
Machine Learning-Based Automatic Utterance Collection Model for Language Development Screening of Children


Abstract
:1. Introduction
2. Related Work: Language Sample Analysis
3. Conversation Collection Protocol
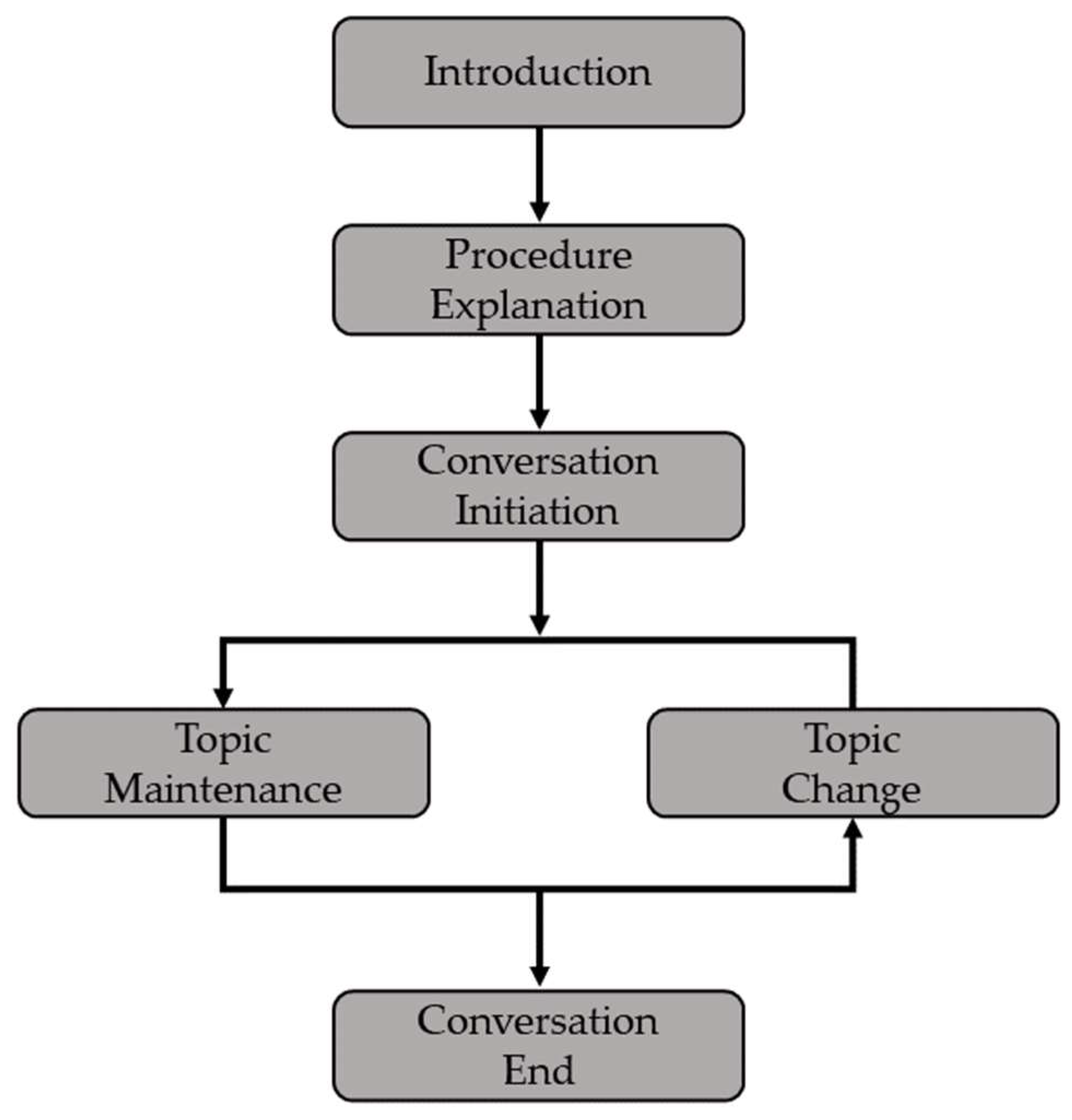
- Conversation Introduction Stage: It is a process of greeting and introducing each other, and it is a process of talking naturally with the child. The purpose of the experiment is not revealed to the child in order to maintain the objectivity of the test.
