Abstract
Multimodal Named Entity Recognition (MNER) and multimodal Relationship Extraction (MRE) play an important role in processing multimodal data and understanding entity relationships across textual and visual domains. However, irrelevant image information may introduce noise that misleads the recognition of information. Additionally, visual and semantic features originate from different modalities, and modal disparity hinders semantic alignment. Therefore, this paper proposes the Visual Description Augmentation Integration Network (VDAIN), which introduces an image description generation technique that allows semantic features generated from image descriptions to be presented in the same modality as the semantic features of textual information. This not only reduces the modal gap but also captures more accurately the high-level semantic information and underlying visual structure in the images. To filter out the modal noise, we use VDAIN to adaptively fuse visual features, semantic features of image descriptions, and textual information, thus eliminating irrelevant modal noise. The F1 score of the proposed model in this paper reaches 75.8% and 87.78% for the MNER task and 82.54% for the MRE task on the three public data sets, respectively, which are significantly better than the baseline model. The experimental results demonstrate the effectiveness of the proposed method in solving the modal noise and modal gap problems.
1. Introduction
Named Entity Recognition (NER) and Relation Extraction (RE) are core tasks in social media information monitoring and evaluation. Given the rising influence of multimodal posts, multimodal information extraction technologies are more conducive to the supervision of public opinion on social media, such as Multimodal Named Entity Recognition (MNER) and Multimodal Relation Extraction (MRE). In recent years, food safety issues have received widespread attention on social media, particularly regarding the safety of staple crops such as rice and wheat [1]. The spread and attention of food safety incidents typically affect consumer confidence and purchasing decisions. Therefore, monitoring and analyzing food safety information on social media, especially the safety information of staple crops, has become increasingly important [2]. To more effectively mine this information, researchers have applied NER and RE techniques to the monitoring and evaluation of food safety incidents, as well as the analysis of food industry dynamics and food recall information [3,4]. On social media platforms, users comment, discuss, and share information about food safety issues, providing valuable data sources for researchers and regulatory authorities.
In early NER and RE research, the focus was mainly on text modality studies. Traditional approaches mainly have focused on constructing various efficient NER features, which were subsequently fed into different linear classifiers, such as the Support Vector Machines, Logistic Regression, and Conditional Random Fields (CRFs) [5,6,7,8,9]. With the development of deep learning techniques, the traditional one-hot representations have been replaced by word embedding methods, such as Word2Vec [10] and GloVe [11]. These methods capture semantic information of words in lower dimensions. In order to simplify the task of feature engineering, researchers have explored the combination of various deep neural networks with CRF layers to achieve word-level predictions—for instance, Recurrent Neural Network (RNN) [12] and Convolutional Neural Network (CNN) [13]. With the advent of the Transformer [14], many researchers adopted this model for NER and RE tasks [15,16,17]. Knowledge-enabled Bidirectional Encoder Representation from Transformers (K-bert) [18] and Enhanced Language Representation with Informative Entities (ERNIE) [19] combined pre-trained models with knowledge graphs to effectively learn additional entity knowledge.
Although the above models have achieved good performance in the text modality, they still face challenges when dealing with short, noisy data, such as Twitter datasets, especially encountering out-of-vocabulary words and complex abbreviations, as this type of text is often ambiguous. Many researchers have also proposed coping strategies. Von et al. [20] employed sentence-level features to enhance the recognition accuracy of named entities in short texts. Xie et al. [21] proposed a novel vocabulary substitution strategy based on constructing Entity Type Compatible (ETC) semantic spaces. Unknown words are replaced with ETC words found through Deep Metric Learning (DML) and Nearest Neighbor (NN) search. Soares et al. [22] fine-tuned pre-trained models with blank relationship data to automatically determine whether entities were shared between two relationship instances. Language Understanding with Knowledge-based Embeddings (LUKE) [23] introduced an entity-aware self-attention strategy and contextualized representation. Nevertheless, the aforementioned methods have not exploited the potential of visual information when dealing with multimodal data.
To compensate for the semantic context deficiencies in a single modality, Moon et al. [24] constructed a deep image network and a generic modality attention module that leverages images to enhance textual information and diminish irrelevant modalities. The model aimed to uncover correlations between multimodal data. Zhang et al. [25] designed an Adaptive Co-Attention Network (ACN), combining textual information with visual information processed by the Visual Geometry Group network (VGGnet) [26]. Subsequently, Arshad et al. [27] extended multidimensional self-attention techniques, simultaneously learning shared semantics between internal textual representations and visual features. Yu et al. [28] proposed an entity span detection technique to consider both word and visual representations of image and text information. To mitigate visual guidance biases introduced by images, Wu et al. [29] incorporated fine-grained images and designed a dense co-attention layer, introducing a co-attention mechanism between related image objects and entities. To further leverage image information, Chen et al. [30] proposed a novel neural network model that introduced image attributes and image knowledge. Zheng et al. [31] came up with the Adversarial Gated Bilinear Attention Neural network (AGBAN) which employs adversarial gating strategies to deal with the image-text alignment issue. To address the issue of image noise, Xu et al. [32] proposed a multimodal matching and alignment model to simultaneously handle modality differences and noise. Chen et al. [33] introduced a visual-prefix-based attention strategy (HVPNet) that progressively integrates visual features into each module of Bidirectional Encoder Representations from Transformers (BERT) for attention computation. Although these methods have improved the noise issue of multimodal information to some extent, there remains a significant modality gap between image features and text features originating from different modalities.
