
Neural Embeddings for the Elicitation of Jurisprudence Principles: The Case of Arabic Legal Texts


Abstract
:1. Introduction
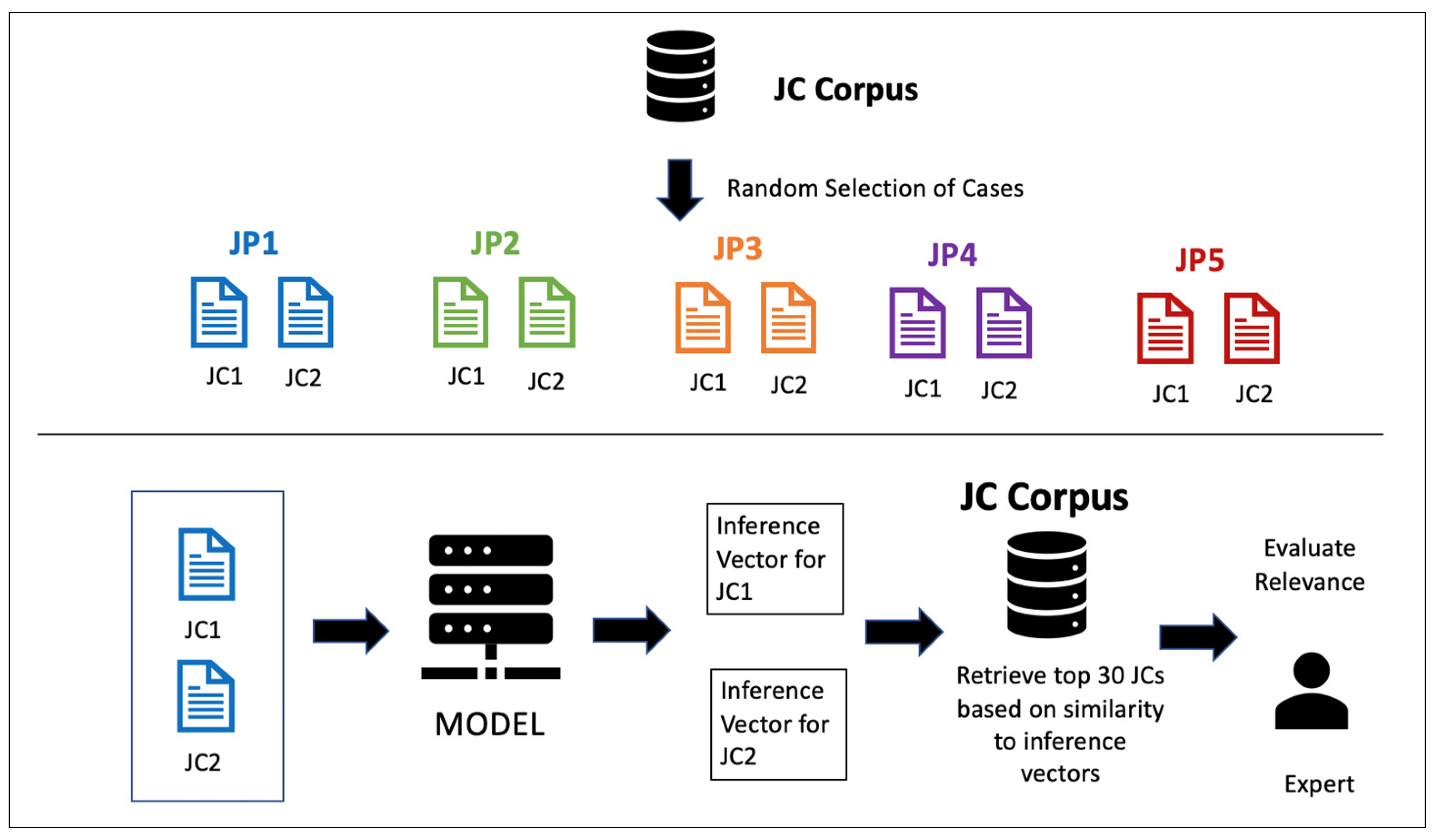
- JP 1: Matters are determined according to intentions;
- JP 2: Certainty is not overruled by doubt;
- JP 3: Hardship begets facility;
- JP 4: Harm must be eliminated;
- JP 5: Custom is a basis for judgment.
