


Visual Simulator for Mastering Fundamental Concepts of Machine Learning




Abstract
1. Introduction
2. Related Work and Requirements
2.1. Machine Learning in Teaching at Universities
2.2. Analysis of Existing Solutions
- Linear regression
- Decision trees
- k-nearest neighbors method
2.3. Proposed Solution for Tool Development
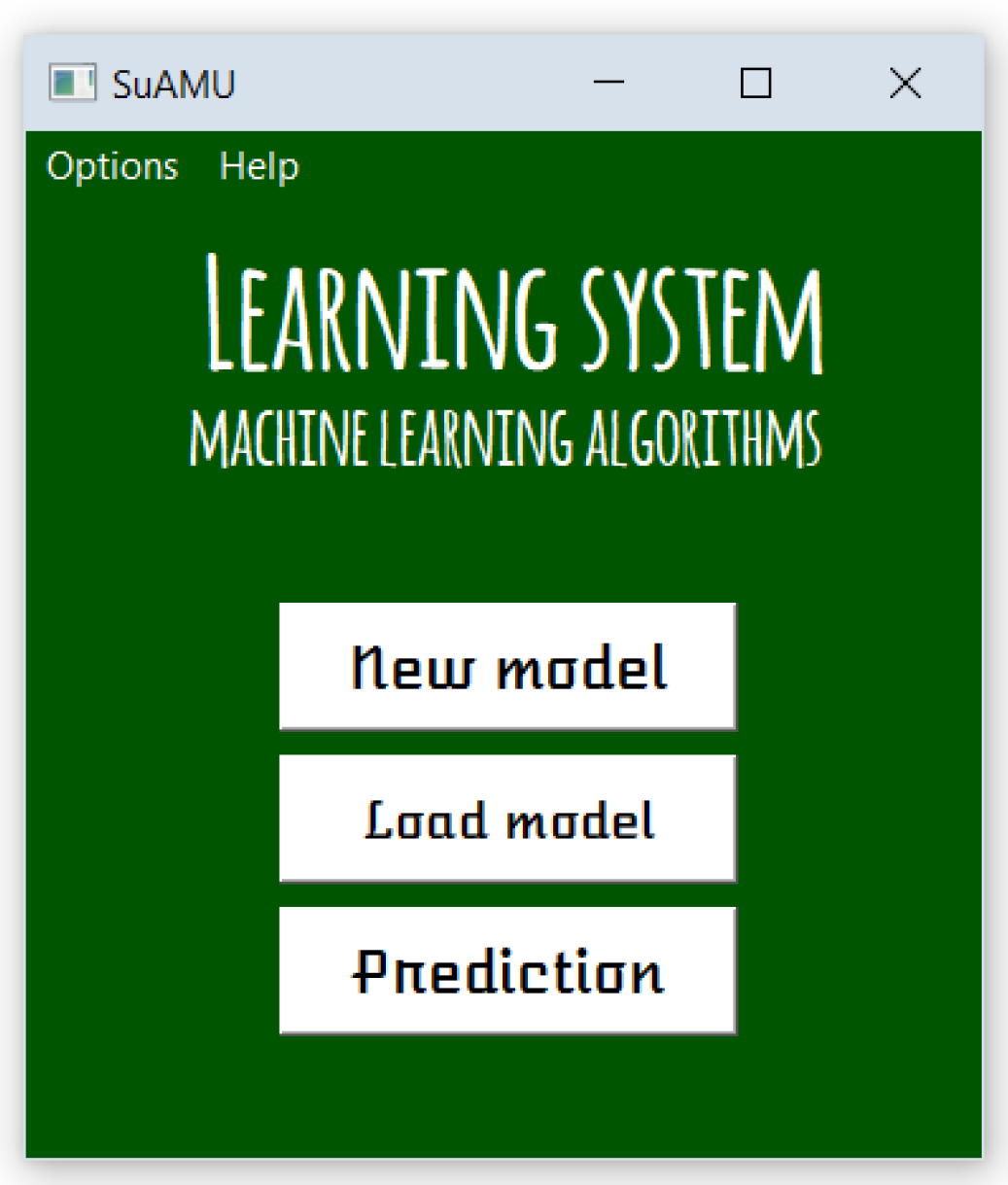
3. System Design with Examples
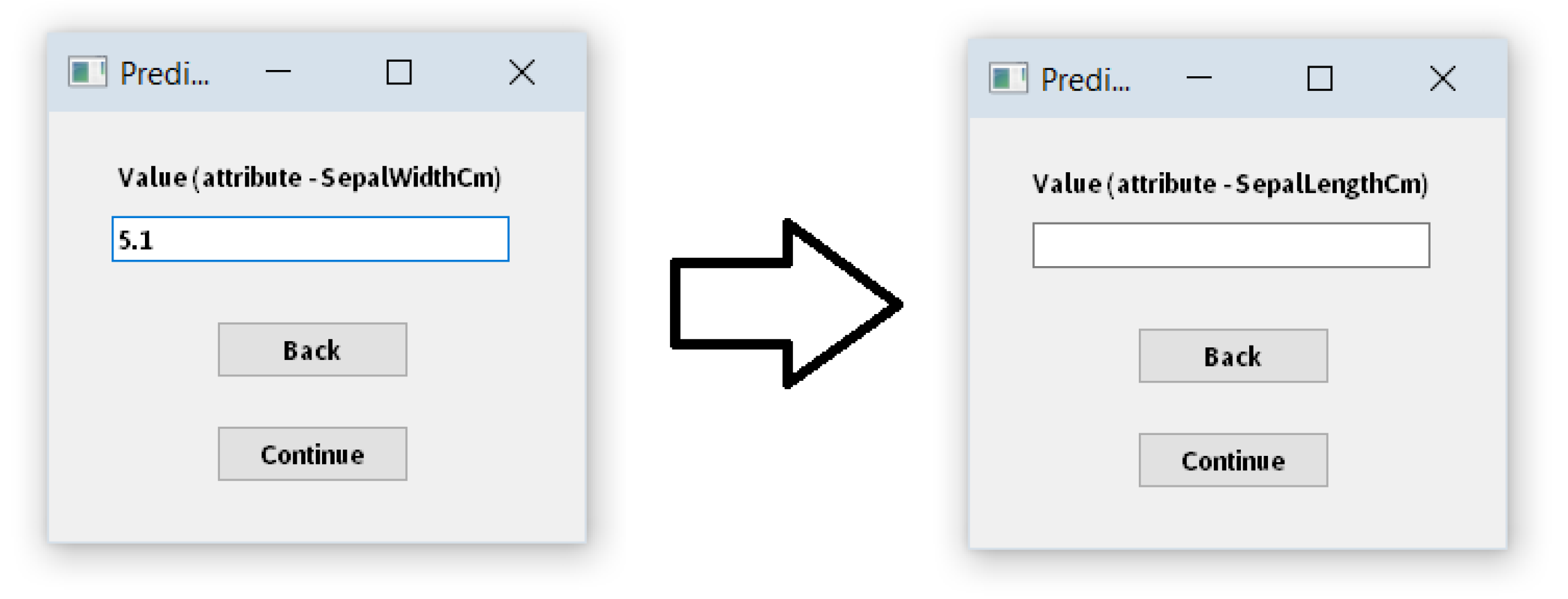
3.1. Creating New Models
- For the linear regression parameter it is possible to choose to use the method of gradient stochastic descent as optimization in searching for the minimum function error, adjusting the maximal number of iterations, and criteria for stopping when finding the minimum of the function, and applying L1 and L2 regularization in model training.
- For the decision tree, there are two ways in which the next attribute for division can be chosen: the attribute with the highest gain or a randomly picked attribute. Additionally, it is possible to choose the function of the division. If the dataset is such that the output value is categorical, possible division functions are entropy and the Gini function. If the dataset is such that the output value is numerical, the possible functions of division are the mean absolute error and mean square error.
