms that have limited production data sets and do not have large volumes of historical egg production data.
Depending on the available historical data for model training, the farm could also employ a multi-model approach, where different models could be run according to the farmer’s needs (forecasting length). Furthermore, this also keeps an option to apply the nonlinear model in situations where no environmental or other productivity-affecting data are recorded. In this case, the nonlinear model could be used either as a separate solution or complementary evidence to follow the production curve dynamics.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}