
Systematic Machine Translation of Social Network Data Privacy Policies †


Abstract
1. Introduction
2. Controlled Natural Language
2.1. CNL4DSA
- Authorizations, referring to permission for subjects to perform actions on object under a specific context.
- Prohibitions, expressing the fact that a subject cannot perform actions on an object under a specific context.
- Obligations, referring to subjects obliged to perform actions on objects under a specific context.
- nil can do nothing.
- can, must, cannotf is the atomic fragment that expresses that f is allowed/require/not permitted, where . Its informal meaning is the subject s can perform action a on the object o.
- is a list of composite fragments (i.e., a list of authorizations, obligations, or prohibitions).
- expresses the logical implication between a context C and a composite fragment: if C holds, then F is allowed/required/not allowed.
- is a temporal sequence of fragments. Informally, after f has happened, then the composite fragment F is allowed/required/not allowed.
2.2. Scenario Examples
- P1: Firefighters can access the victim’s personal and medical information.
- O1: Once the alert states of the accidents have been determined by the Red Cross members, if it is larger than five, they must then inform the local community of the alert level.
- PT1: Non-firemen cannot access tanker delivery notes that are currently in progress.
- c = hasRole(user1, fireman) and hasDataCategory(data, personal) and hasDataCategory(data, medical) and isReferredTo(data, user2) and isInvolvedIn(user2, accident) is a composite context.
- f = can access(user1, data) is a composite authorization fragment.
- c = hasRole(user1, RedCross) and hasDataCategory(data, alertState) then after that access(user1, data) then if isGreaterThan(alertState,five).
- f = must communicate(user1,data) is a composite obligation fragment.
- c = not hasRole(user1,fireman) and hasDataCategory(data, deliveryNote) and isReferredTo(data,truck) then cannot access(user1, data) where not hasRole(user1, fireman) and hasDataCategory(data,deliveryNote) and isReferredTo(data,truck) is a composite context.
