The performance validation of the RFODL-MGEC model was tested using three benchmark datasets [
21], namely, prostate cancer, colon tumor, and ovarian cancer datasets. The details related to the datasets are provided in
Table 1. The proposed model selected a set of 6145, 984, and 8424 features for prostate, colon, and ovarian cancer datasets, respectively.
4.1. Resulting Analysis of RFODL-MGEC Technique on Prostate Cancer Dataset
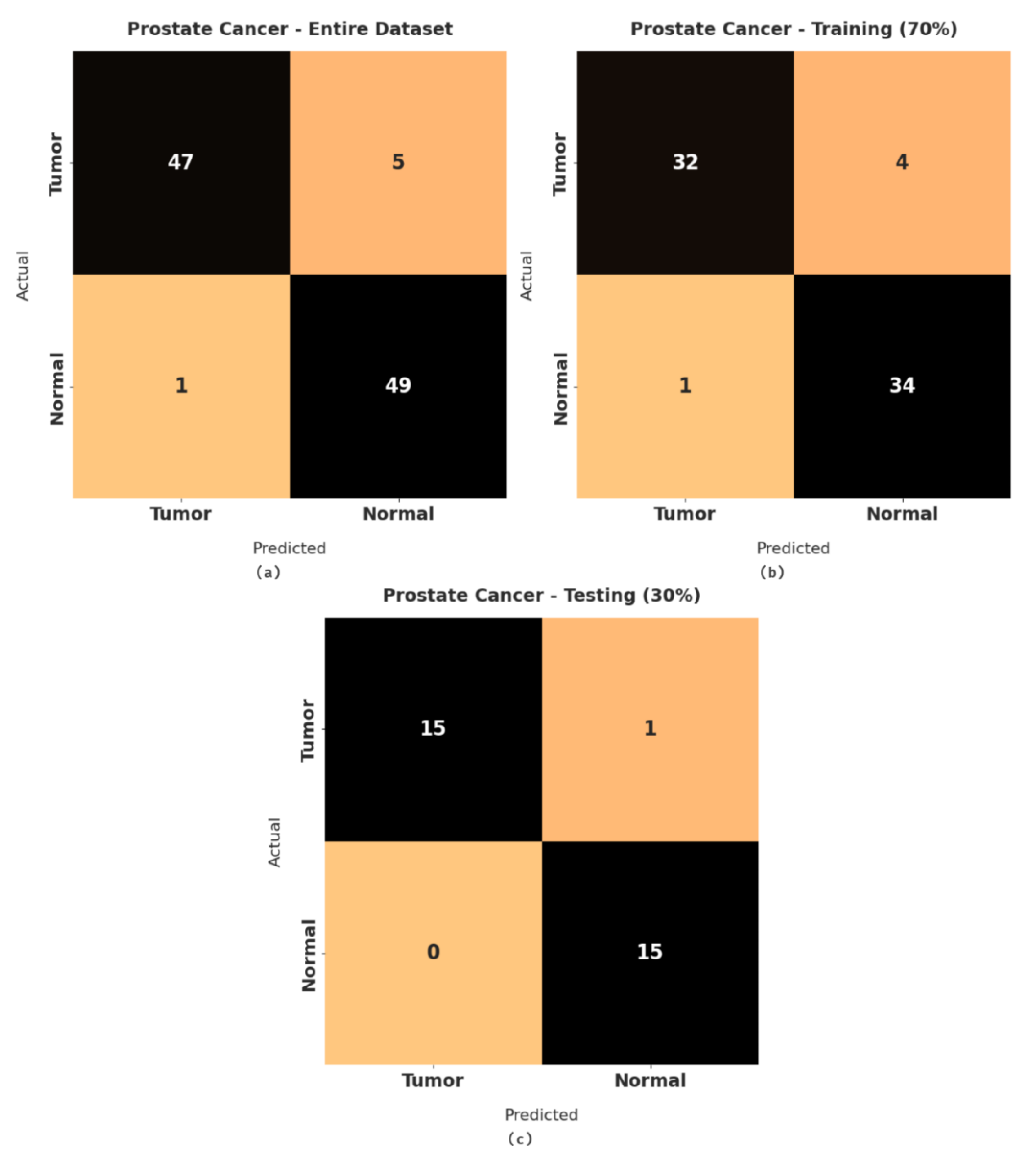
Figure 3 illustrates a set of confusion matrices generated by the RFODL-MGEC model on the test prostate cancer dataset. For the entire dataset, the RFODL-MGEC model categorized 47 images as tumor and 49 images as normal. Similarly, for 70% of the training dataset, the RFODL-MGEC model categorized 32 images as tumor and 34 images as normal. In addition, for 30% of the testing dataset, the RFODL-MGEC model categorized 15 images as tumor and 15 images as normal.
Table 2 shows a brief classification performance report for the RFODL-MGEC model on the prostate cancer dataset. The experimental results indicated that the RFODL-MGEC model demonstrated effective results on the test dataset. For instance, with the entire dataset, the RFODL-MGEC model obtained an average
,
,
, and
of 94.12%, 94.33%, 94.19%, and 94.12%, respectively. Moreover, with 70% of the training dataset, the RFODL-MGEC technique obtained an average
,
,
, and
of 92.96%, 93.22%, 93.02%, and 92.95%, respectively. With 30% of the testing dataset, the RFODL-MGEC system obtained an average
,
,
, and
of 96.77%, 96.88%, 96.88%, and 96.77%, respectively.
