
Mining the Frequent Patterns of Named Entities for Long Document Classification

Abstract
:1. Introduction
- We present the idea that identifying key information in long documents is the key to classifying such long documents;
- We demonstrate the MIPELD, a model that can extract key information from long document samples, classify them according to key information, and provide the basis for the classification choices;
- Our experimental results on three datasets demonstrate that our method has accurate and robust performance.
2. Related Work
2.1. Machine Learning-Based Methods
2.2. Deep Learning-Based Methods
- The hierarchical structure method [57,58,59]: A long document will be split into multiple parts to fit the length limit, and the representations of the parts are sent into neural networks to construct final representations. A typical model, the HAN [59] proposed by Yang et al., includes two levels of attention mechanisms: word level and sentence level, which allow the model to pay more or less attention to individual words or sentences in constructing the representation of a document.
- Key sentence selection [60]: These approaches aim to select the core parts of the original text instance in an intelligent way to preserve the most relevant elements.
3. Method
3.1. Named Entity Recognition for Semantic Generalization
3.2. Key Feature Mining
3.2.1. The Improved Apriori Algorithm
| Algorithm 1: Apriori algorithm. |
|
3.2.2. The Information Gain
3.3. The Naive Bayesian Classifier
4. Experiments
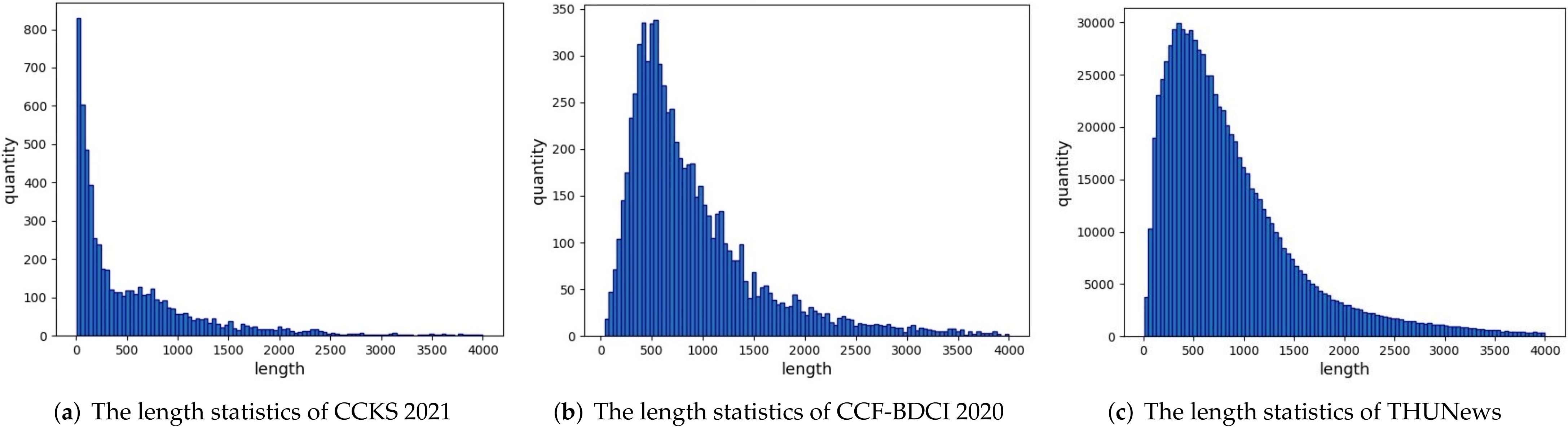
4.1. Dataset and Experimental Settings
4.2. Baseline Methods
4.2.1. Traditional Machine Learning Methods
- K-nearest neighbor (KNN) [21] is a non-parametric classification method that finds the k-nearest neighbors of the text to be classified in the training set, then ranks the candidate types of the text to be classified based on the neighbor types, and finally selects the type with the highest score as the type of text to be classified.
- A support vector machine (SVM) [15] is defined over the vector space where the classification problem is to find the decision surface that “best” separates the data points of one type from the other.
- A decision tree (DT) [27] creates a tree based on the attributes for categorized data points.
- Random forest (RF) [30] is an ensemble learning method for text classification, which uses multiple decision trees.
- Extreme gradient boosting (XGBoost) [34] is an improvement on the gradient boosting decision tree algorithm. It uses a novel regularization technique to control the overfitting.
- Light gradient boosting machine (LGB) [35] is another improvement on the GBDT algorithm. The decision trees in LGB are grown leaf-wise, instead of checking all the previous leaves for each new one.
4.2.2. Deep Learning-Based Methods
- Word2Vec-based classification methods [42] utilize distributed representations of natural words, Word2Vec. Each word in the vocabulary is represented as a vector in a high-dimensional space. Words with similar meanings are close in vector space.
- Doc2Vec-based classification methods [43] employ Doc2Vec to represent the document, which is an unsupervised algorithm that learns vector representations of documents.
- TextCNN [44] applies convolutional neural networks (CNN) with different kernel sizes to extract different features for text classification.
- A recurrent neural network (RNN) [49] is a powerful method for text, string, and sequential data classification by assigning more weights to the previous data points of a sequence.