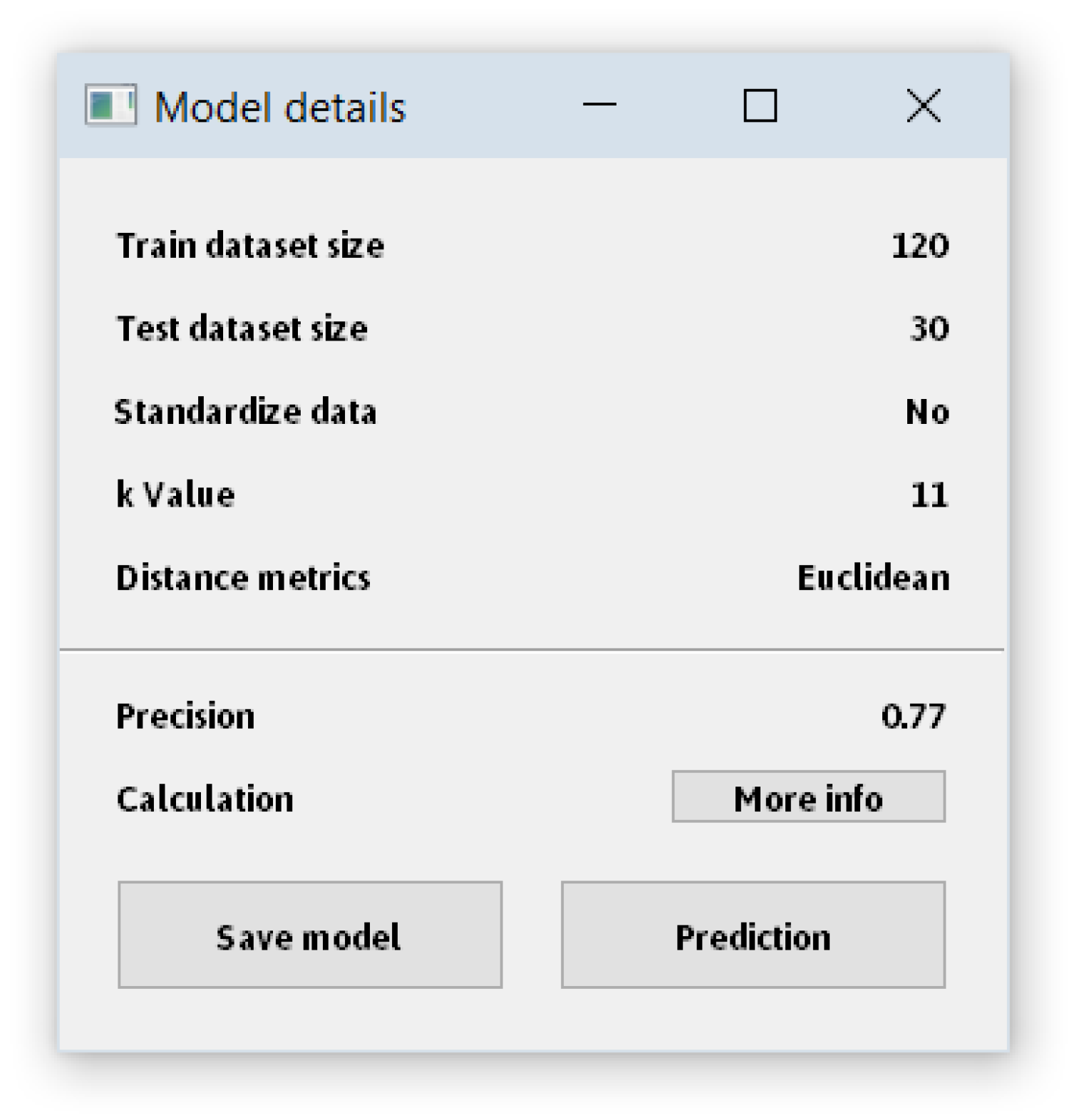
- For the k-nearest neighbor it is possible to choose the value for the k parameter and metrics used to calculate distance. The supported metrics are Euclidan, Manhattan, Chebishev, and Mahalanobis distance.
