

Employing a Multilingual Transformer Model for Segmenting Unpunctuated Arabic Text

 , , ,
, , ,  and
and
Abstract
:1. Introduction
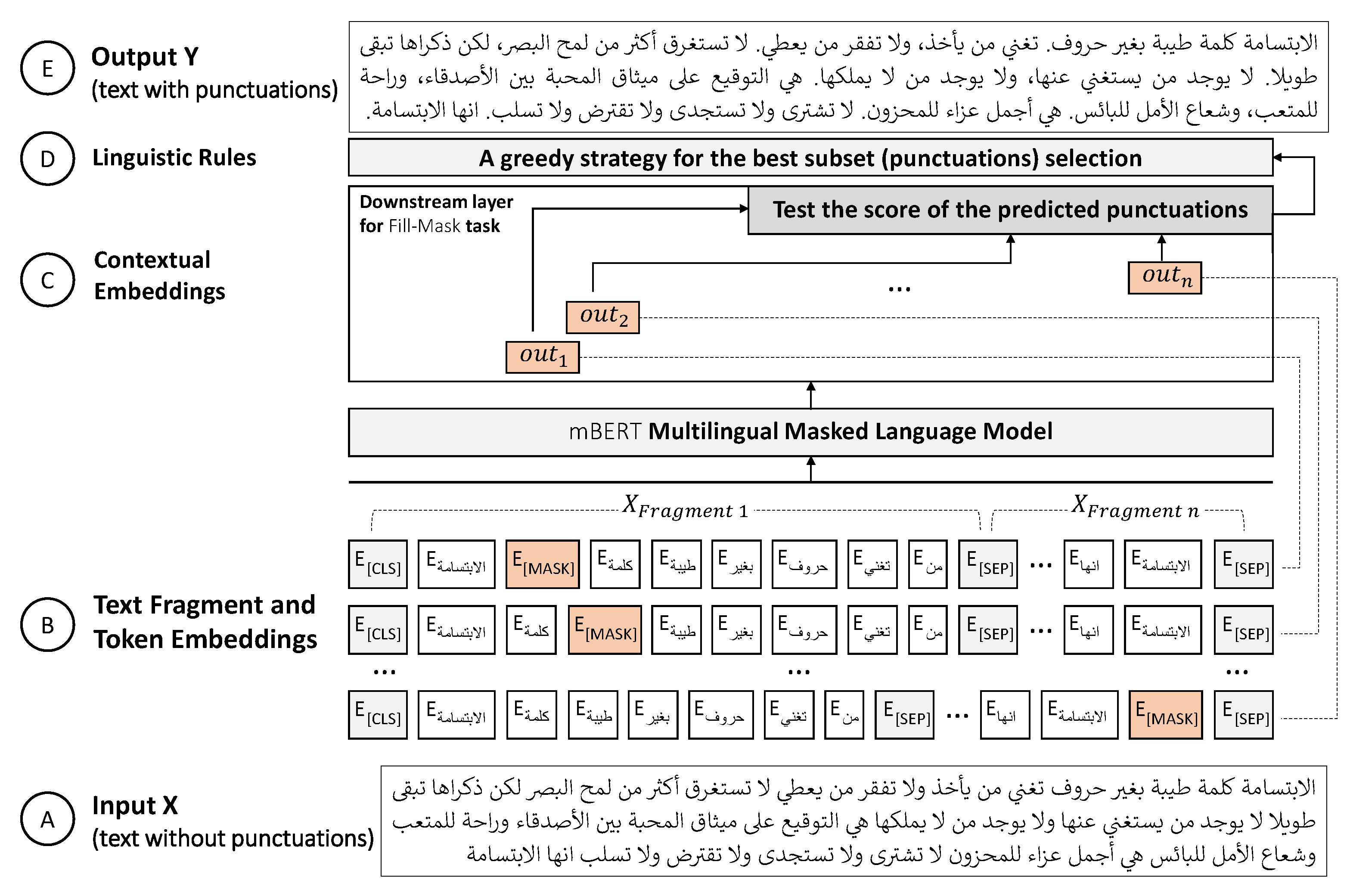
- We propose a punctuation detection approach for splitting a complex Arabic text into a set of simple candidate sentences; each sentence is potentially representing an independent clause. This approach begins with employing an MLM method to detect the missing punctuation in a long text, and then it validates them using straightforward linguistic rules. The originality lies in employing a transfer-based paradigm, for the first time, to address the Arabic text segmentation problem.
