
EmmDocClassifier: Efficient Multimodal Document Image Classifier for Scarce Data

 ,
,  ,
, 
Abstract
:1. Introduction
2. Related Work
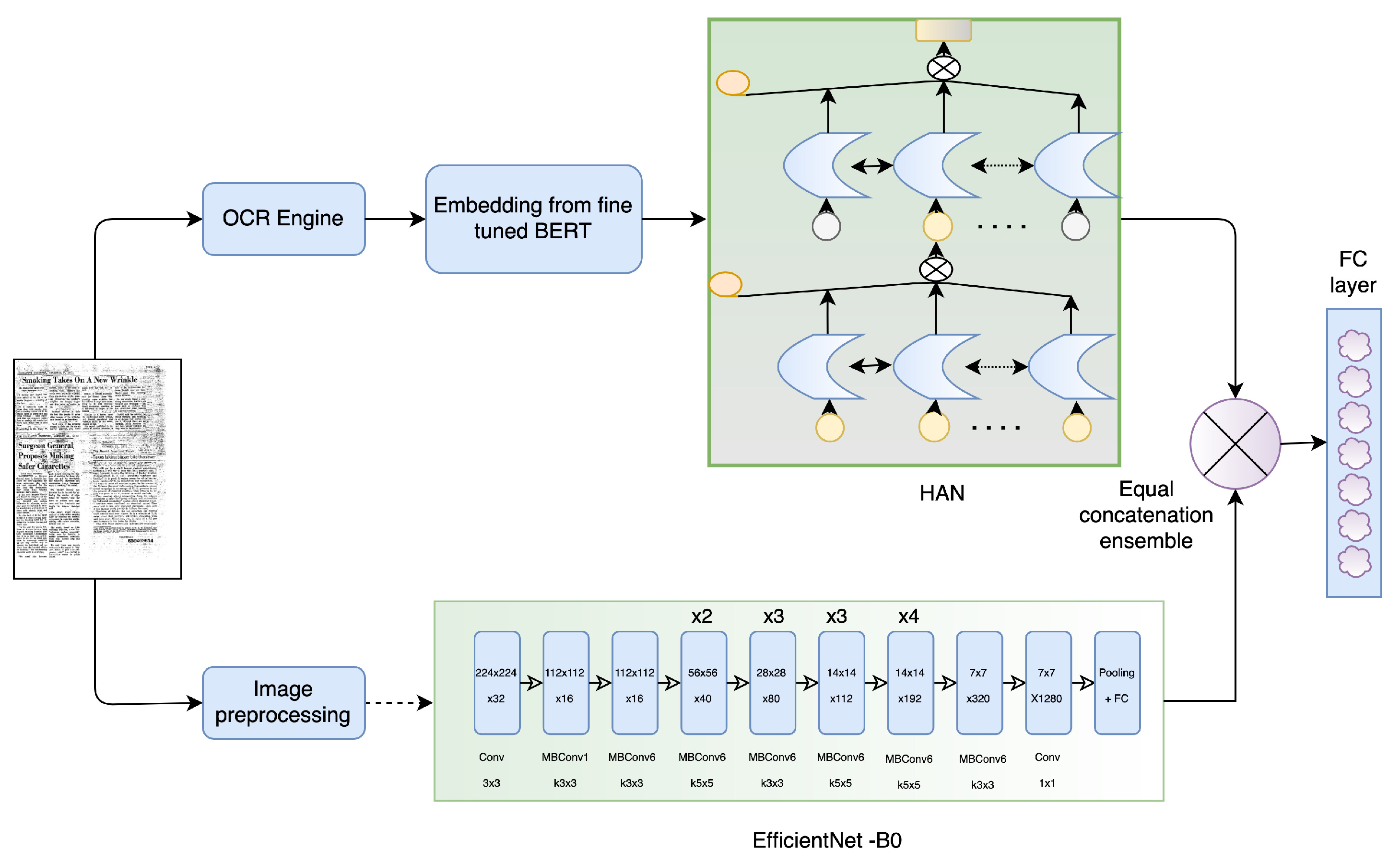
3. Methodology
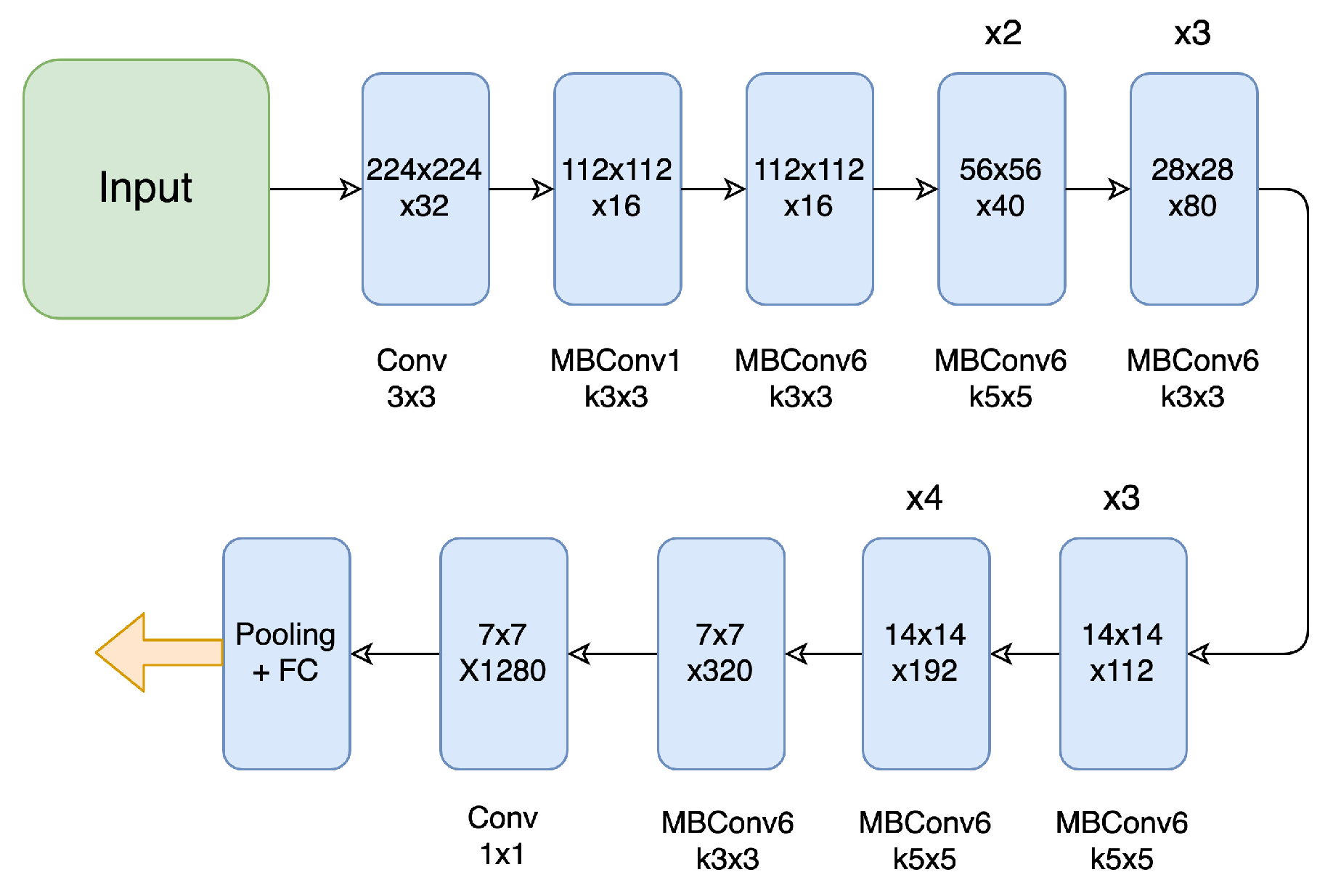
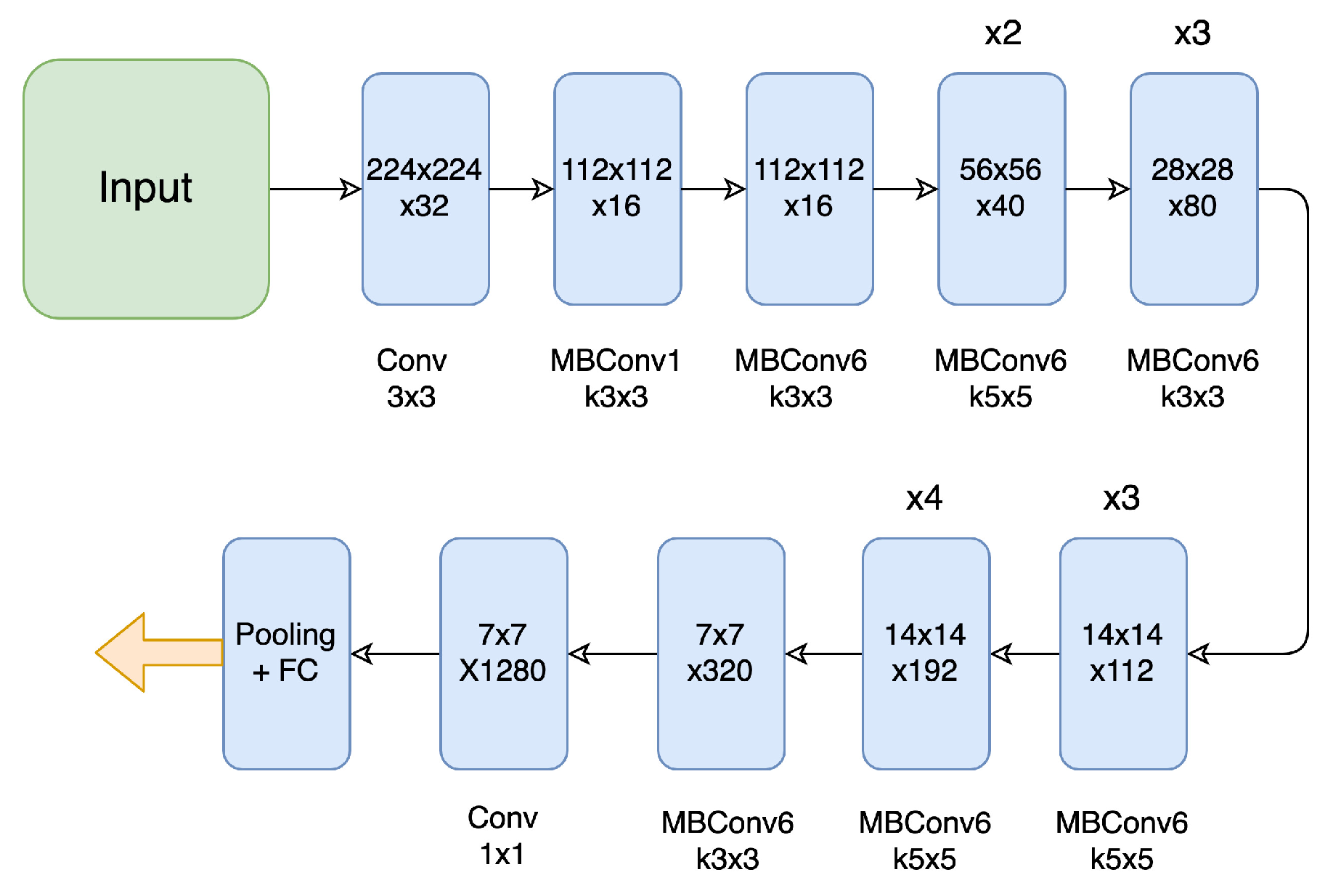
3.1. Visual Stream
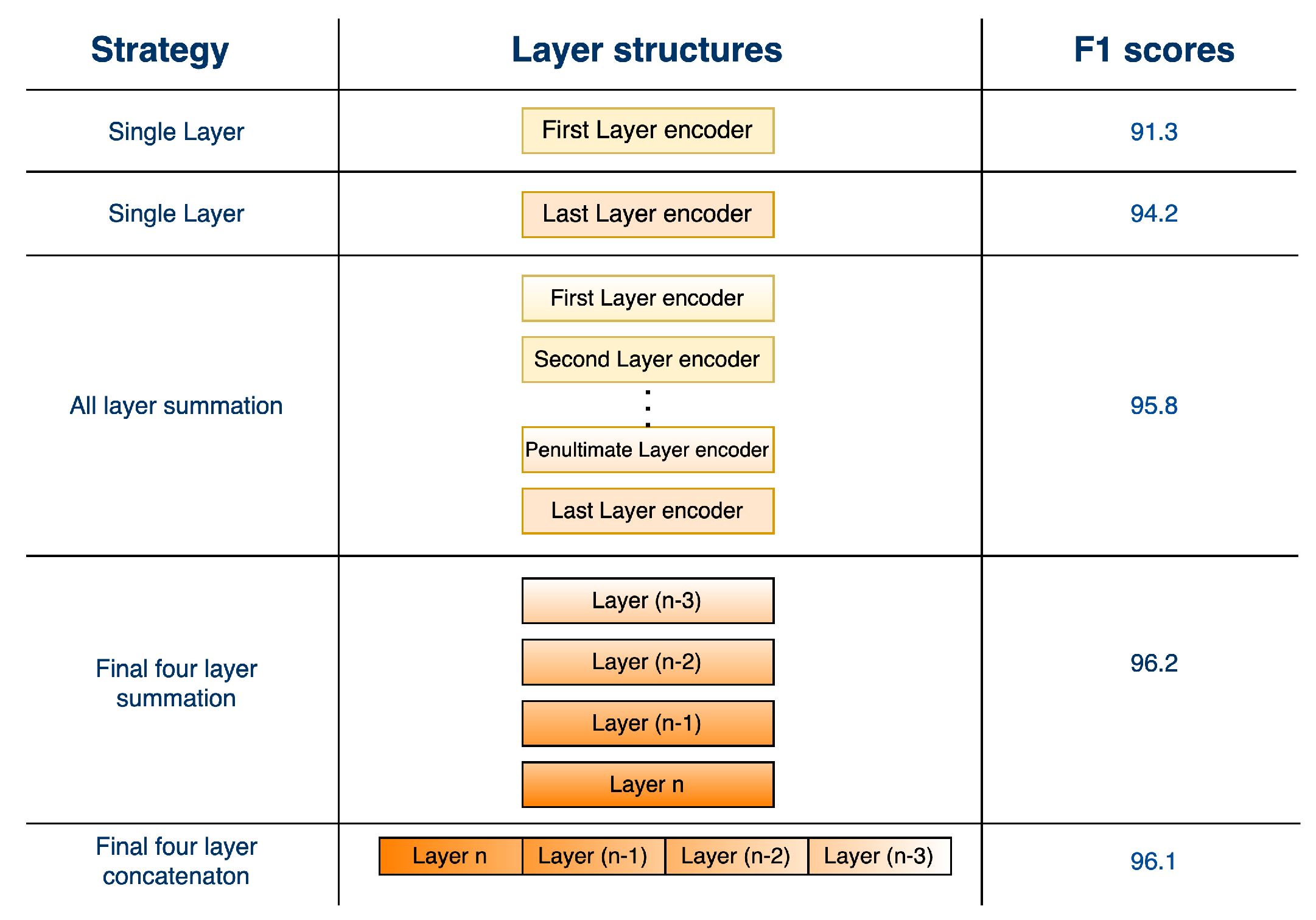
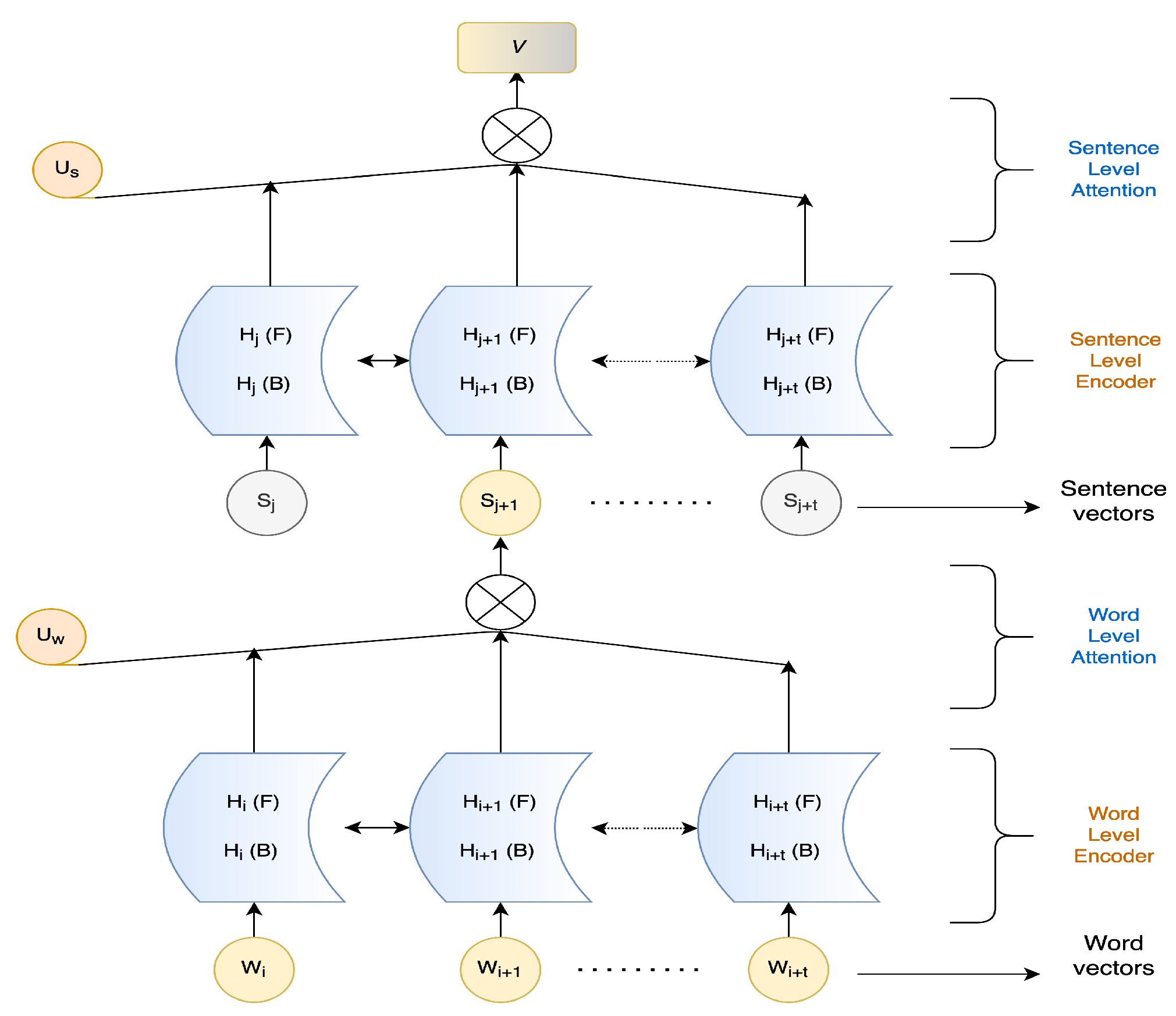
3.2. Textual Stream
3.3. Ensembling Visual and Textual Streams
4. Experimental Results
4.1. Datasets
4.1.1. RVL-CDIP
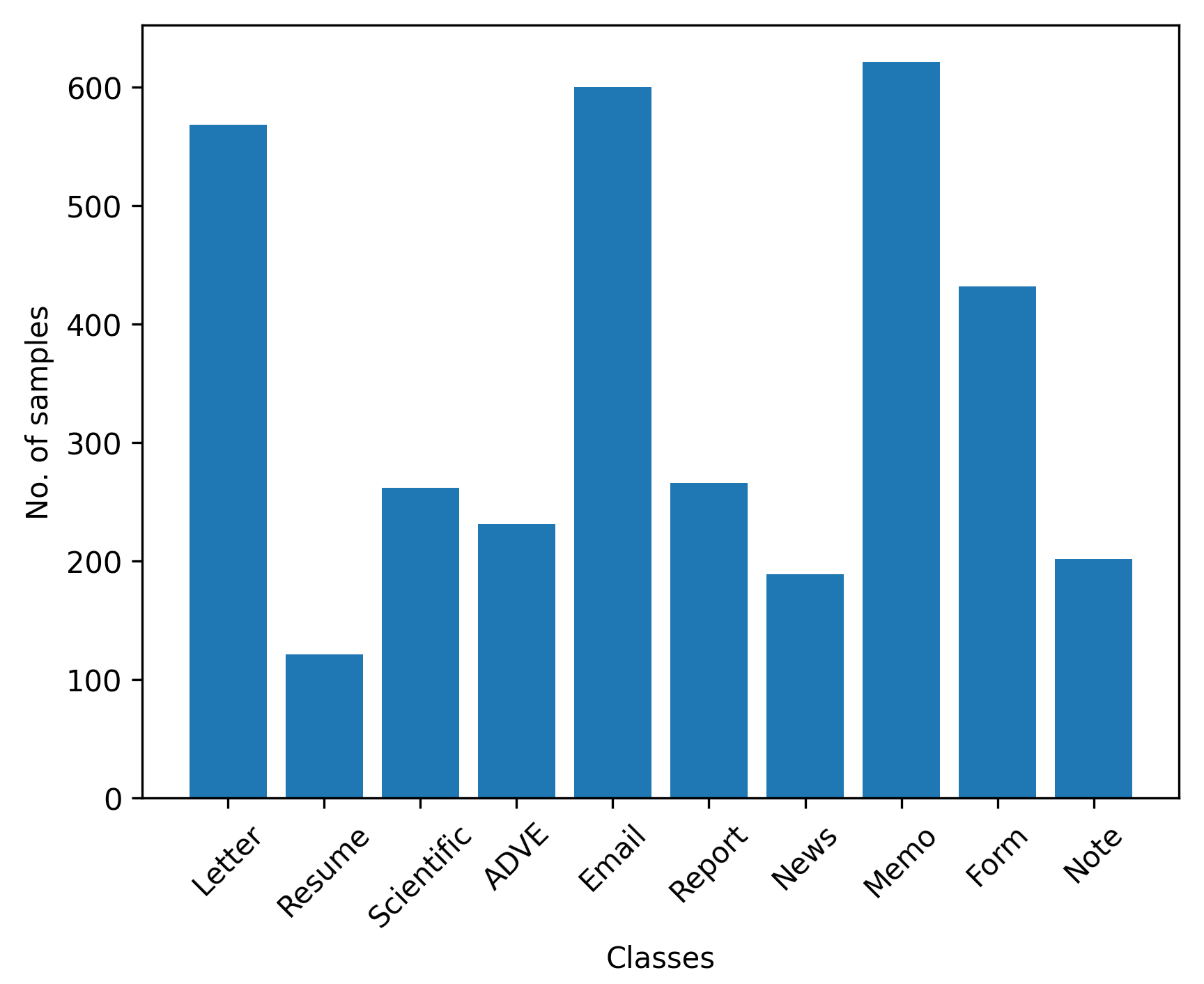
4.1.2. Tobacco-3482
4.2. Experimental Setup
4.3. Implementation Details
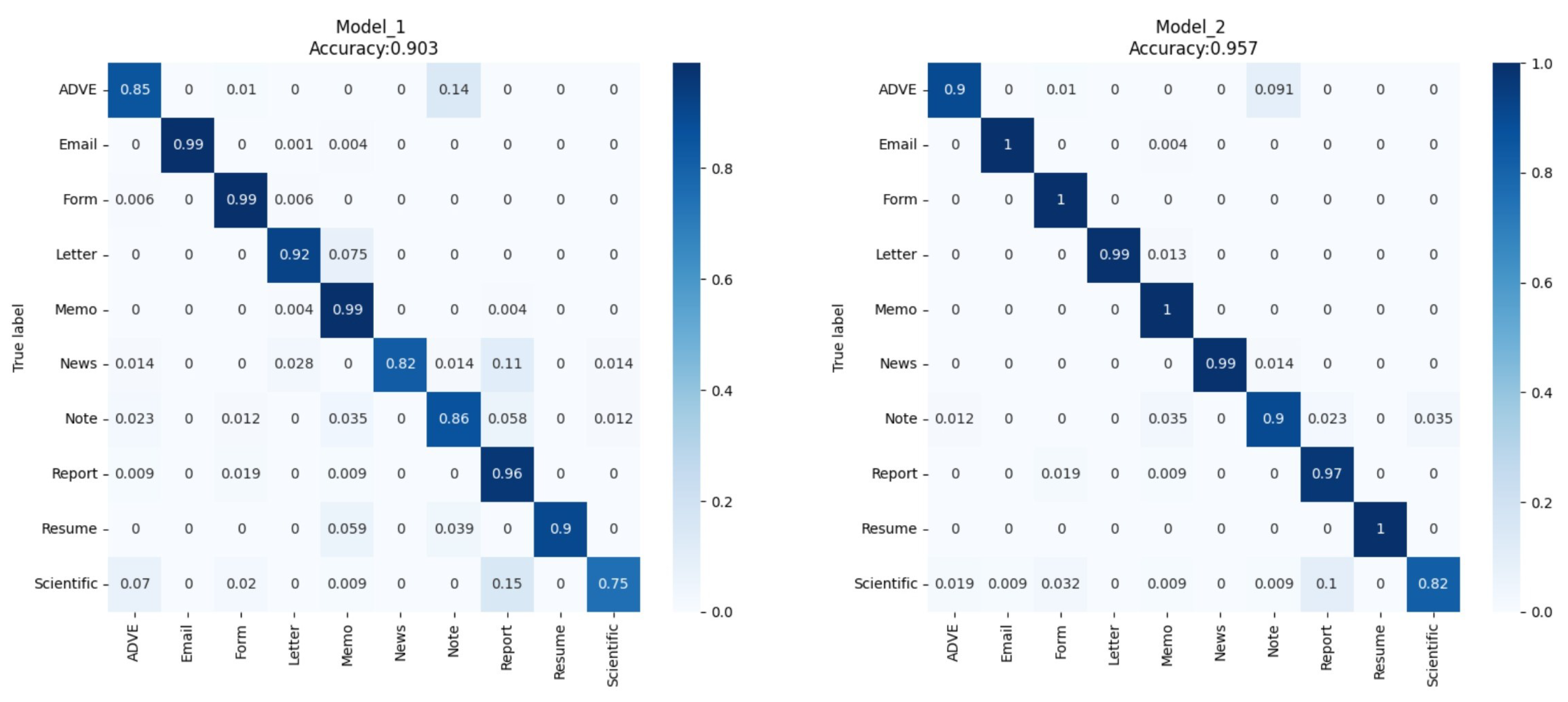
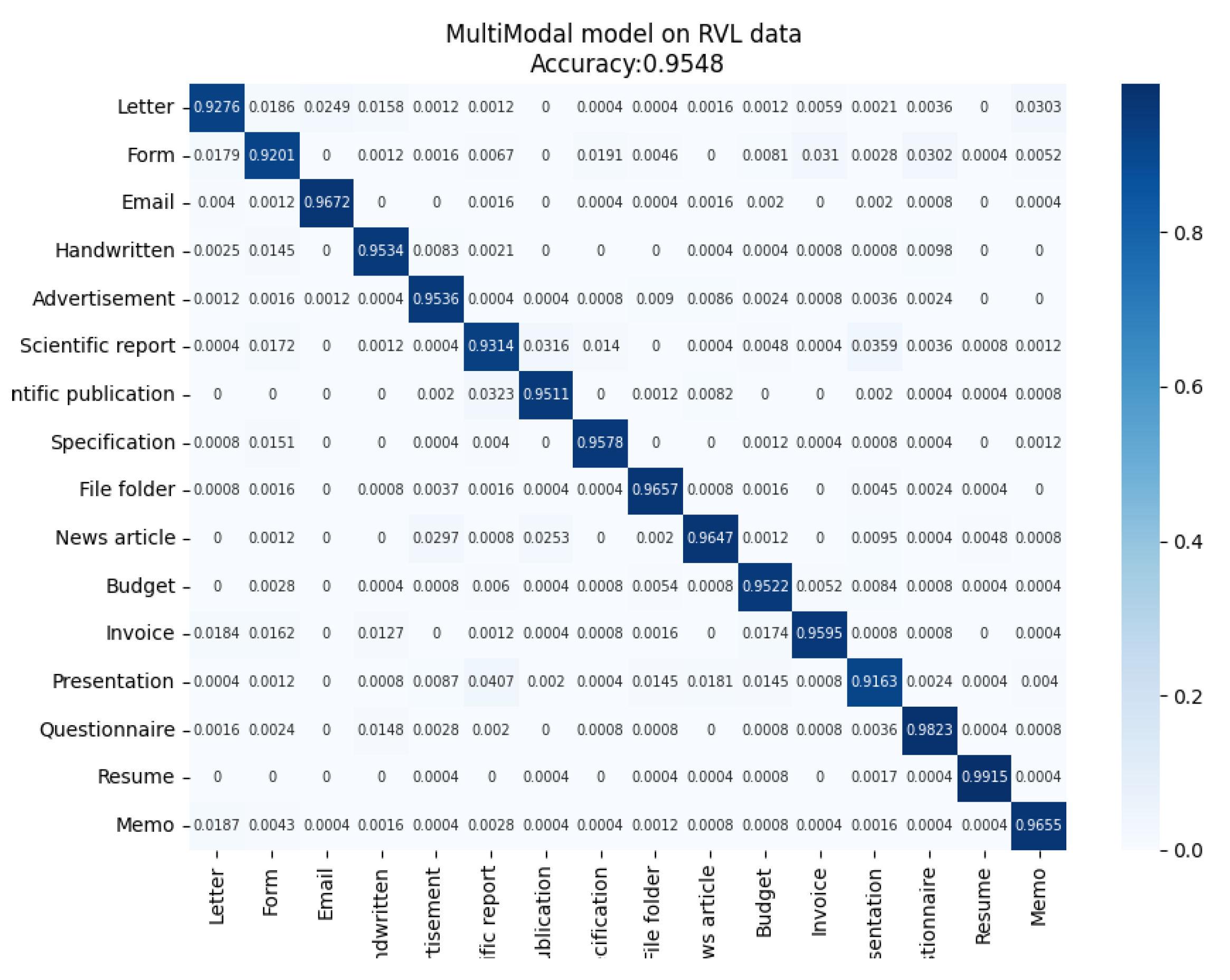
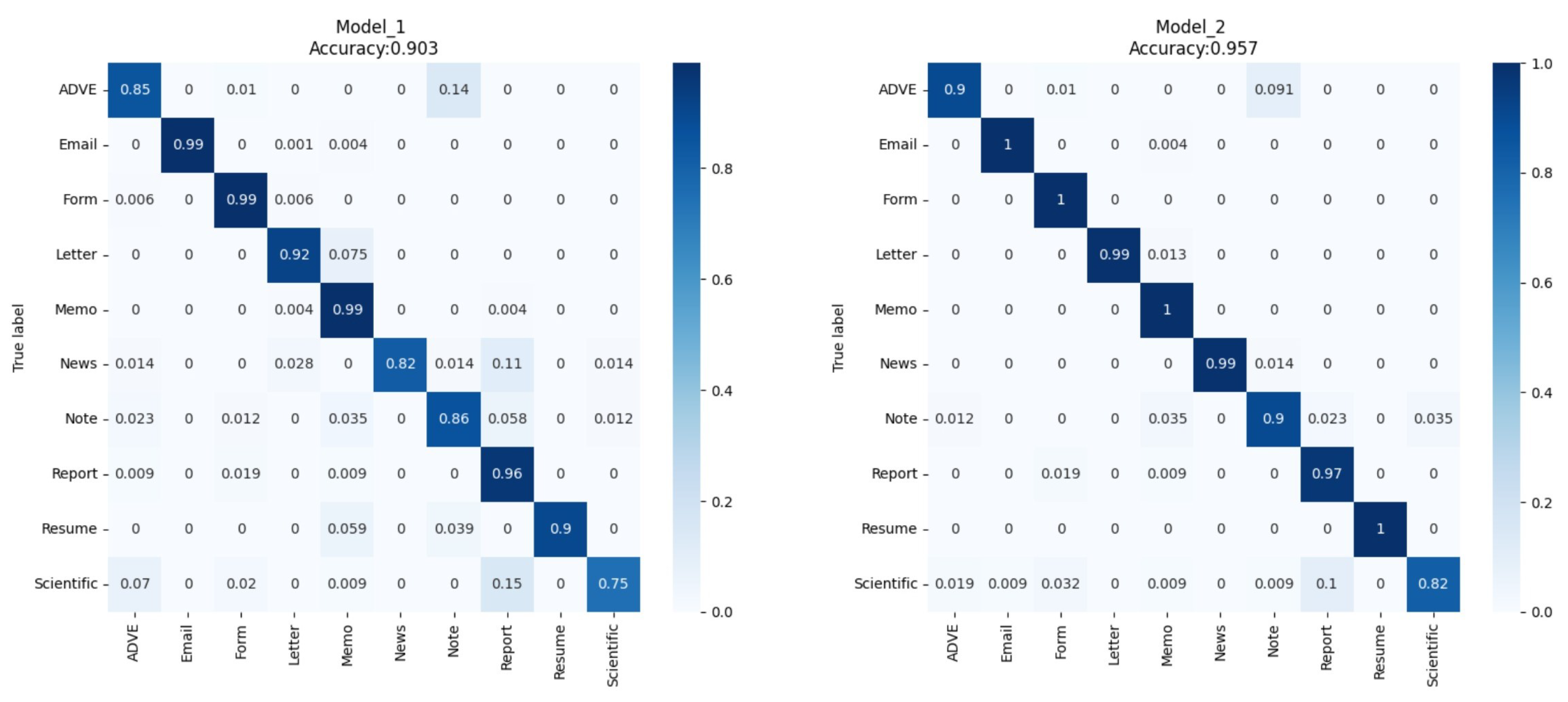
4.4. Results
5. Discussion and Evaluation of the Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Afzal, M.Z.; Capobianco, S.; Malik, M.I.; Marinai, S.; Breuel, T.M.; Dengel, A.; Liwicki, M. Deepdocclassifier: Document classification with deep convolutional neural network. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 1111–1115. [Google Scholar]
- Adnan, K.; Akbar, R. Limitations of information extraction methods and techniques for heterogeneous unstructured big data. Int. J. Eng. Bus. Manag. 2019, 11, 1847979019890771. [Google Scholar] [CrossRef]
- Choi, G.; Oh, S.; Kim, H. Improving Document-Level Sentiment Classification Using Importance of Sentences. Entropy 2020, 22, 1336. [Google Scholar] [CrossRef]