In order to bridge this gap and enhance the performance of multimodal models in various applications, it is crucial to examine the underlying structures and approaches of existing multimodal BERT models. Multimodal BERT models can be categorized into two main dimensions. (1) Structure—its main categories include single-stream and cross-stream. Single-stream multimodal models treat and fuse information from different modalities equally. Visual and textual inputs are processed by their respective encoders, resulting in visual and textual features that are subsequently combined into a unified sequence. The sequence serves as the input for the multimodal transformer, which autonomously learns the associations between cross-modal features. Representatives of this structure include VisualBERT [34], Universal Encoder for Vision and Language (Unicoder-VL) [35], and Object-Semantics Aligned Pre-training (Oscar) [36]. Cross-stream structures process visual and language information independently as two streams. Unimodal features were concatenated and fed into a deep feedforward neural network as input, with information exchange being achieved through cross-modal interaction transformation layers. Typical two-stream structure models include Contrastive Language Image Pre-training (CLIP) [37] and ViLBERT (short for Vision-and-Language BERT) [38]. (2) Pre-training tasks—pre-training tasks in vision-language models are key to interpreting and linking images as well as text within the artificial intelligence domain. However, most existing models are pre-trained based on image caption generation or conditional image generation, which emphasizes multimodal interaction, such as Dual-Level Collaborative Transformer (DLCT) [39], Graph Attention Networks (GAT) [40], Attentional Generative Adversarial Network (AttnGAN) [41], etc. Directly applying these models to multimodal named entity recognition (MNER) and multimodal relation extraction (MRE) tasks may not achieve ideal results because the core objectives of MNER and MRE are to utilize visual features for enhancing text information extraction, rather than predicting image content.
To address these challenges, many models have introduced image caption generation techniques. Accurately describing images is a challenging task, as it requires capturing and understanding various details within the image. Early image caption generation methods were primarily based on matching approaches, such as DFE [42] and VSE++ [43]. However, due to the limited generative capabilities of the description libraries, diversity is still difficult to achieve. Due to the ongoing advancements in deep learning and neural network technologies, numerous scholars have utilized these approaches in the area of image caption creation. Vinyals et al. [44] used CNN to encode images and LSTM as a text generator. Anderson et al. [45] employed Faster R-CNN [46] for staged object detection, improving the accuracy of image caption generation. Following the introduction of the Transformer model [14], Luo et al. [39] improved its attention mechanism by developing a Dual-Level Collaborative Transformer (DLCT) to enhance the complementarity between regional and grid features. Wang et al. [47] proposed the Geometry Attention Transformer (GAT) to further capture relevant geometric relationships of visual objects and extract spatial information within images. With the increase in large-scale models, inference speed has significantly decreased. Jin et al. [48] introduced an early exit strategy through layer-wise similarity to save computational resources while retaining state-of-the-art performance.
To effectively integrate visual features and semantic features generated from image captions, we propose a Visual Description Augmented Integration Network (VDAIN) in this paper. First, we input the raw image as well as the object detection image into the Vision Transformer (ViT) [49] and extract visual features from each ViT module as output. Furthermore, we apply image description generation techniques to the images and use A Lite BERT (ALBERT) [17] to extract semantic features from the generated image descriptions. Finally, we introduce the visual features and text vectors generated from image descriptions into the Visual Description Augmented Integration Network and predict entities and their relationships. In comparison to the shallow attention alignment method of MEGA, we have applied a BERT method fused with visual knowledge, which enhances the integration of visual and textual information. Compared with HVPNet, we adopt a visual description augmented integration mechanism to extract the textual semantic information from images, reducing the modality gap during the information fusion process. Furthermore, we employ ViT as the visual feature extractor, which is more similar to the BERT architecture, thereby improving the model’s ability to integrate cross-modal information to a certain extent. Therefore, our paper contributes to the existing research in three major aspects.
- (1)
- We employ an image description generation approach to extract key information and global summaries from visual content. The introduction of text features generated from image descriptions helps to reduce the modality gap, enhancing the robustness of MNER and MRE tasks.
- (2)
- We propose a Visual Description Augmented Integration Network for MNER and MRE. By adaptively integrating semantic features obtained from image descriptions with the visual features, the model aims to mitigate the error sensitivity caused by irrelevant features.
- (3)
- VDAIN achieves new state-of-the-art results on three public benchmark tests for MNER and MRE. Comprehensive evaluations confirm the practicality and efficacy of the proposed approach.
2. Materials and Methods
The model framework proposed in the text is shown in Figure 1 and consists of four main components: (1) image feature extraction; (2) image caption-based feature extraction; (3) visual description enhanced fusion; (4) integrated visual-text encoder. The model integrates image description generation techniques and introduces a visual description enhancement fusion network that cleverly fuses image features with semantic features extracted from the generated image descriptions to facilitate multimodal entity and relationship extraction. In the subsequent sections, we investigate methods to efficiently combine different features in multimodal datasets, aiming to minimize the interference of unrelated images and bridge the gap between modalities. This approach can multiply improve the performance of MNER and MRE.
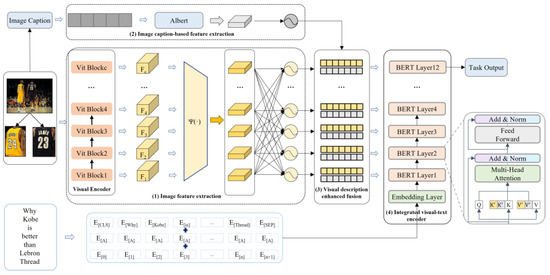
Figure 1.