2. Neural Embeddings
3. Related Work
4. Methodology
- Produce the ideal DCG at position p (iDCGp) to compare the performance on a list sorted by relevance. For our task, the relevance score ranges from 0 to 3:
- ○
- Legal topic match = No, JP Match = No → Score = 0
- ○
- Legal topic match = Yes, JP Match = No → Score = 1
- ○
- Legal topic match = No, JP Match = Yes → Score = 2
- ○
- Legal topic match = Yes, JP Match = Yes → Score = 3
- Compute the normalized version of DCG, with the results between 0 and 1, using this formula:
4.1. Dataset
4.2. Preprocessing
4.3. Experiments
4.3.1. Experiment 1: Using a Supplementary JP Corpus
4.3.2. Experiment 2: Using Paragraph Vector Models
4.3.3. Experiment 3: Using Paragraph-Vector with Negative Sampling
4.3.4. Experiment 4: Using Paragraph Vectors with Task-Oriented Word Embedding (ToWE)
5. Results
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Legal Maxims of Islamic Jurisprudence; Mishkah: Los Angeles, CA, USA, 2014. Available online: https://www.muslim-library.com/english/legal-maxims-of-islamic-jurisprudence/ (accessed on 26 October 2019).
- Kamali, M.H. Shari’ah Law, An Introduction; Oneworld: Oxford, UK, 2012. Available online: https://oneworld-publications.com/shari-ah-law-pb.html (accessed on 26 October 2019).
- Saiti, B.; Abdullah, A. The Legal Maxims of Islamic Law (Excluding Five Leading Legal Maxims) and Their Applications in Islamic Finance. J. King Abdulaziz Univ.-Islamic Econ. 2016, 29, 139–151. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 2, pp. 3111–3119. Available online: http://dl.acm.org/citation.cfm?id=2999792.2999959 (accessed on 13 December 2018).
- Mitra, B.; Craswell, N. An Introduction to Neural Information Retrieval; Foundations and Trends® in Information Retrieval: Boston, MA, USA, 2017; Available online: https://www.microsoft.com/en-us/research/publication/introduction-neural-information-retrieval/ (accessed on 17 March 2018).
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the 31st International Conference on International Conference on Machine Learning, Beijing, China, 21–26 June 2014; Volume 32, pp. II-1188–II-1196. Available online: http://dl.acm.org/citation.cfm?id=3044805.3045025 (accessed on 16 March 2018).
- Pagliardini, M.; Gupta, P.; Jaggi, M. Unsupervised Learning of Sentence Embeddings Using Compositional n-Gram Features. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 5–6 June 2018; Volume 1, pp. 528–540. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, H.; Gao, Y.; Wei, X.; Tian, Y.; Liu, L. Task-oriented Word Embedding for Text Classification. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 2023–2032. Available online: http://aclweb.org/anthology/C18-1172 (accessed on 9 December 2018).
- Mahdaouy, A.E.; Alaoui, S.O.E.; Gaussier, É. Semantically enhanced term frequency based on word embeddings for Arabic information retrieval. In Proceedings of the 2016 4th IEEE International Colloquium on Information Science and Technology (CiSt), Tangier, Morocco, 24–26 October 2016; pp. 385–389. [Google Scholar] [CrossRef]
- Mahdaouy, A.E.; Alaoui, S.O.E.; Gaussier, E. Improving Arabic information retrieval using word embedding similarities. Int. J. Speech Technol. 2018, 21, 121–136. [Google Scholar] [CrossRef]
- Zahran, M.A.; Magooda, A.; Mahgoub, A.Y.; Raafat, H.; Rashwan, M.; Atyia, A. Word Representations in Vector Space and their Applications for Arabic. In International Conference on Intelligent Text Processing and Computational Linguistics; Springer: Berlin/Heidelberg, Germany, 2015; pp. 430–443. [Google Scholar] [CrossRef]
- Ganguly, D.; Roy, D.; Mitra, M.; Jones, G.J.F. Word Embedding Based Generalized Language Model for Information Retrieval. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 795–798. [Google Scholar] [CrossRef]
- Zuccon, G.; Koopman, B.; Bruza, P.; Azzopardi, L. Integrating and Evaluating Neural Word Embeddings in Information Retrieval. In Proceedings of the 20th Australasian Document Computing Symposium, Parramatta, Australia, 8–9 December 2015; pp. 12:1–12:8. [Google Scholar] [CrossRef] [Green Version]
- Vulić, I.; Moens, M.-F. Monolingual and Cross-Lingual Information Retrieval Models Based on (Bilingual) Word Embeddings. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 363–372. [Google Scholar] [CrossRef]
- Lee, S.; Jin, X.; Kim, W. Sentiment Classification for Unlabeled Dataset Using Doc2Vec with JST. In Proceedings of the 18th Annual International Conference on Electronic Commerce: E-Commerce in Smart Connected World, Suwon, Korea, 17–19 August 2016; pp. 28:1–28:5. [Google Scholar] [CrossRef]
- Agrawal, T.; Gupta, R.; Narayanan, S. Multimodal detection of fake social media use through a fusion of classification and pairwise ranking systems. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos Island, Greece, 28 August–2 September 2017; pp. 1045–1049. [Google Scholar] [CrossRef] [Green Version]
- Belinkov, Y.; Mohtarami, M.; Cyphers, S.; Glass, J. VectorSLU: A Continuous Word Vector Approach to Answer Selection in Community Question Answering Systems. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 282–287. Available online: http://www.aclweb.org/anthology/S15-2048 (accessed on 29 April 2018).