- Long short-term memory (LSTM) [50] is a special type of RNN that addresses text classification by preserving long term dependency in a more effective way in comparison to the basic RNN.
- BiLSTM [63] is built on LSTM, adding a backward LSTM, to encode information from back to front to obtain the semantics of the full text.
- HAN [59] is a hierarchical attention network for document classification. The HAN constructs word-level and sentence-level features, respectively. The attention mechanism is applied to assign weights to different words and sentences.
- BERT [57] is a pre-trained language model proposed by Google that extracts the semantics of texts. When dealing with long documents, we use truncation methods to get tokens for BERT.
4.3. Experiments Results
4.3.1. Main Results
4.3.2. Time Consumption Analysis
4.4. Ablation Experiments
4.4.1. About Named Entity Label Replacement
4.4.2. About the Improved Apriori Algorithm
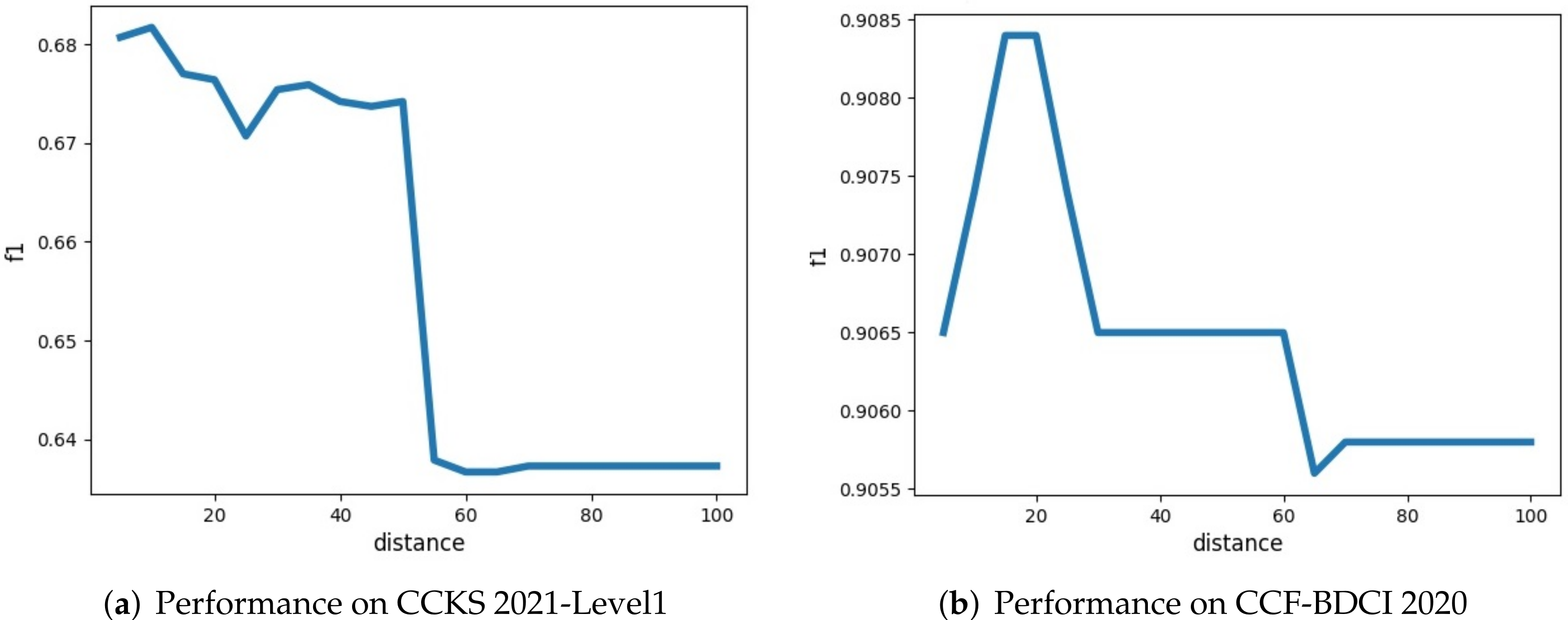
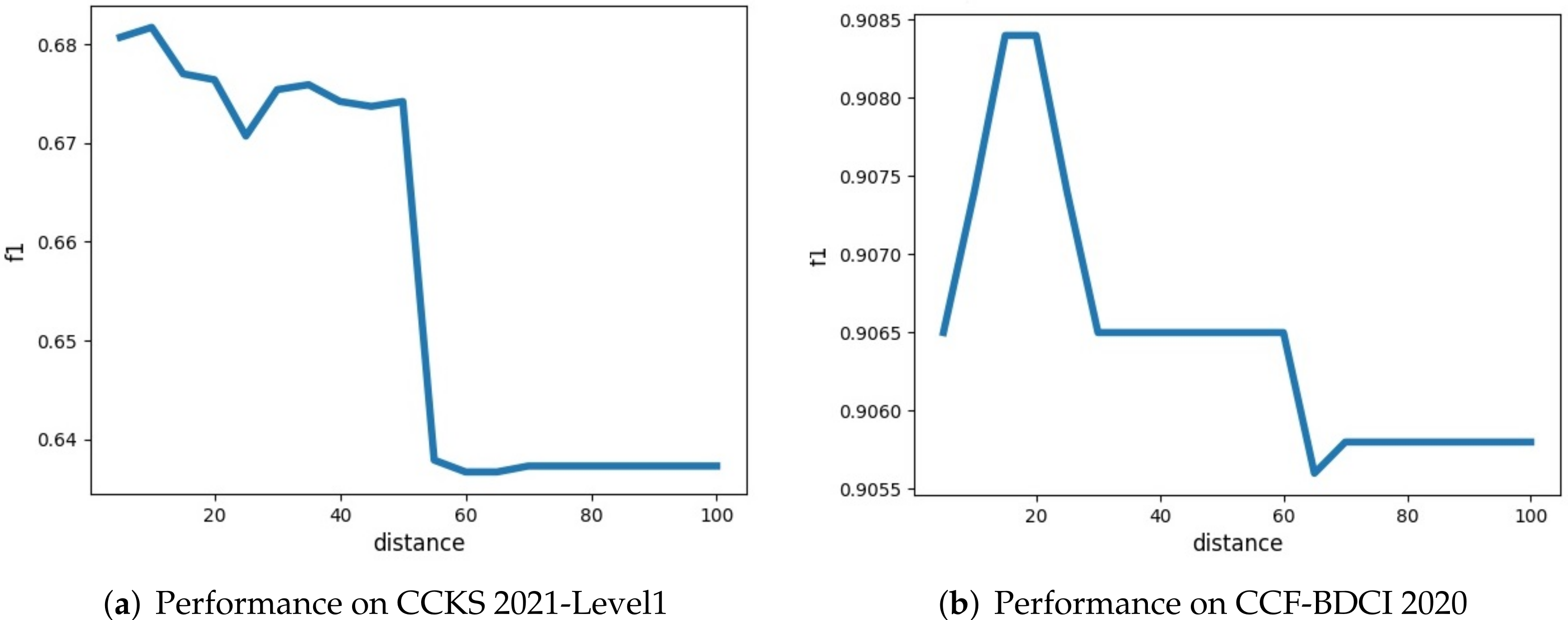
4.4.3. About the Distance Constraint Function
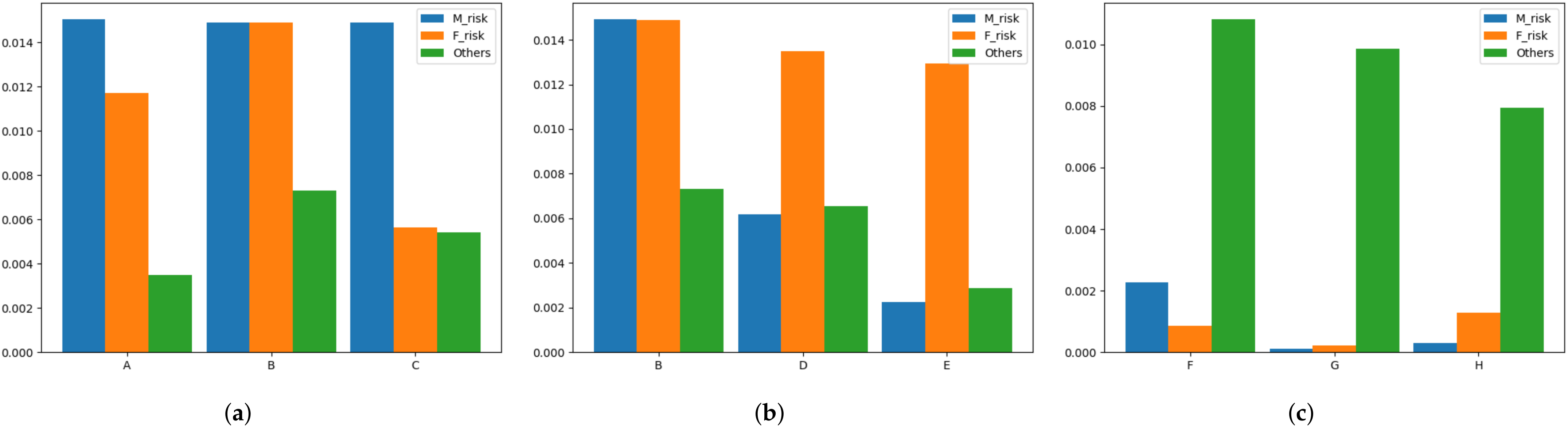
4.5. Case Study
4.5.1. Classification Results Visualization
4.5.2. Feature Weights’ Contributions Visualization
4.6. Analysis Experiments
4.6.1. The Effectiveness of the Distance Constraint
4.6.2. The Effectiveness of the Semantic Generalization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jang, B.; Kim, I.; Kim, J.W. Word2vec convolutional neural networks for classification of news articles and tweets. PLoS ONE 2019, 14, e0220976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bai, J.; Shim, I.; Park, S. MEXN: Multi-Stage Extraction Network for Patent Document Classification. Appl. Sci. 2020, 10, 6229. [Google Scholar] [CrossRef]
- Wang, X.; Tong, Y. Application of an emotional classification model in e-commerce text based on an improved transformer model. PLoS ONE 2021, 16, e0247984. [Google Scholar] [CrossRef] [PubMed]
- Moon, S.; Lee, G.; Chi, S. Semantic text-pairing for relevant provision identification in construction specification reviews. Autom. Constr. 2021, 128, 103780. [Google Scholar] [CrossRef]
- Venkataraman, G.R.; Pineda, A.L.; Bear Don’t Walk IV, O.J.; Zehnder, A.M.; Ayyar, S.; Page, R.L.; Bustamante, C.D.; Rivas, M.A. FasTag: Automatic text classification of unstructured medical narratives. PLoS ONE 2020, 15, e0234647. [Google Scholar] [CrossRef]
- Zhang, X.; LeCun, Y. Which encoding is the best for text classification in chinese, english, japanese and korean? arXiv 2017, arXiv:1708.02657. [Google Scholar]
- Ling, W.; Tsvetkov, Y.; Amir, S.; Fermandez, R.; Dyer, C.; Black, A.W.; Trancoso, I.; Lin, C.C. Not all contexts are created equal: Better word representations with variable attention. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Pittsburgh, PA, USA, 17–21 September 2015; pp. 1367–1372. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. Adv. Neural Inf. Process. Syst. 2015, 28, 649–657. [Google Scholar]