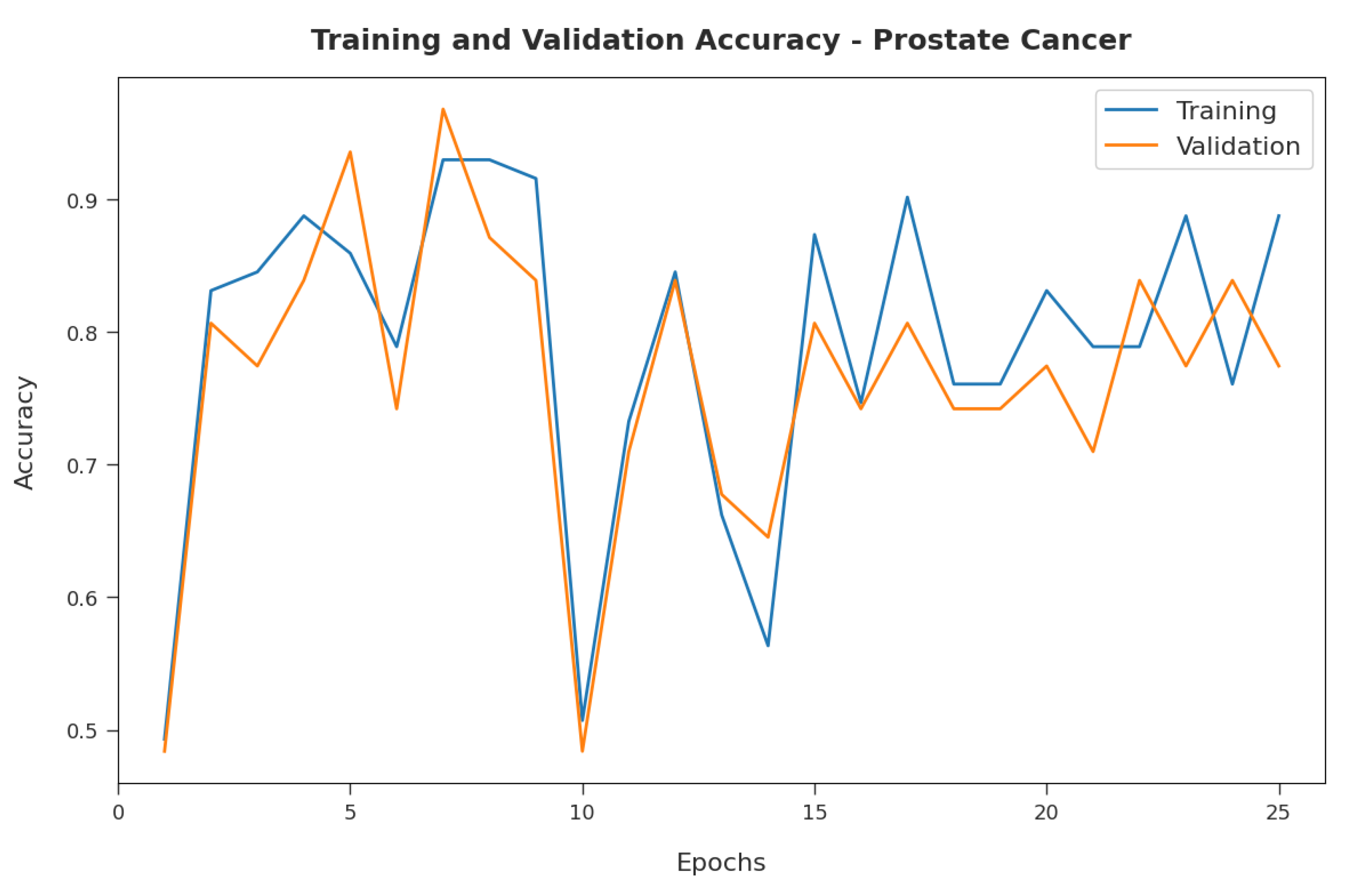
Figure 4 illustrates the training and validation accuracy inspection of the RFODL-MGEC model with the prostate cancer dataset.
Figure 4 conveys that the RFODL-MGEC model offered maximum training/validation accuracy for the classification process.
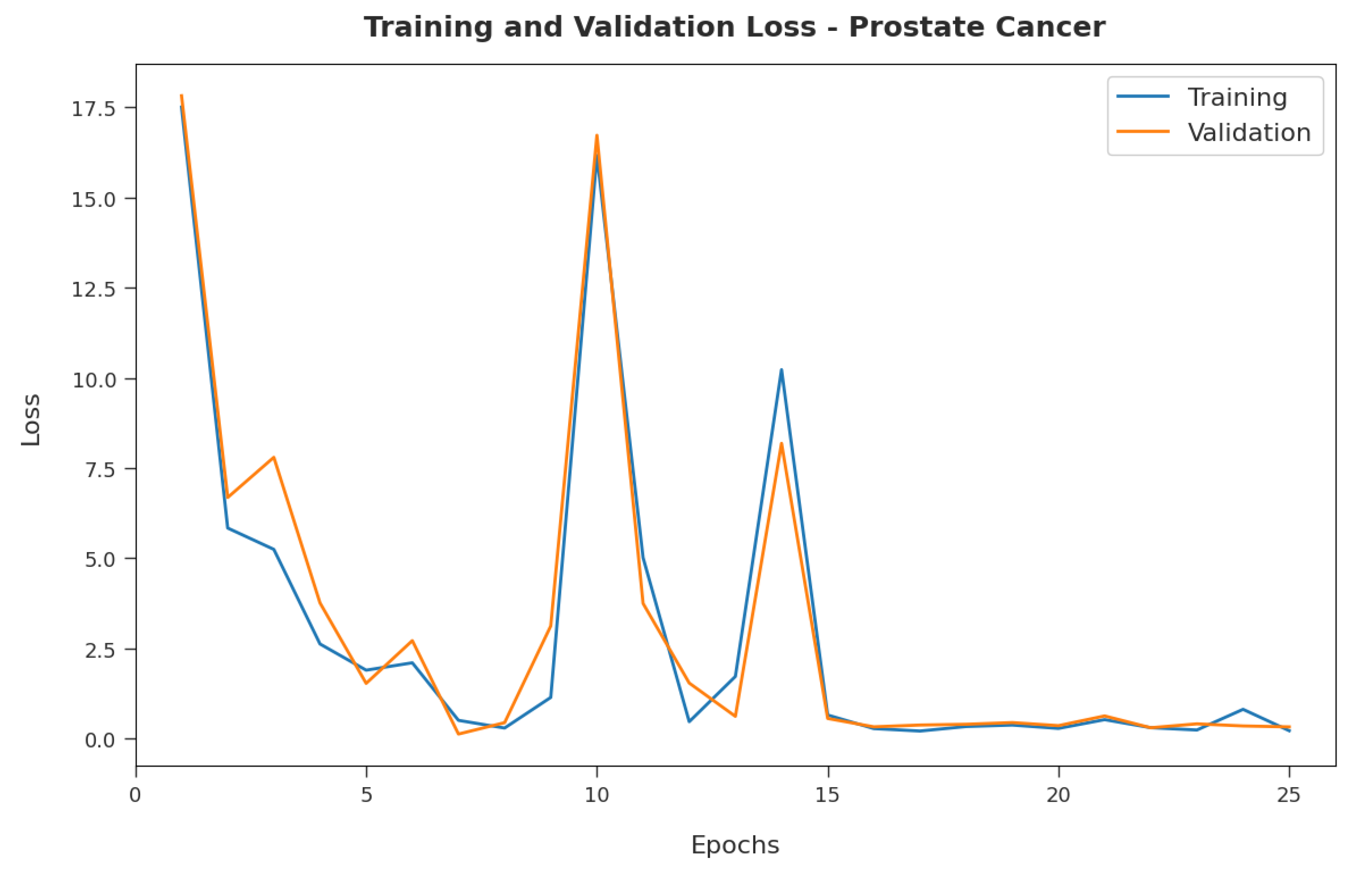
Figure 5 exemplifies the training and validation loss inspection of the RFODL-MGEC model with the prostate cancer dataset.
Figure 5 shows that the RFODL-MGEC model offered reduced training/accuracy loss for the classification process of the test data.
