1. Introduction
Frame-to-frame scan matching is the process of obtaining the relative pose between two frames whose visual fields overlap with one another. Frame-to-frame scan matching is a basic module for robot localization and mapping and has a great impact on the accuracy of localization and mapping. High-precision frame-to-frame scan matching can significantly improve the loop detection accuracy while reducing the computational burden of loop detection. Therefore, frame-to-frame scan matching plays an important role in robot state estimation. A high-precision frame-to-frame scan matching algorithm is critical to improve the autonomous navigation capabilities of robots.
Frame-to-frame matching algorithms can be divided into two categories based on the type of sensor used: laser frame-to-frame matching algorithms and visual frame-to-frame matching algorithms. Compared to visual sensors, laser lidar has anti-interference capabilities, and its performance is not affected by light. Moreover, the research results of this paper are mainly applied to indoor service robots, so 2D lidar sensors were adopted for scan matching.
Due to the importance of the frame-to-frame scan matching algorithm, it has attracted much research attention, and research has resulted in many milestone findings. The most classic frame-to-frame scan matching algorithm is the Iterative Closest Point (ICP) algorithm proposed by Besl et al. [
1]. ICP associated each lidar point in the current frame with the lidar points in the reference frame to construct constraints, allowing the relative pose be obtained with the Horn method [
2], and the relative pose was then applied in the current frame. The ICP continues to repeat this process until convergence. A large number of variants [
3] have been proposed based on ICP. Andrea [
4] proposed Point-to-Line ICP (PL-ICP), which overcomes the shortcomings of low-resolution lidar data and has quadratic convergence properties, achieving fewer iterations and higher accuracy, and this algorithm performed well in a structured environment. Similar to the PL-ICP, Segal et al. [
5] proposed a probabilistic version of the ICP: GICP (Generalized ICP), which uses Gaussian distribution to model the lidar sensor data and assigns weights according to the normal vector. This algorithm can be considered to be a variant of Point-to-Plane ICP [
6]. In order to speed up the scan matching ability of the GICP, Koide [
7] proposed the use of voxels to accelerate nearest neighbor searching. Serafin [
8] introduced normal vector and curvature information into the ICP. He first filtered wrong matches with the normal vectors and curvature and then added the normal vector alignment error term into the error function to obtain a more accurate angle estimation. Deschaud [
9] used the Implicit Moving Least Square (IMLS) method to model the surface in the point cloud and proposed the IMLS-ICP, building an accurate surface model so that the scan matching accuracy was greatly improved. Liu et al. [
10] proposed a precise point set registration method that introduced correntropy measurements to weaken the influence of noise and introduced an adaptive feature fusion algorithm that was distribution specific. Yin et al. [
11] proposed a novel probabilistic variant of the iterative closest point algorithm that leverages both local geometrical information and the global noise characteristics. Liao et al. [
12] proposed new ICP variants that used fuzzy clusters to represent scans with a broad convergence basin and with good noise robustness. Moreover, they also developed a branch-and-bound-based global optimization scheme that was able to minimize the metrics globally regardless of the initialization technique. Li et al. [
13] have carried out a number of studies to determine impact factors such as the overlap ratio, angle difference, distance difference, and noise to come up with a global solution to the ICP algorithm. Liu et al. [
14] proposed a global point set registration method that decouples the optimization of translation and rotation. Additionally, the global translation parameter was obtained first using a fast branch-and-bound method, and then the optimal rotation parameter was calculated using the global translation parameter.
In addition to the ICP algorithm and its variants, there are different methods for frame-to-frame scan matching. Biber et al. [
15] proposed the Normal Distribution Transform (NDT) algorithm, which assumes that the environmental structure has local continuity and constructs multiple local Gaussian distributions to represent the overall geometric structure of the environment and achieves registration by minimizing the distance between the lidar point to the normal distribution. The NDT method is widely used in robot mapping and localization tasks [
16]. Joe et al. [
17] proposed a sonar scan matching method based on NDT that combined two different sonars to reduce the drift errors. Bouraine et al. [
18] proposed a scan matching method based on NDT and particle swarm optimization that could determine the global optimal solution with 70 particles. To overcome the influence of local extrema on the matching results, Olson [
19] proposed the Correlative Scan Match (CSM) method, which divides the search area into grids and then enumerates the poses corresponding to each grid to obtain the robot’s position. The CSM method avoids the influence of local extreme values through enumeration. Ren et al. [
20] proposed an improved CSM method that analyzes environmental degradation with a covariance matrix, which greatly improved the robustness of the algorithm in complex environments. Kohlbrecher et al. [
21] proposed the construction of a local grid map and then generated a continuous likelihood map with Lagrangian interpolation before using the Gauss–Newton method to register the algorithm. Ali et al. [
22] proposed a novel end-to-end trainable deep neural network for rigid point set registration: RPSRNet, which used a novel 2
D-tree representation for the input point sets and hierarchical deep feature embedding in the neural network. Zhang et al. [
23] proposed the lidar odometry and mapping (LOAM) method, which utilizes edge features and planar features in the lidar scans. LOAM is very suitable for structured environments. To improve the accuracy, Zhang et al. [
24] proposed fusing lidar and vision to construct a more accurate odometry. Shan et al. [
25] proposed a lightweight and ground-optimized lidar odometry and mapping (Lego-LOAM) algorithm that leverages the presence of a ground plane during its segmentation and optimization steps and that utilizes two-step optimization to solve different components of the transform matrix.
All of the methods above use two consecutive frames for scan matching, and the pose is integrated frame by frame, so the matching error also accumulates frame by frame. Although strategies have been adopted to minimize the matching error between frames, the increase in the error frame by frame still limits their matching accuracy. Moreover, these methods use most of the laser points for scan matching, resulting in a low matching efficiency. Although we can integrate data sampling methods [
26,
27] to improve the computational efficiency, this would reduce the matching accuracy.
To overcome the shortcomings of the above methods, we introduce an attention mechanism and propose a scan matching method to achieve both high accuracy and computational efficiency. This paper introduces an attention mechanism into the frame-to-frame scan matching algorithm. Different from the above methods, the proposed method only accumulates errors when the attention area is switched. Additionally, the proposed method only uses the lidar data covered by the attention area, so it has very high computational efficiency.
