
Efficient Open-Set Recognition for Interference Signals Based on Convolutional Prototype Learning


Abstract
:1. Introduction
- We propose a new hollow convolution prototype learning (HCPL). A new hybrid loss function is designed that includes an inner-dot-based cross-entropy (ICE) loss, center loss (CL) and radius loss, to make the features of the known class signals at the periphery of the feature space;
- We propose a model that is used for the OSR of interference signals and called hybrid attention and feature reuse net (HAFRNet), which contains a feature reuse structure and hybrid domain attention module (HDAM);
- The influence of the hyperparameter in the hybrid loss function of HCPL is analyzed, and the role of HDAM and the feature reuse structure in the OSR of interference signals is proven in a simulation. The OSR experimental results of nine common interference types show that the proposed method has a better performance and less parameters than other methods under different openness.
2. Related Work
2.1. Interference Signal Recognition Based on Deep Learning
2.2. Open-Set Recognition
2.3. Prototype Learning
3. The Model of OSR of Interference Signals
4. Proposed Method
4.1. Feature Extractor and Prototype Classifier
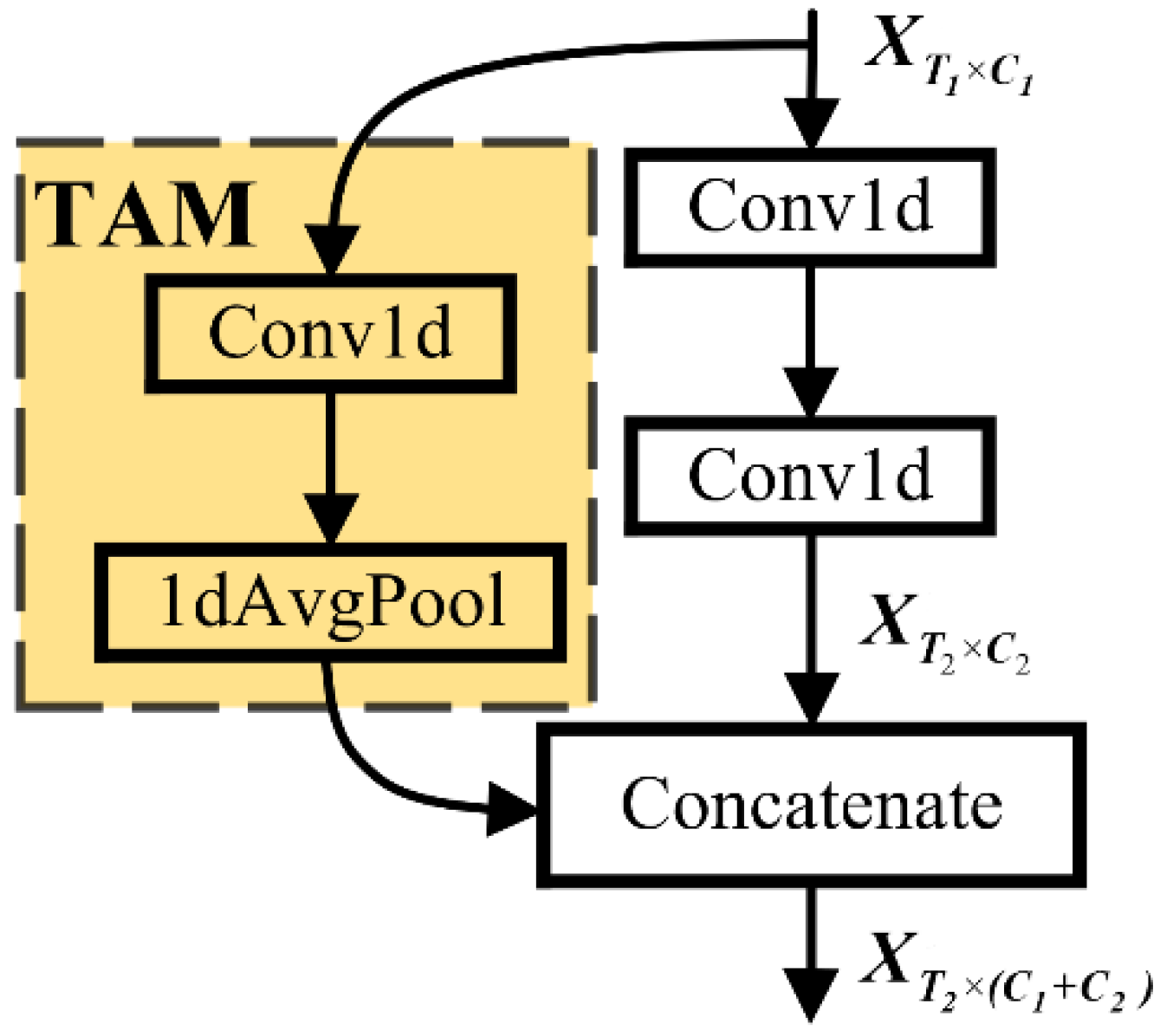
4.1.1. Feature Reuse Structure
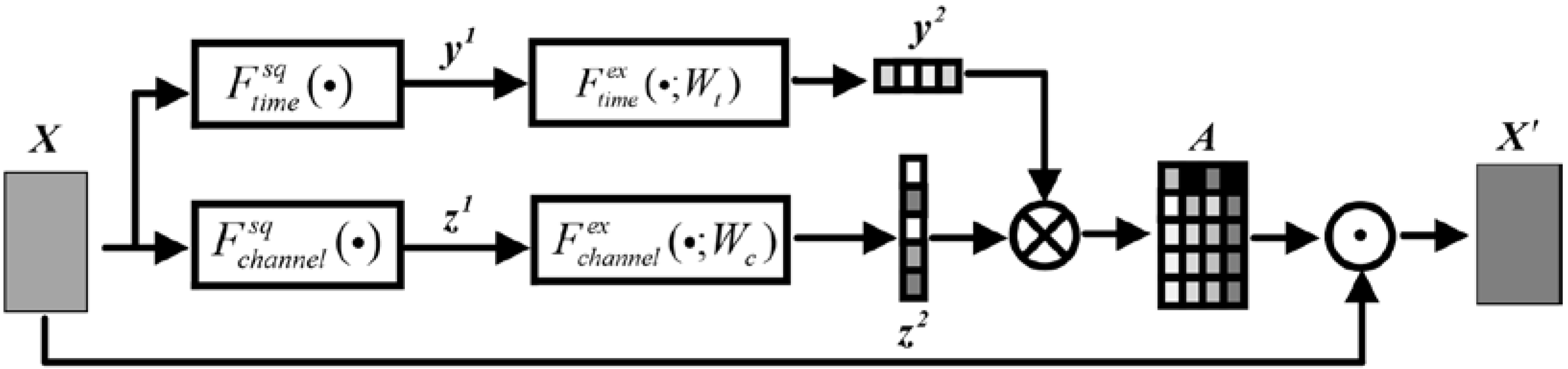
4.1.2. Hybrid Domain Attention Module
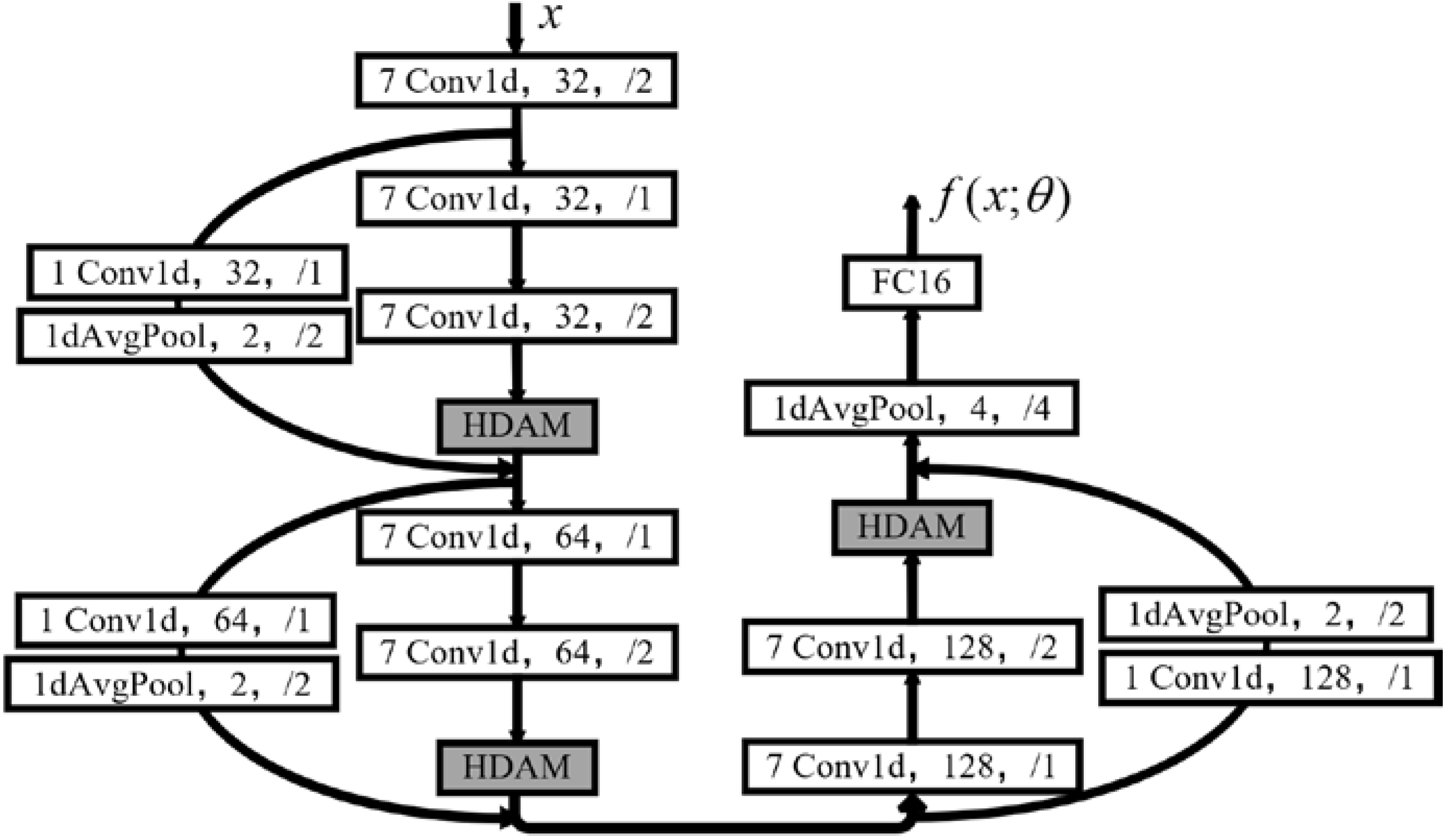
4.1.3. Hybrid Attention and Feature Reuse Net
4.1.4. Prototype Classifier
4.2. Hybrid Loss Function
5. Performance Analysis
5.1. Simulation Setting
5.1.1. Datasets
5.1.2. Structure of Feature Extractor
5.1.3. Performance Metrics
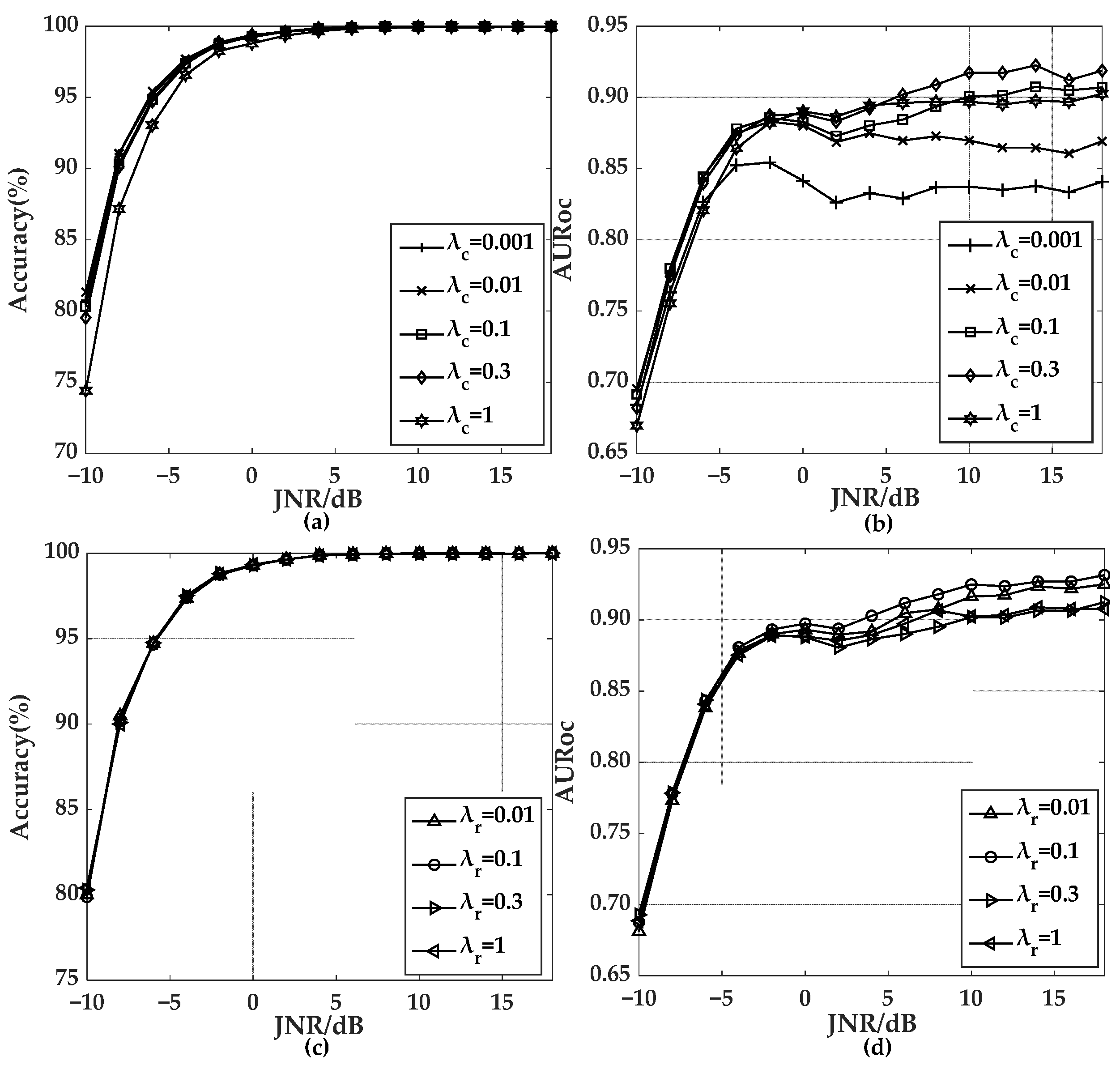
5.2. Effects of Hyperparameters of the Hybrid Loss Function
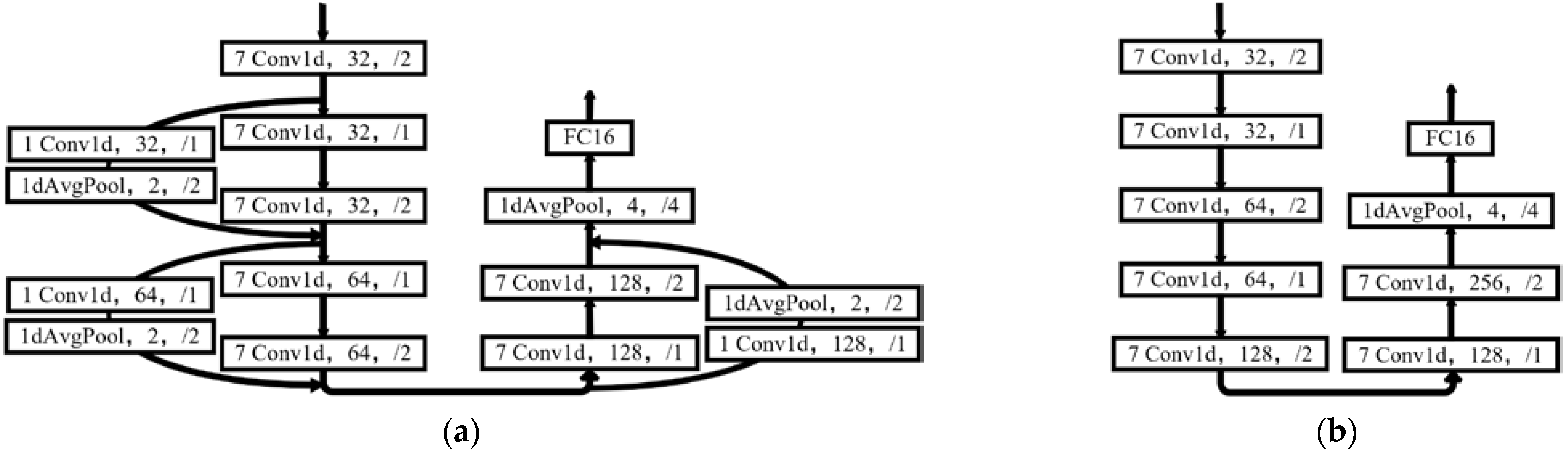
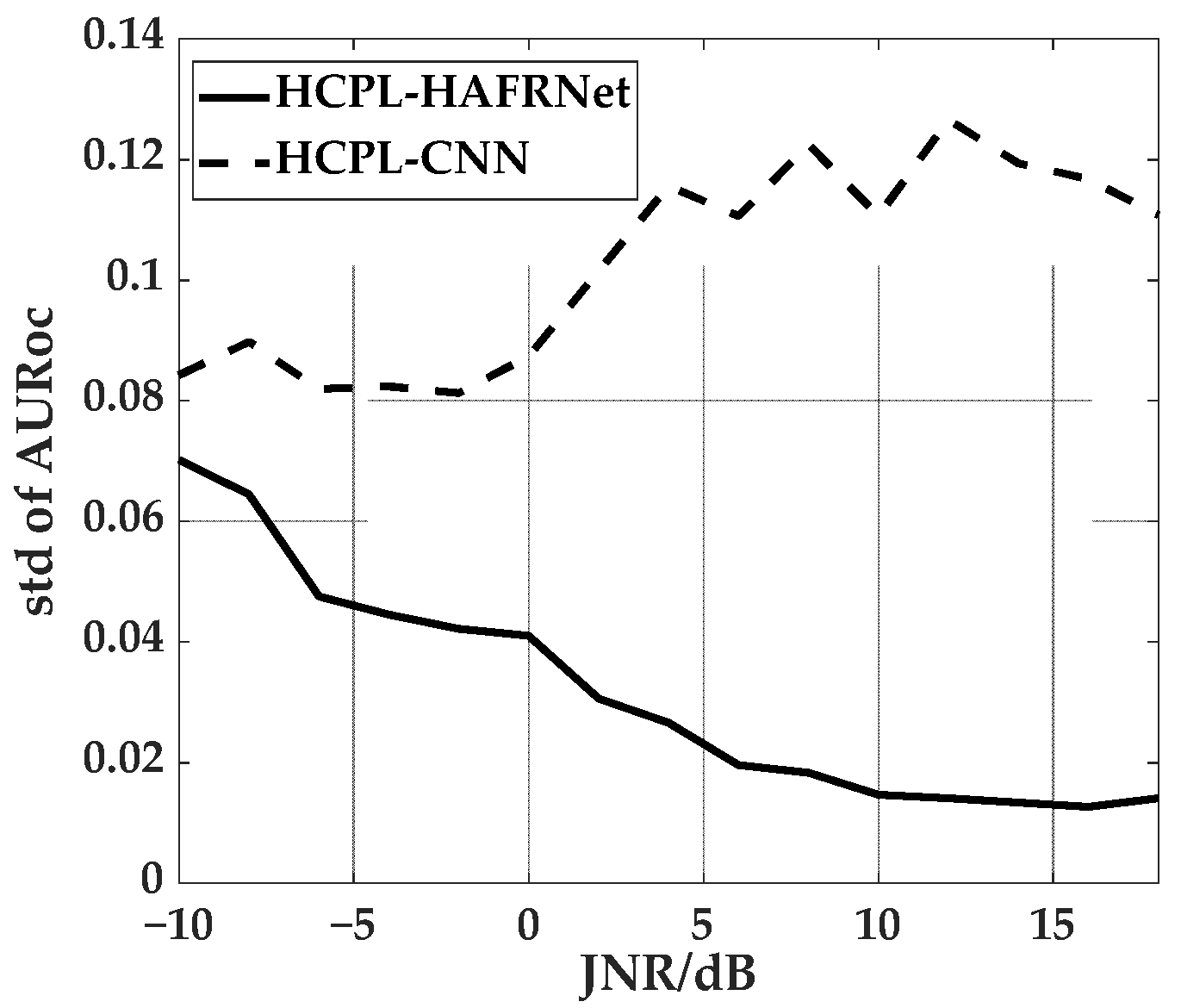
5.3. Effects of Feature Reuse Structure and HDAM
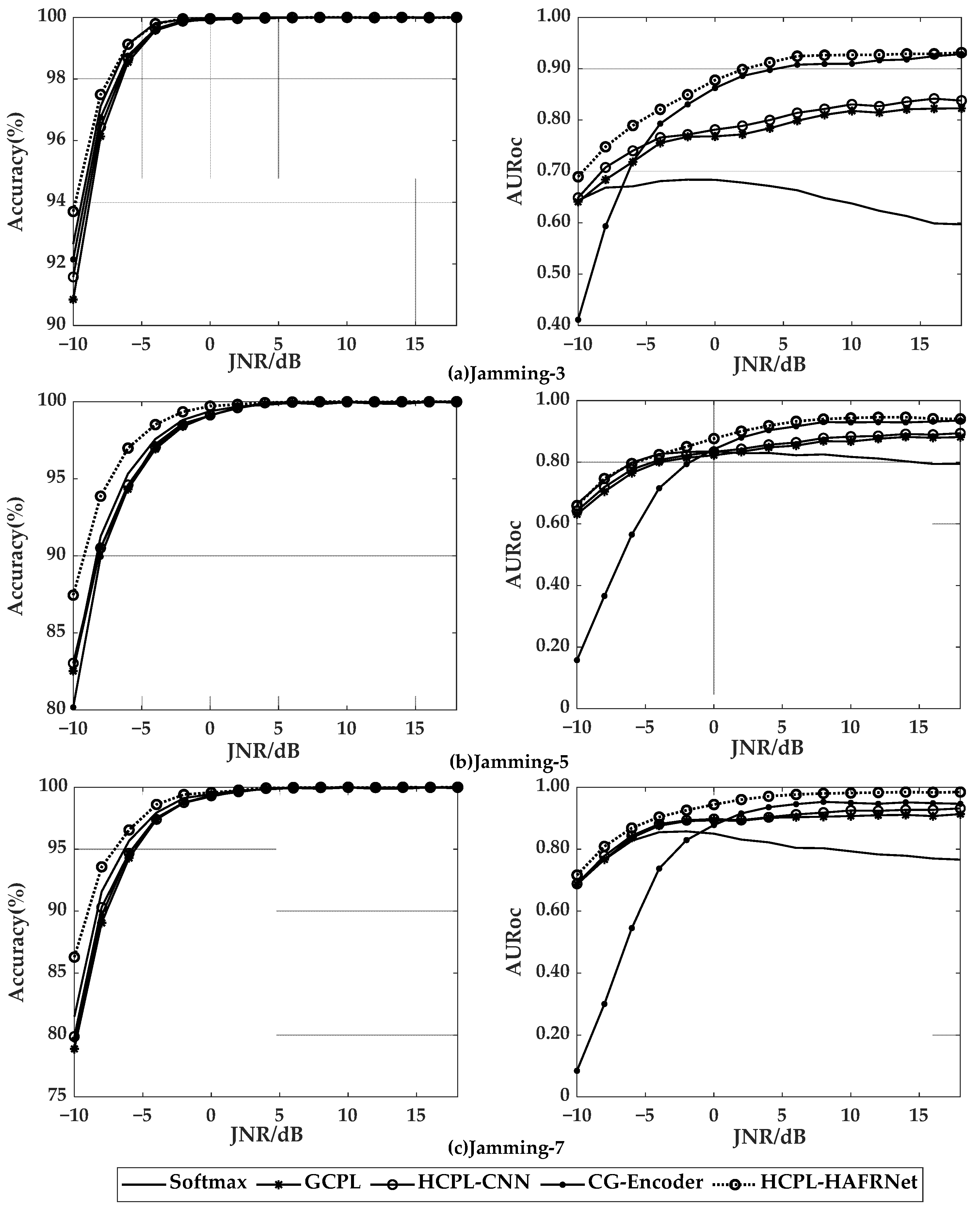
5.4. Comparison of Different Methods
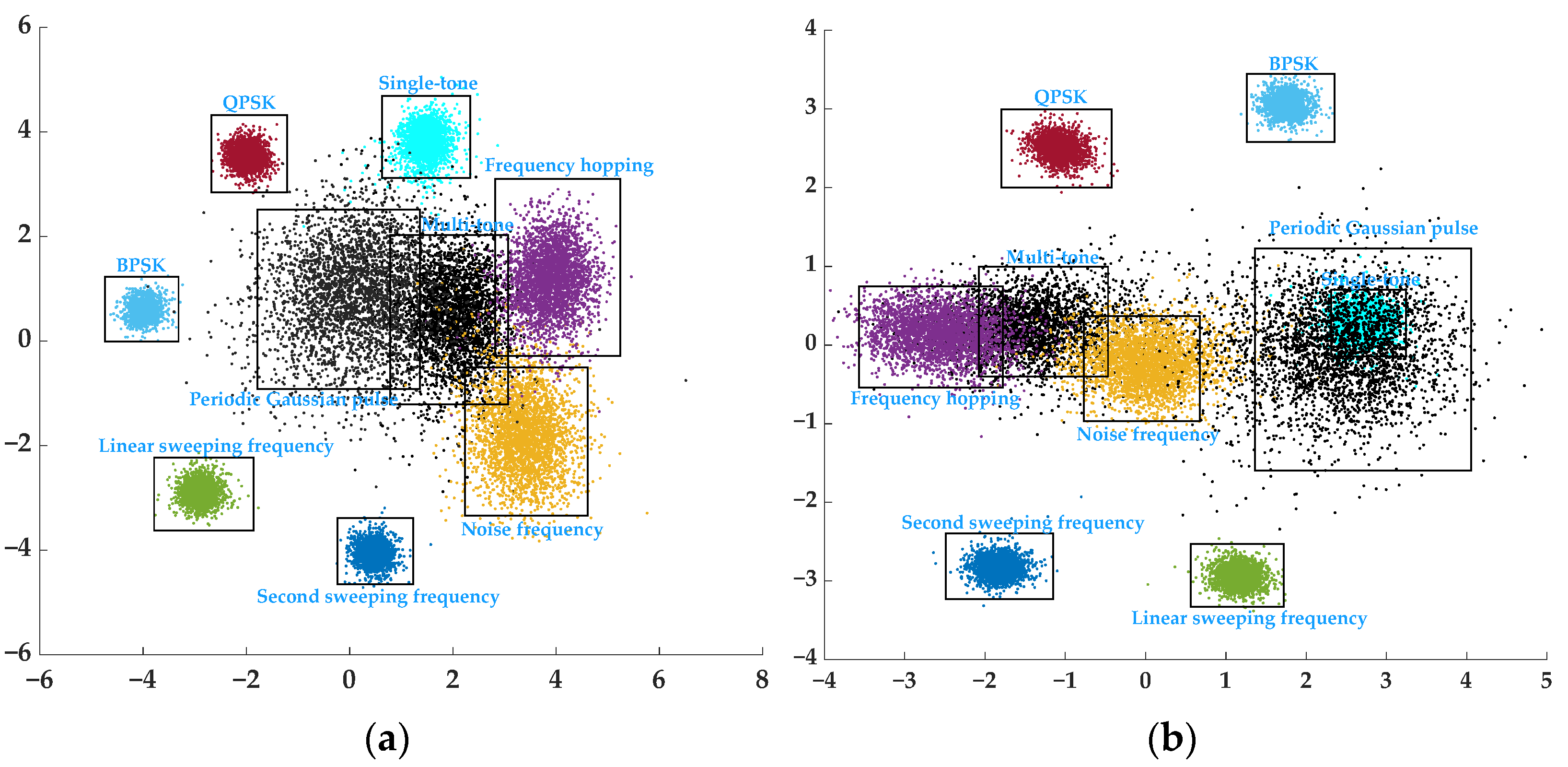
5.5. Visual Analysis of Featrue Space
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tang, Y.; Zhao, Z.; Li, C.; Ye, X. Open Set Recognition Algorithm Based on Conditional Gaussian Encoder. Math. Biosci. Eng. 2021, 18, 6620–6637. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Wang, H.; Zhou, K.; Cao, P. Low Probability of Intercept Radar Signal Recognition by Staked Autoencoder and SVM. In Proceedings of the 10th International Conference on Wireless Communications and Signal Processing (WCSP), Hangzhou, China, 18–20 October 2018; pp. 1–6. [Google Scholar]