- Ke, W.J.; Wu, C.; Fu, X.F.; Gao, C.; Song, Y.Y. Interpretable Test Case Recommendation based on Knowledge Graph. In Proceedings of the 2020 International Conference on Software Quality (QRS), Macau, China, 11–14 December 2020; IEEE: Macau, China, 2020; pp. 489–496. [Google Scholar]
- Heckerman, D. Bayesian networks for data mining. Data Min. Knowl. Discov. 1997, 1, 79–119. [Google Scholar] [CrossRef]
- Chen, J.; Huang, H.; Tian, S.; Qu, Y. Feature selection for text classification with Naïve Bayes. Expert Syst. Appl. 2009, 36, 5432–5435. [Google Scholar] [CrossRef]
- Kim, S.B.; Han, K.S.; Rim, H.C.; Myaeng, S.H. Some effective techniques for naive bayes text classification. IEEE Trans. Knowl. Data Eng. 2006, 18, 1457–1466. [Google Scholar]
- McCallum, A.; Nigam, K. A comparison of event models for naive bayes text classification. In AAAI-98 Workshop on Learning for Text Categorization; Citeseer: Princeton, NJ, USA, 1998; Volume 752, pp. 41–48. [Google Scholar]
- Qu, Z.; Song, X.; Zheng, S.; Wang, X.; Song, X.; Li, Z. Improved Bayes method based on TF-IDF feature and grade factor feature for chinese information classification. In Proceedings of the 2018 IEEE International Conference on Big Data and Smart Computing (BigComp), Shanghai, China, 15–17 January 2018; IEEE: Shanghai, China, 2018; pp. 677–680. [Google Scholar]
- Vapnik, V.; Chervonenkis, A.Y. A class of algorithms for pattern recognition learning. Avtomat. Telemekh 1964, 25, 937–945. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Haddoud, M.; Mokhtari, A.; Lecroq, T.; Abdeddaïm, S. Combining supervised term-weighting metrics for SVM text classification with extended term representation. Knowl. Inf. Syst. 2016, 49, 909–931. [Google Scholar] [CrossRef]
- Kim, H.; Howland, P.; Park, H.; Christianini, N. Dimension reduction in text classification with support vector machines. J. Mach. Learn. Res. 2005, 6, 37–53. [Google Scholar]
- Wang, Z.Q.; Sun, X.; Zhang, D.X.; Li, X. An optimal SVM-based text classification algorithm. In Proceedings of the 2006 International Conference on Machine Learning and Cybernetics, Dalian, China, 13–16 August 2006; IEEE: Dalian, China, 2006; pp. 1378–1381. [Google Scholar]
- Goudjil, M.; Koudil, M.; Bedda, M.; Ghoggali, N. A novel active learning method using SVM for text classification. Int. J. Autom. Comput. 2018, 15, 290–298. [Google Scholar] [CrossRef]
- Fix, E.; Hodges, J.L. Discriminatory analysis. Nonparametric discrimination: Consistency properties. Int. Stat. Rev. Int. Stat. 1989, 57, 238–247. [Google Scholar] [CrossRef]