- f = cannot access(user1, data) is a composite prohibition fragment.
3. Related Work
4. Design Approach
4.1. Policy Translation Using Natural Language Policy Translator (NLPT) 1.0
- c1 = subject1 hasRole ‘’ AND (object1 hasCategory ‘’ OR object1 hasCategory ‘’) AND (subject2 provides object1 OR subject2 provides object1) AND subject2 hasRole ‘’ AND subject2 uses ‘’ is a composite context.
- f1 = subject1 collect object1 is an atomic fragment.
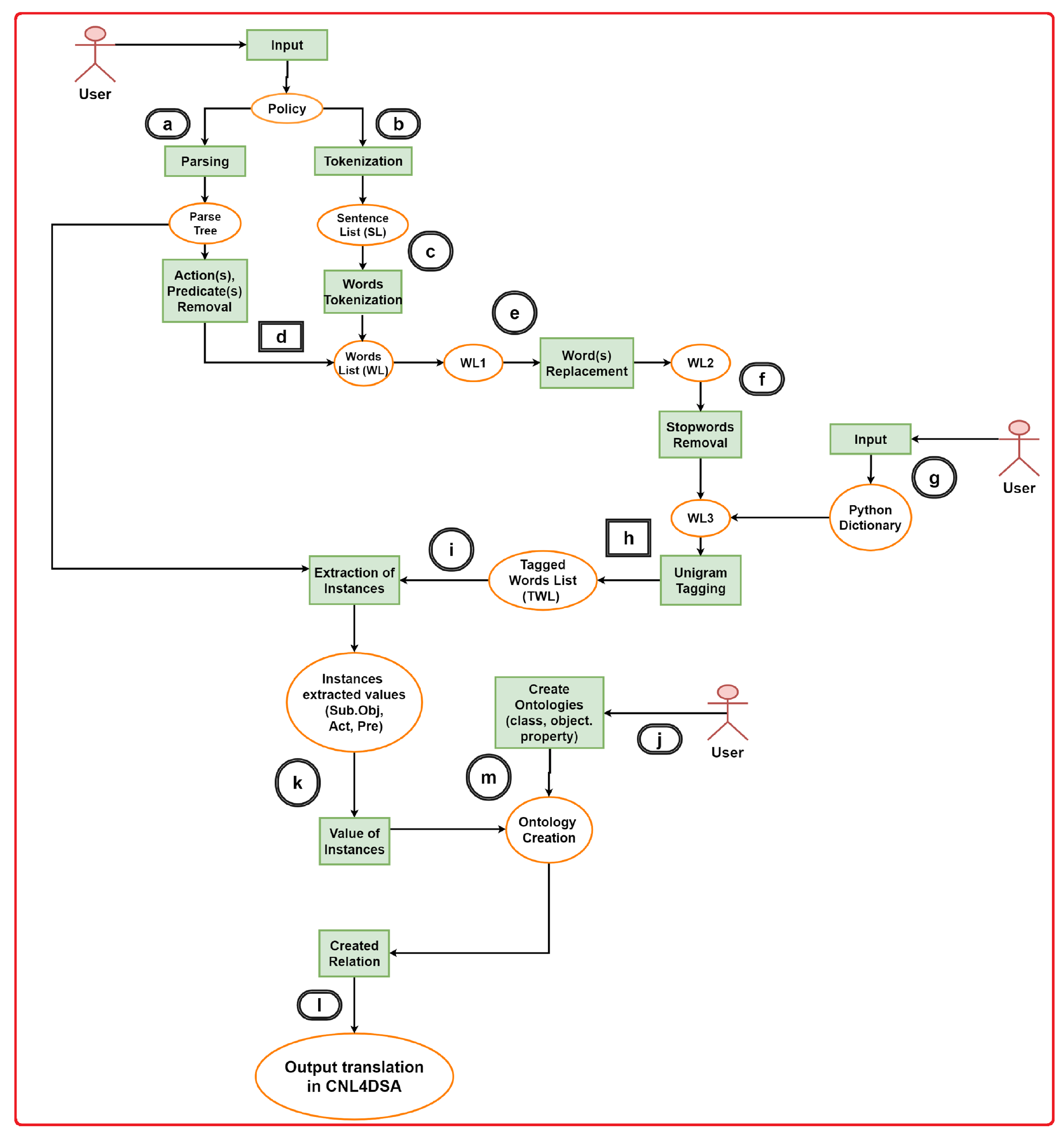
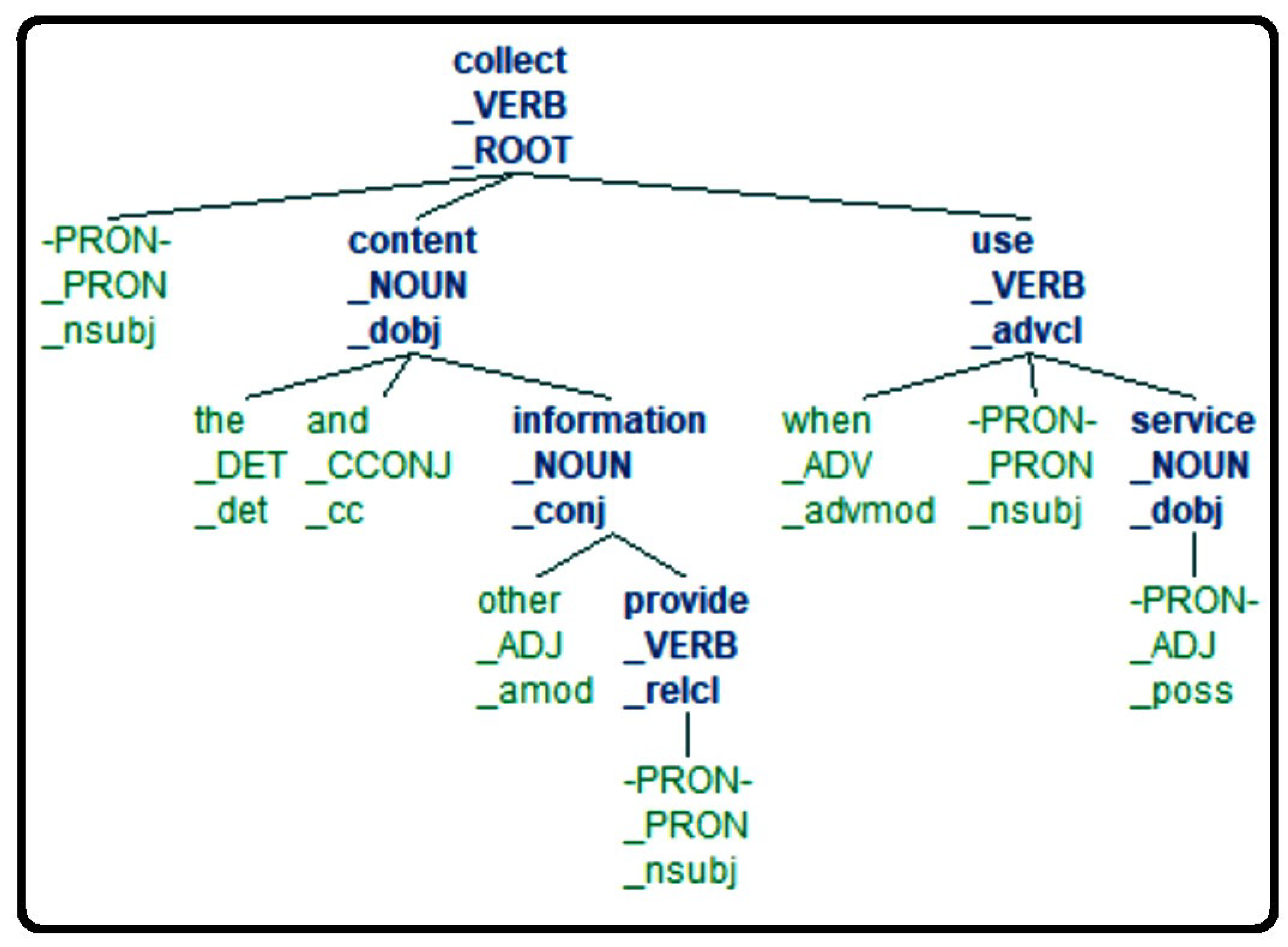
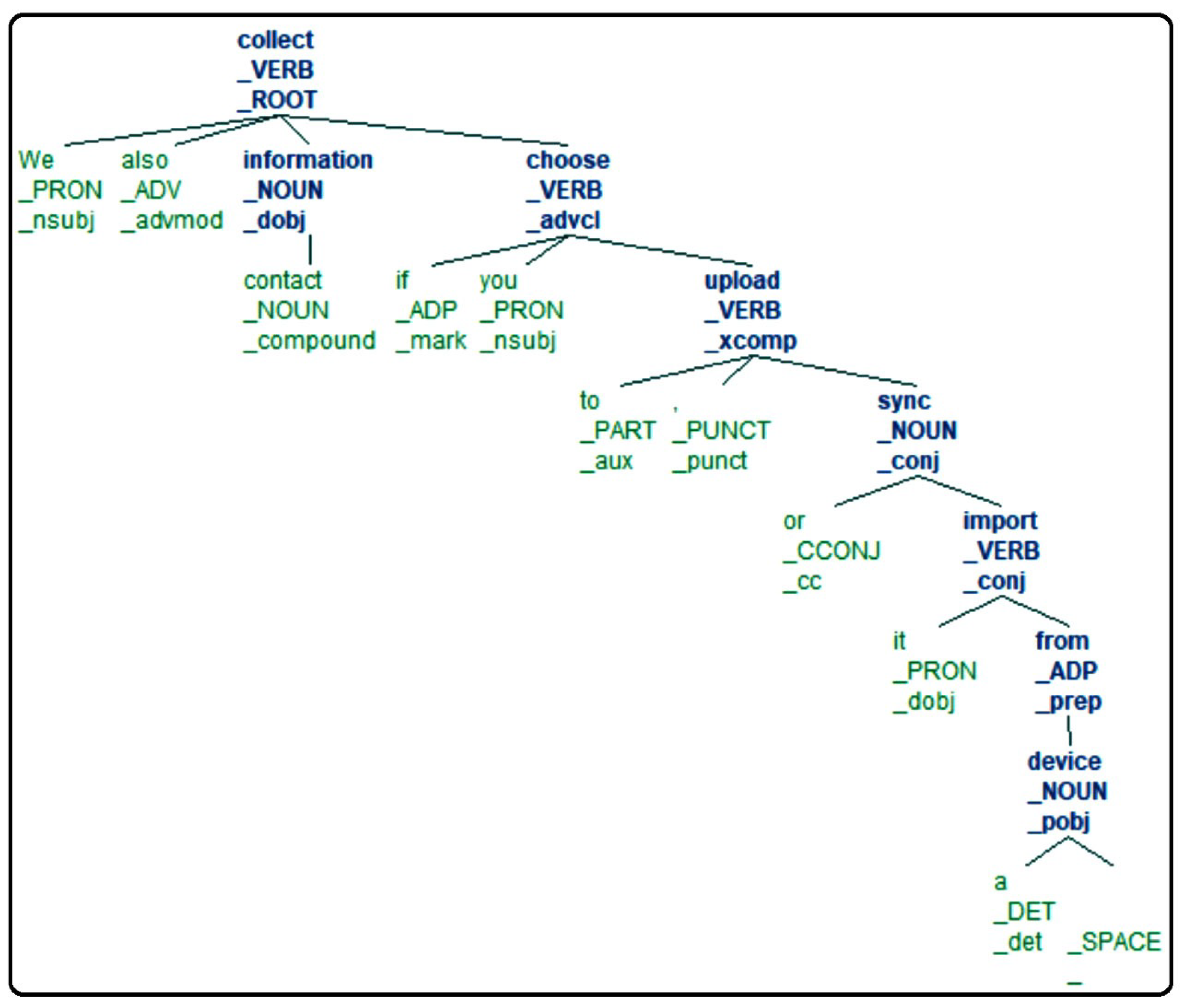
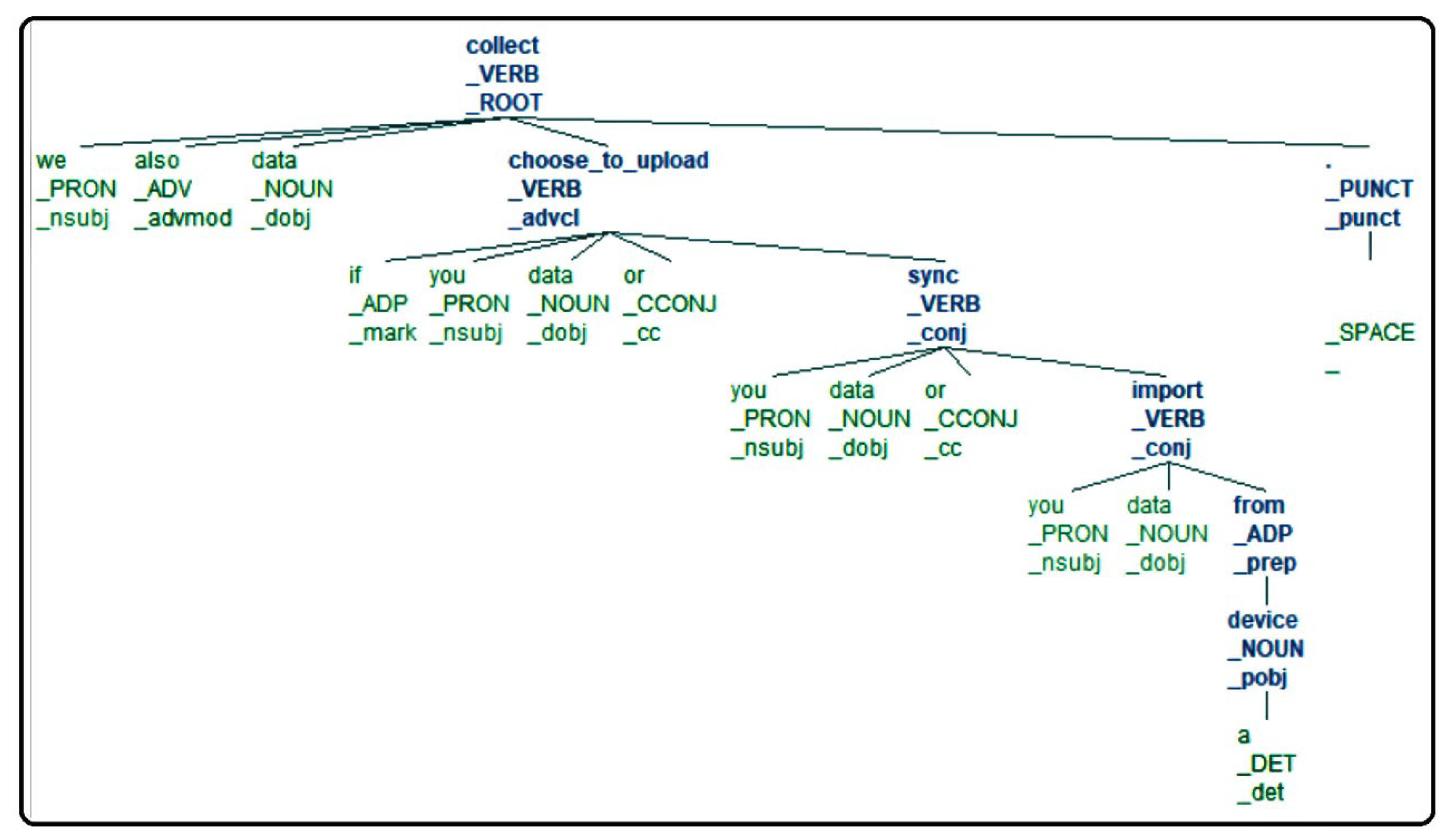
4.1.1. Natural Language Processing
- The subjects, the objects, and the actions;
- The contexts and fragments, as required by the CNL4DSA language.
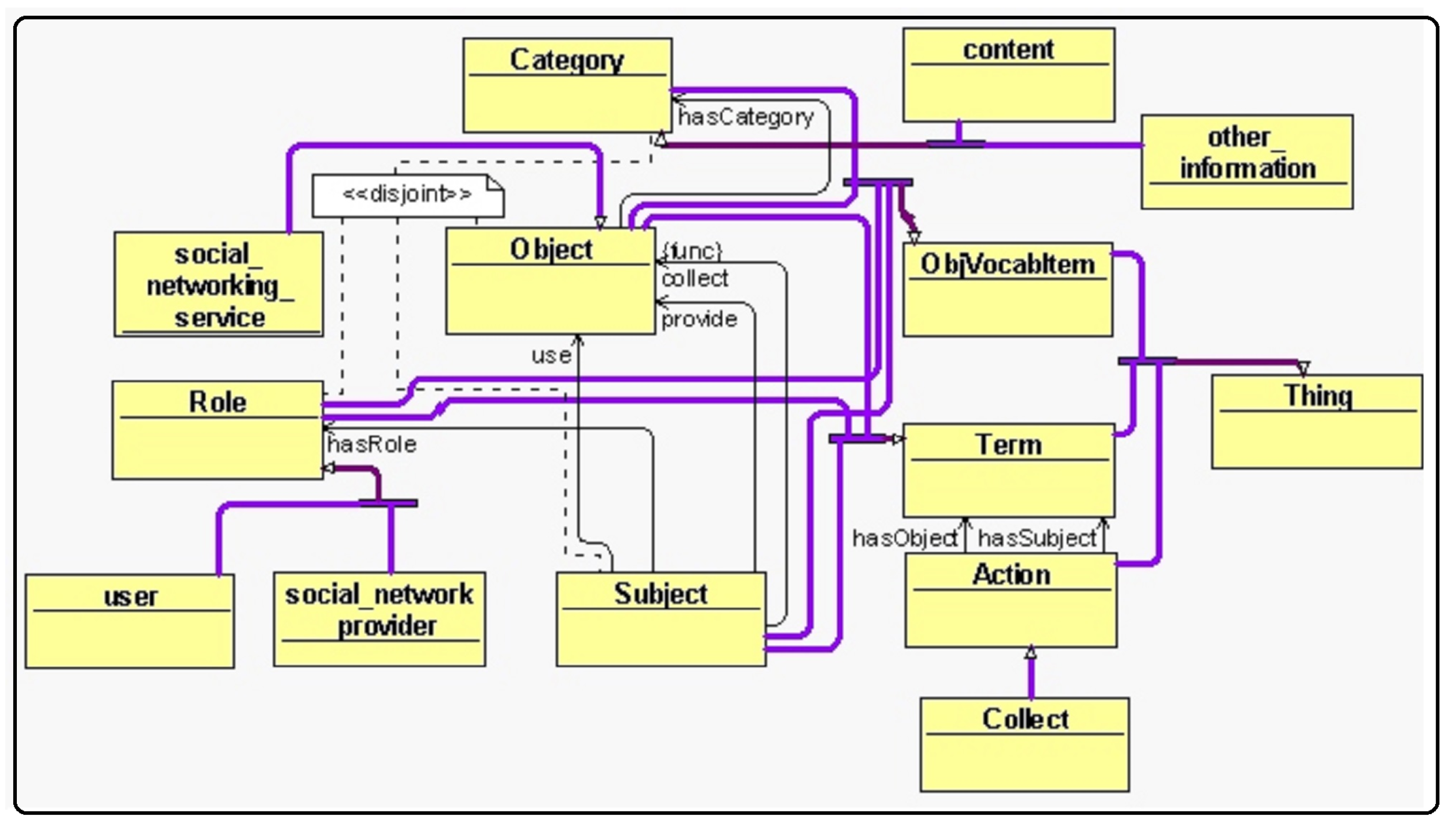
4.1.2. Building Ontologies
4.1.3. Translation into CNL4DSA
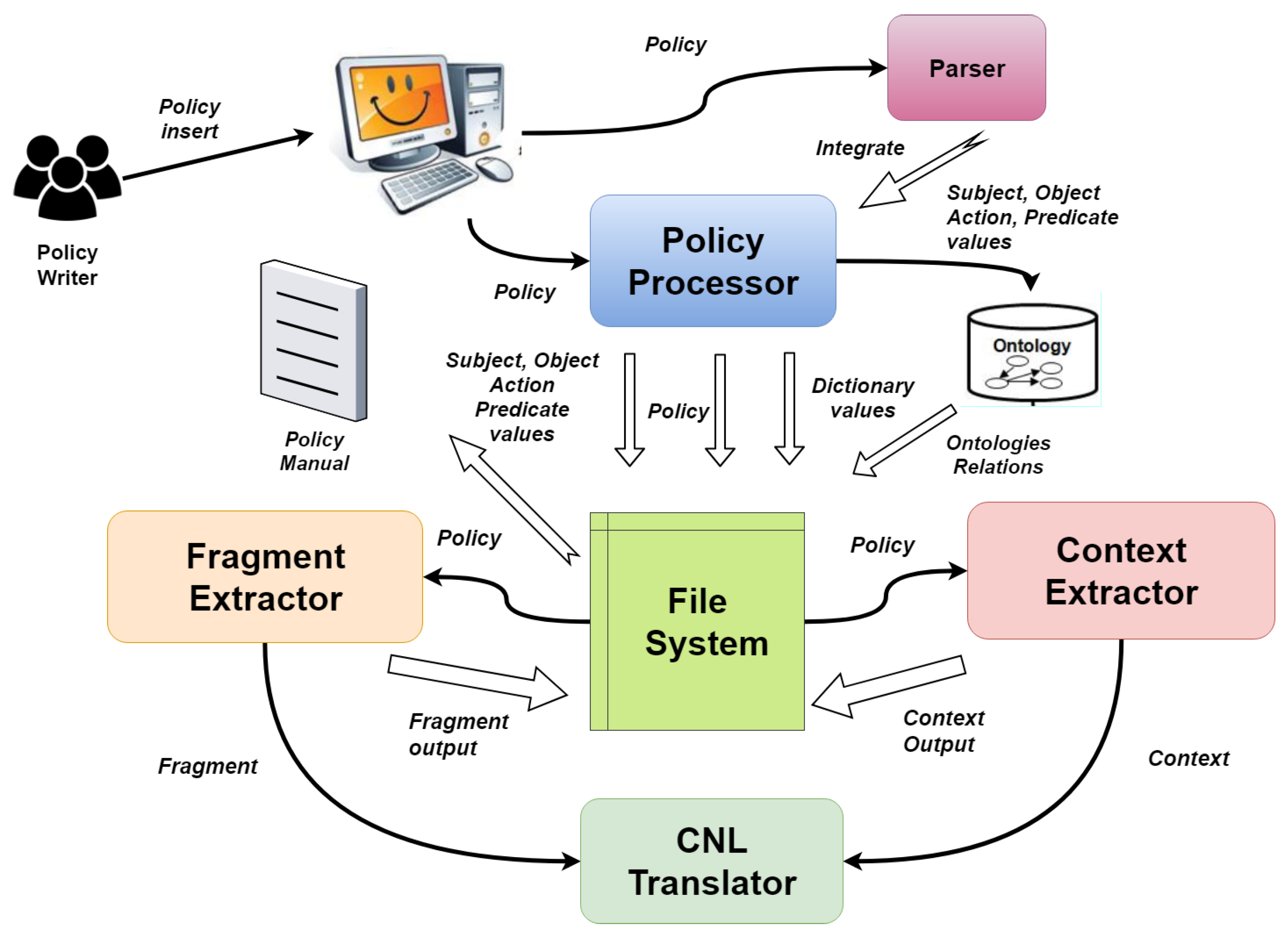
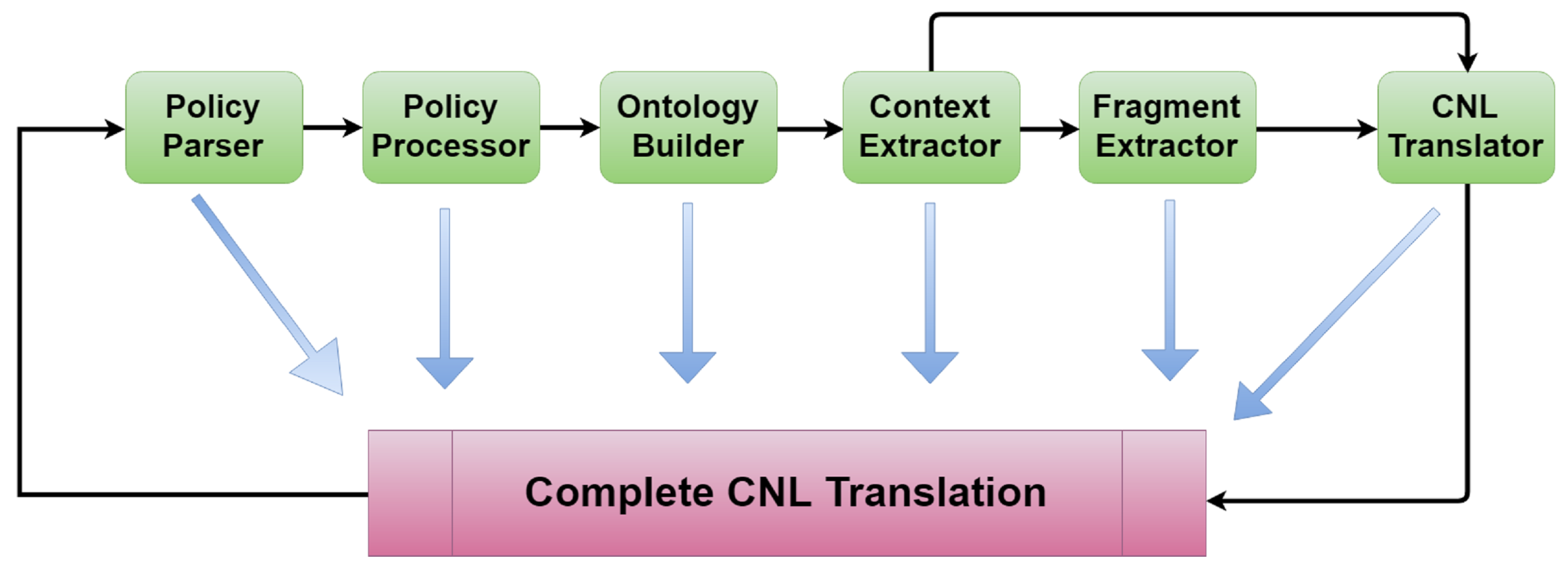
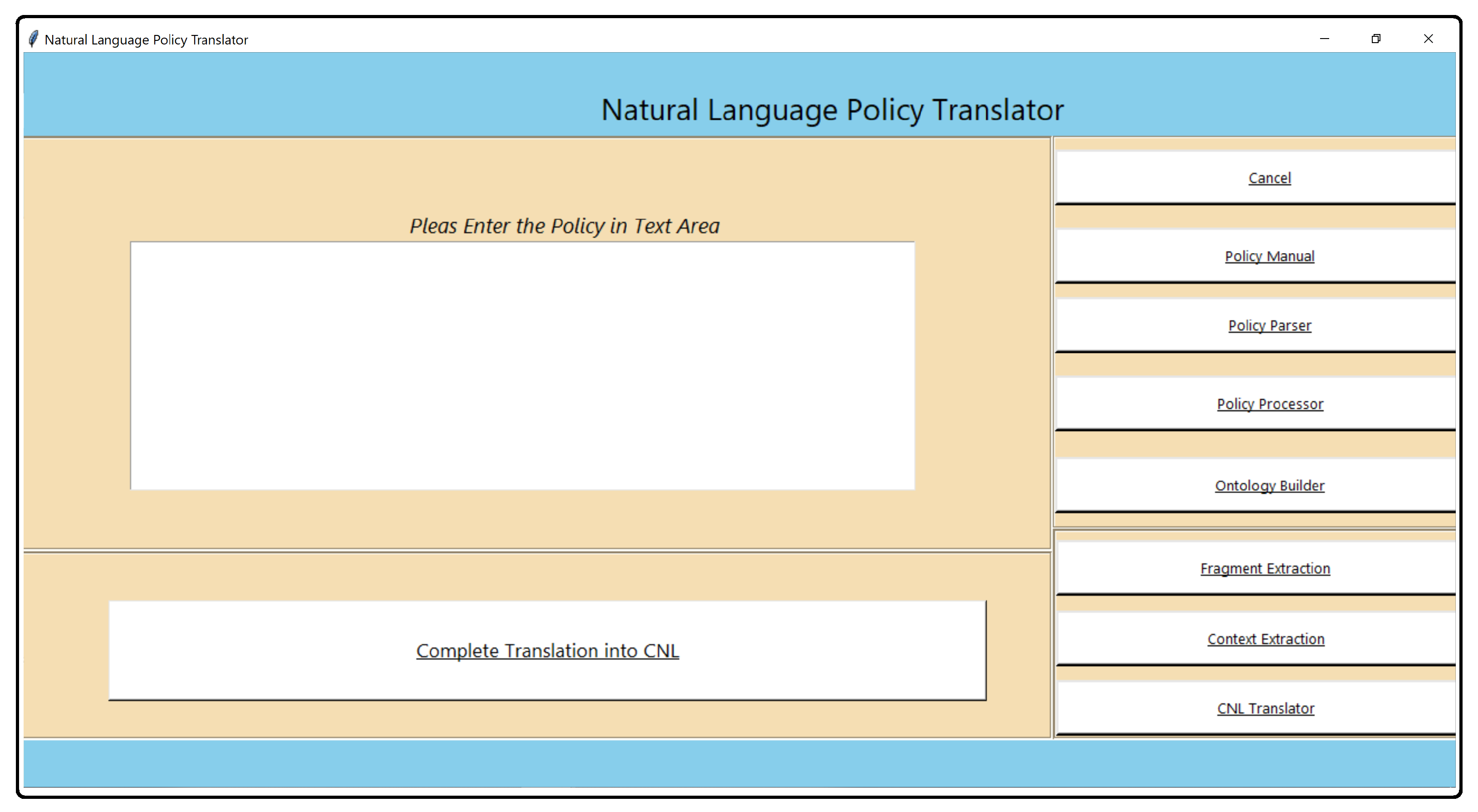
5. Architecture and Graphical User Interface
