
Arabic Language Opinion Mining Based on Long Short-Term Memory (LSTM)

 ,
,  ,
,  , ,
, ,  ,
,
Abstract
1. Introduction
2. Literature Review
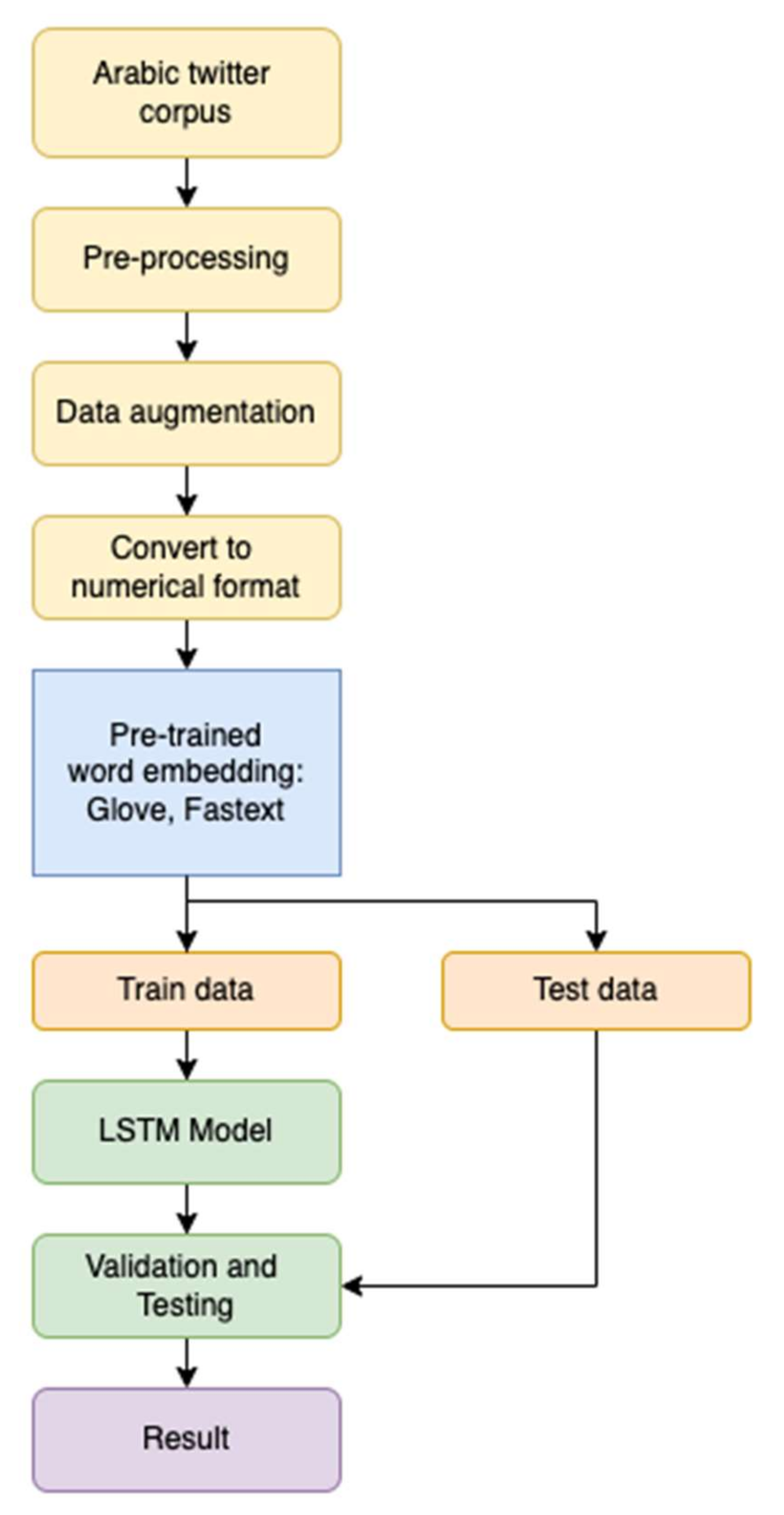
3. Methodology
3.1. Frameworks
3.2. Experimental Scenarios
3.3. Word Embedding
3.3.1. GloVe
3.3.2. fastText
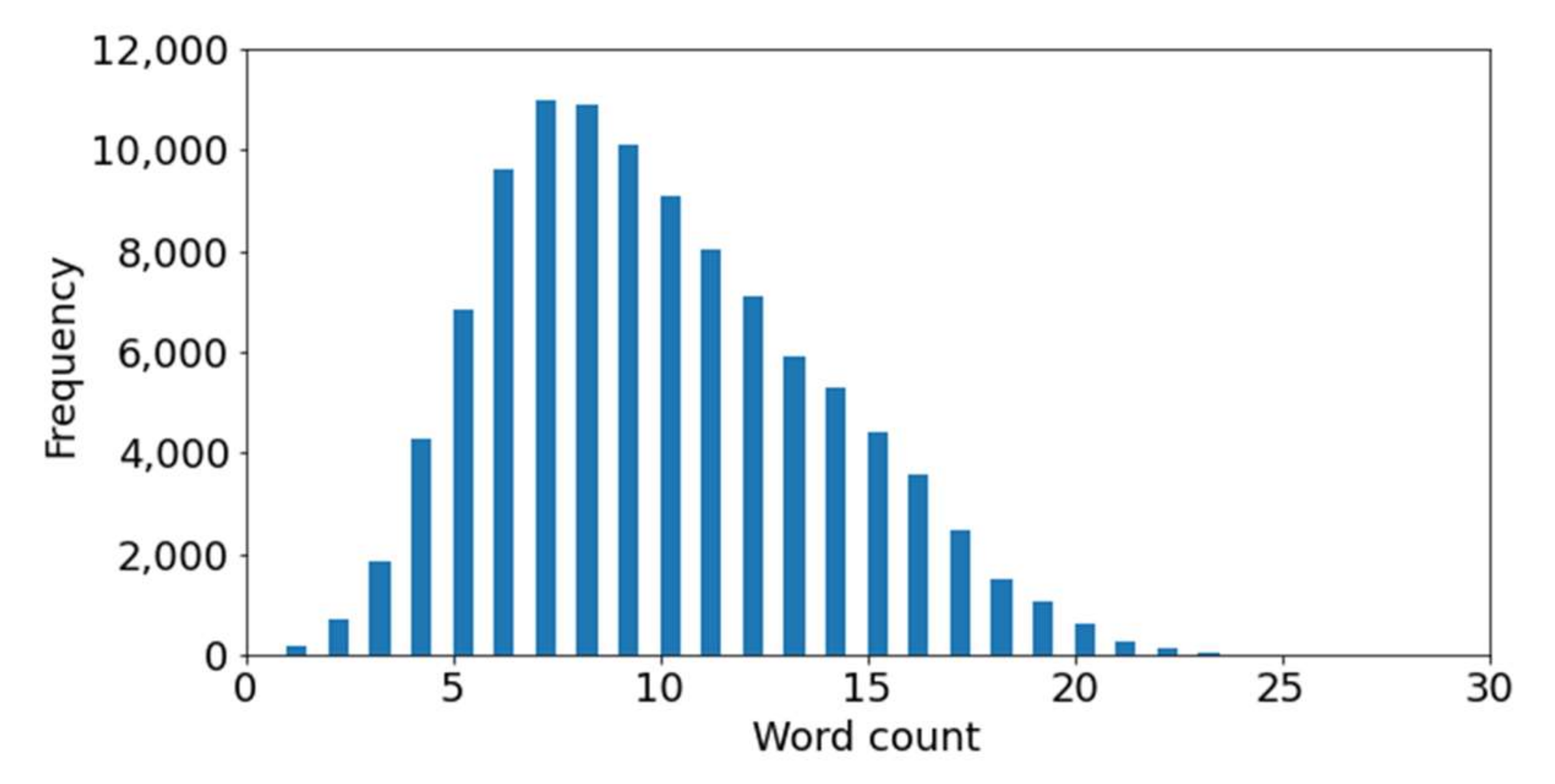
