
Whitening CNN-Based Rotor System Fault Diagnosis Model Features

 , , ,
, , ,  and
and
Abstract
:1. Introduction
2. CNNs and Normalization Layers
2.1. 1D Convolutional Layer
2.2. Pooling Layer and ReLU Activation
2.3. Batch Normalisation
2.4. From BN to Whitening Features
3. Proposed Improvement for Fault Diagnosis Models
3.1. Model Architectures
3.2. Whitening CNN Inputs
3.3. Training the Models
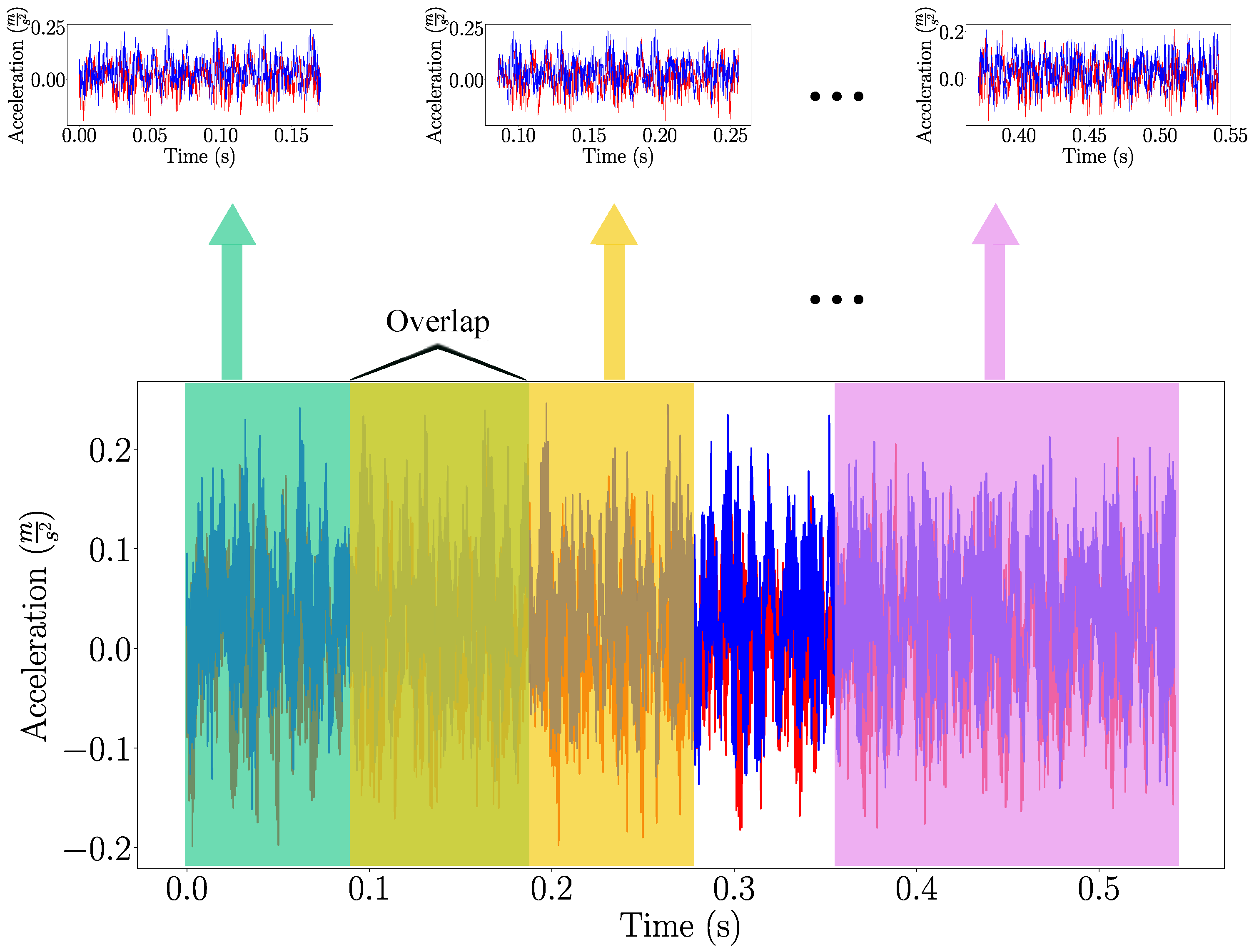
4. Validation of ND for Fault Diagnosis
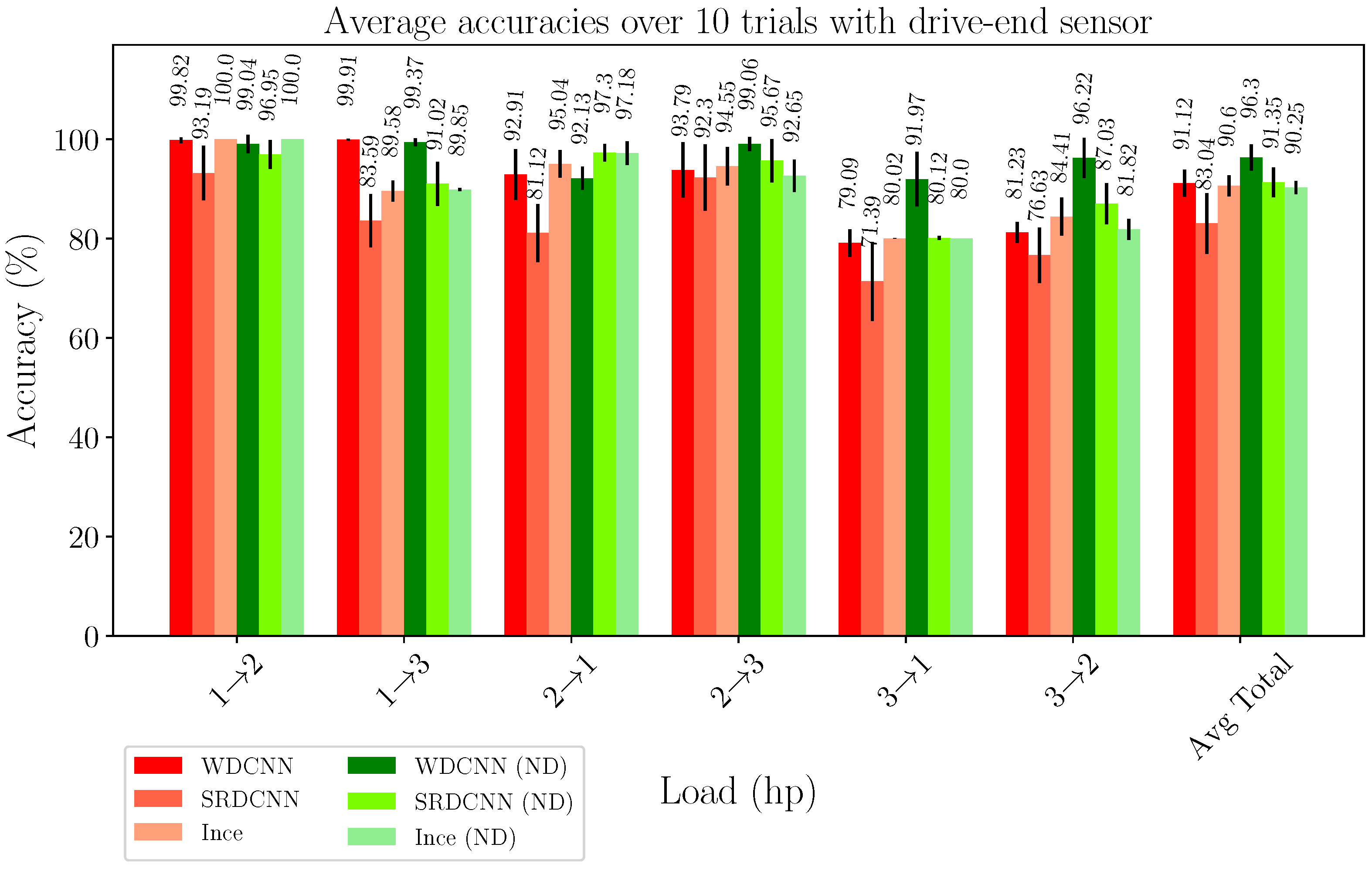
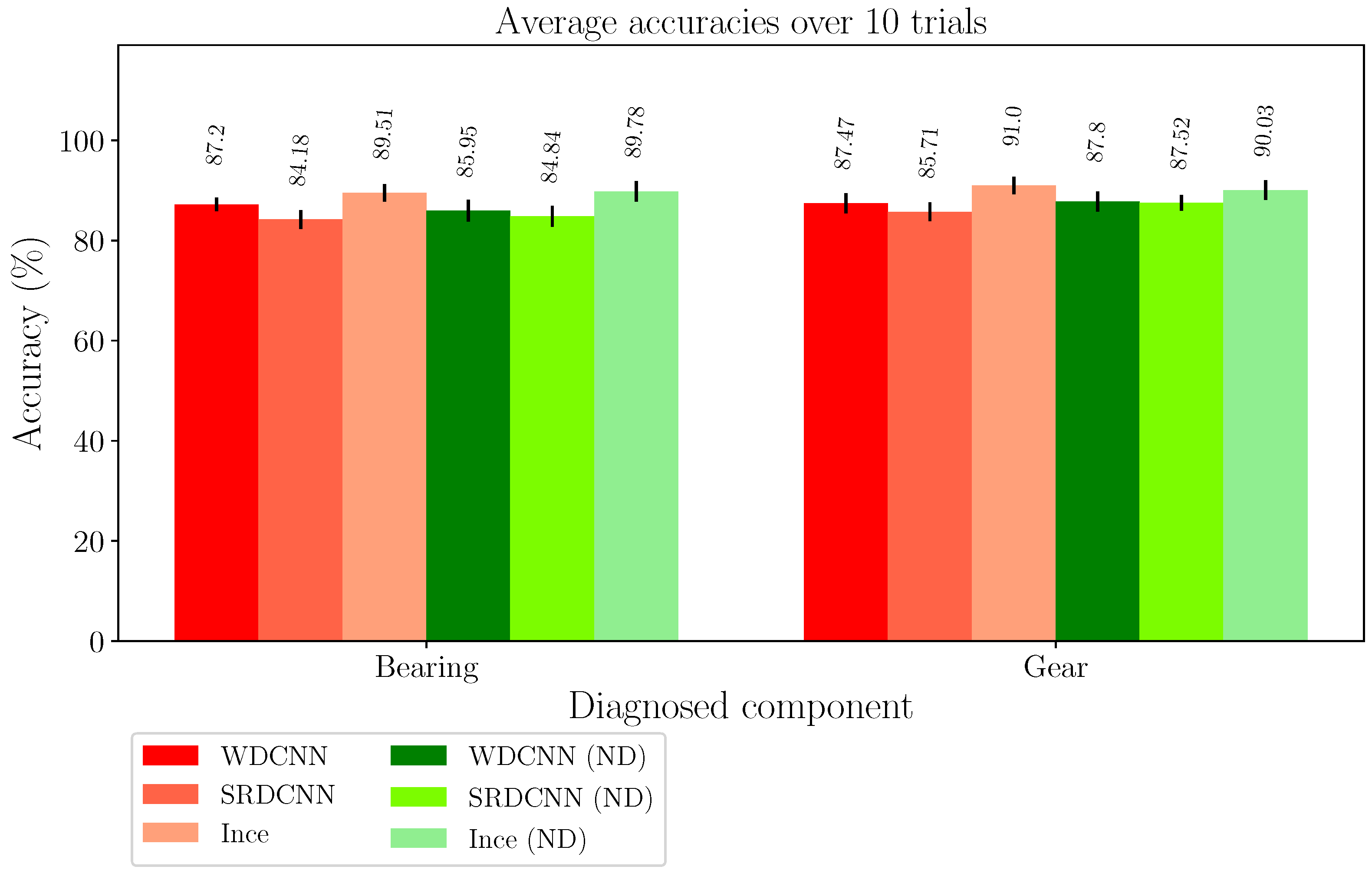
4.1. Case 1: Bearing Fault Diagnosis under Varied Load Conditions
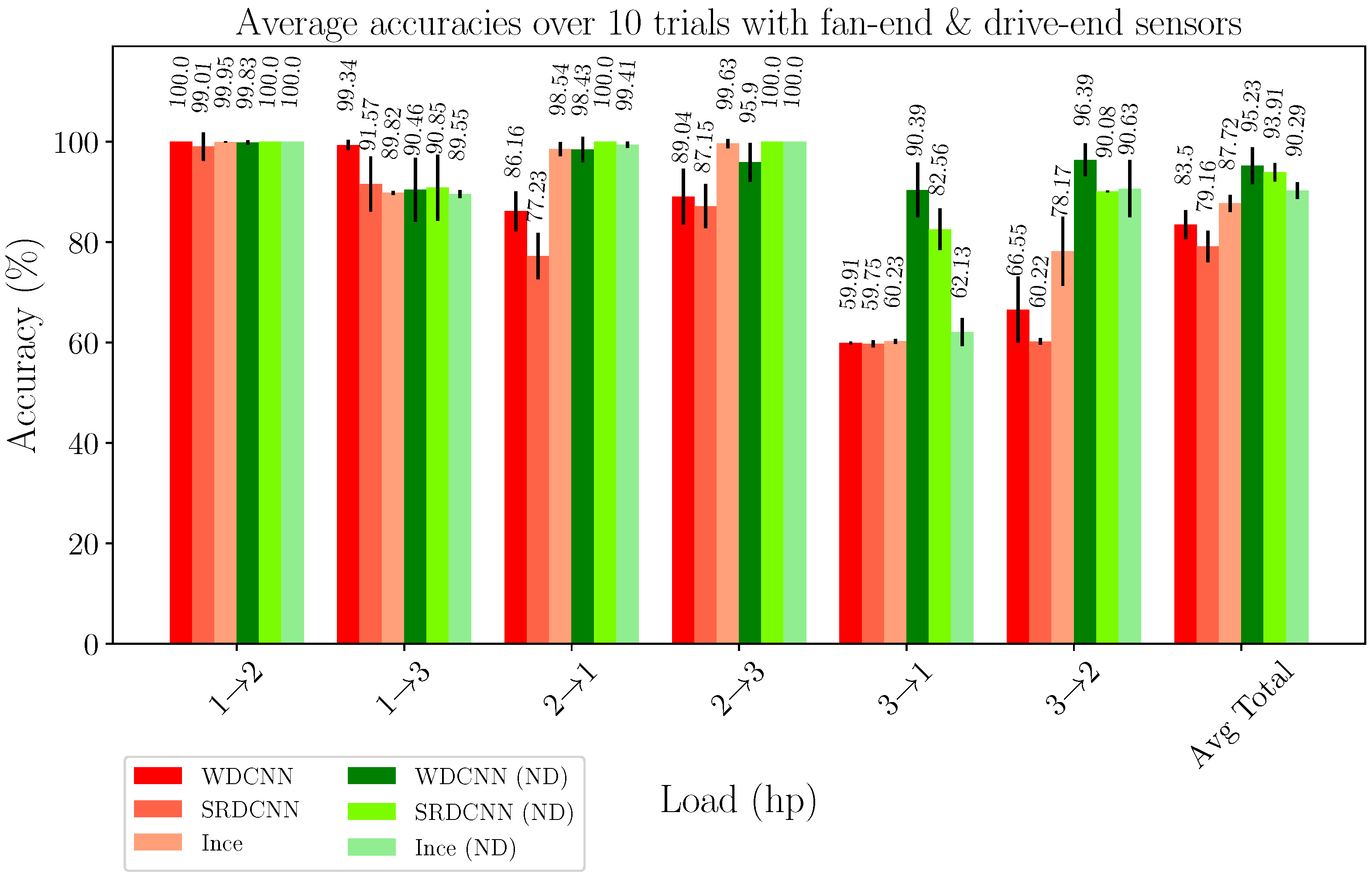
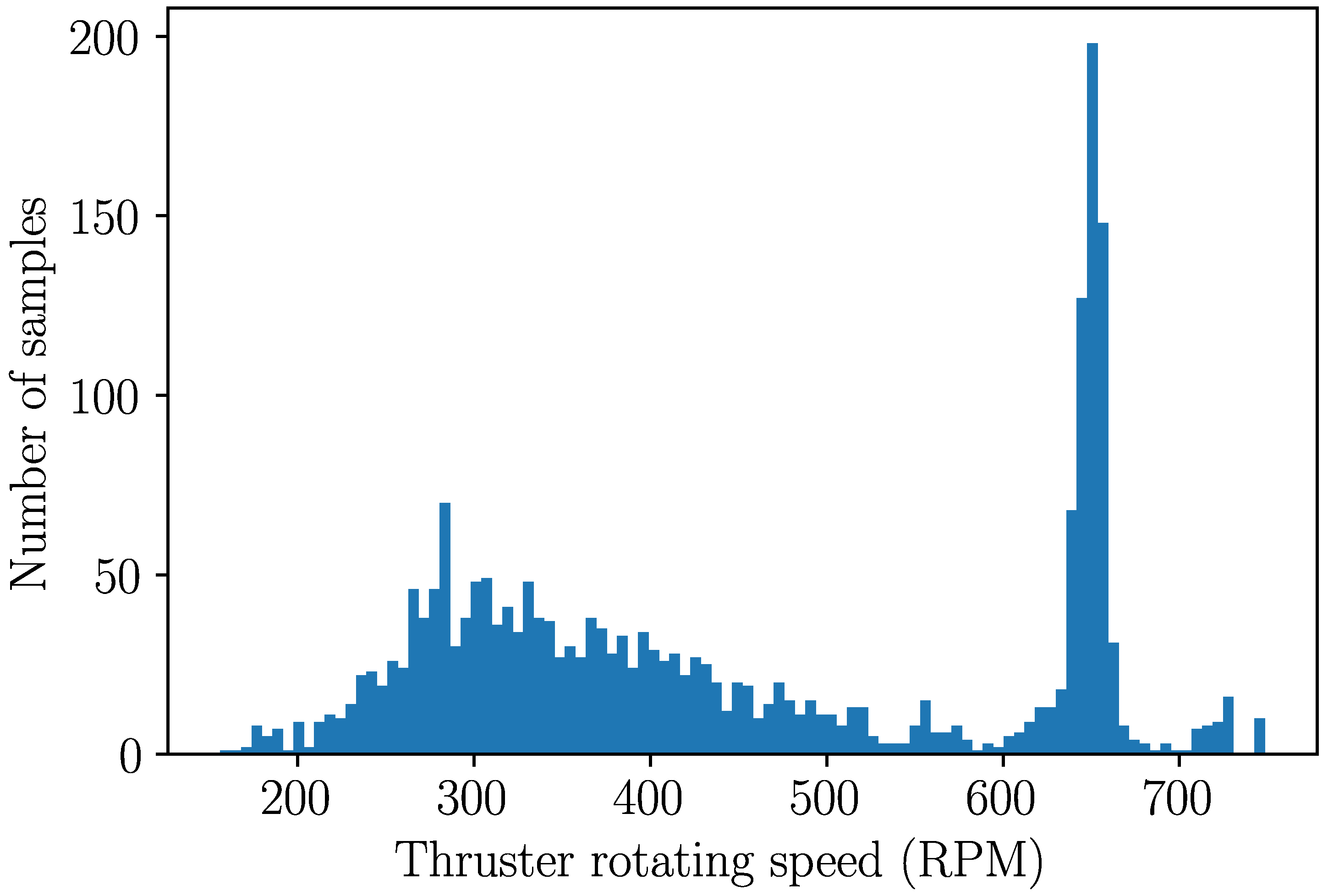
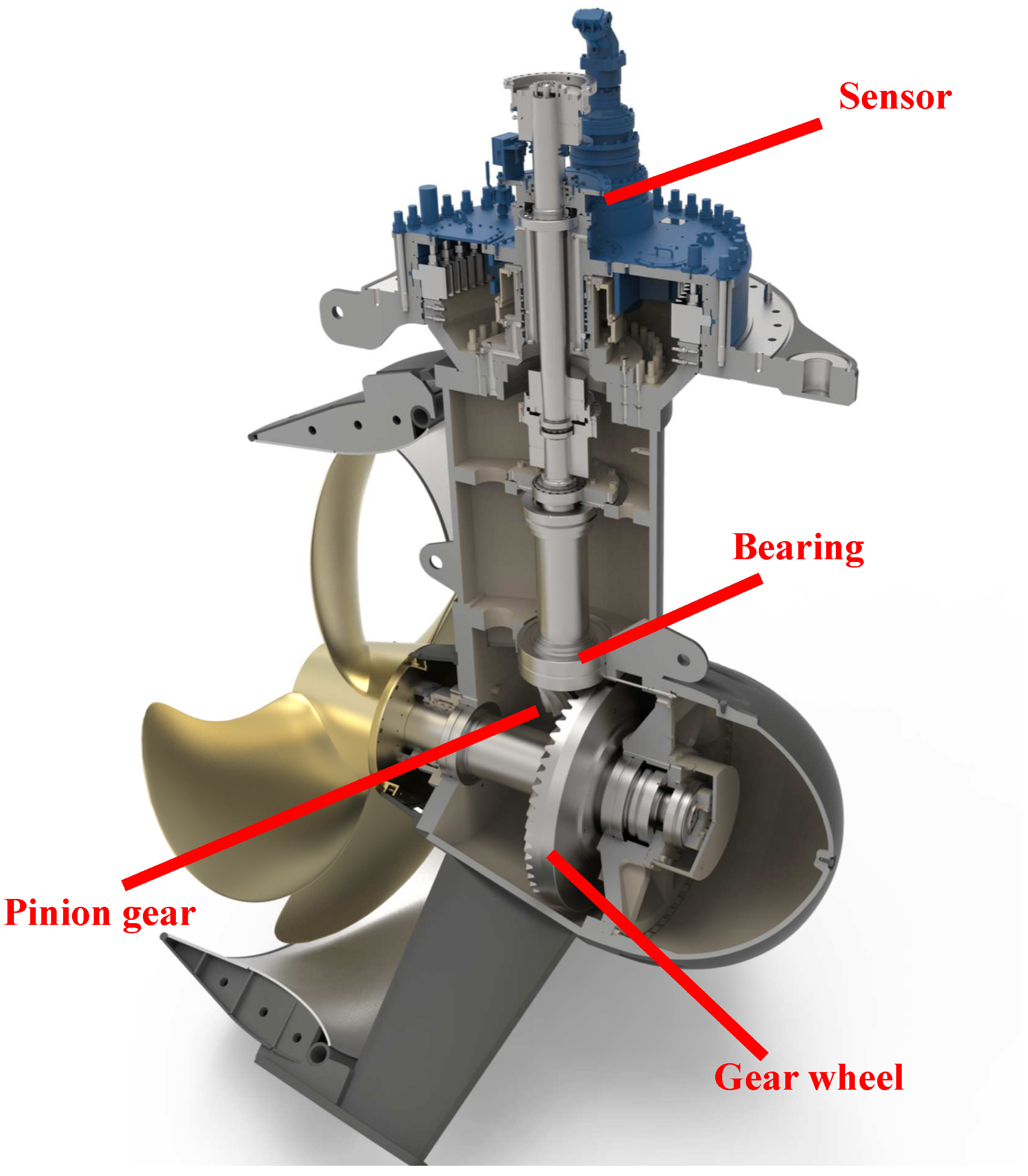
4.2. Case 2: Azimuth Thruster Fault Detection
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| IFD | Intelligent Fault Diagnosis |
| BN | Batch Normalization |
| ND | Network Deconvolution |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| ML | Machine Learning |
| DBN | Deep Belief Network |
| AE | Autoencoder |
| RNN | Recurrent Neural Network |
| WDCNN | Deep Convolutional Neural Networks with Wide First-layer Kernels |
| SRDCNN | Stacked Residual Dilated Convolutional Neural Network |
| ReLU | Rectified Linear Unit |
| LSTM | Long Short-Term Memory |
| CE | Cross-Entropy |
| BCE | Binary Cross-Entropy |
| pp | Percentage Point |
Appendix A. Source Code
Appendix B. Model Specific Hyperparameters

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Param | Ince | SRDCNN | WDCNN | Ince (ND) | SRDCNN (ND) | WDCNN (ND) |
