Abstract
Non-volatile memories (NVMs) have aroused vast interest in hybrid memory systems due to their promising features of byte-addressability, high storage density, low cost per byte, and near-zero standby energy consumption. However, since NVMs have limited write endurance, high write latency, and high write energy consumption, it is still challenging to directly replace traditional dynamic random access memory (DRAM) with NVMs. Many studies propose to utilize NVM and DRAM in a hybrid memory system, and explore sophisticated memory management schemes to alleviate the impact of slow NVM on the performance of applications. A few studies architected DRAM and NVM in a cache/memory hierarchy. However, the storage and performance overhead of the cache metadata (i.e., tags) management is rather expensive in this hierarchical architecture. Some other studies architected NVM and DRAM in a single (flat) address space to form a parallel architecture. However, the hot page monitoring and migration are critical for the performance of applications in this architecture. In this paper, we propose Transformer, an OS-supported reconfigurable hybrid memory architecture to efficiently use DRAM and NVM without redesigning the hardware architecture. To identify frequently accessed (hot) memory pages for migration, we propose to count the number of page accesses in OSes by sampling the access bit of pages periodically. We further migrate the identified hot pages from NVM to DRAM to improve the performance of hybrid memory system. More importantly, Transformer can simulate a hierarchical hybrid memory architecture while DRAM and NVM are physically managed in a flat address space, and can dynamically shift the logical memory architecture between parallel and hierarchical architectures according to applications’ memory access patterns. Experimental results show that Transformer can improve the application performance by 62% on average (up to 2.7×) compared with an NVM-only system, and can also improve performance by up to 79% and 42% (21% and 24% on average) compared with hierarchical and parallel architectures, respectively.
1. Introduction
With the rapid growth of data volume in the fields of artificial intelligence, internet of things, and cloud computing, computer systems are required to store and process big data as fast as possible. However, conventional computer systems are difficult to support these applications effectively due to limited memory resources. As a result, most big data applications usually suffer from frequent input/output (I/O) operations. On the other hand, many big data applications often show rather poor data locality, resulting in very low cache hit rate and frequent I/O operations.
Since DRAM scaling in terms of storage density and energy efficiency [1] has become slow in recent years, conventional computer systems only using DRAM as main memory cannot satisfy the rapidly growing memory requirement for big data processing [2]. Particularly, since DRAM is volatile, data retention mainly relies on frequently refreshing, which significantly affects the DRAM bandwidth and power consumption. Many studies show that DRAM accounts for a large proportion of total energy consumption in computer systems [3].
The emergence of non-volatile memories (NVMs) such as phase-change memory (PCM) [4], resistive random-access memory (ReRAM) [5], and spin-transfer torque random access memory (STT-RAM) [6] offers new opportunities to address the memory scaling problem. NVM has many promising features, such as rather high storage density, non-volatility, byte-addressability, and near-zero static power consumption [7,8]. Moreover, the read performance of NVM approximates that of DRAM [9]. These advantages of NVM have aroused many proposals to use it as a complement to DRAM. However, NVM still has a few disadvantages. First, the write speed of NVM is almost ten times slower than that of DRAM. Second, NVM can only endure about to write operations and thus has limited lifetime [10]. Thus, it is not practical to replace DRAM with NVM directly.
Many studies propose utilizing both DRAM and NVM in hybrid memory systems [11,12,13]. There are mainly two architectures to manage DRAM and NVM. The first one is called the hierarchical hybrid memory architecture in which DRAM is used as a cache for NVM and managed by hardware. The second one is called parallel hybrid memory architecture in which both DRAM and NVM are used as main memory, and hot pages in NVM are migrated to DRAM by OSes. However, there are still some challenges to fully exploit the advantages of both DRAM and NVM in hybrid memory systems. First, a single hybrid memory architecture cannot best fit all applications with different memory access patterns. In general, hierarchical hybrid memory architectures are more suitable for applications with good data locality so that most memory accesses can hit in the DRAM cache. In contrast, parallel hybrid memory architectures are more suitable for applications with large memory footprints and relatively poor data locality because hierarchical hybrid memory architectures may lead to frequent cache thrashing and increased data access latency. Thus, it is essential to design a reconfigurable hybrid memory architecture that can dynamically adapt to different memory access patterns. Second, although parallel hybrid memory architectures offer the advantage of flexibility in terms of memory management, the memory allocation and hot page migration schemes should be carefully designed to mitigate the cost of page migration. Since current OSes only provide “dirty” and “access” bits in a page table entry to record the state of a page. This limited information is not sufficient to precisely monitor all memory accesses to a page. It is often very costly to track all memory references in an OS, and the software overhead of page access monitoring may even offset the benefit of hot page migrations.
To solve these problems, we design Transformer, an OS-supported reconfigurable hybrid memory architecture that can dynamically translate a parallel memory architecture to a hierarchical memory architecture, and vice versa, without any hardware modification. Our major contributions are as follows: (1) We design an address remapping mechanism to logically implement a hierarchical hybrid memory architecture based on the parallel hybrid memory architecture. (2) We design a memory architecture conversion mechanism that can dynamically switch our hybrid memory system between parallel and hierarchical architectures according to applications’ memory access patterns. (3) We propose a lightweight sampling mechanism to monitor memory accesses, and thus can accurately figure out the frequently-accessed (hot) NVM pages with less software overhead. (4) We implement a hot page migration mechanism for both parallel and hierarchical hybrid memory architectures.