3.4. Dataset
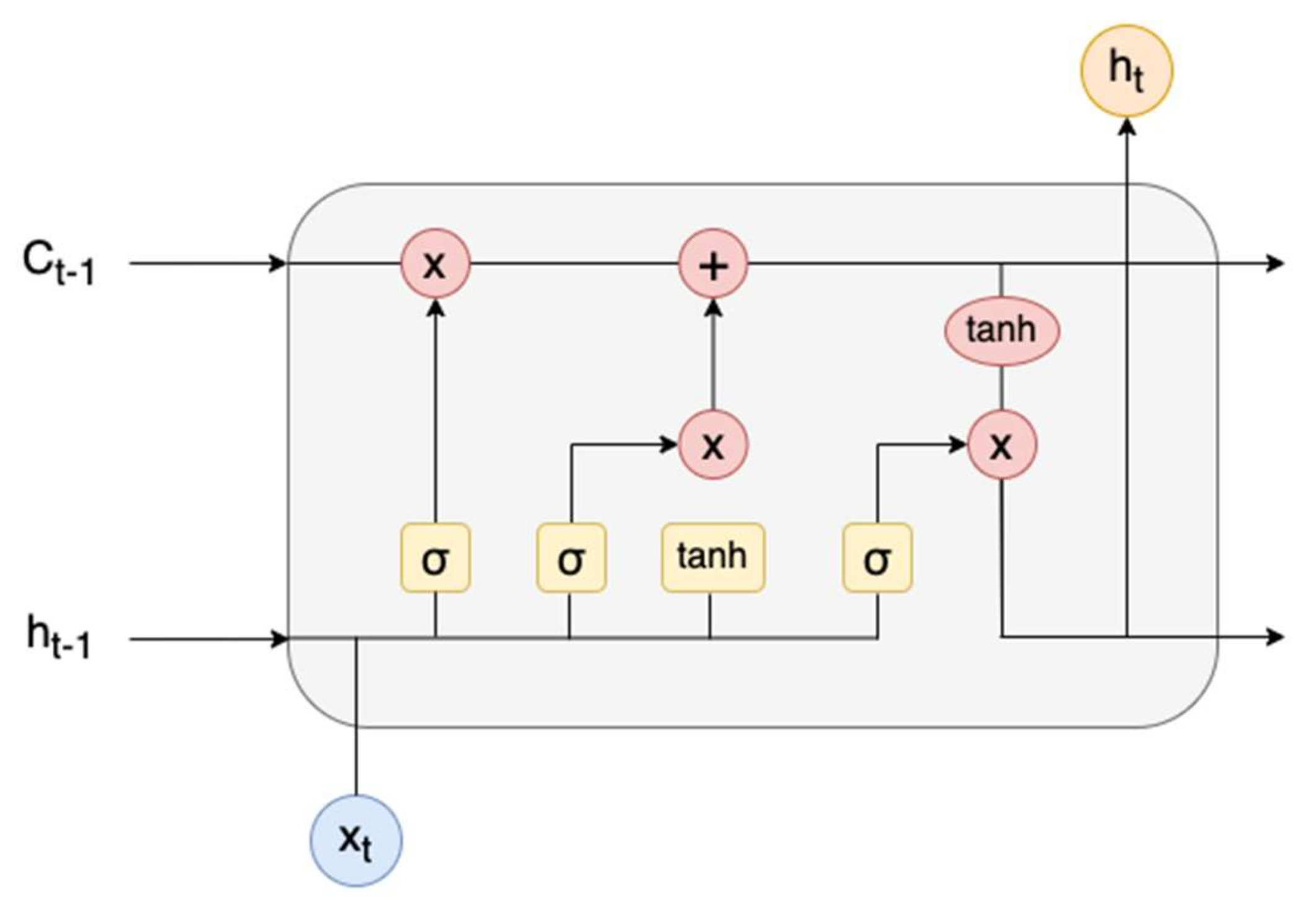
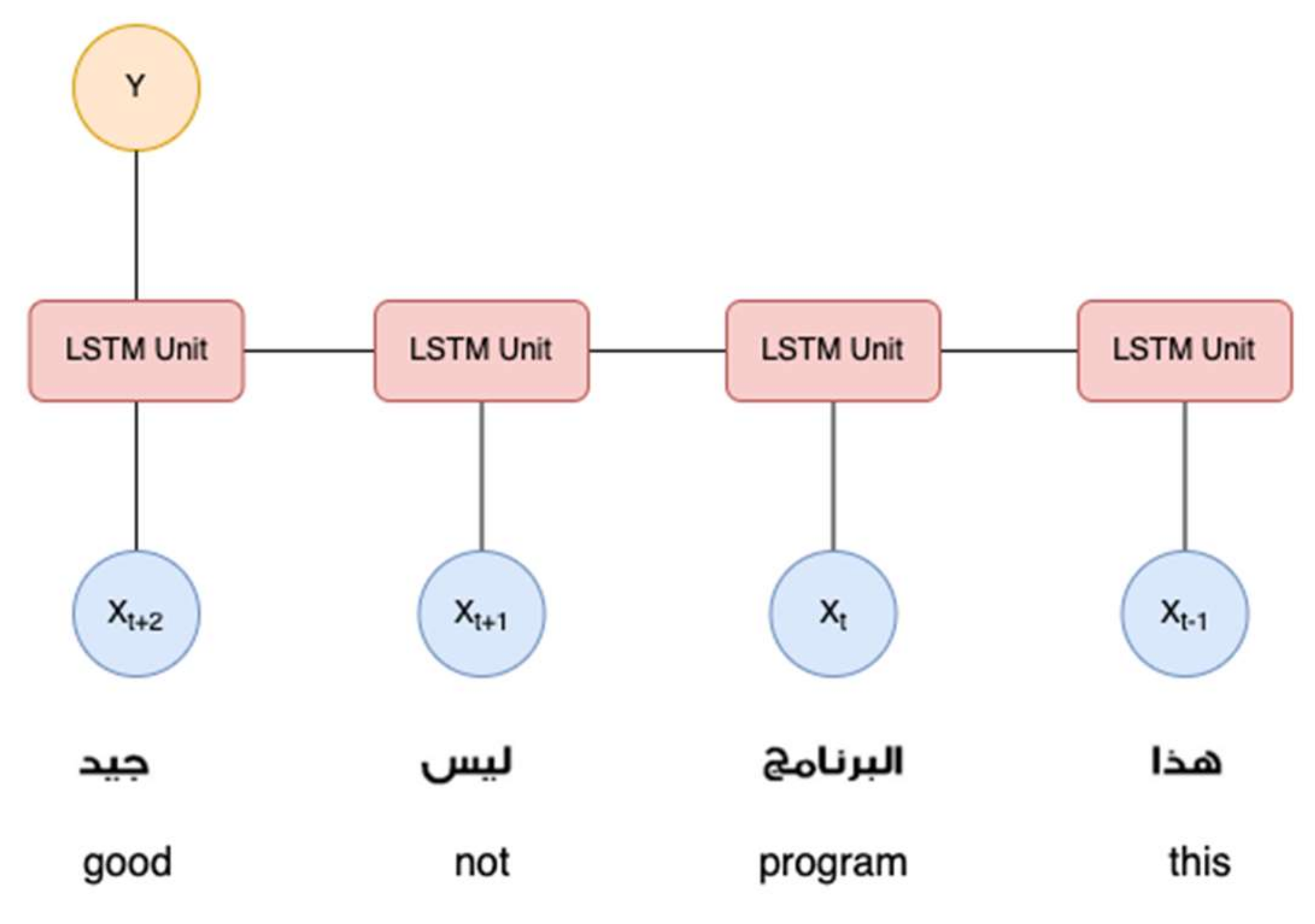
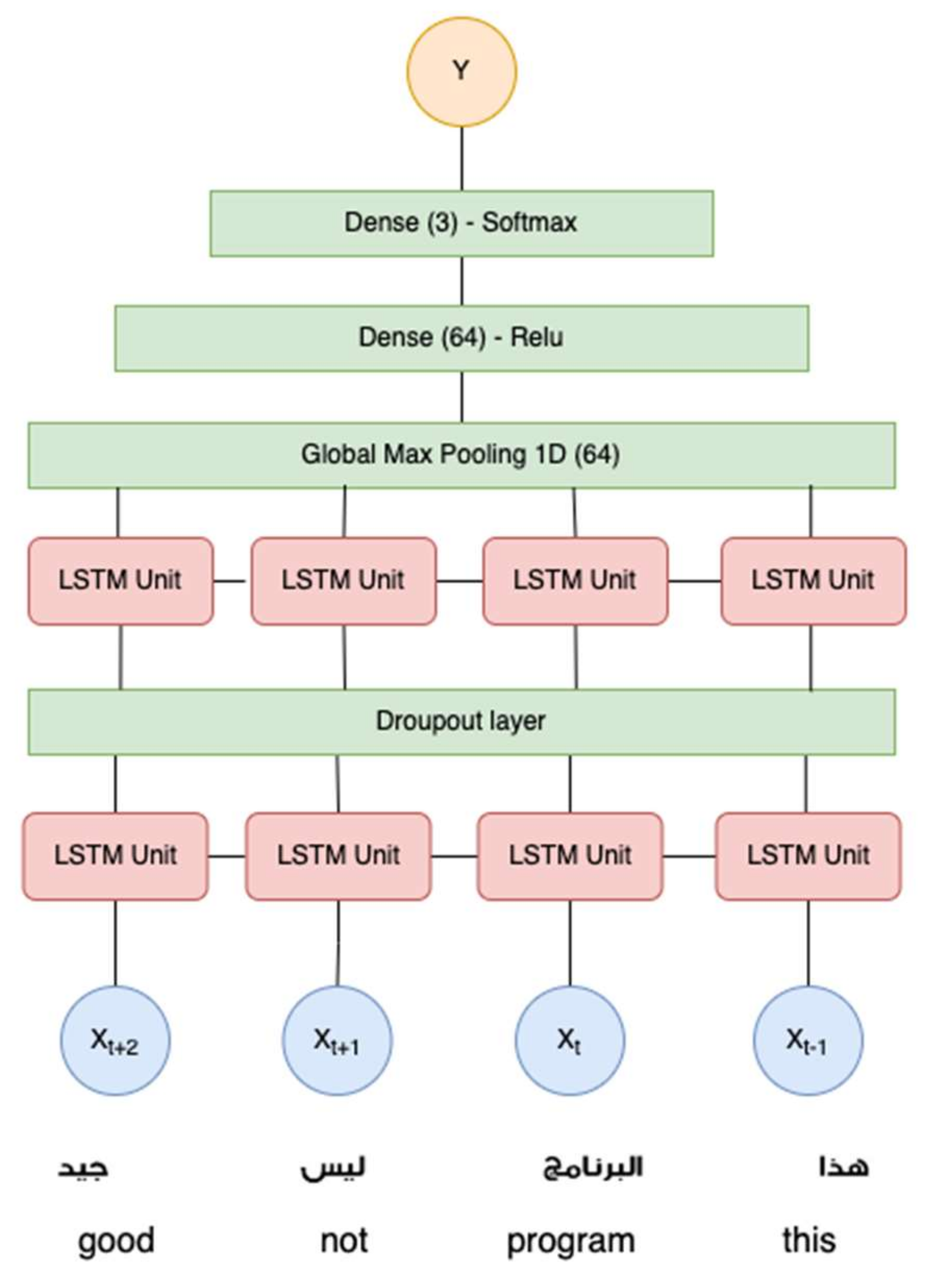