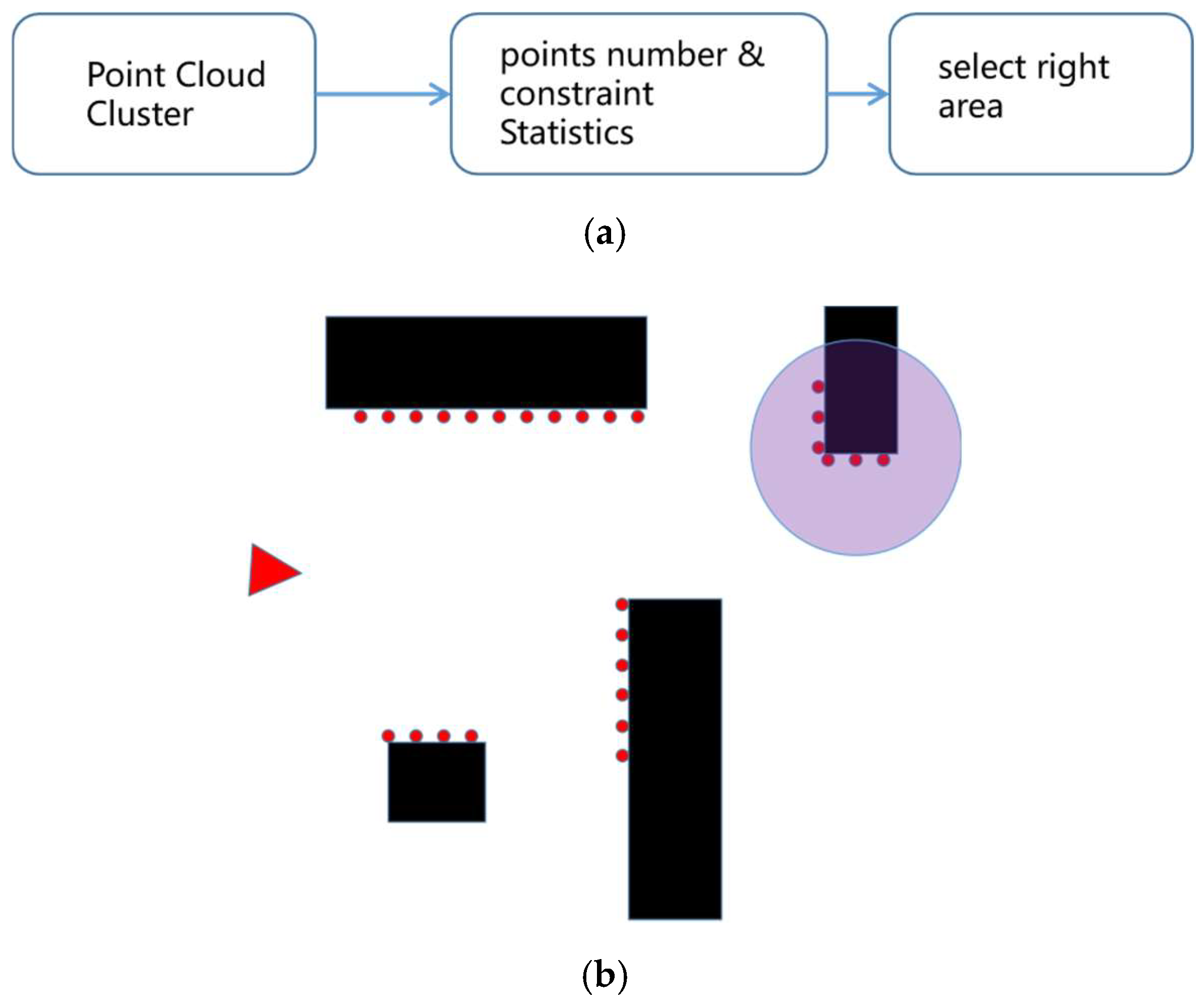
First, we selected a frame as a reference frame and chose an object as a landmark that was far enough away. The size of the landmark must be larger than the given threshold, and the landmark must provide enough information to obtain the relative pose; secondly, we chose the odometer to determine the initial pose of the selected frame and to determine the relative pose between the current frame and the landmark, extracting the corresponding data. Thirdly, the relative pose between the current frame and the reference frame was obtained based on the corresponding data. Finally, if the selected landmark reached the edge of the visual field of the current frame, then a new landmark was selected from the current frame as the reference landmark for the subsequent frame, and the current frame became the new reference frame. Landmark selection is part of the attention construction process, and once the attention has been constructed, the scan matching algorithm only considers the area covered by the attention and ignores other areas. As a result, the number of required calculations is greatly reduced. Since most current lidars have a measurement range of 20 m, the robot can move 20 m without accumulating errors using the ASM method in the ideal conditions. The main contributions of this work are as follows:
- (1)
This paper proposes the concept of an attention mechanism. Additionally, we introduce this mechanism into the frame-to-frame scan matching algorithm, significantly improving the accuracy and computational efficiency of the scan matching algorithm.
- (2)
This paper proposes attention area selection, attention area update, and attention area scan matching methods that successfully integrate the attention mechanism into the scan matching algorithm.
- (3)
The proposed attention-based scan matching algorithm is evaluated on multiple real-world datasets, and it outperforms the current state-of-the-art methods in terms of accuracy and efficiency.
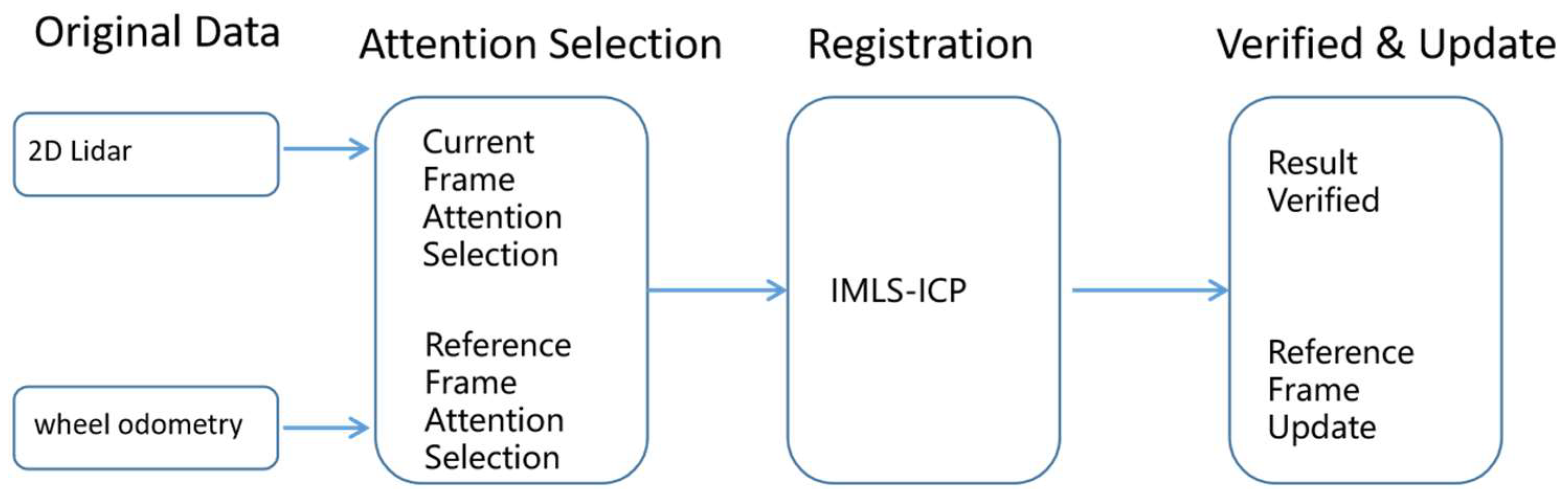
4. Pose Matching Module
After the attention area has been selected, two-point cloud sets from the attention area of the reference frame and from the attention area of the current frame are available. The pose matching module needs to calculate the relative poses of these two-point cloud sets. There are many ways to solve point cloud registration problems. To minimize the impact of sensor noise, a scan-to-model method [
9] that uses the implicit moving least squares method (IMLS) was adopted to model the plane of the point cloud obtained from the reference frame. The distance from the laser point
p in the current frame to the plane is shown in Equation (7) [
29]:
where
S represents the point cloud of the attention area in the reference frame,
ni represents the normal vector of the corresponding laser point,
σ is the artificially set attenuation factor, and
W is an exponential function, and it decays quickly with distance and with the consideration of the reference frame points where the distance
p exceeds 3
σ is not necessary. Equation (7) implicitly expresses the hidden surface in the reference frame. It assumes that the sampling noise of the point cloud to the surface obeys Gaussian distribution, so the number and distribution of the sampling points on both sides of the surface are the same. Moreover, the points on the surface are substituted into Equation (7), and the obtained distance value d is theoretically equal to 0; that is to say, all of the points satisfying
d = 0 constitute a hidden surface.
Based on Equation (7), the objective function of scan-to-model matching method is obtained and is presented as follows:
where
C represents all of the point clouds in the attention area of the current frame,
T represents the transformation matrix corresponding to the robot pose, and its expression was shown earlier in Equation (6).
Equation (8) represent an exponential function that is a nonlinear least square problem. In order to solve the registration problem more effectively, a point
qi on the surface is obtained as a matching point for each point
pi in the current frame, and the objective function of the matching method is shown in Equation (9).