2. Related Work
In recent years, there have been many studies on hybrid memory architectures which can be generally summarized into hierarchical and parallel architectures. As shown in Figure 1a, the hierarchical hybrid memory architecture uses DRAM as a cache for NVM. Only NVM is exposed to OS as main memory, while DRAM is usually managed by hardware [14]. When data are missing in the on-chip cache, the CPU should access the data in DRAM first. If the data are also missing in the DRAM, the CPU will fetch the data from NVM to DRAM. In contrast, in the parallel hybrid memory architecture, NVM and DRAM are both exposed to OS and used as main memory [15], as shown in Figure 1b.
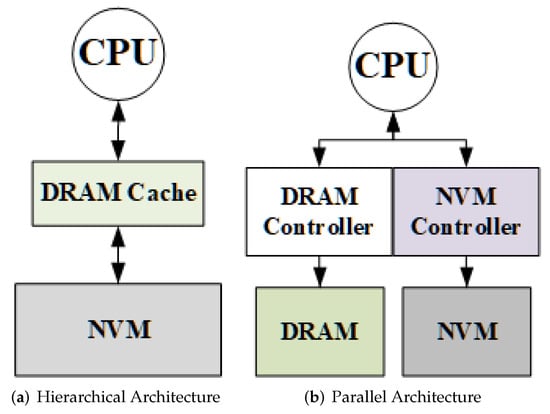
Figure 1.
Hierarchical and parallel hybrid memory architectures.
Hierarchical Memory Architecture. Loh et al. [16] proposed to use high-bandwidth die-stacked DRAM as a cache for DRAM. The near-CPU die-stacked DRAM is managed as a 29-way set-associative cache, and the metadata are stored in die-stacking DRAM by batching tags. To further reduce memory access latency, a bit-vector MissMap in the on-chip last level cache is used to track data blocks in the die-stacked DRAM. Qureshi et al. [17] proposed to use both PCM and DRAM in a hybrid memory architecture. PCM is used as the main memory, whereas DRAM is served as a cache for PCM. In this case, DRAM is managed by a separate controller and is not visible to the operating system. Upon a page fault, one page is allocated in both DRAM and PCM, but only the DRAM page is written. When a DRAM page is evicted, it is written to the PCM only if it has been updated. Liu et al. [11] proposed a hardware/software cooperative caching (HSCC) scheme for hybrid DRAM-NVM memory architectures. DRAM and PCM are physically managed by OS in a flat address space, but DRAM is used as a cache for PCM in logical. TLB entries and page table entries are modified to maintain address mappings between DRAM and NVM pages. Hot NVM pages are migrated to a DRAM cache based on a utility-based cache filtering policy. Vasilakis et al. [18] proposed Hybrid2, a hybrid memory system supporting both caching and page migration. It uses only a small fraction of DRAM as a cache, and keep tags in on-chip SRAM at a reasonable cost. The remaining DRAM capacity is used as main memory in a flat address space of the hybrid memory system, and is managed by transparent data migration.
Parallel Memory Architecture. Yoon et al. [19] proposed a page migration strategy based on row buffer locality for hybrid memory systems composed of PCM and DRAM. Since a row buffer miss in PCM causes longer latency and increased energy consumption than that of DRAM, the strategy migrates data blocks in PCM with relatively high row buffer miss rates to DRAM, whereas those with a high row buffer hit rate still remain in PCM. Dhiman et al. [20] presented a hardware-supported hot page migration mechanism to save energy and prolong the lifetime of PCM. It monitors page accesses to PCM with a hybrid memory controller which notifies the OS to migrate the hot page to DRAM. Lee et al. [21] proposed CLOCK-DWF, a DRAM page replacement mechanism for parallel DRAM/NVM hybrid memory architectures according to write counts of NVM pages. It can effectively reduce the write operations on PCM and extend its lifetime. Peng et al. [22] proposed FlexHM to flexibly and efficiently use hybrid memory resources in cloud computing and virtual machine environments. FlexHM employs a two-layer NUMA architecture to place DRAM and Intel Optane persistent memory, and exploits NUMA memory management mechanisms to facilitate page migration between hot NVM pages and cold DRAM pages. Hirofuchi et al. proposed Raminate [23], a hybrid memory management system for virtualization environments. The hypervisor can periodically scan and clear the dirty bit of the extended page table (EPT) to track page accesses in virtual machines, and migrate hot pages to DRAM by adjusting the address mappings between virtual machines and the host machine dynamically.
These two hybrid memory architectures are suitable for different scenarios. For the hierarchical architecture, since the DRAM cache, which is managed by hardware is faster than NVM, it is more suitable for applications with good data locality. However, applications with poor memory access locality may cause frequent DRAM cache thrashing, which may even degrade the performance of the memory sub-system. In parallel architectures, both NVM and DRAM are used as main memory. A common optimization scheme is to distribute frequent write operations on DRAM pages as much as possible. However, this optimization relies on page access monitoring and hot page migration between NVM and DRAM, resulting in rather high performance overhead. This is a key challenge for the parallel hybrid memory architecture.