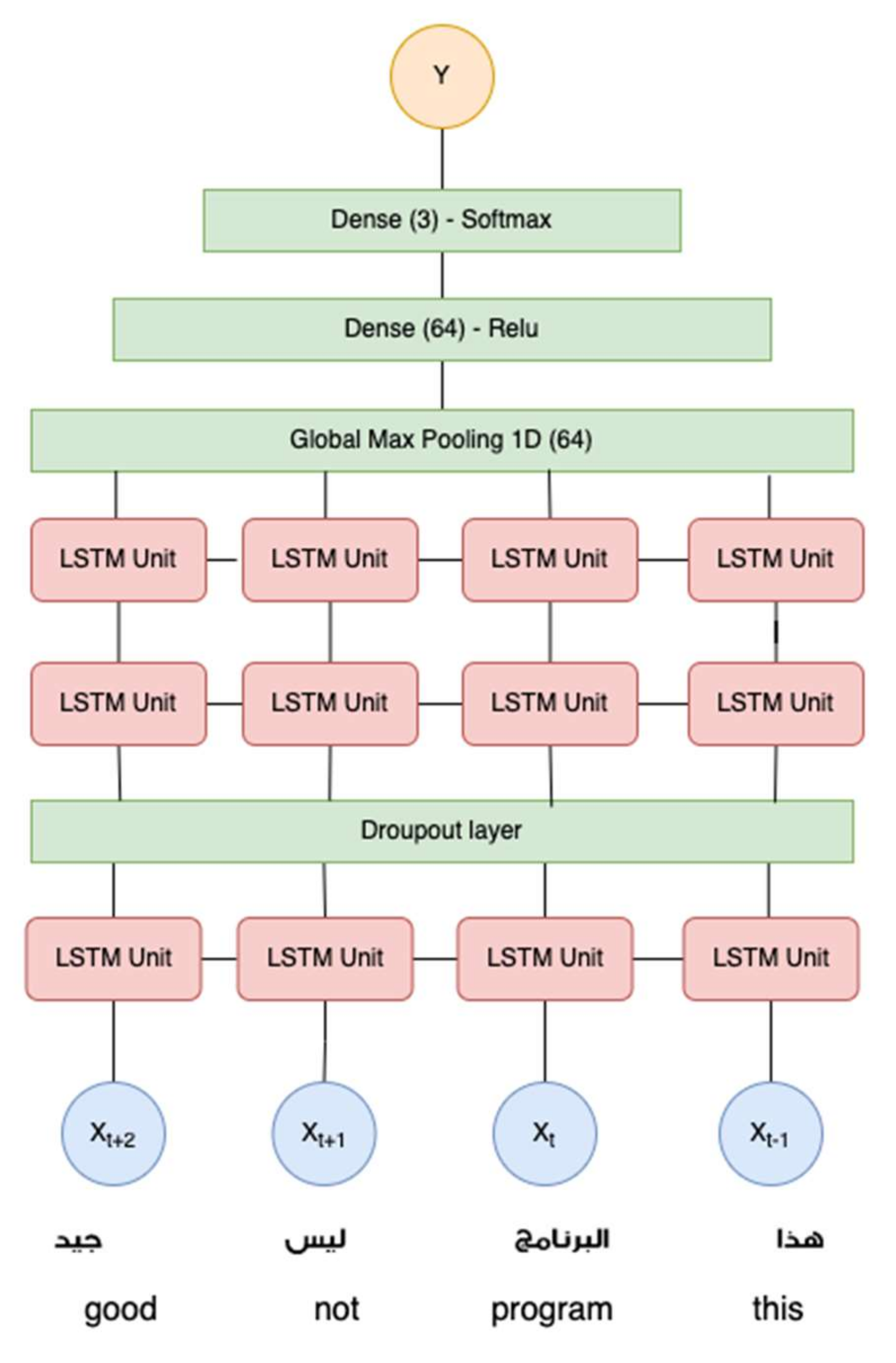
3.5. Long Short-Term Memory (LSTM)
- Xt = Input vector at the time t.
- ht−1 = Previous Hidden state.
- Ct−1 = Previous Memory state.
