
A Deep Learning Approach for Sentiment Analysis of COVID-19 Reviews





Abstract
:1. Introduction
2. Related Work
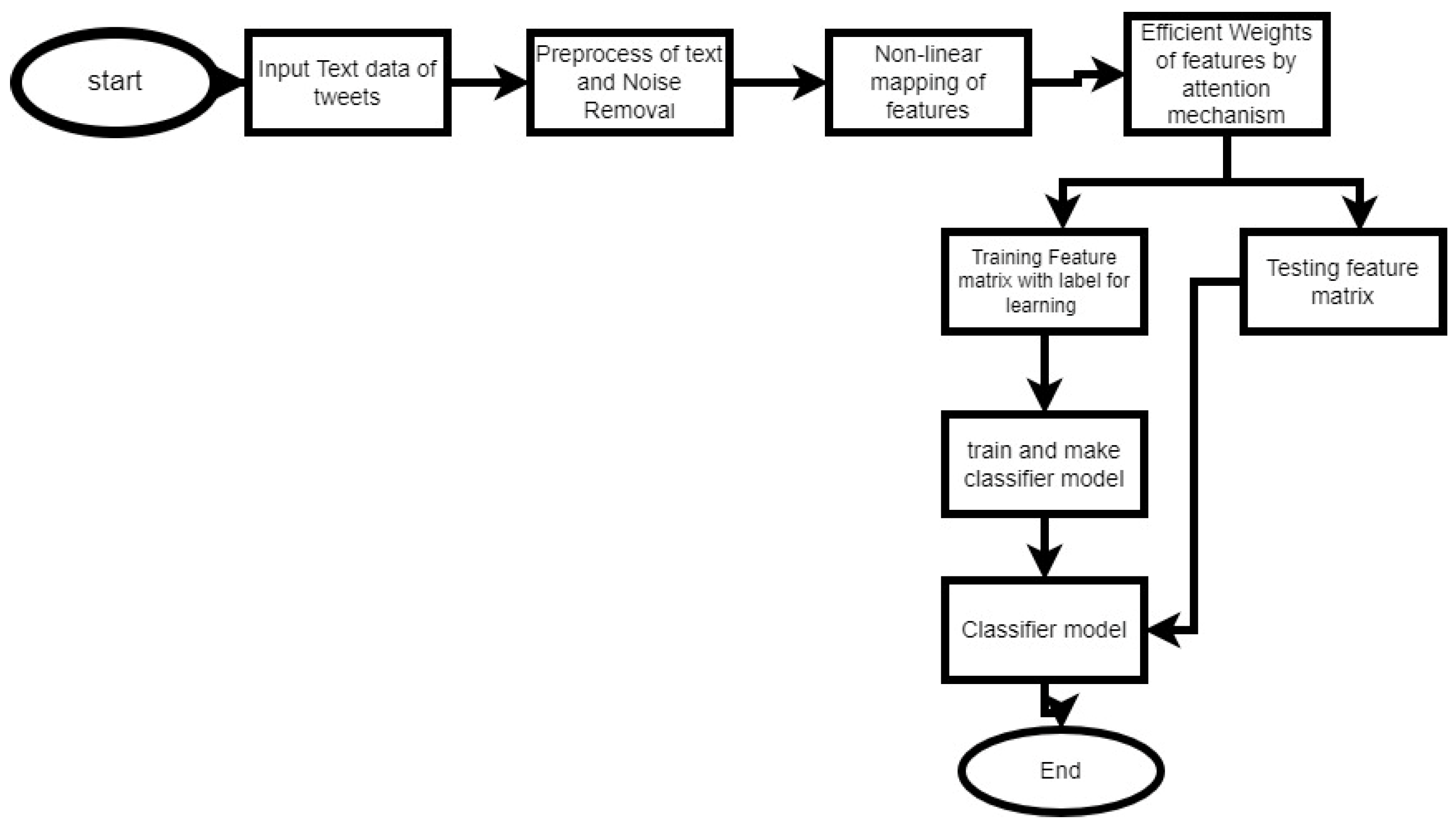
3. The Sentiment Classification Architecture
4. Methodology
4.1. Dataset
4.2. Attribute and Train/Test Dataset Formation
- In both uppercase characters, the formatting is translated into lowercase
- All internet slangs are removed
- Removed all the words that can be safely skipped from the list such as a, an, etc.