The overall architecture of the Visual Description Augmented Integration Network for MNER and MRE.
2.1. Image Feature Extraction
Global image features primarily capture the comprehensive information within an image, including abstract concepts such as scenes, emotions, and themes, which can potentially weaken the learning signal strength. Conversely, local image features focus on capturing the distinct visual attributes of specific targets within the image, such as characters, objects, and shapes, thereby proving to be more beneficial for entity and relation recognition. Combining the two can fully exploit the potential value of global and local information. For the original image, we perform object detection and select images from the top n detection results with high confidence scores as input for subsequent local image feature processing.
Nowadays, ViT [49] is one of the most promising image neural network models, and its excellent fusion capabilities can lead to outstanding performance. To obtain high-quality visual features, we adopt ViT as the base network and extract image features by using the output of the last layer of each module. Specifically, we first resize the input image to 224 × 224 pixels and obtain a set of feature maps of different levels after processing it through .
where represents the input global image and corresponding object detection images, and denotes the pyramid visual features. In order to map visual features to the same dimension to match the text encoder of the visual-semantic fusion, we apply a mapping function Ψ(·) to the features.
where denotes the visual features from different layers, and is the global average pooling layer that reduces the dimensions of the visual features through average pooling and linear transformation operations. A convolution layer with a 1 × 1 kernel size applies a linear transformation to each pixel without changing the feature map’s dimensions, aligning with the text encoder for visual-semantic fusion.
2.2. Image Caption-Based Feature Extraction
As shown in Figure 2, we incorporate image caption generation, which can assist in filtering out noise introduced during the image feature extraction process. Specifically, the semantic features of image caption generation and the textual information share the same modality. This approach not only reduces the modality gap but also more accurately captures the high-level semantic information and underlying visual structure of the image.
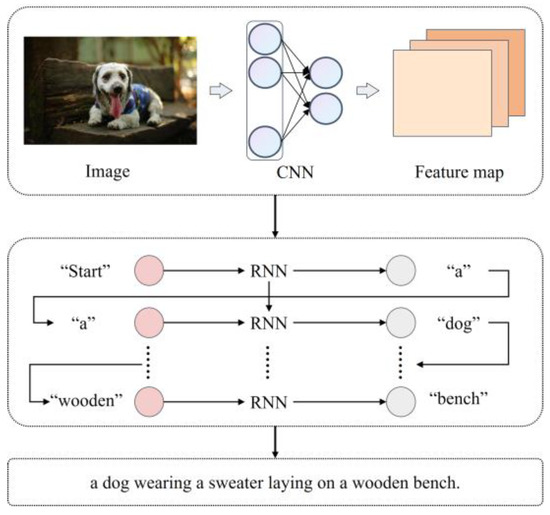
Figure 2.
The model architecture for image captioning.
As one of the best-performing models in the image caption generation domain, we use OFA [48] pre-trained on the COCO dataset to carry out the image captioning task, converting image information into natural language. The input image is first encoded into feature maps using an encoder and then transformed into appropriate vectors and decoded by a decoder.
where represents the size of the vocabulary; denotes the length of the generated image caption; and denotes the word at position n in the sentence. In addition, we input the generated image caption into the pre-trained model:
where is the contextual representation generated by . The generated vector is used as input for the subsequent fusion module facilitating semantic interaction between the multimodal features.
2.3. Visual Description Enhanced Fusion
Effectively reducing the noise introduced by visual features and narrowing the modality gap are significant challenges in current multimodal research. To address this issue, we design a Visual Description Augmented Integration Network that efficiently integrates visual features and semantic features generated by image captioning. Specifically, we incorporate a dynamic attention mechanism that computes multiple normalized vectors and to determine the degree of integration for each visual feature and semantic feature generated by image captioning:
where (·) denotes the activation function PReLU; is the visual feature of the different layers; is the number of layers; and is the semantic feature generated by image captioning, while is the text length. First, we reduce the visual feature to an appropriate dimension through average pooling and calculate the mean value. We further reduce the dimension of the visual feature using an layer and compute continuous values as path probabilities, implementing an adaptive visual feature gating strategy. Similarly, we apply a gating strategy for the semantic features generated by image captioning. Additionally, we use the activation function to process the normalized vectors and , obtaining the corresponding weight matrices and :
where is the activation function. Finally, when integrating feature representations, we adopt an adaptive feature fusion approach. By using the calculated weight matrices and , we perform a weighted summation of the corresponding layers’ visual and textual features to generate the fused feature representation:
where is the fused visual feature; is the visual feature from the c-th layer; is the fused semantic feature; and represents the -th textual vector. Formally, for the -th layer visual-semantic feature of BERT, we obtain it through the following concatenation operation:
where and represent the visual features of the original image and the object detection image, respectively, and denotes the semantic features of the image.
