1. Introduction
With the fourth Industrial Revolution, the application of artificial intelligence technology is expanding in the medical field [
1,
2,
3,
4,
5,
6]. The biggest obstacle to the collaboration of medical data from distinct institutes has been the protection the private information contained in the distributed system. In particular, federate learning is in the spotlight as a distributed machine learning technique that can simultaneously retain privacy and efficiency [
7]. It can produce a similar result to learning all data at once without sharing private data. Since federated learning does not centralize data to a big server, it can protect the private information of each user. Currently, it is being applied to several areas, including health care, smart factories, and finance [
8,
9,
10,
11,
12,
13]. Major companies such as Google and NVIDIA have been conducting research on medical artificial intelligence through the development of their own federated learning algorithms [
8,
9,
10].
Linear block codes have been investigated for applications in several areas of engineering, such as communication systems, cryptography, and security [
14]. A minimal code is a block code in which the support of a codeword is not included in that of any other codewords [
15]. Using the minimal code, one user’s information is not subordinate to other users’ information. This has been constantly studied as one of the mathematical structures that can be used in secret-sharing schemes [
16,
17,
18,
19,
20,
21,
22,
23]. Furthermore, a minimal code can be used in federated learning due to its distributed characteristics of secret information. Almost all the known minimal codes so far have been designed based on the structure and characteristics of finite fields [
24]. In particular, for binary cases, several design methods have been proposed [
16,
17,
18,
19,
20]. On the other hand, non-binary minimal code has been investigated recently [
21,
22,