- Wang, G.S.; Ren, Q.H.; Jiang, Z.; Liu, Y.; Xu, B. Jamming Classification and Recognition in Transform Domain Communication System Based on Signal Feature Space. Syst. Eng. Electron. 2017, 39, 1950–1958. [Google Scholar]
- Guoce, H.U.A.N.G.; Guisheng, W.A.N.G.; Qinghua, R.E.N.; Shufu, D.O.N.G.; Weiting, G.A.O.; Shuai, W.E.I. Adaptive Recognition Method for Unknown Interference Based on Hilbert Signal Space. J. Electron. Inf. Technol. 2019, 41, 1916–1923. [Google Scholar]
- Gao, M.; Li, H.; Jiao, B.; Hong, Y. Simulation Research on Classification and Identification of Typical Active Jamming Against LFM Radar. In Proceedings of the 11th International Conference on Signal Processing Systems (ICSPS), Chengdu, China, 15–17 November 2019; p. 11384. [Google Scholar]
- Lv, Q.; Qin, H. An Improved Method Based on Time-Frequency Distribution to Detect Time-Varying Interference for GNSS Receivers with Single Antenna. IEEE Access 2019, 7, 38608–38617. [Google Scholar] [CrossRef]
- Hao, Z.; Yu, W.; Chen, W. Recognition Method of Dense False Targets Jamming Based on Time-frequency Atomic Decomposition. J. Eng. 2019, 2019, 6354–6358. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, B.; Wang, N. Recognition of Radar Active-jamming through Convolutional Neural Networks. J. Eng. 2019, 2019, 7695–7697. [Google Scholar] [CrossRef]
- Liu, Q.; Zhang, W. Deep Learning and Recognition of Radar Jamming Based on CNN. In Proceedings of the 12th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 14–15 December 2019; pp. 208–212. [Google Scholar]
- Qu, Q.; Wei, S.; Liu, S.; Liang, J.; Shi, J. JRNet: Jamming Recognition Networks for Radar Compound Suppression Jamming Signals. IEEE Trans. Veh. Technol. 2020, 69, 15035–15045. [Google Scholar] [CrossRef]
- Shao, G.; Chen, Y.; Wei, Y. Convolutional Neural Network-Based Radar Jamming Signal Classification with Sufficient and Limited Samples. IEEE Access 2020, 8, 80588–80598. [Google Scholar] [CrossRef]
- Tang, Y.; Zhao, Z.; Ye, X.; Zheng, S.; Wang, L. Jamming Recognition Based on AC-VAEGAN. In Proceedings of the 15th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 6–9 December 2020; pp. 312–315. [Google Scholar]