- Procedure Explanation Stage: This is the stage where you explain how the conversation will proceed. The conversation procedure is as follows. First, the expert shows the prepared photographs of 3–5 sheets, and the child expresses what comes to mind after looking at the pictures. The topic of the picture includes scenes of conversations with friends, scenes of school grounds, scenes of gathering with family, and more. All pictures are in color and are the same size, A4. Each picture indicates a topic for the child to talk about. At this time, experts should inform the child that they should be talking about their experiences rather than describing the situations described in the picture.
- Conversation Initiation Stage: It is very important because it is the stage in which conversation data necessary for spontaneous speech analysis are collected in earnest. When a child looks at a picture and tells an experience about it, the expert must either preserve the conversation topic or transition to a different picture topic, depending on the utterance. For example, if the child says “I went on a trip with my family” the expert maintains the topic to elicit various utterances from the child. Therefore, the expert must respond as if imitating a child’s utterance so as not to change the topic the child is talking about. The expert must have a response that encourages the child to answer, such as “Did you go on a trip?” or “And then?”. If the child directly states that there is nothing to talk about the topic, or if they talk about a topic for a long time, the expert uses their judgement to change the topic. In case of changing the topic, the expert shows the rest of the pictures that the child has not selected and repeats the procedure of maintaining the topic and changing the topic while continuing the conversation. When enough utterances have been collected or the talk regarding the prepared picture has been completed, the conversation ends.
4. Dataset
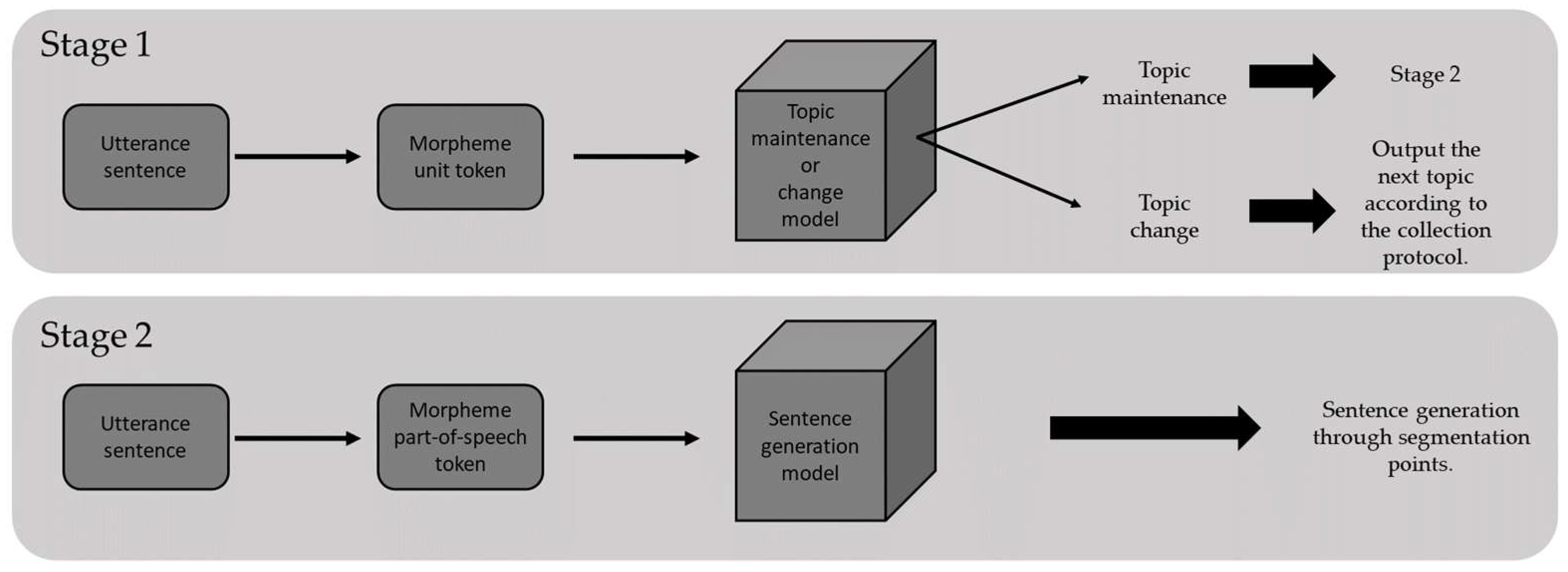
5. Methodology
5.1. Pre-Processing
5.2. Machine Learning-Based Approach
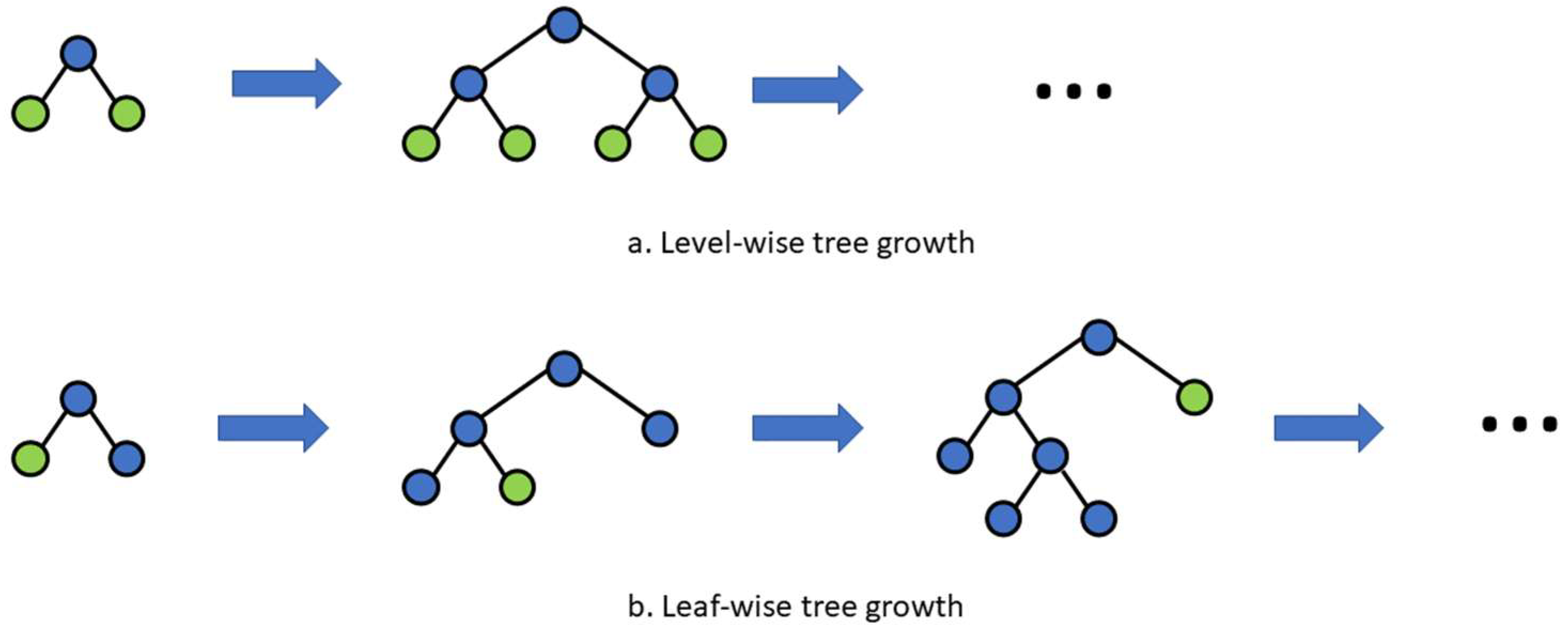
5.2.1. Light Gradient Boosting Machine (LightGBM)
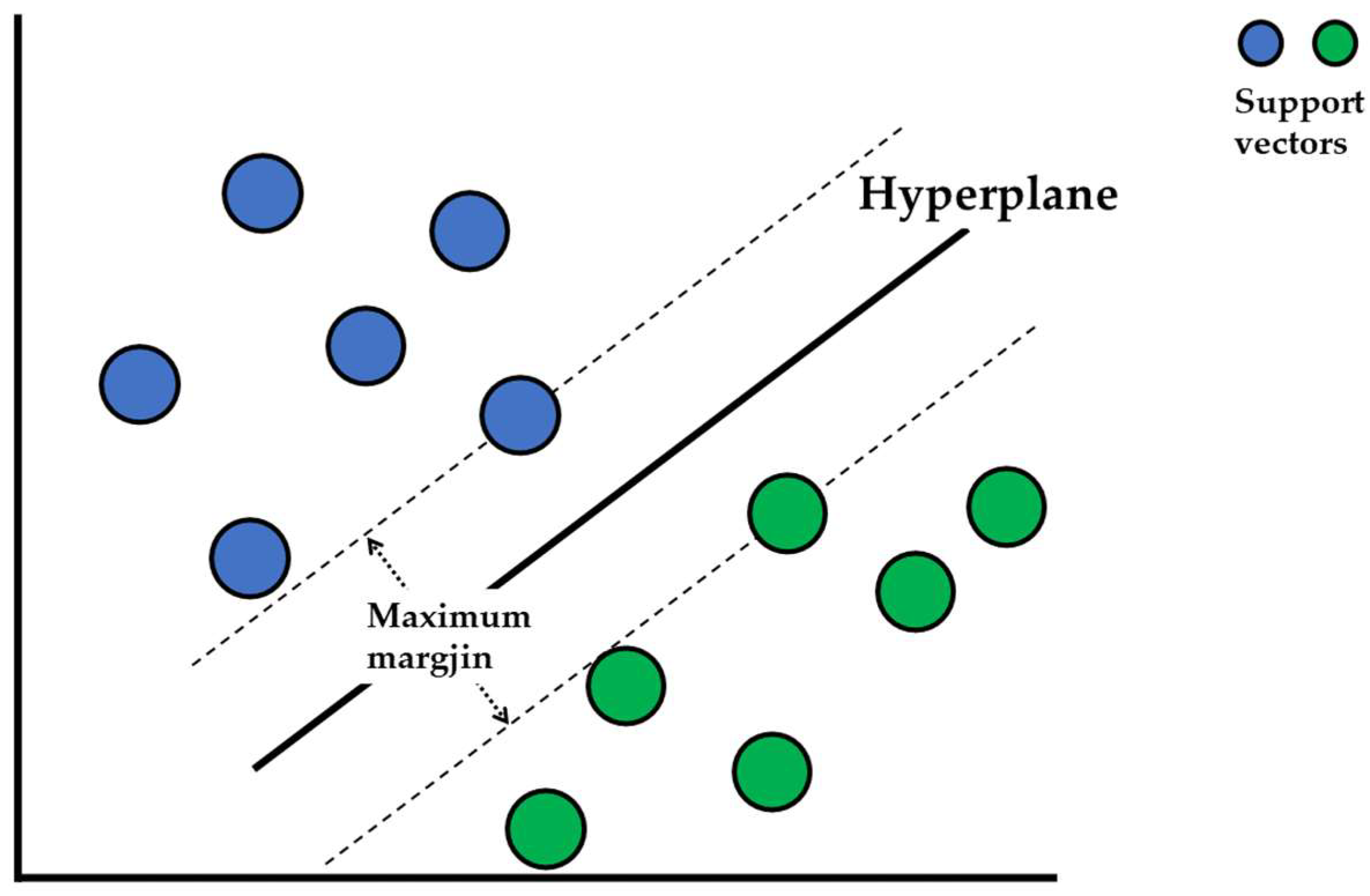
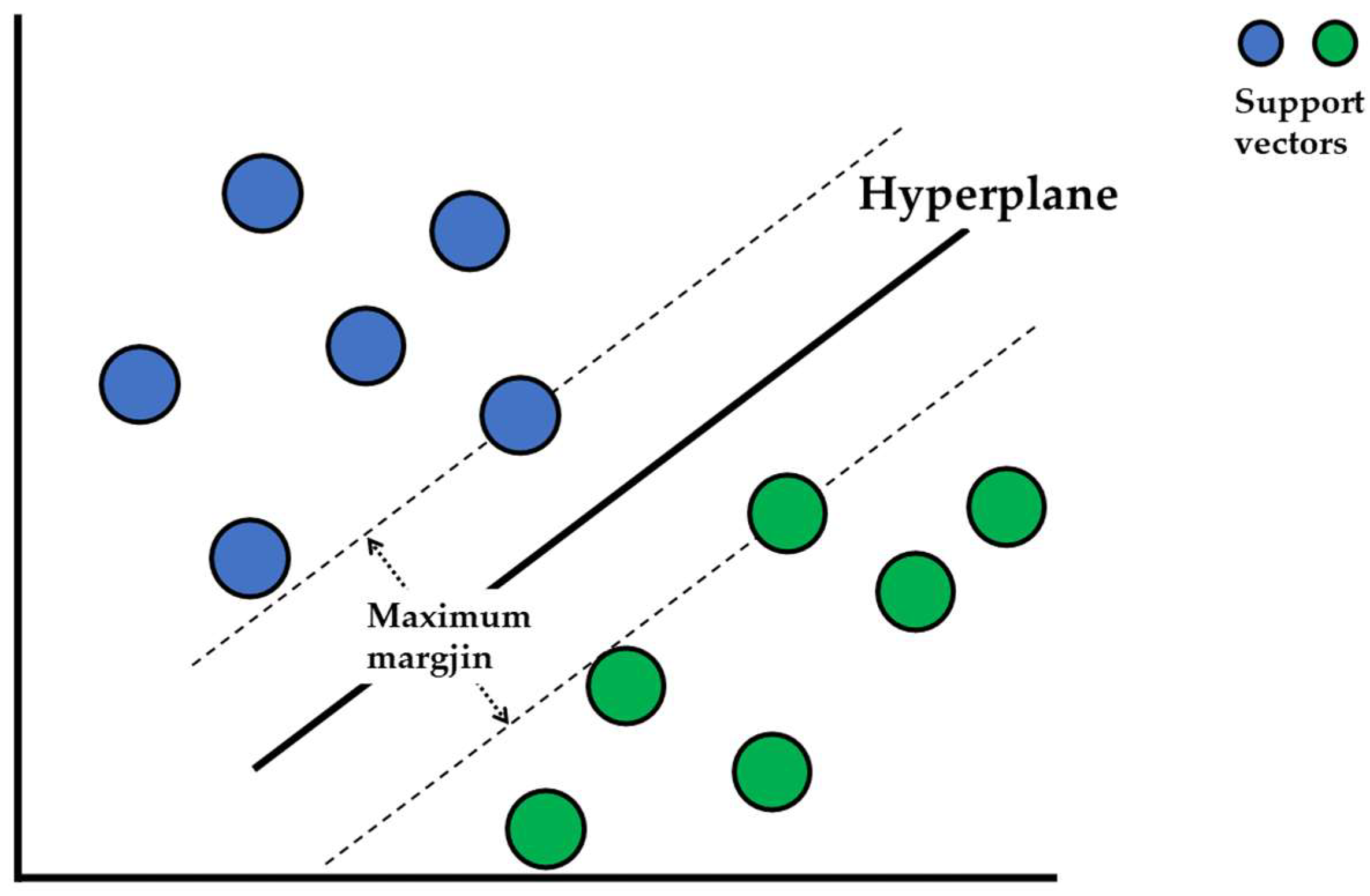
5.2.2. Support Vector Machine
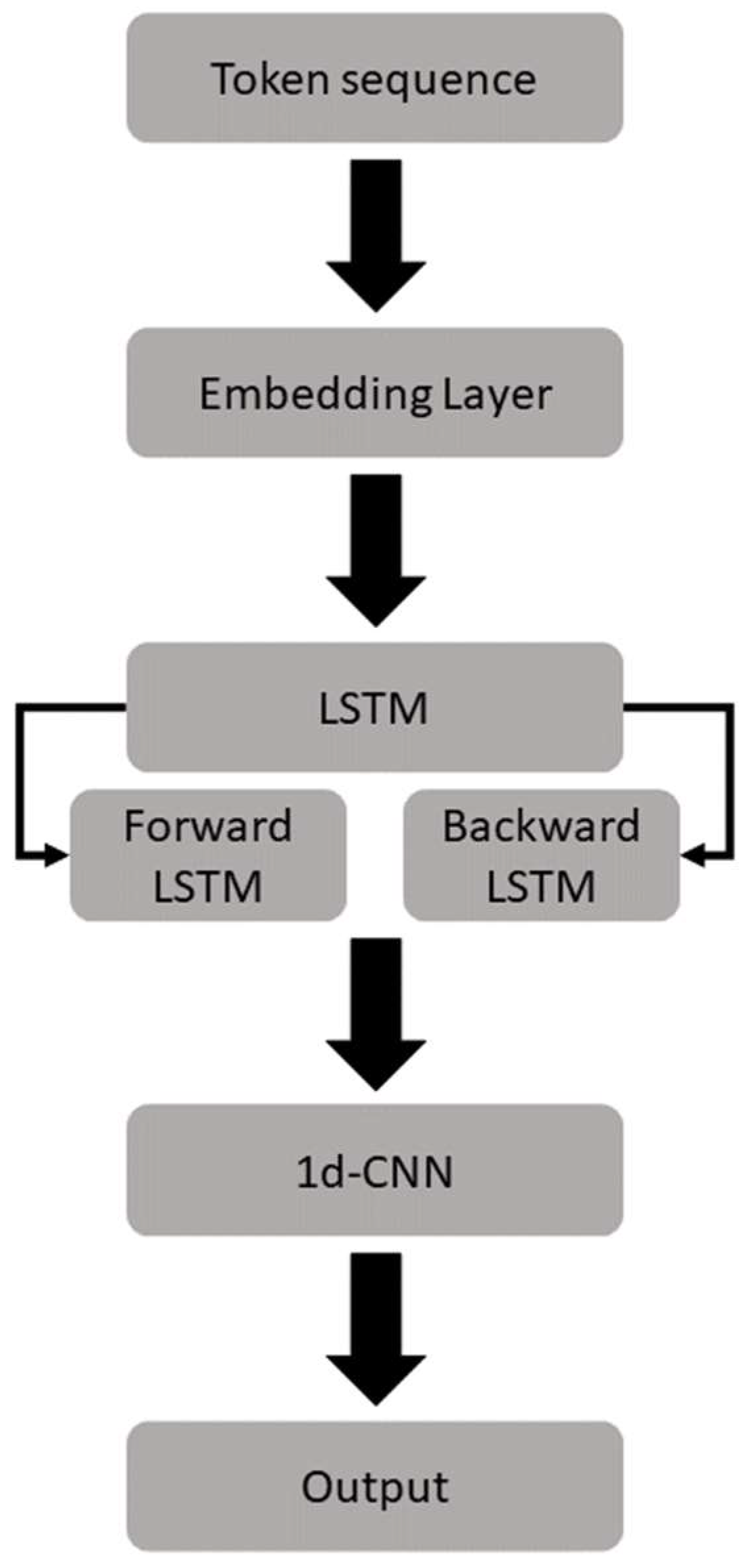
5.3. Deep Learning-Based Approach
6. Experiment and Result
6.1. Data Split
6.2. Parameters
6.3. Evaluation Metrics
6.4. Experiment Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, S.W.; Shin, J.B.; You, S.; Yang, E.J.; Lee, S.K.; Chung, H.J.; Song, D.H. Diagnosis and Clinical Features of Children with Language Delay. J. Korean Acad. Rehabil. Med. 2005, 29, 584–590. (In Korean) [Google Scholar]
- Kim, Y.T. Content and Reliability Analyses of the Sequenced Language Scale for Infants (SELSI). Commun. Sci. Disord. 2002, 7, 1–23. (In Korean) [Google Scholar]