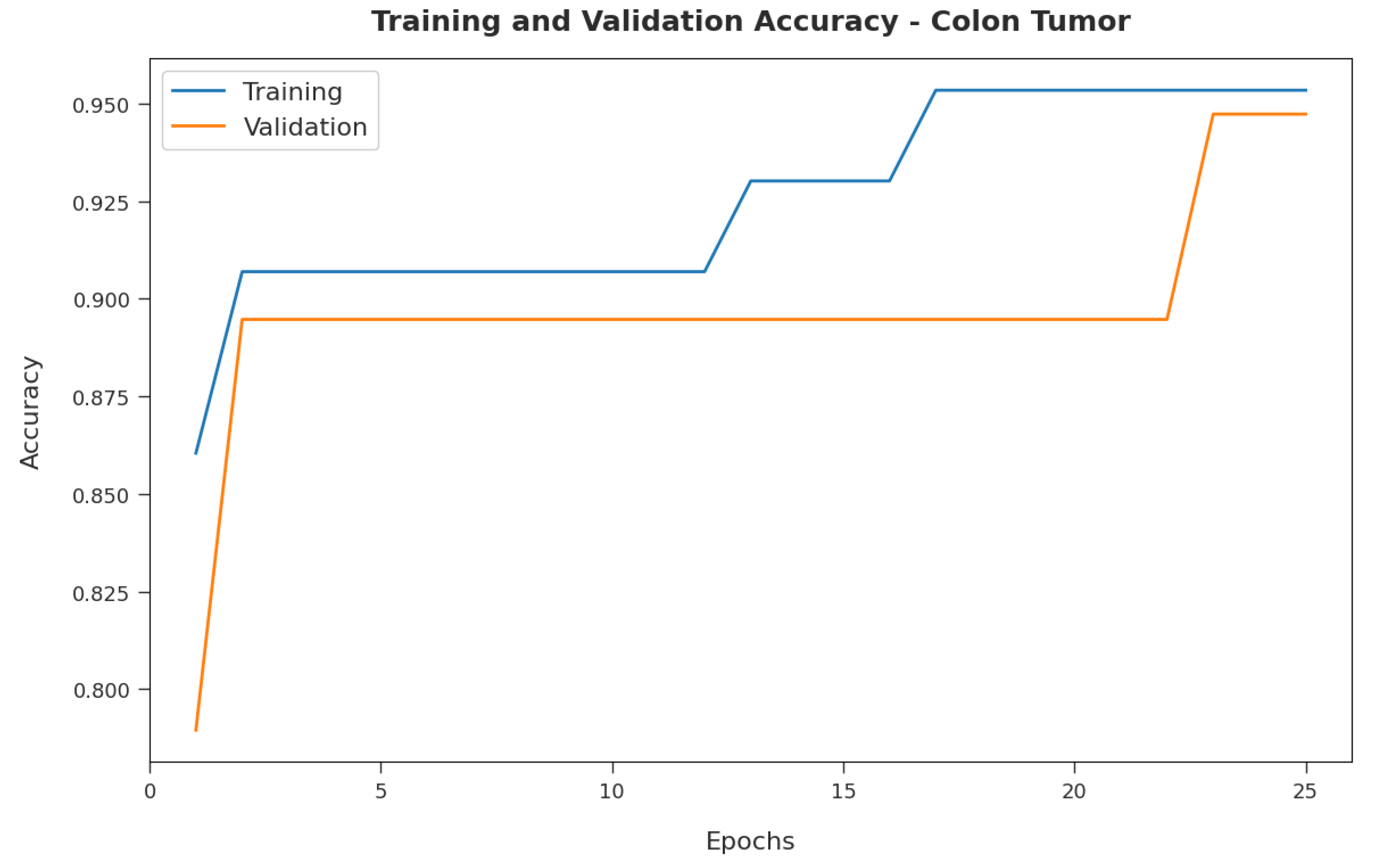
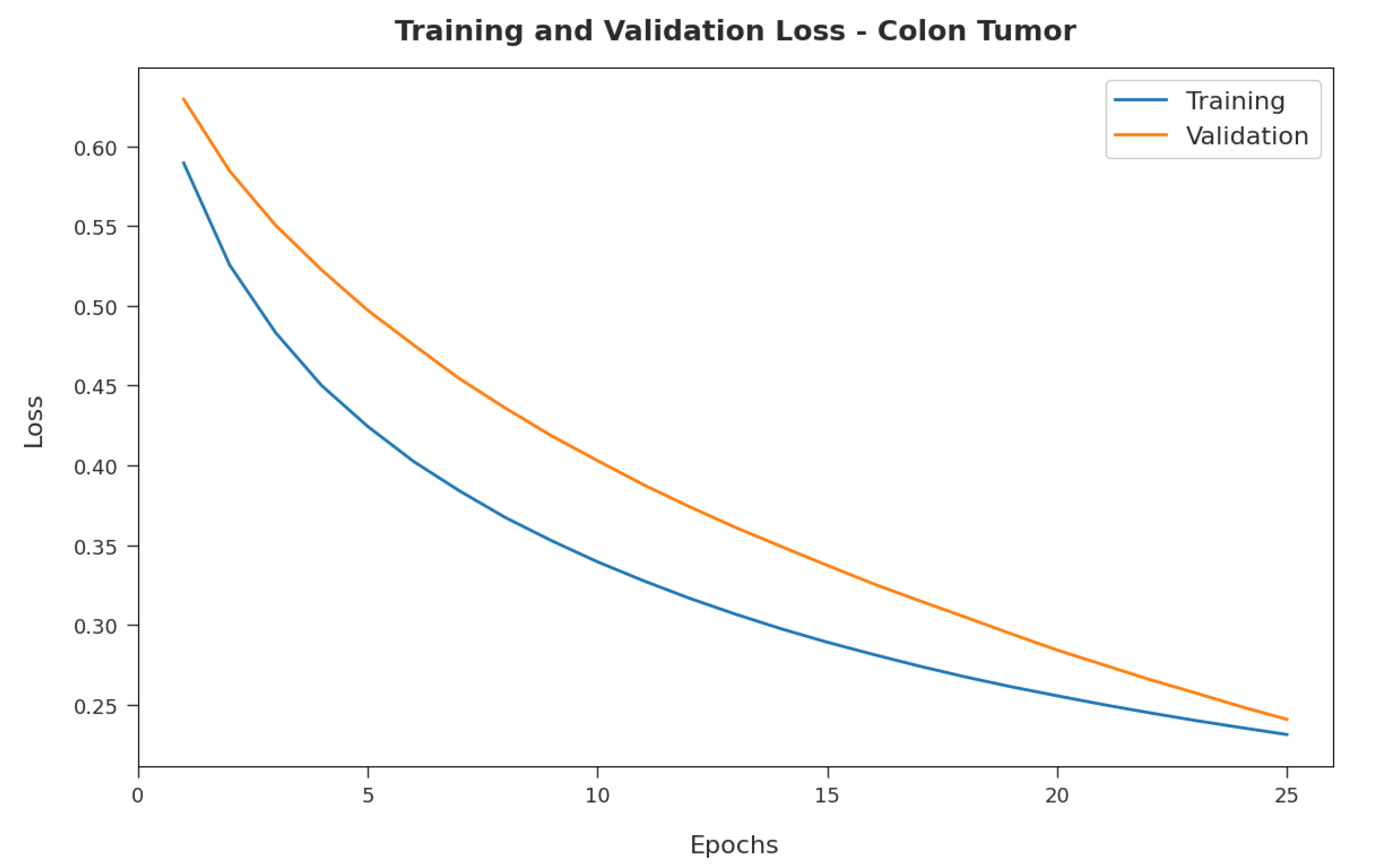
4.2. Resulting Analysis of RFODL-MGEC Technique on Colon Tumor Dataset
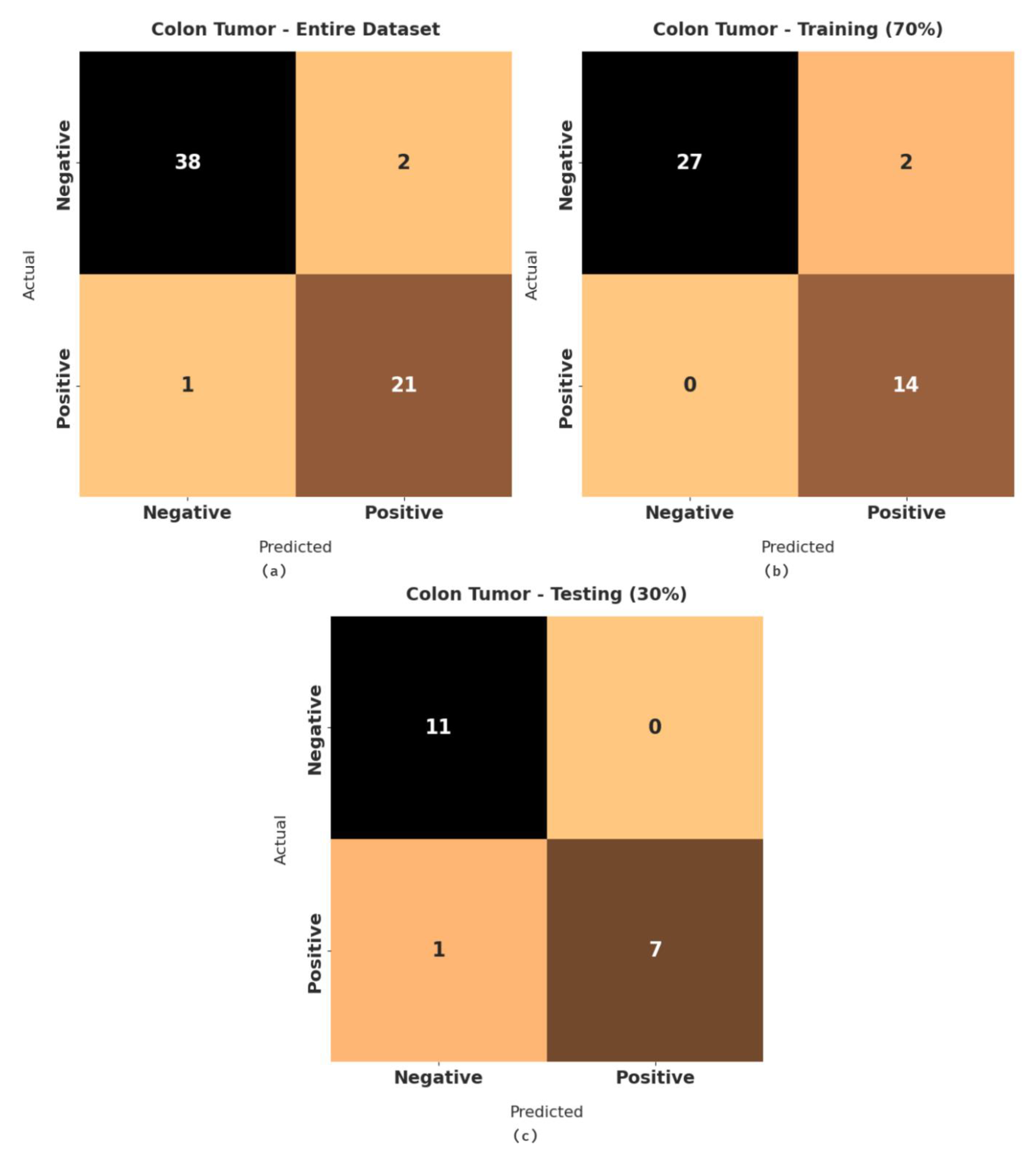
Figure 6 demonstrates a set of confusion matrices generated by the RFODL-MGEC model for the test colon tumor dataset. For the entire dataset, the RFODL-MGEC technique categorized 38 images as negative and 21 images as positive. Likewise, for 70% of the training dataset, the RFODL-MGEC approach categorized 27 images as negative and 14 images as positive. Furthermore, with 30% of the testing dataset, the RFODL-MGEC model categorized 11 images as negative and 7 images as positive.
Table 3 demonstrates a brief classification performance report on the RFODL-MGEC model with the colon tumor dataset. The experimental results indicated that the RFODL-MGEC model demonstrated effective results with the test dataset. For instance, with the entire dataset, the RFODL-MGEC model obtained an average