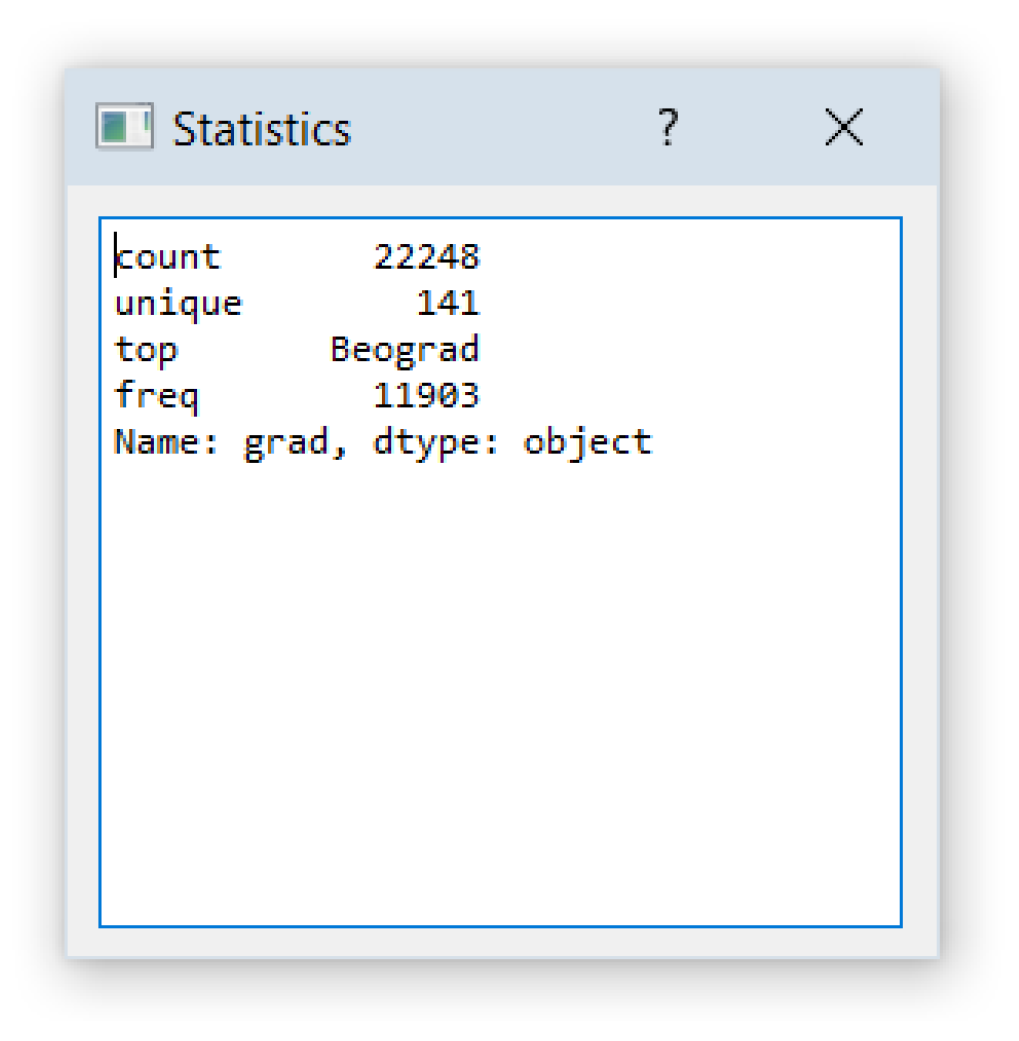
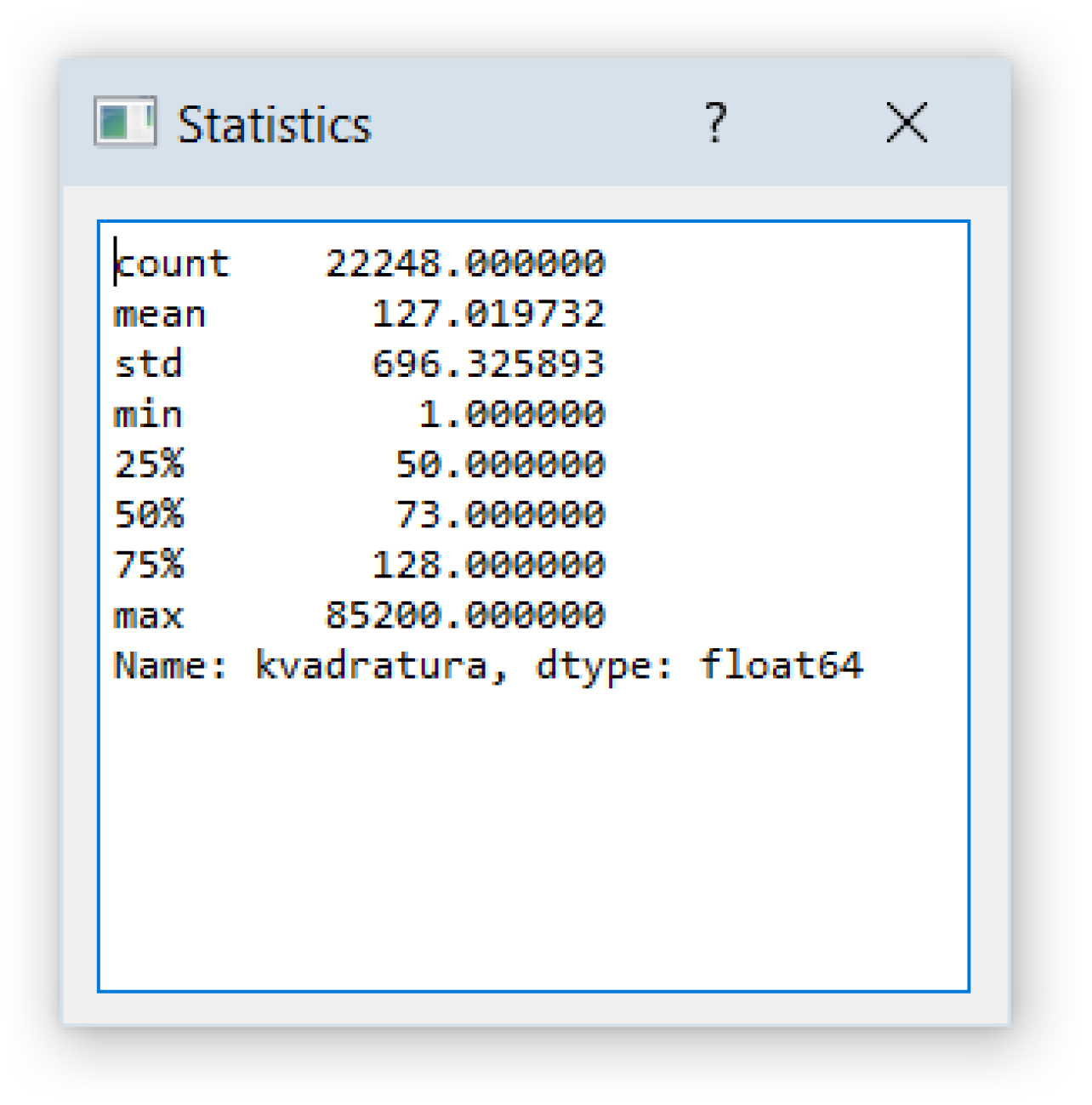
3.2. Analysis of Existing Models
4. Results and Discussion
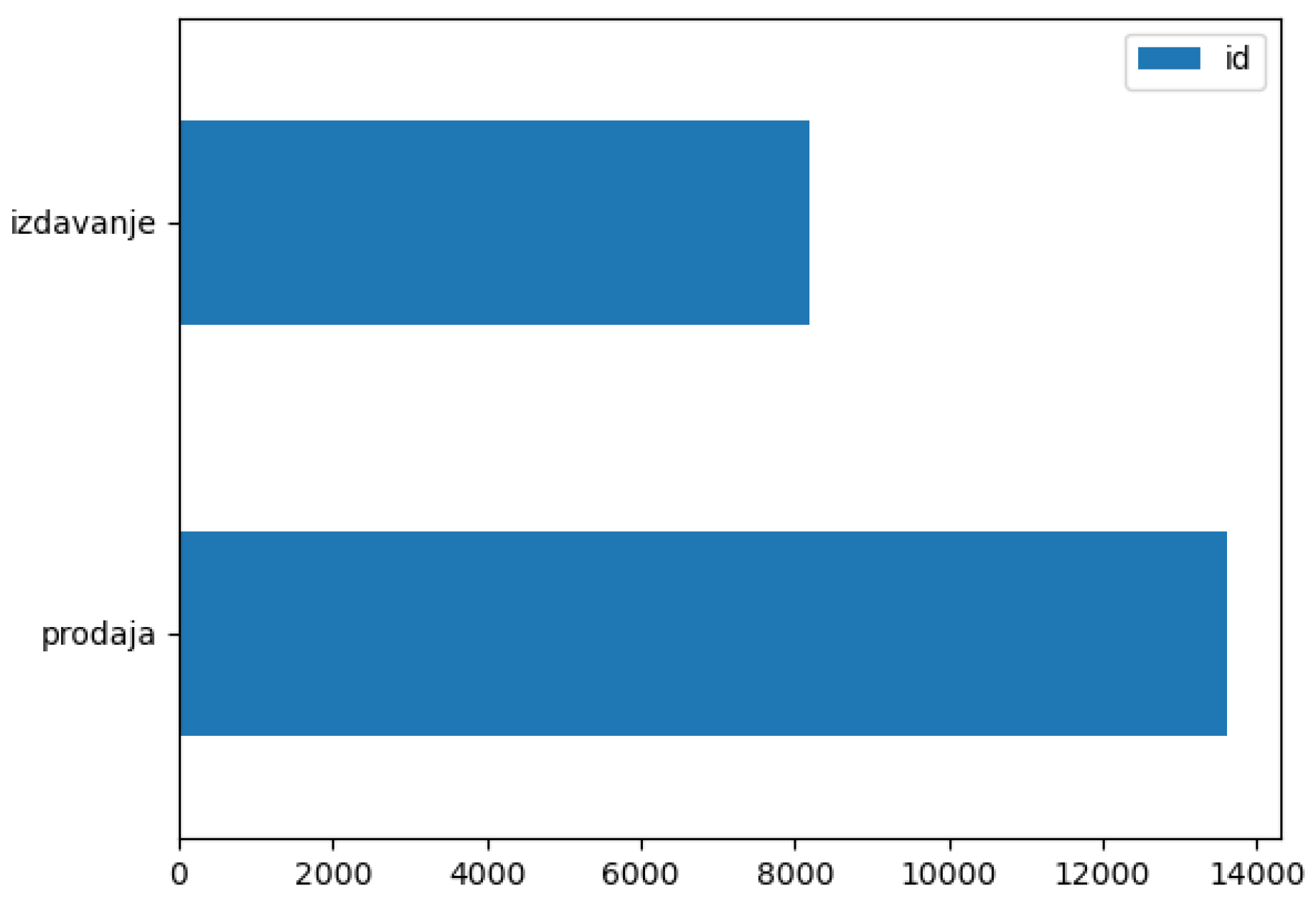
- type of real estate (apartment or house)
- type of offer (rent or sale)
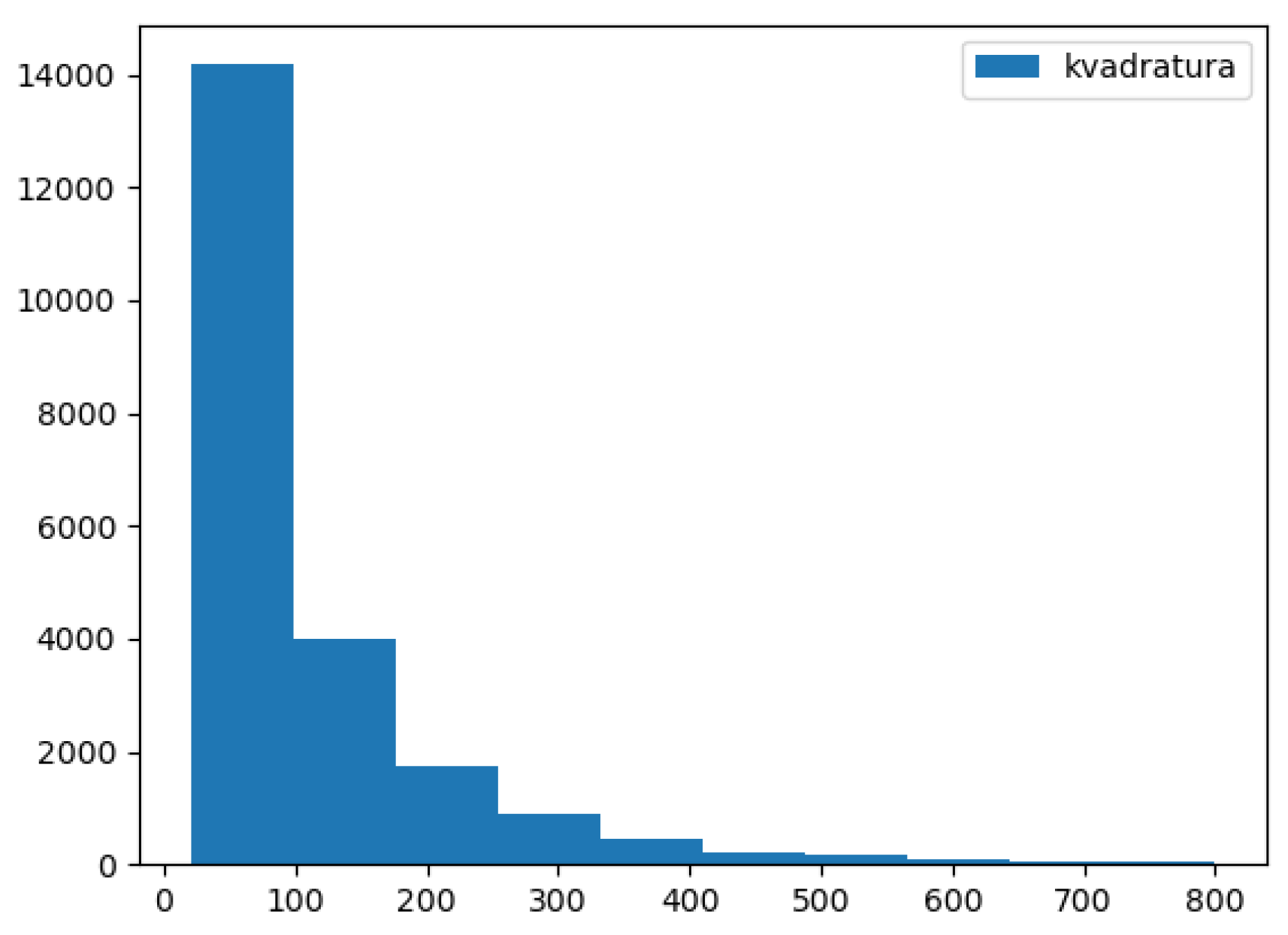