- Removed white spaces such as blank and empty spaces between words
- The redundant terms are compressed such as repetition of words
- The text of the hash tags is kept as it is
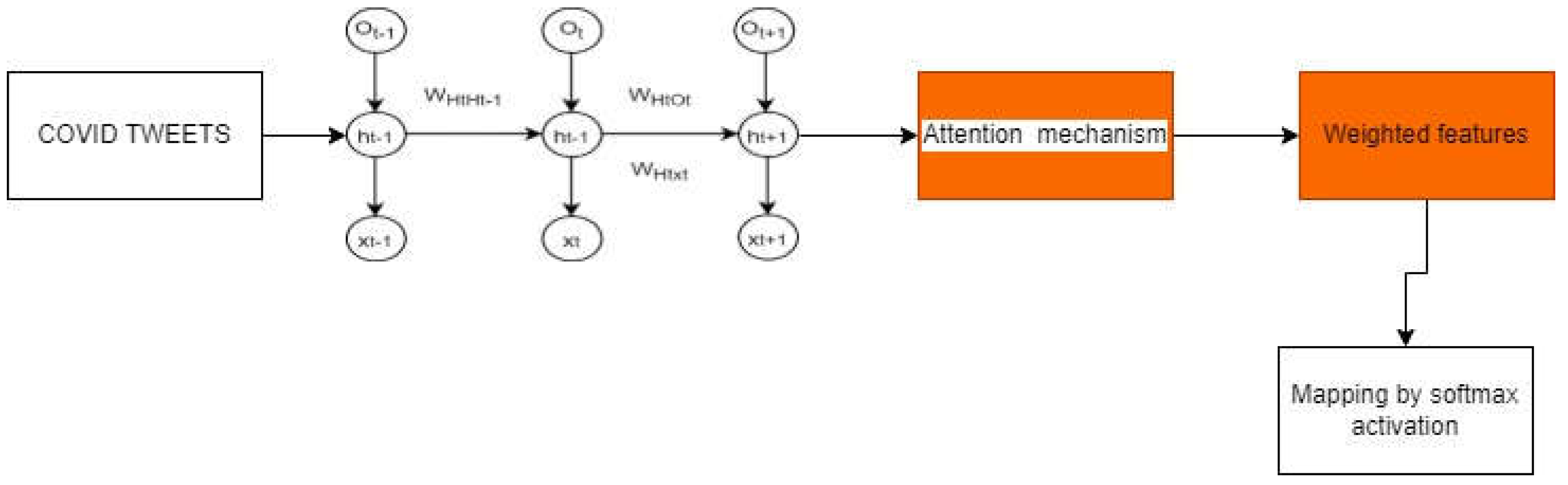
4.3. Additional Steps in LSTM-RNN
4.4. Accuracy
4.5. Precision
4.6. Recall
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chakraborty, K.; Bhatia, S.; Bhattacharyya, S.; Platos, J.; Bag, R.; Hassanien, A. Sentiment analysis of COVID-19 tweets by deep learning classifiers–A study to show how popularity is affecting accuracy in social media. Appl. Soft Comput. 2020, 97, 106754. [Google Scholar] [CrossRef] [PubMed]
- Naw, N. Twitter sentiment analysis using support vector machine and K-NN classifiers. IJSRP 2018, 8, 407–411. [Google Scholar] [CrossRef]
- Bhat, M.; Qadri, M.; Noor-ul Asrar Beg, M.K.; Ahanger, N.; Agarwal, B. Sentiment analysis of social media response on the COVID-19 outbreak. Brain Behav. Immun. 2020, 87, 136–137. [Google Scholar] [CrossRef]
- di Domenico, G.; Sit, J.; Ishizaka, A. Nunan Fake news, social media and marketing: A systematic review. J. Bus. Res. 2021, 124, 329–341. [Google Scholar] [CrossRef]
- Singh, C.; Wibowo, S.; Grandhi, S. An integrated non-linear deep learning method for sentiment classification of online reviews. In Advances in Natural Computation, Fuzzy Systems and Knowledge Discovery; Meng, H., Lei, T., Li, M., Li, K., Xiong, N., Wang, L., Eds.; Springer: Cham, Switzerland, 2020; pp. 1–8. [Google Scholar]
- Wang, Y.; Wang, M.; Xu, W. A sentiment-enhanced hybrid recommender system for movie recommendation: An extensive data analytics framework. Wirel. Commun. Mob. Comput. 2018, 2018, 8263704. [Google Scholar] [CrossRef] [Green Version]
- Pham, D.-H.; Le, A.-C. Learning multiple layers of knowledge representation for aspect-based sentiment analysis. Data Knowl. Eng. 2018, 114, 26–39. [Google Scholar] [CrossRef]
- Aflakparast, M.; de Gunst, M.; van Wieringen, W. Analysis of twitter data with the bayesian fused graphical lasso. PLoS ONE 2020, 15, e0235596. [Google Scholar] [CrossRef]
- Schmidt, A.; Wiegand, M. A survey on hate speech detection using natural language processing. In Proceedings of the Fifth International Workshop on Natural Language Processing for Social Media, Valencia, Spain, 3 April 2017. [Google Scholar]
- Jnoub, N.; Al Machot, F.; Klas, W. A domain-independent classification model for sentiment analysis using neural models. Appl. Sci. 2020, 10, 6221. [Google Scholar] [CrossRef]
- Jianqiang, Z.; Xiaolin, G.; Xuejun, Z. Deep convolution neural networks for twitter sentiment analysis. IEEE Access 2020, 6, 23253–23260. [Google Scholar] [CrossRef]