- Tran, Q.H.; Tran, V.; Vu, T.; Nguyen, M.; Pham, S.B. JAIST: Combining multiple features for Answer Selection in Community Question Answering. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 215–219. Available online: http://www.aclweb.org/anthology/S15-2038 (accessed on 30 April 2018).
- Douzi, S.; Amar, M.; Ouahidi, B.E.; Laanaya, H. Towards A new Spam Filter Based on PV-DM (Paragraph Vector-Distributed Memory Approach). Procedia Comput. Sci. 2017, 110, 486–491. [Google Scholar] [CrossRef]
- Berrazega, I.; Faiz, R.; Bouhafs, A.; Mourad, G. A Semantic Annotation Model for Arabic Legal Texts. In Proceedings of the 9th Hellenic Conference on Artificial Intelligence, Thessaloniki, Greece, 18–20 May 2016. [Google Scholar] [CrossRef]
- Al-Bukhitan, S.; Helmy, T.; Al-Mulhem, M. Semantic Annotation Tool for Annotating Arabic Web Documents. Procedia Comput. Sci. 2014, 32, 429–436. [Google Scholar] [CrossRef] [Green Version]
- Mezghanni, I.B.; Gargouri, F. Detecting hidden structures from Arabic electronic documents: Application to the legal field. In Proceedings of the 2016 IEEE 14th International Conference on Software Engineering Research, Management and Applications (SERA), Towson, MD, USA, 8–10 June 2016; pp. 75–81. [Google Scholar]
- Mezghanni, I.B.; Gargouri, F. ALES: An Arabic Legal query Expansion System. In Proceedings of the Conference on Data Science and Knowledge Engineering for Sensing Decision Support (FLINS 2018), Belfast, UK, 21–24 August 2018; pp. 568–575. [Google Scholar] [CrossRef]
- Mezghanni, I.B.; Gargouri, F. Learning of Legal Ontology Supporting the User Queries Satisfaction. In Proceedings of the 2014 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), Warsaw, Poland, 11–14 August 2014; Volume 1, pp. 414–418. [Google Scholar]
- Dhouib, K.; Gargouri, F. Legal application ontology in Arabic. In Proceedings of the Fourth International Conference on Information and Communication Technology and Accessibility (ICTA), Hammamet, Tunisia, 24–26 October 2013; pp. 1–6. [Google Scholar]
- Belhoucine, K.; Mourchid, M.; Mouloudi, A.; Mbarki, S. A Middle-out Approach for Building a Legal domain ontology in Arabic. In Proceedings of the 2020 6th IEEE Congress on Information Science and Technology (CiSt), Agadir-Essaouira, Morocco, 5–12 June 2021; pp. 290–295. [Google Scholar]
- Belhoucine, K.; Mourchid, M.; Mbarki, S.; Mouloudi, A. A Bottom-Up Approach for Moroccan Legal Ontology Learning from Arabic Texts. In International Conference on Automatic Processing of Natural-Language Electronic Texts with NooJ; Springer: Cham, Germany, 2020; pp. 230–242. [Google Scholar]
- Mezghanni, I.B.; Gargouri, F. Towards an Arabic legal ontology based on documents properties extraction. In Proceedings of the 2015 IEEE/ACS 12th International Conference of Computer Systems and Applications (AICCSA), Marrakech, Morocco, 17–20 November 2015; pp. 1–8. [Google Scholar]
- Ikram, A.Y.; Chakir, L. Arabic Text Classification in the Legal Domain. In Proceedings of the 2019 Third International Conference on Intelligent Computing in Data Sciences (ICDS), Marrakech, Morocco, 28–30 October 2019; pp. 1–6. [Google Scholar]
- Jasim, K.M.; Sadiq, A.T.; Abdullah, H.S. A Framework for Detection and Identification the Components of Arguments in Arabic Legal Texts. In Proceedings of the 2019 First International Conference of Computer and Applied Sciences (CAS), Baghdad, Iraq, 18–19 December 2019; pp. 67–72. [Google Scholar]
- Järvelin, K.; Kekäläinen, J. Cumulated Gain-based Evaluation of IR Techniques. ACM Trans. Inf. Syst. 2002, 20, 422–446. [Google Scholar] [CrossRef]
- المغني لابن قدامة • الموقع الرسمي للمكتبة الشاملة. Available online: http://shamela.ws/index.php/book/8463 (accessed on 22 December 2018).