- Wu, Q.; Sun, Z.; Zhou, X. Interference Detection and Recognition Based on Signal Reconstruction Using Recurrent Neural Network. In Proceedings of the IEEE Globecom Workshops (GC Wkshps), Hawaii Big Island, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Man, F.E.N.G.; Zinan, W.A.N.G. Interference Recognition Based on Singular Value Decomposition and Neural Network. J. Electron. Inf. Technol. 2020, 42, 2573–2578. [Google Scholar]
- Peng, S.; Sun, S.; Yao, Y.D. A Survey of Modulation Classification Using Deep Learning: Signal Representation and Data Preprocessing. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Sun, Z.; Yue, G. Siamese Network-based Open Set Identification of Communications Emitters with Comprehensive Features. In Proceedings of the 6th International Conference on Communication, Image and Signal Processing (CCISP), Chengdu, China, 19–21 November 2021; pp. 408–412. [Google Scholar]
- Karunaratne, S.; Hanna, S.; Cabric, D. Open Set RF Fingerprinting using Generative Outlier Augmentation. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–7. [Google Scholar]
- Xu, Y.; Qin, X.; Xu, X.; Chen, J. Open-Set Interference Signal Recognition Using Boundary Samples: A Hybrid Approach. In Proceedings of the International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 21–23 October 2020; pp. 269–274. [Google Scholar]
