1. Introduction
In recent years, an increasing number of researchers have applied convolutional neural networks (CNNs) to resolve pixelwise and end-to-end image segmentation tasks, e.g., semantic segmentation [
1,
2,
3,
4]. Semantic segmentation can be understood as the need to segment each object in an image and annotate it with different colors. For instance, people, displays, and aircraft in the PASCAL VOC 2012 dataset were marked in pink, blue, and red respectively. As a significant role in computer vision, semantic segmentation has been widely implemented for fields like autonomous driving [
5], robot perception [
6], augmented reality [
7], and video surveillance [
8].
Since the advent of fully convolutional networks (FCN [
9]), they have greatly simplified the conventional approach to address the conundrum of semantic segmentation. Various end-to-end network architectures derived from FCN have been proposed over the years. Based on existing datasets, the segmentation accuracies are relatively high or even the maximum possible. The series of DeepLab [
10,
11,
12,
13] proposes atrous convolution with dilation to improve the problem of a scarce receptive field caused by an insufficient amount of down-sampling. The proposed atrous spatial pyramid pooling, to carry out multi-scale feature fusion, significantly advances the accuracy of network segmentation. Yu et al. [
14] proposed the bilateral segmentation network, which better preserves the spatial information of the original image while ensuring a sufficient receptive field. From semantic segmentation to real-time semantic segmentation [
14,
15,
16], considering redundant to lean network architectures, existing scholars accomplish better segmentation by designing and improving the structure of the network itself and adopting massive data augmentation methods. However, they ignored the impact of the characteristics of the dataset itself on the segmentation results.
Semantic segmentation, as a pixelwise classification task, requires the classification of every pixel. Nevertheless, not every pixel is of interest to us. A substantial amount of background information during the training phase not only increases the difficulty of learning, but also leads to misclassifications, see