- Lu, L.R.; Fa, H.Y. A Density-Based Method for Reducing the Amount of Training Data in kNN Text Classification. J. Comput. Res. Dev. 2004, 41, 539–545. [Google Scholar]
- Wandabwa, H.; Zhang, D.; Sammy, K. Text categorization via attribute distance weighted k-nearest neighbor classification. In Proceedings of the 2016 International Conference on Information Technology (ICIT), Bhubaneswar, India, 22–24 December 2016; IEEE: Bhubaneswar, India, 2016; pp. 225–228. [Google Scholar]
- Han, E.H.S.; Karypis, G.; Kumar, V. Text categorization using weight adjusted k-nearest neighbor classification. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Minneapolis, MN, USA, 2001; pp. 53–65. [Google Scholar]
- Jiang, S.; Pang, G.; Wu, M.; Kuang, L. An improved K-nearest-neighbor algorithm for text categorization. Expert Syst. Appl. 2012, 39, 1503–1509. [Google Scholar] [CrossRef]
- Chen, S. K-nearest neighbor algorithm optimization in text categorization. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2018; Volume 108, p. 052074. [Google Scholar]
- Hormann, A.M. Programs for machine learning Part I. Inf. Control. 1962, 5, 347–367. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Wang, Z.O. Text categorization rule extraction based on fuzzy decision tree. In Proceedings of the 2005 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18–21 August 2005; IEEE: Guangzhou, China, 2005; Volume 4, pp. 2122–2127. [Google Scholar]
- Bahassine, S.; Madani, A.; Kissi, M. An improved Chi-sqaure feature selection for Arabic text classification using decision tree. In Proceedings of the 2016 11th International Conference on Intelligent Systems: Theories and Applications (SITA), Mohammedia, Morocco, 19–20 October 2016; pp. 1–5. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Parmar, H.; Bhanderi, S.; Shah, G. Sentiment mining of movie reviews using Random Forest with Tuned Hyperparameters. In Proceedings of the International Conference on Information Science, Seoul, Korea, 6–9 May 2014; pp. 1–6. [Google Scholar]
- Xu, B.; Guo, X.; Ye, Y.; Cheng, J. An Improved Random Forest Classifier for Text Categorization. J. Comput. 2012, 7, 2913–2920. [Google Scholar] [CrossRef] [Green Version]
- Islam, M.Z.; Liu, J.; Li, J.; Liu, L.; Kang, W. A semantics aware random forest for text classification. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1061–1070. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; 30. [Google Scholar]
- Guzella, T.S.; Caminhas, W.M. A review of machine learning approaches to spam filtering. Expert Syst. Appl. 2009, 36, 10206–10222. [Google Scholar] [CrossRef]
- Dwivedi, S.K.; Arya, C. Automatic text classification in information retrieval: A survey. In Proceedings of the Second International Conference on Information and Communication Technology for Competitive Strategies, Udaipur, India, 4–5 May 2016; pp. 1–6. [Google Scholar]