- size
- city
- part of the city
- floor (basement value is −1 and ground floor value is 0)
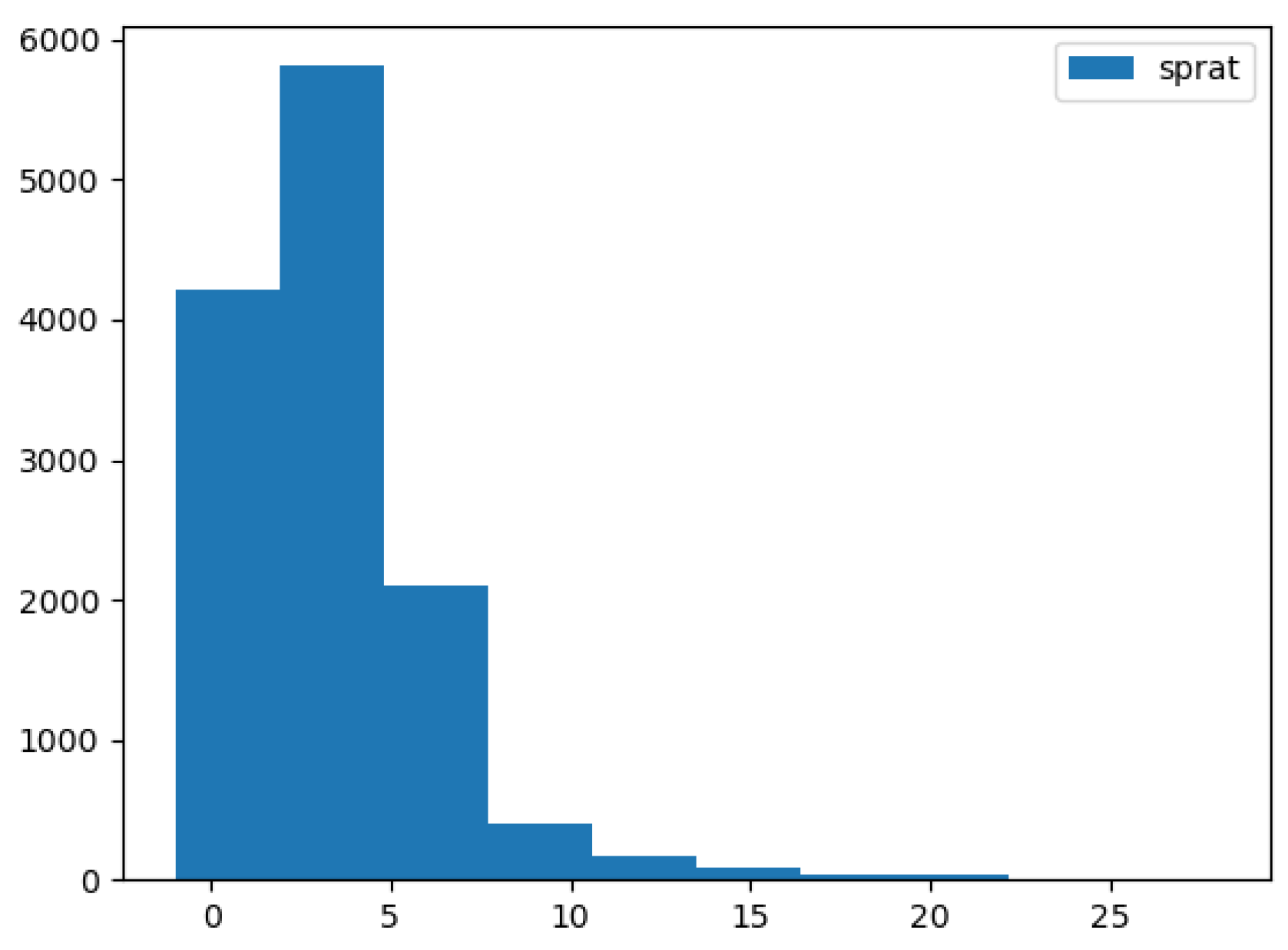
- number of rooms
- number of bathrooms
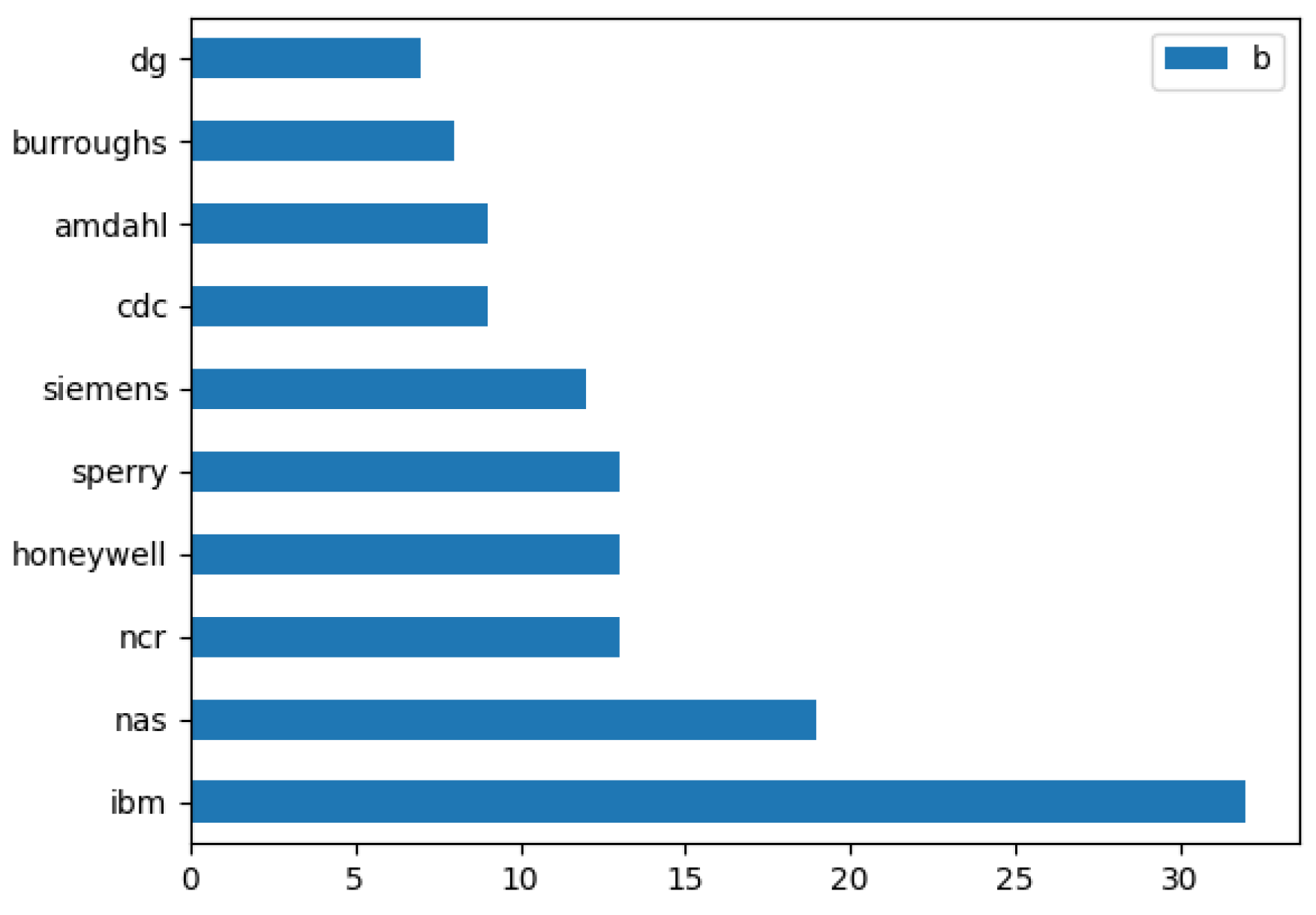
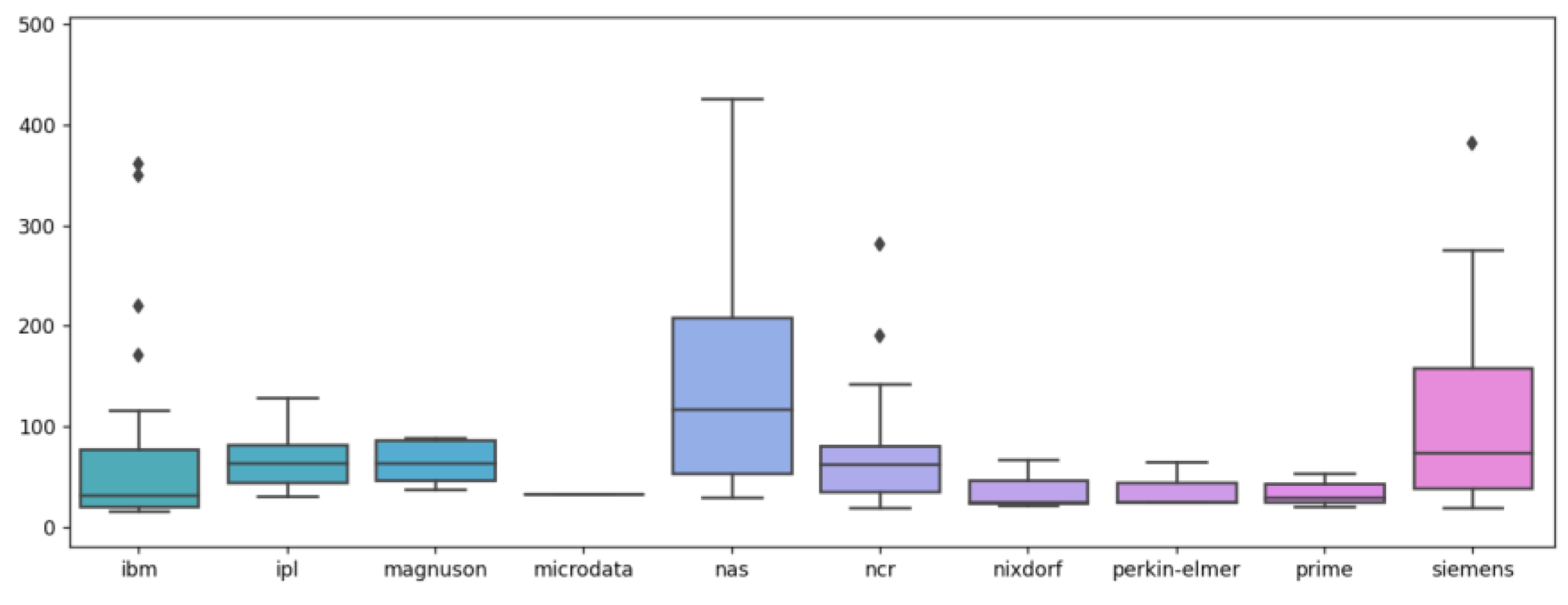