23]. Research on previously known minimal codes has focused only on the weight distribution of the codes. Considering recent applications, further characteristics or structures of minimal codes, such as their error-correction capability and relation to the learning rate, should be investigated.
In this paper, we propose a framework for secret codes in application to distributed systems. Then, we provide new methods to construct such codes using the synthesis or decomposition of previously known minimal codes. The numerical results show that new constructions can generate codes with more flexible parameters than original constructions in the sense of the number of possible weights and the range of weights. The secret codes from new constructions may be applied to more general situations or environments in distributed systems.
The remainder of this paper is organized as follows. In
Section 2, we present some preliminaries on secret-sharing schemes, finite fields, and minimal codes. We present design methods for secret codes, and propose a framework for the application of designed codes to distributed learning systems in
Section 3. We provide the results of our construction in
Section 4, and then compare them with the previous researches in
Section 5. Finally, we present concluding remarks in
Section 6.
2. Preliminaries
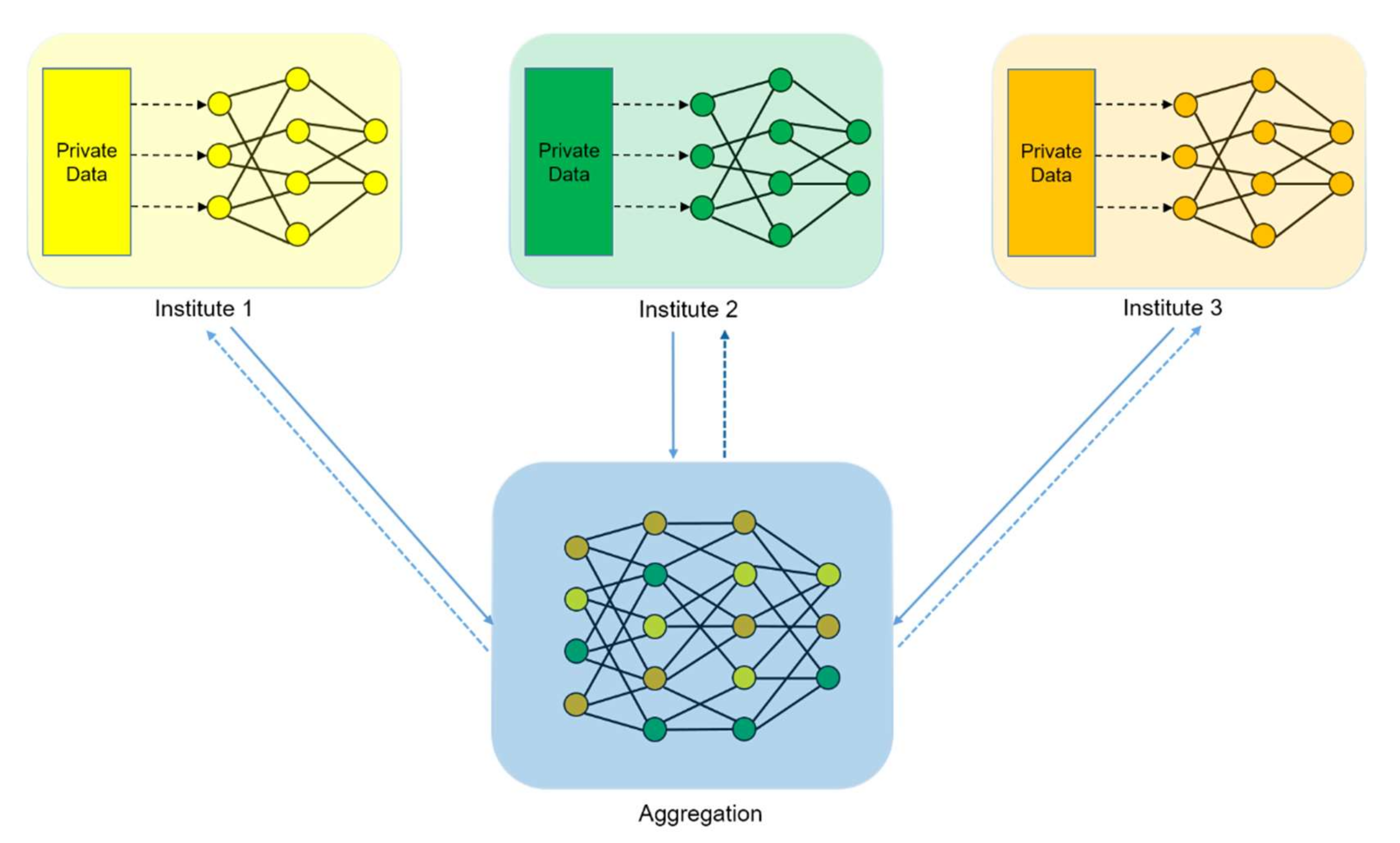
In the distributed learning schemes depicted in
Figure 1, the distribution of secret or private information is very important in order to retain secret properties. Linear block codes can be used as a mathematical tool to design such distribution strategies [
17,
18]. In this section, we present some preliminary knowledge on finite fields and algebraic codes that are used in secret-sharing schemes.
Minimal codes are a class of linear block codes, in which the support of a codeword is not included to that of another codeword. A binary linear block code
of length
is a subspace of vectors in the space
. An element of a linear block code is called a codeword. A codeword
of length
in a binary linear block code can be expressed as
where
represent the index of each symbol, and
is the set of integers modulo
