Abstract
Many customers rely on online reviews to make an informed decision about purchasing products and services. Unfortunately, fake reviews, which can mislead customers, are increasingly common. Therefore, there is a growing need for effective methods of detection. In this article, we present a case study showing research aimed at recognizing fake reviews in Google Maps places in Poland. First, we describe a method of construction and validation of a dataset, named GMR–PL (Google Maps Reviews—Polish), containing a selection of 18 thousand fake and genuine reviews in Polish. Next, we show how we used this dataset to train machine learning models to detect fake reviews and the accounts that published them. We also propose a novel metric for measuring the typicality of an account name and a metric for measuring the geographical dispersion of reviewed places. Initial recognition results were promising: we achieved an F1 score of and when detecting fake accounts and reviews, respectively. We believe that our experience will help in creating real-life review datasets for other languages and, in turn, will help in research aimed at the detection of fake reviews on the Internet.
1. Introduction
Fake information has become an enormous problem in recent years. It is very easy to fabricate information posted on the Internet, and there are many incentives to do so. Fake information can be used for various purposes, from attracting new customers and shaping people’s views, through fake news [1], manipulation, and the introduction of social divisions, to massive disinformation campaigns known as infodemics [2], as recently experienced during the COVID-19 outbreak [3]. It is also an important element of cyberwar, as can be seen in Russia’s invasion of Ukraine. For these reasons, it is essential to search for effective methods of detecting false information.
In this study, we narrow our focus to fake reviews published in one of the most popular Google services: Google Maps [4]. Our case study involves reviews of Google Maps places in Poland, written in Polish. First, we show how we constructed a dataset containing fake and genuine reviews from Google Maps. Next, we show the initial results of detecting fake accounts and reviews. We also propose novel metrics to help in their detection.
Our article is structured as follows. First, in Section 2, we present a brief review of related work in the field of fake review detection. Next, in Section 3, we describe in detail the construction of our dataset and its basic characteristics. In Section 4, we present initial experiments using our dataset and show their results. The article ends with a discussion of the results (Section 5) and conclusions (Section 6).
2. Related Work
Various researchers have recently addressed the problem of fake review detection. The most common approach is to use machine learning (ML) methods to build a binary classifier, working in a carefully designed feature space. However, to make an ML model, there needs to be a dataset that it can be trained on. There are numerous such datasets; we briefly review the most important ones in the next subsection and follow this with a concise description of detection algorithms.
2.1. Existing Datasets
One of the first review datasets was created by Jindal and Liu [5]; they used web-scraping methods to obtain 5.8 million reviews from Amazon. Then, they analyzed the newly created dataset and labeled reviews genuine or fake by checking whether their content was repeated elsewhere. While this is a fast method of labeling a dataset of that size, it may produce a lot of false labels, i.e., genuine reviews which happened to repeat and were labeled as fake. Unfortunately, the authors did not publish their dataset.
Another approach was taken by Ott et al. [6], where the authors created a dataset of 400 real and 400 fake reviews. Real reviews were collected from TripAdvisor’s 20 most popular hotels in American cities. Fake reviews were specially prepared for that study using crowd-sourcing. Crowd workers were tasked with writing either positive or negative reviews for hotels (the same as in authentic reviews) that they had never visited. This approach produced a dataset with no false labels, but the data were artificial and might not have been a good representation of how fake reviewers operate. The dataset was also relatively small (800 entries).
Yet another dataset was created by Yoo and Gretzel [7]. They focused on a particular Marriott hotel and collected 40 genuine reviews from TripAdvisor. To acquire fake reviews, they instructed tourism marketing students to write fake reviews aimed at promoting the hotel, and in this way, collected 42 deceptive reviews. Then, they looked for psycho-linguistic differences between the two types of reviews. Unfortunately, the size of their dataset is insufficient for training most ML algorithms. Despite this, this study gives an insight into how fake reviewers may think and how they may construct their reviews.
Another noteworthy dataset was obtained by Sandulescu and Ester [8]. Trustpilot, which is one of the largest platforms that allows customers to review a business from which they have purchased a product or service or where they contacted customer service, provided the dataset of 9000 reviews, labeled as fake or real. The dataset contained only reviews with four or five stars. Unfortunately, the dataset was not made public, so no other studies using this dataset were found.
An Amazon review dataset was initially published in 2014 [9] and later updated by Ni et al. [10] in 2018. This dataset includes reviews of products on Amazon and associated product metadata (descriptions, category information, price, brand, and image features). The original dataset from 2014 was filtered to exclude duplicated reviews (potentially fake reviews) and contains 83.68 M reviews. The updated version was not filtered and contains 233.1 M reviews. The original dataset contains reviews from May 1996 to July 2014; the updated version extends that to 2018.
Another approach was proposed by Joni S et al. [11], where they used GPT-2 and ULMFiT models to generate samples of fake reviews. They created a dataset with 20,000 fake reviews generated with GPT-2 and 20,000 real reviews sampled from the Amazon review dataset.