- Singh, C.; Wibowo, S.; Grandhi, S. A deep learning approach for human face sentiment classification. In Proceedings of the 2021 21st ACIS International Semi-Virtual Winter Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, SNPD-Winter 2021, Ho Chi Minh City, Vietnam, 28–30 January 2021; pp. 28–32. [Google Scholar]
- Han, J.; Qian, K.; Song, M.; Yang, Z.; Ren, Z.; Liu, S.; Li, X. An early study on intelligent analysis of speech under COVID-19: Severity, sleep quality, fatigue, and anxiety. arXiv 2020, arXiv:2005.00096. [Google Scholar]
- Parimala, M.; Priya, R.M.S.; Reddy, M.P.K.; Chowdhary, C.L.; Poluru, R.K.; Khan, S. Spatiotemporal-based sentiment analysis on tweets for risk assessment of event using deep learning approach. Softw. Pract. Exp. 2021, 51, 550–570. [Google Scholar] [CrossRef]
- Li, X.; Rao, Y.; Xie, H.; Lau, R.; Yin, J.; Wang, F. Bootstrapping social emotion classifcation with semantically rich hybrid neural networks. IEEE Trans. Afect. Comput. 2017, 8, 428–442. [Google Scholar] [CrossRef]
- Xiong, S.; Wang, K.; Ji, D.; Wang, B. A short text sentiment-topic model for product reviews. Neurocomputing 2018, 297, 94–102. [Google Scholar] [CrossRef]
- Hassan, A.; Mahmood, A. Convolutional recurrent deep learning model for sentence classification. IEEE Access 2018, 6, 13949–13957. [Google Scholar] [CrossRef]
- Preethi, G.; Krishna, P.; Mohammad, S.; Obaidat, V.; Sartha, V.; Yenduri, S. Application of deep learning to sentiment analysis for recommender system on cloud. In Proceedings of the International Conference on Computer, Information and Telecommunication Systems, Dalian, China, 21–23 July 2017. [Google Scholar]
- Jongeling, R.; Sarkar, P.; Datta, S.; Serebrenik, A. On negative results when using sentiment analysis tools for software engineering research. Empir. Softw. Eng. 2017, 22, 2543–2584. [Google Scholar] [CrossRef] [Green Version]
- Rani, S.; Singh, J. Sentiment analysis of Tweets using support vector machine. Int. J. Comput. Sci. Mob. Appl. 2017, 5, 83–91. [Google Scholar]
- Jagdale, R.S.; Shirsat, V.S.; Deshmukh, S.N. Sentiment analysis on product reviews using machine learning techniques. In Cognitive Informatics and Soft Computing; Springer: Singapore, 2019; pp. 639–647. [Google Scholar]
- Arras, L.; Montavon, G.; Müller, K.R.; Samek, W. Explaining recurrent neural network predictions in sentiment analysis. arXiv 2017, arXiv:1706.07206. [Google Scholar]
- Gupta, I.; Joshi, N. Enhanced Twitter sentiment analysis using hybrid approach and by accounting local contextual semantic. J. Intell. Syst. 2019, 29, 1611–1625. [Google Scholar] [CrossRef]
- Du, J.; Xu, Y.; Song, H.; Tao, C. Leveraging machine learning-based approaches to assess human papilloma virus vaccination sentiment trends with Twitter data. BMC Med. 2017, 17, 69. [Google Scholar]