,
,
, and
of 95.16%, 94.37%, 95.23%, and 94.77%, respectively. With 70% of the training dataset, the RFODL-MGEC method attained an average
,
,
, and
of 95.35%, 93.75%, 96.55%, and 94.88%, respectively. Additionally, with 30% of the testing dataset, the RFODL-MGEC algorithm obtained an average
,
,
, and
of 94.74%, 95.83%, 93.75%, and 94.49%, respectively.
Figure 7 demonstrates the training and validation accuracy inspection of the RFODL-MGEC model on the colon tumor dataset. The figure conveys that the RFODL-MGEC technique offered maximal training/validation accuracy for the classification process.
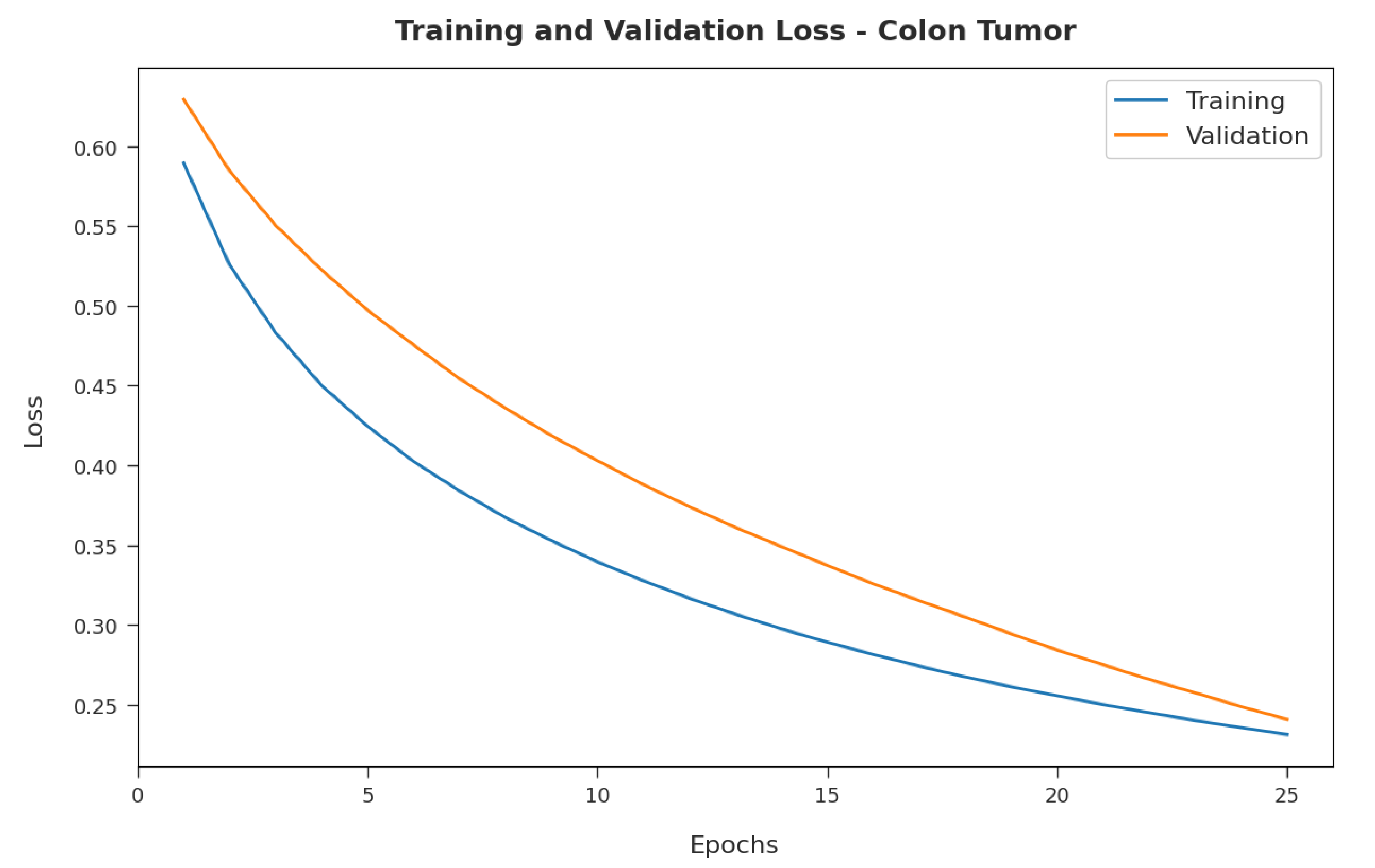
Figure 8 illustrates the training and validation loss inspection of the RFODL-MGEC model on the colon tumor dataset. The figure shows that the RFODL-MGEC approach offered lower training/accuracy loss for the classification process of the test data.