|---|---|---|---|---|---|---|
| Batch size | 32 | 64 | 64 | 8 | 128 (8) | 8 |
| Learning rate | 0.001 | 0.0001 | 0.001 | 0.0001 | 0.1 (0.0001) | 0.0001 |
| Max epochs | 60 | 60 | 70 | 70 | 40 | 70 |
| Bias | False | True | True | True | True | True |
| First layer iterations | N/A | N/A | N/A | 15 | 15 | 15 |
| Deconv iterations | N/A | N/A | N/A | 5 | 5 | 5 |
| N/A | N/A | N/A | ||||
| Sampling stride | N/A | N/A | N/A | 5 | 5 | 5 |
| Param | Ince | SRDCNN | WDCNN | Ince (ND) | SRDCNN (ND) | WDCNN (ND) |
|---|---|---|---|---|---|---|
| Batch size | 32 | 64 | 64 | 8 | 8 | 8 |
| Learning rate | 0.001 | 0.0001 | 0.001 | 0.0001 | 0.0001 | 0.0001 |
| Max epochs | 60 | 60 | 70 | 70 | 70 | 70 |
| Bias | False | True | True | True | True | True |
| First layer iterations | N/A | N/A | N/A | 15 | 15 | 25 |
| Deconv iterations | N/A | N/A | N/A | 5 | 5 | 5 |
| N/A | N/A | N/A | ||||
| Sampling stride | N/A | N/A | N/A | 5 | 5 | 36 |
Appendix C. Quality Control Function for Filtering Abnormal Samples
Appendix D. Batch Size and Sampling Stride Effect on ND
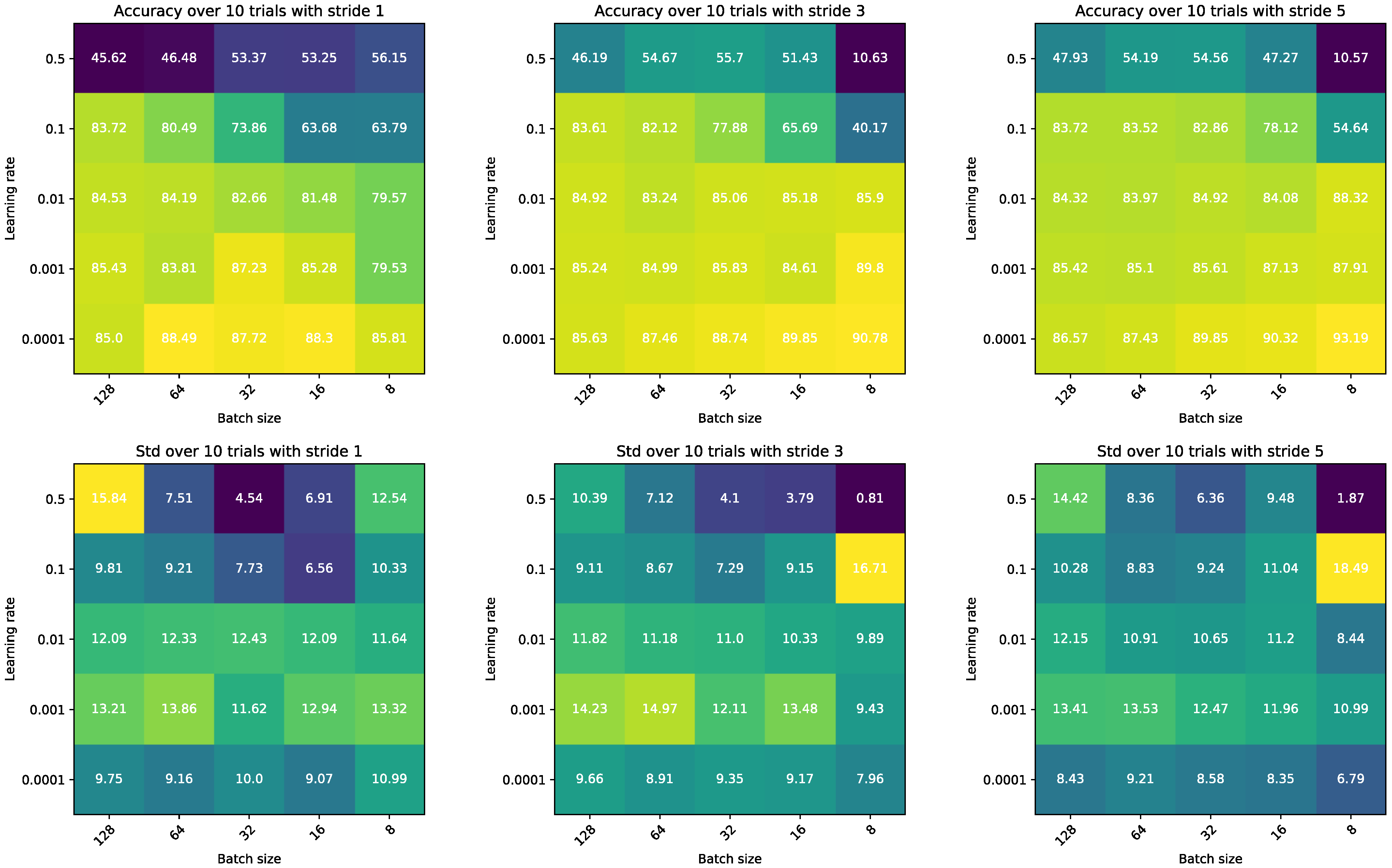
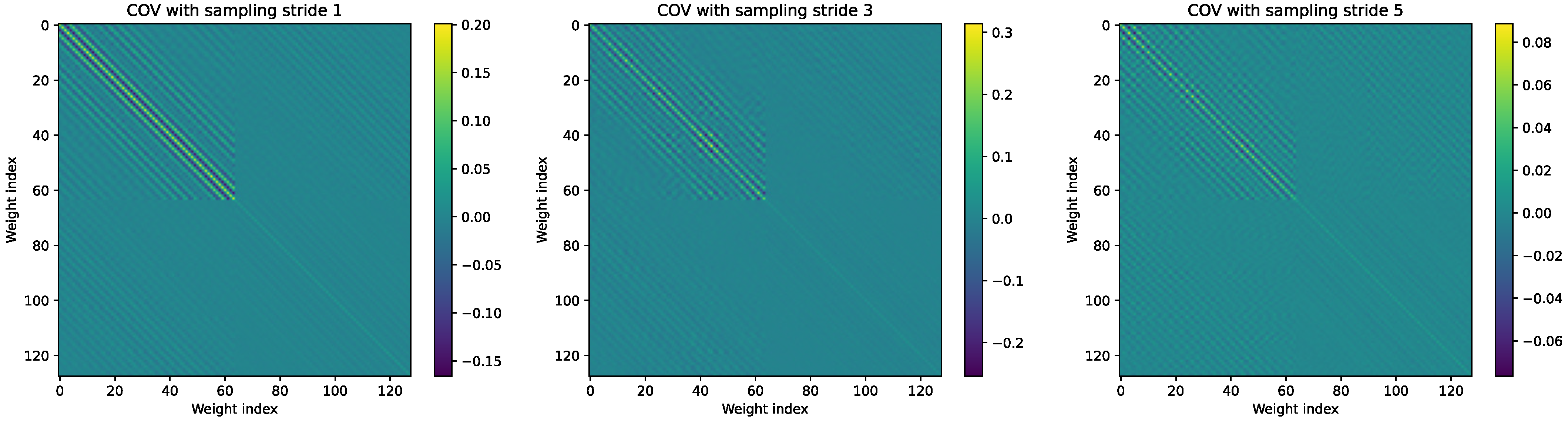
Appendix E. Iteration Count Effect on the Approximation of the Deconvolution Kernel
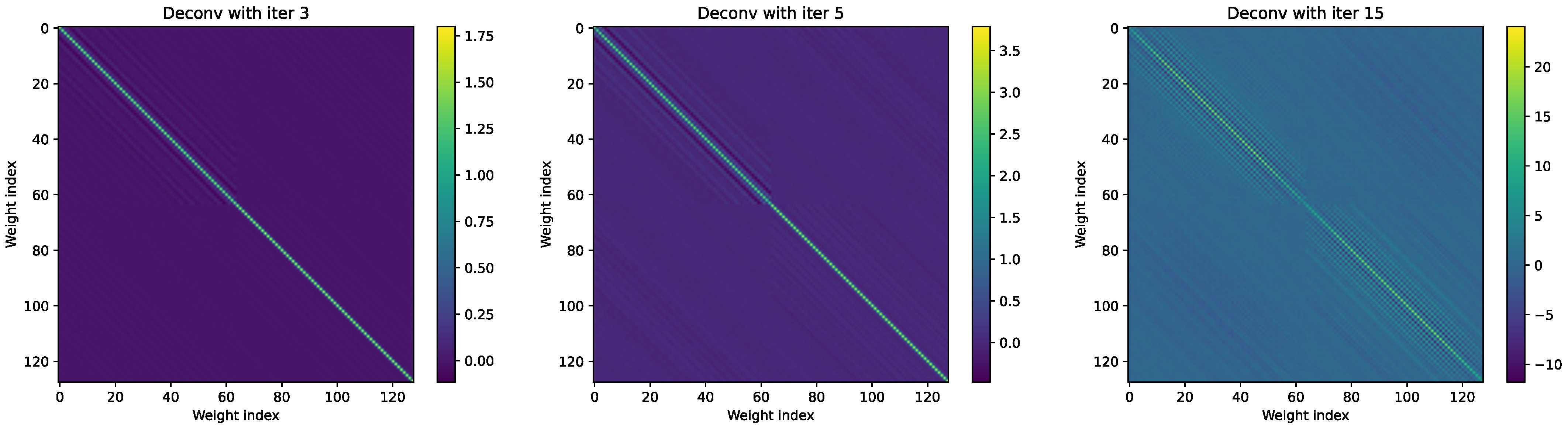
References
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Lei, Y.; Zuo, M.J.; He, Z.; Zi, Y. A multidimensional hybrid intelligent method for gear fault diagnosis. Expert Syst. Appl. 2010, 37, 1419–1430. [Google Scholar] [CrossRef]