The commercially available Intel Optane DC persistent memory modules (DCPMM) offers two operation modes, i.e., memory mode and APP direct mode. These two modes typically utilize DRAM and Optane DCPMM in hierarchical and parallel architectures, respectively. However, one architecture can be converted into another one only if the physical server is reconfigured and rebooted. To the best of our knowledge, there is not a hybrid memory system that can dynamically convert the parallel architecture into the hierarchical architecture at runtime, and vice versa.
3. Design and Implementation
We describe our dynamic reconfigurable hybrid memory architecture Transformer in detail in this section. Transformer is an OS-supported reconfigurable hybrid memory architecture to efficiently use DRAM and NVM without redesigning the hardware architecture. It converts the parallel architecture into the hierarchical architecture and vice versa according to the proportion of accessed pages’ hotness. As illustrated in Figure 2, Transformer is composed of three modules, i.e., page hotness monitoring, architecture dynamic reconstruction, and hot page migration. We present these three modules in the following.
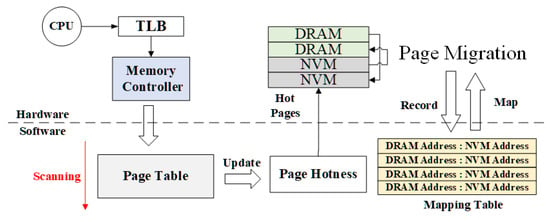
Figure 2.
Architecture of Transformer.
3.1. Page Hotness Monitoring
Transformer aims to improve the performance of hybrid memory systems through page migration. Thus, we should monitor the access frequency of memory pages at first. There is not enough hardware support for counting the number of memory page accesses in the traditional ×86 architecture. Modern operating systems only provide “dirty” and “access” bits in a page table entry to record the state of a page. However, these two bits cannot record the number of page accesses in a small time interval. They are not sufficient to guide the selection of frequently accessed memory pages precisely. Many previous studies propose dedicated hardware to count the number of page accesses [11]. However, the hardware design is often too difficult to implement in a real ×86_64 hardware environment. A number of proposals also considered page access counting by applications or operating systems [24]. The goal of Transformer is to achieve page migration by software only. After careful deliberation, our architecture counts the number of memory page accesses by scanning the access bit of page table entries periodically, and then identifies the frequently accessed (hot) pages for migration.
3.1.1. Page Access Counting
Most modern operating systems use virtual addresses to manage memory. A page table entry (PTE) is exploited to record the virtual-to-physical address mapping for each page. Due to the vast range of virtual address space, multi-level page tables are used to reduce the storage overhead of PTEs in modern OS. In the newest version of the 64-bit Linux kernel, the number of page table levels reaches four even five. The page size is usually 4 KB, and the lowest 12-bit address is the offset in a page because the address is aligned to 4 KB. As shown in Figure 3, the lowest 12 bits of the last level page table record the status of a page. Among them, the access bit (red ’A’) is used by the kernel to judge whether this page should be reclaimed. Translation Lookaside Buffer (TLB) only caches pages whose access bit is set to 1. When the access bit is cleared, the entry in the TLB of this page would be flushed. The access bit can be modified by hardware and cleared by OS. Upon a page fault, the CPU needs to perform page table walking to implement virtual-to-physical address translation. Meanwhile, the hardware modifies the access bit of this page.

Figure 3.
Data structure of modified page table entry.
Transformer uses a kernel thread in the background to monitor the page access for each process. For each monitored process, the kernel thread scans page tables and checks the access bit in page table entries periodically. If the access bit has been modified, meaning this page has been accessed recently, we obtain one access count and record it. Then, the kernel thread clears the access bit immediately. In the next period of scanning, the kernel thread will check the access bit again to determine whether this page has been accessed between these two adjacent periods. The kernel thread keeps sampling the access bit till the monitored process is finished. The number of page accesses counted by the kernel thread is not the actual access counts. However, it is unnecessary to track all access counts accurately in our architecture. Instead, it only needs to figure out the top-K hot pages according to the relative access frequency, which can be determined by programmers. In our experiments, we select the top 20% of frequently accessed pages as hot pages, like the previous work [11]. Therefore, the statistical results can reflect the page hotness of the monitored process.
3.1.2. A Level Array for Storing Page Access Counts
As mentioned before, the kernel thread needs to scan the page table of the monitored process and count the access counts. The statistical information includes the starting address of the page, page access counts, and a flag to distinguish whether the page is currently in DRAM or NVM. Theoretically, the virtual memory address space of 64-bit operating systems is . Although the address space actually used in a 64-bit Linux is only 48 bits, it is still very large. However, a process usually uses only a small portion of virtual memory space, and not all virtual pages are accessed due to the data access locality. We only have to scan existing page table entries. If we store all page access counts in a regular array directly, the page access monitoring module would incur significant memory space overhead. Thus, it is essential to design an efficient data structure to store the access counts of memory pages. The multi-level page table is essentially a data structure reflecting the page mappings. Inspired by the idea of the page table, we design a data structure named level array to store the access counts of memory pages. Since the time complexity of accessing and modifying data in the level array is constant, we can quickly obtain and update the access counts of any page with the level array.