- ht = Current Hidden state.
- Ct = Current Memory state.
- [x] = Multiplication operation.
- [+] = Addition operation.
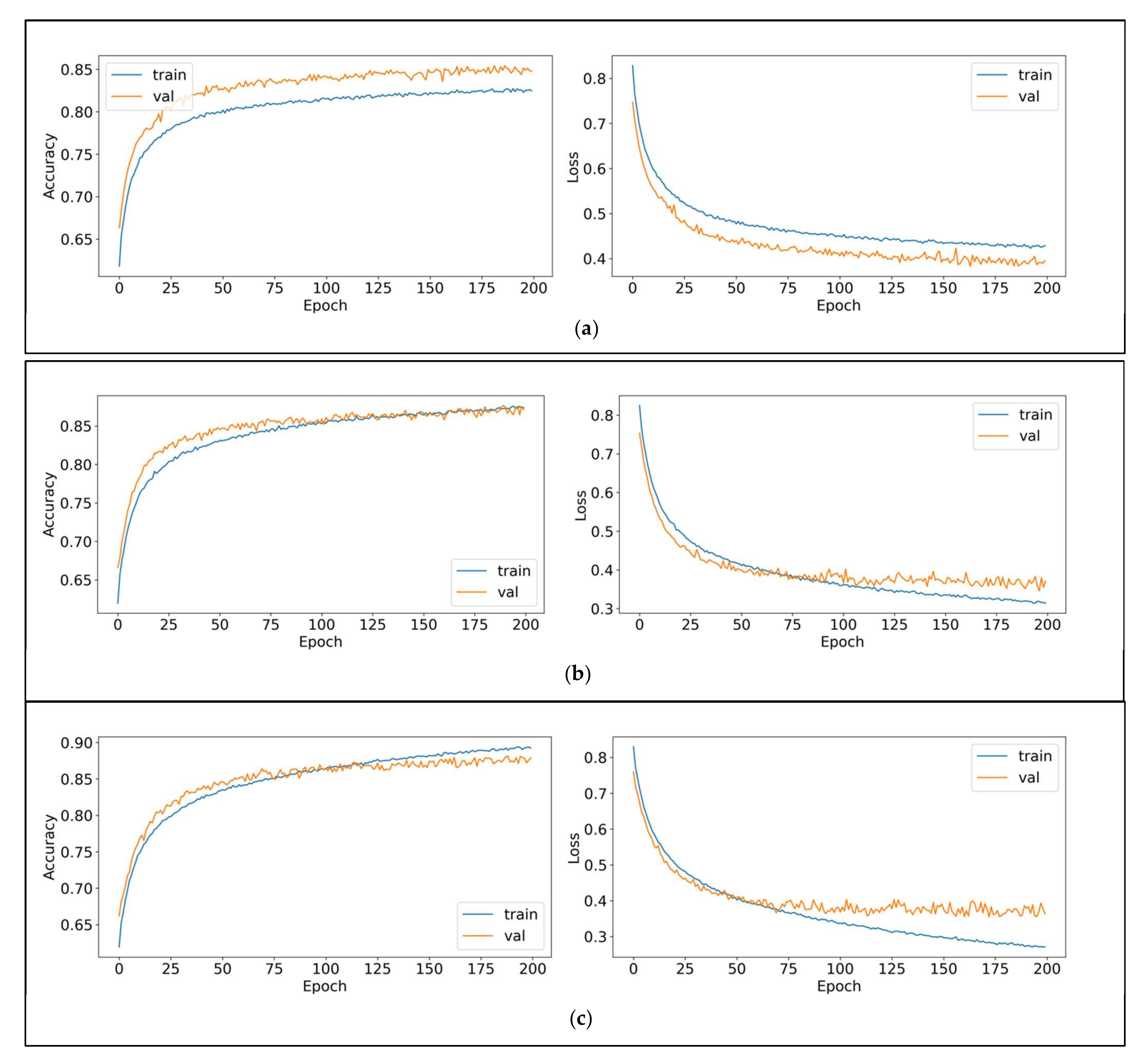
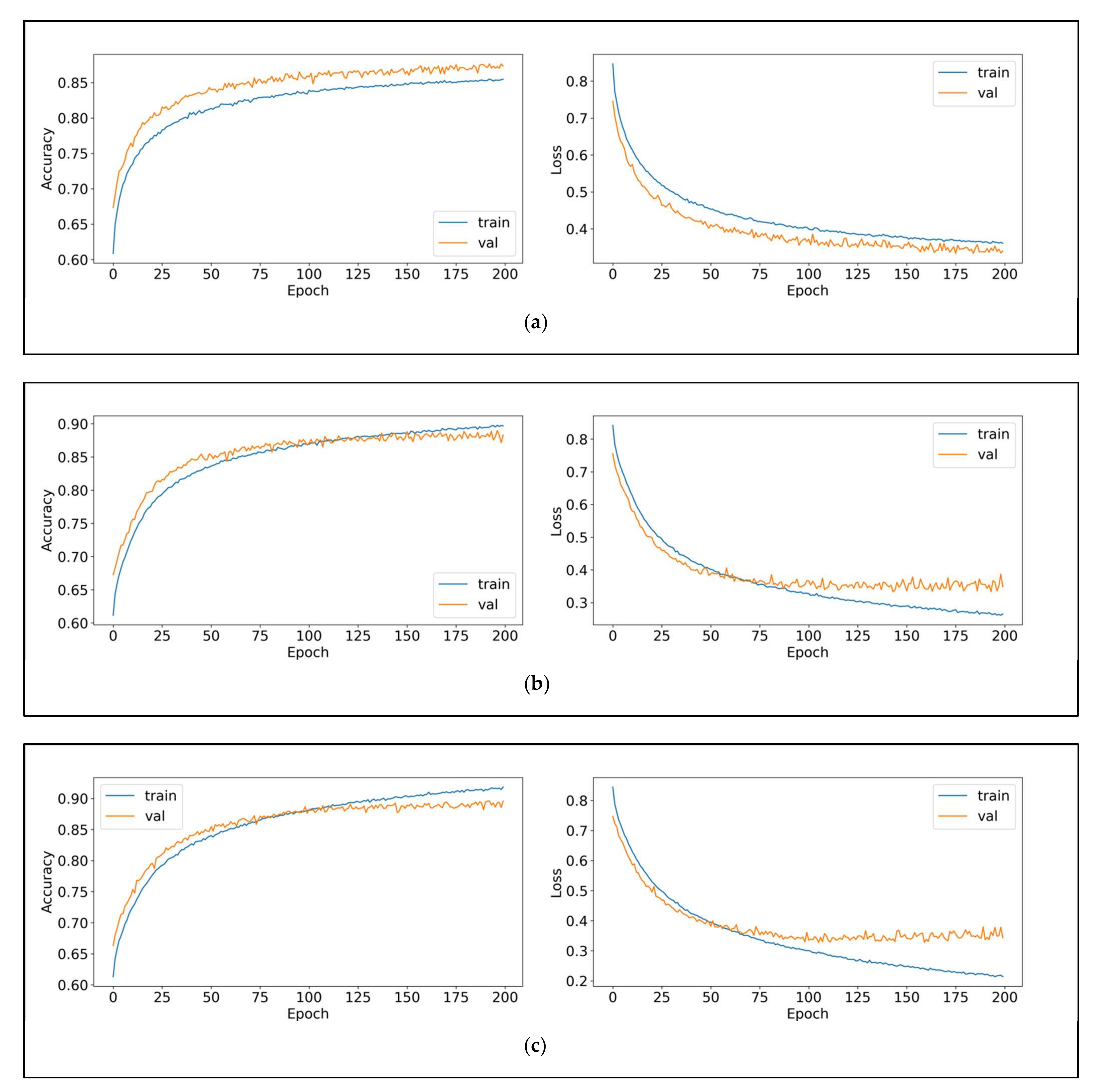
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rezaeinia, S.M.; Rahmani, R.; Ghodsi, A.; Veisi, H. Sentiment analysis based on improved pre-trained word embeddings. Expert Syst. Appl. 2019, 117, 139–147. [Google Scholar] [CrossRef]
- Cambria, E.; Schuller, B.; Xia, Y.; Havasi, C. New avenues in opinion mining and sentiment analysis. IEEE Intell. Syst. 2013, 28, 15–21. [Google Scholar] [CrossRef]
- Hubert, R.B.; Estevez, E.; Maguitman, A.; Janowski, T. Examining government-citizen interactions on twitter using visual and sentiment analysis. In Proceedings of the 19th Annual International Conference on Digital Government Research: Governance in the Data Age, Delft, The Netherlands, 30 May 2018. [Google Scholar]
- Noor, N.H.M.; Sapuan, S.; Bond, F. Creating the open wordnet Bahasa. In Proceedings of the 25th Pacific Asia Conference on Language, Information and Computation, Singapore, 16–18 December 2011; pp. 255–264. [Google Scholar]
- ElSahar, H.; El-Beltagy, S.R. Building large arabic multi-domain resources for sentiment analysis. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2015; Volume 9042, pp. 23–34. [Google Scholar]
- Al-Rowaily, K.; Abulaish, M.; Haldar, N.A.; Al-Rubaian, M. BiSAL—A bilingual sentiment analysis lexicon to analyze Dark Web forums for cyber security. Digit. Investig. 2015, 14, 53–62. [Google Scholar] [CrossRef]
- Badaro, G.; Baly, R.; Hajj, H.; Habash, N.; El-Hajj, W. A Large Scale Arabic Sentiment Lexicon for Arabic Opinion Mining. In Proceedings of the EMNLP 2014 Workshop on Arabic Natural Langauge Processing (ANLP), Doha, Qatar, 25 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 165–173. [Google Scholar]
- Eskander, R.; Rambow, O. SLSA: A sentiment lexicon for Standard Arabic. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2545–2550. [Google Scholar]
- Kurniasari, L.; Setyanto, A. Sentiment analysis using recurrent neural network-lstm in bahasa Indonesia. J. Eng. Sci. Technol. 2020, 15, 3242–3256. [Google Scholar]
- Gelbukh, A. Computational Linguistics and Intelligent Text Processing. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Proceedings of the 16th International Conference, CICLing 2015, Cairo, Egypt, 14–20 April 2015; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9042. [Google Scholar]
- Mukhtar, N.; Khan, M.A.; Chiragh, N. Lexicon-based approach outperforms Supervised Machine Learning approach for Urdu Sentiment Analysis in multiple domains. Telemat. Inform. 2018, 35, 2173–2183. [Google Scholar] [CrossRef]
- Jones, K.S. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the 1st International Conference on Learning Representations ICLR 2013, Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Boudad, N.; Faizi, R.; Thami, R.O.H.; Chiheb, R. Sentiment analysis in Arabic: A review of the literature. Ain Shams Eng. J. 2018, 9, 2479–2490. [Google Scholar] [CrossRef]
- Guellil, I.; Saâdane, H.; Azouaou, F.; Gueni, B.; Nouvel, D. Arabic natural language processing: An overview. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 497–507. [Google Scholar] [CrossRef]