- Yang, B.S.; Di, X.; Han, T. Random forests classifier for machine fault diagnosis. J. Mech. Sci. Technol. 2008, 22, 1716–1725. [Google Scholar] [CrossRef]
- Widodo, A.; Yang, B.S. Support vector machine in machine condition monitoring and fault diagnosis. Mech. Syst. Signal Process. 2007, 21, 2560–2574. [Google Scholar] [CrossRef]
- Witczak, M.; Korbicz, J.; Mrugalski, M.; Patton, R.J. A GMDH neural network-based approach to robust fault diagnosis: Application to the DAMADICS benchmark problem. Control Eng. Pract. 2006, 14, 671–683. [Google Scholar] [CrossRef]
- Hinton, G.E. Learning multiple layers of representation. Trends Cogn. Sci. 2007, 11, 428–434. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Sanchez, R.V.; Zurita, G.; Cerrada, M.; Cabrera, D.; Vásquez, R.E. Multimodal deep support vector classification with homologous features and its application to gearbox fault diagnosis. Neurocomputing 2015, 168, 119–127. [Google Scholar] [CrossRef]
- Lu, C.; Wang, Z.Y.; Qin, W.L.; Ma, J. Fault diagnosis of rotary machinery components using a stacked denoising autoencoder-based health state identification. Signal Process. 2017, 130, 377–388. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Khan, S.; Yairi, T. A review on the application of deep learning in system health management. Mech. Syst. Signal Process. 2018, 107, 241–265. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Zhang, H.; Duan, W.; Liang, T.; Wu, S. Rolling bearing fault feature learning using improved convolutional deep belief network with compressed sensing. Mech. Syst. Signal Process. 2018, 100, 743–765. [Google Scholar] [CrossRef]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. LSTM-based Encoder-Decoder for Multi-sensor Anomaly Detection. arXiv 2016, arXiv:1607.00148. [Google Scholar]