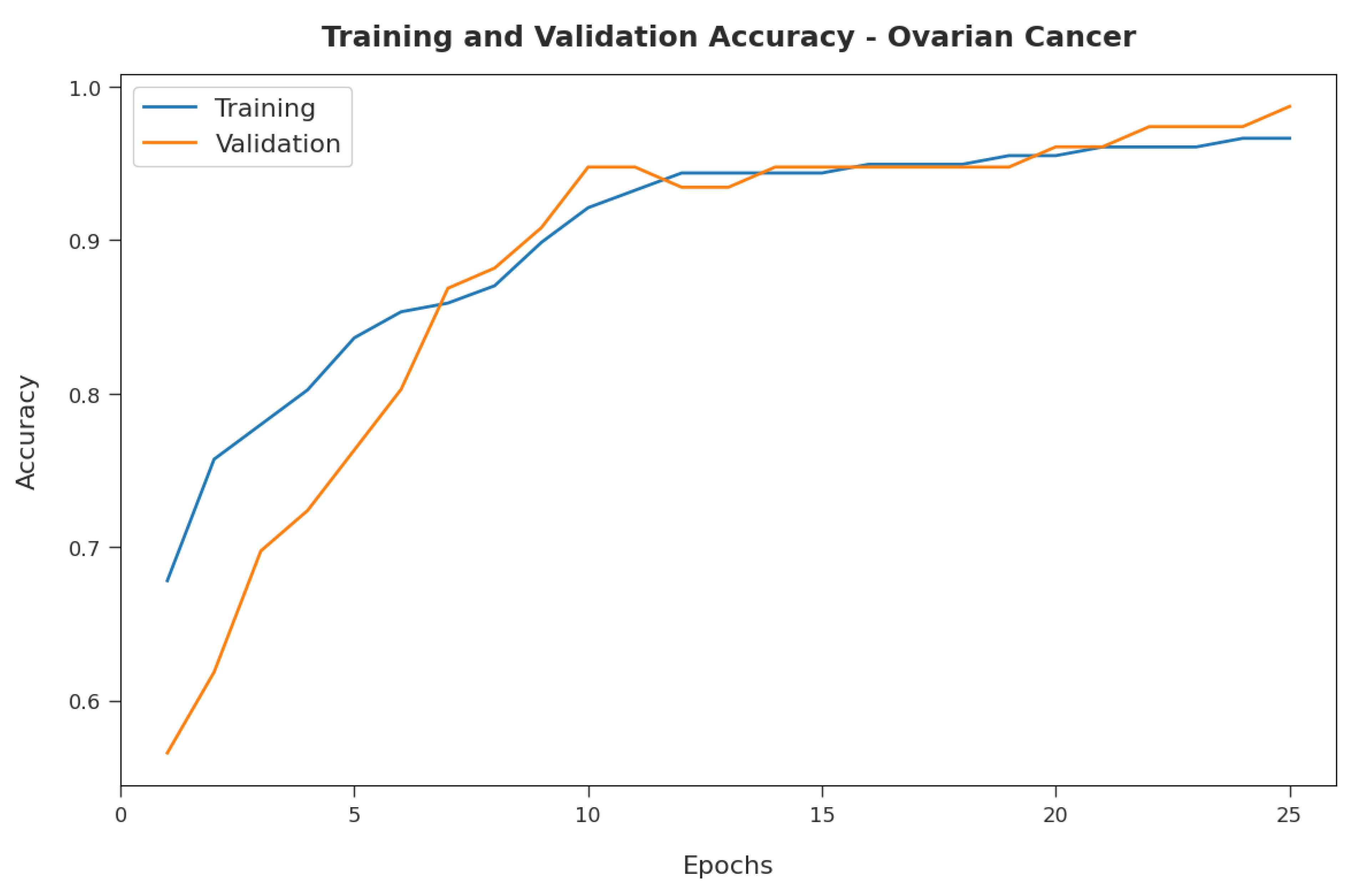
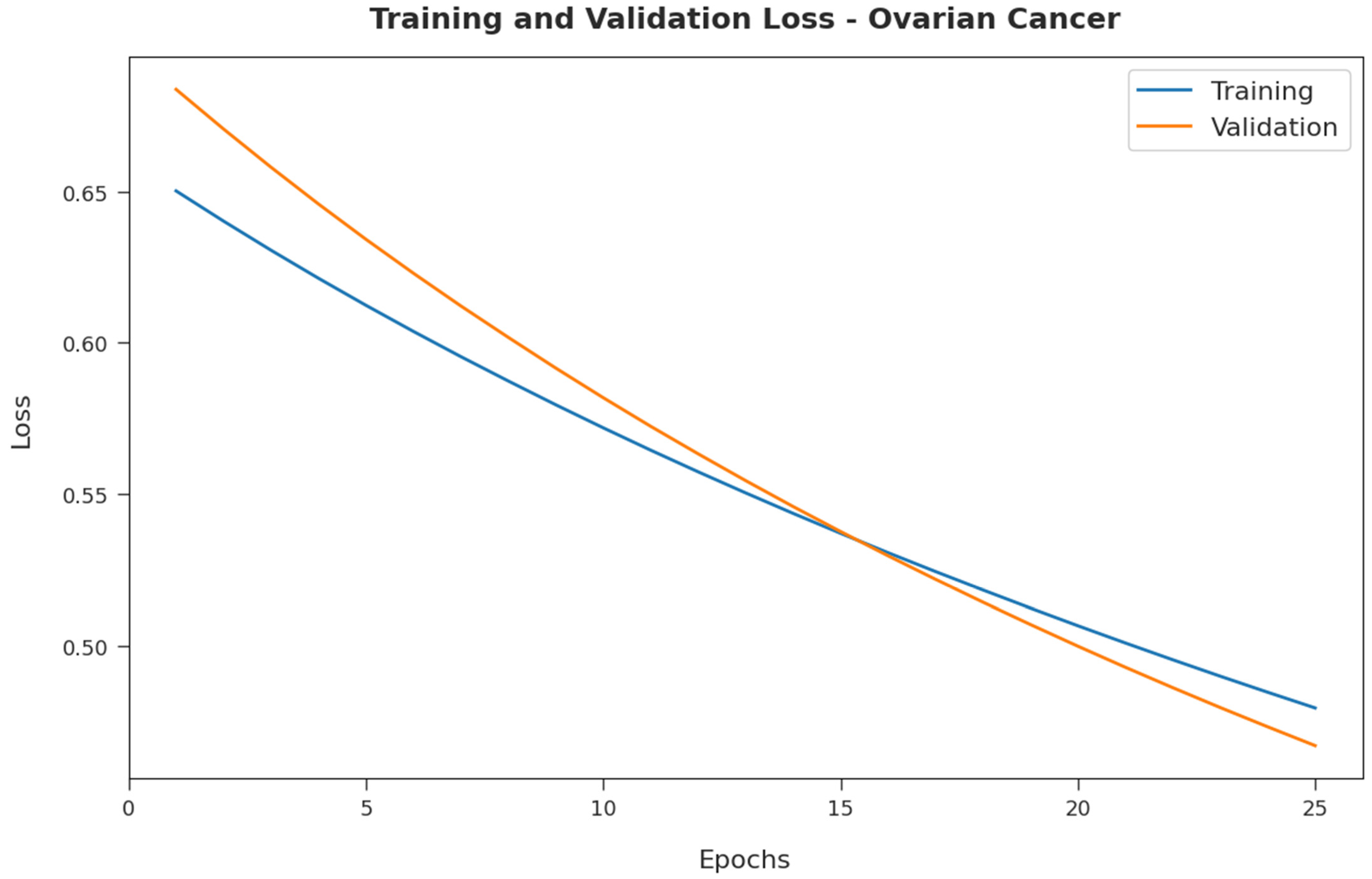
4.3. Resulting Analysis of RFODL-MGEC Technique on Ovarian Cancer Dataset
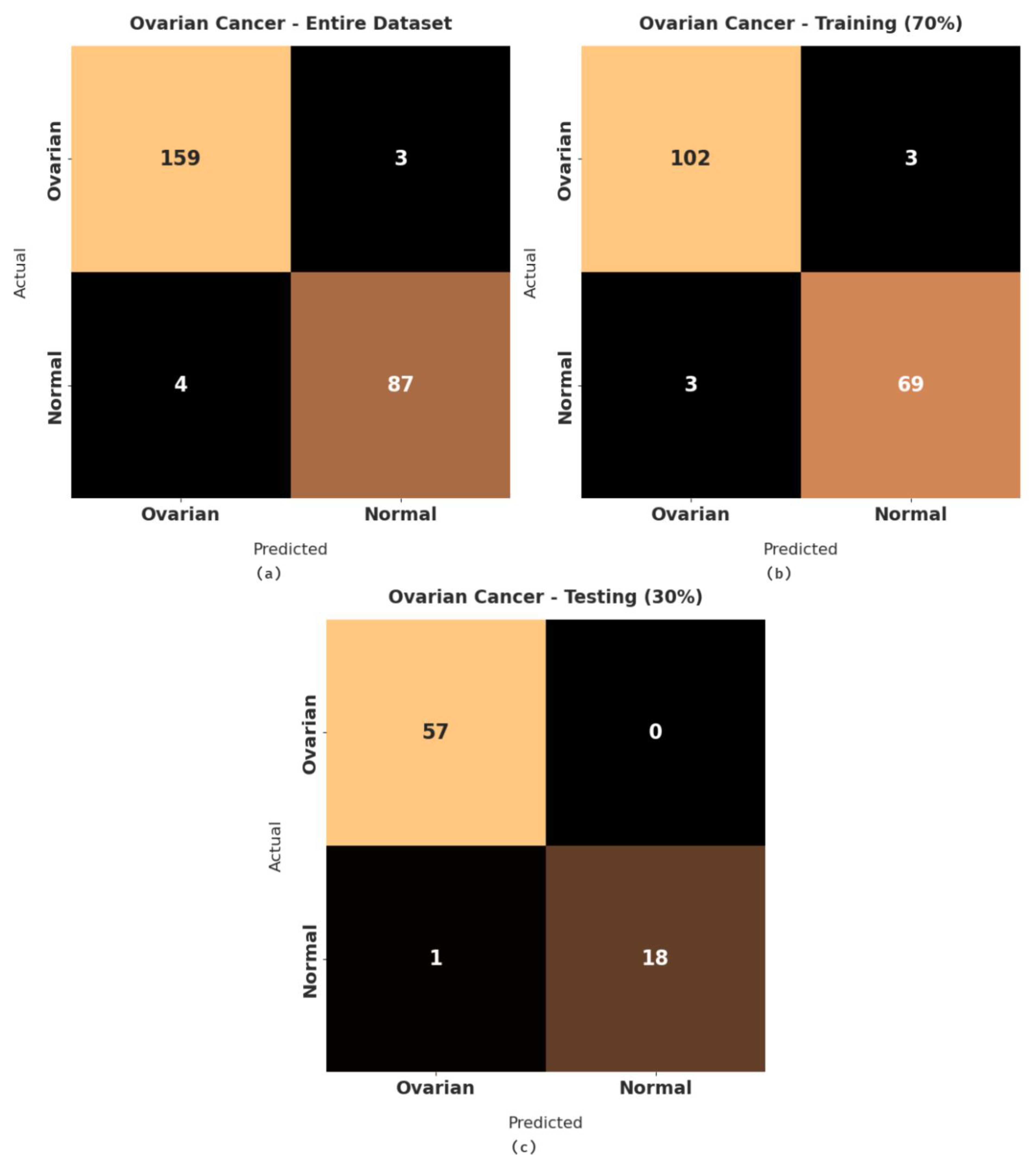
Figure 9 illustrates a set of confusion matrices generated by the RFODL-MGEC algorithm on the test ovarian cancer dataset. For the entire dataset, the RFODL-MGEC technique categorized 159 images as ovarian and 87 images as normal. With 70% of the training dataset, the RFODL-MGEC algorithm categorized 102 images as ovarian and 69 images as normal. For 30% of the testing dataset, the RFODL-MGEC technique categorized 57 images as ovarian and 18 images as normal.
Table 4 shows a brief classification performance report on the RFODL-MGEC technique with the ovarian cancer dataset. The experimental results indicated that the RFODL-MGEC technique demonstrated effective results on the test dataset. For instance, with the entire dataset, the RFODL-MGEC system obtained an average
,
,
, and
of 97.23%, 97.11%, 96.88%, and 96.99%, respectively. With 70% of the training dataset, the RFODL-MGEC algorithm obtained an average
,
,
, and
of 96.61%, 96.49%, 96.49%, and 96.49%, respectively. Eventually, with 30% of the testing dataset, the RFODL-MGEC algorithm obtained an average
,
,
, and
of 98.68%, 99.14%, 97.37%, and 98.21%, respectively.