Since the initial pose of the current frame is determined by wheel odometry, the error rate can be controlled within a small range. When the angle error is small, a small angle approximation can be introduced [
30], and
T can be expressed as
By introducing the approximation shown in Equation (10), Equation (9) can be simplified as follows:
Obviously, Equation (11) is a linear equation system, and the independent variables can be extracted:
If we substitute Equation (12) into Equation (9), then we can achieve
Equation (13) is a linear least squares equation, where
A and
b can be expressed as follows:
For the linear least squares problem described in Equation (13), matrix A can be decomposed by means of SVD, and the singular vector corresponding to the minimum singular value of matrix A is the solution of the corresponding problem.
5. Result Verification and Key-Frame Selection Module
Through the above two modules, the pose of the current frame can be determined. Next, the current frame needs to be verified to determine whether the pose of the current frame is accurate. Moreover, whether the reference frame needs to be updated according to the position of the reference frame landmark in the current frame needs to be determined. The purpose of verifying the matching result is to prevent a jump problem in the matching pose caused by insufficient constraints. Two methods can be used to verify the post, with the first method calculating the difference between the wheel odometry pose and the scan matching pose. The pose difference is defined in Equation (15). If the difference is less than a certain threshold, the scan matching pose is considered legal; otherwise, the scan matching pose is illegal.
Here,
Todom represents the transformation matrix corresponding to the odometry pose,