- Lin, C.Y.; Hovy, E. Automatic evaluation of summaries using n-gram co-occurrence statistics. In Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, Edmonton, AB, Canada, 27 May 2003; pp. 150–157. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on Machine Learning, PMLR, China, Bejing, 22–24 June 2014; pp. 1188–1196. [Google Scholar]
- Altowayan, A.A.; Tao, L. Word embeddings for Arabic sentiment analysis. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; IEEE: Washington, DC, USA, 2016; pp. 3820–3825. [Google Scholar]
- Dogru, H.B.; Tilki, S.; Jamil, A.; Hameed, A.A. Deep learning-based classification of news texts using doc2vec model. In Proceedings of the 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 91–96. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25 August 2014. [Google Scholar]
- Pang, B.; Lee, L. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Ann Arbor, MI, USA, 25–30 June 2005. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- Keeling, R.; Chhatwal, R.; Huber-Fliflet, N.; Zhang, J.; Wei, F.; Zhao, H.; Shi, Y.; Qin, H. Empirical Comparisons of CNN with Other Learning Algorithms for Text Classification in Legal Document Review. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 2038–2042. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classification with multi-task learning. arXiv 2016, arXiv:1605.05101. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Miwa, M.; Bansal, M. End-to-end relation extraction using lstms on sequences and tree structures. arXiv 2016, arXiv:1601.00770. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune bert for text classification. In China National Conference on Chinese Computational Linguistics; Springer: Hohhot, China, 2019; pp. 194–206. [Google Scholar]
- Akbik, A.; Bergmann, T.; Blythe, D.; Rasul, K.; Schweter, S.; Vollgraf, R. FLAIR: An easy-to-use framework for state-of-the-art NLP. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), Minneapolis, MN, USA, 2–7 June 2019; pp. 54–59. [Google Scholar]
- Adhikari, A.; Ram, A.; Tang, R.; Lin, J. Docbert: Bert for document classification. arXiv 2019, arXiv:1904.08398. [Google Scholar]
- Mulyar, A.; Schumacher, E.; Rouhizadeh, M.; Dredze, M. Phenotyping of clinical notes with improved document classification models using contextualized neural language models. arXiv 2019, arXiv:1910.13664. [Google Scholar]
- Zhang, R.; Wei, Z.; Shi, Y.; Chen, Y. BERT-AL: BERT for Arbitrarily Long Document Understanding. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Min, S.; Zhong, V.; Socher, R.; Xiong, C. Efficient and robust question answering from minimal context over documents. arXiv 2018, arXiv:1805.08092. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. 2016. Available online: http://xxx.lanl.gov/abs/1603.01360 (accessed on 13 January 2022).
