1. Introduction
As a necessary means to maintain the long-term stable transmission of electric power, the UAV (Unmanned Aerial Vehicle) inspection technology equipped with deep learning object detection has been effective in improving the automation of transmission line inspection, which is based on a large number of inspection images [
1,
2,
3]. However, due to various factors such as temperature, weather, and human fallibility, there are many types of power defects, especially the scarcity of defect samples of key components such as insulators, vibration damper, and pins, resulting in low detection precision of these kinds of defects by object detection algorithms based on deep learning, which poses great challenges for the pilotless inspection of transmission lines [
4].
Few-shot learning is a method to solve a problem with few training samples in the target domain, which can alleviate problems such as overfitting and the inability to converge deep-learning models in the case of few samples [
5] and mainly contains metric learning, data augmentation, fine-tuning, meta-learning, and other methods [
6]. Among them, data augmentation is the most commonly used technology for dealing with few-shot problems; for example, Bayraktar et al. [
7] proposed a method to optimize the route of the target ground vehicle benefit from some geometric transformations, effectively expanding the sample and enhancing the segmentation ability of the model. In addition, [
8] presents a method to improve the performance of surface defect detection by combining GAN (Generative Adversarial Networks) [
9] with classical methods. The synthetic samples generated by the GANs are then used to train a deep convolutional neural network (CNN) to perform image segmentation and detect defects. In terms of metric learning, Hsieh et al. [
10] proposed a metric-based method with margin-ranking loss, which calculates the similarity between the features of region proposal and the features of ground truth, assisting the model in classifying few-shot objects. Li et al. [
11] proposed the Deep Nearest Neighbor Neural Network (DN4) that replaces image-level feature measurements with local descriptors from images to classes in the final layer. When mapping features for query samples, DN4 calculates a similarity for each spatial feature and sums up all spatial similarities to obtain the similarity of the query sample. In terms of fine-tuning, Wang et al. [
12] improved Faster R-CNN [
13] by first training with base-class data, and in the fine-tuning stage, they froze the parameter weights of the early network and fine-tuned the top-level classifier and regressor with a balanced subset composed of base and novel classes. Sun et al. [
14] trained the base-class data first, then fine-tuned it with a small amount of mixed data from base and novel classes to achieve few-shot object detection. In terms of meta-learning, Ye et al. [
15] combined the adaptive algorithm Transformer [
16] with the Set-to-Set function to map instances to the space of the corresponding task and construct different internal correlations within the set, enabling the model to perform specific learning for the object. Zhang et al. [
17] proposed a meta-learning-based search and decoding method and introduced the Meta Navigator framework to find effective parameter adaptation strategies and apply them to different stages of the model to achieve few-shot classification.
At present, there are few studies on few-shot object detection for transmission lines, and the method of data augmentation is usually chosen to solve the problem. For example, Xu et al. [
18] used GAN to expand the samples of small fittings, and Cui et al. [
19] supplemented insulator defect samples by improving Cyclic-Consistent Generative Adversarial Networks (CycleGAN) [
20]. However, such methods based on virtual sample construction have limited improvement in the detection precision of the classes with few samples and require high computing power and data quality in the source domain, as well as poor generalization, and can only perform data enhancement for a certain type of component defects, which requires repeated data expansion and model training operations when new few-shot detection tasks are added in subsequent inspection work. Choosing metric learning to measure different components is easy to operate, but the global features of defective components and normal components are more similar, resulting in metric learning that cannot solve the core problem of defect detection. Fine-tuning is suitable for detection tasks in which the base class is similar to the novel class. Zhang et al. [
21] conducted pre-training on the YOLOv3 [
22] model using the publicly available ImageNet dataset. Subsequently, they fine-tuned the model using a small number of vibration damper and wire clamp samples to achieve few-shot detection. On the other hand, Zhai et al. [
23] pre-trained Faster R-CNN on artificial samples and fine-tuned it using insulator defects. Ultimately, they achieved a detection accuracy of 62.7% mAP for insulator defects with a real sample size of 184. However, the generalization of fine-tuning is poor and will lead to a decrease in detection precision when the type of components to be detected is changed. In contrast, by dividing the training data into several different small tasks to train the model, meta-learning not only improves the generalizability of the model under few sample conditions but also the training strategy of using fine-tuning for novel classes is applicable to defect detection tasks in which normal components are similar to defective components.
