In this section, we provide the definitions for some concepts that will be used in the remainder of the paper. The proposed parallel algorithm will also be explained in detail.
3.2. Grouping Strategy
Data partitioning is the premise of the parallel algorithm. An effective data partitioning method can greatly reduce the data communication between different slave nodes, thereby reducing the parallel computing time. Based on the above findings, the grouping strategy (GS) of PCFMIS used to divide all the trees in original data set D into different groups is described below:
(1) If given m slave nodes, we should divide all the trees in D into m groups, and the number of the group is denoted as . For the edge (x,y) in D, divide (x,y) into the set ,.
(2) For , all the edges in may belong to several according to (1). Take the minimum of these k as the of , = min k, so is put into the group which = min k. Then, for , cut the edges which belong to . Some new trees will appear after cutting edges.
(3) For these new trees , repeat (2) until no new trees are produced.
(4) For , repeat (2) and (3).
(5) All the trees in original data set D are divided into different groups, and the different groups will be put in different slave nodes.
Definition 6. Related Tree. Given a tree , for , there is . min k is the minimum of k. When , T is a related tree of , denoted as . The set of t is denoted as .
Property 1. According to grouping strategy, a tree in original data set only belongs to one group.
Property 2. According to grouping strategy, if , all will be put into the group which .
According to Property 1, the trees in the original data set are grouped into different groups, which can reduce the scale of the data each slave node needs to process. Although in (2), new trees may be generated during the grouping process, the new trees are trimmed and less complex than the original tree.