- Adhikari, A.; Ram, A.; Tang, R.; Lin, J. Rethinking Complex Neural Network Architectures for Document Classification. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; Volume 1, pp. 4046–4051. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Association for Computational Linguistics: San Diego, CA, USA, 2016; pp. 1480–1489. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Xu, Y.; Lv, T.; Cui, L.; Wei, F.; Wang, G.; Lu, Y.; Florencio, D.; Zhang, C.; Che, W.; et al. LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding. arXiv 2021, arXiv:cs.CL/2012.14740. [Google Scholar]
- Afzal, M.Z.; Kölsch, A.; Ahmed, S.; Liwicki, M. Cutting the error by half: Investigation of very deep cnn and advanced training strategies for document image classification. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 1, pp. 883–888. [Google Scholar]
- Harley, A.W.; Ufkes, A.; Derpanis, K.G. Evaluation of deep convolutional nets for document image classification and retrieval. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 991–995. [Google Scholar]
- Das, A.; Roy, S.; Bhattacharya, U.; Parui, S.K. Document image classification with intra-domain transfer learning and stacked generalization of deep convolutional neural networks. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3180–3185. [Google Scholar]
- Asim, M.N.; Khan, M.U.G.; Malik, M.I.; Razzaque, K.; Dengel, A.; Ahmed, S. Two stream deep network for document image classification. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1410–1416. [Google Scholar]
- Bakkali, S.; Ming, Z.; Coustaty, M.; Rusinol, M. Visual and textual deep feature fusion for document image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 562–563. [Google Scholar]
- Noce, L.; Gallo, I.; Zamberletti, A.; Calefati, A. Embedded Textual Content for Document Image Classification with Convolutional Neural Networks. In Proceedings of the 2016 ACM Symposium on Document Engineering, DocEng’16, Vienna, Austria, 13–16 September 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 165–173. [Google Scholar] [CrossRef]