Figure 10 illustrates the training and validation accuracy inspection of the RFODL-MGEC algorithm with the ovarian cancer dataset. The figure conveys that the RFODL-MGEC technique offered maximum training/validation accuracy for the classification process.
Figure 11 exemplifies the training and validation loss inspection of the RFODL-MGEC technique on the ovarian cancer dataset. The figure shows that the RFODL-MGEC system offered reduced training/accuracy loss for the classification process of the test data.
4.4. Discussion
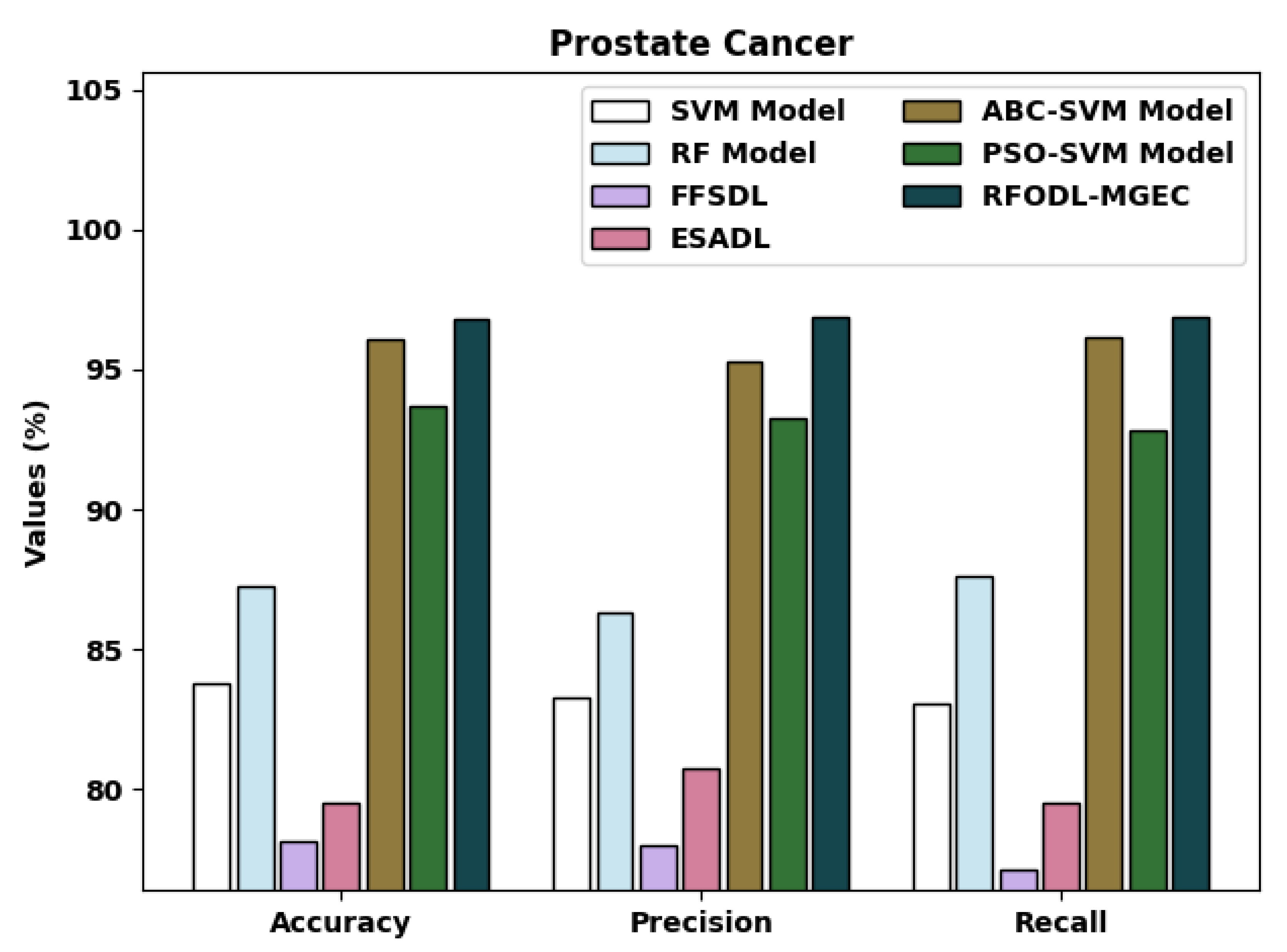
A detailed comparative examination of the RFODL-MGEC model with recent approaches [
15] for prostate cancer is provided in
Table 5 and
Figure 12. The experimental outcomes indicated that the FFSDL and ESADL models reached lower classification outcomes than other approaches. At the same time, the SVM and RF models accomplished slightly enhanced classification outcomes compared with the FFSDL and ESADL models. Along with that, the ABC-SVM and PSO-SVM models accomplished closer classification performances, with an
of 96.06% and 93.71%, respectively.
The proposed RFODL-MGEC model resulted in maximum classification efficiency, with an , , and of 96.77%, 96.88%, and 96.88% respectively.
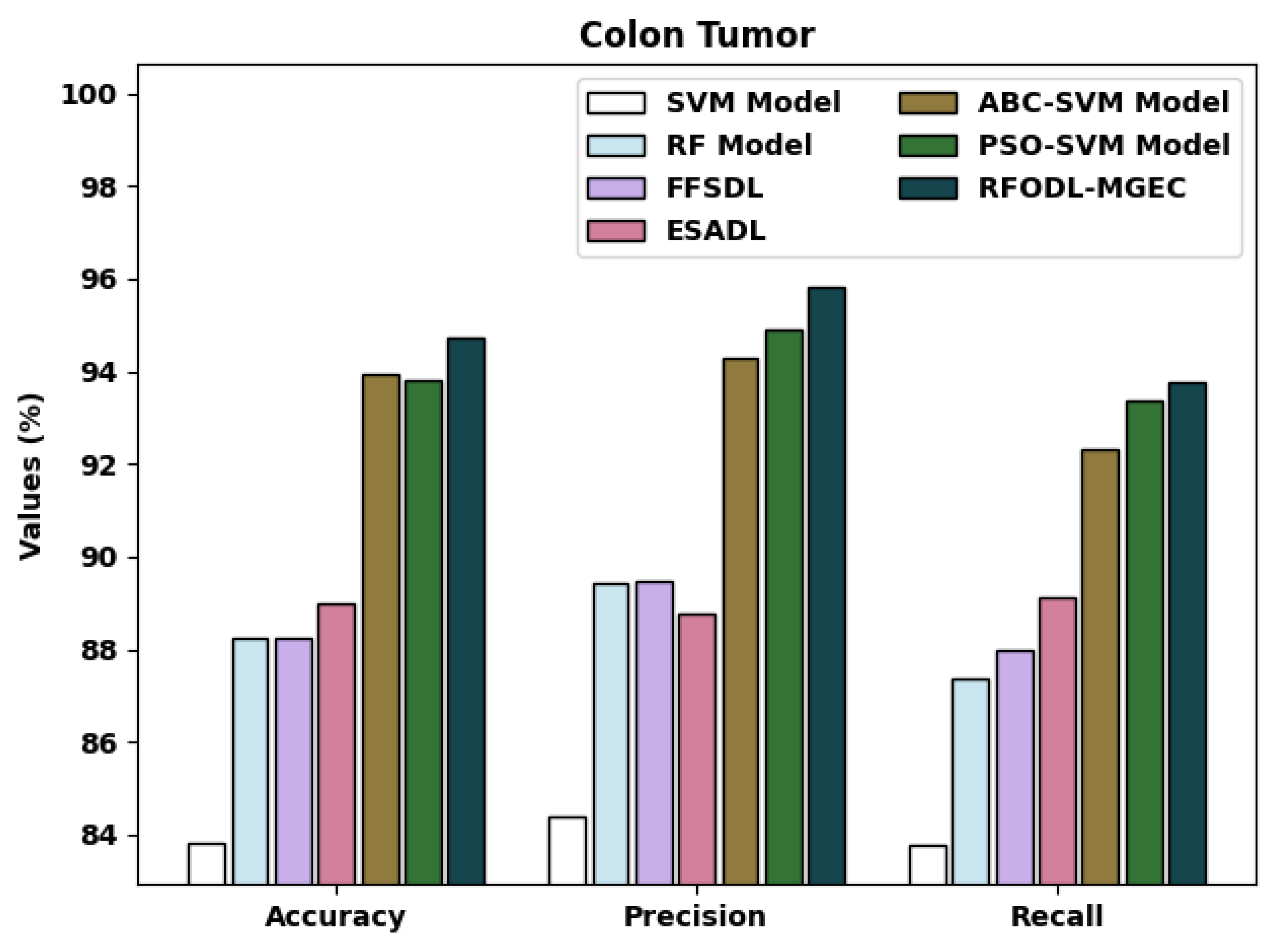
A brief comparative examination of the RFODL-MGEC approach with recent approaches for colon tumors is given in
Table 6 and
Figure 13. The experimental outcomes indicated that the FFSDL and ESADL approaches reached lower classification outcomes than the other approaches. Likewise, the SVM and RF approaches accomplished somewhat enhanced classification outcomes compared with the FFSDL and ESADL approaches.