Our goal is meta-learning-based object detection for improving the efficiency of transmission line defect detection tasks under insufficient sample size conditions by combining meta-learning with defect detection. Specifically, we propose a meta-learning object detection algorithm (Meta PowerNet) for few-shot defect detection of transmission lines. First, a meta-attention region proposal network is designed to use a support set with prior knowledge and low-level features with detailed information of the query set to improve the quality of the anchor boxes generated by the region’s proposal network. Second, for the characteristics of transmission line defect detection, a defect feature reconstruction module is designed to reconstruct the support set meta-features according to normal and defective components, which not only reduces the computation of fusion meta-features of the support set and ROI features of the query set but also improves the fine-tuning effect of the detection head in the stage of meta-test. Third, this method can detect seven classes, including an insulator, vibration damper, and pin and their defects. Finally, the Meta-Attention Region Proposal Network can be embedded in other meta-learning object detection frameworks to effectively improve the detection precision.
The rest of this study is organized as follows:
Section 2 discusses the related works on meta-learning and meta-learning object detection.
Section 3 explains the details for each module. In
Section 4, the implementation is explained, including the dataset; experimental parameters; evaluation indicators; and the results of ablation, comparison, and expanding the experiment. Finally,
Section 5 concludes the paper and puts forward prospects for future work.
3. Method
3.1. Overall Architecture
The key to applying meta-learning to defect detection is how to use a small number of defect samples to make the model learn the differences between normal components and defective components. Therefore, our method focuses on learning the features of defective components and the differences between them and normal components. Considering the regression problem in meta-learning object detection, a two-stage object detection method is adopted in our method, detecting the targets from coarse to fine granularity.
The framework of the Meta PowerNet model is shown in
Figure 2, which mainly consists of four parts: feature extraction network, region proposal module, meta-learner, and predictor head. The feature extraction network is responsible for extracting features from the support set and the query set. The region proposal module, with MA-RPN (Meta-Attention Region Proposal Network) as its core, generates proposal regions of query images with fusing support set features, which could reduce noise in proposal regions. The meta-learner is used to learn the meta-features of each class in the support set as prior information to assist the model in detecting the target in the query set. In addition, a defect feature reconstruction module is designed to enhance the feature representation of defects in meta-features. The predictor head is responsible for classifying and regressing the proposal region features of the query set to generate the final detection results. In addition, the normal components with sufficient samples are selected as base classes, while the defect components with few samples are treated as novel classes.
3.2. Feature Extraction Network
In this paper, we adopt the Siamese Neural Network [
32] as the backbone to extract features from the query and support sets. This method is a commonly used approach for meta-learning-based object detection [
25,
27,
31]. The input image of the query set is the original image that has been resized to a uniform size. After extracting the features using the ResNet101 backbone network, the image features at the res4 stage are used as the output.
As another branch of the Siamese neural network, the backbone network for extracting support set features also uses ResNet101 and shares weights with the backbone network for the query set. Moreover, since the background information in the support set images is useless for the model training, we crop the target object in support image with 16-pixel image context, zero-padded, and then resized to a square image of 320 × 320.
3.3. Region Proposal
Region Proposal Network (RPN) is mainly used to generate anchor boxes for the predictor head and to perform foreground–background classification on these boxes. However, in the meta-test of meta-learning object detection, the training mode of RPN is fine-tuned based on the parameters learned in meta-training. Due to the small number of samples, RPN has limited regression ability for the new class targets in this way, resulting in low-quality anchor boxes for new classes and affecting the detection of new class targets by the predictor head.