- Gong, J.; Qin, X.; Xu, X. Multi-Task Based Deep Learning Approach for Open-Set Wireless Signal Identification in ISM Band. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 121–135. [Google Scholar] [CrossRef]
- Miller, D.; Sunderhauf, N.; Milford, M.; Dayoub, F. Class Anchor Clustering: A Loss for Distance-based Open Set Recognition. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 3569–3577. [Google Scholar]
- Yang, H.M.; Zhang, X.Y.; Yin, F.; Liu, C.L. Robust Classification with Convolutional Prototype Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3474–3482. [Google Scholar]
- Yang, H.M.; Zhang, X.Y.; Yin, F.; Yang, Q.; Liu, C.L. Convolutional Prototype Network for Open Set Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2358–2370. [Google Scholar] [CrossRef] [PubMed]
- Awan, M.J.; Rahim, M.S.M.; Salim, N.; Rehman, A.; Nobanee, H.; Shabir, H. Improved Deep Convolutional Neural Network to Classify Osteoarthritis from Anterior Cruciate Ligament Tear Using Magnetic Resonance Imaging. J. Pers. Med. 2021, 11, 1163. [Google Scholar] [CrossRef] [PubMed]
- Bendale, A.; Boult, T.E. Towards Open Set Deep Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 1563–1572. [Google Scholar]
- Kardan, N.; Stanley, K.O. Mitigating Fooling with Competitive Overcomplete Output Layer Neural Networks. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 518–525. [Google Scholar]
- Neal, L.; Olson, M.; Fern, X.; Wong, W.K.; Li, F. Open Set Learning with Counterfactual Images. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 620–635. [Google Scholar]
- Jo, I.; Kim, J.; Kang, H.; Kim, Y.D.; Choi, S. Open Set Recognition by Regularising Classifier with Fake Data Generated by Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2686–2690. [Google Scholar]
- Yang, Y.; Hou, C.; Lang, Y.; Guan, D.; Huang, D.; Xu, J. Open-set Human Activity Recognition Based on Micro-Doppler Signatures. Pattern Recognit. 2019, 85, 60–69. [Google Scholar] [CrossRef]
- Yue, Z.; Wang, T.; Sun, Q.; Hua, X.S.; Zhang, H. Counterfactual Zero-Shot and Open-Set Visual Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 15399–15409. [Google Scholar]
- Kong, S.; Ramanan, D. OpenGAN: Open-Set Recognition via Open Data Generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 10 March 2021; pp. 813–822. Available online: https://arxiv.org/abs/2104.02939 (accessed on 20 March 2022).