- Geetha, R.; Karthika, S.; Mohanavalli, S. Tweet classification using deep learning approach to predict sensitive personal data. In Advances in Electrical and Computer Technologies; Springer: Singapore, 2020; pp. 171–180. [Google Scholar]
- Hosseini, H.; Xiao, B.; Jaiswal, M.; Poovendran, R. On the limitation of convolutional neural networks in recognizing negative images. In Proceedings of the 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 352–358. [Google Scholar] [CrossRef] [Green Version]
- Ghimire, S.; Thapa, A.K.; Jha, A.; Kumar, A.; Kumar, A.; Adhikari, S. AI and IoT solutions for tackling COVID-19 pandemic. In Proceedings of the 4th International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 5–7 November 2020; pp. 1083–1092. [Google Scholar]
- Siedlikowski, S.; Noël, L.P.; Moynihan, S.A.; Robin, M. Chloe for COVID-19: Evolution of an intelligent conversational agent to address infodemic management needs during the COVID-19 pandemic. J. Med. Intern. Res. 2021, 23, e27283. [Google Scholar] [CrossRef]
- Dhakal, P.; Damacharla, P.; Javaid, A.Y.; Vege, H.K.; Devabhaktuni, V.K. IVACS: Intelligent voice assistant for coronavirus disease (COVID-19) self-assessment. In Proceedings of the 2020 International Conference on Artificial Intelligence & Modern Assistive Technology (ICAIMAT), Riyadh, Saudi Arabia, 24–26 November 2020; pp. 1–6. [Google Scholar]
- Khan, H.; Kushwah, K.K.; Singh, S.; Urkude, H.; Maurya, M.R.; Sadasivuni, K.K. Smart technologies driven approaches to tackle COVID-19 pandemic: A review. Biotech 2021, 11, 50. [Google Scholar] [CrossRef] [PubMed]
- Mujahid, M.; Lee, E.; Rustam, F.; Washington, P.B.; Ullah, S.; Reshi, A.A.; Ashraf, I. Sentiment analysis and topic modeling on Tweets about online education during COVID-19. Appl. Sci. 2021, 11, 8438. [Google Scholar] [CrossRef]
- Sawik, B.; Płonka, J. Project and prototype of mobile application for monitoring the global COVID-19 epidemiological situation. Int. J. Environ. Res. Public Health 2022, 19, 1416. [Google Scholar] [CrossRef] [PubMed]
- Ilho, R.; Sarmento, R.M.; Holanda, G.B.; Lima, D.D. New approach to detect and classify stroke in skull CT images via analysis of brain tissue densities. Comput. Meth. Prog. Biomed. 2017, 148, 27–43. [Google Scholar]
- Karthik, R.; Gupta, U.; Jha, A.; Rajalakshmi, R.; Menaka, R. A deep supervised approach for ischemic lesion segmentation from multimodal MRI using fully convolutional network. Appl. Soft Comput. 2019, 84, 105685. [Google Scholar] [CrossRef]
- Vijayaprabakaran, K.; Sathiyamurthy, K. Towards activation function search for long short-term model network: A differential evolution-based approach. J. King Saud Uni. Comput. Inform. Sci. 2020; in press. [Google Scholar]
- Rustam, F.; Khalid, M.; Aslam, W.; Rupapara, V.; Mehmood, A.; Choi, G. A performance comparison of supervised machine learning models for Covid-19 tweets sentiment analysis. PLoS ONE 2021, 16, 4–17. [Google Scholar] [CrossRef]