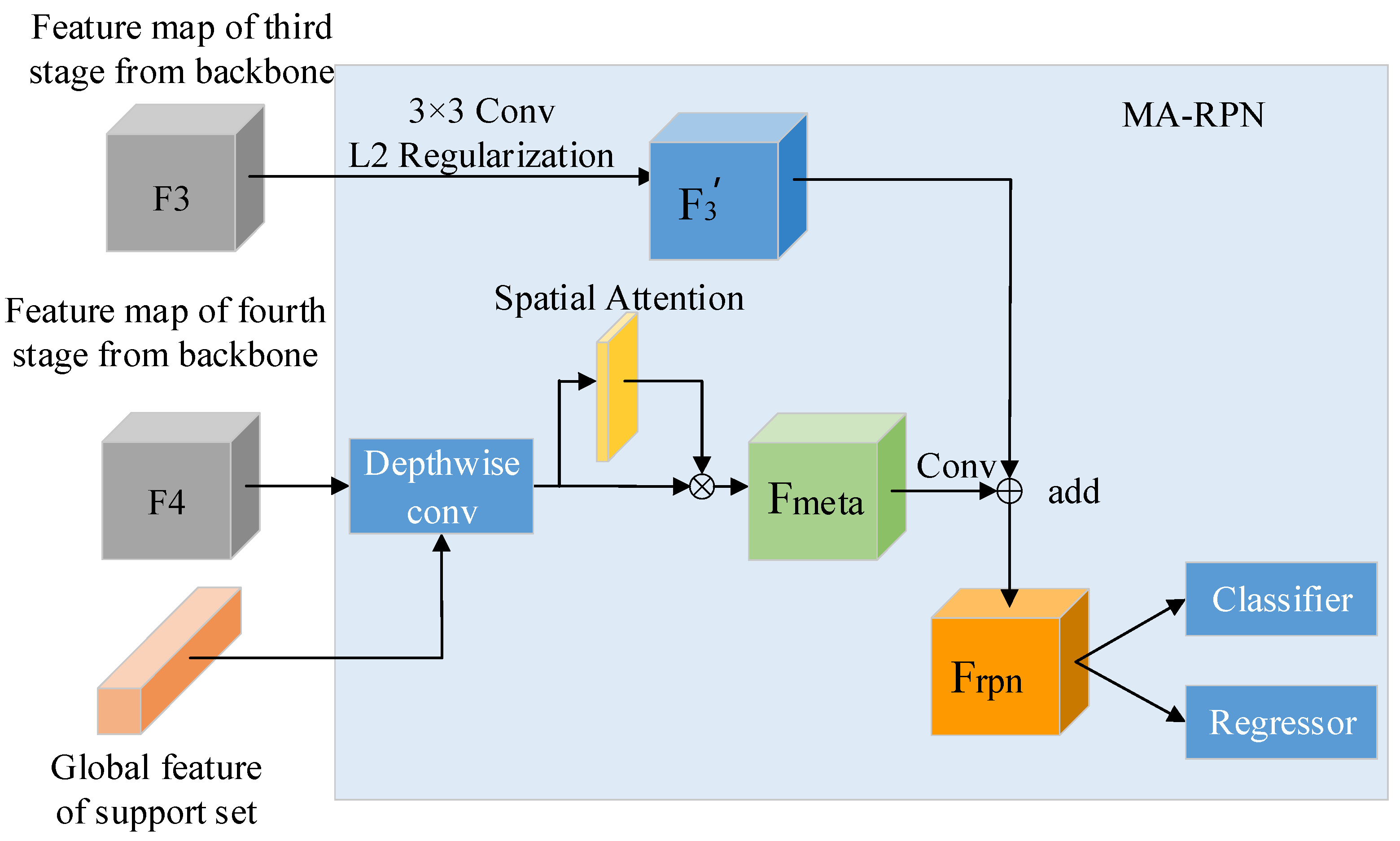
We propose the Meta-Attention Region Proposal Network (MA-RPN), which utilizes support set features to enhance the expression ability of target classes in query set features and increases the model’s attention to foreground regions through spatial attention mechanism. Finally, by combining image details, the module could generate higher quality and more effective anchor boxes.