The Yelp database is a dataset owned and publicized by Yelp, Inc., which is an American company that gathers and publishes crowd-sourced reviews about businesses. It is a real dataset consisting of nearly 7M reviews and 150k businesses located in 11 metropolitan areas. The dataset is widely used among researchers; its key features are that it is a naturally collected dataset and its sheer size. The dataset is rarely used in its entirety; often, its subsets are used separately.
One subset is the Chicago subset (YelpCHI). The Yelp filtering algorithm, which detects “fake/suspicious”, was used to label all reviews in that set as either fake or genuine. The dataset includes 67,395 reviews of 201 restaurants and hotels written by 38,063 reviewers. The algorithm labeled 13.23% of reviews and 20.33% of reviewers as fake. Even though the algorithm was not perfect, its labels are considered “near ground truth”. This encourages many data scientists to train their own ML models based on the Yelp algorithm.
Table 1 summarizes the information about existing datasets. It lists essential features of each dataset. Values given in the “Name” column are not official (we named them ourselves). The fake percentage is the number of fake records in the dataset divided by the total number of records. The “Labeled” attribute marks whether records in the dataset are labeled genuine or fake; the value “Some” means that not all records are labeled. The “Natural” attribute says whether the dataset was obtained by capturing real-life data or generated artificially in some way. The “Public” column states whether the dataset is open to the research community. An ideal dataset for research purposes would be, of course, labeled, natural, and public. However, as displayed in Table 1, none of the above-described datasets fully satisfies these conditions. The current study, among other things, will fill this gap.

Table 1.
Comparison of existing review datasets with fake reviews.
The previously mentioned researchers created new datasets and used them to train their models. Contrary to this, the most common approach is to use already existing datasets and concentrate on the detection method. This approach is currently limited because even though numerous datasets exist, few are labeled. Wang et al. [13] helped with this problem by creating a method of Rolling Collaborative Training that allows unlabeled data to be used in training models.
2.2. Detection of Fake Reviews
Detection of fake reviews using an ML model was shown to be effective by many researchers: for example, by Barbado et al. [14] and Li et al. [15]. However, ML algorithms need a dataset of meaningful features to build a good model. To do so, many existing researchers followed the work of Crawford et al. [16]. They separated the detection of fake reviews into two approaches and described features that can be used in both:
- “Review–centric”, which mostly concentrates on the content of the review itself. This relies on natural language processing (NLP) methods to separate fake reviews from real ones.
- “Reviewer–centric”, which looks more broadly at the reviewer’s account and considers the general statistics of the account, such as the percentage of positive reviews or number of reviews written in a given time.
The already mentioned research [7] studied the psycho-linguistic differences between real and fake reviews. The researchers observed that fake reviews were more complex and contained more self-references and a greater number of references to the hotel brand. They also contained a greater percentage of positive words.
In [11], it was shown that algorithms such as support vector machines (SVMs) with Naïve Bayes features (NBSVM) and the fine-tuned large neural language model RoBERTA [17] called “fakeRoBERTA” [11] models gave a very high performance. Neural networks (NNs) were also shown to be effective, e.g., in Hajek et al. [18]. On the other hand, Li et al. [19] showed that even simple ML algorithms, such as Naïve Bayes, SVM, and decision trees, can perform well.
3. Creating a Dataset of Google Maps Reviews
In this case study, we focused on detecting fake reviews of Google Maps places in Poland. The Google Maps tool was selected because according to reports [20,21], it is the most popular platform for posting and reading reviews. To analyze Polish Google Maps reviews, we needed to create our own reviews dataset because the existing datasets did not satisfy our needs: none contained reviews from Google Maps or reviews in Polish, nor allowed per-account analysis of reviewed places. We named the dataset we created GMR–PL (Google Maps Reviews—Polish) and made it available to the research community as described in the Data Availability Statement section at the end of this article.
Below, we present the process of creating our dataset, starting from scraping the Google Maps data, through database validation, and ending with presenting the statistics of the GMR–PL dataset. We think this procedure could be helpful for other researchers planning similar studies for their locations and languages.
3.1. Scraping Google Maps to Identify Fake and Genuine Data
First, we created a dedicated scraper program, which navigated through the places displayed on Google Maps, the reviews published next to them, and the Google profiles of users who published these reviews. The scraper was able to collect various information about both the reviews and user accounts. For simplicity in gathering and accessing the collected information, we used the MongoDB system. We divided the data into two collections: accounts and reviews.
The process of identifying fake reviews in Google Maps, and their authors, was inspired by [22]. It consisted of the following steps:
- Find online services offering fake reviews.
- Search their website for examples of reviews they have written.
- Use these samples to find the corresponding review and the reviewed object.
- If the reviewer has not set their status to private, save this account’s name and URL address in a temporary database.
- Use our automated Google Maps scraper to check, among the reviewed places, whether there are groups of reviewers who have reviewed the same places.
- Save the accounts that were present in the mentioned groups as fake.
- Scrape more detailed data about accounts presumed to be fake and save them into the dataset.