- Darwish, K. Arabizi Detection and Conversion to Arabic. arXiv 2015, arXiv:1306.6755. [Google Scholar]
- Alharbi, B.; Alamro, H.; Alshehri, M.; Khayyat, Z.; Kalkatawi, M.; Jaber, I.I.; Zhang, X. ASAD: A Twitter-based Benchmark Arabic Sentiment Analysis Dataset. arXiv 2020, arXiv:2011.00578. [Google Scholar]
- Smetanin, S.; Komarov, M. Deep transfer learning baselines for sentiment analysis in Russian. Inf. Process. Manag. 2021, 58, 102484. [Google Scholar] [CrossRef]
- Baly, R.; Hajj, H.; Habash, N.; Shaban, K.B.; El-hajj, W. A Sentiment Treebank and Morphologically Enriched Recursive Deep. ACM Trans. Asian Low-Resource Lang. Inf. Process. 2017, 16, 1–21. [Google Scholar] [CrossRef]
- Montejo-Ráez, A.; Martínez-Cámara, E.; Martín-Valdivia, M.T.; Ureña-López, L.A. Ranked WordNet graph for Sentiment Polarity Classification in Twitter. Comput. Speech Lang. 2014, 28, 93–107. [Google Scholar] [CrossRef]
- Kouloumpis, E.; Wilson, T.; Moore, J. Twitter Sentiment Analysis: The Good the Bad and the OMG! In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; Volume 5, pp. 538–541. [Google Scholar]
- Liu, B.; Blasch, E.; Chen, Y.; Shen, D.; Chen, G. Scalable sentiment classification for Big Data analysis using Naïve Bayes Classifier. In Proceedings of the IEEE International Conference on Big Data, Silicon Valley, CA, USA, 6–9 October 2013; pp. 99–104. [Google Scholar]
- Oueslati, O.; Cambria, E.; HajHmida, M.B.; Ounelli, H. A review of sentiment analysis research in Arabic language. Futur. Gener. Comput. Syst. 2020, 112, 408–430. [Google Scholar] [CrossRef]
- Al-Osaimi, S.; Badruddin, M. Sentiment Analysis Challenges of Informal Arabic Language. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 278–284. [Google Scholar] [CrossRef]
- Aly, M.; Atiya, A. LABR: A large scale arabic book reviews dataset. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; Volume 2, pp. 494–498. [Google Scholar]
- Abdulla, N.A.; Ahmed, N.A.; Shehab, M.A.; Al-Ayyoub, M. Arabic Sentiment Analysis: Lexicon-based and Corpus-based. In Proceedings of the 2013 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies (AEECT), Amman, Jordan, 3–5 December 2013; Volume 6, pp. 1–6. [Google Scholar]
- Nabil, M.; Aly, M.; Atiya, A.F. ASTD: Arabic sentiment tweets dataset. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2515–2519. [Google Scholar]
- Baly, R.; El-Khoury, G.; Moukalled, R.; Aoun, R.; Hajj, H.; Shaban, K.B.; El-Hajj, W. Comparative Evaluation of Sentiment Analysis Methods Across Arabic Dialects. Procedia Comput. Sci. 2017, 117, 266–273. [Google Scholar] [CrossRef]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-basedmethods for sentiment analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- Abdulla, N.; Majdalawi, R.; Mohammed, S.; Al-Ayyoub, M.; Al-Kabi, M. Automatic lexicon construction for arabic sentiment analysis. In Proceedings of the 2014 International Conference on Future Internet of Things and Cloud, Barcelona, Spain, 27–29 August 2014; pp. 547–552. [Google Scholar]
- Al-Ayyoub, M.; Essa, S.B.; Alsmadi, I. Lexicon-based sentiment analysis of Arabic tweets Mahmoud Al-Ayyoub * and Safa Bani Essa Izzat Alsmadi. Int. J. Soc. Netw. Min. 2015, 2, 101–114. [Google Scholar] [CrossRef]
- Khoo, C.S.; Johnkhan, S.B. Lexicon-based sentiment analysis: Comparative evaluation of six sentiment lexicons. J. Inf. Sci. 2018, 44, 491–511. [Google Scholar] [CrossRef]