2.4. Integrated Visual-Text Encoder
We perform multi-modal information fusion on visual features, semantic features generated from image descriptions, and textual semantic features, which are jointly fed into the encoder. Specifically, in the self-attention mechanism of BERT, text embeddings are first mapped to query (Q), key (K), and value (V) vectors. The process projects the contextual representation of text embeddings into a specific vector space:
where represents the contextual representation of text embeddings. For that matter, a set of linear mappings is applied to project the hierarchical visual features and semantic features generated by image description into the self-attention module, aligning them within the same embedding space as the textual representation.
where represents the concatenated matrix of visual features and semantic features generated from image descriptions, and are prefix vectors containing hierarchical visual features and semantic features generated from image descriptions. denotes the length of the visual features and semantic features generated from image descriptions, and refers to the number of input images and target detection images.
2.5. Classifier
2.5.1. Named Entity Recognition
To enforce the structural correlation among labels during sequence decoding, we follow the methods presented in the research [24,27] and adopt a CRF decoder to accomplish the NER task, as illustrated in Figure 3a.
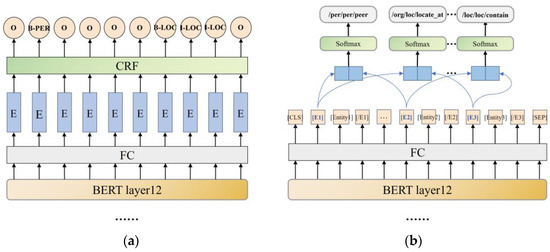
Figure 3.
(a) the MNER task classifier; (b) the MRE task classifier.
We utilize the output from BERT’s final layer as input, which undergoes processing through a feed-forward neural network layer before being processed in the CRF layer to obtain BIO tags for the MNER task. The probability formula between the label sequence and the MNER target is as follows:
where represents the final representation of the encoder, and denotes the fusion function between visual and textual features. Furthermore, represents a set of parameters defining the potential functions and weight vectors associated with label pairs for the task.
2.5.2. Relation Extraction
As illustrated in Figure 3b, we concatenate the identifiers of two entities and then classify the relationships between entities using a classifier. The corresponding mathematical formula is as follows:
where represents the trainable parameters. With the help of the token, we can infer the probability distribution over the class set . For the MRE task, we employ the cross-entropy loss method:
where represents the number of samples in the dataset, and denotes the fusion function between visual and textual features. In addition, are the prefix vectors containing hierarchical visual features and semantic features generated from image descriptions.
3. Results and Discussion
3.1. Data Set
We conduct experiments on the proposed model using three publicly available multimodal datasets: Twitter-2015, Twitter-2017, and MNRE. The two Twitter datasets cover four entity categories, including people, locations, organizations, and miscellaneous, as shown in Table 1. The distribution of samples in the training, validation, and test sets for these datasets is as follows: 4000/1000/3257 for Twitter-2015 and 3373/723/723 for Twitter-2017.

Table 1.
The statistics of MNER datasets.
The MNRE dataset is expansive, encompassing diverse topics such as food safety, entertainment, and sports. It is characterized by 23 distinct relationship types. In addition, we have constructed a dataset related to the topic of food safety, named FOOD dataset. Further details about this data can be located in Table 2. The distribution of samples in the training, validation, and test sets for these datasets is as follows: 12,247/1624/1614 for MNER and 1115/205/205 for FOOD datasets.
Table 2.
The statistics of MNRE and FOOD datasets.
3.2. Experimental Environment
Our experiments are conducted on an Nvidia 3090 GPU. We select five different random seeds (1, 56, 3452, 4477, 1234) and perform each experiment five times, reporting the average performance. Then, we employ the BERT-base-uncased pre-trained model and the AdamW optimizer [50]. For learning, the rate of linear warm-up gradient updates is set to the maximum for the first 10% of the updates, while the weight decay is set to 0.01. Additionally, for the MNER task, we set the batch size to 8, the maximum sentence length to 128, and the learning rate to 3 × 10−5 and train the model for 15 epochs, with evaluation starting from the 10th epoch. In the MRE task, we set the batch size to 16, the maximum sentence length to 80, and the learning rate to 1 × 10−5 and train the model for 20 epochs, with evaluation starting from the 8th epoch. The assessment metrics employed in this research include accuracy, precision, recall rate, and F1 score [51].
3.3. Experimental Results of MNER and MRE Tasks
To validate the performance of our model, we conduct comparative analyses against several baseline models for both the MNER and MRE tasks.
We first compared our model with several classic pure text-based NER and RE models. The NER baselines contain (1) BiLSTM-CRF [12], which combines BiLSTM and CRF; (2) CNN-BiLSTM-CRF [13], which combines CNN and BiLSTM-CRF; (3) BERT [15], which employs a deep bidirectional Transformer architecture. The RE baselines involve (1) PCNN [52], which is a distant supervision relation extraction method; (2) MTB [22], which employs a training method maximizing cosine similarity; (3) PURE [53], which is a rule-based and text pattern-matching method.
Additionally, we compare our model with several competitive methods in the MNER and MRE domains. MNER baselines include (1) GVATT [54]; (2) AdaCAN [25]; (3) GVATT-BERT-CRF, which enhances the GVATT model by substituting the text encoder with BERT; (4) AdaCAN-BERT-CRF, which refines the AdaCAN model by replacing its text encoder with BERT; (5) UMT [28], which employs entity span detection techniques; (6) SMKG-Attention-CRF [30], which introduces image attribute modality; (7) HVPNet [33], which uses multiscale visual features as visual prefixes. MRE baselines include (1) VisualBERT [38], which inserts visual information into the input sequence of BERT; (2) BERT + SG [55], which uses two models to counter data bias; (3) UMT [28], which uses a unified multimodal transformer based on attention and gating mechanisms; (4) UMGF [56], which uses gating mechanisms and text-image alignment techniques; (5) MEGA [55], which uses a dynamic programming-based algorithm; and (6) HVPNet [33], which integrates multi-scale visual features into visual prefixes to alleviate modality noise.