- Policy Parser (PP)
- Policy Processor (PR)
- Ontology Builder (OB)
- Fragment Extractor (FE)
- Context Extractor (CE)
- Controlled Natural Language Translator (CNLT)
6. Experimental Social Networks Policies
6.1. Experimental Setup
6.2. Evaluation Criteria
- How many policies are accurately parsed by Policy Parser (PP), i.e., extracting action(s) and predicate(s) in a policy?
- How many times is a dictionary update required in terms of subject(s) and object(s) while processing the policy with Policy Processor (PR) until no update is required?
- How many times does an existing ontology have to be updated, or be created, while processing with Ontology Builder (OB) until no update is required?
- Can the Fragment Extractor (FE) accurately extract the fragment from the given policy?
- Can the Context Extractor (CFE) properly extract the context(s) from the input policy?
- Can the Controlled Natural Language Translator (CNLT) correctly classify the policy as authorization, obligation, and prohibition fragment?
- What is the success rate of Policy Parser (PP), Fragment Extractor (FE), Context Extractor (CFE) and Controlled Natural Language Translator (CNLT) over the total number of policies?
6.3. Experimental Operations
- Run Policy Parser
- Count the number of policies parsed correctly in a single iteration.
- Run Policy Processor
- Count the number of policies where it is required to update the vocabulary, with new subjects, objects, and predicates until no update is required.
- Run Ontology Builder
- Count the number of policies where it is required to create or update the ontology dictionary until no update is required.
- Run Fragment Extractor
- Count the number of fragments correctly extracted in a single iteration.
- Run Context Extractor
- Count the number of contexts correctly extracted in a single iteration.
- Run Controlled Natural Language (CNL) Translator
- Count the number of policies where a Controlled Natural Language Translator (CNLT) successfully identifies fragments as authorizations, obligations, and prohibitions in a single iteration.