Tsm represents the transformation matrix corresponding to the scan matching pose, and
T2V () represents the function that extract the robot pose from the transformation matrix and is expressed as follows:
The second method evaluates the correctness of the pose using the degree of overlap between the attention area of the current frame and the reference frame. Since the two areas represent the same object in the physical space, the degree of overlap can be large if the pose is correct. The degree of overlap in the two areas is defined as the reference area generating a distance field, each grid storing the distance to the nearest obstacle, and the current area being converted to the distance field. If the distance from the obstacle to the point is less than the threshold, then the point and the reference frame are considered to be overlapping. The number of overlapping points is counted, and the ratio of the number of overlapping points to the total number of points indicates the degree of overlap between the current area and the reference area. The degree of overlap ranges from 0 to 1. When the degree of overlap is greater than the threshold, then the pose is considered accurate; otherwise, the pose is considered inaccurate, and the odometry pose is used to replace the matching pose.
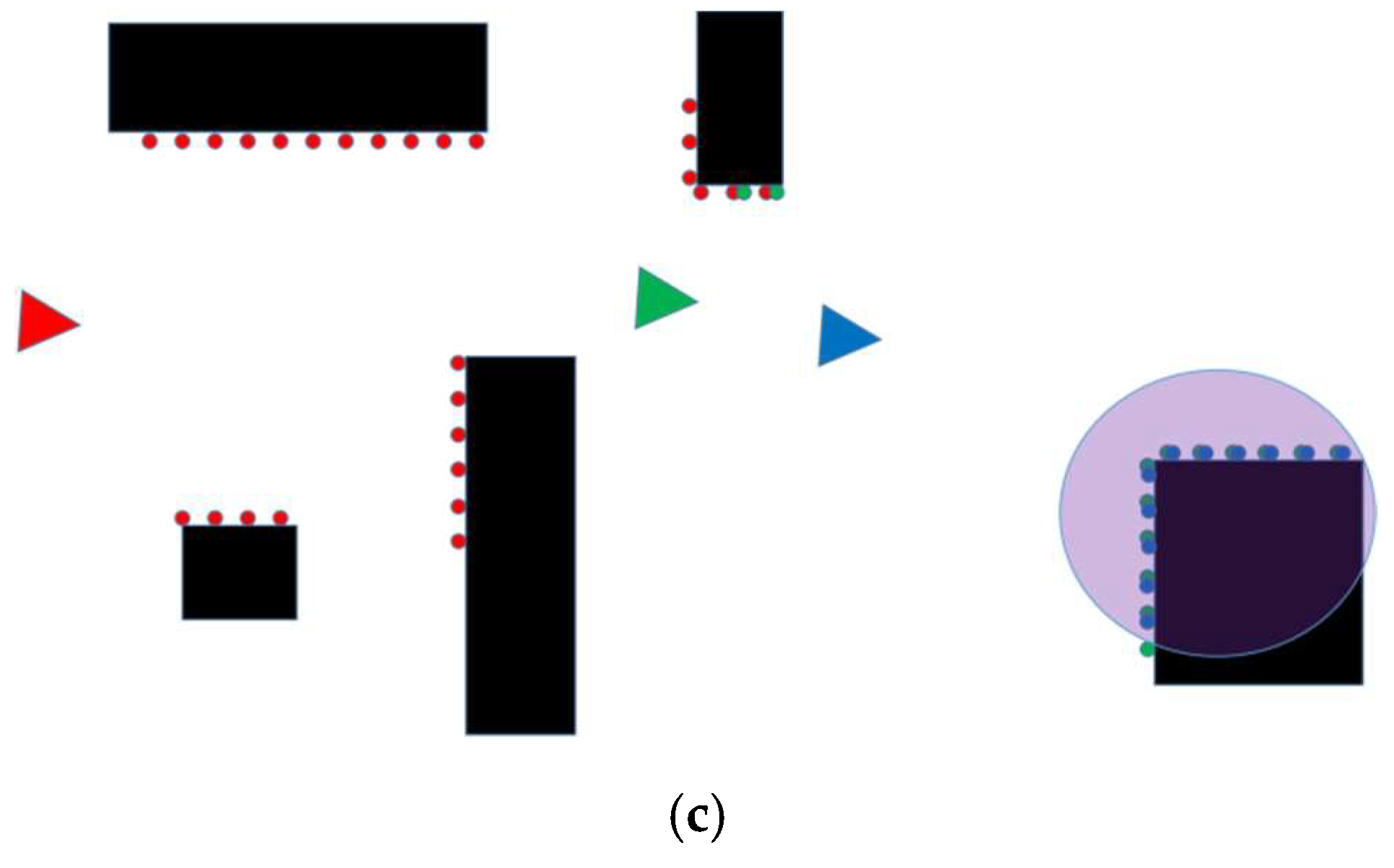
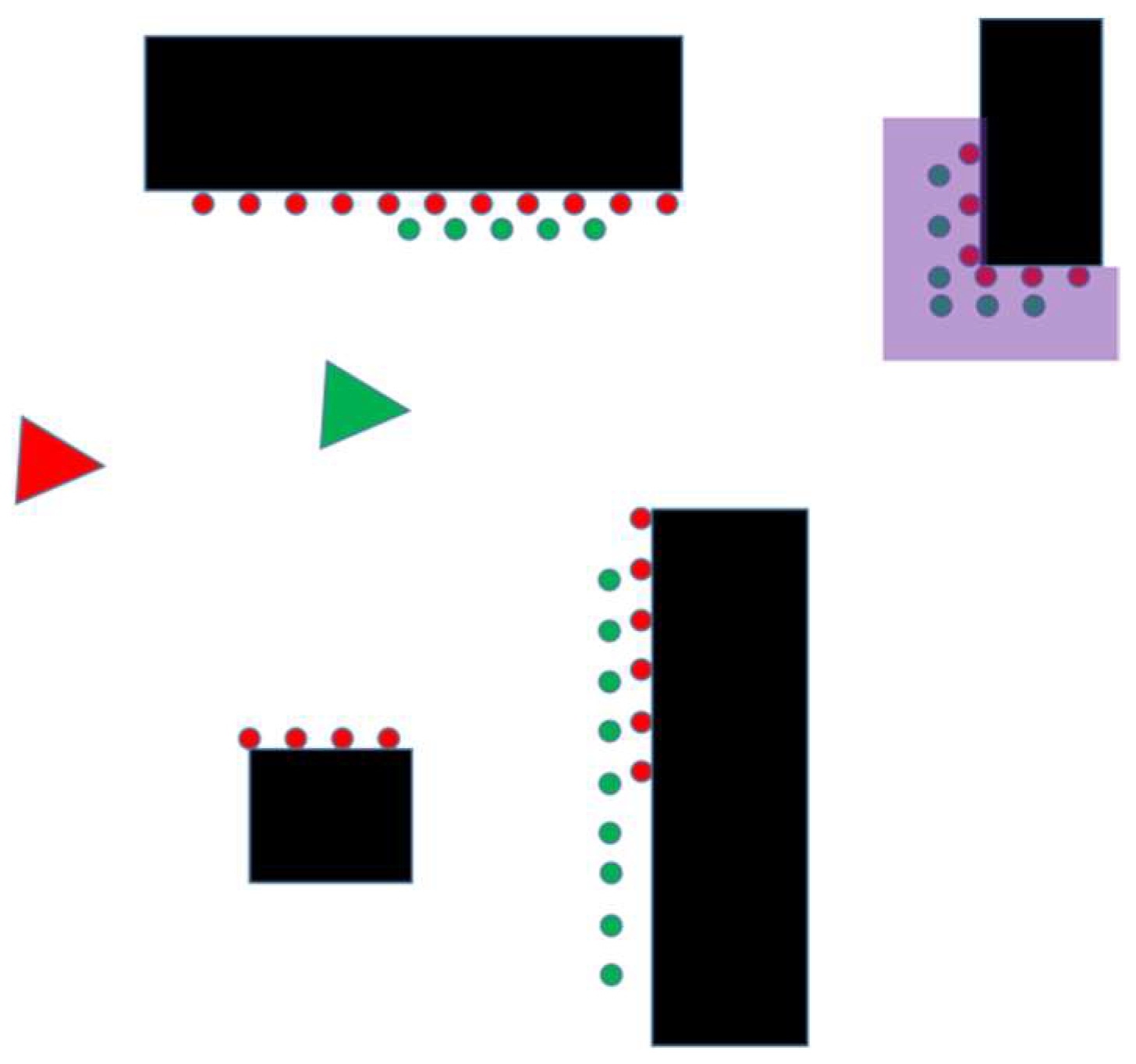
After the pose of the current frame is determined, whether the current frame needs to be updated to a new reference frame needs to be determined. If the current frame is to become the new reference frame, then it needs to meet two conditions: the distance of the current landmark from the origin of the current frame needs to be less than the threshold so that a suitable landmark can be selected in the current frame. If the current landmark is close to the origin of the current frame, then a new landmark selection strategy needs to be undertaken. The new landmark selection method is shown in