- Since our approach can generate a large set of potentially missed punctuations that are prone to prediction errors, we tackle this by proposing a greedy strategy for selecting the best subset punctuations (i.e., subject to the unknown size of the optimal subset).
- We showcase the efficient performance and practicality of our proposal through several experimental evaluations conducted on two public Arabic corpora. The evaluation protocols include standard quantitative metrics with an ablation study and a qualitative human-based judgment. Further, we report on an implementation and make the code publicly available for replicating our experiments (https://github.com/AMahfodh/ArSummarizer, accessed on 14 October 2022).
2. Related Literature
- The natural language understanding (NLU) approaches depending on artificial neural networks, particularly those adopted transformer-based models (e.g., [27]).
- The high computational effort consumed in generating linguistic annotation features;
- The uncertainty in implementing large discourse segmentation, especially with unpunctuated texts;
- The inability to effectively handle multiple textual dialects that often raises out-of-vocabulary (OOV) problems. This inability mainly results from training specific models on a limited available annotated corpus.
3. PDTS: Punctuation Detector for Text Segmentation
| Algorithm 1: The proposed procedure for predicting punctuations in an unpunctuated document using an MLM model. |
 |
| Algorithm 2: The proposed procedure for validating the predicted punctuations in Algorithm 1 and selecting the best ones to be added in X. These added punctuations can be then used as split delimiters for segmenting X. |
 |
3.1. mBERT: Multilingual Masked Language Model
3.2. Arabic Text Fragments and Masked Token-to-Vocab Prediction
3.3. A Greedy Strategy for Selecting the Best Subset Punctuations
4. Experiments and Discussion
4.1. Experiment Setup
4.1.1. Experiment Protocol and Metrics
4.1.2. Arabic Corpora
4.1.3. Baselines
4.1.4. Implementation Details
4.2. Performance Evaluation
4.3. Human Evaluation
- Adequacy (preservation of the source meaning);
- Contextual soundness (in terms of the avoidance of error cases, including (1) the generation of unimportant punctuations and/or (2) the failure in not generating important punctuations);
- Grammaticality (the correctness of the generated punctuations).
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alshanqiti, A.; Namoun, A.; Alsughayyir, A.; Mashraqi, A.M.; Gilal, A.R.; Albouq, S.S. Leveraging DistilBERT for Summarizing Arabic Text: An Extractive Dual-Stage Approach. IEEE Access 2021, 9, 135594–135607. [Google Scholar] [CrossRef]
- Martin, L.; Fan, A.; de la Clergerie, É.; Bordes, A.; Sagot, B. MUSS: Multilingual unsupervised sentence simplification by mining paraphrases. arXiv 2020, arXiv:2005.00352. [Google Scholar]
- Maddela, M.; Alva-Manchego, F.; Xu, W. Controllable text simplification with explicit paraphrasing. arXiv 2020, arXiv:2010.11004. [Google Scholar]
- Niklaus, C.; Cetto, M.; Freitas, A.; Handschuh, S. Context-Preserving Text Simplification. arXiv 2021, arXiv:2105.11178. [Google Scholar]
- Hao, T.; Li, X.; He, Y.; Wang, F.L.; Qu, Y. Recent progress in leveraging deep learning methods for question answering. Neural Comput. Appl. 2022, 34, 2765–2783. [Google Scholar] [CrossRef]