As shown in
Figure 3, in order to activate the important feature representation of the support set classes in query features, the global feature of the support set, which is obtained through global average pooling with support feature
, is fused with the query feature
by MA-RPN. The specific method to obtain the global feature of support set will be introduced in the next section. More specifically, we use depth-wise cross-correlation [
33] as the fusing method, the global feature of support set is used as a convolutional kernel to reweight the query set features
, and the reweighted query feature
can guide MA-RPN to produce anchor boxes relevant to classes of support set. Fusing process is shown in Equation (1).
Subsequently, MA-RPN trains a spatial weight matrix to weight the reweighted query features through spatial attention mechanism, highlighting the position representation of foreground objects in the features; we mark it as . Unlike traditional spatial attention, the input features here are the reweighted query features, which not only enhance the region proposal ability in meta-training but also carry more effective new-class features to participate in the spatial attention in meta-test, which can effectively improve the efficiency of fine-tuning and generate more accurate anchor boxes for new-class objects.
In addition, in order to reduce the loss of detailed information in the feature extraction network and improve the accuracy in predicting positions of anchor boxes, we also involve the low-level feature in the generation process of anchor boxes. First, we feed the query set feature
, which carries more detailed information from the third level of backbone to a convolutional layer, which has a convolution kernel with a size of 3×3, to adjust its dimension and size. After the L
2 regularization process, the new feature
is output. Then, the feature
is fused with it, so that the model can generate more effective candidate boxes by combining high-level semantic information with low-level detail information. The fusion method used here is inspired by the Feature Pyramid Network, where features
and
are added layer by layer to obtain feature
, which is used as the feature layer for anchor boxes extraction. The formula is shown in Equation (2). Subsequently, anchor boxes are classified as foreground or background, and their bounding boxes are regressed through the same operations as in the original RPN. Finally, a specified number and size of anchor boxes are output and mapped to feature
via ROI Align.
3.4. Meta-Learner
As the most important module in the meta-learning-based object detection model, the meta-learner generates class prototypes as meta-features for each target class by extracting sufficient support set features to assist the model in classifying ROI features of query set. However, the overall features of the defective components of the power transmission line are similar to those of the normal components. The overall features of normal components have already been learned in meta-training. However, treating novel classes as completely new classes unrelated to base class in meta-test not only results in learning insufficiently the features of defective parts but also adds unnecessary redundancy to the predictor head.
We designed a meta-learner with the Defect Feature Reconstruction Module (DFRM) as its core according to the characteristics of defect detection in power transmission lines. By learning the channel differences between normal and defective components, the meta-learner reconstructs the meta-features to improve the attention of the predictor head to the channel relevant to defect class in the query set ROI features.
As shown in
Figure 4, we perform global average pooling on the support set features to obtain a one-dimensional vector
, which is used as channel-level weights to reweight the original support set feature and enhance the representation of potential important features. Then, the output features are fed into the global average pooling layer to be compressed into one-dimensional features as meta-features, which will conduct channel-wise dot product with the query set ROI features in order to achieve channel feature selection. The one-dimensional vector
is the support set one-dimensional vector mentioned in the previous section, and the reason for choosing global average pooling to squeeze features is that this operation can retain more class-related information. To prevent confusion between meta-features of different classes, which would lead to ambiguity in classification task of predictor head, we adopted the Meta Loss from Meta R-CNN. The meta-features fed into a fully connected network for classification and adjusted the weights of the meta-learner through the feedback from loss function to enhance the distinguishability between different meta-features.
To improve the detection of differences between normal and defective components in the same category, the differences mainly exist in a few channels of image features. In the meta-testing phase, we proposed the Defect Feature Reconstruction Module (DFRM) to calculate the difference values between the corresponding meta-features of normal and defective components on each channel. The DFRM multiplies the vector of difference values with the meta-feature of normal components to enhance the values corresponding to channels with different values that are large. After fusing with the ROI features of query set, the predictor head can pay more attention to the channels related to defects.
First, the element-wise subtraction between normal and defective meta-features is computed, followed by taking absolute value to obtain the initial difference values. Then, through standardization and
ReLU as activation function, the small difference values are suppressed to zero as noise, which could reduce their impact on distinguishing the defect-related features in predictor head. The formula is shown in Equation (3), where
represents the meta-feature of base class,
refers to the meta-feature of novel class, and
represents the reconstructed meta-feature.