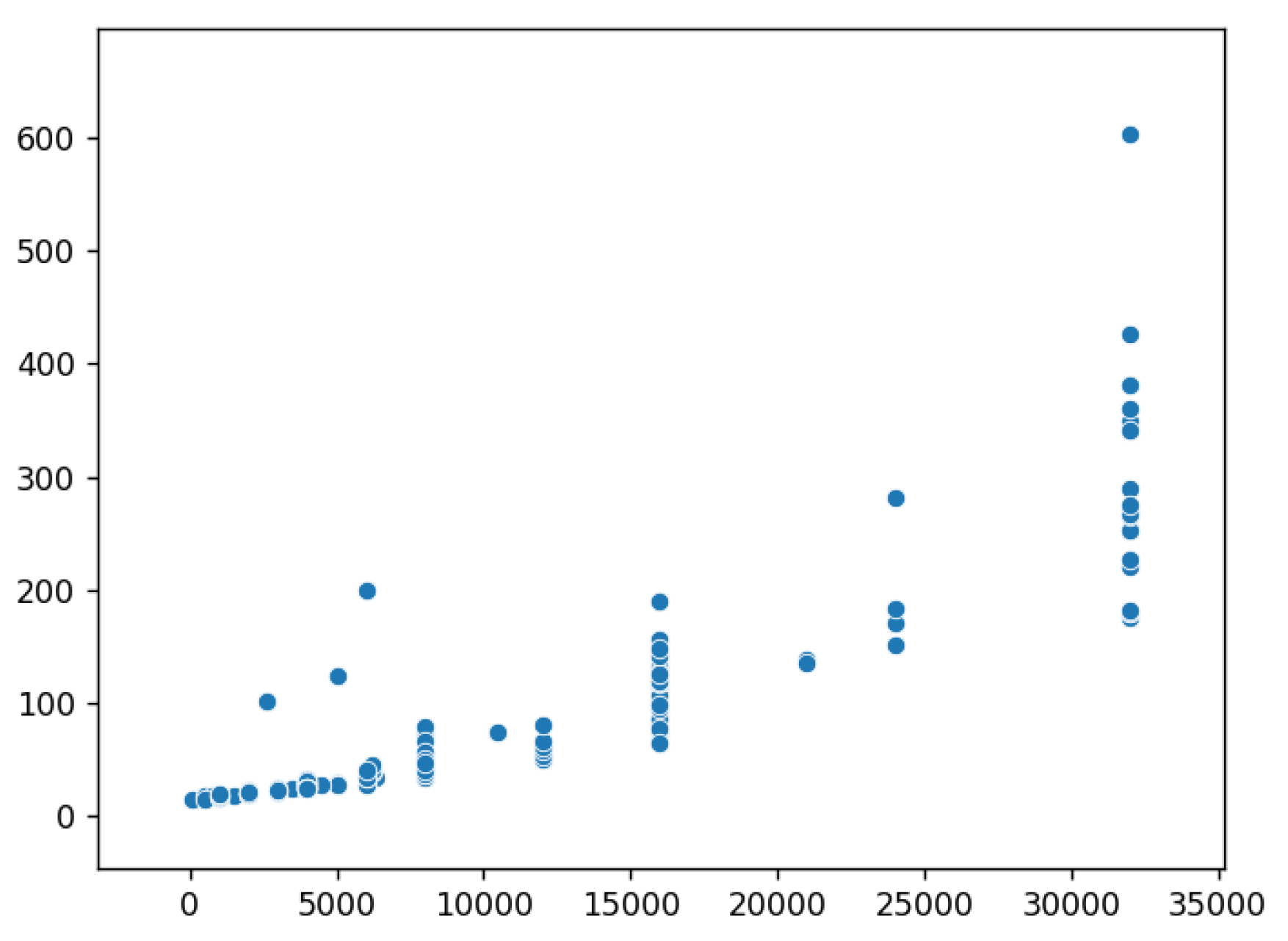
- vendor name,
- model name,
- machine cycle time in nanoseconds,
- minimum main memory in kilobytes,
- maximum main memory in kilobytes,
- cache memory in kilobytes,
- minimum channels in units,
- maximum channels in units.
5. Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 4th ed.; Pearson: London, UK, 2020. [Google Scholar]
- Janičić, P.; Nikolić, M. Artificial Intelligence (Book in Serbian), 1st ed.; University of Belgrade: Belgrade, Serbia, 2021. [Google Scholar]
- Chen, L.; Chen, P.; Lin, Z. Artificial Intelligence in Education: A Review. IEEE Access 2020, 8, 75264–75278. [Google Scholar] [CrossRef]
- Smola, A.; Vishwanathan, S.V.N. Introduction to Machine Learning; Cambridge University: Cambridge, UK, 2008; Volume 32, No. 34. [Google Scholar]
- ACM Computing Curricula Task Force (Ed.) Computer Science Curricula 2013: Curriculum Guidelines for Undergraduate Degree Programs in Computer Science; ACM Inc.: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Hawkins, D.M. The Problem of Overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef]
- Qi, S.; Liu, L.; Kumar, B.S.; Prathik, A. An English Teaching Quality Evaluation Model Based on Gaussian Process Machine Learning. Expert Syst. 2021, 39, e12861. [Google Scholar] [CrossRef]
- Fang, L.; Tuan, L.A.; Hui, S.C.; Wu, L. Personalized Question Recommendation for English Grammar Learning. Expert Syst. 2018, 35, e12244. [Google Scholar] [CrossRef]
- Yoon, D.-M.; Kim, K.-J. Challenges and Opportunities in Game Artificial Intelligence Education Using Angry Birds. IEEE Access 2015, 3, 793–804. [Google Scholar] [CrossRef]
- Nykan, M.; Bissonette, V.; Yilmaz, R.; Ledwos, N.; Winkler-Schwartz, A.; Del Maestro, R.F. The Virtual Operative Assistant: An Explainable Artificial Intelligence Tool for Simulation-Based Training in Surgery and Medicine. PLoS ONE 2020, 15, e0229596. [Google Scholar] [CrossRef]
- Chen, Y.; De Luca, G. Technologies Supporting Artificial Intelligence and Robotics Application Development. J. Artif. Intell. Technol. 2021, 1, 1–8. [Google Scholar] [CrossRef]
- Jiang, L. Virtual Reality Action Interactive Teaching Artificial Intelligence Education System. Complexity 2021, 2021, 5553211. [Google Scholar] [CrossRef]
- Çağlayan, C. Comparison of the Code-Based or Tool-Based Teaching of the Machine Learning Algorithm for the First-Time Learners. Int. Inform. Softw. Eng. Conf. 2019, 1, 1–3. [Google Scholar] [CrossRef]
- Langley, P. An Integrative Framework for Artificial Intelligence Education. Proc. AAAI Conf. Artif. Intell. 2019, 33, 9670–9677. [Google Scholar] [CrossRef]
- Djordjevic, J.; Nikolic, B.; Borozan, T.; Milenković, A. CAL2: Computer Aided Learning in Computer Architecture Laboratory. Comput. Appl. Eng. Educ. 2008, 16, 172–188. [Google Scholar] [CrossRef]
- Draskovic, D.; Batanovic, V.; Nikolic, B. Software system for expert systems learning. Telecommun. Forum TELFOR 2010, 11, 1129–1132. [Google Scholar]
- Draskovic, D.; Nikolic, B. Software System for Expert Systems Learning. In Proceedings of the Africon 2013, Pointe aux Piments, Mauritius, 9–12 September 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Tubić, S.; Cvetanović, M.; Radivojević, Z.; Stojanović, S. Annotated Functional Decomposition. Comput. Appl. Eng. Educ. 2021, 29, 1390–1402. [Google Scholar] [CrossRef]
- Cvetanovic, M.; Radivojevic, Z.; Blagojevic, V.; Bojovic, M. ADVICE—Educational System for Teaching Database Courses. IEEE Trans. Educ. 2011, 54, 398–409. [Google Scholar] [CrossRef]
- Radivojević, Z.; Cvetanović, M.; Jovanović, Z. Reengineering the SLEEP Simulator in a Concurrent and Distributed Programming Course. Comput. Appl. Eng. Educ. 2014, 22, 39–51. [Google Scholar] [CrossRef]
- Draskovic, D.; Cvetanovic, M.; Nikolic, B. SAIL—Software System for Learning AI Algorithms. Comput. Appl. Eng. Educ. 2018, 26, 1195–1216. [Google Scholar] [CrossRef]
- Batanović, V.; Cvetanović, M.; Nikolić, B. A Versatile Framework for Resource-Limited Sentiment Articulation, Annotation, and Analysis of Short Texts. PLoS ONE 2020, 15, e0242050. [Google Scholar] [CrossRef]
- Shanghai Ranking’s Academic Ranking of World Universities. 2020. Available online: https://www.shanghairanking.com/rankings/arwu/2020 (accessed on 14 December 2021).
- Times Higher Education World University Rankings. 2020. Available online: https://www.timeshighereducation.com/world-university-rankings/2020/world-ranking (accessed on 17 December 2021).
- QS World University Rankings. 2020. Available online: https://www.topuniversities.com/university-rankings/world-university-rankings/2020 (accessed on 20 December 2021).
- Association for Computing Machinery (ACM); IEEE Computer Society (IEEE-CS). Computer Engineering Curricula 2016—Curriculum Guidelines for Undergraduate Degree Programs in Computer Engineering. December 2016. Available online: https://ieeecs-media.computer.org/assets/pdf/ce2016-final-report.pdf (accessed on 1 November 2021).
- Association for Computing Machinery (ACM); IEEE Computer Society (IEEE-CS). Information Technology Curricula 2017–Curriculum Guidelines for Baccalaureate Degree Programs in Information Technology. December 2017. Available online: https://www.acm.org/binaries/content/assets/education/curricula-recommendations/it2017.pdf (accessed on 5 November 2021).
- Holmes, G.; Donkin, A.; Witten, I.H. WEKA: A Machine Learning Workbench. In Proceedings of the ANZIIS ’94-Australian New Zealnd Intelligent Information Systems Conference, Brisbane, QLD, Australia, 29 November–2 December 1994; pp. 357–361. [Google Scholar] [CrossRef]
- Nguyen, A.T.; Lease, M.; Wallace, B.C. Mash: Software Tools for Developing Interactive and Transparent Machine Learning Systems. In Proceedings of the ACM IUI 2019 Workshops (IUI Workshops’ 19), Los Angeles, CA, USA, 16–20 March 2019. 7p. [Google Scholar]
- Knoll, B.; Kisynski, J.; Carenini, G.; Conati, C.; Mackworth, A.; Poole, D. AIspace: Interactive Tools for Learning Artificial Intelligence. In Proceedings of the AAAI 2008 AI Education Workshop, Chicago, IL, USA, 13–17 July 2008. [Google Scholar]
- Decision Trees. Available online: http://aispace.org/dTree/index.shtml (accessed on 4 May 2022).