- Alonzo, O. The Use of Automatic Text Simplification to Provide Reading Assistance to Deaf and Hard-of-Hearing Individuals in Computing Fields. SIGACCESS Access. Comput. 2022, 3, 1. [Google Scholar] [CrossRef]
- Gamal, D.; Alfonse, M.; Jiménez-Zafra, S.M.; Aref, M. Survey of Arabic Machine Translation, Methodologies, Progress, and Challenges. In Proceedings of the 2022 2nd International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 8–9 May 2022; pp. 378–383. [Google Scholar]
- Zhou, M.; Duan, N.; Liu, S.; Shum, H.Y. Progress in Neural NLP: Modeling, Learning, and Reasoning. Engineering 2020, 6, 275–290. [Google Scholar] [CrossRef]
- Khalifa, I.; Feki, Z.; Farawila, A. Arabic discourse segmentation based on rhetorical methods. Int. J. Electr. Comput. Sci. 2011, 11, 10–15. [Google Scholar]
- Monroe, W.; Green, S.; Manning, C.D. Word segmentation of informal Arabic with domain adaptation. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 206–211. [Google Scholar]
- Souri, A.; Al Achhab, M.; El Mouhajir, B.E. A proposed approach for Arabic language segmentation. In Proceedings of the 2015 First International Conference on Arabic Computational Linguistics (ACLing), Cairo, Egypt, 17–20 April 2015; pp. 43–48. [Google Scholar]
- Elmadany, A.A.; Abdou, S.M.; Gheith, M. Turn Segmentation into Utterances for Arabic Spontaneous Dialogues and Instance Messages. arXiv 2015, arXiv:1505.03081. [Google Scholar]
- Abdelali, A.; Darwish, K.; Durrani, N.; Mubarak, H. Farasa: A fast and furious segmenter for arabic. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 11–16. [Google Scholar]
- Eldesouki, M.; Samih, Y.; Abdelali, A.; Attia, M.; Mubarak, H.; Darwish, K.; Laura, K. Arabic multi-dialect segmentation: bi-LSTM-CRF vs. SVM. arXiv 2017, arXiv:1708.05891. [Google Scholar]
- Cheragui, M.A.; Hiri, E. Arabic Text Segmentation using Contextual Exploration and Morphological Analysis. In Proceedings of the 2020 2nd International conference on mathematics and information technology (ICMIT), Adrar, Algeria, 18–19 February 2020; pp. 220–225. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Pires, T.; Schlinger, E.; Garrette, D. How multilingual is Multilingual BERT? arXiv 2019, arXiv:1906.01502. [Google Scholar]
- Abdul-Mageed, M.; Elmadany, A.; Nagoudi, E.M.B. ARBERT & MARBERT: Deep Bidirectional Transformers for Arabic. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 7088–7105. [Google Scholar] [CrossRef]
- Antoun, W.; Baly, F.; Hajj, H. AraBERT: Transformer-based Model for Arabic Language Understanding. arXiv 2020, arXiv:2003.00104. [Google Scholar]
- Inoue, G.; Alhafni, B.; Baimukan, N.; Bouamor, H.; Habash, N. The Interplay of Variant, Size, and Task Type in Arabic Pre-trained Language Models. In Proceedings of the Sixth Arabic Natural Language Processing Workshop; Association for Computational Linguistics: Kyiv, Ukraine, 2021; pp. 92–104. [Google Scholar]
- Pak, I.; Teh, P.L. Text segmentation techniques: A critical review. Innov. Comput. Optim. Appl. 2018, 741, 167–181. [Google Scholar]
- Daroch, S.K.; Singh, P. An Analysis of Various Text Segmentation Approaches. In Proceedings of International Conference on Intelligent Cyber-Physical Systems; Agarwal, B., Rahman, A., Patnaik, S., Poonia, R.C., Eds.; Springer Nature Singapore: Singapore, 2022; pp. 285–302. [Google Scholar]