In more detail, we gathered the initial fake accounts using a two-step process. First, we looked for examples of orders completed by the fake review services in the past and tried to reverse-engineer an account or a place where the review was posted. Using this method, we managed to find ten accounts from three different services. Next, we found the Google Maps places corresponding to these three fake review services and analyzed the accounts that reviewed them. Our thought was that fake services might also post fake reviews on their own objects. Many of those accounts left reviews on the same cluster of other Google Maps places. This suggested that these accounts were also fake. As a consequence, we deemed the reviews published by them as fake also.
Having found some fake accounts, we checked for groups of reviewers. If another account had rated at least the same N places, it was considered to be in the same group and therefore marked as fake. We automated this process so that we could easily find more fake accounts using such a net of connections. The more accounts we flagged as fake, the easier it was to find the next ones, until we found all accounts from a given service. Following this method, we found 319 fake accounts. However, having disqualified the accounts that were private (and therefore could not be further examined), we were left with 187 fake accounts and their 2451 reviews.
The value of N was chosen heuristically. When we set , the number of accounts suspected to be fake was very high, which suggested a high false positive rate. When we used , we obtained only a few suspect accounts. Therefore, as a trade-off, we eventually set N equal to 3.
As a reference, we also collected data on a similar number of genuine reviews from Google Maps and the accounts that published them. The process of identifying them was different. We assumed that most of the accounts on the platform are genuine. We randomly scattered 27 points (value chosen heuristically), equally spaced, on the map of Poland, and took the nearest Google Maps places with at least five reviews posted. Next, we analyzed all accounts which posted these reviews. This way, we collected 284 accounts, which were later scraped for a total of 15,528 reviews authored by these accounts.
3.2. Challenges Faced When Crawling Google Maps Data
During the collection of the data from Google Maps, we faced several challenges. Some were caused by the fact that the scraping spanned several weeks since the crawler was continuously developed to handle various types of Google Maps places. Below, we present some of the major problems in detail.
Changes to Google Maps HTML markers. Surprisingly, we noticed that during the period we were crawling the data, Google Maps HTML class names changed from simple names, such as review-place-name, to non-intuitive ones, such as d4r55 YJxk2d. These names have changed a couple of times since, and each time they forced us to update the crawler code and restart scraping. At the end of the scraping process, 35 distinct classes were observed.
Lack of access to precise dates. Every review on Google Maps is marked by its creation date. The problem lies in the presentation of this, as Google Maps shows only relative dates, with progressively worse accuracy. The older a review was, the less accurate was the time we could scrape. Because of that, newer reviews have much better accuracy than older ones. We decided to estimate the original date of review creation by subtracting the amount of time given by Google Maps from the date of scraping. However, we are aware that the date of older reviews are stored with large error margins, as displayed in Table 2.
Table 2.
Precision of date and time information in Google Maps.
Rebranding of reviewed places. During the scraping, the line of supermarkets “Tesco” was bought by Salling Group S/A, and therefore, the corresponding Google Maps places were renamed to “Netto”. We decided to merge the reviews from old Tesco stores with the reviews of the corresponding new Netto stores.
Changes in accessibility of accounts. During our initial scraping, we gathered data on every account that we found. Among those data was information on whether the account was private or not—private accounts cannot be properly accessed, so we were only able to collect the account’s name, id, and the fact that it was private. During our research and refinement of the database, we noticed that we could not access data from a lot of accounts that once were public. Interestingly, most of them were the same accounts that we labeled as fake. We realized that most probably Google banned those accounts. Fortunately, this change came late into our research and did not impact the collection of data; it only made it harder to validate such accounts.
3.3. Database Validation
We conducted a validation procedure to ensure the correctness of annotation in our dataset. We decided to follow the reviewer-centric analysis. First, we wanted to double-check if the accounts indicated algorithmically as fake were also fake in experts’ opinions. Similarly, we wanted to check if the accounts presumed to be genuine, which were selected randomly, were genuine indeed in the eyes of invited experts. It is worth noting that the algorithm selecting genuine accounts did not evaluate their genuineness in any way, but simply relied on the presumption that most of the users commenting on Google Maps places were real. However, theoretically, a fake review might have been randomly selected.
To validate our database, we invited opinions from seven experts with experience in cyber security and Internet media. Each was presented with a questionnaire with the basic data for 442 accounts in random order, and they were asked to decide whether they found them genuine (scored as ‘’) or fake (scored as ‘’); “don’t know” as an answer was also allowed (scored ‘0’). The experts were able to see basic data about the account (the account name, the local guide level, the number of reviews), data about the first five reviews of the account (the type of object assigned by Google Maps, rating, the review content), and a map showing the location of the reviewed places, captioned with the object type. If an account published fewer than five reviews, all the available reviews were displayed.
After the assessment, the scores were summed up. Their distribution is shown in Figure 1 (please note the logarithmic scale of the Y axis). One can see that agreement between the raters was high, which resulted in low values between and scores and high extreme values (). Additionally, the correlation between the raters’ opinions and the initial labels was very high.