- Moraes, R.; Valiati, J.F.; Neto, W.P.G. Document-level sentiment classification: An empirical comparison between SVM and ANN. Expert Syst. Appl. 2013, 40, 621–633. [Google Scholar] [CrossRef]
- Altowayan, A.A.; Elnagar, A. Improving Arabic sentiment analysis with sentiment-specific embeddings. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 4314–4320. [Google Scholar]
- Al-Ayyoub, M.; Nuseir, A.; Kanaan, G.; Al-Shalabi, R. Hierarchical Classifiers for Multi-Way Sentiment Analysis of Arabic Reviews. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 531–539. [Google Scholar] [CrossRef]
- Alayba, A.M.; Palade, V.; England, M.; Iqbal, R. Arabic language sentiment analysis on health services. In Proceedings of the International Workshop on Arabic Script Analysis and Recognition (ASAR), Nancy, France, 3–5 April 2017; pp. 114–118. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014; pp. 103–111. [Google Scholar]
- Rehman, A.U.; Malik, A.K.; Raza, B.; Ali, W. A Hybrid CNN-LSTM Model for Improving Accuracy of Movie Reviews Sentiment Analysis. Multimed. Tools Appl. 2019, 78, 26597–26613. [Google Scholar] [CrossRef]
- Mohammed, A.; Kora, R. Deep learning approaches for Arabic sentiment analysis. Soc. Netw. Anal. Min. 2019, 9, 52. [Google Scholar] [CrossRef]
- Heikal, M.; Torki, M.; El-Makky, N. Sentiment Analysis of Arabic Tweets using Deep Learning. Procedia Comput. Sci. 2018, 142, 114–122. [Google Scholar] [CrossRef]
- Guellil, I.; Azouaou, F.; Chiclana, F. ArAutoSenti: Automatic annotation and new tendencies for sentiment classification of Arabic messages. Soc. Netw. Anal. Min. 2020, 10, 75. [Google Scholar] [CrossRef]
- Ombabi, A.H.; Ouarda, W.; Alimi, A.M. Deep learning CNN–LSTM framework for Arabic sentiment analysis using textual information shared in social networks. Soc. Netw. Anal. Min. 2020, 10, 53. [Google Scholar] [CrossRef]
- Robertson, S. Understanding inverse document frequency: On theoretical arguments for IDF. J. Doc. 2004, 60, 503–520. [Google Scholar] [CrossRef]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by latent semantic analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Grave, E.; Bojanowski, P.; Gupta, P.; Joulin, A.; Mikolov, T. Learning word vectors for 157 languages. arXiv 2019, arXiv:1802.06893. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Papers | Dataset | Composition | Language | Algorithm | Accuracy |
|---|---|---|---|---|---|
| [41] | Corpus on Arabic Egyptian tweets | 40,000:20,000 Positive, 20,000 Negative | Arabic (Modern Standard Arabic) and Egyptian Dialect | LSTM + Augmentation | 88.05 |
| LSTM | 81.3 | ||||
| CNN | 75.72 | ||||
| RCNN | 78.76 | ||||
| [44] | LABR (Large Scale Arabic Book Review) | 63,257:5 classes 1:2939, 2:5285, 3:12,201, 4:19,054, 5: 25,778 | Arabic | FastText Skip gram—CNN-LSTM | 90.75 |
| LSTM 1 layer | 87.98 | ||||
| LSTM 2 Layers | 90.75 | ||||
| [36] | LABR (Large Scale Arabic Book Review) | 63,257:5 classes 1:2939, 2:5285, 3:12,201, 4:19,054, 5:25,778 | Arabic | Logistic Regression | 84.97 |
| [42] | Arabic SemEval-2016 dataset for the Hotels domain | 24,028 | Arabic | CNN | 82.7 |
| LSTM | 82.6 | ||||
| [43] | Arabic SemEval-2016 dataset for the Hotels domain | 24,028 | Arabic | Bi-LSTM | 87.31 |