. Because a linear block code is a subspace, the vector addition of any two codewords in a code is included as another codeword in the code. The support of
is a subset of
, which is defined as
The size of
is called the Hamming weight of
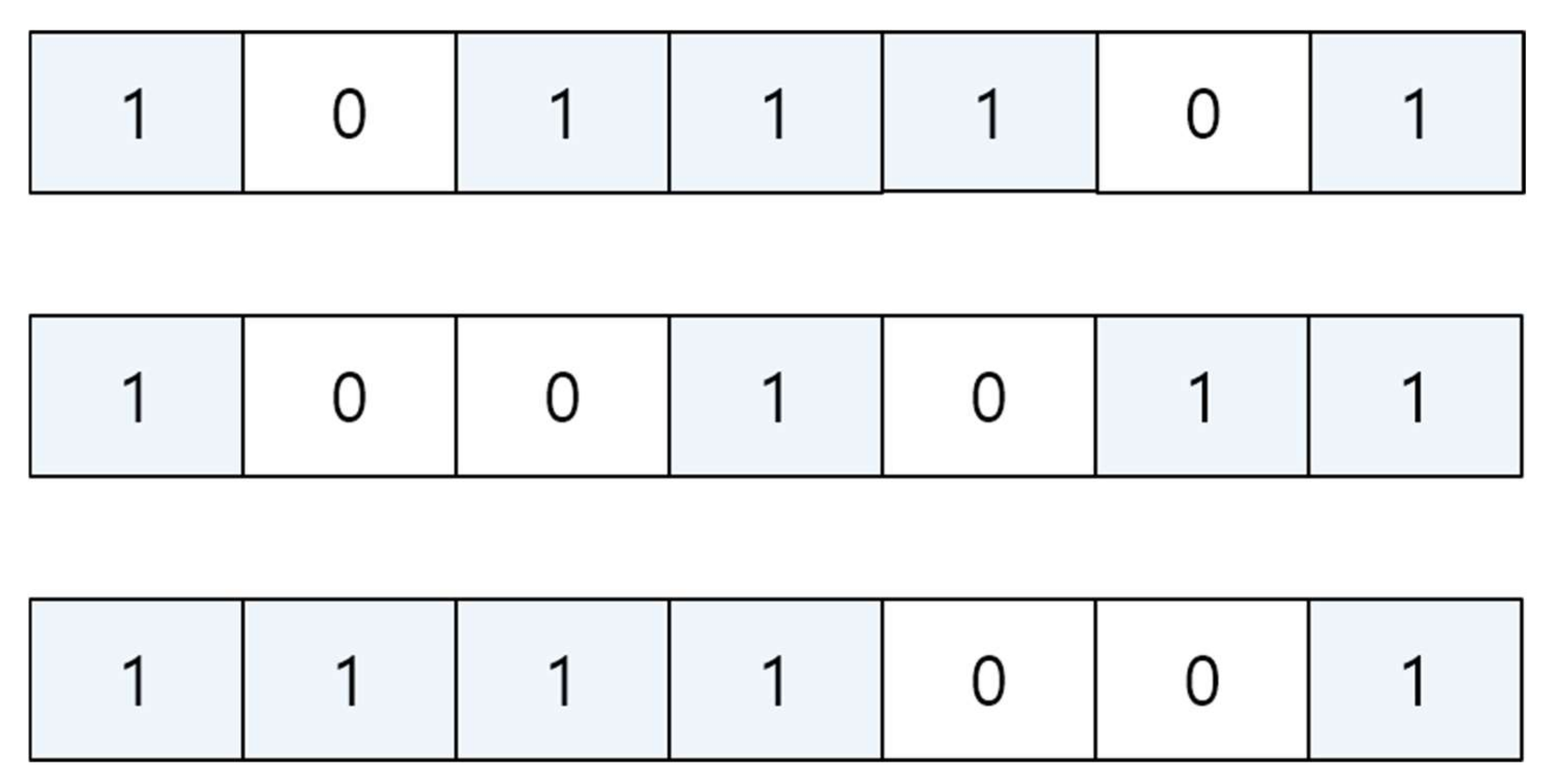
. In secret-sharing schemes, a secret codeword is assigned to a user or a device. Information in the codeword should not be subordinate to any other codewords. A minimal code is defined as a linear block code in which the support of a codeword is not a subset of the support of any other codeword, as shown in
Figure 2. Using this characteristic, secret information can be distributed to users, and the information of a user is not fully revealed to the other users. Due to this characteristic, minimal codes have been applied to secret-sharing schemes [
15,
17]. However, in distributed learning, the secret-storing structure is important, as is the weight distribution of a code. Research on analytic approaches to the structure is ongoing.
A secret-sharing scheme is, from a mathematical viewpoint, constructed on a finite field. A finite field is an algebraic structure in which addition, subtraction, multiplication, and division can be freely operated [
24]. For a prime
and a positive integer
, a finite field
consists of the additive identity
and
, where
is called a primitive element of
. The finite field
is an Abelian group with respect to the addition modulo
, and
is a cyclic group with respect to the multiplication. Any element of a finite field can be represented not only in a multiplicative way using the power of the primitive element, but also in an additive way using vector representation on the basis
. Note that
can be interpreted as a vector space of dimension
over
. Most of the well-known error-correction codes and pseudorandom sequences have been constructed based on the properties of finite fields [
14]. In this paper, we assume that
, which corresponds to the cases of binary codes. Because most machine learning algorithms are based on the binary operation, the assumption is appropriate.