- Lee, H.J.; Kim, Y.T. Measures of Utterance Length of Normal and Language—Delayed Children. Commun. Sci. Disord. 1999, 4, 1–14. (In Korean) [Google Scholar]
- Jin, C.; Choi, H.J.; Lee, J.T. Usefulness of Spontaneous Language Analysis Scale in Patients with Mild Cognitive Impairment and Mild Dementia of Alzheimer’s Type. Commun. Sci. Disord. 2016, 21, 284–294. (In Korean) [Google Scholar] [CrossRef] [Green Version]
- Oh, K.A.; Nam, K.W.; Kim, S.J. The Development of Verbs through Semantic Categories in the Spontaneous Speech of Preschoolers. J. Speech-Lang. Hear. Disord. 2014, 23, 63–72. (In Korean) [Google Scholar]
- Park, C.H.; Lee, S.H. A Study on Use of Expression Pattern in Spontaneous Speech from 3 to 5-Year-Old Children; Korean Speech-Language & Hearing Association: Busan, Korea, 2017; pp. 187–190. (In Korean) [Google Scholar]
- Jin, Y.S.; Pae, S.Y. Grammatical Ability of School-aged Korean Children. J. Speech Hear. Disord. 2008, 17, 1–16. (In Korean) [Google Scholar] [CrossRef]
- Kim, S.S.; Lee, S.K. The Comparison of Conversation, Freeplay, and Strory as Methods of Spontaneous Language Sample Elicitation. KASA 2008, 13, 44–62. (In Korean) [Google Scholar]
- Park, Y.J.; Choi, J.; Lee, Y. Development of Topic Management Skills in Conversation of School-Aged Children. Commun. Sci. Disord. 2017, 22, 25–34. (In Korean) [Google Scholar] [CrossRef]