As illustrated in Figure 4, we observe that during the training process, our models exhibit a stabilization of training and validation losses on both the Twitter-2015 and Twitter-2017 datasets after approximately 10 epochs. This observation implies that our models have attained a state of convergence on these datasets, yielding satisfactory performance. Similarly, in the case of the MNRE and FOOD datasets, the training and validation losses reached a stable state after around 15 epochs, suggesting that our models have also achieved laudable performance on this dataset.
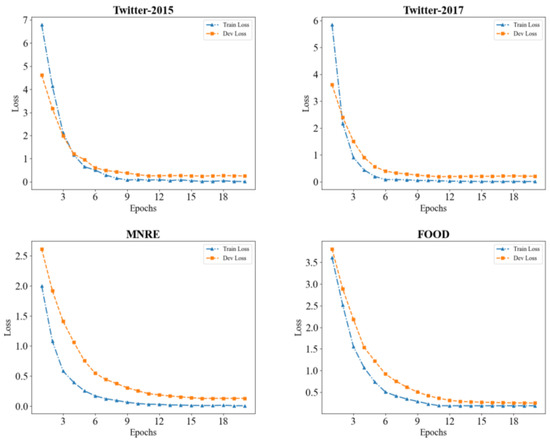
Figure 4.
The loss curves of three public datasets.
In Table 3 and Table 4, we evaluate the effectiveness of each model. Table 3 presents the evaluation results of the final performance of each model on the Twitter-2015 and Twitter-2017 datasets, while Table 4 shows the evaluation results of each model on the MNRE dataset. The evaluation results for the MNER task include the metrics of overall precision (P%), recall (R%), and micro-F1-score (F1%) for all models. For the MRE task, the evaluation results include the metrics of overall accuracy (Acc%), precision (P%), recall (R%), and micro-F1-score (F1%) for all models.
Table 3.
Overall MNER results.
Table 4.
Overall MNRE results.
From the preceding data, the following can be inferred:
- (1)
- Adopting BERT as a text encoder significantly improves the performance of NER and RE tasks compared to traditional BiLSTM and CNN models. For instance, BERT achieves a notable increase in F1 scores on the Twitter datasets. In RE tasks, models with BERT as a text encoder (PURE and MTB) outperform other models (PCNN) with F1 value improvements of 5.37% and 5.73%, respectively. The improvements highlight the importance of pre-trained BERT in NER and RE tasks.
- (2)
- Incorporating image information significantly enhances the performance of NER and RE tasks. Multimodal methods generally perform better than pure text methods in these tasks. In NER tasks, GVATT employs image information and achieves a 6.38% and 5.56% increase in overall F1 values compared to BiLSTM-CRF on two datasets. Meanwhile, AdaCAN demonstrates improvements of 6.27% and 5.84%. In RE tasks, adding image modality with UMT and UMGT results in a 2.24% and 4.07% increase in F1 values compared to the single modality PURE. The improvements further confirm that integrating visual and textual information can generally improve the performance of NER and RE models, emphasizing the importance of combining visual and textual information.
- (3)
- By adopting a visual description augmented integration mechanism to reduce image noise and adaptively integrate visual features into BERT, the performance of the VDAIN method is significantly improved. In the two tables, our model outperforms methods such as UMT and MEGA, which employ shallow attention alignment, particularly achieving notable progress in the MNRE task. The finding emphasizes the importance of eliminating irrelevant visual noise and multimodal information fusion strategies. It may be the challenge of optimizing the integration of visual and textual information to enhance the performance of multimodal methods across various tasks.
- (4)
- Introducing image descriptions is more effective in extracting key image information and reducing modality gaps. We find that models using visual features combined with image descriptions to generate semantic features perform significantly better than HVPNet and MEGA, which only utilize visual features. VDAIN attains state-of-the-art results on all three datasets, showcasing the efficacy of our approach. Specifically, compared to the second-ranked HVPNet model, VDAIN shows a 0.48% increase in overall F1 scores on the Twitter-2015 dataset, a 0.91% increase on the Twitter-2017 dataset, and a 0.69% increase on the MNRE dataset. The experimental findings suggest that incorporating image description generation allows the model to capture essential image information and reduce modality gaps.
- (5)
- Figure 5 illustrates the performance of various models in terms of F1 score when solely utilizing datasets related to food safety. For this study, we selected data on the theme of food safety from three publicly available datasets and constructed a new dataset named FOOD datasets. We compared our model, VDAIN, with four other models: UMT, MEGA, and HVPNet. The results demonstrated that VDAIN outperforms the other multimodal models. This further validates the efficacy of our proposed method in entity recognition and relation extraction from food safety-related data on social media. Notably, despite the smaller volume of the FOOD datasets, our model still manages to enhance its performance under low-resource conditions.