In a secret-sharing scheme defined on
, a secret corresponds to an element of the finite field. Let
be users or devices engaged in the scheme. Pieces of the secret are assigned to each user using a secret code. This secret information must be encoded so that the whole information is not synthesized from any proper subset of information of users. Moreover, in a partial group of users, if a user can recover some part of the secret, the other user should also be able to recover the same information. Minimal codes are good mathematical structures to apply to various kinds of secret-sharing schemes due to their linearity and the non-inclusive properties of supports. A minimal code can be parameterized by the length of codewords, the number of codewords, and the weight distribution. The length means the number of information indices, the number of codewords corresponds to the number of users or devices, and the weight distribution is related to the placement of information. In
Table 1, some well-known constructions for minimal codes are summarized. Recently, Mesnager et al. presented a generalized construction tool including several existing design methods [
23]. Since most of known minimal codes are designed using the structure of
, their lengths are restricted to
for a prime
.
In [
16], Aschkmin and Barg established a sufficient condition on the existence of minimal codes as in the following theorem.
Theorem 1. [
16]
A linear code defined over a finite field of characteristic becomes a minimal code ifwhere(resp.) is the minimum (resp. maximum) value among the Hamming weights of the codewords of.
Note that the ratio between the minimum and the maximum weights refers to the possible range of information throughput or performance of each device that the system can accommodate. Although the inequality (1) provides an efficient guideline for designing a minimal code, it also restricts the range of selection of Hamming weights, which is closely related to the flexibility of information distribution in learning data. Recently, some constructions which are not restricted in (1) have been presented [
20,
22], as shown in
Table 1. These constructions can provide flexibility in the selection of amounts of information according to distinct users.
3. Design of Secret Codes for Distributed Systems
The authors of [
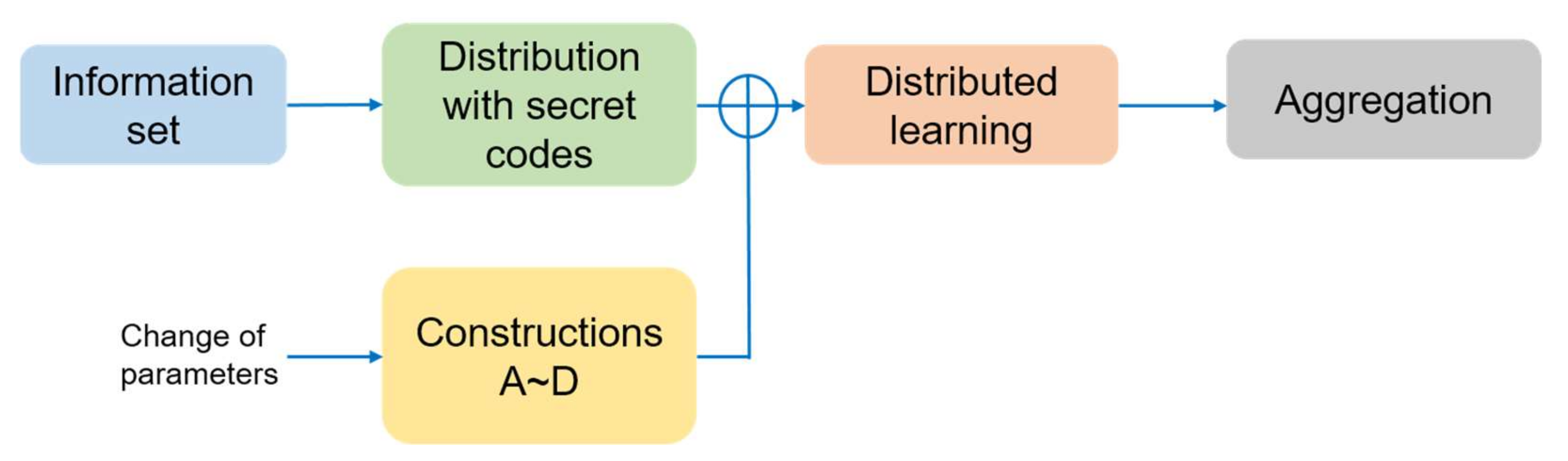
12] summarized the federated learning structure for health care systems sharing data. In this section, we consider a framework for a group of users or institutions with secret information. If a group of users or participants in the distributed learning system can regenerate some part of the secret information, any other group including this group should also be able to regenerate the same information. On the other hand, the entire secret should not be generated from one user or a small group of users. Furthermore, to support adaptive amounts of information on each user and flexibility in the number of users, the construction of secret codes supporting various numbers of users and adaptive rates of information is required. Our framework, with secret codes for application in distributed systems, is summarized in
Figure 3.