- Park, E.J.; Cho, S.Z. KoNLPy: Korean natural language processing in Python. In Proceedings of the Annual Conference on Human and Language Technology, Kangwon, Korea, 10–11 October 2014; pp. 133–136. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Rana, S.; Garg, R. Slow learner prediction using multi-variate naïve Bayes classification algorithm. Int. J. Eng. Technol. Innov. 2017, 7, 11–23. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Pokhrel, P.; Ioup, E.; Hoque, M.T.; Abdelguerfi, M.; Simeonov, J. A LightGBM based Forecasting of Dominant Wave Periods in Oceanic Waters. arXiv 2021, arXiv:2105.08721. [Google Scholar]
- Li, F.; Zhang, L.; Chen, B.; Gao, D.; Cheng, Y.; Zhang, X.; Peng, J. A light gradient boosting machine for remaining useful life estimation of aircraft engines. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3562–3567. [Google Scholar]
- Taha, A.A.; Malebary, S.J. An intelligent approach to credit card fraud detection using an optimized light gradient boosting machine. IEEE Access 2020, 8, 25579–25587. [Google Scholar] [CrossRef]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural. Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Speaker | Utterance (Kor) | Utterance (Eng) | Category |
|---|---|---|---|
| Expert | daehwaga mueos-inji al-ayo? | Do you know what a conversation is? | Procedure Explanation |
| Child | aniyo. mollayo. | No. I don’t know. | Procedure Explanation |