Figure 1. In view of the aforementioned issues, and motivated by the excellence of the self-attention mechanism in the segmentation task [
17,
18], we apply the attention mechanism to the dataset itself. Through in-depth analysis of the dataset, we propose the background blur module bokeh. The overall structure is shown in
Figure 2, and a feasible strategy for selecting the fuzzy factor
is proposed in
Section 3.
Humans, as the most sophisticated creatures on earth, have a natural advantage in patten recognition. Relying on foveated and active vision, our visual center always focusses on the area of interest to us, rather than on the background.
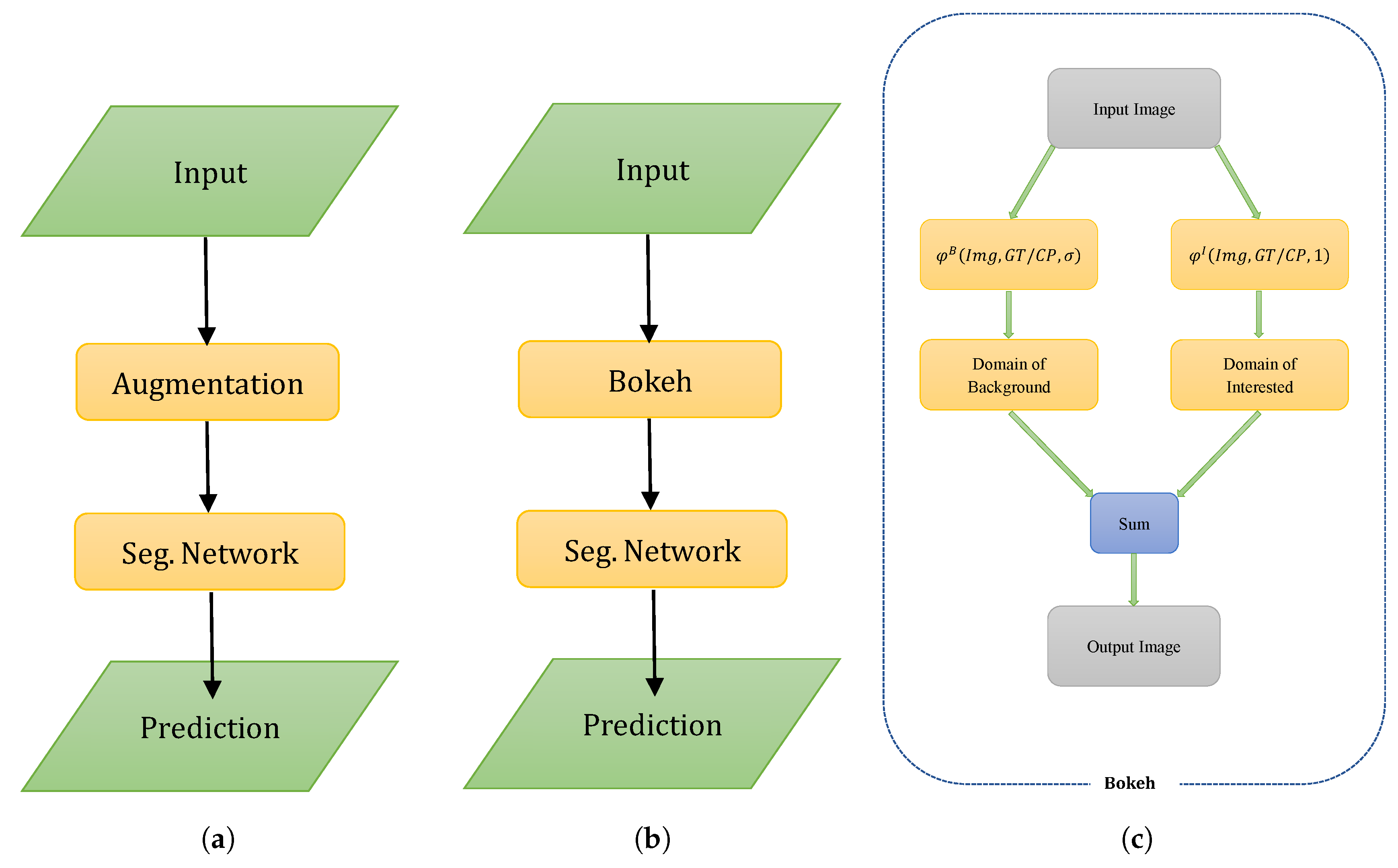
The proposed bokeh module mainly performs a certain degree of background blurring according to the distribution of various categories of the dataset itself, without any prior knowledge of the domain of interest. It combines the blurred background with the domain of interest as the subsequent segmentation network input. Specifically, during the training stage, background and foreground are divided accurately by real semantic labels provided by the training set. In the validation phase, the original segmentation network is able to separate the background and foreground, based on the coarse segmentation. The reconstructed segmentation network with the bokeh module performs the final semantic segmentation. The visualization of our bokeh module is shown in
Figure 3.
We demonstrate the effectiveness of our approach on two datasets, PASCAL VOC 2012 [
19] and CamVid [
20], and on several existing end-to-end network architectures.
The main contributions of our paper are:
Semantic segmentation is viewed from the dataset itself, and an inference strategy based on the background blurring module (bokeh) is easy to embed into existing semantic networks.
According to the characteristics of each dataset, an appropriate strategy for selecting the fuzzy factor is proposed.
It is verified from the FCN-based network that our bokeh module can improve the segmentation quality of the network without changing any network structure. The segmentation results of BiSeNet [
14] on CamVid are improved by 3.7 points, while the performance of HyperSeg [
21] on the PASCAL VOC 2012 is improved by 5.2 points after adding the bokeh module.