We can conclude from Property 2, for , all the induced subtrees of containing can be found in the group in which . So frequent induced subtrees of containing can be found only in group k instead of the whole original data set. This avoids communication between groups and realizes real parallelism.
Definition 7. Frequent Edge Degree. , the frequent edge degree of is the number of times appears in D, denoted as .
How to divide the edge into set in (1) directly affects the of . One feasible method is described below:
Given an evenly divided interval
,
,
,
. If
, the edge
is divided into
, then
will be put into the group in which
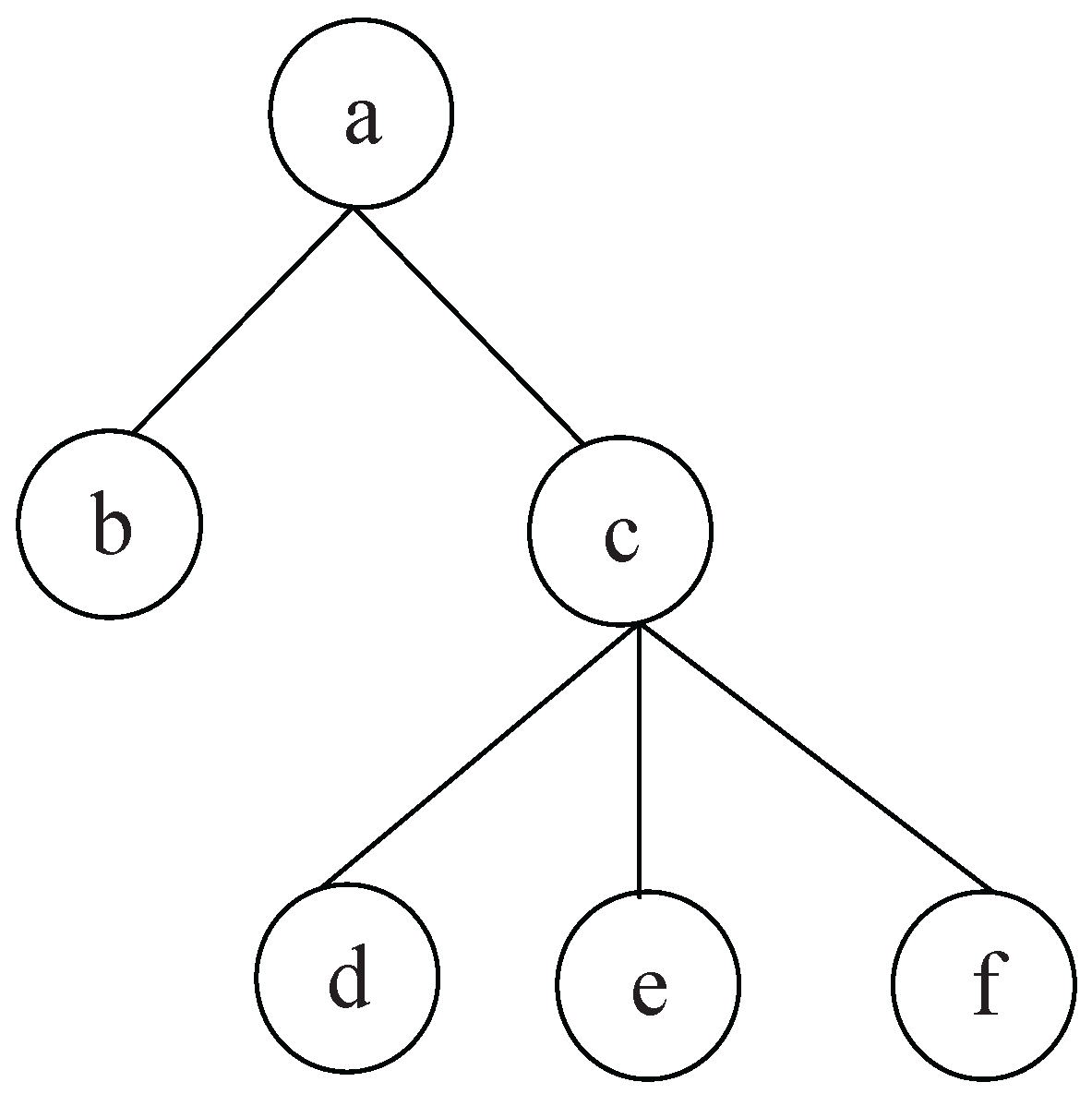
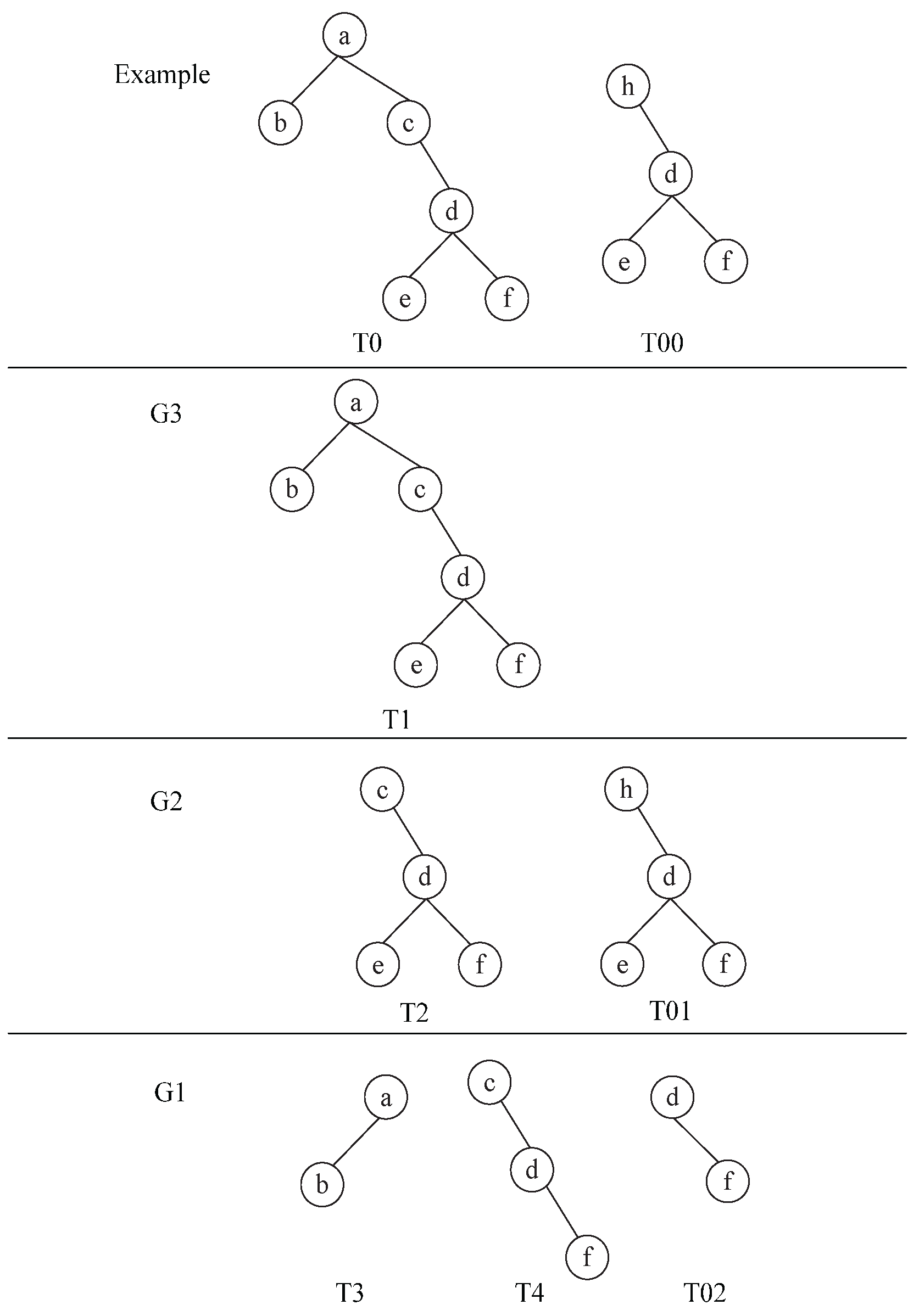
. For example, in
Figure 2, suppose that the number of slave nodes is 3. Divide the trees
into 3 groups
. Given dividing interval
,
.
,
,
,
, so
are divided into
;
are divided into
;
is divided into
. Take
in
Figure 2 as an example. For
,
(in
Figure 2) is divided into
. Then delete
from
and cut
. For
,
(
in
Figure 2) are divided into
. Then delete
from
and cut
. For
,
(
in
Figure 2),
(
in
Figure 2) and
(
in
Figure 2) are divided into