6.4. Performance Evaluation Criteria
7. Results and Discussion
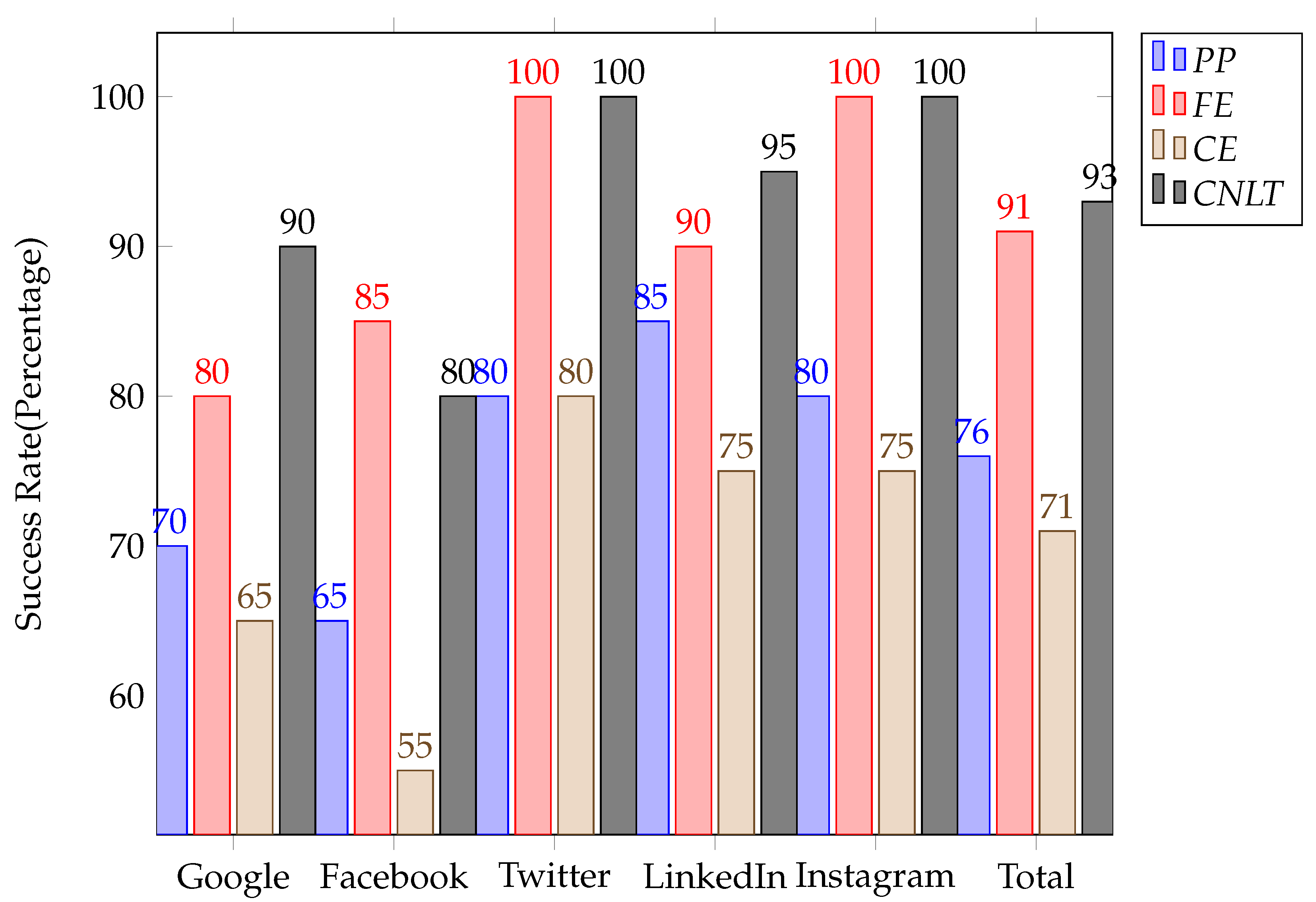
- Google: Out of 20 policies, 14 (70%) are accurately parsed by the Policy Parser (PP), identifying terms either as the main action or predicate(s). Initially, the dictionary has been updated 11 times (55%) with new terms for subjects and objects (including seven times (35%) with predicates due to the wrong parser tagging). The vocabulary for ontologies required an update eight times (40%) manually by the Policy Writer. It is hypothesized as if the percentage for dictionary and ontology updates is becoming low, as the system becomes more efficient at classifying subject(s), object(s), or predicates within a policy with less human intervention.In total, 16 fragments (80%) and 13 contexts (65%) have been properly extracted, while for 18 policies (90%), the Controlled Natural Language Translator (CNLT) classified terms as either authorization, obligation, or prohibition fragments.
- Facebook: 13 policies (65%) are correctly parsed by Policy Parser (PP), and the dictionary and ontology are updated by the Policy Writer 7 (35%) and 4 (20%) times. Fragment Extractor (FE) classifies 17 (85%) fragments and Context Extractor (CFE) 11 (55%) contexts correctly. Controlled Natural Language Translator (CNLT) validates 16 (80%) policy fragments as authorizations, obligations, or prohibitions accurately.
- Twitter: The obtained results of Twitter appear to be quite promising. In total, 16 (80%) policies are correctly parsed, while there was no need to update vocabularies for ontology and terms. Fragment Extractor (FE) obtains 20 (100%)) fragments accurately. A total of 16 (80%) contexts are correctly extracted by Context Extractor (CFE). Controlled Natural Language Translator (CNLT) recognizes all 20 (100%) policies as authorization, obligation, or prohibition.
- LinkedIn and Instagram: For LinkedIn and Instagram, 17 (85%) and 16 80 are properly parsed. The dictionary terms and ontologies are required to update only 1–2 times. Fragment Extractor (FE) and Context Extractor (CFE) obtained 18 (90%) fragments and 15 (75%) contexts for the premier, 20 (100%) and 15 (75%) for later. The performance of Controlled Natural Language Translator (CNLT) is (95%) for LinkedIn and (100%) for Instagram.
8. Conclusions
- Parses the policy to extract action(s) and predicate(s).
- Processes policy by means of tokenization of sentences, words, stop-words, unigram tagging to label subject(s) and object(s) and extract subject(s), object(s), action(s) and predicate(s).
- Identifies and produces ontologies with respect to subject hasRole, the object hasCategory, the object hasPurpose, relation as subject predicate object, etc.
- Extracts the fragment from the original policy.
- Extracts the context from the original policy.
- Classifies between authorization, obligation, and prohibition fragments.
- Performs all the above tasks separately and together.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ali, S.; Islam, N.; Rauf, A.; Din, I.U.; Guizani, M.; Rodrigues, J.J. Privacy and security issues in online social networks. Future Internet 2018, 10, 114. [Google Scholar] [CrossRef]
- Facebook Privacy Policy, 2022. Available online: https://m.facebook.com/privacy/explanation/ (accessed on 20 June 2022).
- Twitter Privay Policy, 2022. Available online: https://twitter.com/en/privacy (accessed on 20 June 2022).
- Google Privacy and Terms, 2022. Available online: https://policies.google.com/privacy (accessed on 20 June 2022).
- Cambridge Dictionary. 1999. Available online: https://dictionary.cambridge.org/dictionary/english/policy (accessed on 20 June 2021).