3. Proposed Method
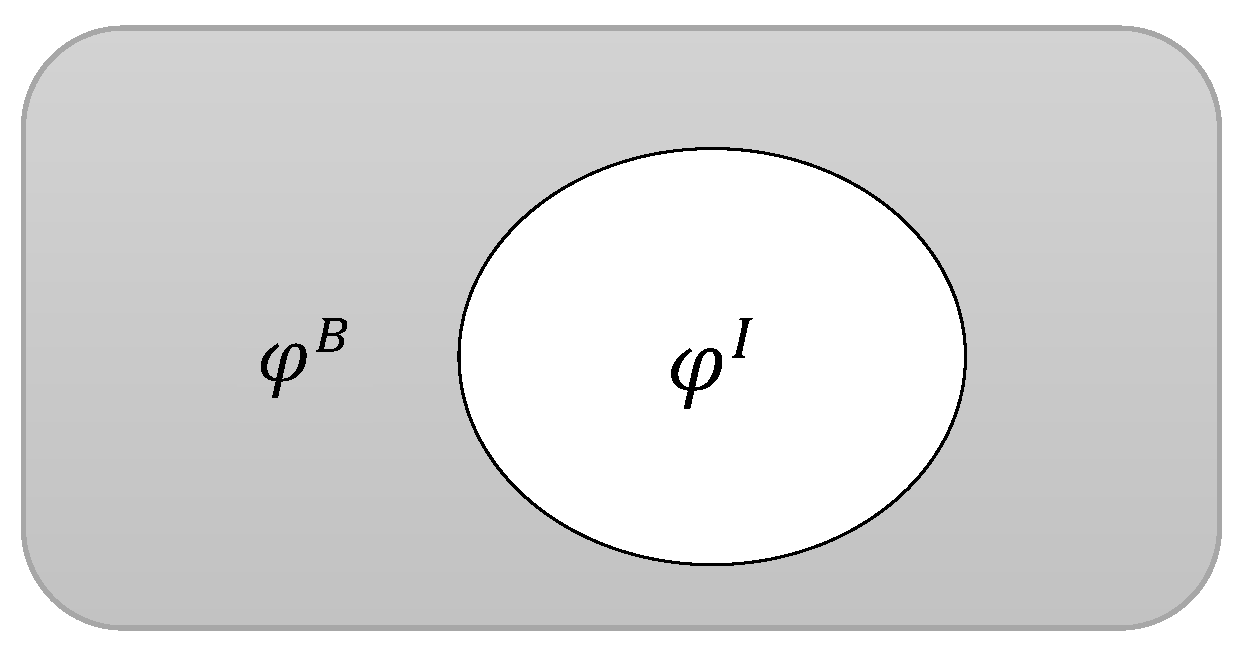
In this section, we will elaborate on the bokeh algorithm. We will begin with a brief description of the symbols used. Suppose the whole image is divided into interest and background domains.
denotes the collection of all the pixels that we are interested in; otherwise, the collection of all pixels that we are not interested in is
. The distribution relationship can be simply expressed as
Figure 4. For two matrices
and
, matrix
is called the Hadamard product [
26] of matrices A and B if matrix C satisfies the following condition:
We found that, on some of the datasets used for semantic segmentation (e.g., PASCAL VOC 2012, etc.), there is an imbalance between different categories in the dataset, and an imbalance between the interest and background domains. For example, of Bicycle (0.29%) and Person (4.57%), both of which are of interest, the former is only one sixteenth of the latter. Moreover, the ratio of the interest domain to background domain is about 1:3, as shown in
Table 2. This is not favorable for the segmentation task. A considerable amount of background information either increases the difficulty of training or has no effect on the improvement of segmentation accuracy. Some areas of the background domain may resemble some areas of the interest domain. Learning more background information weakens the role of the usable information. We are more inclined to play down the impact of background information on learning. Learning more and more useful information improves the segmentation accuracy of all categories. We use the effective labeling information in the existing labels to obtain the interest domain of a training set.
3.1. The Algorithm of Bokeh
For any input image and the corresponding label in the training stage,
,
,
, where
is the size of the image, and
C represents the number of image channels (for RGB,
), the background blur module bokeh can be summarized as follows
where:
We denote
as the interest domain, and
as the background blur domain. When
, it means that the pixel at
belongs to the background; otherwise, it belongs to the interest domain.
I is an H-by-W matrix of ones. “∗” is the matrix Hadamard product operator.
denotes the fuzzy factor, whose value is inversely proportional to the degree of blur. Its selection strategy will be given later. Background label variable
can be presented as:
Assume that
is the proportion of the background field in an image, and
is the proportion of the field of interest. Obviously, we obtain
, where
and
are defined as follows:
where
is the sum of the pixel number of the background domain, and
is the sum of the pixel number of the interested domain. For PASCAL VOC 2012 train dataset,
,
.