The level array adopts a hierarchical structure similar to the page table; it allocates memory according to the number of data elements stored in it. As shown in Figure 4, a level array is composed of multiple layers, and each layer consists of several nodes. Each node is the same size as a memory page. A level array uses a chained structure, which means nodes between each layer are connected by pointers. Therefore, it does not need a continuous large memory space. Only leaf nodes in the last layer store the actual data elements. The other branch nodes store pointers that point to the next layer. The level array uses a reference counting mechanism to free the memory of useless data in time. Each branch node records the number of nodes in the next layer it points to. When the number becomes zero, it means that this layer has become the last layer. Therefore, it will release the memory of nodes in the next level to avoid unnecessary memory waste. The level array also stores a bitmap in the leaf node to verify whether the data stored in the leaf nodes are valid or not. The bitmap has as many bits as the quantity of data elements stored. By setting and clearing the values on the corresponding bits in the bitmap, we can determine whether the data elements in the leaf node are valid or not.
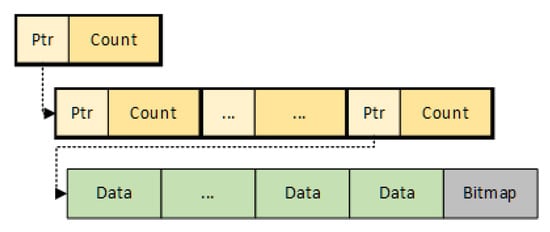
Figure 4.
Schematic diagram of a level array.
A level array needs to determine the range of data elements in advance. For instance, when the level array is designed to store the memory pages-access counts, the index range of the level array is the entire virtual address space. The number of layers is dynamically adjusted by the volume of data elements actually stored. A level array with only one layer contains only one leaf node. As mentioned before, the size of each node is the same as the size of a page, which is 4 KB, so the level array of only one layer can store 4096/datasize data elements, where the datasize represents the size of the data element. If the level array of one layer is not enough to store all data elements, it will expand to two layers. The original leaf node in the first layer becomes a branch node, and the nodes in the second layer become leaf nodes. The first layer contains several branch nodes; each branch node contains a pointer to the next layer and a counter that is used for reference counting. In 64-bit systems, each branch node occupies 8 × 2 bytes, so one page can contain 256 branch nodes. Therefore, a two-layer level array can store the actual number of data elements up to 256 × 4096/datasize. The capacity of the level array increases exponentially by the number of layers. However, the increase in layers will result in an additional query overhead. Thus, the actual number of layers is the minimum number that meets the storage requirements. Assume that the minimum number of layers is denoted by n and the maximum number of data elements that the level array can store is denoted by maxlen. We can calculate the number of leaf nodes that one page can store, i.e., leafperpage with Equation (1), and the number of branch nodes that one page can store, i.e., branchperpage with Equation (2). Equation (3) reflects the relationship between n and maxlen:
When the monitoring thread finishes, the memory of the level array needs to be reclaimed. The level array also stores a bitmap in the leaf node to verify whether the data stored in the leaf nodes is valid or not. The bitmap has as many bits as the amount of data elements stored in each leaf node. By setting and clearing the values on the corresponding bits in the bitmap, we can determine whether the data elements in the leaf node are valid or not.
3.2. Architecture Dynamic Conversion
Transformer organizes both NVM and DRAM in a parallel architecture physically. The NVM and DRAM are both visible to the operating system as main memory. Transformer also supports the hierarchical hybrid memory architecture logically via maintaining a DRAM-to-NVM address mapping in the OS. It can dynamically convert one architecture into another architecture according to the memory hotness. To construct the hierarchical architecture, the DRAM-to-NVM address mapping is essential maintained by a hash table. The key and value of the hash table entry are the physical address of the DRAM page and the corresponding NVM page. The mapping table entry uses a flag field to distinguish whether the entry is valid or not.
To describe the reconfiguration function more clearly, We list key notations and programming APIs in Table 1. Transformer is a parallel memory architecture by default. At first, the total_pages, hot_pages and type are initialized as 0. When the kernel thread starts the monitoring, it not only records the number of page accesses, but also calculates the proportion of hot pages. Transformer dynamically reconstructs the hybrid memory architecture according to the proportion of hot_pages.

Table 1.
Notations and APIs.
When the “access” or “dirty” bits of a page is set during a period of sampling, the total_pages increases by 1. If the number of access counts exceeds the threshold of hotness, the hot_pages will increase by 1. When total_pages increases, the ratio between hot_pages and the total_pages is still lower than the threshold of hierarchical architecture; this implies that the monitored process accesses memory pages roughly uniformly. The architecture should behave as the parallel architecture. It will check the type and do nothing if it is just a parallel architecture. Otherwise, it will shift from the hierarchical architecture to the parallel architecture. The DRAM-to-NVM mappings should be removed in the hash table, and dirty pages that have been cached in the DRAM should be written back to NVM. In contrast, it establishes a hash table for storing the physical address mapping between NVM and DRAM pages when the parallel hierarchical architecture is converted into the hierarchical architecture. Transformer keeps monitoring the hot_pages ratio and dynamically converts itself into an appropriate architecture for applications. The pseudo-code of architecture dynamic conversion is shown in Algorithm 1.
| Algorithm 1: Architecture dynamic conversion. |
 |
3.3. Page Migration
The parallel hybrid memory architecture achieves page migration by OSes, in contrast to the hierarchical hybrid memory architecture in which the DRAM cache is completely managed by hardware. We design different page migration mechanisms for the two modes in Transformer.