3.5. Predictor Head
We adopt the most commonly used predictor head in current two-stage object detection algorithms, which is the predictor head in Faster R-CNN. It consists of a classification branch and a regression branch, and both branches process ROI features through fully connected layer with activation functions to output the classification scores and bounding box coordinates of the object regions in query set image. The loss function for the classification is cross-entropy loss, and Smooth L1 loss is the loss function of regression branches. Finally, the total loss function of our model consists of classification loss
and regression loss
of RPN, classification loss
and regression loss
of predictor head, and meta-loss
, as shown in Equation (4).
Due to the high similarity between the normal components and the defect components, meta-test phase takes the training strategy of that fine-tuning the predictor head based on the pre-trained model in meta-training phase. This approach reduces computation while maintaining detection accuracy for the base class and avoids catastrophic forgetting caused by the introduction of novel class data.
4. Experiment
4.1. Dataset
We validate the model’s detection effect using both a self-built few-shot defect dataset on power transmission lines and a public dataset. The self-built dataset includes 3845 images of three important components in power transmission lines, namely, an insulator, vibration damper, and pin, as well as 571 corresponding images of defective components covering four types of defects, including insulator self-explosion, insulator damage, damper missing, and pin missing. The training set, validation set, and test set are divided in a ratio of 7:2:1. In addition, according to the few-shot object detection dataset standard, we selected 30 objects with more obvious features for each class in the above training dataset to construct a few-shot dataset. Specifically, seven few-shot annotation files corresponding to each class are provided to generate support set data for the meta-learner. Since we plan to experiment with 30 shots of each class, every few-shot annotation file contains several image names, which include 30 annotations of the corresponding class. As multiple objects may be selected in one image, the few-shot training dataset consists of 141 images. An example of the power transmission line dataset is shown in
Figure 5.
For the public dataset, we used the PASCAL VOC2007 few-shot detection dataset, which contains 20 common classes in natural scenes, such as a person, bicycle, bus, bird, and sofa. Fifteen of these classes were selected as base classes, while the other five were selected as novel classes. This dataset is the same as the original PASCAL VOC2007, except it includes 20 few-shot annotation files that correspond to each class.
4.2. Implementation
The experimental hardware configuration in this study consisted of 16 GB memory, an Intel i7-6800K CPU, and an NVIDIA GeForce RTX 3090 GPU. The software configuration included an Ubuntu 18.04 operating system, CUDA 11.3, PyTorch 1.10.2, as well as the object detection training frameworks mmdetection and mmfewshot for few-shot object detection training.
The training process adopts the Stochastic Gradient Descent (SGD) algorithm to optimize the model parameters. The input image size is uniformly adjusted to 1200 × 800 pixels, and the batch size is set to four. In the meta-training phase, normal components are used as the base class for training, with an initial learning rate of 0.02, weight decay rate of 0.002, momentum of 0.9, and 15,000 iterations of training for each batch. For each base class (insulator, vibration damper, and pin), 200 objects are randomly selected as training samples from the training set and only one object is taken from each image. In the meta-test phase, normal components (base class, including insulator, vibration damper, and pin) and defect components (new class including insulator self-explosion, insulator damage, damper missing, and pin missing) samples are mixed to feed into the model for training. A total of 30 objects are selected as support set training samples for each class, and the number of iterations is set to 1000. Other parameters are the same as in the meta-training phase. In addition, the validation set and test set divided in
Section 3.1 are used for both the meta-training phase and meta-test phase. To ensure the accuracy of the experiment, only the annotated boxes related to the training classes are retained for evaluation metric calculation during validation and testing. For example, only the annotated boxes of the base class are treated as ground truth in the evaluation of the meta-training phase, while in the meta-test phase, annotated boxes of both the base class and novel class participate in the calculation of evaluation.
4.3. Evaluation Indicators
We evaluate the detection performance using commonly used evaluation metrics in object detection and few-shot object detection, namely
AP50 and
mAP (Mean Average Precision).
AP50 represents the average precision calculated at an IOU threshold of 50%, as shown in Equation (7).