- Ferrando, J.; Domínguez, J.L.; Torres, J.; García, R.; García, D.; Garrido, D.; Cortada, J.; Valero, M. Improving Accuracy and Speeding Up Document Image Classification Through Parallel Systems. In Proceedings of the Computational Science—ICCS 2020, Amsterdam, The Netherlands, 3–5 June 2020; Krzhizhanovskaya, V.V., Závodszky, G., Lees, M.H., Dongarra, J.J., Sloot, P.M.A., Brissos, S., Teixeira, J., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 387–400. [Google Scholar]
- Powalski, R.; Borchmann, Ł.; Jurkiewicz, D.; Dwojak, T.; Pietruszka, M.; Pałka, G. Going Full-TILT Boogie on Document Understanding with Text-Image-Layout Transformer. arXiv 2021, arXiv:cs.CL/2102.09550. [Google Scholar]
- Xu, Y.; Li, M.; Cui, L.; Huang, S.; Wei, F.; Zhou, M. Layoutlm: Pre-training of text and layout for document image understanding. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 23–27 August 2020; pp. 1192–1200. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- de la Fuente Castillo, V.; Díaz-Álvarez, A.; Manso-Callejo, M.Á.; Serradilla Garcia, F. Grammar guided genetic programming for network architecture search and road detection on aerial orthophotography. Appl. Sci. 2020, 10, 3953. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:cs.CV/1512.00567. [Google Scholar]
- Kay, A. Tesseract: An open-source optical character recognition engine. Linux J. 2007, 2007, 2. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:cs.LG/1905.11946. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:cs.CL/1810.04805. [Google Scholar]