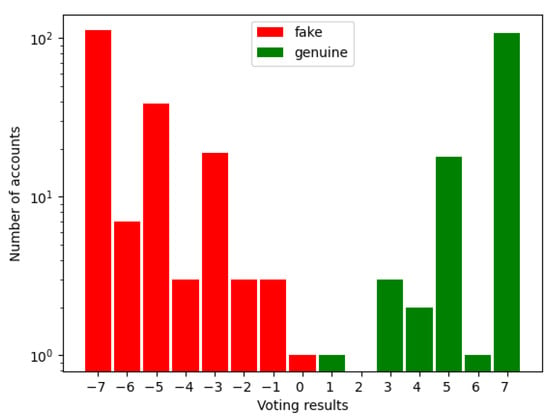
Figure 1.
Summarized results of experts’ voting.
The accounts which received scores in the range of <> were further analyzed by a group of three experts. This was also done with cases where an expert left a comment expressing doubts. This analysis involved using additional data, e.g., checking all the available reviews (instead of only the first five), taking the context into account, etc. The final consensus on the genuineness of an account was reached in discussion. As a result, two initial decisions were changed: both from ‘fake’ to ‘genuine’.
3.4. Clustering Object Types
Our review database contains 980 distinct types of places, as assigned by Google, which is difficult to analyze. Therefore, we used natural language processing (NLP) methods to group types that have names with a similar meaning. We experimented with different dimensions of two word2vec [23] Polish models, Gensim [24,25] and FastText [26,27], and various clustering algorithms. The best results were achieved by using the 300-dimension FastText model [28] paired with the Agglomerative Clustering algorithm [29,30] bound with a maximum of 20 clusters. The resulting clusters were manually reviewed and minor corrections were made, so we ended up with 17 clusters, which we named as shown in Figure 2.
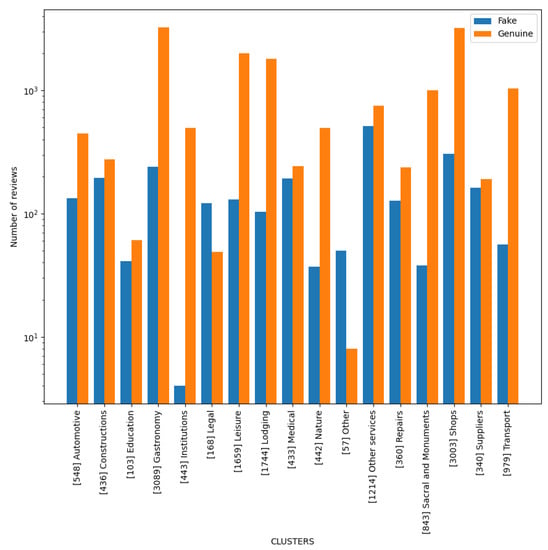
Figure 2.
Number of reviews in each cluster.
In Figure 2, we also show how many fake and how many real reviews fall under each cluster. The number in square brackets next to the name of a cluster is the number of reviews in that cluster. We can see that the Gastronomy, Shops, Lodging (i.e., hotels, apartments, etc.), and Leisure (i.e., cinemas, clubs, etc.) clusters are the largest. In most of the clusters, genuine reviews prevail, with the exception of Legal (i.e., attorneys, legal counsels, etc.) and Other (i.e., closed places). On the other hand, the Institutions cluster contains the fewest reviews assessed as fake (2 only).
3.5. Features Collected
The GMR–PL dataset is composed of two collections: the accounts and the reviews. The collection of accounts consists of data as shown in Table 3. Each account is described by basic information, such as its name, reviewer ID, and the number of reviews. In addition, it is marked with two flags saying whether the account is private and whether we suspect it was banned.
Table 3.
Account collection features.
The second collection, containing the gathered reviews, encompasses the data presented in Table 4. Each review is described with 14 features, starting from the basic ones, such as the ID number, the name of the reviewed object, and the rating given, i.e., the number of stars. The other properties say, for example, whether the object owner answered the review or any photographs accompanied the review.
Table 4.
Review collection features.
There is some redundancy between our two collections (e.g., the “is_real” field is always assigned the “is_real” value of the reviewer authoring the given review). In any event, we added it for easier analysis of the data.
3.6. Dataset Statistics
In Table 5, we present the basic statistics of the GMR–PL dataset. “Private accounts at the start” are accounts that were already private when we first encountered them. “Private accounts at the end” are accounts that, at the time of writing this article (March 2023), cannot be accessed fully; 64 of them were private at the start of this study, and 25 changed to private during our study. “Deleted accounts at the end” are accounts that were deleted at the time of writing. All were deleted since the time of scraping (around June 2021); 149 were fully accessible at the start, and 96 were already private. They may have been banned by Google since all were previously marked as fake.
Table 5.
General information about our GMR–PL dataset.
The newest review in the database is dated 9 February 2023 23:05:17, which is a precise date and time. The oldest review is estimated to originate from 2013. Its exact date, as explained earlier, cannot be determined. The value recorded in the database (11 February 2013 22:03:25) should be treated with a large error margin (approx. ±6 months), as should all date and time values before the year 2020.