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago de Chile, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
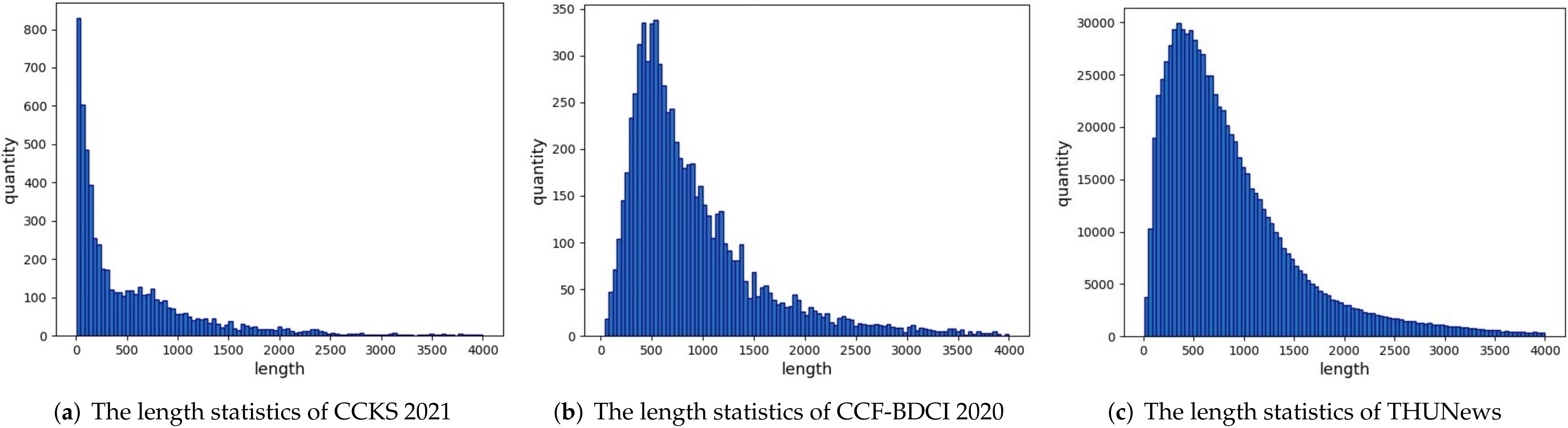
| Dataset | Texts | Classes | Train | Test |
|---|---|---|---|---|
| CCKS 2021-Level1 | 6000 | 3 | 4800 | 1200 |
| CCKS 2021-Level2 | 6000 | 8 | 4800 | 1200 |
| CCF-BDCI 2020 | 7320 | 10 | 5856 | 1464 |
| THUNews | 836,075 | 14 | 668,860 | 167,215 |
| Model | CCKS 2021-Level1 | CCKS 2021-Level2 | CCF-BDCI 2020 | THUNews | ||||
|---|---|---|---|---|---|---|---|---|
| ACC (%) | Macro-F1 (%) | ACC (%) | Macro-F1 (%) | ACC (%) | Macro-F1 (%) | ACC (%) | Macro-F1 (%) | |
| KNN | 59.75 | 38.48 | 42.92 | 31.79 | 88.52 | 87.26 | 84.85 | 82.95 |
| RandomForest | 84.58 | 56.55 | 52.25 | 39.38 | 88.80 | 88.00 | 81.01 | 72.04 |
| DT | 80.42 | 53.76 | 50.16 | 42.26 | 86.48 | 85.68 | 81.61 | 77.66 |
| SVM | 89.25 | 59.70 | 55.67 | 41.54 | 91.39 | 90.38 | 85.41 | 70.82 |
| XGBoost | 89.19 | 61.38 | 62.17 | 52.26 | 88.91 | 88.61 | 82.83 | 84.36 |
| LGB | 90.42 | 63.12 | 61.84 | 54.13 | 89.92 | 90.81 | 84.59 | 85.69 |
| Word2Vec | 71.42 | 50.80 | 38.50 | 30.94 | 80.19 | 77.82 | 70.36 | 62.87 |
| Doc2Vec | 80.17 | 53.91 | 50.08 | 42.12 | 89.84 | 88.34 | 85.57 | 83.13 |
| RNN | 85.50 | 57.17 | 38.60 | 25.27 | 75.27 | 69.63 | 78.40 | 63.98 |
| TextCNN | 89.40 | 59.73 | 58.40 | 46.39 | 86.58 | 84.17 | 92.41 | 90.67 |
| UniLSTM | 88.60 | 59.26 | 46.30 | 33.96 | 55.27 | 42.21 | 84.56 | 66.22 |
| BiLSTM | 89.20 | 59.67 | 61.80 | 52.09 | 88.01 | 86.50 | 93.05 | 90.44 |
| HAN | 74.73 | 50.15 | 44.87 | 36.47 | 70.75 | 51.88 | 90.36 | 87.27 |
| BERT | 92.70 | 66.96 | 37.80 | 16.56 | 30.74 | 20.85 | 50.63 | 48.84 |
| MIPELD | 89.42 | 68.17 | 62.33 | 55.11 | 92.01 | 90.84 | 87.97 | 85.88 |
| Model | Training | Inference |
|---|---|---|
| KNN | 1.26 s | 10.98 s |
| RandomForest | 2.98 s | 2.35 s |
| DT | 4.08 s | 0.78 s |
| SVM | 16.72 s | 6.26 s |
| XGBoost | 29.62 s | 4.90 s |
| LGB | 22.17 s | 5.10 s |
| Word2Vec | 36.13 s | 26.01 s |
| Doc2Vec | 106.21 s | 28.80 s |
| RNN | 59 min | 7 min |
| TextCNN | 73 min | 9 min |
| UniLSTM | 60 min | 7 min |
| BiLSTM | 82 min | 10 min |
| HAN | 89 min | 5 min |
| BERT | 102 min | 13 min |
| MIPELD | 33.09 s | 8.12 s |
| Model | CCKS 2021-Level1 | CCKS 2021-Level2 | CCF-BDCI 2020 | THUNews | ||||
|---|---|---|---|---|---|---|---|---|
| Macro-F1 (%) | Decline↓(%) | Macro-F1 (%) | Decline↓(%) | Macro-F1 (%) | Decline↓(%) | Macro-F1 (%) | Decline↓(%) | |