3.3.1. Page Migration in the Parallel Architecture
For the parallel hybrid memory, our architecture migrates the NVM pages to DRAM when the number of access counts exceeds the threshold of page hotness, and the NVM pages is reclaimed after the page migration. In the Linux kernel, a move_pages system call is implemented. It provides users with the opportunity to migrate pages between different non-uniform memory access (NUMA) nodes. Based on the move_pages, Transformer can perform page migration between different NUMA nodes.
Figure 5 shows the process of page migration in the parallel architecture. First, the operating system allocates a new DRAM page to accommodate the migrated NVM page. Since the Linux kernel provides alloc_pages_node and other similar functions, we can directly use these functions to allocate pages in DRAM or NVM. Second, all page table entries mapping to this NVM page should be unmapped in the page table according to the table entries in the reverse mapping table. After unmapping, the access permission information, and the data of the NVM page will be copied to the newly allocated DRAM page. Third, we update the page table entries to establish a mapping between the virtual and physical addresses of the newly allocated page, and invalidate the corresponding entry in the TLB. Finally, the original NVM page is reclaimed.
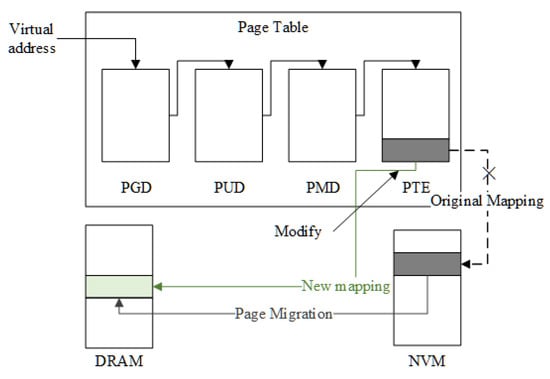
Figure 5.
The page migration process in the parallel architecture.
3.3.2. Page Migration in the Hierarchical Architecture
For the hierarchical hybrid memory architecture, DRAM and NVM are architected in a cache/memory hierarchy logically. A page migration may be involved in caching a NVM page or evicting a DRAM page and writing back to the NVM.
As shown in Figure 6, like the parallel hybrid memory architecture, we should first allocate a new page in DRAM or NVM, and then copying the data to the new page. After that, all page table entries mapping to old pages should be updated to map to the new page. However, unlike the parallel hybrid memory architecture, an NVM page is not reclaimed after it has been migrated to DRAM. Both the physical addresses of the NVM and the DRAM pages are recorded in the hash table. When there is no available capacity in DRAM, the DRAM page with the lowest access counts should be evicted and written back to the mapped NVM page. After a page is evicted from DRAM, the DRAM page and the corresponding entries in the hash table are deleted to free the DRAM space.
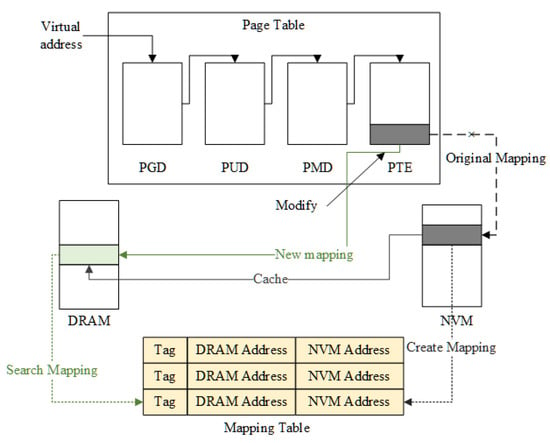
Figure 6.
The page migration process in the hierarchical architecture.
4. Evaluation
We evaluate Transformer with several standard benchmarks and analyze the performance of Transformer with and without architecture dynamic conversions.
4.1. Experimental Setup
We use a server equipped with DRAM/NVM hybrid memory to conduct our experiments. Table 2 shows the configuration of the hybrid memory system. We use typical benchmarks from the SPEC CPU2006 [25], PARSEC [26], and Graph500 [27] to evaluate the performance of our architecture, as shown in Table 3. We run different benchmarks with DRAM-only, NVM-only, hybrid memory using a hierarchical architecture (H.S.), hybrid memory using a parallel architecture (P.S.), and our dynamic reconfigurable hybrid memory architecture (Dynamic).
Table 2.
Configurations of our hybrid memory system.
Table 3.
Workloads.
DRAM-only: In the DRAM-only architecture, we use 640 GB DRAM as the main memory. Obviously, the experimental results in this DRAM-only architecture are the best among all above memory systems. We set it as the baseline and the performance upper-bound.
NVM-only: In the NVM-only architecture, there is no page migration or caching. Theoretically, this architecture has the lowest performance.
H.S.: DRAM is configured as a cache for the NVM. According to Loh [16], DRAM is managed as a 29-way set-associative cache, and a missmap is established in the last-level cache.
P.S.: DRAM and NVM are managed by OSes in a flat address space. Hot pages are migrated from NVM to DRAM according to a hotness threshold described in Section 3.
Transformer: Our reconfigurable hybrid memory architecture can be converted between hierarchical and parallel architectures dynamically at runtime according to the hot page monitoring.
We exploit the hotness monitoring module to count the number of total accessed memory pages and hot pages of these programs. Because there is a significant difference between experimental results of different benchmarks, we normalize all results to represent them in the same figures. We use the DRAM-only system as the baseline; all other experimental results are normalized to the baseline. We also measure the overhead of the architecture dynamic conversions.