| Word Embedding | LSTM Architectures |
|---|---|
| GloVe | Single-Layer LSTM |
| Double-Layer LSTM | |
| Triple-Layer LSTM | |
| fastText | Single-Layer LSTM |
| Double-Layer LSTM | |
| Triple-Layer LSTM |
| Neutral | Positive | Negative | |
|---|---|---|---|
| Initial composition | 36,082 | 8533 | 8674 |
| Composition after augmentation | 36,082 | 36,082 | 36,082 |
| Layer (Type) | Output Shape | Number of Parameters |
|---|---|---|
| Word Embedding | (None, 30, 300) | 31,476,300 |
| LSTM layer | (None, 30, 64) | 93,440 |
| Maxpooling | (None, 64) | 0 |
| Dense layer | (None, 64) | 4160 |
| Dense layer | (None, 3) | 195 |
| Layer (Type) | Output Shape | Number of Parameters |
|---|---|---|
| Word Embedding | (None, 30, 300) | 31,476,300 |
| LSTM Layer | (None, 30, 64) | 93,440 |
| LSTM Layer | (None, 30, 64) | 33,024 |
| Max Pooling | (None, 64) | 0 |
| Dense Layer | (None, 64) | 4160 |
| Dense Layer | (None, 3) | 195 |
| Layer (Type) | Output Shape | Number of Parameters |
|---|---|---|
| Word Embedding | (None, 30, 300) | 31,476,300 |
| LSTM Layer | (None, 30, 64) | 93,440 |
| LSTM Layer | (None, 30, 64) | 33,024 |
| LSTM Layer | (None, 30, 64) | 33,024 |
| MaxPooling | (None, 64) | 0 |
| Dense Layer | (None, 64) | 4160 |
| Dense Layer | (None, 3) | 195 |
| GloVe | fastText | |||||
|---|---|---|---|---|---|---|
| Training Accuracy | Validation Accuracy | Testing Accuracy | Training Accuracy | Validation Accuracy | Testing Accuracy | |
| Single-Layer LSTM | 0.904 | 0.854 | 0.867 ± 0.005 | 0.928 | 0.876 | 0.881 ± 0.006 |
| Double-Layer LSTM | 0.943 | 0.876 | 0.891 ± 0.008 | 0.954 | 0.889 | 0.902 ± 0.003 |
| Triple-Layer LSTM | 0.955 | 0.881 | 0.903 ± 0.008 | 0.967 | 0.896 | 0.909 ± 0.007 |
| Architectures | Trainable Parameters | Training Time (min) | Testing Time (µs) | Testing in Consumer PC (s) | |||
|---|---|---|---|---|---|---|---|
| GloVe | fastText | GloVe | fastText | GloVe | fastText | ||
| Single-Layer LSTM | 97,795 | 37 | 37 | 6.68 | 6.20 | 7.31 | 6.28 |
| Double-Layer LSTM | 130,819 | 79 | 78 | 6.91 | 6.90 | 10.8 | 11.9 |
| Triple-Layer LSTM | 163,843 | 117 | 117 | 7.39 | 6.91 | 16.6 | 16.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Setyanto, A.; Laksito, A.; Alarfaj, F.; Alreshoodi, M.; Kusrini; Oyong, I.; Hayaty, M.; Alomair, A.; Almusallam, N.; Kurniasari, L. Arabic Language Opinion Mining Based on Long Short-Term Memory (LSTM). Appl. Sci. 2022, 12, 4140. https://doi.org/10.3390/app12094140
Setyanto A, Laksito A, Alarfaj F, Alreshoodi M, Kusrini, Oyong I, Hayaty M, Alomair A, Almusallam N, Kurniasari L. Arabic Language Opinion Mining Based on Long Short-Term Memory (LSTM). Applied Sciences. 2022; 12(9):4140. https://doi.org/10.3390/app12094140
Chicago/Turabian StyleSetyanto, Arief, Arif Laksito, Fawaz Alarfaj, Mohammed Alreshoodi, Kusrini, Irwan Oyong, Mardhiya Hayaty, Abdullah Alomair, Naif Almusallam, and Lilis Kurniasari. 2022. "Arabic Language Opinion Mining Based on Long Short-Term Memory (LSTM)" Applied Sciences 12, no. 9: 4140. https://doi.org/10.3390/app12094140
APA StyleSetyanto, A., Laksito, A., Alarfaj, F., Alreshoodi, M., Kusrini, Oyong, I., Hayaty, M., Alomair, A., Almusallam, N., & Kurniasari, L. (2022). Arabic Language Opinion Mining Based on Long Short-Term Memory (LSTM). Applied Sciences, 12(9), 4140. https://doi.org/10.3390/app12094140