| Expert | daehwaneun yeoleosalam-i gat-i iss-eul ttae seolo mal-eul jugobadneun geos-eul daehwalago haeyo. jigeum ulido daehwaleul hago issneun geoyeyo. | The conversation is about talking to each other. When we talk like this, it calls the conversation. | Procedure Explanation |
| Child | ne | Yes. | Procedure Explanation |
| Expert | yeogie issneun geulim kadeu ne gaeleul bogo daehwaleul hal geoyeyo. geulim-e daehae seolmyeonghaneun ge anila gieognaneun geoleul yaegihamyeon dwae. hana gollabolkkayo? | We’re going to look at the four picture cards here and talk to them. You don’t have to explain the picture, you just have to talk about what you remember. Would you like to pick one? | Conversation initiation (topic selection) |
| Child | ne. gollass-eoyo. (family picture) | Yes. I picked (family picture) | Conversation initiation (topic selection) |
| Expert | geuleom yaegileul haejuseyo. | Then please talk about family | Conversation initiation |
| Child | gajog-ilang yeohaeng-eul gass-eoyo. | I went on a trip with my family. | Conversation initiation (topic maintenance) |
| Expert | yeohaeng-eul gass-eoyo? | Did you go on a trip? | Conversation initiation (topic maintenance) |
| Child | gajog-ilang imjingag gaseo lolleokoseuteo tass-eoyo. | I went to Imjingak with my family and rode the roller coaster. | Conversation initiation (topic maintenance) |