- Zhang, S.; Zhang, S.; Wang, B.; Habetler, T.G. Deep Learning Algorithms for Bearing Fault Diagnostics—A Comprehensive Review. IEEE Access 2020, 8, 29857–29881. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A New Deep Learning Model for Fault Diagnosis with Good Anti-Noise and Domain Adaptation Ability on Raw Vibration Signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef]
- Zhang, W.; Li, C.; Peng, G.; Chen, Y.; Zhang, Z. A deep convolutional neural network with new training methods for bearing fault diagnosis under noisy environment and different working load. Mech. Syst. Signal Process. 2018, 100, 439–453. [Google Scholar] [CrossRef]
- Shenfield, A.; Howarth, M. A Novel Deep Learning Model for the Detection and Identification of Rolling Element-Bearing Faults. Sensors 2020, 20, 5112. [Google Scholar] [CrossRef]
- Zhuang, Z.; Lv, H.; Xu, J.; Huang, Z.; Qin, W. A Deep Learning Method for Bearing Fault Diagnosis through Stacked Residual Dilated Convolutions. Appl. Sci. 2019, 9, 1823. [Google Scholar] [CrossRef] [Green Version]
- Hendriks, J.; Dumond, P.; Knox, D. Towards better benchmarking using the CWRU bearing fault dataset. Mech. Syst. Signal Process. 2022, 169, 108732. [Google Scholar] [CrossRef]