Section 3.1. If a landmark that meets the requirements is selected, then the current frame is used as the new reference frame, and the landmark corresponding to the current frame is used as the new landmark, as shown in
Figure 4.
In
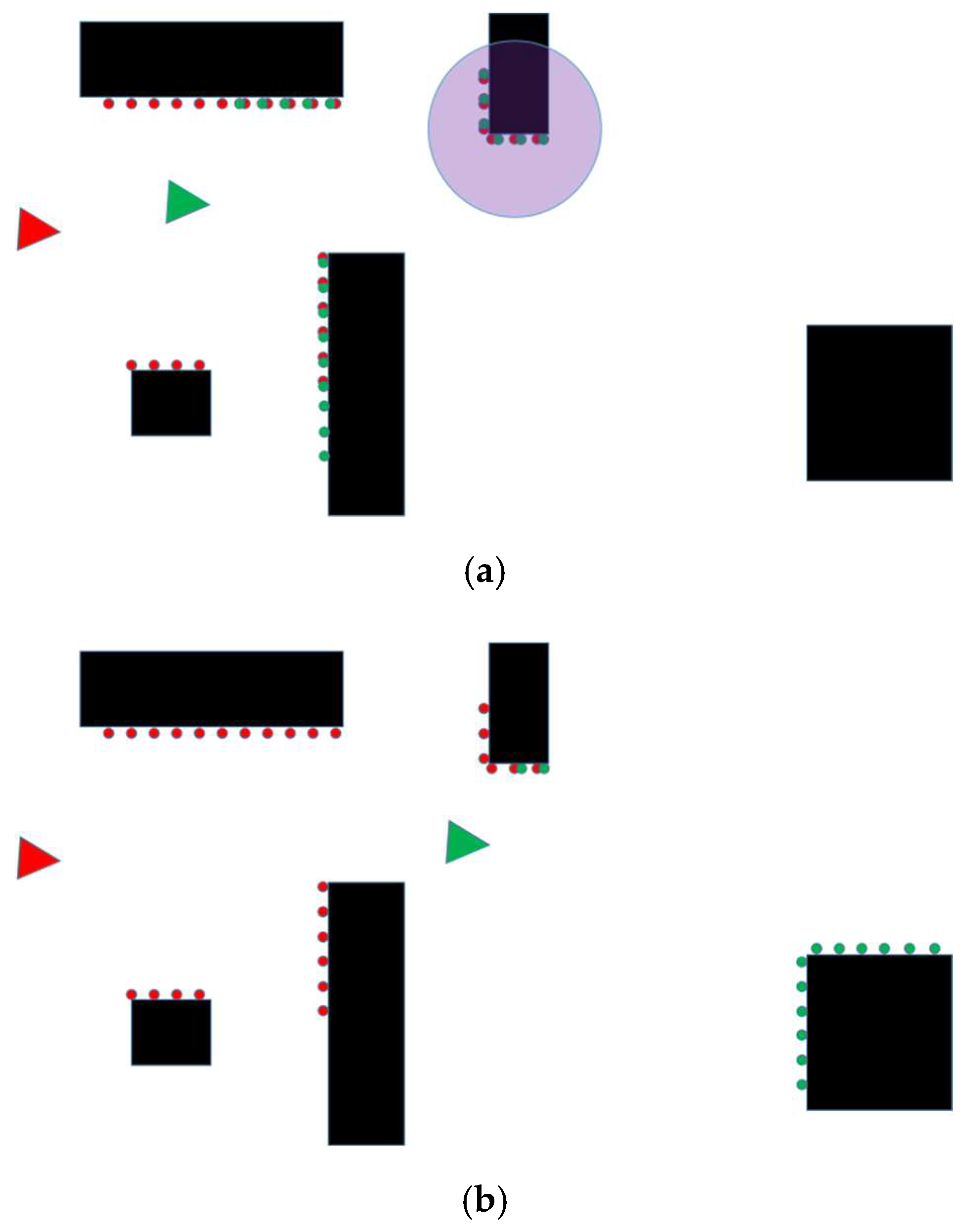
Figure 4a, the red triangle and red dots represent the reference frame and its laser data, the green triangle and green dots represent the current frame and the corresponding laser data, and the purple-red area represents the current landmark. As the robot continues to move forward, it comes to the position shown in
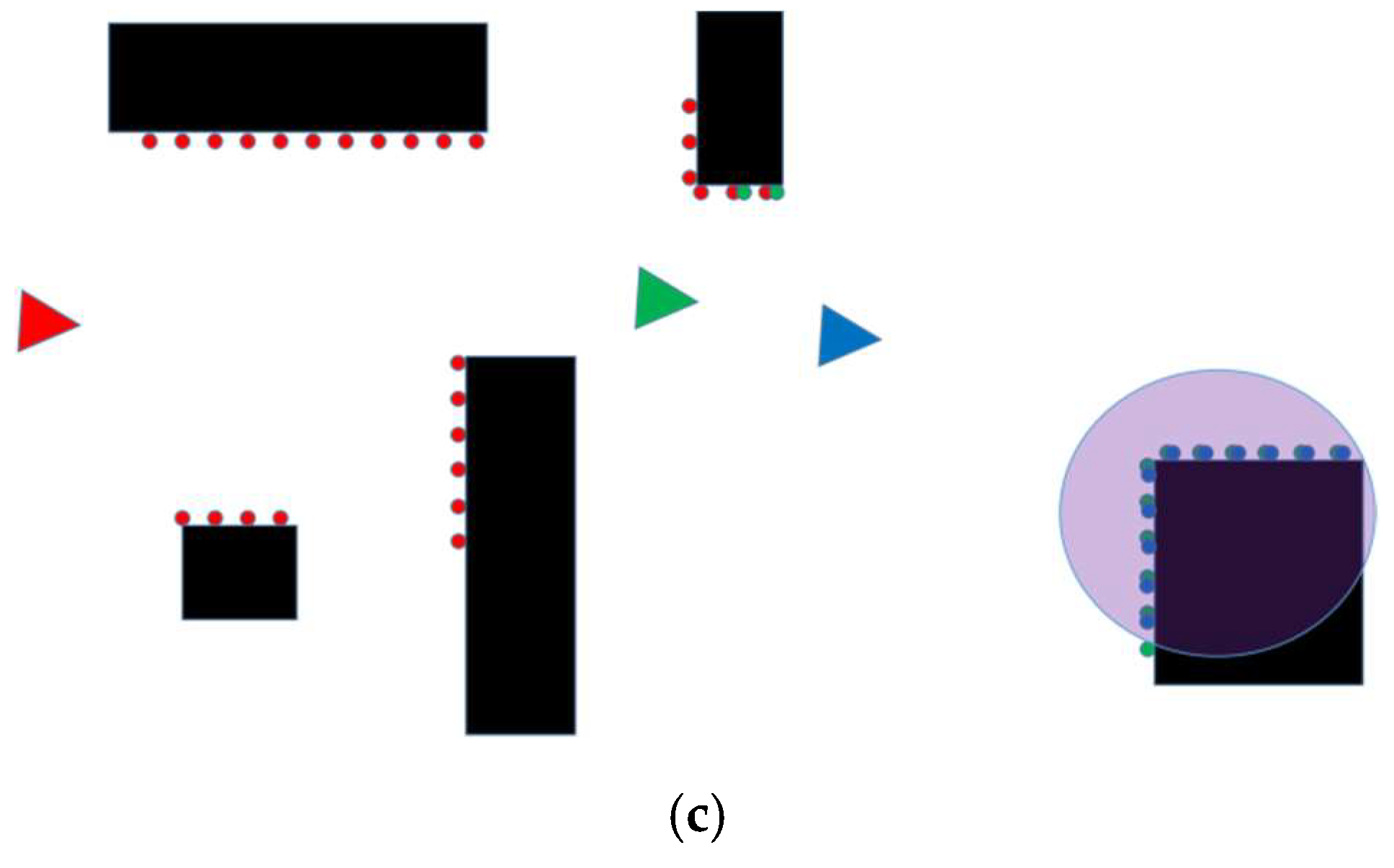
Figure 4b, at which point the current landmark is very close to the robot’s position and is about to leave the robot’s field of view. Therefore, the reference frame and landmark need to be updated at this time. The current frame is used as the reference frame, and the landmark is selected to be the new reference landmark from the current frame. The new landmark is shown in
Figure 4c, where the green triangle represents the new reference frame, the blue triangle represents the current frame, and the purple-red area represents the new landmark.
6. Experiments
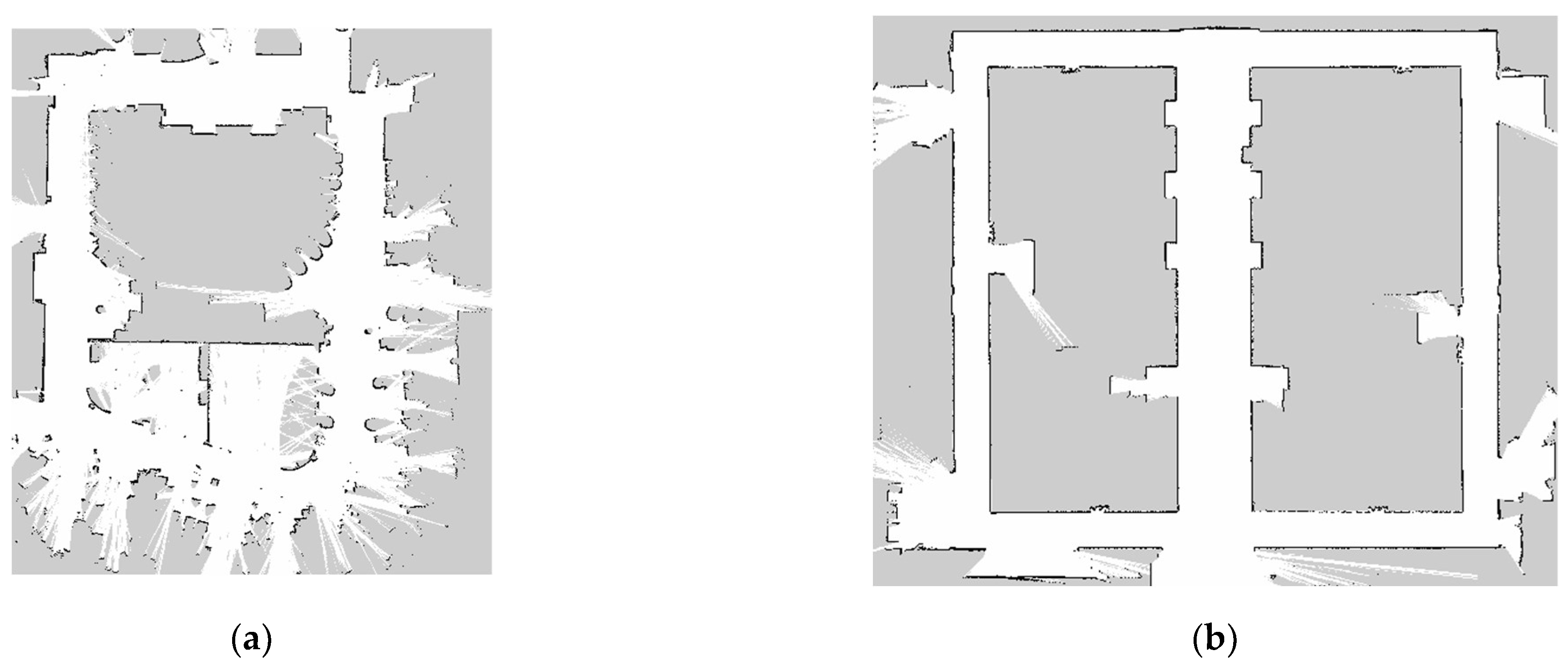
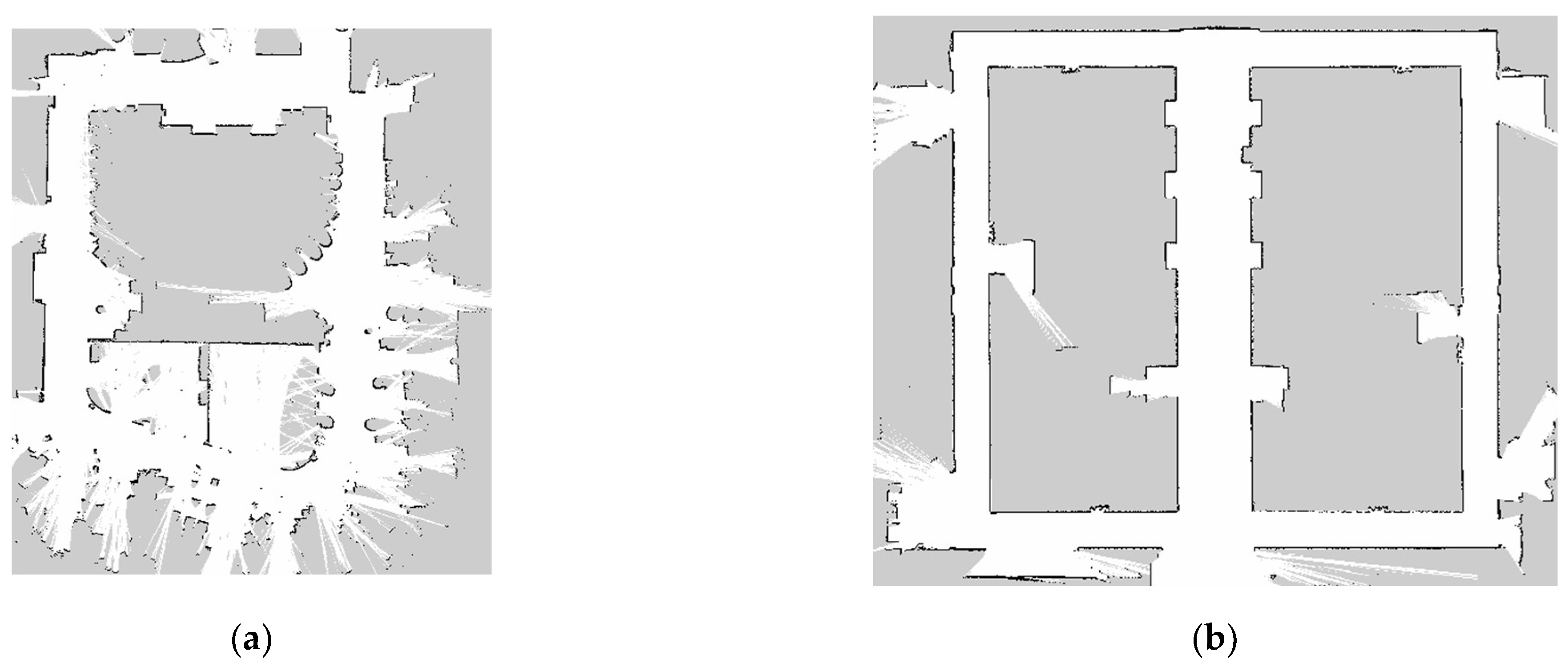
In order to verify the effectiveness of the ASM algorithm, experiments were conducted in four typical indoor scenarios, including offices, office buildings, libraries, and shopping malls. Cartographer [
31] software was used to build 2D maps of the four test environments and are shown in
Figure 5.