- PyArabic. PyPI. Available online: https://pypi.org/project/PyArabic/ (accessed on 6 October 2018).
- Rehurek, R. Gensim: Python Framework for Fast Vector Space Modelling. Available online: http://radimrehurek.com/gensim (accessed on 12 December 2018).
- الممتع في القواعد الفقهية. Available online: https://www.goodreads.com/work/best_book/16932078 (accessed on 8 October 2018).
- الوجيز في إيضاح قواعد الفقه الكلية - المكتبة الوقفية للكتب المصورة. Available online: http://waqfeya.com/book.php?bid=9501 (accessed on 8 October 2018).
- Lau, J.H.; Baldwin, T. An Empirical Evaluation of doc2vec with Practical Insights into Document Embedding Generation. In Proceedings of the 1st Workshop on Representation Learning for NLP, Berlin, Germany, 11 August 2016; pp. 78–86. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Values for Each Model | |||
|---|---|---|---|
| Hyperparameter Name and Description | PV-DBOW | PV-DM Average | PV-DM Concatenate |
| dm: If the value is 1 then distributed memory (PV-DM) is used; if the value is 0 then distributed bag-of-words (PV-DBOW) is used | 0 | 1 | 1 |
| vector_size: Dimensionality of the feature vectors | 100 | 100 | 100 |
| Negative | 5 | 5 | 5 |
| min_count: Ignores all words with a total frequency < 5 | 2 | 2 | 2 |
| epochs: Number of iterations (epochs) over the corpus | 20 | 20 | 20 |
| alpha: The initial learning rate | - | 0.05 | - |
| window: The maximum distance between the current and predicted word within a sentence | 5 | 10 | 5 |
| Sample | 0 | 0 | 0 |
| Hyperparameter Name and Description | Setting |
|---|---|
| dm: Distributed bag-of-words (PV-DBOW) is employed | 0 |
| vector_size: Dimensionality of the feature vectors | 300 |
| Negative: “Noise words” should be drawn | 20 |
| min_count: Ignores all words with a total frequency < 5 | 5 |
| epochs: Number of iterations (epochs) over the corpus | 30 |
| dbow_words: Trains word vectors simultaneously with DBOW document vector training | 1 |
| window: The word context | 3 |
| sample: The threshold for configuring which higher-frequency words are randomly downsampled | 0 |
| hs: Negative sampling will be used | 0 |
| Principle | Percent of Relevant Results |
|---|---|
| JP1: Matters are determined according to intentions | 80% |
| JP2: Certainty is not overruled by doubt | 80% |
| JP3: Hardship begets facility | 90% |
| JP4: Harm must be eliminated | 60% |
| JP5: Custom is a basis for judgment | 90% |
| Jurisprudence Principle | NDCG |
|---|---|
| JP 1: Matters are determined according to intentions | 11.74/12.52 = 0.9 |
| JP 2: Certainty is not overruled by doubt | 11.597/12.72 = 0.9 |
| JP 3: Hardship begets facility | 12.16/12.16 = 1.0 |
| JP 4: Harm must be eliminated | 10.86/12.07 = 0.8 |
| JP 5: Custom is a basis for judgment | 13.22/13.46 = 0.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alrumayyan, N.; Al-Yahya, M. Neural Embeddings for the Elicitation of Jurisprudence Principles: The Case of Arabic Legal Texts. Appl. Sci. 2022, 12, 4188. https://doi.org/10.3390/app12094188
Alrumayyan N, Al-Yahya M. Neural Embeddings for the Elicitation of Jurisprudence Principles: The Case of Arabic Legal Texts. Applied Sciences. 2022; 12(9):4188. https://doi.org/10.3390/app12094188
Chicago/Turabian StyleAlrumayyan, Nafla, and Maha Al-Yahya. 2022. "Neural Embeddings for the Elicitation of Jurisprudence Principles: The Case of Arabic Legal Texts" Applied Sciences 12, no. 9: 4188. https://doi.org/10.3390/app12094188
APA StyleAlrumayyan, N., & Al-Yahya, M. (2022). Neural Embeddings for the Elicitation of Jurisprudence Principles: The Case of Arabic Legal Texts. Applied Sciences, 12(9), 4188. https://doi.org/10.3390/app12094188