- Janssens, O.; Slavkovikj, V.; Vervisch, B.; Stockman, K.; Loccufier, M.; Verstockt, S.; Van de Walle, R.; Van Hoecke, S. Convolutional Neural Network Based Fault Detection for Rotating Machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Jing, L.; Zhao, M.; Li, P.; Xu, X. A convolutional neural network based feature learning and fault diagnosis method for the condition monitoring of gearbox. Measurement 2017, 111, 1–10. [Google Scholar] [CrossRef]
- Zhao, D.; Wang, T.; Chu, F. Deep convolutional neural network based planet bearing fault classification. Comput. Ind. 2019, 107, 59–66. [Google Scholar] [CrossRef]
- Han, T.; Liu, C.; Yang, W.; Jiang, D. A novel adversarial learning framework in deep convolutional neural network for intelligent diagnosis of mechanical faults. Knowl.-Based Syst. 2019, 165, 474–487. [Google Scholar] [CrossRef]
- Guo, L.; Lei, Y.; Xing, S.; Yan, T.; Li, N. Deep Convolutional Transfer Learning Network: A New Method for Intelligent Fault Diagnosis of Machines With Unlabeled Data. IEEE Trans. Ind. Electron. 2019, 66, 7316–7325. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Jia, F.; Xing, S. An intelligent fault diagnosis approach based on transfer learning from laboratory bearings to locomotive bearings. Mech. Syst. Signal Process. 2019, 122, 692–706. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:cs.LG/1502.03167. [Google Scholar]
- Huang, L.; Qin, J.; Zhou, Y.; Zhu, F.; Liu, L.; Shao, L. Normalization techniques in training DNNs: Methodology, analysis and application. arXiv 2020, arXiv:2009.12836. [Google Scholar]
- LeCun, Y.A.; Bottou, L.; Orr, G.B.; Müller, K.R. Efficient backprop. In Neural networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 9–48. [Google Scholar] [CrossRef]