- Dong, X.; de Mel, G. A helping hand: Transfer learning for deep sentiment analysis. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Baboota, R.; Kaur, H. Predictive analysis and modelling football results using machine learning approach for English premier league. Int. J. Forecast. 2019, 35, 741–755. [Google Scholar] [CrossRef]
- Liu, N.; Shen, B.; Zhang, Z.; Zhang, Z.; Mi, K. Attention-based sentiment reasoner for aspect-based sentiment analysis. Hum. Comput. Inform. Sci. 2019, 9, 35. [Google Scholar] [CrossRef]
- Rehman, A.; Malik, B.; Raza; Ali, W. A hybrid CNN-LSTM model for improving accuracy of movie reviews sentiment analysis. Multimed. Tools Appl. 2019, 78, 26597–26613. [Google Scholar] [CrossRef]
- Hernández, A.; Amigó, J.M. Attention mechanisms and their applications to complex systems. Entropy 2021, 23, 283. [Google Scholar] [CrossRef] [PubMed]
- Kardakis, S.; Perikos, I.; Grivokostopoulou, F.; Hatzilygeroudis, I. Examining attention mechanisms in deep learning models for sentiment analysis. Appl. Sci. 2021, 11, 3883. [Google Scholar] [CrossRef]
- Pandey, C.; Rajpoot, D.S.; Saraswat, M. Twitter sentiment analysis using hybrid cuckoo search method. Inform. Process. Manag. 2017, 53, 764–779. [Google Scholar] [CrossRef]
- Depoux, A.; Martin, S.; Karafillakis, E.; Preet, R.; Wilder-Smith, A.; Larson, H. The pandemic of social media panic travels faster than the COVID-19 outbreak. J. Travel Med. 2020, 27, taaa031. [Google Scholar] [CrossRef] [PubMed] [Green Version]


{kind=link}
{kind=link}
{kind=link}
| C | Gamma | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| 0.1 | 1 | 55.12 | 56.23 | 50.12 | 60.12 |
| 1 | 0.1 | 58.12 | 60.13 | 61.23 | 57.23 |
| 10 | 0.01 | 62.13 | 63.12 | 62 | 63 |
| 100 | 0.001 | 60 | 61.23 | 56 | 58 |
| 500 | 0.0001 | 61.23 | 56.12 | 57.12 | 56.23 |
| 1000 | 0.0001 | 60 | 53.22 | 50.12 | 50 |
| 1 | 0.5 | 45.12 | 45.45 | 50 | 53.12 |
| 10 | 0.25 | 34.23 | 56.12 | 52.12 | 54.12 |
| 100 | 0.125 | 52.12 | 53.12 | 52.12 | 55.12 |
| 500 | 0.0625 | 56.23 | 57.23 | 54.23 | 52.12 |
| 1000 | 0.0325 | 57.12 | 54.12 | 51.23 | 54.12 |
| Max Depth | Estimators | min Split | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|---|
| 10 | 200 | 2 | 45.23 | 50.12 | 54.23 | 56.12 |
| 20 | 300 | 5 | 48.12 | 49.23 | 50.12 | 58.12 |
| 30 | 400 | 10 | 60 | 56.22 | 50.12 | 53.23 |
| 40 | 500 | 2 | 54.2 | 57.23 | 49.11 | 50.23 |
| 50 | 600 | 5 | 60 | 61 | 62 | 60 |
| 60 | 700 | 10 | 51.8875 | 53.2 | 50.895 | 54.425 |
| 70 | 800 | 2 | 55.58 | 55.92 | 52.8375 | 55.395 |
| 80 | 900 | 5 | 56.52188 | 56.9125 | 53.03125 | 54.47125 |
| 90 | 1000 | 10 | 55.41688 | 56.8375 | 53.71063 | 55.0125 |