| MIPELD | 68.17 | - | 55.11 | - | 90.84 | - | 87.96 | - |
| w/o NER | 66.27 | 1.90 | 54.54 | 0.57 | 90.66 | 0.18 | 86.88 | 1.08 |
| w/o Apriori | 63.31 | 4.86 | 52.98 | 2.13 | 90.46 | 0.38 | 82.36 | 5.60 |
| w/o Distance | 63.73 | 4.44 | 53.87 | 1.24 | 90.59 | 0.25 | 85.78 | 2.11 |
| Class | Dataset | Frequent Itemsets Feature | Key Sentence | Original Texts |
|---|---|---|---|---|
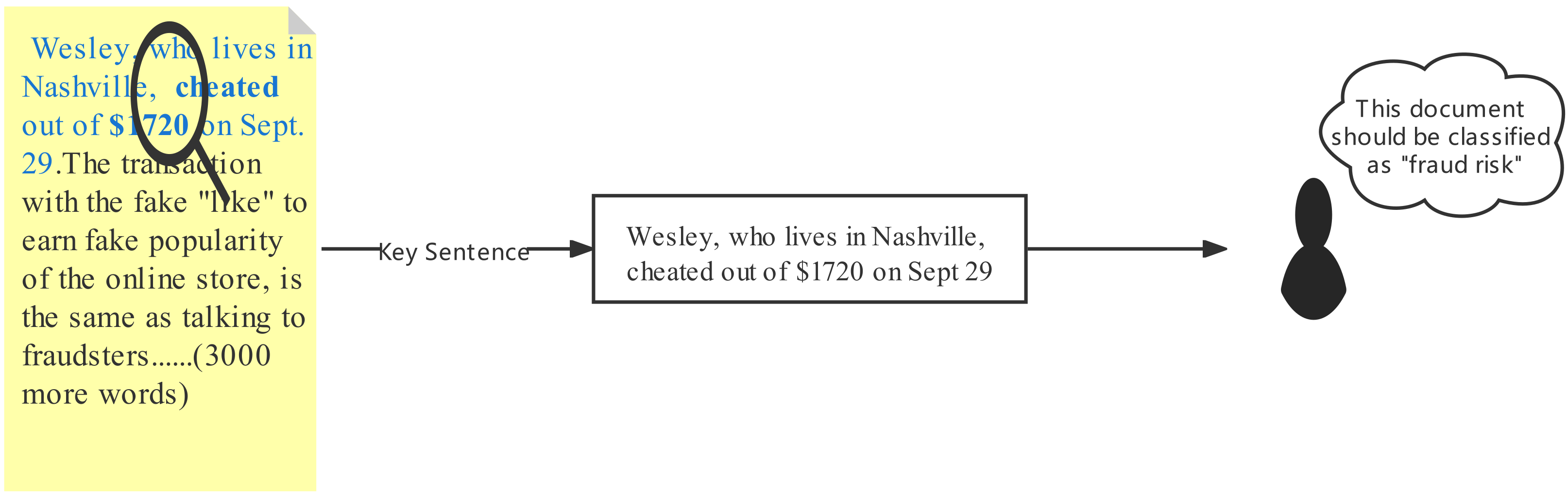
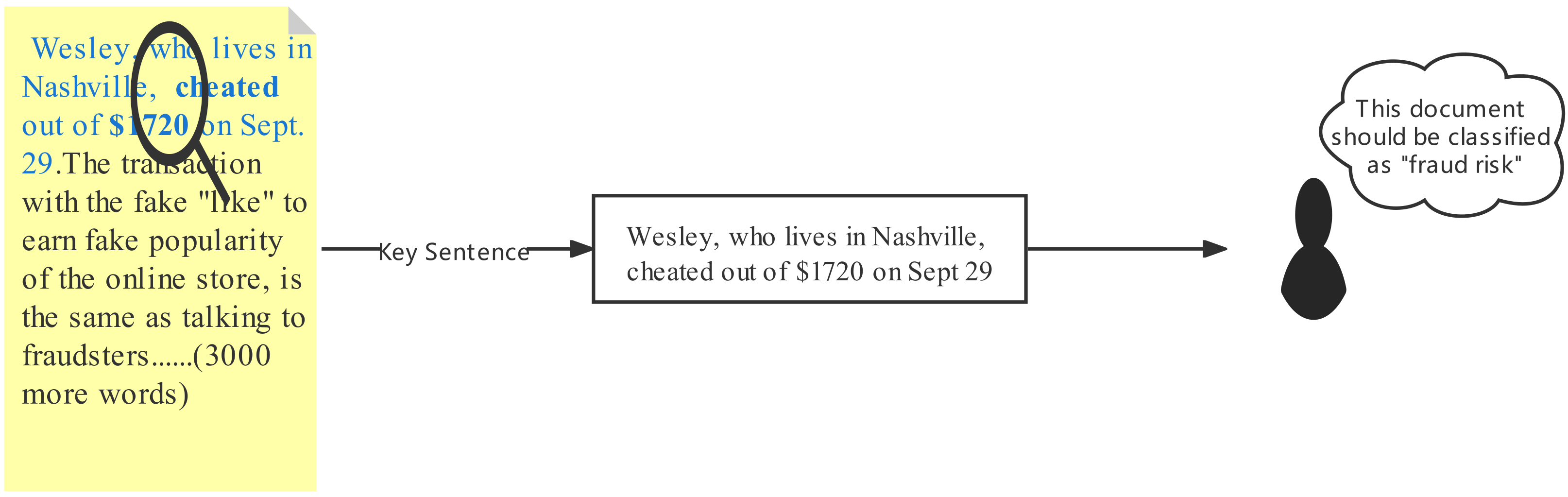
| Fraud risk | CCKS 2021-Level1 | “[name], [money], cheat” | [name], who lives in Nashville, was cheated out of [money] on 29 September. | Wesley, who lives in Nashville, was cheated out of on 29 September. The transaction with the fake “like” to earn fake popularity of the online store, is the same as talking to fraudsters…(3000 more words) |
| Part-time click farming | CCKS 2021-Level2 | “[name], click farming”, “[name], [money], cheat” | In the [time], [name] saw an ad in a chat group, advertising that there is a software can make a profit by part-time click farming,…, So in the end [name] was cheated out of a total of [money] | In the afternoon of 5 September 2019, Larry saw an ad in a chat group, advertising that there is a software can make a profit by part-time click farming,…, So in the end Larry was cheated out of a total of $29,686. |
| Sports | CCF-BDCI 2020 | “[name], medalist, [time]” | On [time], [name], the bronze medalist in the singles men’s table tennis at the Rio Olympics, posted that he had resumed training. | On 22 September, Jun Mizutani, the bronze medalist in the singles men’s table tennis at the Rio Olympics, posted that he had resumed training…(500 more words). |
| Lottery | THUNews | “lottery, [time], [address]” | Lottery winner may have hit $80m jackpot–china’s lottery may have set a new record with a man expected to win 514 million yuan ($80 million) from two tickets bought in East China’s [address] on [time]. | Lottery winner may have hit $80m jackpot–china’s lottery may have set a new record with a man expected to win 514 million yuan ($80 million) from two tickets bought in East China’s Zhejiang Proince on Tuesday...(600 more words). |
| Class | Original Sentences | Interpretability |
|---|---|---|
| Misappropriation risk | On 18 January 2019, Young, who worked in an auto equipment manufacturing company in Wuhu City, verbally reported to the police that he had identity theft on their credit card and $2900 was spent in their account…(1700 more words) | On [time], [name], who worked in an auto equipment manufacturing company in [address], verbally reported to the police that he had identity theft on their credit card and [money] was spent in their account. |