Along with that, the ABC-SVM and PSO-SVM models accomplished closer classification performances, with an of 93.94% and 93.80%, respectively. Finally, the RFODL-MGEC model resulted in higher classification efficiency with an , , and of 94.74%, 95.83%, and 93.75% respectively.
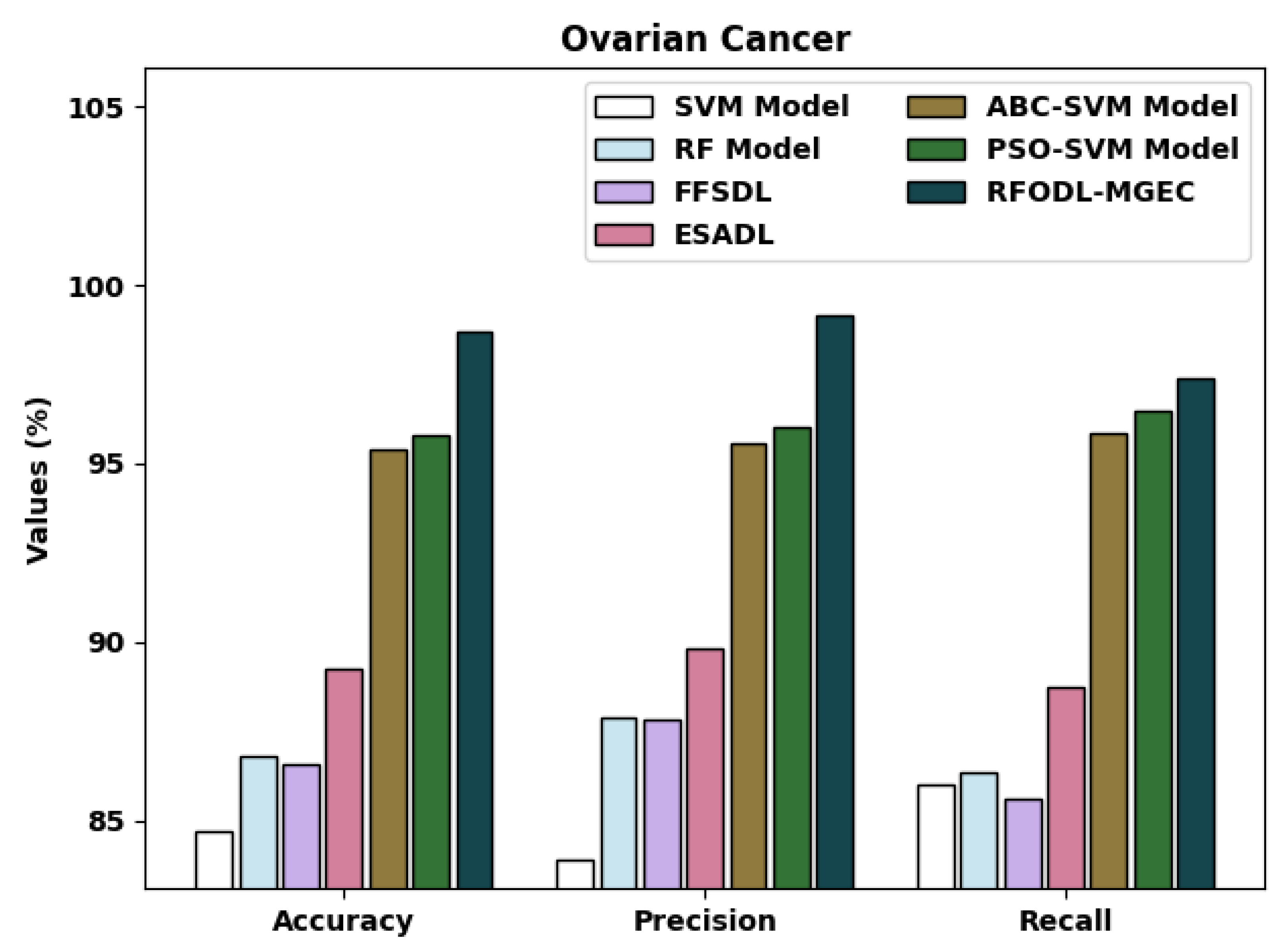
A detailed comparative examination of the RFODL-MGEC algorithm with recent approaches for ovarian cancer is given in
Table 7 and
Figure 14. The experimental outcomes indicated that the FFSDL and ESADL methods reached lower classification outcomes than the other approaches.
The SVM and RF models accomplished some enhanced classification outcomes compared with the FFSDL and ESADL models. This was followed by the ABC-SVM and PSO-SVM techniques, which accomplished closer classification performances with an of 95.42% and 95.81%, respectively. Finally, the RFODL-MGEC methodology resulted in maximum classification efficiency, with an , , and of 98.68%, 99.11%, and 97.37%, respectively.
Finally, a computation time (CT) examination of the RFODL-MGEC technique with recent models for the three distinct datasets is provided in
Table 8. The experimental results indicated that the RFODL-MGEC technique showed a lower CT compared with the other methods. The proposed RFODL-MGEC technique required a lower CT of 1.231, 0.432, and 1.542 s with the test prostate cancer, colon tumor, and ovarian cancer datasets, respectively.
After examining the aforementioned tables and figures, we noted that the RFODL-MGEC model was able to maximize classification performance compared with the other methods.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}