- Audebert, N.; Herold, C.; Slimani, K.; Vidal, C. Multimodal deep networks for text and image-based document classification. arXiv 2019, arXiv:cs.CV/1907.06370. [Google Scholar]
- Cavnar, W.B.; Trenkle, J.M. N-Gram–Based Text Categorization. In Proceedings of the SDAIR-94, 3rd Annual Symposium on Document Analysis and Information Retrieval, Las Vegas, NV, USA, 11–13 April 1994; pp. 161–175. [Google Scholar]
- Hoch, R. Using IR Techniques for Text Classification in Document Analysis. In Proceedings of the SIGIR ’94, Dublin, Ireland, 3–6 July 1994; Croft, B.W., van Rijsbergen, C.J., Eds.; Springer: London, UK, 1994; pp. 31–40. [Google Scholar]
- Ittner, D.J.; Lewis, D.D.; Ahn, D.D. Text categorization of low quality images. In Proceedings of the Symposium on Document Analysis and Information Retrieval, Citeseer. Las Vegas, NV, USA, 24–26 April 1995; pp. 301–315. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Abuelwafa, S.; Pedersoli, M.; Cheriet, M. Unsupervised Exemplar-Based Learning for Improved Document Image Classification. IEEE Access 2019, 7, 133738–133748. [Google Scholar] [CrossRef]
- Kölsch, A.; Afzal, M.Z.; Ebbecke, M.; Liwicki, M. Real-time document image classification using deep CNN and extreme learning machines. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 1, pp. 1318–1323. [Google Scholar]
- Roy, S.; Das, A.; Bhattacharya, U. Generalized stacking of layerwise-trained deep convolutional neural networks for document image classification. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1273–1278. [Google Scholar]