All four of the environments shown in
Figure 5 have a back-shaped structure. The robot starts from the origin and makes a circle around the environment and then returns to the vicinity of its origin. These types of environments are very suitable for comparing accuracy with end-to-end error metrics.
In order to compare the presented method with existing methods, four representative methods: ICP [
3], PL-ICP [
4], iCSM [
20], and IMLS-ICP [
9] were selected. The ICP is implemented in the Point Cloud Library (PCL) [
32], the PL-ICP method uses the author’s own open-source code, the iCSM method uses the implementation in the cartographer [
31] software with covariance matrix degradation analysis, and the IMLS-ICP method is not open source, and therefore, a 2D version was implemented according to the methodology outlined in the paper in which it was published. The test platform used in this paper is shown in
Figure 6.
The test platform shown in
Figure 6 is a differentially driven wheeled robot and is a prototype of the delivery robot created by Yuefan Innovation. The robot is equipped with a wheeled odometer and a low-cost 2D TOF lidar sensor. The update frequency of the wheel odometer is 100 Hz, the update frequency of the lidar data is 10 Hz, and the field of view is 250 degrees. The wheel odometer pose is used as the initial pose, and the scan matching algorithm is further optimized based on the initial pose. All programs run on an Rockchip ARM Core RK3399 process at 1.5 Ghz with 2 GB of memory.
Since it is impossible to obtain the true value of the robot’s trajectory in these four datasets, the end-to-end error was used to compare the accuracy. When the robot starts from the origin position, moves around the environment, and then returns to the origin position, the spatial displacement of the same object in the environment is selected as the cumulative error of the frame-to-frame matching algorithm.
To ensure that the experimental results are not affected by different batches of experimental data. Before the start of the experiment, the robot was controlled to move in the four environments, and the data of the sensors carried by the robot were collected to form four datasets. All experiments are carried out on these datasets.
6.1. Accuracy Test
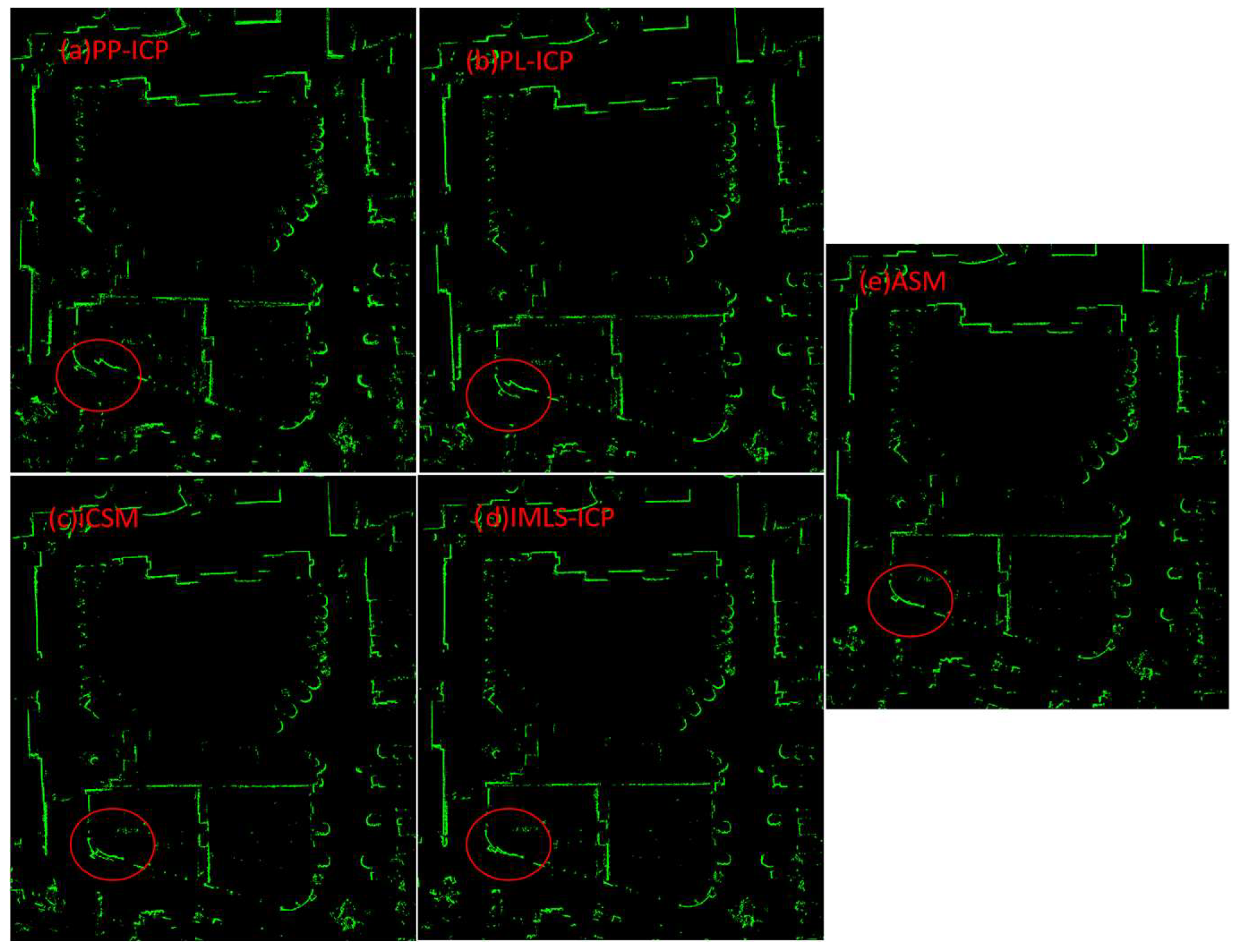
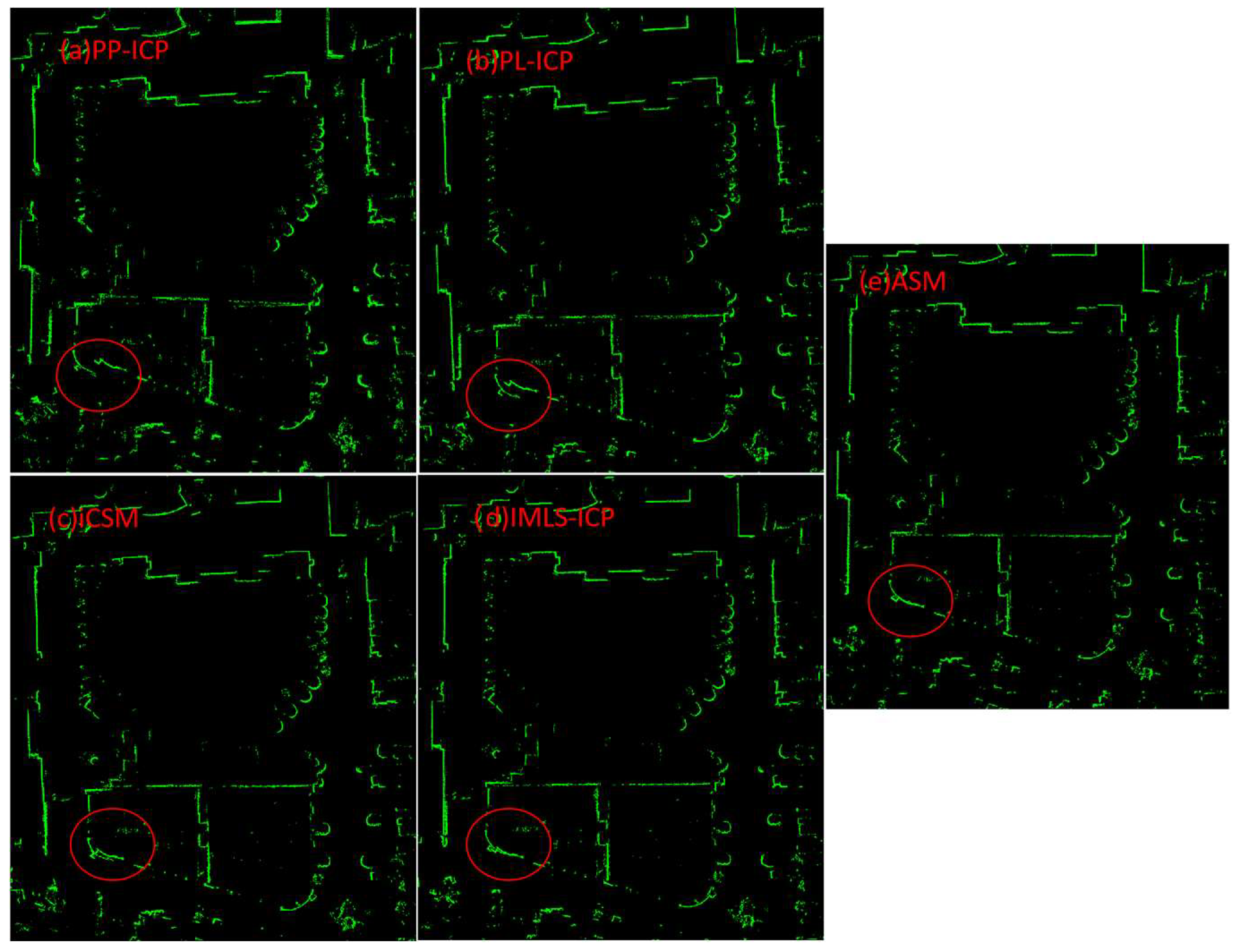