- Niklaus, C.; Cetto, M.; Freitas, A.; Handschuh, S. Transforming Complex Sentences into a Semantic Hierarchy. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Lattisi, T.; Farina, D.; Ronchetti, M. Semantic Segmentation of Text Using Deep Learning. Comput. Inform. 2022, 41, 78–97. [Google Scholar] [CrossRef]
- Hananto, V.R.; Serdült, U.; Kryssanov, V. A Text Segmentation Approach for Automated Annotation of Online Customer Reviews, Based on Topic Modeling. Appl. Sci. 2022, 12, 3412. [Google Scholar] [CrossRef]
- Lukasik, M.; Dadachev, B.; Simoes, G.; Papineni, K. Text segmentation by cross segment attention. arXiv 2020, arXiv:2004.14535. [Google Scholar]
- Pasha, A.; Al-Badrashiny, M.; Diab, M.; El Kholy, A.; Eskander, R.; Habash, N.; Pooleery, M.; Rambow, O.; Roth, R. Madamira: A fast, comprehensive tool for morphological analysis and disambiguation of arabic. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; pp. 1094–1101. [Google Scholar]
- Li, J.; Sun, A.; Joty, S.R. SegBot: A Generic Neural Text Segmentation Model with Pointer Network. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence Main Track, Stockholm, Sweden, 13–19 July 2018; AAAI Press: Stockholm, Sweden, 2018; pp. 4166–4172. [Google Scholar]
- Li, J.; Chiu, B.; Shang, S.; Shao, L. Neural text segmentation and its application to sentiment analysis. IEEE Trans. Knowl. Data Eng. 2020, 34, 828–842. [Google Scholar] [CrossRef]
- Alosh, M. Using Arabic: A Guide to Contemporary Usage; ‘Using’ Linguistic Books, Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Liu, H.; Yu, L. Toward integrating feature selection algorithms for classification and clustering. IEEE Trans. Knowl. Data Eng. 2005, 17, 491–502. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. arXiv 2020, arXiv:1911.02116. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Language | Reference | Segmentation Level | Method | Dialect-Specific | Language Understanding | Transfer Learning | |||
|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | ||||||
| Arabic | Rhetorical SVM classifier [9] | Phrase to a simple sentence | ✓ | ✗ | |||||
| Linear-chain Markov model [10] | Word | ✓ | ✓ | ✓ | ✗ | ||||
| Chunking procedure [11] | Random between word to small text segments | ✓ | ✗ | ||||||
| USeg (utterances) [12] | Phrase to a simple sentence | ✓ | ✓ | ✓ | ✗ | ||||
| Farasa-linear SVM model [13] | Word | ✓ | ✓ | ✗ | |||||
| SVM and Bi-directional LSTM [14] | Word | ✓ | ✓ | ✗ | |||||
| DJAZI (Chunking procedure) [15] | Random between word to small text segments | ✓ | ✗ | ||||||
| Regular rule-based expressions [1] | Simple sentence (independent clause) | ✓ | ✓ | ✗ | |||||
| Our PDTS | Simple sentence (in)dependent clause | ✓ | ✓ | Multilingual | ✓ | ||||
| English | SegBot [29,30] | Sentence and document | ✓ | ✗ | |||||
| DisSim [24] | Discourse sentence | ✓ | ✗ | ||||||
| Three BERT-style models [27] | Discourse sentence and document | ✓ | Monolingual | ||||||
| Context-preserving approach [4] | Simple sentence | ✓ | ✗ | ||||||
| TopicDiff-LDA Latent Dirichlet Allocation [26] | Document | ✓ | ✗ | ||||||
| Rule | Description |
|---|---|
| Rule1: if then true :false otherwise. | It asserts that segment s consists of at least two-word tokens. |