The support of a codeword can be regarded as the position of the secret information on the corresponding user. Let
be a minimal code of length
and size
. For each codeword
,
, we can describe its support as
Furthermore, we define the set of user indices as .
Construction A. For a minimal codeof length, let be a new vector whose support is given by a union of supports of two codewords as
whereandis not a subset offor anyThe new codeis constructed as the union of and
.
In a recursive way, the supports can be merged into an arbitrary combination of the supports. Note that the code in Construction A is not linear since the support set is not the direct sum of two supports, but the union of the two sets. However, the distributed property of the secret is preserved by the characteristics of the minimal code. Construction A corresponds to the situation where a user is out of the federated group, and the amount of corresponding information and learning resources can be assigned to another user. The information of a user is not subordinate to that of the other users even after merging the resources. Although Construction A only describes a case where the information on the user who has left is assigned to only one user, we can generalize to a case where it is distributed to multiple users.
Construction B. For a minimal codeof length, let be a new vector whose union of two supports make
whereandandare not a subset offor anyThe new codeis constructed as the union ofand.
Applying this construction in a recursive way, the supports can be separated into arbitrary sizes. Because of the non-inclusive property of the supports in Construction B, the situation can be interpreted as one where a user is out of the federated group, and the amount of corresponding information and learning resources can be assigned to another user. The information of a user is not included to that of the other users even after separating the resources. Construction B describes a case in which the support is separated from only one user, but it can be easily generalized to a case in which the information is extracted from different users.
When we consider merging two disjoint distributed systems with secret codes, it is impossible to preserve the non-inclusive property of supports if the two codes are unified without any additional modification of the structure. The interleaving of blocks is a well-known technique in the design of pseudorandom sequences [
25]. We apply the technique to the structure of minimal codes as in the following construction.
Construction C. For minimal codesandof odd lengthand size, whereand. Define codewords of lengthas
whereis the greatest integer less than. Define a new codeas the set of all combination ofand.
In Construction C, if the index of is even, the code structure follows . Otherwise, it follows . Since the non-inclusive properties and linearity are preserved by the structure of the original codes, the new code could be used in merging two disjoint systems. Moreover, the extension can be generalized to the case of merging three or more distinct systems. Therefore, when two or more distributed systems are merged, we do not need to design a new code for the new system. When we have two distinct secret codes of relatively prime lengths, it is possible to enlarge the number of codewords and the length as in the following construction.
Construction D. For two minimal codes,of lengthand size, andof lengthsand size, assume thatandare relatively prime. Define codewords of lengthas
wheremeans the remainder ofdivided by. Define a new codeas collection of alls forand.
Figure 4 shows application scenarios for Constructions A and B. The two constructions correspond to a case in which a user or a device leaves or joins the federation, respectively. Construction C can be applied to a situation where two distributed systems are merged into one, as shown in
Figure 5. The original codes are embedded into the extended code without a change in the structure in Construction C. Therefore, any new algebraic design of the distribution is not required for that case. It is also easy to generalize to a case in which three or more systems are merged. Note that the three constructions can be combined according to the application scenarios, and several known constructions, including those in
Table 1, can be applied to the four constructions.