- Tanoli, I.K.; Petrocchi, M.; De Nicola, R. Towards automatic translation of social network policies into controlled natural language. In Proceedings of the 2018 12th International Conference on Research Challenges in Information Science (RCIS), Nantes, France, 29–31 May 2018. [Google Scholar]
- Costantino, G.; Martinelli, F.; Matteucci, I.; Petrocchi, M. Analysis of Data Sharing Agreements. In Proceedings of the Information Systems Security and Privacy, Porto, Portugal, 19–21 February 2017; pp. 167–178. [Google Scholar]
- Standard, O. Extensible Access Control Markup Language (Xacml) Version 3.0. 2013. Available online: http://docs.oasis-open.org/xacml/3.0/xacml-3.0-core-spec-os-en.html (accessed on 22 January 2018).
- Matteucci, I.; Petrocchi, M.; Sbodio, M.L. CNL4DSA: A controlled natural language for data sharing agreements. In Proceedings of the Symposium on Applied Computing, Sierre, Switzerland, 22–26 March 2010; pp. 616–620. [Google Scholar]
- Costantino, G.; Martinelli, F.; Matteucci, I.; Petrocchi, M. Efficient Detection of Conflicts in Data Sharing Agreements. In Proceedings of the Information Systems Security and Privacy—Revised Selected Papers, Porto, Portugal, 19–21 February 2017; pp. 148–172. [Google Scholar]
- Lenzini, G.; Petrocchi, M. Modelling of Railway Signalling System Requirements by Controlled Natural Languages: A Case Study. In From Software Engineering to Formal Methods and Tools, and Back; Springer: Berlin, Germany, 2019; pp. 502–518. [Google Scholar]
- Instagram Data Policy, 2021. Available online: https://help.instagram.com/519522125107875 (accessed on 20 June 2021).
- LinkedIn Privacy Policy, 2021. Available online: https://www.linkedin.com/legal/privacy-policy (accessed on 20 June 2021).
- Schwitter, R. Controlled natural languages for knowledge representation. In Proceedings of the Coling 2010: Posters, Beijing, China, 23–27 August 2010; pp. 1113–1121. [Google Scholar]
- Gao, T. Controlled natural languages for knowledge representation and reasoning. In Proceedings of the Technical Communications of the 32nd International Conference on Logic Programming (ICLP 2016), New York, NY, USA, 16–21 October 2016. [Google Scholar]
- Schwitter, R.; Kaljurand, K.; Cregan, A.; Dolbear, C.; Hart, G. A Comparison of Three Controlled Natural Languages for OWL 1.1; 2008. Available online: https://www.researchgate.net/publication/228635222_A_comparison_of_three_controlled_natural_languages_for_OWL_11 (accessed on 20 June 2022).
- Kuhn, T. A survey and classification of controlled natural languages. Comput. Linguist. 2014, 40, 121–170. [Google Scholar] [CrossRef]
- Hujisen, W.O. Controlled language: An introduction. In Proceedings of the 2nd International Workshop on Controlled Language Applications (CLAW), Pittsburgh, PA, USA, 21–22 May 1998; pp. 1–15. [Google Scholar]
- ASD Simplified Technical English, 2017. Available online: http://www.asd-ste100.org/ (accessed on 20 June 2021).
- Civil Aviation Authority. CAP 722 Unmanned Aircraft System Operations in UK Airspace—Guidance. Dir. Airsp. Policy 2010, 8, 1–238. [Google Scholar]
- Nyberg, E.; Mitamura, T. The KANTOO machine translation environment. In Proceedings of the Conference of the Association for Machine Translation in the Americas, Cuernavaca, Mexico, 10–14 October 2000; pp. 192–195. [Google Scholar]
- Fuchs, N.; Kaljurand, K.; Kuhn, T. Attempto Controlled English for knowledge representation. In Reasoning Web; Springer: Berlin/Heidelberg, Germany, 2008; pp. 104–124. [Google Scholar]
- Martinelli, F.; Matteucci, I.; Petrocchi, M.; Wiegand, L. A formal support for collaborative data sharing. In Proceedings of the Availability, Reliability, and Security, Prague, Czech Republic, 20–24 August 2012; pp. 547–561. [Google Scholar]
- Clavel, M.; Durán, F.; Eker, S.; Lincoln, P.; Martí-Oliet, N.; Meseguer, J.; Talcott, C. All About Maude—A High-Performance Logical Framework: How to Specify, Program and Verify Systems in Rewriting Logic; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Matteucci, I.; Mori, P.; Petrocchi, M.; Wiegand, L. Controlled data sharing in E-health. In Proceedings of the Socio-Technical Aspects in Security and Trust (STAST), Milan, Italy, 8 September 2011; pp. 17–23. [Google Scholar]
- Tateishi, T.; Yoshihama, S.; Sato, N.; Saito, S. Automatic smart contract generation using controlled natural language and template. IBM J. Res. Dev. 2019, 63, 6:1–6:12. [Google Scholar] [CrossRef]
- Calafato, A.; Colombo, C.; Pace, G.J. A Controlled Natural Language for Tax Fraud Detection. In Proceedings of the International Workshop on Controlled Natural Language, Aberdeen, UK, 25–27 July 2016; pp. 1–12. [Google Scholar]
- Colombo, C.; Grech, J.P.; Pace, G.J. A controlled natural language for business intelligence monitoring. In Proceedings of the Applications of Natural Language to Information Systems, Passau, Germany, 17–19 June 2015; pp. 300–306. [Google Scholar]
- Feuto Njonko, P.B.; Cardey, S.; Greenfield, P.; El Abed, W. RuleCNL: A controlled natural language for business rule specifications. In Proceedings of the International Workshop on Controlled Natural Language, Galway, Ireland, 20–22 August 2014; pp. 66–77. [Google Scholar]
- Brodie, C.A.; Karat, C.M.; Karat, J. An empirical study of natural language parsing of privacy policy rules using the SPARCLE policy workbench. In Proceedings of the Usable Privacy and Security, Pittsburgh, PA, USA, 12–14 July 2006; pp. 8–19. [Google Scholar]
- Fisler, K.; Krishnamurthi, S. A model of triangulating environments for policy authoring. In Proceedings of the Access Control Models and Technologies, Pittsburgh, PA, USA, 9–11 June 2010; pp. 3–12. [Google Scholar]
- Kiyavitskaya, N.; Zannone, N. Requirements model generation to support requirements elicitation: The Secure Tropos experience. Autom. Softw. Eng. 2008, 15, 149–173. [Google Scholar] [CrossRef]
- Fantechi, A.; Gnesi, S.; Ristori, G.; Carenini, M.; Vanocchi, M.; Moreschini, P. Assisting requirement formalization by means of natural language translation. Form. Methods Syst. Des. 1994, 4, 243–263. [Google Scholar] [CrossRef]
- Craven, R.; Lobo, J.; Ma, J.; Russo, A.; Lupu, E.; Bandara, A. Expressive policy analysis with enhanced system dynamicity. In Proceedings of the Information, Computer, and Communications Security, Sydney, Australia, 10–12 March 2009; pp. 239–250. [Google Scholar]
- Fockel, M.; Holtmann, J. A requirements engineering methodology combining models and controlled natural language. In Proceedings of the 2014 IEEE 4th International Model-Driven Requirements Engineering Workshop (MoDRE), Karlskrona, Sweden, 25 August 2014; pp. 67–76. [Google Scholar]
- Mousas, A.S.; Antonakopoulou, A.; Gogoulos, F.; Lioudakis, G.V.; Kaklamani, D.I.; Venieris, I.S. Visualising access control: The PRISM approach. In Proceedings of the Panellenic Conference on Informatics (PCI), Tripoli, Greece, 10–12 September 2010; pp. 107–111. [Google Scholar]
- Ruiz, J.F.; Petrocchi, M.; Matteucci, I.; Costantino, G.; Gambardella, C.; Manea, M.; Ozdeniz, A. A lifecycle for data sharing agreements: How it works out. In Proceedings of the Annual Privacy Forum, Frankfurt am Main, Germany, 7–8 September 2016; pp. 3–20. [Google Scholar]
- Crossley, S.A.; Allen, L.K.; Kyle, K.; McNamara, D.S. Analyzing discourse processing using a simple natural language processing tool. Discourse Process. 2014, 51, 511–534. [Google Scholar] [CrossRef]
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the COLING, Sydney, Australia, 17–21 July 2006; pp. 69–72. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
- Matthew Honnibal, Ines Montani. spaCy 101: Everything You Need to Know. 2017. Available online: https://spacy.io/ (accessed on 20 June 2022).