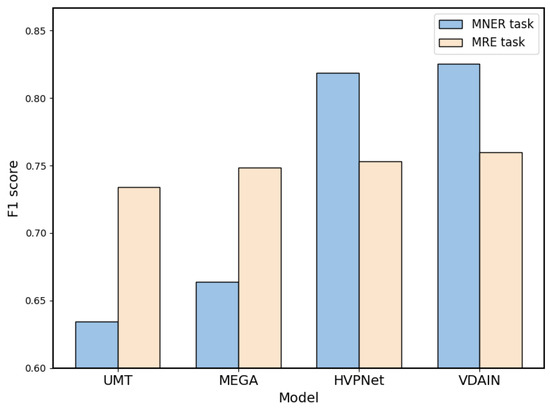 Figure 5. F1 scores for FOOD datasets in MNER and MRE tasks.
Figure 5. F1 scores for FOOD datasets in MNER and MRE tasks.
Despite the semantic features generated from image descriptions and those from text information residing within the same modality and effectively narrowing modality gaps, there are instances where the interpretations between the two do not perfectly align. This disparity can be attributed to the inherent complexities associated with transposing visual context onto textual descriptors. Furthermore, although our visual description augmented integration mechanism proficiently mitigates image noise, it sometimes fails to fully filter out irrelevant or misleading visual cues. This can potentially introduce inaccuracies in entity recognition and relation extraction. As a result, refining the transformation and fusion mechanisms between these two modalities could be a constructive direction for optimizing our model’s overall performance.
3.4. Ablation Study
We conduct three sets of ablation experiments on the Twitter-2015, Twitter-2017, and MNRE datasets to validate the effectiveness of the image description generation strategy, the visual description augmented integration network, and the different levels of the image encoder.
3.4.1. Analysis of the Effectiveness of Image Caption Generation
We conduct ablation experiments to verify the effectiveness of image description generation on the overall performance. As shown in Table 5, we introduce two approaches for a more in-depth evaluation. Specifically, “NoCap” removes all image descriptions, and “NoObj” removes image descriptions of the object detection images while retaining the original image descriptions. We can observe that the introduction of image description generation achieved the best results, with the F1 scores on the three datasets being 0.52%, 1.36%, and 2.7% higher than “NoCap” and 0.2%, 0.44%, and 0.57% higher than “NoObj”. Therefore, image description generation is a key component of VDAIN’s effectiveness. In particular, image descriptions can summarize the key information as well as complex semantics of images and effectively prompt information extraction.
Table 5.
The effectiveness of image captioning.
3.4.2. Analysis of the Effectiveness of Visual Description Augmented Integration Network
In this research, we present three approaches to demonstrate the efficiency of VDAIN. Specifically, the first method, “Direct”, aligns each layer of visual features from ViT and semantic features generated by image description directly with the corresponding layers in BERT. The second method, “Concatenate”, concatenates all visual features as well as the semantic features generated by image description and passes them through a linear layer. The third method, “Random”, randomly fuses each layer of visual features with the corresponding layers in BERT. Through these three methods, we can observe the effectiveness and flexibility of VDAIN in handling multimodal data.
As illustrated in Table 6, we note that the F1 scores on the three datasets, when utilizing the VDAIN, are 1.05%, 1.91%, and 3.22% higher than the “Direct” method. It is also 0.88%, 1.87%, and 3.79% higher than the “Concatenate” method, and 1.42%, 1.99%, and 2.98% higher than the “Random” method. Therefore, the visual description augmented integration network is a core component in achieving outstanding performance. Specifically, the visual description-enhanced fusion mechanism can adaptively merge various image features with the semantic features generated by image descriptions and match them with each layer of the BERT model. The strategy helps improve the performance of multimodal data processing and reduce the modality gap, further enhancing the understanding of images and key information.
Table 6.
The effectiveness of Visual Description Augmented Integration Network.
3.4.3. Analysis of the Effectiveness of Utilizing Various Layers of Image Encoder
To examine the impact of varying levels of image encoders, we carry out six ablation experiments. Specifically, the model Layer (1–12) uses 12 layers of the image encoder, and Layer (1–11) makes use of layers 1 to 11. Similarly, Layer (1–6) and Layer (6–12) apply layers 1 to 6 as well as layers 6 to 12. Furthermore, only the first layer and only the last layer are used for Layer (only1) and Layer (only12), respectively. As shown in Figure 6, without using the full-layer matching model, the F1 values of Layer (1–11), Layer (1–6), Layer (6–12), Layer (only1), and Layer (only12) decrease. The performance reduction is relatively small when using Layer (1–11), while it is more significant when using only the first or the last layer. This suggests that the visual features can provide support for semantic information in various levels of BERT, thereby enhancing the multimodal fusion effect. The F1 value decreases when only a portion of the layer is used. These experimental results further verify that visual information is distributed across the layers of the image encoder, and the visual knowledge contained in each layer is essential for improving the model’s performance during the multimodal fusion process. This also indicates that by analyzing and integrating different levels of visual features, semantic features generated from image descriptions, and semantic features of textual information, the relationship between images and text can be more effectively captured.
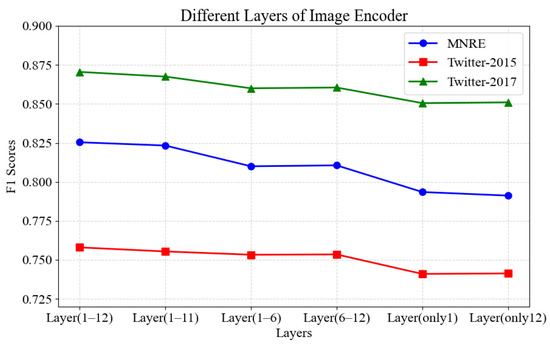
Figure 6.