| Fraud risk | Wesley, who lives in Nashville, cheated out of on 29 September. The transaction with the fake “like” to earn fake popularity of the online store, is the same as talking to fraudsters…(3000 more words) | [name], who lives in Nashville, was cheated out of [money] on 29 September. |
| Others | From February 2018 to April 2018, Cai used their cell phone for profit, disseminated obscene electronic information through online chat and other forms, disseminated more than 80 obscene videos and more than 200 obscene pictures, and made a profit of more than $9000. He was accused of spreading obscene materials…(1500 more words) | From [time] to [time], [name] used their cell phone for profit, disseminated obscene electronic information through online chat and other forms, disseminated more than 80 obscene videos and more than 200 obscene pictures, and made a profit of more than $9000. He was accused of spreading obscene materials. |
| Replaced Entities | Feature Vector Dimensions | ACC (%) | Macro-F1 (%) |
|---|---|---|---|
| w/o NER | 1227 | 89.33 | 66.27 |
| organization | 1216 | 89.33 | 67.64 |
| organization, money, address | 1117 | 89.37 | 68.11 |
| organization, money, name, address, time | 1115 | 89.42 | 68.17 |
| organization, money, name, address, time, job | 1113 | 88.83 | 67.32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, B.; Qi, R.; Gao, J.; Zhang, J.; Yuan, X.; Ke, W. Mining the Frequent Patterns of Named Entities for Long Document Classification. Appl. Sci. 2022, 12, 2544. https://doi.org/10.3390/app12052544
Wang B, Qi R, Gao J, Zhang J, Yuan X, Ke W. Mining the Frequent Patterns of Named Entities for Long Document Classification. Applied Sciences. 2022; 12(5):2544. https://doi.org/10.3390/app12052544
Chicago/Turabian StyleWang, Bohan, Rui Qi, Jinhua Gao, Jianwei Zhang, Xiaoguang Yuan, and Wenjun Ke. 2022. "Mining the Frequent Patterns of Named Entities for Long Document Classification" Applied Sciences 12, no. 5: 2544. https://doi.org/10.3390/app12052544
APA StyleWang, B., Qi, R., Gao, J., Zhang, J., Yuan, X., & Ke, W. (2022). Mining the Frequent Patterns of Named Entities for Long Document Classification. Applied Sciences, 12(5), 2544. https://doi.org/10.3390/app12052544