.
are obtained after applying GS on
.
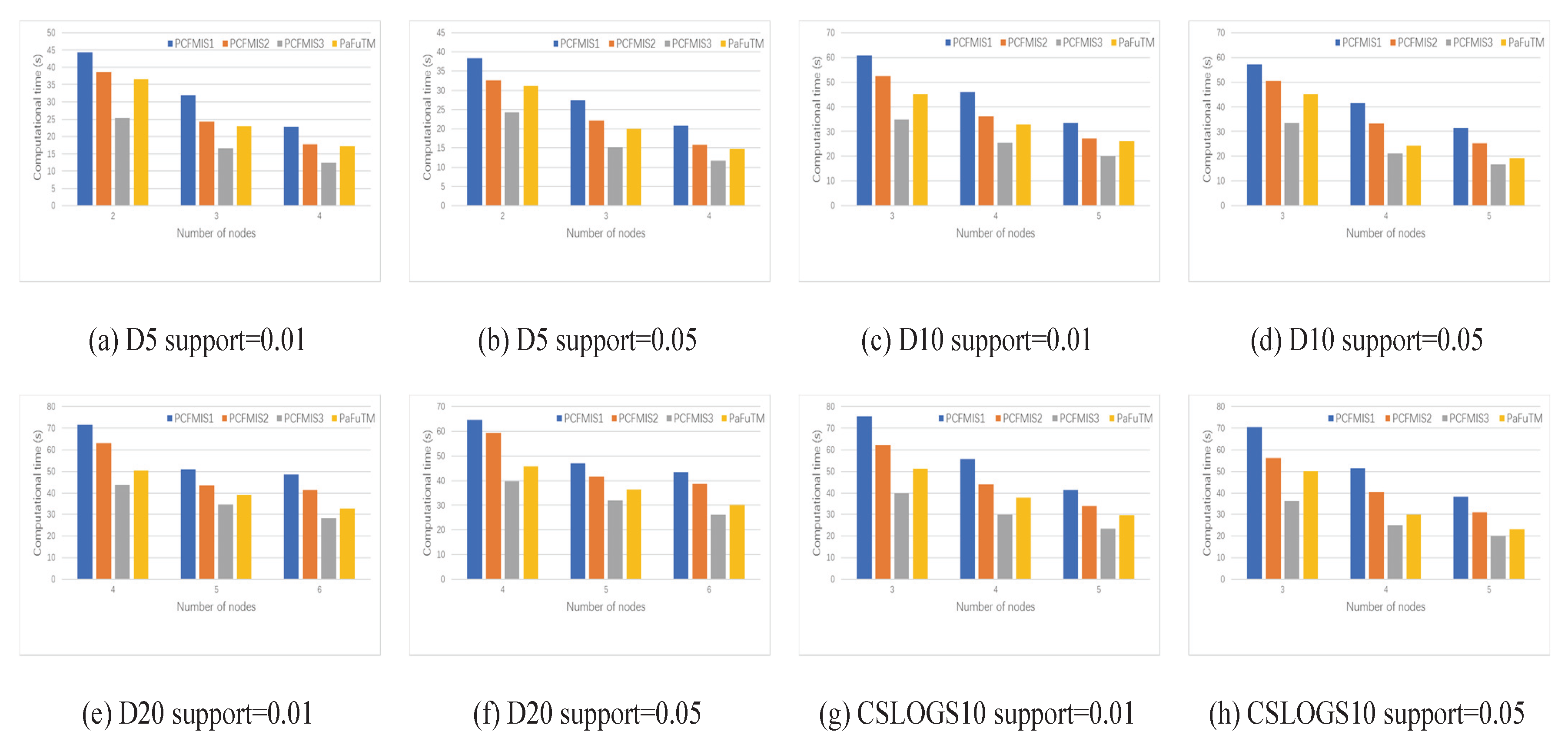
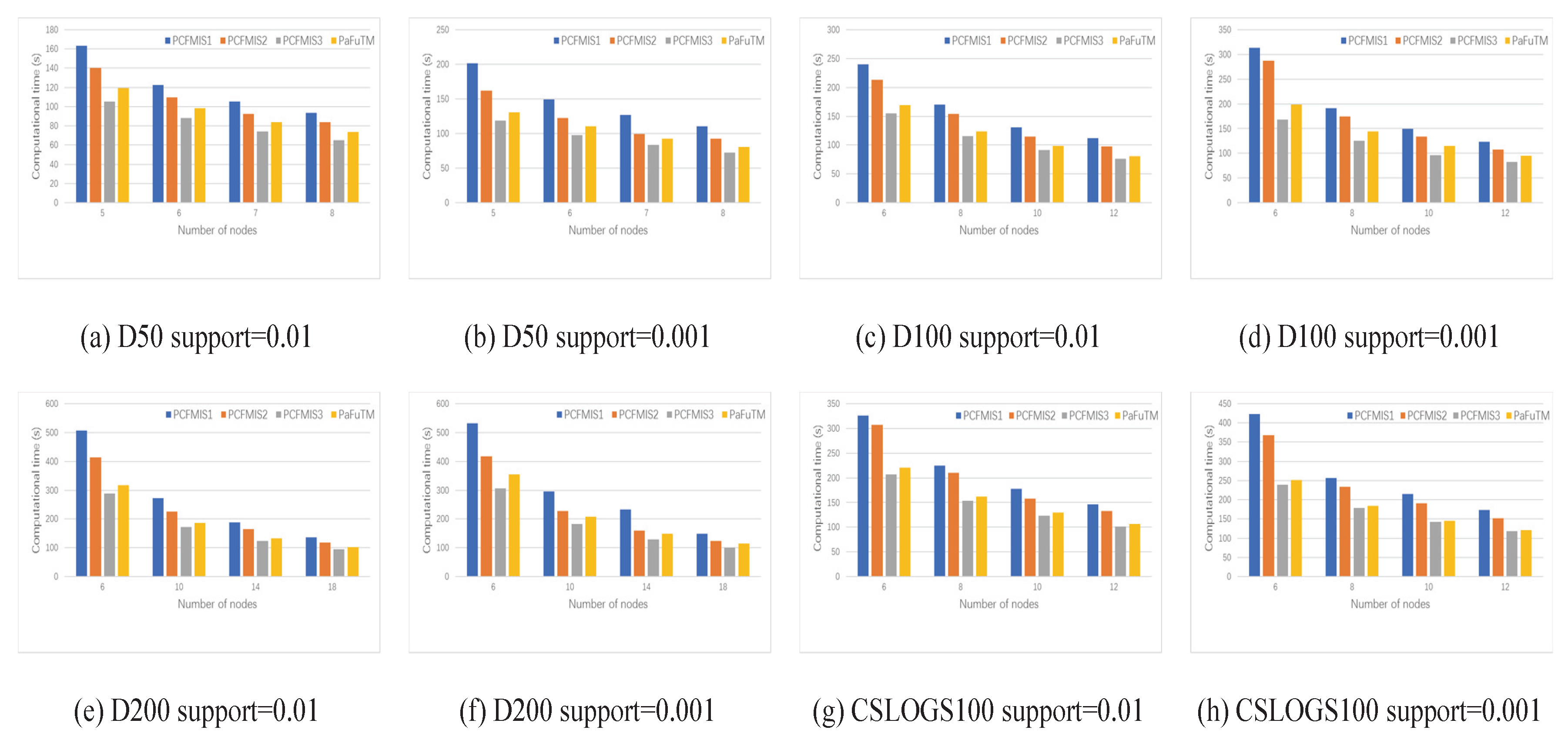
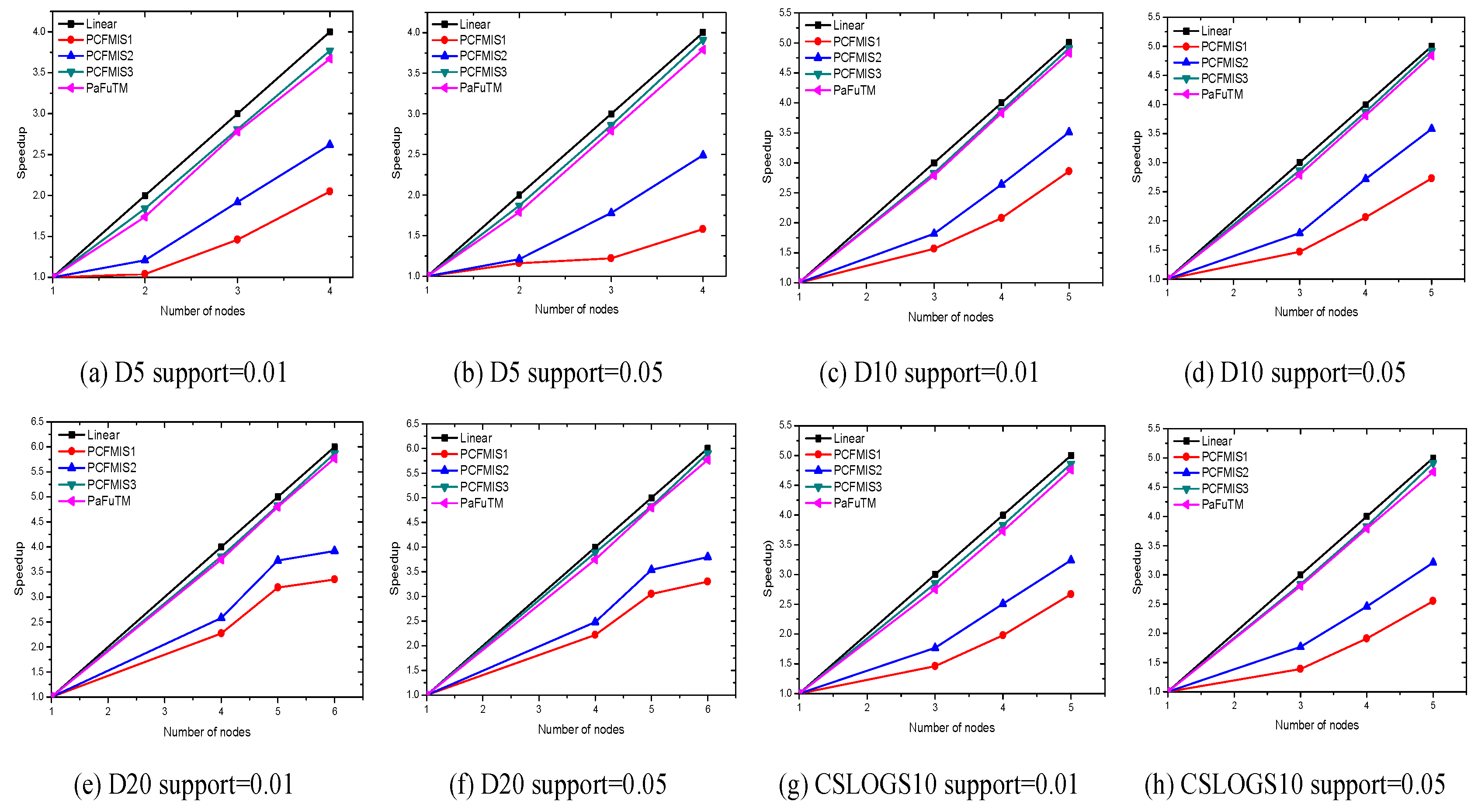
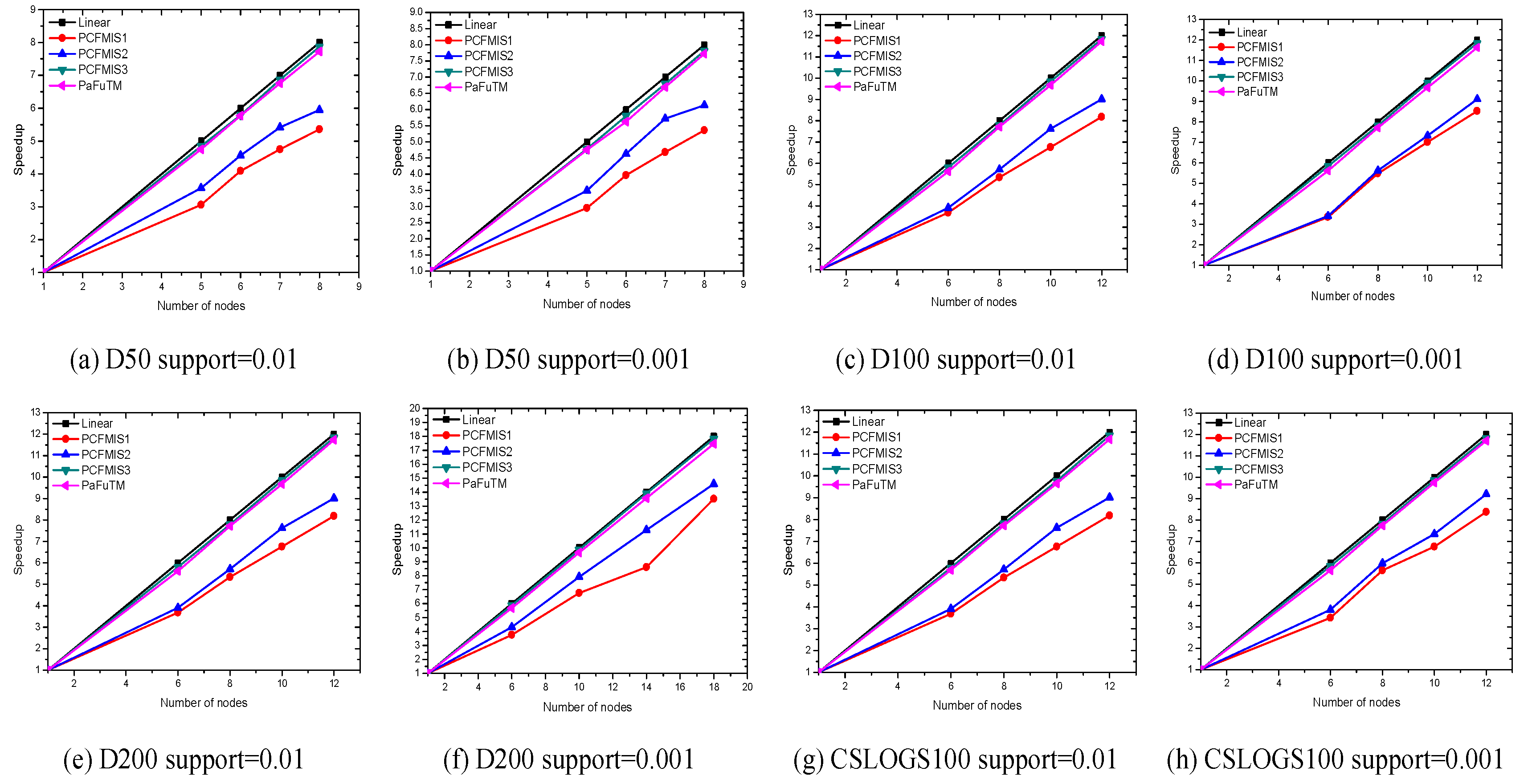
By using the above grouping strategy on the original data set and applying CFMIS algorithm in each group, the CFMIS algorithm is implemented in parallel. The new parallel algorithm is called PCFMIS1. However, the experiment results shown in
Section 4.2 indicate that the parallel computing time and speedup did not achieve the desired results. Further improvements on PCFMIS1 will be discussed below.