For the selection of the fuzzy factor
, we initially set
equal to the background rate of the whole dataset (e.g., for PASCAL VOC train dataset,
). Suppose
. The degree of background blur of each image depends on the distribution of its own background. If its background proportion is larger, the background blurring degree should be aggravated. Hence,
should be smaller. Conversely,
should be greater. Specifically, when
, only the field of interest is involved, the corresponding background blurred factor
should be maximized. When
, the background domain is barely included, the
should be minimized. Let
and
satisfy the linear relation:
such that
where
.
We solve (
7), and obtain
, Thus,
could be recasted by
Substituting (
3), (
4) and (
8) into (
2), we obtain the formula for the evaluation of the bokeh:
where
is defined in (
5).
3.2. The Main Mechanism of Bokeh
The reason why CNNs can achieve various classification tasks is that, after a series of convolution and pooling operations, networks are able to infer the abstract representation (also called advanced feature map) of the input image. The ability of abstract representation depends not only on the performance of the network but also on the characteristics of the input image. Finding differences between similar objects is much more difficult than finding differences between different objects. For example, we use the same dichotomous network to classify apples and bananas, or tomatoes and cherry tomatoes. The latter is obviously more difficult, precisely because similarities weaken the differences between different objects.
Since semantic segmentation often requires a large amount of sample data, similarities between categories inevitably exist. Therefore, the proposed bokeh method enables differences between categories amplified. Assuming that there are two similar objects in an image, and , where is marked as background and is marked as category I in GT. In a training iteration of the network model, abstract representation learned from is denoted as , and the abstract representation learned from is denoted as . Obviously, and also have some representation elements in common. The segmentation network learns similar high-level features from two different categories of objects, so it is hard for the network to figure out the features of the category of interest . After bokeh and fuzzy operations imposed on , the similarity between and is abated during iterations, and the network can gradually learn the features of properly.
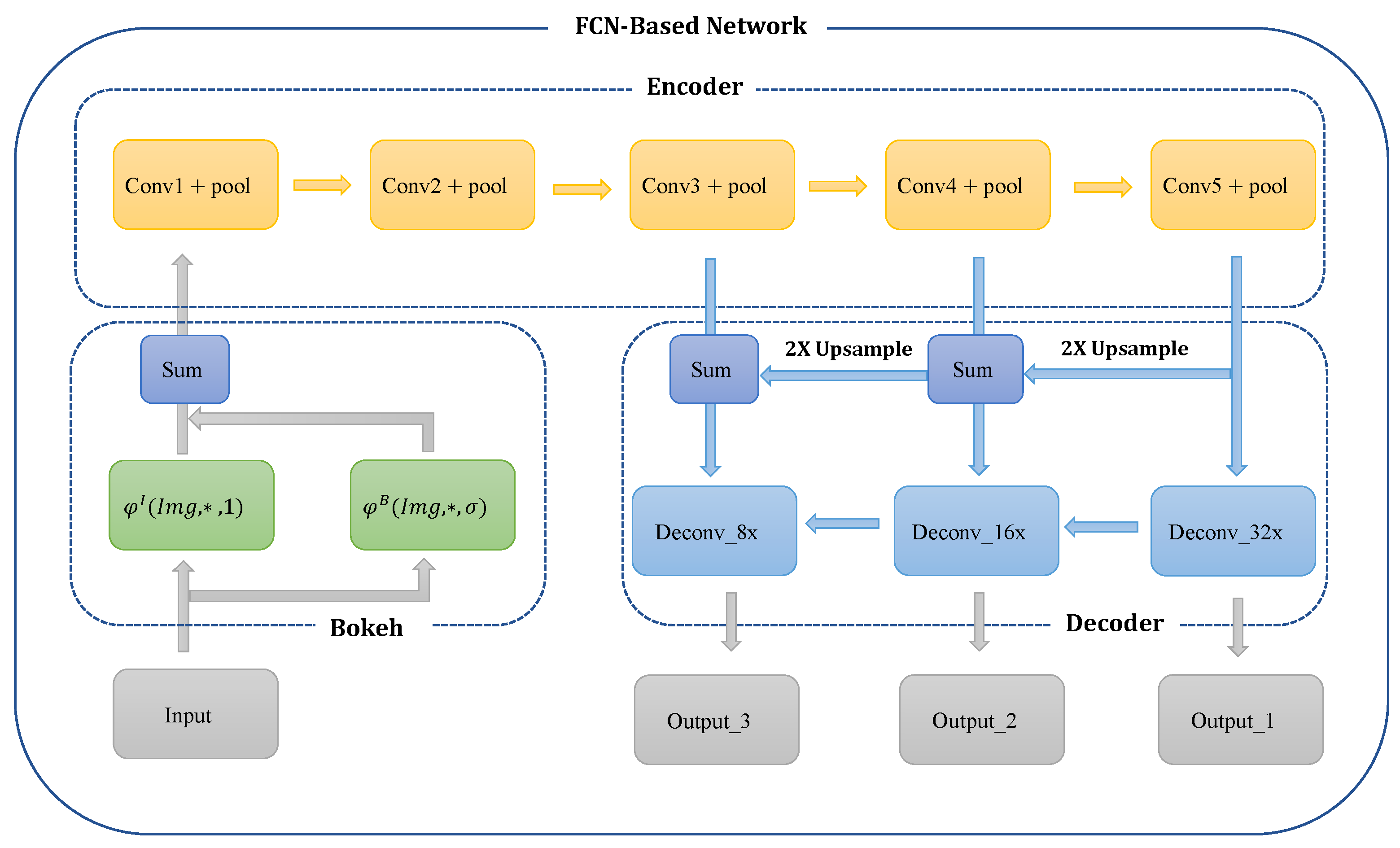
3.3. Embed into an Existing Network
According to (
8), the selection of fuzzy factor
is merely related to the background rate(
and