- Huang, L.; Zhou, L.Z.Y.; Zhu, F.; Liu, L.; Shao, L. An investigation into the stochasticity of batch whitening. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6438–6447. [Google Scholar] [CrossRef]
- Huang, L.; Yang, D.; Lang, B.; Deng, J. Decorrelated Batch Normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ye, C.; Evanusa, M.; He, H.; Mitrokhin, A.; Goldstein, T.; Yorke, J.A.; Fermuller, C.; Aloimonos, Y. Network Deconvolution. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Ince, T.; Kiranyaz, S.; Eren, L.; Askar, M.; Gabbouj, M. Real-Time Motor Fault Detection by 1-D Convolutional Neural Networks. IEEE Trans. Ind. Electron. 2016, 63, 7067–7075. [Google Scholar] [CrossRef]
- Case Western Reserve University Bearing Data Center. Case Western Reserve University Bearing Data Center Website. Available online: https://engineering.case.edu/bearingdatacenter (accessed on 5 April 2022).
- Scherer, D.; Müller, A.; Behnke, S. Evaluation of pooling operations in convolutional architectures for object recognition. In Proceedings of the International Conference on Artificial Neural Networks, Thessaloniki, Greece, 15–18 September 2010; pp. 92–101. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Desjardins, G.; Simonyan, K.; Pascanu, R.; Kavukcuoglu, K. Natural Neural Networks. In Proceedings of the NIPS’15: 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 2, pp. 2071–2079. [Google Scholar]
- Luo, P. Learning Deep Architectures via Generalized Whitened Neural Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 2238–2246. [Google Scholar]