3.3. Improvements on Parallel Algorithm
3.3.1. Optimized Compression in CFMIS
Stage 3 is the central step of the CFMIS algorithm, and it also takes most of the time in CFMIS. The subsequence processing of Stage 3 must find all subtrees of a compression tree to determine whether each of them is frequent. In fact, it consumes up to 70% of the execution time in this stage. Optimizing Stage 3 can greatly reduce time consumption of the algorithm, particularly when the data size is large. In this section, CFMIS is refined by optimizing Stage 3.
According to Property 2, for any edges , all the induced subtrees of containing can be found in the group k, so frequent induced subtrees of can also be found. For other edges , all the induced subtrees of containing can be found in the group f. For the reasons above, we only need to find all the frequent induced subtrees of which contain instead of all the frequent induced subtrees in group k. Other frequent induced subtrees could be found in other groups. If a CTS in group k does not contain , this CTS does not have to match with the CTSs following it. That is, this improvement in Stage 3 avoids finding all subtrees of a compression tree to determine whether each of them is frequent. The improvement in compression in groups makes the running time shorter. The improved parallel algorithm is called PCFMIS2. Although the time has been reduced, the load on slave nodes is not balanced.
3.3.2. Load Balancing
An effective edge division strategy (EDS) is proposed in this section. If A, (x,y) will be put into the group k. The division of edges in the original data set affects the load of the slave nodes. Take the frequent edge degree as the basis for the edge division strategy. Abstract edge division strategy as a math problem, it can be described as below: Suppose that there are w different edges in the original data set, and their frequent edge degree is denoted as , 1 ⩽ i ⩽ w. Record in the array . Divide different edges from the original data set into the set , ensuring that the sum of the frequent edge degree in each A is approximately equal. The improved parallel algorithm is called PCFMIS3.
The steps of EDS are described below:
- 1.
Get the mean of array X, u=.
- 2.
Traverse the array X, if > u, then it is assigned separately to a group. Suppose there are s groups like that.
- 3.
Now, the problem is translated into such a problem: divide − different edges into − sets, ensuring that the sum of the frequent edge degree in each group is approximately equal.
- 4.
For the rest , 1 ⩽ j ⩽w−s, get the mean of array X, =.
- 5.
Translate the step (3) and (4) problem to 0–1 Knapsack Problem in order to solve it.
An example of the EDS method is given here to show how it works: suppose that the frequent edge degree of the original data set is 50, 60, 80, 100, 150, 200, 400, 1000, and k = 3. The mean value u = = 680. As 1000 > 680, 1000 is assigned separately to . Now, the problem is translated into such a problem: Divide the rest of the edges into two sets, ensuring that the sum of the frequent edge degree in each set is approximately equal. Get the mean value u = = 520. Translate the problem to 0–1 Knapsack Problem in order to solve it. The weights of these items are 50, 60, 80, 100, 150, 200, 400 and the backpack capacity is 520. The answer is that 50, 60, 400 make the total value biggest in the backpack. 50, 60, 400 are assigned to , and the rest are assigned to .