In order to evaluate the matching accuracy of the ASM algorithm and to compare the end-to-end error of different matching algorithms, the experiment was executed in four environments. The office maps constructed by the five matching algorithms are shown in
Figure 7. The inconsistencies created by the matching algorithms are highlighted by the red circle. The green points represent lidar points. It can be seen in
Figure 7 that the inconsistencies caused by the ASM algorithm are almost invisible. Additionally, the PP-ICP algorithm has the largest cumulative error, PL-ICP has the second-largest cumulative error, iCSM has the third-largest cumulative error, and IMLS-ICP has the fourth-largest cumulative error. The ASM algorithm has the smallest cumulative error. Additionally, the map built by the ASM algorithm is mostly consistent, which means that the cumulative error of the ASM algorithm on this data set is very small and outperforms other methods. The IMLS-ICP’s cumulative error is slightly larger than ASM’s cumulative error. The reason for this is that the test environment is relatively small, allowing the IMLS-ICP to obtain better results.
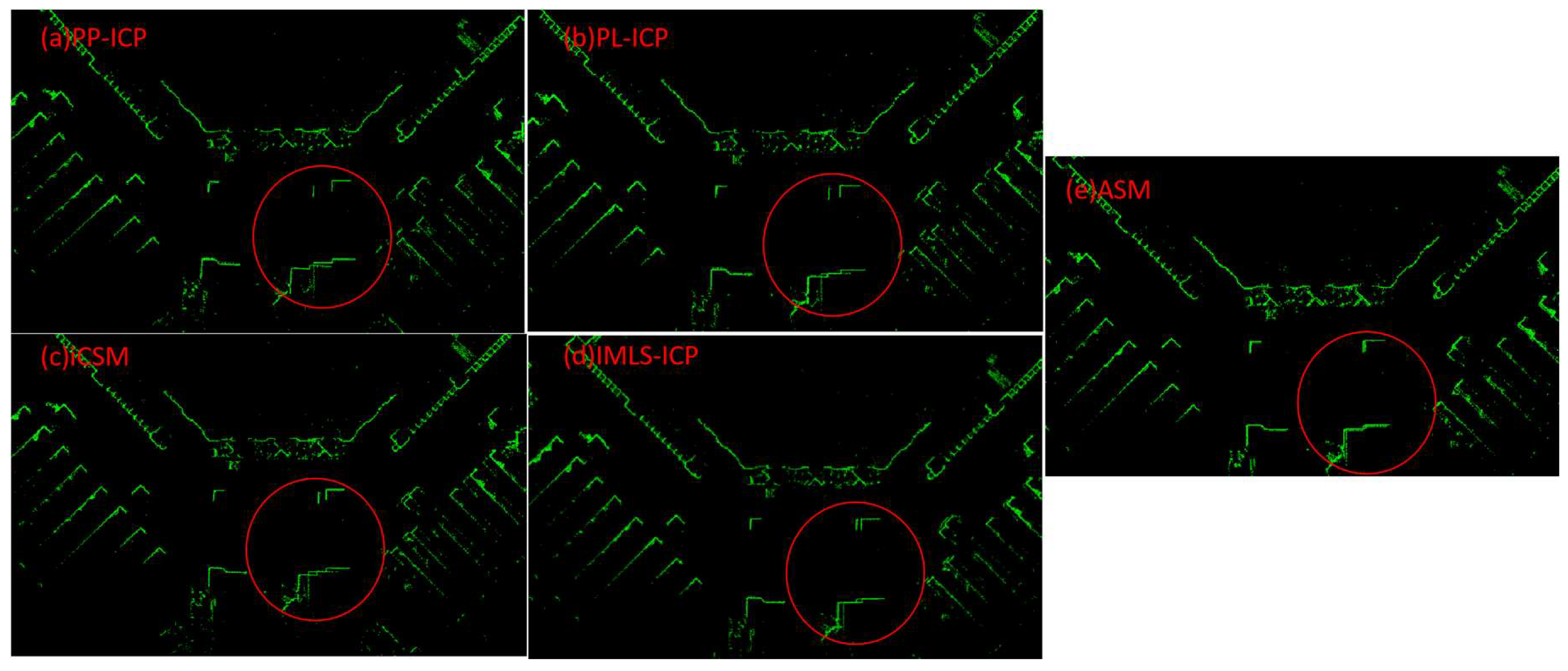
In addition to the office environment, we also tested the frame-to-frame scan matching methods in the library environment. The robot was still allowed to start from one point, move around the environment, and return to the same point. The robot built the map of the environment during the test based on the poses obtained by the scan matching algorithm. The maps of the library environment constructed by the five algorithms are shown in
Figure 8. To display the differences more clearly, Only the inconsistencies in the library maps are shown. The red circle represents the inconsistencies in the maps caused by the cumulative error of the scan matching algorithm. It is clear that PP-ICP had the largest cumulative error followed by the PL-ICP algorithm, the CSM algorithm, and the IMLS-ICP algorithm. The ASM algorithm had the smallest cumulative error. The inconsistencies in the maps of the library environment built by the ASM algorithm are clearly greater than those in the office environment, as the robot had to travel over a much larger distance in the library. The ASM algorithm achieved similar results in the library environment as it did in the office environment, and its scan matching accuracy greatly outperforms that of the other four algorithms.