- Derrac, J.; Luengo, J.; Alcalá-Fdez, J.; Fernández, A.; García, S.; Hilario, A.F. Using KEEL Software as a Educational Tool: A Case of Study Teaching Data Mining. In Proceedings of the 7th International Conference on Next Generation Web Services Practices, Salamanca, Spain, 19–21 October 2011; pp. 464–469. [Google Scholar] [CrossRef]
- Eibe, F.; Hall, M.; Trig, L.; Holmes, G.; Witten, I.H. Data Mining in Bioinformatics Using Weka. Bioinformatics 2004, 20, 2479–2481. [Google Scholar]
- Thornton, C.; Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Auto-WEKA: Combined Selection and Hyperparameter Optimization of Classification Algorithms. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 847–855. [Google Scholar] [CrossRef]
- Kalmegh, S. Analysis of WEKA Data Mining Algorithm REPTree, Simple Cart and RandomTree for Classification of Indian News. Int. J. Innov. Sci. Eng. Technol. 2015, 2, 438–446. [Google Scholar]
- Mate, A.; De Gregorio, E.; Camara, J.; Trujillo, J.; Lujan-Mora, S. The Improvement of Analytics in Massive Open Online Courses by Applying Data Mining Techniques. Expert Syst. 2015, 33, 374–382. [Google Scholar] [CrossRef]
- Sneiders, E.; Sjöbergh, J.; Alfalahi, A. Automated Email Answering by Text-Pattern Matching: Performance and Error Analysis. Expert Syst. 2018, 35, e12251. [Google Scholar] [CrossRef]
- Chen, T.; Cheng, H.; Chen, Y. Developing a Personal Value Analysis Method of Social Media to Support Customer Segmentation and Business Model Innovation. Expert Syst. 2019, 36, e12374. [Google Scholar] [CrossRef]
- Alcalá-Fdez, J.; Sánchez, L.; García, S.; del Jesus, M.J.; Ventura, S.; Garrell, J.M.; Otero, J.; Romero, C.; Bacardit, J.; Rivas, V.M.; et al. KEEL: A Software Tool to Assess Evolutionary Algorithms for Data Mining Problems. Soft Comput. 2019, 13, 307–318. [Google Scholar] [CrossRef]
- Lasota, T.; Mazurkiewicz, J.; Trawinski, B.; Trawinski, K. Investigation of Fuzzy Models for the Valuation of Residential Premises Using the KEEL Tool. In Proceedings of the 2008 Eighth International Conference on Hybrid Intelligent Systems, Barcelona, Spain, 10–12 September 2008; pp. 258–263. [Google Scholar] [CrossRef]
- Lasota, T.; Mazurkiewicz, J.; Trawiński, B.; Trawiński, K. Comparison of Data Driven Models for the Valuation of Residential Premises Using KEEL. Int. J. Hybrid Intell. Syst. 2010, 7, 3–16. [Google Scholar] [CrossRef]
- Alcalá-Fdez, J. Keel data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework. J. Mult. Valued Log. Soft Comput. 2011, 17, 255–287. [Google Scholar]
- Triguero, I.; González, S.; Moyano, J.M.; López, S.G.; Fernández, J.A.; Martín, J.L.; Fernández Hilario, A.L.; Jesús Díaz, M.J.; Sánchez, L.; Triguero, F.H. KEEL 3.0: An Open Source Software for Multi-Stage Analysis in Data Mining. Int. J. Comput. Intell. Syst. 2017, 10, 1238–1249. [Google Scholar] [CrossRef]
- Upadhyay, K.; Kaur, P.; Kumar Verma, D. Evaluating the Performance of Data Level Methods Using KEEL Tool to Address Class Imbalance Problem. Arab. J. Sci. Eng. 2022, 47, 9741–9754. [Google Scholar] [CrossRef]
- Singh, A.P.; Gupta, C.; Singh, R.; Singh, N. A Comparative Analysis of Evolutionary Algorithms for Data Classification Using KEEL Tool. Int. J. Swarm Intell. Res. (IJSIR) 2021, 12, 17–28. [Google Scholar] [CrossRef]
- Graczyk, M.; Lasota, T.; Trawiński, B. Comparative Analysis of Premises Valuation Models Using KEEL, RapidMiner, and WEKA. Computational Collective Intelligence. Semantic Web, Social Networks and Multiagent Systems. In Proceedings of the First International Conference, ICCCI 2009, Wroclaw, Poland, 5–7 October 2009; Springer: Berlin/Heidelberg, Germany, 2020; pp. 800–812. [Google Scholar] [CrossRef]
- Zhou, C.; Kuang, D.; Liu, J.; Yang, H.; Zhang, Z.; Mackworth, A.; Poole, D. AISpace2: An Interactive Visualization Tool for Learning and Teaching Artificial Intelligence. Proc. AAAI Conf. Artif. Intell. 2020, 34, 13436–13443. [Google Scholar] [CrossRef]
- Jones, B.; Sall, J. JMP statistical discovery software. WIREs Comput. Stat. 2021, 3, 188–194. [Google Scholar] [CrossRef]
- Chen, M.; Chen, C. Develop JMP 16 Based STEAMS and Six Sigma DMAIC Training Curriculum for Data Scientist. In Proceedings of the International Conference on Industrial Engineering and Operations Management, Rome, Italy, 2–5 August 2021. [Google Scholar]
- Abousalh-Neto, N.; Guan, M.; Hummel, R. Better together: Extending JMP with open-source software. ISI’s J. Rapid Dissem. Stat. Res. 2020, 10, e336. [Google Scholar] [CrossRef]
- Yu, C.H.; Lee, H.S.; Gan, S.; Brown, E. Nonlinear modeling with big data in SAS and JMP. In Proceedings of the Western Users of SAS Software Conference, Long Beach, CA, USA, 20–22 September 2017; pp. 1–12. [Google Scholar]
- Computer Engineering Undergraduate Program, School of Electrical Engineering, University of Belgrade. Available online: https://www.etf.bg.ac.rs/en/studies/bachelor-studies/electrical-and-computer-engineering/2013/computer-engineering-and-information-theory (accessed on 15 May 2022).
- Software Engineering Undergraduate Program, School of Electrical Engineering, University of Belgrade. Available online: https://www.etf.bg.ac.rs/en/studies/basic-academic-studies-bachelor-studies/software-engineering (accessed on 15 May 2022).
- Dataset for Measuring Processor Performance. Available online: https://data.world/uci/computer-hardware/workspace/file?filename=machine.names.txt (accessed on 30 November 2022).
- Dataset for Condition Monitoring. Available online: https://www.kaggle.com/datasets/stephanmatzka/condition-monitoring-dataset-ai4i-2021 (accessed on 1 December 2022).
- Radojičić, D.; Radojičić, N.; Kredatus, S. A multicriteria optimization approach for the stock market feature selection. Comput. Sci. Inf. Syst. 2021, 18, 749–769. [Google Scholar] [CrossRef]
- Battineni, G.; Chintalapudi, N.; Amenta, F. Machine learning in medicine: Performance calculation of dementia prediction by support vector machines (SVM). Inform. Med. Unlocked 2019, 16, 100200. [Google Scholar] [CrossRef]
- Guo, J.; Yang, L.; Bie, R.; Yu, J.; Gao, Y.; Shen, Y.; Kos, A. An XGBoost-based physical fitness evaluation model using advanced feature selection and Bayesian hyper-parameter optimization for wearable running monitoring. Comput. Netw. 2019, 151, 166–180. [Google Scholar] [CrossRef]
- Devedžić, V. Web Intelligence and Artificial Intelligence in Education. J. Educ. Technol. Soc. 2004, 7, 29–39. [Google Scholar]
- Wong, G.K.W.; Ma, X.; Dillenbourg, P.; Huan, J. Broadening Artificial Intelligence Education in K-12: Where to Start? ACM Inroads 2020, 11, 20–29. [Google Scholar] [CrossRef]
- Roll, I.; Wylie, R. Evolution and Revolution in Artificial Intelligence in Education. Int. J. Artif. Intell. Educ. 2016, 26, 582–599. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Course Title | University | Machine Learning Tasks | Inductive Learning | Simple Machine Learning Algorithms | Over-Fitting Problem | Measurement Error | Belonging Group |
|---|---|---|---|---|---|---|---|
| Introduction to Machine Learning | Harvard University | + | + | + | + | + | First group |
| Machine Learning | Harvard University | + | + | Second group | |||
| Machine Learning | Stanford University | + | + | + | + | + | First group |
| Applied Machine Learning | Stanford University | + | + | + | + | Second group | |
| Introduction to Machine Learning | Massachusetts Institute of Technology | + | + | + | + | + | First group |
| Introduction to Machine Learning | University of California, Berkeley | + | + | + | + | + | First group |
| Machine Learning | Princeton University | + | + | + | + | + | First group |
| Machine Learning | Columbia University | + | + | + | + | + | First group |
| Machine Learning & Data Mining | California Institute of Technology | + | + | + | + | + | First group |
| Machine Learning | University of Oxford | + | + | + | + | First group | |
| Machine Learning and Predictive Analytics | University of Chicago | + | + | + | + | + | First group |
| Advanced Machine Learning and Artificial Intelligence | University of Chicago | + | + | Second group | |||
| Statistical Data Mining | Cornell University | + | + | Third group | |||
| Machine Learning for Intelligent Systems | Cornell University | + | + | + | + | First group | |