4.2. Experimental Results
Figure 7 shows the page access counts of programs tracked our page access monitor. The total pages represent the amount of pages scanned by the page hotness monitoring module during the runtime of the program, i.e., the amount of pages the program has touched in memory. Hot pages represent the amount of memory pages that exceeds the hot page threshold. For a relative small hotness threshold, the proportion of hot pages is rather high for applications with a good data locality or memory-intensive applications, such as sjeng, lbm, and streamcluster.
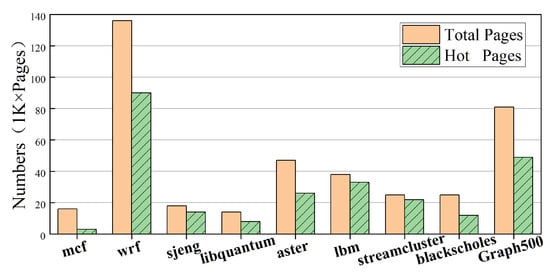
Figure 7.
Numbers of total accessed pages and hot pages.
Figure 8 shows that the ratio of hot pages varies with the time for different workloads in SPEC CPU2006. We can find that the hot page ratio of sjeng varies significantly, while mcf, libquantum, aster, and lbm are relatively stable. The memory access intensity of mcf is rather low, and the proportion of hot pages always remains low. Since libquantum accesses memory intensively, the proportion of hot pages is always high. Aster has a good temporal locality of memory accesses, and thus generates large amounts of hot pages in a very brief period of time and a high percentage of hot pages. Similarly, lbm has a good spatial locality, and thus a large portion of hot pages are identified.
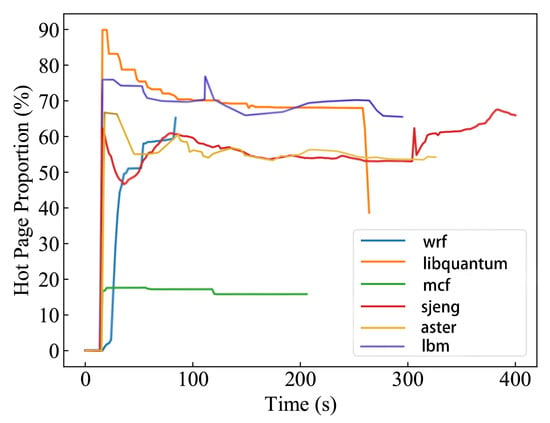
Figure 8.
The proportion of hot pages identified in SPEC CPU2006.
Figure 9 shows that Transformer can effectively improve the performance of applications in SPEC CPU2006, PARSEC, and Graph500. libquantum shows the best performance in Transformer because libquantum is a memory-intensive application with good data locality. As most memory accesses are spread over a small portion of memory space, these memory pages reach the threshold of hot pages faster than other programs. On the other hand, libquantum only requires a few page migrations due to a small memory footprint, and thus causes less performance overhead. The aster has similar performance in the H.S. and dynamic modes, but much better than that in the P.S. mode. The reason is that aster has good temporal locality, and pages are accessed in a very short time. In the H.S. mode, DRAM is able to cache a large number of hot pages and these hot pages have a high reuse rate. In our dynamic mode, aster is actually running in the hierarchical mode which has a similar performance to the H.S. mode. In contrast, lbm runs more efficiently in the P.S. mode because of good spatial locality. In the P.S. mode, as one migration contains 256 B data, lbm is able to get quick access to the adjacent data of the current hot data in DRAM. Furthermore, we find that the execution time of programs has a slight effect on the performance improvement. For example, the performance improvement of blackscholes is not significant. Since the execution time of blackscholes is only 2 min in our experiment, it cannot identify most hot pages and migrate them to DRAM in a very short time, and thus can only achieve slight performance improvement from page migrations. Therefore, we can reduce the threshold of hot pages slightly for these applications to migrate more pages.
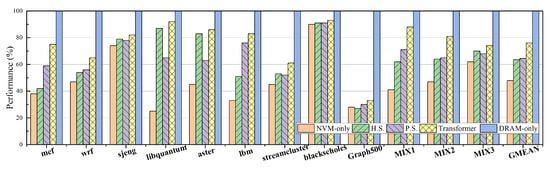
Figure 9.
The normalized performance of applications in different memory systems.
Figure 10 shows the breakdown of execution time in different hybrid memory architectures. We can find that libquantum spends more than 90% of execution time in the hierarchical hybrid memory. The reason is that the memory-intensive libquantum has a good data locality, and our hybrid memory system can quickly convert the parallel architecture into the hierarchical architecture. In contrast, since mcf is not a memory-intensive application, it runs in the parallel memory architecture at most of time. For Graph500, Transformer achieves very limited performance improvement compared with parallel and hierarchical memory architectures (i.e., H.S and P.S) because most data accessed by Graph500 have a relatively small reuse distance. Although Graph500 shows a large memory footprint, most pages are only accessed a few times in a very short period. After our hybrid memory system identifies the hot pages and migrates them from NVM to DRAM, these pages may be rarely accessed. Thus, Graph500 can only gain little performance benefit from page migrations. Overall, our dynamic reconfigurable hybrid memory architecture achieves 62% (up to 2.7×) performance improvement on average compared with the NVM-only architecture, and improves the application performance by up to 79% and 42% (21% and 24% on average) compared with H.S. and P.S., respectively.