- Huang, L.; Zhou, Y.; Zhu, F.; Liu, L.; Shao, L. Iterative Normalization: Beyond Standardization Towards Efficient Whitening. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. Proceedings of International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
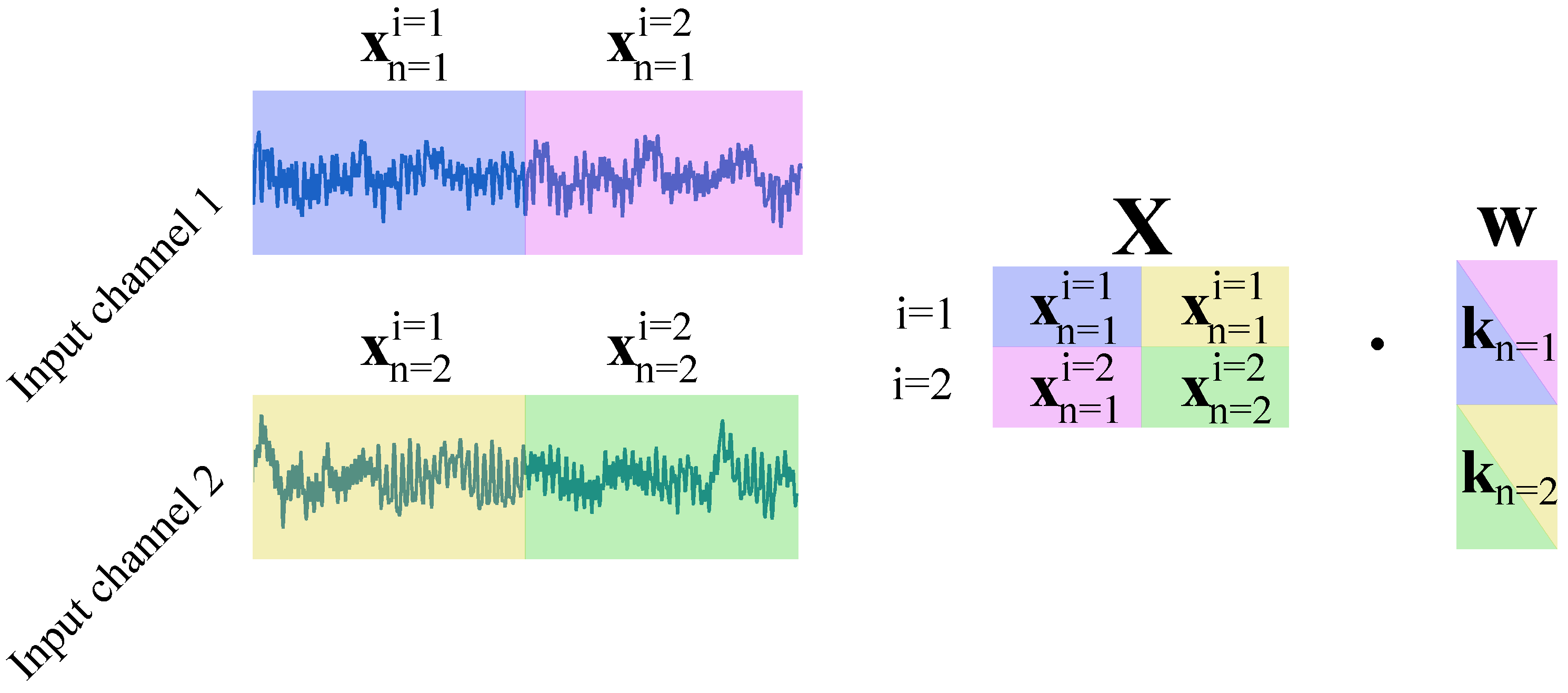
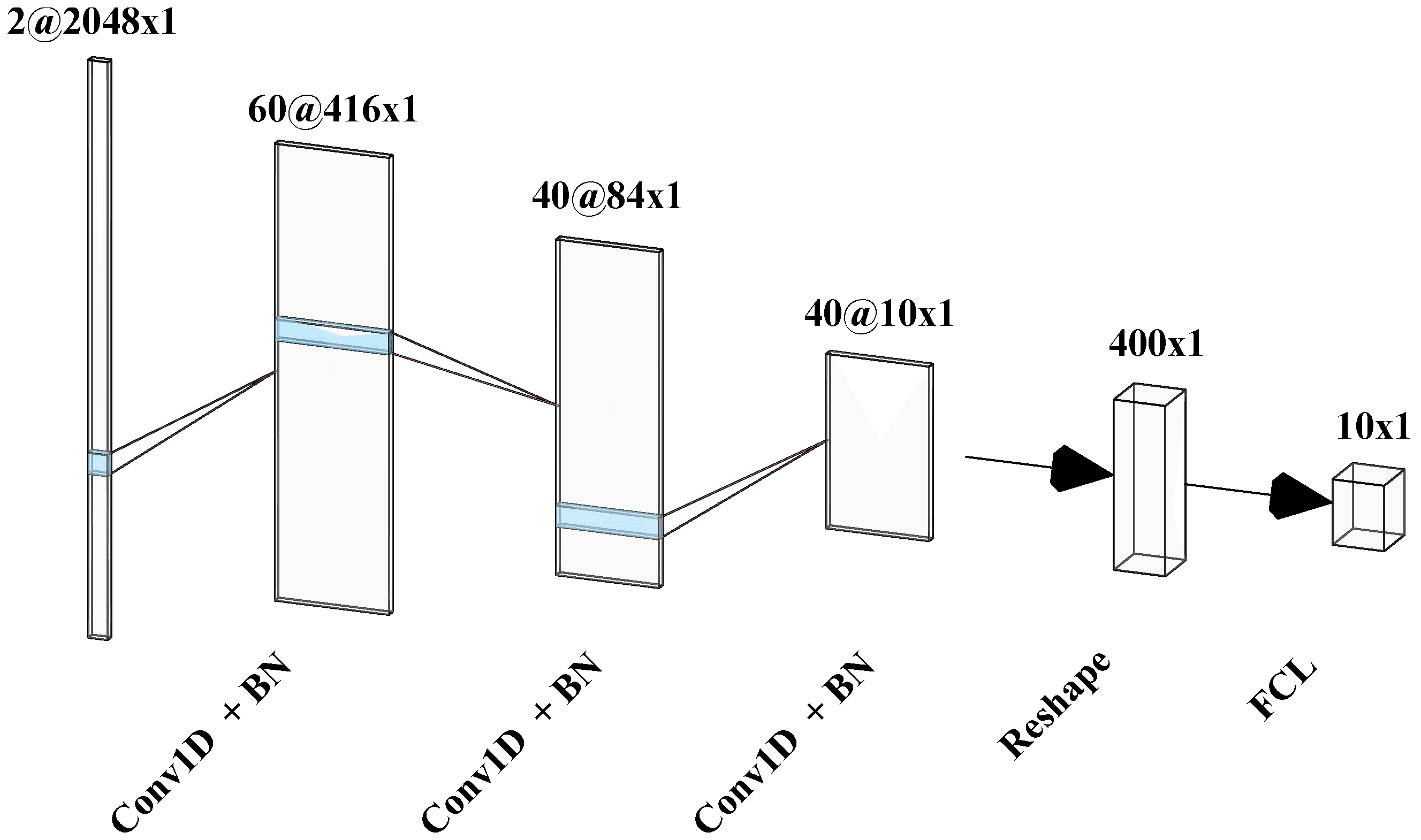
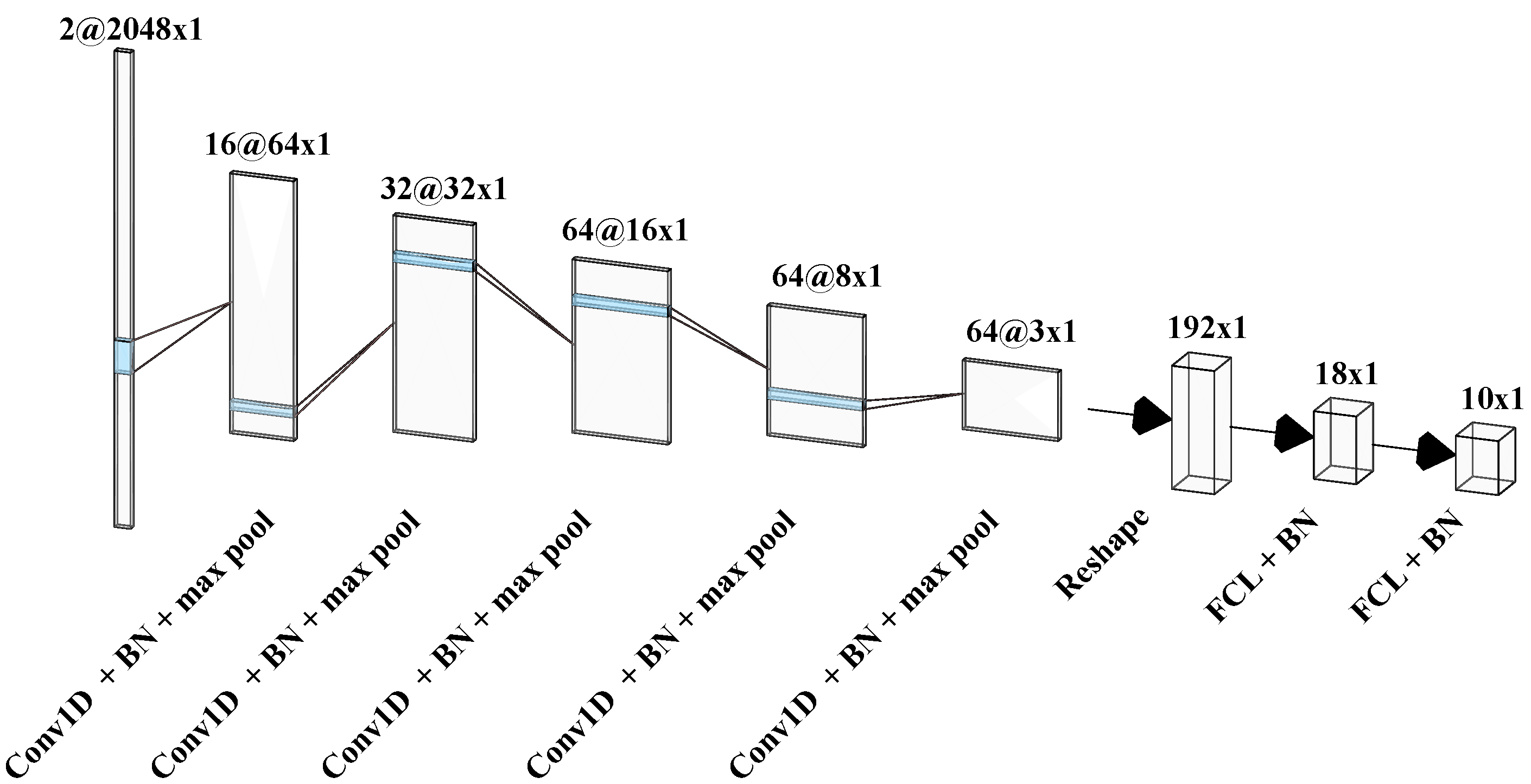
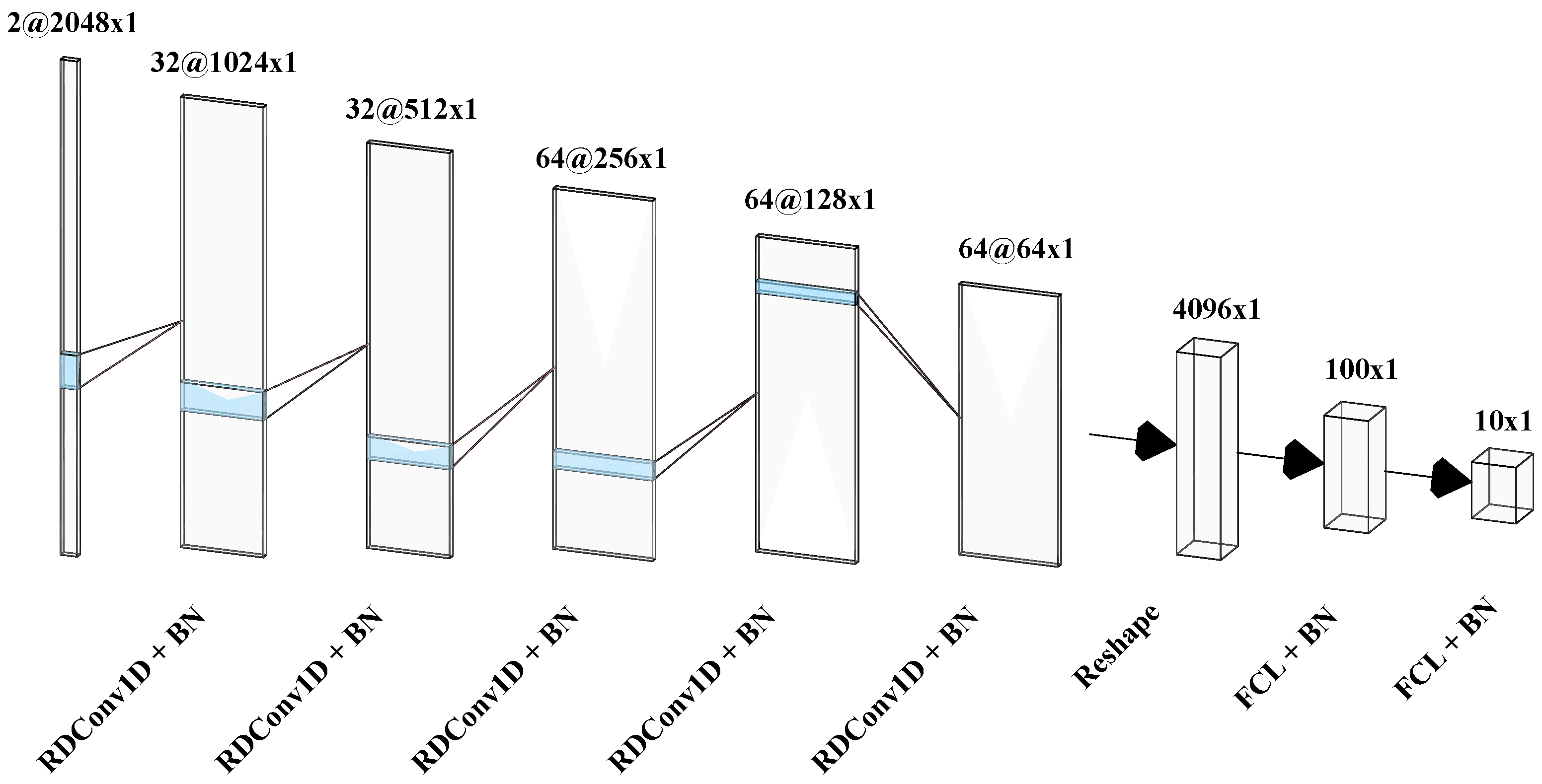

| Layer | Kernel Size | Channels in | Filters | Stride | Padding |
|---|---|---|---|---|---|
| Conv1D | 9 × 1 | 1 or 2 | 60 | 5 | 18 |
| Conv1D | 9 × 1 | 60 | 40 | 5 | 4 |
| Conv1D | 9 × 1 | 40 | 40 | 9 | 3 |
| FCL | 1×1 | 400 | 1 or 10 | N/A | N/A |
| Layer | Kernel Size | Channels in | Filters | Stride | Padding |
|---|---|---|---|---|---|
| Conv1D | 64 × 1 | 1 or 2 | 16 | 16 | 24 |
| Conv1D | 3 × 1 | 16 | 32 | 1 | 1 |
| Conv1D | 3 × 1 | 32 | 64 | 1 | 1 |
| Conv1D | 3 × 1 | 64 | 64 | 1 | 1 |
| Conv1D | 3 × 1 | 64 | 64 | 1 | 1 |
| FCL | 1×1 | 192 | 18 | N/A | N/A |
| FCL | 1×1 | 18 | 1 or 10 | N/A | N/A |
| Layer | Kernel Size | Channels in | Filters | Stride | Padding | Dilation |
|---|---|---|---|---|---|---|
| RDConv1D | 64 × 1 | 1 or 2 | 32 | 2 | 31 | 1 |
| RDConv1D | 32 × 1 | 32 | 32 | 2 | 31 | 2 |
| RDConv1D | 16 × 1 | 32 | 64 | 2 | 30 | 4 |
| RDConv1D | 8 × 1 | 64 | 64 | 2 | 28 | 8 |
| RDConv1D | 4 × 1 | 64 | 64 | 2 | 24 | 16 |
| FCL | 1×1 | 4096 | 100 | N/A | N/A | N/A |
| FCL | 1×1 | 100 | 1 or 10 | N/A | N/A | N/A |
| Load | Split | H | B | B | B | I | I | I | O | O | O |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 hp | Train Test | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 |