In Figure 3a,b, we compare the number of reviews of genuine and fake accounts. In both graphs, we can observe that the majority of accounts have only a few reviews. Fake accounts tend to have fewer reviews than real ones.
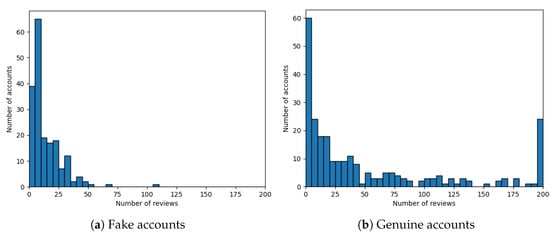
Figure 3.
Histograms of numbers of reviews per account for (a) fake and (b) genuine accounts. The last bin contains accounts with 200 or more reviews.
In Figure 4a,b, we compare maps of the locations reviewed by the genuine and fake accounts. Though there are a lot more real reviews, both distributions have similar characteristics. We can observe large groupings near bigger agglomerations and smaller groupings along the main highways, the coastline, and in other tourist regions (e.g., mountain areas).
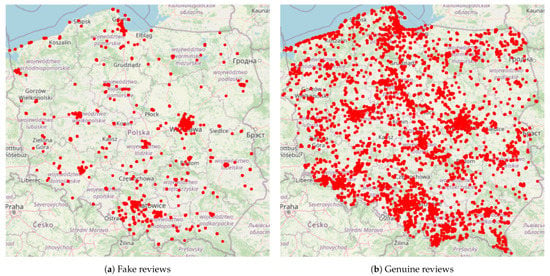
Figure 4.
Geographical locations of reviewed places, shown on map of Poland, for (a) fake and (b) genuine reviews.
In Figure 5a,b we compare ratings of fake and genuine accounts. Because the main goal of purchasing fake reviews is to boost the overall average rating of a business, we expected to see more high reviews from fake accounts than from genuine ones. Our expectations were confirmed: nearly all fake reviews had five stars, whereas the genuine reviews varied a lot more. This also means that in this study, we did not observe any cases of negative PR.
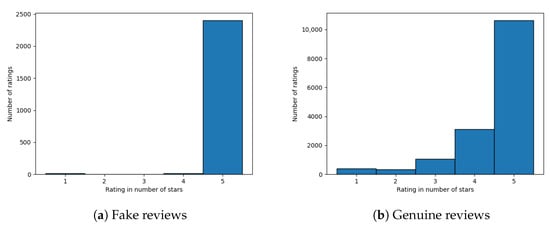
Figure 5.
Histograms of review ratings for (a) fake and (b) genuine reviews.
4. Initial Experiments and Results
We decided to test whether an ML algorithm can detect fake accounts and reviews in our dataset. Therefore, we conducted a series of experiments, described in the next subsections. We start with detecting fake accounts, followed by experiments to detect fake reviews.
4.1. Detection of Fake Accounts
First, we tried to predict whether an account was genuine or fake. We excluded empty accounts from this experiment since we had no information about their reviews. Using the “sklearn” [31] Python library, we employed a random forest (RF) classifier with 100 classifiers. We also tried other classifiers, but RF yielded the best results, so we will present only the results for RF here.
Initially, we used basic features derived from an account, such as:
- Local guide level;
- Number of reviews;
- Basic rating statistics (mean, median, and variance);
- Percentage of reviews with responses given.
The use of the last feature was motivated by our observation that the place owners usually responded to the reviews they had bought.
To use our dataset more efficiently, to estimate the performance of our detection model, we used 10-fold cross-validation. We measured the accuracy of detection, as well as the precision, recall, and F1 score for the detection of fake accounts. We show the detection results in Table 6. We reached an F1 score equal to , with similar precision and recall results. A prevalence value of , calculated by dividing the number of positive results by the sum of the positive and negative results, shows that the model is not biased toward any particular side.
Table 6.
Results of fake account prediction.
4.2. Additional Features
We propose using additional features to increase the accuracy of detection of fake accounts. They are based on analysis of the account’s name and the reviewed places. The details are described in the following three subsections.
4.2.1. Name Score
We noticed that the names of fake accounts in the GMR–PL dataset appear to be more often common names that we would expect to see in the real world, whereas the names of real accounts sometimes were abbreviations or nicknames rather than full names. To measure that difference, we used the register of Polish names and surnames [32], which gives the number of people registered to date with a specific name or surname. To obtain the score of an account’s name, we used the method described in Algorithm 1, where is the number of people in the registry with first name , and is the number of people in the index with surname .