| Rule2: if nltk (NLTK: Natural Language Toolkit—www.nltk.org/, accessed on 14 October 2022). pos_tag(s).numOf() then true :false otherwise. | It asserts that segment s consists of at least two part-of-speech nouns. |
| Rule3: if nltk.pos_tag(s).numOf() and nltk.pos_tag(s).numOf() then true: false otherwise. | It asserts that segment s consists of at least one part-of-speech noun as well as one verb. |
| Rule4: if nltk.pos() and then true: false otherwise. | It asserts that segment s represents the end of a sentence/text. |
| Document Size | Documents | Sentences | Words |
|---|---|---|---|
| Small | 5427 | 6639 | 328,872 |
| Medium | 5427 | 6807 | 491,693 |
| Large | 5427 | 13,404 | 1,057,131 |
| Total | 16,281 | 26,850 | 1,877,696 |
| Accuracy | Precision | Recall | F-Measure | |
|---|---|---|---|---|
| small | 0.86 | 0.74 | 0.87 | 0.79 |
| medium | 0.87 | 0.67 | 0.67 | 0.65 |
| large | 0.95 | 0.78 | 0.92 | 0.82 |
| avg. | 0.89 | 0.73 | 0.82 | 0.75 |
| With Excluding Linguistic Rules | With Applying Linguistic Rules | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc | P | R | FM | ET (Sec) | Acc | P | R | FM | ET (Sec) | |
| 5 | 0.81 | 0.66 | 0.36 | 0.44 | 865 * | 0.93 * | 0.55 | 0.90 * | 0.64 | 886 |
| 10 | 0.82 | 0.73 | 0.44 | 0.51 | 973 | 0.91 | 0.61 | 0.84 | 0.69 | 983 |
| 20 | 0.80 | 0.77 | 0.44 | 0.54 | 1213 | 0.91 | 0.71 | 0.74 | 0.70 | 1234 |
| 40 * | 0.77 | 0.78 | 0.44 | 0.54 | 1980 | 0.89 | 0.73 | 0.82 | 0.75 * | 1987 |
| 80 | 0.77 | 0.80 * | 0.48 | 0.57 | 3181 | 0.87 | 0.69 | 0.74 | 0.68 | 3213 |
| 160 | 0.77 | 0.77 | 0.47 | 0.55 | 3507 | 0.86 | 0.63 | 0.69 | 0.64 | 3542 |
| Base Model | Language | F-Measure | ET (Sec) |
|---|---|---|---|
| ArBERT [19] | Monolingual (Arabic) | 0.6235 | 1286.81 |
| AraBERT [20] | Monolingual (Arabic) | 0.3500 | 1173.98 |
| CAMeLBERT [21] | Monolingual (Arabic) | 0.2121 | 986.17 * |
| XLM-RoBERTa [33] | Multilingual | 0.3035 | 4916.51 |
| mBERT [16] | Multilingual | 0.7523 * | 1986.91 |
| Base Model | A | C | G | Avg. | p-Value (t-Value) |
|---|---|---|---|---|---|
| ArBERT [19] | 4.17 * | 3.17 | 3.67 * | 3.67 | 0.925156 (0.11) |
| AraBERT [20] | 3.33 | 2.50 | 3.17 | 3.00 | 0.069934 (2.46) |
| CAMeLBERT [21] | 2.67 | 1.50 | 2.17 | 2.11 | 0.002153 (7.03) † |
| XLM-RoBERTa [33] | 1.67 | 1.83 | 1.67 | 1.72 | 0.003126 (6.36) † |
| mBERT [16] | 3.83 | 3.33 | 3.30 | 3.50 | 0.468527 (0.81) |
| mBERT [16] + Linguistic rules | 3.83 | 3.83 * | 3.50 | 3.72 * | ‡ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alshanqiti, A.M.; Albouq, S.; Alkhodre, A.B.; Namoun, A.; Nabil, E. Employing a Multilingual Transformer Model for Segmenting Unpunctuated Arabic Text. Appl. Sci. 2022, 12, 10559. https://doi.org/10.3390/app122010559
Alshanqiti AM, Albouq S, Alkhodre AB, Namoun A, Nabil E. Employing a Multilingual Transformer Model for Segmenting Unpunctuated Arabic Text. Applied Sciences. 2022; 12(20):10559. https://doi.org/10.3390/app122010559
Chicago/Turabian StyleAlshanqiti, Abdullah M., Sami Albouq, Ahmad B. Alkhodre, Abdallah Namoun, and Emad Nabil. 2022. "Employing a Multilingual Transformer Model for Segmenting Unpunctuated Arabic Text" Applied Sciences 12, no. 20: 10559. https://doi.org/10.3390/app122010559
APA StyleAlshanqiti, A. M., Albouq, S., Alkhodre, A. B., Namoun, A., & Nabil, E. (2022). Employing a Multilingual Transformer Model for Segmenting Unpunctuated Arabic Text. Applied Sciences, 12(20), 10559. https://doi.org/10.3390/app122010559