Quantitative results of our method on the effectiveness of utilizing various layers of image encoder.
4. Conclusions
The MNER and MRE tasks play a vital role in accurately identifying and extracting entities and relationships related to food safety from a vast amount of social media text. This allows us to better monitor food safety opinion issues and provide early warning. Addressing the challenges posed by these tasks, we propose a model called VDAIN for MNER and MRE. The model employs visual information from a visually pre-trained model as an auxiliary, integrating image description generation and visual information through adaptive fusion. The approach aims to address modality noise and modality gap issues in MNER and MRE tasks. We conduct a large number of comparative experiments to validate the effectiveness of the proposed model and achieve optimal experimental results in three benchmark tests. This superior performance also extends to the FOOD datasets, where it showcases the best outcome. Moreover, we carry out several ablation experiments to demonstrate the effectiveness of each module of VDAIN. A key challenge in research is to explore how to more effectively alleviate the modality gap and filter crucial information in multimodal pre-trained models based on the Transformer framework. Despite our model’s success, there are limitations, such as occasional inaccuracies in entity recognition and relation extraction due to residual visual noise and modality translation challenges. Therefore, we leave these directions for future studies.
Author Contributions
Conceptualization, Y.W. and M.Z.; methodology, W.D.; software, Q.Z.; validation, Y.C., W.D. and Y.W.; formal analysis, Y.W.; investigation, W.D.; resources, J.K.; data curation, Y.C.; writing—original draft preparation, M.Z.; writing—review and editing, J.K.; visualization, J.K.; supervision, Q.Z.; project administration, Q.Z.; funding acquisition, M.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Technology R&D Program of China, No. 2021YFD2100605; the Natural Science Foundation of China, No. 62006008; Beijing Natural Science Foundation, No. 4202014; Project of Beijing Municipal University Teacher Team Construction Support Plan, No. BPHR20220104; the Humanity and Social Science Youth Foundation of Ministry of Education of China, grant number 20YJCZH229.
Data Availability Statement
Data were obtained from third party and are available at https://github.com/zjunlp/HVPNeT (accessed on 1 January 2023).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Koklu, M.; Cinar, I.; Taspinar, Y.S. Classification of rice varieties with deep learning methods. Comput. Electron. Agric. 2021, 187, 106285. [Google Scholar] [CrossRef]
- Valdés, A.; Álvarez-Rivera, G.; Socas-Rodríguez, B.; Herrero, M.; Ibáñez, E.; Cifuentes, A.J.A.C. Foodomics: Analytical opportunities and challenges. Anal. Chem. 2021, 94, 366–381. [Google Scholar] [CrossRef] [PubMed]
- Kong, J.; Wang, H.; Wang, X.; Jin, X.; Fang, X.; Lin, S. Multi-stream hybrid architecture based on cross-level fusion strategy for fine-grained crop species recognition in precision agriculture. Comput. Electron. Agric. 2021, 185, 106134. [Google Scholar] [CrossRef]
- Kong, J.; Wang, H.; Yang, C.; Jin, X.; Zuo, M.; Zhang, X.J.A. A spatial feature-enhanced attention neural network with high-order pooling representation for application in pest and disease recognition. Agriculture 2022, 12, 500. [Google Scholar] [CrossRef]
- Schütze, H.; Manning, C.D.; Raghavan, P. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 39. [Google Scholar]
- Jin, X.-B.; Wang, Z.-Y.; Kong, J.-L.; Bai, Y.-T.; Su, T.-L.; Ma, H.-J.; Chakrabarti, P. Deep Spatio-Temporal Graph Network with Self-Optimization for Air Quality Prediction. Entropy 2023, 25, 247. [Google Scholar] [CrossRef] [PubMed]
- Nadeau, D.; Sekine, S.J.L.I. A survey of named entity recognition and classification. Lingvisticae Investig. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Jin, X.-B.; Wang, Z.-Y.; Gong, W.-T.; Kong, J.-L.; Bai, Y.-T.; Su, T.-L.; Ma, H.-J.; Chakrabarti, P. Variational Bayesian Network with Information Interpretability Filtering for Air Quality Forecasting. Mathematics 2023, 11, 837. [Google Scholar] [CrossRef]
- Kong, J.-L.; Fan, X.-M.; Jin, X.-B.; Su, T.-L.; Bai, Y.-T.; Ma, H.-J.; Zuo, M. BMAE-Net: A Data-Driven Weather Prediction Network for Smart Agriculture. Agronomy 2023, 13, 625. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end sequence labeling via bi-directional lstm-cnns-crf. arXiv 2016, arXiv:1603.01354. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Zheng, Y.Y.; Kong, J.L.; Jin, X.B.; Wang, X.Y.; Zuo, M. CropDeep: The Crop Vision Dataset for Deep-Learning-Based Classification and Detection in Precision Agriculture. Sensors 2019, 19, 1058. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5754–5764. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-bert: Enabling language representation with knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 2901–2908. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced language representation with informative entities. arXiv 2019, arXiv:1905.07129. [Google Scholar]
- Von Däniken, P.; Cieliebak, M. Transfer Learning and Sentence Level Features for Named Entity Recognition on Tweets. In Proceedings of the NUT@EMNLP, 2017, Copenhagen, Denmark, 7 September 2017. [Google Scholar]
- Xie, J.; Zhang, K.; Sun, L.; Su, Y.; Xu, C. Improving NER in Social Media via Entity Type-Compatible Unknown Word Substitution. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7693–7697. [Google Scholar]