Using this algorithm, we can measure how common an account name is: the lower the score, the less common the name is. We show the difference between name scores for fake and genuine accounts in Figure 6a,b. Genuine accounts tend to be more unique. A high score means that the account name is considered to be common in Poland. The zero bin contains unusual account names, such as nicknames or names with numbers. The histograms show that such names are much more frequent for authentic accounts.
| Algorithm 1: Algorithm for calculating name score. |
| Input: name_of_account(string) Output: name score(int) 1: number of words in name_of_account 2: if () then 3: first(name_of_account) 4: second(name_of_account) 5: 6: return 7: else 8: first word of name_of_account 9: second word of name_of_account 10: 11: 12: 13: 14: 15: 16: 17: return 18: end if |
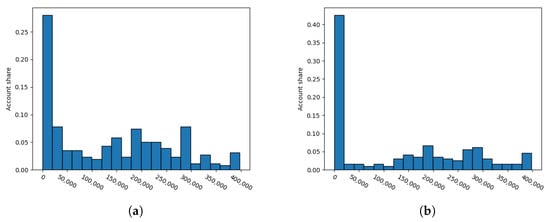
Figure 6.
Histograms of account name scores (values above 400 k were skipped). (a) Fake accounts (zoomed); (b) genuine accounts (zoomed).
4.2.2. Geographic Dispersion
We observed that owners of genuine accounts tended to review places located in clusters: first, close to the place they live (most probably) and next, in the places they visit when traveling (e.g., in tourist or business areas). On the other hand, places reviewed by fake accounts were geographically much more spread out; probably, the location of the places was not related to any itinerary but depended on the order for reviews placed.
To measure the level of geographic dispersion, we decided to group the reviewed places into n clusters and measure distances d from the reviewed places to the centroids of the clusters they belong to. Clustering was performed using the K-means algorithm [33]. The number of centroids, n, was set with Formula (1).
The values of a and b were adjusted heuristically as and . Figure 7a,b show histograms of d values for fake and genuine reviews, respectively. As expected, the histogram for genuine reviews is heavily leaning to the left, which means that in many cases, the reviewed places were close to the centroids of their corresponding clusters. On the other hand, the centroids of the clusters with fake reviews were much further from reviewed places. This means that the geographical dispersion of places reviewed by a fake account was much higher.
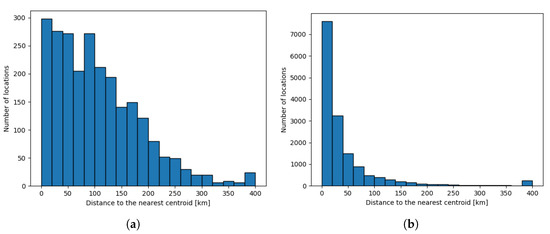
Figure 7.
Histograms of geographic distribution of reviews. (a) Fake reviews (zoomed); (b) genuine reviews.
4.3. Results of Detection of Fake Accounts Using the Extended Feature Set
We have extended the basic feature set with the proposed features: name score and the features based on the d distance: mean, median, and variance of d for the reviews authored by an account. The results of fake account detection, using the enlarged feature set, are shown in Table 6, next to the results for the basic feature set. One can observe an improvement in all metrics: e.g., the F1 score increased from to almost .
4.4. Detection of Fake Reviews
We also experimented with detecting fake reviews on their own, i.e., without analyzing other reviews authored by the same account (because, in real conditions, this information may not be available, e.g., if an account is private). We used the same classification method (RF with 100 classifiers), fed with the following features:
- Name score of the authoring account;
- Local guide level of the authoring account;
- Number of reviews of the authoring account;
- Rating awarded;
- Whether the review was responded to.
We decided not to include the geographical coordinates of the reviewed places, as we think that this could result in model overfitting to our dataset: the model might associate specific coordinates with having fake or genuine reviews.
To assess the efficacy of our model, we used 10-fold cross-validation. We present the detection results in Table 7. In this case, the metrics are much lower than when detecting fake accounts: the F1 score yielded , compared to for the fake account detection. The accuracy result is similar in both cases (), but it should be noted that in the case of the reviews, the dataset is imbalanced: there are more than six times more genuine reviews than fake ones.
Table 7.
Results of fake review prediction.
5. Discussion
Fake accounts pose an increasing threat to the reliability of Google Maps reviews, so it is no wonder that Google bans them, as we observed during our project. Google has also recently introduced its algorithm for detecting forbidden content (including fake content). According to the information on the Google website [34], the algorithm uses three main factors to determine whether a review should be deleted: the content of the review, the account that left the review, and the place itself. The main focus of this algorithm seems to be detecting harmful, offensive, or off-topic content. However, it also tries to detect fake reviews in the very same way that we used to find the first fake accounts. Among other methods, it looks for groups of people leaving reviews on the same cluster of Business Profiles. Unfortunately, Google does not provide more information about their methods.
Our experimentation with review-based fake recognition is very important because it allows for analysis of reviews authored by private accounts. In such cases, we cannot access the account page but can see only basic information about it.
The efficacy of the detection of fakes may improve, e.g., by fine-tuning the classification model. However, this was not the main focus of our study: we concentrated on creating a dataset that would foster further studies in this field and encourage others to create similar datasets for other locations and languages.