| Expert | lolleokoseuteo tass-eoyo? | Did you ride the roller coaster? | Conversation initiation (topic maintenance) |
| Child | ne ollagassda naelyeogassda haneun geosdo tassgo | Yes, I rode it up and down | Conversation initiation (topic maintenance) |
| Expert | ollagassda naelyeogassda haneun geosdo tassgo geuligo? | You also rode up and down rides. And then? | Conversation initiation (topic maintenance) |
| mediated syncope | |||
| Child | deo eobs-eoyo. | No more. | Conversation initiation (topic change) |
| Expert | ibeon-eneun jangnangam yaegileul haebolkka? joh-ahaneun jangnangam iss-eoyo? | Would you talk about toys? Do you have a favorite toy? | Conversation initiation (topic change) |
| Child | mimiyo. | It’s MIMI | Conversation initiation (topic maintenance) |
| Expert | Mimiyo? | MIMI? | Conversation initiation (topic maintenance) |
| Child | mimi jangnangam malgo tto iss-eoyo. | There are more than MIMI toys. | Conversation initiation (topic maintenance) |
| Expert | tto iss-eoyo? | Do you have more? | Conversation initiation (topic maintenance) |
| mediated syncope | |||
| Children Utterance | Expert Utterance | Label |
|---|---|---|
| gajog-ilang yeohaeng-eul gass-eoyo. | gajog-ilang <S> yeohaeng-eul gass-eoyo. | Topic maintenance |
| gajog-ilang imjingag gagajigo lolleokoseuteo tass-eoyo. | gajog-ilang imjingag gagajigo <S> lolleokoseuteo tass-eoyo. | Topic maintenance |