). Therefore, for different datasets, we only need to calculate the proportion of each category before using the bokeh method, which can be used as a general method. With the FCN network, the overall network architecture after adding our bokeh module is shown in
Figure 5. For each block, the convolution stride is one and the stride of pooling is two. There are two more convolution operations with stride 1 after “Conv5 + pool”. After each downsampling, the size becomes half of the original. The decoder consists of outputs of three different structures. First, FCN-32s(Output_1) is obtained from the results of “Conv5 + pool” through 32x upsampling. The output of Conv5 + pool with a 2x upsampling is added to the output of “Conv4 + pool” to obtain
. Then, FCN-16s(Output_2) is acquired from
through 16x of upsampling. Similarly, as shown in the figure above, we can obtain FCN-8s (Output_3). Detailed structure is shown in
Table 3. The network backbone can use AlexNet [
27], VGGnet [
28], and GoogLeNet [
29].
4. Experimental Results
FCN [
9], BiseNet [
14], and HyperSeg [
21] are selected as our segmentation networks, and relevant experiments are carried out on PASCAL VOC 2012 [
19] and CamVid [
20] benchmarks. A brief review of the corresponding datasets and metrics will be first presented. Following this, implementation and explanation of experiments will be given.
PASCAL VOC 2012: As one of the rockstars used for semantic segmentation, PASCAL VOC 2012 covers not only indoor and outdoor scenes, but also night-time scenes with a total of 21 semantic categories (20 categories of interest and a class for the background). The whole dataset contains 4369 images, 1464 of which are used for training, 1449 for validation and 1456 for testing. The training set and validation set adopt full annotation, while the test set does not provide labels. The capacity has been later expanded in SBD [
30] to reach 10,582 training samples.
CamVid: As a small-scale urban street view dataset, CamVid includes a total of 701 fully annotated images, 367 of which are employed to train, 101 for validation and 233 for testing. The CamVid dataset consists of 11 semantic categories (e.g., cars, buildings, billboards, etc.) and an Unlabelled class. Each image has the same resolution: .
Metrics: Let be the number of pixels that class i is predicted to be class j, and C be the number of object classes (including the background class). We compute four indices: Pixel Acc, Mean Acc, Mean IOU and F.W IOU, as defined below. Naturally, the higher the values are, the better network performance is.
Pixel accuracy(Pixel Acc): ;
Mean pixel accuracy(Mean Acc): ;
Mean intersection over union(Mean IOU): ;
Frequency weight intersection over union (F.W IOU): .