- Lamy, J.B. Owlready: Ontology-oriented programming in Python with automatic classification and high level constructs for biomedical ontologies. Artif. Intell. Med. 2017, 80, 11–28. [Google Scholar] [CrossRef] [PubMed]
- Facebook Data Policy, 2022. Available online: https://www.facebook.com/policy.php (accessed on 20 June 2022).
- Chen, D.; Manning, C. A fast and accurate dependency parser using neural networks. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 740–750. [Google Scholar]
- Maruch, S.; Maruch, A. Python for Dummies; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media: Newton, MA, USA, 2009. [Google Scholar]
- Bradner, S. RFC 2119: Keywords for Use in RFCs to Indicate Requirement Levels. 1997. Available online: https://www.ietf.org/rfc/rfc2119.txt (accessed on 20 June 2022).
- Noy, N.F.; McGuinness, D.L. Ontology Development 101: A Guide to Creating Your First Ontology. 2001. Available online: https://protege.stanford.edu/ (accessed on 20 June 2022).
- Hitzler, P.; Krötzsch, M.; Parsia, B.; Patel-Schneider, P.F.; Rudolph, S. OWL 2 web ontology language primer. W3C Recomm. 2009, 27, 123. [Google Scholar]
- Musen, M.A. The protégé project: A look back and a look forward. AI Matters 2015, 1, 4–12. [Google Scholar] [CrossRef] [PubMed]
- Tanoli, I.K.; Tanoli, Y.K.; Qureshi, A.K. Semi-automatic Translations of Data Privacy Policies into Controlled Natural Languages. J. Indep. Stud. Res. Comput. 2021, 17. [Google Scholar] [CrossRef]
- Don Rozenberg. PAGE PYTHON. Available online: http://page.sourceforge.net/ (accessed on 20 June 2022).
- Tanoli, I.K. Policies Dataset Result. 2022. Available online: https://www.dropbox.com/sh/prkfyizeaxe3mmg/AAAiFOkFbPDPXr22B1crnvIba?dl=0 (accessed on 20 June 2022).
- Resnik, P.; Lin, J. 11 evaluation of NLP systems. In The Handbook of Computational Linguistics and Natural Language Processing; Wiley: Hoboken, NJ, USA, 2010; Volume 57. [Google Scholar]
- Matteucci, I.; Petrocchi, M.; Sbodio, M.L.; Wiegand, L. A design phase for data sharing agreements. In Data Privacy Management and Autonomous Spontaneus Security; Springer: Berlin, Germany, 2012; pp. 25–41. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Success Rate | 80% >= | 80% < and >=60% | 60% < and >=40% | 40% < and >=20% | 20% < |
| Rating | Excellent | Above Average | Average | Below Average | Low |
| Social Network Site | Total Policies | Correct Parsing | Accurate FE | Accurate CE | Distinction by CNLT |
|---|---|---|---|---|---|
| 20 | 14 (≈70%) | 16 (≈80%) | 13 (≈65%) | 18 (≈90%) | |
| 20 | 13 (≈65%) | 17 (≈85%) | 11 (≈55%) | 16 (≈80%) | |
| 20 | 16 (≈80%) | 20 (≈100%) | 16 (≈80%) | 20 (≈100%) | |
| 20 | 17 (≈85%) | 18 (≈90%) | 15 (≈75%) | 19 (≈95%) | |
| 20 | 16 (≈80%) | 20 (≈100%) | 15 (≈75%) | 20 (≈100%) | |
| Total | 100 | 76 (≈76%) | 91 (≈91%) | 71 (≈70%) | 93 (≈93%) |
| Social Network Site | Number of Policies | Dictionary Update | Ontology Update |
|---|---|---|---|
| 20 | 11 (≈55%) | 08 (≈40%) | |
| 20 | 07 (≈35%) | 04 (≈20%) | |
| 20 | 0 (≈0%) | 0 (≈0%) | |
| 20 | 02 (≈1%) | 01 (≈1%) | |
| 20 | 01 (≈1%) | 0 (≈0%) | |
| Total | 100 | 21 (≈21%) | 13 (≈12%) |
| Case Study | PP Performance | FE Performance | CE Performance | CNLT Performance |
|---|---|---|---|---|
| Above Average | Excellent | Above Average | Excellent | |
| Above Average | Excellent | Average | Excellent | |
| Excellent | Excellent | Excellent | Excellent | |
| Excellent | Excellent | Above Average | Excellent | |
| Excellent | Excellent | Above Average | Excellent | |
| Total | Above Average | Excellent | Above Average | Excellent |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tanoli, I.K.; Amin, I.; Junejo, F.; Yusoff, N. Systematic Machine Translation of Social Network Data Privacy Policies. Appl. Sci. 2022, 12, 10499. https://doi.org/10.3390/app122010499
Tanoli IK, Amin I, Junejo F, Yusoff N. Systematic Machine Translation of Social Network Data Privacy Policies. Applied Sciences. 2022; 12(20):10499. https://doi.org/10.3390/app122010499
Chicago/Turabian StyleTanoli, Irfan Khan, Imran Amin, Faraz Junejo, and Nukman Yusoff. 2022. "Systematic Machine Translation of Social Network Data Privacy Policies" Applied Sciences 12, no. 20: 10499. https://doi.org/10.3390/app122010499
APA StyleTanoli, I. K., Amin, I., Junejo, F., & Yusoff, N. (2022). Systematic Machine Translation of Social Network Data Privacy Policies. Applied Sciences, 12(20), 10499. https://doi.org/10.3390/app122010499