| 2 hp | Train Test | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 |
| 3 hp | Train Test | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 | 1980 59 |
| Thruster | Condition | B | G |
|---|---|---|---|
| 1 | Healthy Faulty | 263 468 | 283 448 |
| 2 | Healthy Faulty | 108 843 | 200 751 |
| 3 | Healthy Faulty | 125 405 | 216 314 |
| Total | Healthy Faulty | 496 1716 | 699 1513 |
| Data splits | Train Val Test | 48,230 11,960 368 | 77,740 19,110 592 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miettinen, J.; Nikula, R.-P.; Keski-Rahkonen, J.; Fagerholm, F.; Tiainen, T.; Sierla, S.; Viitala, R. Whitening CNN-Based Rotor System Fault Diagnosis Model Features. Appl. Sci. 2022, 12, 4411. https://doi.org/10.3390/app12094411
Miettinen J, Nikula R-P, Keski-Rahkonen J, Fagerholm F, Tiainen T, Sierla S, Viitala R. Whitening CNN-Based Rotor System Fault Diagnosis Model Features. Applied Sciences. 2022; 12(9):4411. https://doi.org/10.3390/app12094411
Chicago/Turabian StyleMiettinen, Jesse, Riku-Pekka Nikula, Joni Keski-Rahkonen, Fredrik Fagerholm, Tuomas Tiainen, Seppo Sierla, and Raine Viitala. 2022. "Whitening CNN-Based Rotor System Fault Diagnosis Model Features" Applied Sciences 12, no. 9: 4411. https://doi.org/10.3390/app12094411
APA StyleMiettinen, J., Nikula, R.-P., Keski-Rahkonen, J., Fagerholm, F., Tiainen, T., Sierla, S., & Viitala, R. (2022). Whitening CNN-Based Rotor System Fault Diagnosis Model Features. Applied Sciences, 12(9), 4411. https://doi.org/10.3390/app12094411