4.1. Implementation Protocol
We reconstruct the classical FCN [
9], BiSeNet [
14], and HyperSeg [
21] network. In order to more objectively evaluate the impact of background information on segmentation accuracy, we remove all data augmentation (except for cropping size) in the original paper. The reconstructed networks are represented by (Re)FCN-8s, (Re)FCN-16s, (Re)FCN-32s, (Re)HyperSeg, and (Re)BiSeNet, respectively. Our reconstruction results are a little bit lower than the original results because we did not add a mass of data augmentation. However, our focus is to demonstrate the feasibility of our method, rather than narrowing the gap with the original paper.
Training details: For the CamVid [
19] dataset, an Adam optimizer was used, with batch size 8, initial learning rate 1
, and weight decay 1
in training. Similar to Deeplab series [
11,
12,
13], the “poly” learning rate attenuation strategy was also adopted, and the last learning rate was multiplied by
, where
, after each iteration. For the PASCAL VOC 2012 [
19] dataset, parameters were set with batch size 12, and weight decay 2
in training. After every 50 epochs, the learning rate decayed to half of the last one.
Data augmentation: No additional operations are required except clipping. For Camvid, images processed by SegNet [
31] are used as input in this paper, and these images are
. The PASCAL VOC 2012 dataset is clipped to a fixed size as input.
4.2. Ablation for Bokeh
Applying bokeh to multiple segmentation networks on two datasets, comparative experiments were made. The experimental results of three FCN network architectures and HyperSeg on the PASCAl VOC dataset are shown in
Table 4. As can be seen, the mean IOU of the four mentioned network architectures ((Re)FCN-32s, (Re)FCN-16s, (Re)FCN-8s, and (Re)HyperSeg) with bokeh are improved by 4.7, 4.6, 4.8, and 5.2 points, respectively. At the same time, the specific precision of FCN-8s before and after adding the bokeh module on the PASCAL VOC 2012 Val dataset is given, as illustrated in
Table 5. Note that the segmentation accuracy of an individual category is significantly improved, except for 5 out of 84 comparison items.
Considering the results in
Table 2 and
Table 5 together, we find relatively small categories, such as bicycle (0.29%), boat (0.58%) and potted plant (0.64%), make a significant contribution to accuracy improvement. Note that the segmentation accuracy of exceptional categories, such as “Cow” and “Dinning Table”, decrease inversely. This is because while blurring the background, it depresses the context information to some extent. We considered it from two aspects. One is to employ the fusion of “(Re)FCN-8s” and “(Re)FCN-8s + bokeh”, named “(Re)FCN-8s + Fusion”. Another is to confine the scope of the background blur field to ensure rich context information is preserved, named “(Re)FCN-8s + Shrink.” The experimental results demonstrate, as shown in
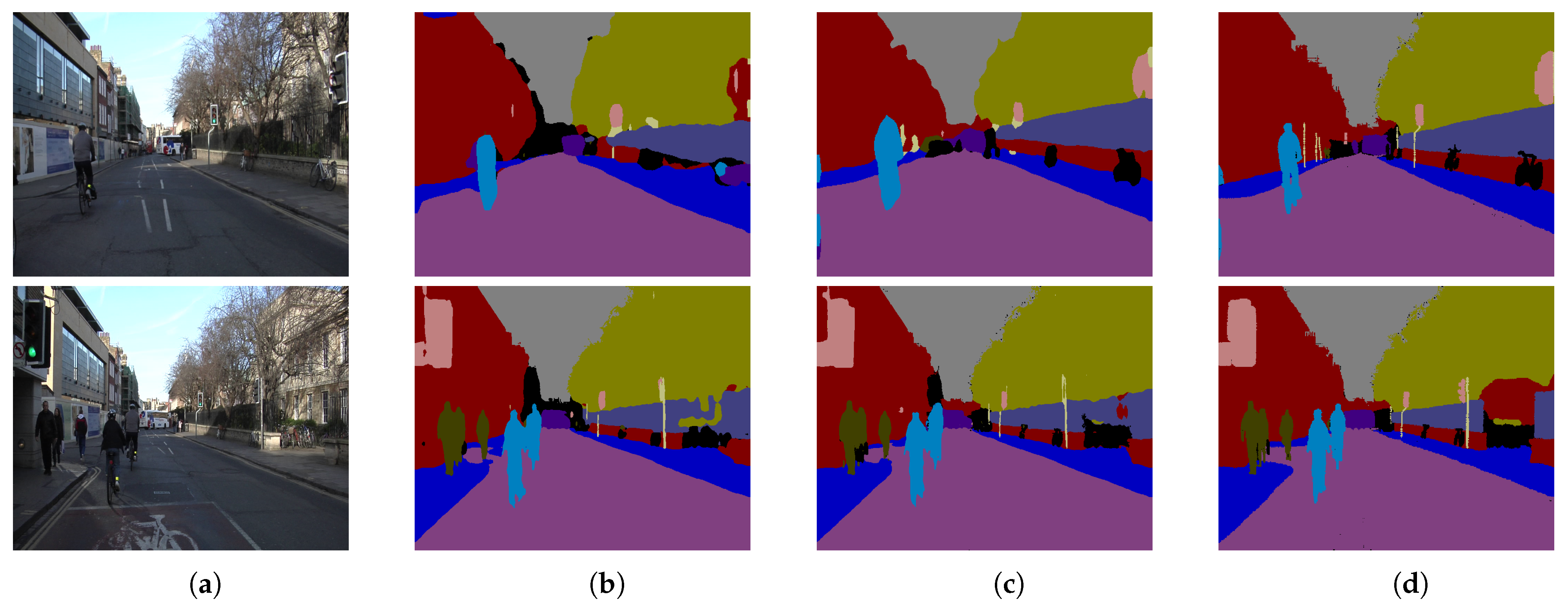
Table 5, that these two methods can avoid the accuracy decrease in specific categories. However, the improvement of the overall segmentation accuracy is not as good as before. As a result, the accuracy decrease in some individual categories is permitted. Qualitative examples on this dataset are shown in