| Machine Learning for Data Science | Cornell University | + | + | Second group | |||
| Machine Learning Algorithms | University of California, Los Angeles | + | + | + | + | + | First group |
| Introduction to Machine Learning | Johns Hopkins University | + | + | + | + | + | First group |
| Foundations of Machine Learning and Data Science | University College London | + | + | + | + | + | First group |
| Introduction to Machine Learning | University of Washington | + | + | + | + | + | First group |
| Data analytics using Python | University of California, San Diego | + | + | Third group | |||
| Machine learning fundamentals | University of California, San Diego | + | + | + | First group | ||
| Introduction to Machine Learning | University of Pennsylvania | + | + | + | + | + | First group |
| Machine Learning | University of Pennsylvania | + | + | + | + | Second group | |
| Introduction to Artificial Intelligence | University of British Columbia | + | + | Third group | |||
| Introduction to Data Mining | University of Texas at Austin | + | + | Third group | |||
| Sistemas Inteligentes para la Gestión de la Empresa | University of Granada | + | Third group | ||||
| Data Mining with Weka | University of Waikato | + | + | + | + | Third group | |
| Introduction to Machine Learning | Ecole Polytechnique Federale de Lausanne | + | + | + | + | + | First group |
| Machine Learning | Ecole Polytechnique Federale de Lausanne | + | + | + | + | + | First group |
| Machine Learning: Methods and Tools | Technical University of Munich | + | + | + | + | + | First group |
| Machine Learning | Wageningen University & Research | + | + | + | + | + | First group |
| Machine learning for data science | University of Ljubljana | + | + | + | + | + | First group |
| Machine Learning 1 | University of Zagreb | + | + | + | + | + | First group |
| Course Title | Level of Study | University | Lab. Exercises | Tool or Technology for Lab | Project | Tool or Technology for Project | Developed Own Tool |
|---|---|---|---|---|---|---|---|
| Introduction to Machine Learning | bachelor | Harvard University | + | Python | + | Python | |
| Machine Learning | master | Harvard University | + | Python | + | Python | |
| Machine Learning | bachelor | Stanford University | + | Python | |||
| Applied Machine Learning | bachelor | Stanford University | + | Python | |||
| Introduction to Machine Learning | bachelor | Massachusetts Institute of Technology | + | Python | |||
| Introduction to Machine Learning | bachelor | University of California, Berkeley | + | Python | |||
| Machine Learning | bachelor | Princeton University | + | Python | |||
| Machine Learning | bachelor | Columbia University | + | MATLAB, Python | |||
| Machine Learning & Data Mining | bachelor | California Institute of Technology | + | Python | |||
| Machine Learning | bachelor | University of Oxford | + | Lua, Python | |||
| Machine Learning and Predictive Analytics | master | University of Chicago | + | R, Python | |||
| Advanced Machine Learning and Artificial Intelligence | master | University of Chicago | + | Python | |||
| Statistical Data Mining | bachelor | Cornell University | + | R | + | R | |
| Machine Learning for Intelligent Systems | bachelor | Cornell University | + | Python | |||
| Machine Learning for Data Science | bachelor | Cornell University | + | R, Python, Java | |||
| Machine Learning Algorithms | master | University of California, Los Angeles | + | Python | |||
| Introduction to Machine Learning | master | Johns Hopkins University | + | Python, FastDT | + | Python, Java, C# | |
| Foundations of Machine Learning and Data Science | master | University College London | + | Python | + | Seminar paper in Latex text editor | |
| Introduction to Machine Learning | bachelor | University of Washington | + | Python | |||
| Machine Learning | master | University of Washington | + | Python | |||
| Data Analytics using Python | bachelor | University of California, San Diego | + | Python | |||
| Machine Learning Fundamentals | bachelor | University of California, San Diego | + | Python | |||
| Introduction to Machine Learning | bachelor | University of Pennsylvania | + | Weka | + | Python | |
| Machine Learning | master | University of Pennsylvania | + | Python | |||
| Introduction to Artificial Intelligence | bachelor | University of British Columbia | + | Decision Trees [14] | + | Seminar paper in Latex text editor | + |
| Introduction to Data Mining | bachelor | University of Texas at Austin | + | Python, Mash [12] | + | Darwin | + |
| Sistemas Inteligentes para la Gestión de la Empresa | master | University of Granada | + | Keel, Weka | + | R | + |
| Data Mining with Weka | master | University of Waikato | + | Weka | + | Weka | + |
| Introduction to Machine Learning | bachelor | Ecole Polytechnique Federale de Lausanne | + | Python | |||
| Machine Learning | master | Ecole Polytechnique Federale de Lausanne | + | Python | |||
| Machine Learning: Methods and Tools | master | Technical University of Munich | + | Python | |||
| Machine Learning | master | Wageningen University & Research | + | Python | + | Python | |
| Machine learning for data science | master | University of Ljubljana | + | Python | |||
| Machine Learning 1 | master | University of Zagreb | + | Python |
| Tool Name | Simplicity of User Interface | Inclusion of Selected Algorithms | Open Source Software | Good Control of Algorithm Execution | Covered Topics |
|---|---|---|---|---|---|
| Weka | 2 | Linear regression, Decision trees, k-nearest neighbors | yes | 3 | Data preprocessing, Classification, Regression, Clustering |
| Keel | 3 | Linear regression, Decision trees, k-nearest neighbors | yes | 3 | Data preprocessing, Classification, Regression, Clustering |
| JMP | 2 | Linear regression, Decision trees, k-nearest neighbors | no | 2 | Data preprocessing, Classification, Regression, Clustering |
| Decision Trees | 5 | Decision trees | yes | 4 | Classification-Decision trees |
| Model Name | Linear Regression Model |
|---|---|
| Size of the training set | 20,717 |
| Size of the testing set | 1090 |
| Data mixed before division | no |
| Standardized data | yes |
| Optimization SGD | yes |
| Maximum number of iterations | 1000 |
| Stopping criterion | 0.001 |
| L1 regularization | no |
| L2 regularization | yes |
| Model Name | Decision Tree Model |
|---|---|
| Size of the training set | 20,717 |
| Size of the testing set | 1090 |
| Data mixed before division | No |
| Standardized data | Yes |
| Selection of division attributes | Greatest gain |
| Division function | Mean square error |
| Model Name | K-Nearest Neighbor Model |
|---|---|
| Size of the training set | 20,717 |
| Size of the testing set | 1090 |
| Data mixed before division | No |
| Standardized data | Yes |
| K value | 81 |
| Metrics | Euclidean |
| Model Name | Precision |
|---|---|
| Decision tree model | 0.81 |
| k-nearest neighbor model | 0.79 |
| Model Name | Precision for the First Dataset | Precision for the Second Dataset |
|---|---|---|
| Linear regression | 0.94 | 0.88 |
| Decision tree model | 0.98 | 0.91 |
| k-nearest neighbor model | 0.96 | 0.95 |
| School Year | 2018/19 | 2019/20 | 2020/21 | 2021/22 |
|---|---|---|---|---|
| ER-average points | 57.4 | 76.25 | 92.5 | 91.6 |
| SI-average points | 64.1 | 80.0 | 80.8 | 88.33 |
| School Year | 2018/19 | 2019/20 | 2020/21 | 2021/22 | 2022/23 |
|---|---|---|---|---|---|
| Number of enrolled students | 129 | 122 | 143 | 148 | 175 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Milakovic, A.; Draskovic, D.; Nikolic, B. Visual Simulator for Mastering Fundamental Concepts of Machine Learning. Appl. Sci. 2022, 12, 12974. https://doi.org/10.3390/app122412974
Milakovic A, Draskovic D, Nikolic B. Visual Simulator for Mastering Fundamental Concepts of Machine Learning. Applied Sciences. 2022; 12(24):12974. https://doi.org/10.3390/app122412974
Chicago/Turabian StyleMilakovic, Adrian, Drazen Draskovic, and Bosko Nikolic. 2022. "Visual Simulator for Mastering Fundamental Concepts of Machine Learning" Applied Sciences 12, no. 24: 12974. https://doi.org/10.3390/app122412974
APA StyleMilakovic, A., Draskovic, D., & Nikolic, B. (2022). Visual Simulator for Mastering Fundamental Concepts of Machine Learning. Applied Sciences, 12(24), 12974. https://doi.org/10.3390/app122412974