- Hearst, M.A. Support Vector Machines. IEEE Intell. Syst. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Saddami, K.; Munadi, K.; Arnia, F. Degradation Classification on Ancient Document Image Based on Deep Neural Networks. In Proceedings of the 2020 3rd International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 24–25 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 405–410. [Google Scholar]
- Gatos, B.; Ntirogiannis, K.; Pratikakis, I. ICDAR 2009 document image binarization contest (DIBCO 2009). In Proceedings of the 2009 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1375–1382. [Google Scholar]
- Pratikakis, I.; Gatos, B.; Ntirogiannis, K. ICDAR 2011 Document Image Binarization Contest (DIBCO 2011). In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 1506–1510. [Google Scholar] [CrossRef]
- Pratikakis, I.; Gatos, B.; Ntirogiannis, K. H-DIBCO 2010—Handwritten Document Image Binarization Competition. In Proceedings of the 2010 12th International Conference on Frontiers in Handwriting Recognition, Kolkata, India, 16–18 November 2010; pp. 727–732. [Google Scholar] [CrossRef]
- Pratikakis, I.; Gatos, B.; Ntirogiannis, K. ICFHR 2012 Competition on Handwritten Document Image Binarization (H-DIBCO 2012). In Proceedings of the 2012 International Conference on Frontiers in Handwriting Recognition, Bari, Italy, 18–20 September 2012; pp. 817–822. [Google Scholar] [CrossRef]
- Pratikakis, I.; Gatos, B.; Ntirogiannis, K. ICDAR 2013 Document Image Binarization Contest (DIBCO 2013). In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1471–1476. [Google Scholar] [CrossRef]
- Ntirogiannis, K.; Gatos, B.; Pratikakis, I. ICFHR2014 Competition on Handwritten Document Image Binarization (H-DIBCO 2014). In Proceedings of the 2014 14th International Conference on Frontiers in Handwriting Recognition, Hersonissos, Greece, 1–4 September 2014; pp. 809–813. [Google Scholar] [CrossRef]