Figure 6.
The bokeh module improves the segmentation results on the CamVid val dataset by 3.7 in Mean IOU, as shown in
Table 6. This demonstrates that the proposed bokeh module is easily embedded into a real-time network architecture. In view of the consequences of PASCAL VOC 2012, bokeh plays a vital role in the class with a small proportion of the dataset. As for CamVid, the background occupies a relatively small proportion, but the accuracy increase is clear. The proportion of the CamVid training dataset by category is presented in
Table 7.
It is clear from
Table 8 that the improvement in the Unlabelled category is the most significant. Analyzing the characteristics of CamVid, it can be observed that low background proportion of the dataset itself and diversity of categories in each image leads to this. After adding the bokeh module, the image changes are not noticeable compared to the ones before the fuzzification. However, this slight improvement occurs in almost all of the Unlabelled category. Qualitative examples on this dataset are given in
Figure 7.
We compared the advanced feature maps of 20 channels (excluding background channels) in the last layer of HyperSeg [
21] before and after adding bokeh. The sensitivity of the network to the categories of interest is higher after adding bokeh, as shown in
Figure 8.
5. Conclusions
In this paper, we propose a semantic segmentation method based on background blurring, which adaptively processes the input image background via the fuzzy factor , without changing the original network structure or introducing additional parameters, to expand differences between background and foreground and guide the network segmentation. The selection of is determined by the overall background rate of the dataset and the background rate of the current image. The former determines the approximate range of its value, while the latter determines its specific value. Compared to the attention mechanism in the network layer, bokeh plays the same role in the dataset, by weakening the background information to highlight the features of the foreground. Moreover, our approach can be lightly embedded into the existing segmentation network. As our experiments show, our method achieves competitive performance on PASCAL VOC 2012 and CamVid, with mean IOU increased by 5.2 and 3.7, especially for the small proportion category in the dataset. The main limitation of this study is that our bokeh method relies on the existing segmentation network, and the performance of the existing segmentation network directly determines whether we can accurately trace the background. Different segmentation networks selected may result in diverse results. Therefore, a natural progression of this work is how to efficiently segment the foreground and background without relying on the current network. In addition, adding classical image processing methods and how to encode and decode contour information effectively will be the focus of this paper in the future.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}