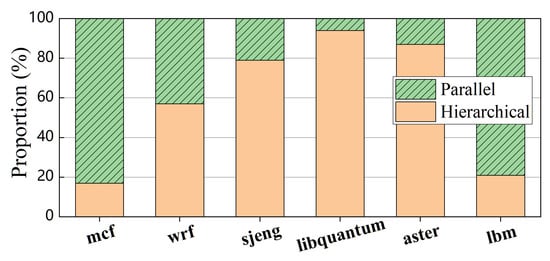
Figure 10.
Execution time of different memory architectures.
We also evaluate the cost of architecture dynamic conversion, as shown in Figure 11. Specifically, Figure 11a shows the times that the architecture reconfiguration function is triggered during the execution of applications, and Figure 11b shows the total time cost spent in reconfiguring the memory architecture. We find that our architecture leads to the most number of reconstructions and the highest time overhead for sjeng. The reason is that the proportion of hot pages in sjeng changes dynamically over time. In contrast, the hot page ratio of mcf, libquantum, and aster are relatively stable, and thus our architecture only reconstructs a few times during the execution of these applications.
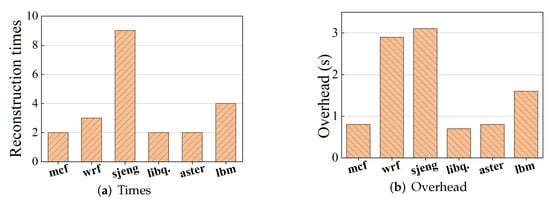
Figure 11.
Overhead of architecture dynamic conversion.
5. Conclusions
In this paper, we present Transformer, an OS-supported reconfigurable hybrid memory architecture to improve the performance of hybrid memory. For this purpose, a lightweight page monitoring mechanism is designed to find out frequently-accessed memory pages by tracking the page access counts. Transformer organizes DRAM and NVM in a single flat address space (i.e., parallel architecture) physically, but also supports a hierarchical architecture by maintaining address mappings between DRAM and NVM pages. Our architecture can switch between parallel and hierarchical architectures dynamically according to applications’ memory access patterns. Experimental results show that our architecture can improve the performance of hybrid memory effectively, especially for memory-intensive applications.
Author Contributions
Methodology, Y.C. and H.L.; Software, Y.C. and G.P.; Data curation, G.P.; Writing—review & editing, H.L.; Supervision, H.L., X.L. and H.J.; Project administration, X.L. and H.J.; Funding acquisition, H.L. and X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported jointly by National Key Research and Development Program of China under grant No.2022YFB4500303, and National Natural Science Foundation of China (NSFC) under grants No.62072198, 61732010, 61825202, 61929103.
Data Availability Statement
The data presented in this study are openly available in SPEC CPU2006, PARSEC, and Graph500 at https://www.spec.org/cpu2006/Docs/install-guide-unix.html, http://parsec.cs.princeton.edu/ and http://www.graph500.org, reference number [24,26,27].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Malladi, K.T.; Shaeffer, I.; Gopalakrishnan, L.; Lo, D.; Lee, B.C.; Horowitz, M. Rethinking DRAM power modes for energy proportionality. In Proceedings of the 2012 45th Annual IEEE/ACM International Symposium on Microarchitecture, Vancouver, BC, Canada, 1–5 December 2012; pp. 131–142. [Google Scholar]
- Hao, Y.; Xiang, S.; Han, G.; Zhang, J.; Ma, X.; Zhu, Z.; Guo, X.; Zhang, Y.; Han, Y.; Song, Z. Recent progress of integrated circuits and optoelectronic chips. Sci. China Inf. Sci. 2021, 64, 201401. [Google Scholar] [CrossRef]
- Deng, Q.; Ramos, L.; Bianchini, R.; Meisner, D.; Wenisch, T. Active low-power modes for main memory with memscale. IEEE Micro 2012, 32, 60–69. [Google Scholar] [CrossRef]
- Lee, B.C.; Ipek, E.; Mutlu, O.; Burger, D. Architecting phase change memory as a scalable DRAM alternative. In Proceedings of the 2009 36th Annual International Symposium on Computer Architecture (ISCA), Austin, TX, USA, 20–24 June 2009; pp. 2–13. [Google Scholar]
- Xu, C.; Niu, D.; Muralimanohar, N.; Jouppi, N.P.; Xie, Y. Understanding the trade-offs in multi-level cell ReRAM memory design. In Proceedings of the 2013 50th ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 29 May–7 June 2013; pp. 1–6. [Google Scholar]
- Kültürsay, E.; Kandemir, M.; Sivasubramaniam, A.; Mutlu, O. Evaluating STT-RAM as an energy-efficient main memory alternative. In Proceedings of the 2013 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Austin, TX, USA, 21–23 April 2013; pp. 256–267. [Google Scholar]
- Cai, M.; Huang, H. A survey of operating system support for persistent memory. Frontiers Comput. Sci. 2021, 15, 154207. [Google Scholar] [CrossRef]
- Cheng, C.; Tiw, P.; Cai, Y.; Yan, X.; Yang, Y.; Huang, R. In-memory computing with emerging nonvolatile memory devices. Sci. China Inf. Sci. 2021, 64, 221402. [Google Scholar] [CrossRef]
- Xue, C.J.; Zhang, Y.; Chen, Y.; Sun, G.; Yang, J.J.; Li, H. Emerging non-volatile memories: Opportunities and challenges. In Proceedings of the 2011 9th IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis (CODES+ISSS), Taipei, China, 9–14 October 2011; pp. 325–334. [Google Scholar]