- Pratikakis, I.; Zagoris, K.; Barlas, G.; Gatos, B. ICFHR2016 Handwritten Document Image Binarization Contest (H-DIBCO 2016). In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 619–623. [Google Scholar] [CrossRef]
- Pratikakis, I.; Zagoris, K.; Barlas, G.; Gatos, B. ICDAR2017 Competition on Document Image Binarization (DIBCO 2017). In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1395–1403. [Google Scholar] [CrossRef]
- Ayatollahi, S.; Nafchi, H. Persian heritage image binarization competition. In Proceedings of the 2013 First Iranian Conference on Pattern Recognition and Image Analysis (PRIA), Birjand, Iran, 6–8 March 2013; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Saddami, K.; Munadi, K.; Muchallil, S.; Arnia, F. Improved Thresholding Method for Enhancing Jawi Binarization Performance. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1108–1113. [Google Scholar] [CrossRef]
- Saddami, K.; Afrah, P.; Mutiawani, V.; Arnia, F. A New Adaptive Thresholding Technique for Binarizing Ancient Document. In Proceedings of the 2018 Indonesian Association for Pattern Recognition International Conference (INAPR), Jakarta, Indonesia, 7–8 September 2018; pp. 57–61. [Google Scholar] [CrossRef]
- Zingaro, S.P.; Lisanti, G.; Gabbrielli, M. Multimodal Side—Tuning for Document Classification. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5206–5213. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:cs.CL/1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. arXiv 2016, arXiv:1607.04606. [Google Scholar] [CrossRef] [Green Version]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. arXiv 2018, arXiv:cs.CV/1707.07012. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Xiao, H. Bert-as-Service. 2018. Available online: https://github.com/hanxiao/bert-as-service (accessed on 2 January 2022).
- Mangal, S.; Joshi, P.; Modak, R. LSTM vs. GRU vs. Bidirectional RNN for script generation. arXiv 2019, arXiv:cs.CL/1908.04332. [Google Scholar]
- Kumar, J.; Ye, P.; Doermann, D. Learning document structure for retrieval and classification. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 1558–1561. [Google Scholar]
- Lewis, D.; Agam, G.; Argamon, S.; Frieder, O.; Grossman, D.; Heard, J. Building a Test Collection for Complex Document Information Processing. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’06, Seattle, WA, USA, 6–11 August 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 665–666. [Google Scholar] [CrossRef]
- The Legacy Tobacco Document Library (LTDL), University of California, San Francisco. 2007. Available online: http://legacy.library.ucsf.edu/ (accessed on 27 January 2022).
- Kumar, J.; Ye, P.; Doermann, D. Structural Similarity for Document Image Classification and Retrieval. Pattern Recognit. Lett. 2014, 43, 119–126. [Google Scholar] [CrossRef]
- Kang, L.; Kumar, J.; Ye, P.; Li, Y.; Doermann, D. Convolutional Neural Networks for Document Image Classification. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 3168–3172. [Google Scholar]
- Nielsen, J. Usability Engineering; Morgan Kaufman: Burlington, MA, USA, 1994. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Imagenet + RVL-CDIP | Imagenet + No RVL-CDIP | |||
|---|---|---|---|---|