- Soares, L.B.; FitzGerald, N.; Ling, J.; Kwiatkowski, T. Matching the blanks: Distributional similarity for relation learning. arXiv 2019, arXiv:1906.03158. [Google Scholar]
- Yamada, I.; Asai, A.; Shindo, H.; Takeda, H.; Matsumoto, Y. LUKE: Deep contextualized entity representations with entity-aware self-attention. arXiv 2020, arXiv:2010.01057. [Google Scholar]
- Moon, S.; Neves, L.; Carvalho, V. Multimodal named entity recognition for short social media posts. arXiv 2018, arXiv:1802.07862. [Google Scholar]
- Zhang, Q.; Fu, J.; Liu, X.; Huang, X. Adaptive co-attention network for named entity recognition in tweets. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Arshad, O.; Gallo, I.; Nawaz, S.; Calefati, A. Aiding intra-text representations with visual context for multimodal named entity recognition. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 337–342. [Google Scholar]
- Yu, J.; Jiang, J.; Yang, L.; Xia, R. Improving multimodal named entity recognition via entity span detection with unified multimodal transformer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Wu, Z.; Zheng, C.; Cai, Y.; Chen, J.; Leung, H.-f.; Li, Q. Multimodal representation with embedded visual guiding objects for named entity recognition in social media posts. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1038–1046. [Google Scholar]
- Chen, D.; Li, Z.; Gu, B.; Chen, Z. Multimodal named entity recognition with image attributes and image knowledge. In Proceedings of the Database Systems for Advanced Applications: 26th International Conference, DASFAA 2021, Taipei, Taiwan, 11–14 April 2021; Part II 26. pp. 186–201. [Google Scholar]
- Zheng, C.; Wu, Z.; Wang, T.; Cai, Y.; Li, Q. Object-aware multimodal named entity recognition in social media posts with adversarial learning. IEEE Trans. Multimed. 2020, 23, 2520–2532. [Google Scholar] [CrossRef]
- Xu, B.; Huang, S.; Sha, C.; Wang, H. MAF: A General Matching and Alignment Framework for Multimodal Named Entity Recognition. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 1215–1223. [Google Scholar]
- Chen, X.; Zhang, N.; Li, L.; Yao, Y.; Deng, S.; Tan, C.; Huang, F.; Si, L.; Chen, H. Good Visual Guidance Makes A Better Extractor: Hierarchical Visual Prefix for Multimodal Entity and Relation Extraction. arXiv 2022, arXiv:2205.03521. [Google Scholar]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.-J.; Chang, K.-W. Visualbert: A simple and performant baseline for vision and language. arXiv 2019, arXiv:1908.03557. [Google Scholar]
- Li, G.; Duan, N.; Fang, Y.; Gong, M.; Jiang, D. Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11336–11344. [Google Scholar]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F. Oscar: Object-semantics aligned pre-training for vision-language tasks. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XXX 16. pp. 121–137. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning transferable visual models from natural language supervision. In Proceedings of the International conference on machine learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Luo, Y.; Ji, J.; Sun, X.; Cao, L.; Wu, Y.; Huang, F.; Lin, C.-W.; Ji, R. Dual-level collaborative transformer for image captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 2286–2293. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1316–1324. [Google Scholar]
- Devlin, J.; Gupta, S.; Girshick, R.; Mitchell, M.; Zitnick, C.L. Exploring nearest neighbor approaches for image captioning. arXiv 2015, arXiv:1505.04467. [Google Scholar]
- Faghri, F.; Fleet, D.; Kiros, J.; Fidler, S.V. Improving visual-semantic embeddings with hard negatives. arXiv 2017, arXiv:1707.05612. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Shen, Y.; Ji, L. Geometry Attention Transformer with position-aware LSTMs for image captioning. Expert Syst. Appl. 2022, 201, 117174. [Google Scholar] [CrossRef]
- Tang, S.; Wang, Y.; Kong, Z.; Zhang, T.; Li, Y.; Ding, C.; Wang, Y.; Liang, Y.; Xu, D. You Need Multiple Exiting: Dynamic Early Exiting for Accelerating Unified Vision Language Model. arXiv 2022, arXiv:2211.11152. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Loshchilov, I.; Hutter, F.J. Decoupled weight decay regularization. In Proceedings of the 7th International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Taspinar, Y.S.; Koklu, M.; Altin, M. Classification of flame extinction based on acoustic oscillations using artificial intelligence methods. Case Stud. Therm. Eng. 2021, 28, 101561. [Google Scholar] [CrossRef]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1753–1762. [Google Scholar]
- Zhong, Z.; Chen, D. A frustratingly easy approach for entity and relation extraction. arXiv 2020, arXiv:2010.12812. [Google Scholar]
- Lu, D.; Neves, L.; Carvalho, V.; Zhang, N.; Ji, H. Visual attention model for name tagging in multimodal social media. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1: Long Papers. pp. 1990–1999. [Google Scholar]
- Zheng, C.; Wu, Z.; Feng, J.; Fu, Z.; Cai, Y. Mnre: A challenge multimodal dataset for neural relation extraction with visual evidence in social media posts. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Zhang, D.; Wei, S.; Li, S.; Wu, H.; Zhu, Q.; Zhou, G. Multi-modal graph fusion for named entity recognition with targeted visual guidance. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 14347–14355. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).