In addition, following the widely used standard in few-shot object detection, we set the support set sample size to 1, 5, and 10 in each training task to evaluate the performance of the MA-RPN with the public dataset under different training conditions.
4.4. Performance in Difference Hyperparameters
In order to fully exploit the performance of the model and verify the effectiveness of our method, we investigated the performance of the model under different optimization methods and learning rates at 30-shot. The experimental results are shown in
Table 1.
We found that using Meta-SGD [
34], which can change the update direction and learning rate, optimizes the model and performs better than using SGD with a fixed learning rate. In the comparison of the results of using SGD with different learning rates, the learning rate of 0.02 is optimum. In order to effectively compare with other few-shot learning algorithms, in the subsequent experiments, the model will use the optimal learning rate of 0.02 during training. However, if the best detection performance is desired, the Meta-SGD method should be used to optimize the model.
4.5. Ablation
We conducted ablation experiments on MA-RPN and the feature reconstruction module DFRM. For the ablation experiment on MA-RPN, the traditional RPN structure was used to generate proposal regions instead of MA-RPN. For the ablation experiment on the DFRM, the original meta-features and ROI features from the query set were directly fused during the meta-test phase. The results are shown in
Table 2. It can be seen that adding MA-RPN alone increased the mAP of defect components by 1.1%, and the defect detection performance of small-sized components such as pins was significantly improved, demonstrating that MA-RPN can not only effectively reduce noise in anchor boxes but can also generate more accurate candidate regions for small target objects by introducing low-level details. After adding the DFRM alone, the detection mAP increased by 2.0%, which was a significant improvement. This suggests that reconstructing meta-features based on the differences between defect and normal component features helps the model focus on defect-related features during classification in predictor head. Finally, the best detection performance was achieved with the model that combined both modules, verifying that the two modules do not conflict with each other and do not affect detection accuracy.
4.6. Comparision Experiment
We compared the proposed detection algorithm with other mainstream few-shot object detection algorithms with a self-built few-shot defect dataset on a power transmission line; the results are presented in
Table 1 for comparison. The training parameters of each model refer to the optimized experimental parameters in the mmfewshot algorithm framework, ensuring that the models achieve optimal performance. The detection results are shown in
Figure 6.
Table 3 presents and compares the detection performance of the proposed detection algorithm with other mainstream few-shot object detection algorithms based on the fully trained models. The following conclusions can be drawn: (1) Our proposed method achieved the highest overall mAP among mainstream methods, with significant performance improvements, indicating that Meta PowerNet is more suitable for defect detection tasks of transmission lines under small sample conditions. Specifically, the detection accuracy of normal components such as insulators and vibration dampers is slightly improved compared to other methods, but the detection performance of defect components such as insulator self-explosions and missing vibration dampers is significantly better than other methods, indicating that the main advantage of our method compared to other methods is the high detection accuracy of defect parts. (2) Meta PowerNet also performed well in detecting pins and pins missing, indicating that the model has better detection performance for small target objects and can be used for the defect detection of components with small sizes on transmission lines. (3) When detecting different types of defects of the same component, such as insulator self-explosion and insulator damage, our proposed method also demonstrated good discrimination.
4.7. Expand
This experiment extends MA-RPN to Meta R-CNN and Attention RPN models, both of which are also meta-learning-based object detection algorithms. The PASCAL VOC2007 split1 few-shot dataset was used for training and testing. The experimental results are compared in
Table 4.
We compared Meta R-CNN and Attention RPN models with and without the MA-RPN module under the conditions with 1, 5, and 10 support samples per class. The results showed that MA-RPN improved the detection precision of both models by 0.6% and 0.3% for 1-shot, 1.4% and 0.9% for 5-shot, and 0.5% and 0.4% for 10-shot. The results indicating that the improvement was weak under 1-shot but most significant under 5-shot. As for the 10-shot condition, the performance gain began to decrease due to the insufficient feature extraction of the meta-learner and the fine-tuning effect of the RPN. Overall, the results demonstrated the general applicability of the MA-RPN module for the two models under different support sample conditions.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}