Our study is somewhat limited because we considered only a binary division into genuine and fake accounts, which author only genuine or only fake reviews, respectively. Apparently, the providers of fake reviews, from whom we started searching for fake data (see Section 3.1), did not use more complex methods. However, in general, fake reviews may occasionally be created by genuine accounts. The opposite situation is even more likely: fake accounts can author innocent-looking reviews (e.g., with reviews of natural objects) to mislead detection algorithms.
The lack of fake negative reviews causes further limitations. In contrast to the genuine ones, the fake reviews in the GMR–PL dataset almost exclusively assess the reviewed places using the highest score (five stars). This made the detection of fake accounts and reviews easier, but it may not necessarily correspond to reality. So far, we have not been able to identify fake negative reviews; however, in the future, the dataset may be enlarged by reviews of this type.
6. Conclusions
In this article, we presented the results of our work on detecting fake reviews on Google Maps. In our case study, we focused on Google Maps places located in Poland and written in Polish. We created a public dataset named GMR–PL with almost 18,000 reviews authored by more than 600 accounts, of which about 50% were assessed as fake. We showed how to create such a dataset from the ground up. In doing so, we paved the way for further studies in different languages, which we strongly encourage other researchers to do.
In addition, we conducted initial experiments using GMR–PL to detect fake reviews in Google Maps, and the accounts which authored them. For that purpose, we proposed a metric describing the geographical dispersion of reviews and name score, which gives information about the typicality of an account name. We achieved a promising F1 score of and when detecting fake accounts and reviews, respectively. However, these results leave room for improvement. Future work may involve analysis of the review content using NLP techniques and a search for improved detection models.
Author Contributions
Conceptualization, P.G. and A.J.; methodology, P.G. and A.J.; software, P.G.; validation, P.G. and A.J.; formal analysis, P.G. and A.J.; investigation, P.G. and A.J.; resources, P.G. and A.J.; data curation, P.G.; writing—original draft preparation, P.G.; writing—review and editing, P.G. and A.J.; visualization, P.G.; supervision, A.J.; project administration, A.J.; funding acquisition, P.G. and A.J. All authors have read and agreed to the published version of the manuscript.
Funding
Paweł Gryka is a beneficiary of the program “Szkoła Orłów na PW”, funded by the EU POWER Program. The work was partially funded by a statutory activity subsidy from the Polish Ministry of Education and Science.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The GMR–PL dataset, in pseudo-anonymized version, is available on Kaggle [35]. The full version is available from the authors on request.
Acknowledgments
The authors wish to thank Piotr Zarzycki for his excellent talk entitled “How much does a good online reputation cost—statistics, examples [memes]” during the “Oh My Hack 2020” event in Warsaw, Poland (27–28 November 2020), including the description of the method of searching for fake accounts, which inspired us to undertake this study. We would also like to thank everyone who helped complete the validation questionnaire for their time and effort.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bondielli, A.; Marcelloni, F. A survey on fake news and rumour detection techniques. Inf. Sci. 2019, 497, 38–55. [Google Scholar] [CrossRef]
- Calleja, N.; AbdAllah, A.; Abad, N.; Ahmed, N.; Albarracin, D.; Altieri, E.; Anoko, J.N.; Arcos, R.; Azlan, A.A.; Bayer, J.; et al. A Public Health Research Agenda for Managing Infodemics: Methods and Results of the First WHO Infodemiology Conference. JMIR Infodemiol. 2021, 1, e30979. [Google Scholar] [CrossRef] [PubMed]
- Gradoń, K.T.; Hołyst, J.A.; Moy, W.R.; Sienkiewicz, J.; Suchecki, K. Countering misinformation: A multidisciplinary approach. Big Data Soc. 2021, 8, 1–14. [Google Scholar] [CrossRef]
- Google Maps. Google Maps. 2023. Available online: https://www.google.pl/maps (accessed on 20 May 2023).
- Jindal, N.; Liu, B. Opinion spam and analysis. In Proceedings of the International Conference on Web Search and Data Mining (WSDM 2008), Palo Alto, CA, USA, 11–12 February 2008; pp. 219–229. [Google Scholar] [CrossRef]
- Ott, M.; Choi, Y.; Cardie, C.; Hancock, J.T. Finding Deceptive Opinion Spam by Any Stretch of the Imagination. arXiv 2011, arXiv:1107.4557. [Google Scholar]
- Yoo, K.H.; Gretzel, U. Comparison of Deceptive and Truthful Travel Reviews. In Proceedings of the Information and Communication Technologies in Tourism, Amsterdam, The Netherlands, 28–30 January 2009; Springer: Vienna, Austria, 2009; pp. 37–47. [Google Scholar] [CrossRef]
- Sandulescu, V.; Ester, M. Detecting singleton review spammers using semantic similarity. In Proceedings of the 24th International Conference on World Wide Web (WWW 2015), Florence, Italy, 18–22 May 2015; Association for Computing Machinery, Inc.: New York, NY, USA, 2015; Volume 5, pp. 971–976. [Google Scholar] [CrossRef]
- Amazon. Amazon Reviews Dataset. 2014. Available online: https://jmcauley.ucsd.edu/data/amazon/ (accessed on 31 March 2023).