| Authors | Image | Both Modalities | Image | Both Modalities |
| Kumar et al. (2014) [55] | - | - | 43.8 | - |
| Kang et al. (2014) [56] | - | - | 65.37 | - |
| Afzal et al. (2015) [1] | - | - | 77.6 | - |
| Harley et al. (2015) [8] | 89.8 | - | 79.9 | - |
| Noce et al. (2016) [12] | - | - | - | 79.8 |
| Afzal et al. (2017) [7] | 91.13 | - | - | - |
| Das et al. (2018) [9] | 92.21 | - | - | - |
| Audebert et al. (2019) [23] | - | - | 84.5 | 87.8 |
| Asim et al. (2019) [10] | 93.2 | 95.8 | - | - |
| Souhail et al. (2020) [11] | 91.3 | 96.94 | - | - |
| Javier et al. (2020) [13] | 94.04 | 94.9 | 85.99 | 89.47 |
| Our approach | 94.04 | 95.7 | 86.0 | 90.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kanchi, S.; Pagani, A.; Mokayed, H.; Liwicki, M.; Stricker, D.; Afzal, M.Z. EmmDocClassifier: Efficient Multimodal Document Image Classifier for Scarce Data. Appl. Sci. 2022, 12, 1457. https://doi.org/10.3390/app12031457
Kanchi S, Pagani A, Mokayed H, Liwicki M, Stricker D, Afzal MZ. EmmDocClassifier: Efficient Multimodal Document Image Classifier for Scarce Data. Applied Sciences. 2022; 12(3):1457. https://doi.org/10.3390/app12031457
Chicago/Turabian StyleKanchi, Shrinidhi, Alain Pagani, Hamam Mokayed, Marcus Liwicki, Didier Stricker, and Muhammad Zeshan Afzal. 2022. "EmmDocClassifier: Efficient Multimodal Document Image Classifier for Scarce Data" Applied Sciences 12, no. 3: 1457. https://doi.org/10.3390/app12031457
APA StyleKanchi, S., Pagani, A., Mokayed, H., Liwicki, M., Stricker, D., & Afzal, M. Z. (2022). EmmDocClassifier: Efficient Multimodal Document Image Classifier for Scarce Data. Applied Sciences, 12(3), 1457. https://doi.org/10.3390/app12031457