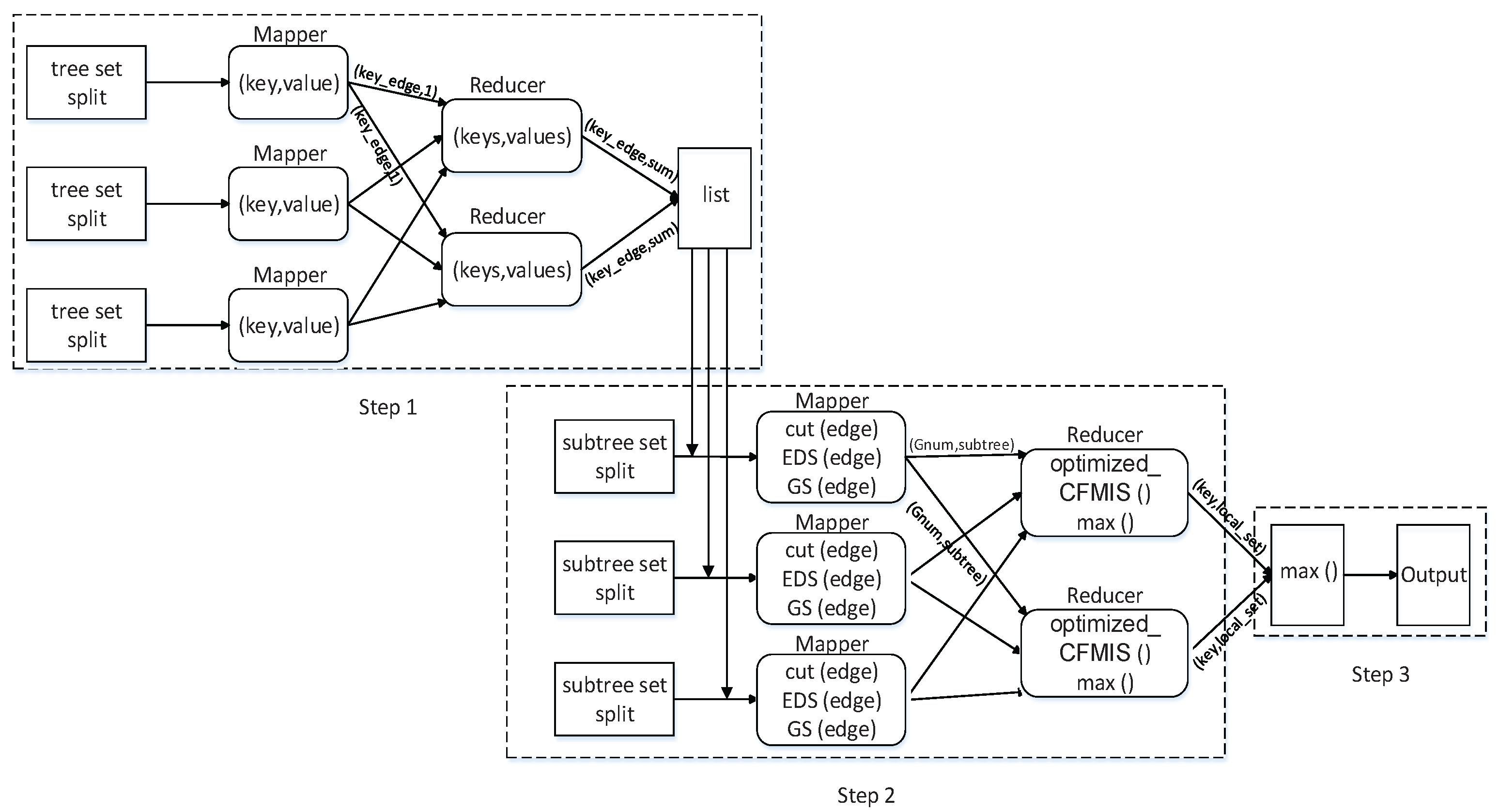
PCFMIS3 solved the problem of load balancing and introduced the optimized compression. The flowchart of PCFMIS3 is shown in
Figure 3. Three steps including two Map-reduce operations are completed during parallel computation.
Step1: Calculate edge frequent degree of each edge in original tree set. In Map 1 (Algorithm 1), record each occurrence of each edge in a tree set split, which is the input of Reduce 1 (Algorithm 2). In Reduce 1, the edge frequent degree of each edge is counted out.
Step 2: Cut edge and find frequent subtree. In Map 2 (Algorithm 3), trim the edges for which the edge frequent degree is less than according to the list; divide the edges into different sets according to EDS; divide the subtrees into different groups according to GS. Then which group the subtree is divided to is the input of Reduce (Algorithm 4). In Reduce 2, find frequent subtrees in each group. The maximal frequent subtrees of each group could be obtained.
Step 3: Find the maximal subtrees of original tree set. In this step, run the frequent subtree sets maximal processing to obtain the final maximal frequent subtrees.
| Algorithm 1: Map 1 |
 |
| Algorithm 2: Reduce 1 |
 |
| Algorithm 3: Map 2 |
 |
| Algorithm 4: Reduce 2 |
 |















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}