- Ni, J.; Li, J.; McAuley, J. Justifying Recommendations using Distantly-Labeled Reviews and Fine-Grained Aspects. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP 2019), Hong Kong, China, 3–7 November 2019; pp. 188–197. [Google Scholar] [CrossRef]
- Salminen, J.; Kandpal, C.; Kamel, A.M.; Jung, S.G.; Jansen, B.J. Creating and detecting fake reviews of online products. J. Retail. Consum. Serv. 2022, 64, 102771. [Google Scholar] [CrossRef]
- Yelp Inc. Yelp Reviews and Users Dataset. 2022. Available online: https://www.yelp.com/dataset/documentation/main (accessed on 31 March 2023).
- Wang, J.; Kan, H.; Meng, F.; Mu, Q.; Shi, G.; Xiao, X. Fake review detection based on multiple feature fusion and rolling collaborative training. IEEE Access 2020, 8, 182625–182639. [Google Scholar] [CrossRef]
- Barbado, R.; Araque, O.; Iglesias, C.A. A framework for fake review detection in online consumer electronics retailers. Inf. Process. Manag. 2019, 56, 1234–1244. [Google Scholar] [CrossRef]
- Li, H.; Chen, Z.; Liu, B.; Wei, X.; Shao, J. Spotting Fake Reviews via Collective Positive-Unlabeled Learning. In Proceedings of the IEEE International Conference on Data Mining, Shenzhen, China, 14–17 December 2014. [Google Scholar] [CrossRef]
- Crawford, M.; Khoshgoftaar, T.M.; Prusa, J.D.; Richter, A.N.; Najada, H.A. Survey of review spam detection using machine learning techniques. J. Big Data 2015, 2, 23. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Hajek, P.; Barushka, A.; Munk, M. Fake consumer review detection using deep neural networks integrating word embeddings and emotion mining. Neural Comput. Appl. 2020, 32, 17259–17274. [Google Scholar] [CrossRef]
- Li, Y.; Feng, X.; Zhang, S. Detecting Fake Reviews Utilizing Semantic and Emotion Model. In Proceedings of the 3rd International Conference on Information Science and Control Engineering (ICISCE 2016), Beijing, China, 8–10 July 2016; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2016; Volume 10, pp. 317–320. [Google Scholar] [CrossRef]
- Online Reviews Statistics and Trends: A 2022 Report by ReviewTrackers. 2022. Available online: https://www.reviewtrackers.com/reports/online-reviews-survey/ (accessed on 20 May 2023).
- Paget, S. Local Consumer Review Survey 2023. 2023. Available online: https://www.brightlocal.com/research/local-consumer-review-survey/ (accessed on 31 March 2023).
- Zarzycki, P. Ile kosztuje dobra opinia w internecie—Statystyki, przykłady, [memy] (How much does a good online reputation cost—Statistics, examples [memes]). In Proceedings of the Oh My H@ck 2020, Poland (Online), 27–28 November 2020. [Google Scholar]
- Rong, X. Word2vec Parameter Learning Explained. arXiv 2014, arXiv:1411.2738. [Google Scholar]
- Rehurek, R.; Sojka, P. Gensim–Python Framework for Vector Space Modelling; NLP Centre, the Faculty of Informatics, Masaryk University: Brno, Czech Republic, 2011; Volume 3. [Google Scholar]
- Dadas, S. A Repository of Polish NLP Resources. 2019. Available online: https://github.com/sdadas/polish-nlp-resources/ (accessed on 20 May 2023).
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. arXiv 2016, arXiv:1607.04606. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Kocoń, J.; KGR10 FastText Polish Word Embeddings. CLARIN-PL Digital Repository. 2018. Available online: http://hdl.handle.net/11321/606 (accessed on 20 May 2023).
- Agglomerative Clustering Algorithm Explained by ScikitLearn. Available online: https://scikit-learn.org/stable/modules/clustering.html#hierarchical-clustering (accessed on 31 March 2023).
- Müllner, D. Modern hierarchical, agglomerative clustering algorithms. arXiv 2011, arXiv:1109.2378. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Serwis Rzeczypospolitej Polskiej (Republic of Poland Service). Lista Imion i Nazwisk Wystȩpujących w Rejestrze PESEL (List of Forenames and Surnames Appearing in the Polish PESEL Register). Available online: https://dane.gov.pl/en/dataset/1667,lista-imion-wystepujacych-w-rejestrze-pesel-osoby-zyjace (accessed on 31 March 2023).
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Society. Ser. C 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Leader, I. How Reviews on Google Maps Work. 2022. Available online: https://blog.google/products/maps/how-google-maps-reviews-work/ (accessed on 31 March 2023).
- GMR-PL Fake Reviews Dataset. Available online: https://www.kaggle.com/datasets/pawegryka/gmr-pl-fake-reviews-dataset (accessed on 20 May 2023).







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).