| CNN-Layer | Activation Function | Attention Layers | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|---|
| 4 | Leaky Relu | 1 | 81.23 | 80.23 | 79.12 | 80 |
| 4 | Leaky Relu | 2 | 85.12 | 82.12 | 84.13 | 84.12 |
| 4 | Leaky Relu | 3 | 83.12 | 84.23 | 80.12 | 83.23 |
| 4 | Leaky Relu | 4 | 86.12 | 84.23 | 85.23 | 85.12 |
| 4 | Leaky Relu | 5 | 81.23 | 82.12 | 81.23 | 82.12 |
| 4 | Leaky Relu | 6 | 80.12 | 82.12 | 80 | 79 |
| 4 | Leaky Relu | 7 | 78.12 | 70.23 | 70 | 70 |
| 4 | Leaky Relu | 8 | 80.12 | 80 | 79.12 | 76.12 |
| Convolution Layers | Activation Function | Attention Layers | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|---|
| 4 | TANH | 4 | 83.23 | 80.12 | 80 | 83.12 |
| 4 | Sigmoid | 4 | 84.12 | 83.23 | 82.12 | 80 |
| 4 | RELU | 4 | 84.56 | 82.34 | 82.12 | 81.23 |
| 4 | LEAKY RELU | 4 | 85.12 | 82.12 | 84.13 | 84.12 |
| Epochs | Accuracy | Precision | Recall | Epochs | Accuracy | Precision | Recall |
|---|---|---|---|---|---|---|---|
| 1 | 80.12 | 80.23 | 80.23 | 11 | 82.34 | 81.73678 | 80.17906 |
| 2 | 82.12 | 79.12 | 78.34 | 12 | 83.164 | 81.83814 | 80.49035 |
| 3 | 81.23 | 80 | 80 | 13 | 83.1508 | 81.55977 | 80.38897 |
| 4 | 81.34 | 81.23 | 78 | 14 | 83.15496 | 81.62612 | 80.15883 |
| 5 | 82.34 | 80.45 | 81.2 | 15 | 83.18595 | 81.65663 | 80.18152 |
| 6 | 83 | 81.23 | 82 | 16 | 82.99914 | 81.68349 | 80.21214 |
| 7 | 83.23 | 83.23 | 80 | 17 | 83.13097 | 81.67283 | 80.25251 |
| 8 | 83.13 | 81.228 | 79.96714 | 18 | 84.56 | 82.34 | 82.12 |
| 9 | 83 | 81.4736 | 79.92959 | 19 | 83.40621 | 81.79581 | 80.54347 |
| 10 | 84.12 | 81.52232 | 80.15668 | 20 | 83.45645 | 81.82975 | 80.55106 |
| Classifier | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| Naive Bayes | 67 | 68.12 | 69.23 | 68 |
| Random Forest | 60 | 61 | 62 | 60 |
| SVM | 62.13 | 63.12 | 62 | 63 |
| Logistic Regression | 70.12 | 69.123 | 70 | 67.12 |
| LSTM-RNN | 76.23 | 70.12 | 79.23 | 75.67 |
| Proposed Approach | 84.56 | 82.34 | 82.12 | 81.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singh, C.; Imam, T.; Wibowo, S.; Grandhi, S. A Deep Learning Approach for Sentiment Analysis of COVID-19 Reviews. Appl. Sci. 2022, 12, 3709. https://doi.org/10.3390/app12083709
Singh C, Imam T, Wibowo S, Grandhi S. A Deep Learning Approach for Sentiment Analysis of COVID-19 Reviews. Applied Sciences. 2022; 12(8):3709. https://doi.org/10.3390/app12083709
Chicago/Turabian StyleSingh, Chetanpal, Tasadduq Imam, Santoso Wibowo, and Srimannarayana Grandhi. 2022. "A Deep Learning Approach for Sentiment Analysis of COVID-19 Reviews" Applied Sciences 12, no. 8: 3709. https://doi.org/10.3390/app12083709
APA StyleSingh, C., Imam, T., Wibowo, S., & Grandhi, S. (2022). A Deep Learning Approach for Sentiment Analysis of COVID-19 Reviews. Applied Sciences, 12(8), 3709. https://doi.org/10.3390/app12083709