- Hendrycks, D.; Mazeika, M.; Dietterich, T. Deep Anomaly Detection with Outlier Exposure. In Proceedings of the 7th International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Sun, X.; Yang, Z.; Zhang, C.; Ling, K.V.; Peng, G. Conditional Gaussian Distribution Learning for Open Set Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13477–13486. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A Discriminative Feature Learning Approach for Deep Face Recognition. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 499–515. [Google Scholar]
- Geng, C.; Huang, S.J.; Chen, S. Recent Advances in Open Set Recognition: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3614–3631. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dhamija, A.R.; Günther, M.; Boult, T. Reducing Network Agnostophobia. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NIPs), Montreal, QC, Canada, 2–8 December 2018; pp. 9157–9168. [Google Scholar]
- Chen, G.; Qiao, L.; Shi, Y.; Peng, P.; Li, J.; Huang, T.; Tian, Y. Learning Open Set Network with Discriminative Reciprocal Points. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 507–522. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Interference Types | Parameter Setting |
|---|---|
| Single-tone | The center frequency is between [100, 500] kHz, and the phase is between [0, 2π]. |
| Multitone | The number of audio is [2, 10], and , are the same as single-tone jamming. |
| Periodic Gaussian pulse | The pulse period is 2.5~10 μs, and the duty cycle is 1/8~1/2. |
| Frequency hopping | N = 20, {} is between [100, 500] kHz, the frequency hopping period is between 3.2~6.4 μs, and the phase is between [0, 2π]. |
| Linear sweeping frequency | The starting frequency is [50, 100] kHz, and the ending frequency is [300, 1000] kHz. |
| Second sweeping frequency | The frequency is quadratic, and other parameters are the same as linear sweeping frequency jamming. |
| BPSK modulation | The information symbol is a 32-bits 0,1 random sequence, the symbol period is 3.2 μs, and the modulation signal is sinusoidal signal. |
| Noise frequency | The frequency modulation coefficient is between [0.125, 0.933], and the carrier signal parameters are the same as single-tone jamming. |
| QPSK modulation | The information symbol is a 32-bit 0,1 random sequence, the symbol period is 3.2 μs, I-channel modulation signal is sinusoidal signal, Q-channel modulation signal is cosine signal. |
| Dataset (Openness)\Method | GCPL | CG-Encoder | HCPL-CNN | HCPL-HAFRNet |
|---|---|---|---|---|
| Jamming-2(0.397) | 0.8102 | 0.9088 | 0.8132 | 0.8921 |
| Jamming-3(0.293) | 0.8197 | 0.9193 | 0.8346 | 0.9287 |
| Jamming-4(0.216) | 0.8409 | 0.9289 | 0.8677 | 0.9369 |
| Jamming-5(0.155) | 0.8774 | 0.9313 | 0.8888 | 0.9437 |
| Jamming-6(0.106) | 0.8854 | 0.9397 | 0.9071 | 0.9690 |
| Jamming-7(0.065) | 0.9093 | 0.9412 | 0.9268 | 0.9834 |
| Jamming-8(0.030) | 0.9403 | 0.9869 | 0.9710 | 0.9883 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Zhao, Z.; Ye, X.; Zheng, S.; Lou, C.; Yang, X. Efficient Open-Set Recognition for Interference Signals Based on Convolutional Prototype Learning. Appl. Sci. 2022, 12, 4380. https://doi.org/10.3390/app12094380
Chen X, Zhao Z, Ye X, Zheng S, Lou C, Yang X. Efficient Open-Set Recognition for Interference Signals Based on Convolutional Prototype Learning. Applied Sciences. 2022; 12(9):4380. https://doi.org/10.3390/app12094380
Chicago/Turabian StyleChen, Xiangwei, Zhijin Zhao, Xueyi Ye, Shilian Zheng, Caiyi Lou, and Xiaoniu Yang. 2022. "Efficient Open-Set Recognition for Interference Signals Based on Convolutional Prototype Learning" Applied Sciences 12, no. 9: 4380. https://doi.org/10.3390/app12094380
APA StyleChen, X., Zhao, Z., Ye, X., Zheng, S., Lou, C., & Yang, X. (2022). Efficient Open-Set Recognition for Interference Signals Based on Convolutional Prototype Learning. Applied Sciences, 12(9), 4380. https://doi.org/10.3390/app12094380