- García, A.A.; Jong, R.D.; Wang, W.; Diestelhorst, S. Composing lifetime enhancing techniques for non-volatile main memories. In Proceedings of the 2017 International Symposium on Memory Systems (MEMSYS), Alexandria, VA, USA, 2–5 October 2017; pp. 363–373. [Google Scholar]
- Liu, H.; Chen, Y.; Liao, X.; Jin, H.; He, B.; Zheng, L.; Guo, R. Hardware/software cooperative caching for hybrid DRAM/NVM memory architectures. In Proceedings of the 2017 International Conference on Supercomputing (ICS), Chicago, IL, USA, 14–16 June 2017; pp. 1–10. [Google Scholar]
- Chen, T.; Liu, H.; Liao, X.; Jin, H. Resource abstraction and data placement for distributed hybrid memory pool. Front. Comput. Sci. 2021, 15, 153103. [Google Scholar] [CrossRef]
- Jain, S.; Sapatnekar, S.; Wang, J.; Roy, K.; Raghunathan, A. Computing-in-memory with spintronics. In Proceedings of the 2018 Design, Automation and Test in Europe Conference and Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 1640–1645. [Google Scholar]
- Meza, J.; Chang, J.; Yoon, H.; Mutlu, O.; Ranganathan, P. Enabling efficient and scalable hybrid memories using fine-granularity DRAM cache management. IEEE Comput. Archit. Lett. 2012, 11, 61–64. [Google Scholar] [CrossRef]
- Zhang, W.; Li, T. Exploring phase change memory and 3D die-stacking for power/thermal friendly, fast and durable memory architectures. In Proceedings of the 18th International Conference on Parallel Architectures and Compilation Techniques (PACT), Raleigh, NC, USA, 12–16 September 2009; pp. 101–112. [Google Scholar]
- Loh, G.; Hill, M. Efficiently enabling conventional block sizes for very large die-stacked DRAM caches. In Proceedings of the 2011 44th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Porto Alegre, Brazil, 4–5 December 2011; pp. 454–464. [Google Scholar]
- Qureshi, M.K.; Srinivasan, V.; Rivers, J.A. Scalable high performance main memory system using phase-change memory technology. In Proceedings of the 2009 36th Annual International Symposium on Computer Architecture (ISCA), Austin, TX, USA, 20–24 June 2009; pp. 24–33. [Google Scholar]
- Vasilakis, E.; Papaefstathiou, V.; Trancoso, P.; Sourdis, I. Hybrid2: Combining caching and migration in hybrid memory systems. In Proceedings of the 2020 26th IEEE International Symposium on High Performance Computer Architecture (HPCA), San Diego, CA, USA, 22–26 February 2020; pp. 649–662. [Google Scholar]
- Yoon, H.; Meza, J.; Ausavarungnirun, R.; Harding, R.A.; Mutlu, O. Row buffer locality aware caching policies for hybrid memories. In Proceedings of the 2012 30th International Conference on Computer Design (ICCD), Montreal, QC, Canada, 30 September–3 October 2012; pp. 337–344. [Google Scholar]
- Dhiman, G.; Ayoub, R.; Rosing, T. PDRAM: A hybrid PRAM and DRAM main memory system. In Proceedings of the 2009 46th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 26–31 July 2009; pp. 664–669. [Google Scholar]
- Lee, S.; Bahn, H.; Noh, S.H. CLOCK-DWF: A write-history-aware page replacement algorithm for hybrid PCM and DRAM memory architecture. IEEE Trans. Comput. 2014, 63, 2187–2200. [Google Scholar] [CrossRef]
- Peng, B.; Dong, Y.; Yao, J.; Wu, F.; Guan, H. FlexHM: A Practical System for Heterogeneous Memory with Flexible and Efficient Performance Optimizations. ACM Trans. Archit. Code Optim. 2022; Accepted. [Google Scholar] [CrossRef]
- Hirofuchi, T.; Takano, R. Raminate: Hypervisor-based virtualization for hybrid main memory systems. In Proceedings of the 2016 7th ACM Symposium on Cloud Computing (SoCC), Santa Clara, CA, USA, 5–7 October 2016; pp. 112–125. [Google Scholar]
- Agarwal, N.; Wenisch, T.F. Thermostat: Application-transparent page management for two-tiered main memory. In Proceedings of the 2017 22nd International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Xi’an, China, 8 April 2017; pp. 631–644. [Google Scholar]
- Spradling, C.D. SPEC CPU2006 benchmark tools. ACM SIGARCH Comput. Archit. News 2007, 35, 130–134. [Google Scholar] [CrossRef]
- Bienia, C.; Kumar, S.; Singh, J.P.; Li, K. The Parsec benchmark suite: Characterization and architectural implications. In Proceedings of the 2008 17th International Conference on Parallel Architectures and Compilation Techniques (PACT), Toronto, ON, Canada, 25–29 October 2008; pp. 72–81. [Google Scholar]
- Murphy, R.C.; Wheeler, K.B.; Barrett, B.W.; Ang, J.A. Introducing the graph 500. Cray Users Group 2010, 19, 45–74. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).