| ne ollagassda naelyeogassda haneun geosdo tassgo | ne <S> ollagassda naelyeogassda haneun geosdo tassgo | Topic maintenance |
| deo eobs-eoyo. | - | Topic change |
| geuman hallaeyo. | - | Topic change |
| Model | Topic Maintenance or Change Classification (Accuracy) | Imitation Sentence Generation (Votes) |
|---|---|---|
| SVM | 79.41 | 60.375 |
| LGBM | 89.70 | 76 |
| DNN | 94.17 | 36.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J.-M.; Lee, Y.-K.; Kim, J.-D.; Park, C.-Y.; Kim, Y.-S. Machine Learning-Based Automatic Utterance Collection Model for Language Development Screening of Children. Appl. Sci. 2022, 12, 4747. https://doi.org/10.3390/app12094747
Choi J-M, Lee Y-K, Kim J-D, Park C-Y, Kim Y-S. Machine Learning-Based Automatic Utterance Collection Model for Language Development Screening of Children. Applied Sciences. 2022; 12(9):4747. https://doi.org/10.3390/app12094747
Chicago/Turabian StyleChoi, Jeong-Myeong, Yoon-Kyoung Lee, Jong-Dae Kim, Chan-Young Park, and Yu-Seop Kim. 2022. "Machine Learning-Based Automatic Utterance Collection Model for Language Development Screening of Children" Applied Sciences 12, no. 9: 4747. https://doi.org/10.3390/app12094747
APA StyleChoi, J.-M., Lee, Y.-K., Kim, J.-D., Park, C.-Y., & Kim, Y.-S. (2022). Machine Learning-Based Automatic Utterance Collection Model for Language Development Screening of Children. Applied Sciences, 12(9), 4747. https://doi.org/10.3390/app12094747