4. Results
In this section, we present some resultant theory and examples obtained from our constructions. Constructions C and D provide extended codes in the sense of the length and the weight. Moreover, their properties can be shown by combining the properties of the original codes and the construction terminologies, as shown in the following propositions.
Proposition 1. The codein Construction C is a minimal code of lengthand size. The weight of each codewordis the sum of the weights ofand.
Proof . The length and the size of the code are clear from the definition. The next step is to check the linearity of the new code, that is, whether the equality for any is satisfied or not. Note that the addition is the vector addition modulo 2. Since and are linear codes, it is possible to let for some with . Similarly, we have . These two equations imply
by the definition in Construction C. Thus, for all
, there exists a
with
such that
, which implies that
is linear. Non-inclusive properties of supports can be also shown using the definition. The support
can be partitioned into
, where
(resp.
) is the subset of
with even (resp. odd) indices. It is clear that
is equivalent to multiplying
by two, and
is equivalent to adding one after multiplying
by two. Thus,
and
are not included in one another for any
. Similarly,
and
satisfy the same property. Therefore, it is shown that the code
satisfies the conditions of minimal codes. □
Example 1 shows a resultant code applying Construction C to a code present in [
20]. Additional parameters of codes with more flexible choices of weights can be obtained by simply changing the index of one code. More parameters from numerical simulations are presented in
Section 5.
Example 1. In Example 20 from[20], a minimal code of length and size
is given. The weight distributions for weights (
)
are given by (
).
Using two codes from two different primitive elements of the finite field GF(63), we can construct a new code of length whose weight distribution is given by (
)
for weights (
)
when assuming the order of indices of the codewords are according to the order of weights. If we change the order of combinations, several different codes with different weight distributions are generated. Table 2 compares one example of the code of length with the original code of length .
The properties of codes from Construction D can be formulated in the following proposition.
Proposition 2. The codein Construction D is a minimal code of lengthand size. The weight of each codeword is the product of the weights of two component codewords.
Proof . By the definition, the length of each codeword is clearly , and the size of the code is . For each support of , all the indices of support of can be combined. Thus, the weight of is equal to the product of the weights of and . Assume that for and for . Then, it is clear that for any combination of and , which implies that is linear. Note that for any and , the supports of and are not included in one another if or due to the properties of and . □
Example 2. Assume that there are two codes:of lengthandof length. Furthermore, suppose the weight distribution ofbe given by () for weights (), and the weight distribution of by () for weights (). Then, by Construction D, we can obtain a code of length . The weight of a codeword is the product of two weights from and .
It may be possible to use Construction D in the case that computing resources are enhanced and the number of devices is significantly increased. However, Construction D extends the size and weight from the component codes, cases where
and
are relatively prime are very rare for previously known constructions. Thus, finding primary constructions for minimal codes for more general parameters should be a future research topic. Furthermore, as shown in Example 2, the parameters of the codes are increased significantly. Therefore, it would be possible to apply Construction D to a case in which the resources are also increased considerably.
Table 2 summarizes the characteristics of the resultant codes from Constructions A~D.
5. Discussions
In this section, we discuss the flexibility of resultant codes from Construction C compared with the previously known constructions.
Table 3, which was obtained by numerical simulation, shows an example of code parameters with more possible numbers of information lengths compared to the previous construction. In this example, we can observe that there are more choices of possible weights in Construction C. This means that the distribution of information becomes more flexible. Note that several additional combinations for weight distribution are possible by exchanging the order of codewords in Construction C.
Table 4, which was obtained by another numerical simulation, compares the ratio between the minimum and the maximum Hamming weights presented in (1) of Theorem 1. The original codes of lengths 128 and 512 from [
20] are not restricted in (1), since the ratio
is less than 1/2. It is possible to obtain a ratio farther from 1/2 using Construction C, as shown in
Table 4. Thus, Construction C can provide an extended range of the information ratio among different users.
From the comparisons in
Table 2 and
Table 3, we can deduce that Construction C provides more flexibility in the distribution of secret information compared to the previous construction. Therefore, the new codes can be not only applied to more general cases but also adapted to the flexible learning conditions.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}