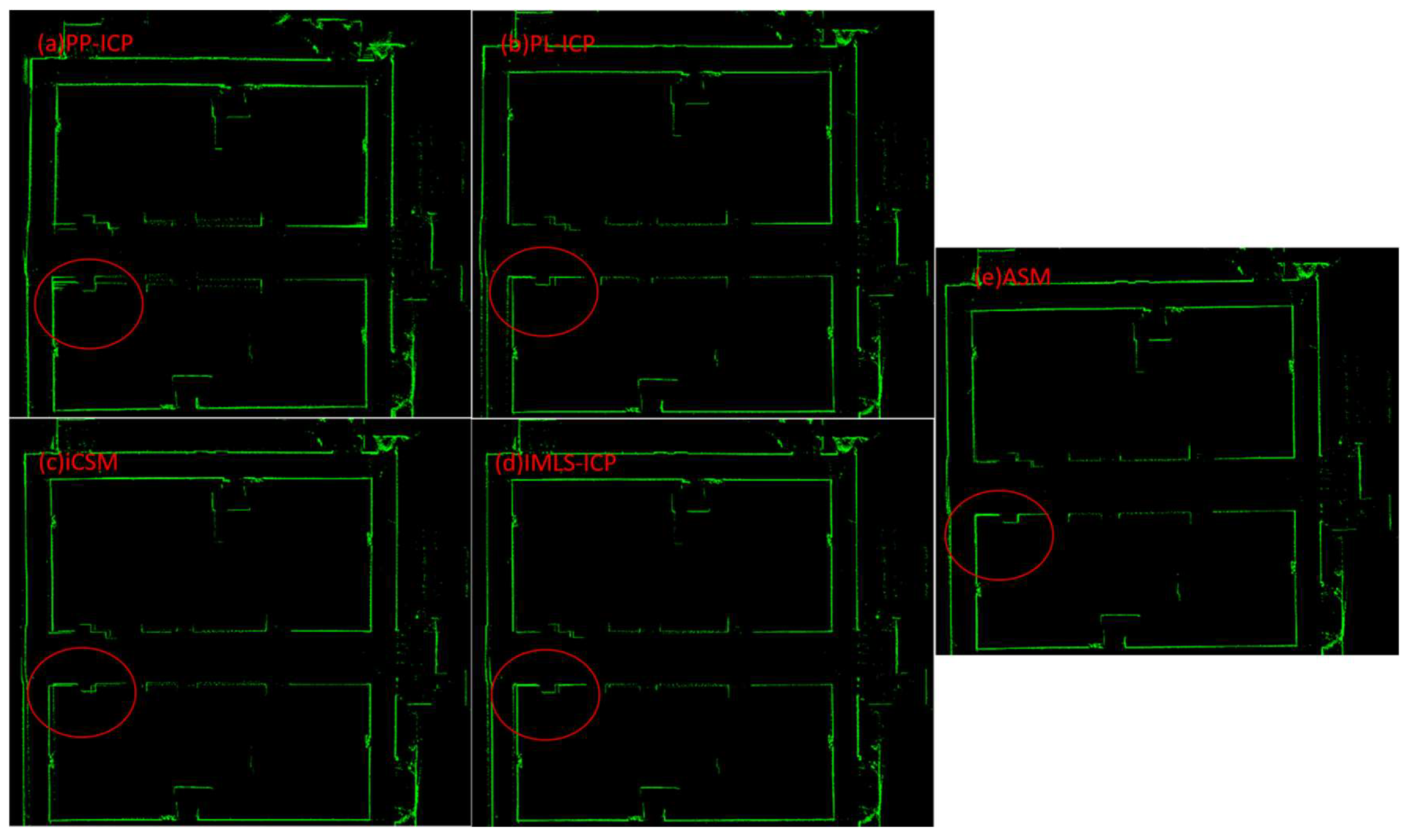
In addition, we also tested the inter-frame matching in the office building environment. The maps constructed by the five algorithms are shown in
Figure 9. Once again, the red circle highlights the areas of inconsistency in the maps. Unlike the test results in the office and library environments, the PL-ICP algorithm, CSM algorithm, and IMLS-ICP algorithm show similar cumulative error rates. Because the office building environment is more structured compared to the office environment and the library environment, it is filled with many linear structures, so the different algorithms were able to achieve good results in this environment. Even in such a highly structured environment, the ASM algorithm was superior to the other four algorithms. There are no distinguishable inconsistencies in the map generated by the ASM algorithm. That is to say, in an office building environment, the ASM algorithm can build a globally consistent map while only relying on the scan matching pose, and the cumulative error the scan matching algorithm is very small.
To make a more fair comparison, we needed to prevent random factors from affecting the experimental results. To achieve this, we ran the five algorithms in the four test environments one hundred times. For each scan matching algorithm, we counted the data from these 100 experiments, calculated the cumulative error of each experiment, and used the average error of the 100 experiments as the final error to evaluate the matching accuracy of each scan matching algorithm.
Table 1 shows the cumulative error statistics of each scan matching algorithm in the different environments.
It can be seen from
Table 1 that the ASM algorithm significantly outperforms the other four frame-to-frame matching algorithms in the four experimental environments. The reason for this is that the ASM method introduces an attention mechanism, so it is only possible for errors to accumulate when the attention area is switched. However, the frequency at which the attention area switches is very low. The robot only switches the attention area when the robot moves several tens of meters, so the cumulative error of the ASM algorithm is very small. The error of the other algorithms accumulate frame by frame, so the accumulated error will be larger. The superiority of the ASM algorithm is more prominent in the library and shopping mall environments. The reason for this is that the ASM algorithm can select a landmark from the reference frame that is far enough away from the origin of the reference frame in a large-scale environment. In large-scale environments, the longer lifetime of the reference landmarks results in the ASM algorithm having a longer drift-free movement distance. That is to say, the attention regions switch less frequently, and the error accumulation of the matching algorithm is smaller.
6.2. Efficiency Test
In addition to accuracy, computational efficiency is also very important for evaluating the scan matching algorithm. Similar to the accuracy test, the scan matching algorithm was repeatedly run on each dataset 100 times, and the average computation time required per each algorithm was used as the final evaluation standard. The statistical results are shown in
Table 2.
It can be seen from
Table 2 that the time spent by each algorithm in different environments is similar, and this is because that the algorithm matching time is only related to the point cloud data and has nothing to do with the size of the environment. Although the office and office building environments are small in size, the number of point clouds in each frame of the laser data is similar, so the final matching efficiency is also similar. The most time-consuming algorithm is the IMLS-ICP algorithm because it needs to build a KD tree to find the nearest neighbors, which is time-consuming. The time spent by the PP-ICP and PL-ICP algorithms is basically the same, whereas the time spent by the ASM algorithm lower than that of the other algorithms. This is because the ASM algorithm only uses landmarks for matching tasks, and in most cases, the number of points in a landmark is less than 1/10 of the total number of points, so the matching speed can be greatly improved.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}