
On the Detection Capabilities of Signature-Based Intrusion Detection Systems in the Context of Web Attacks

 , , , and
, , , and
Abstract
:1. Introduction
- We experimentally study the detection rate of standard preconfigurations of three SIDS in the context of URI web attacks.
- We experimentally study the false alarm rate and precision of three SIDS using a large web real-life trace.
- We study how a cooperative decision (i.e., ensemble of the three SIDS) impacts precision and detection rates.
- We propose an efficient method to reduce false positives by deactivating signatures from a full ruleset.
2. Theoretical Background and Related Works
- True Positives (TP): The number of attack events classified as attack.
- True Negatives (TN): The number of normal events classified as normal.
- False Positives (FP): The number of normal events classified as attack.
- False Negatives (FN): The number of attack events classified as normal.
Related Works
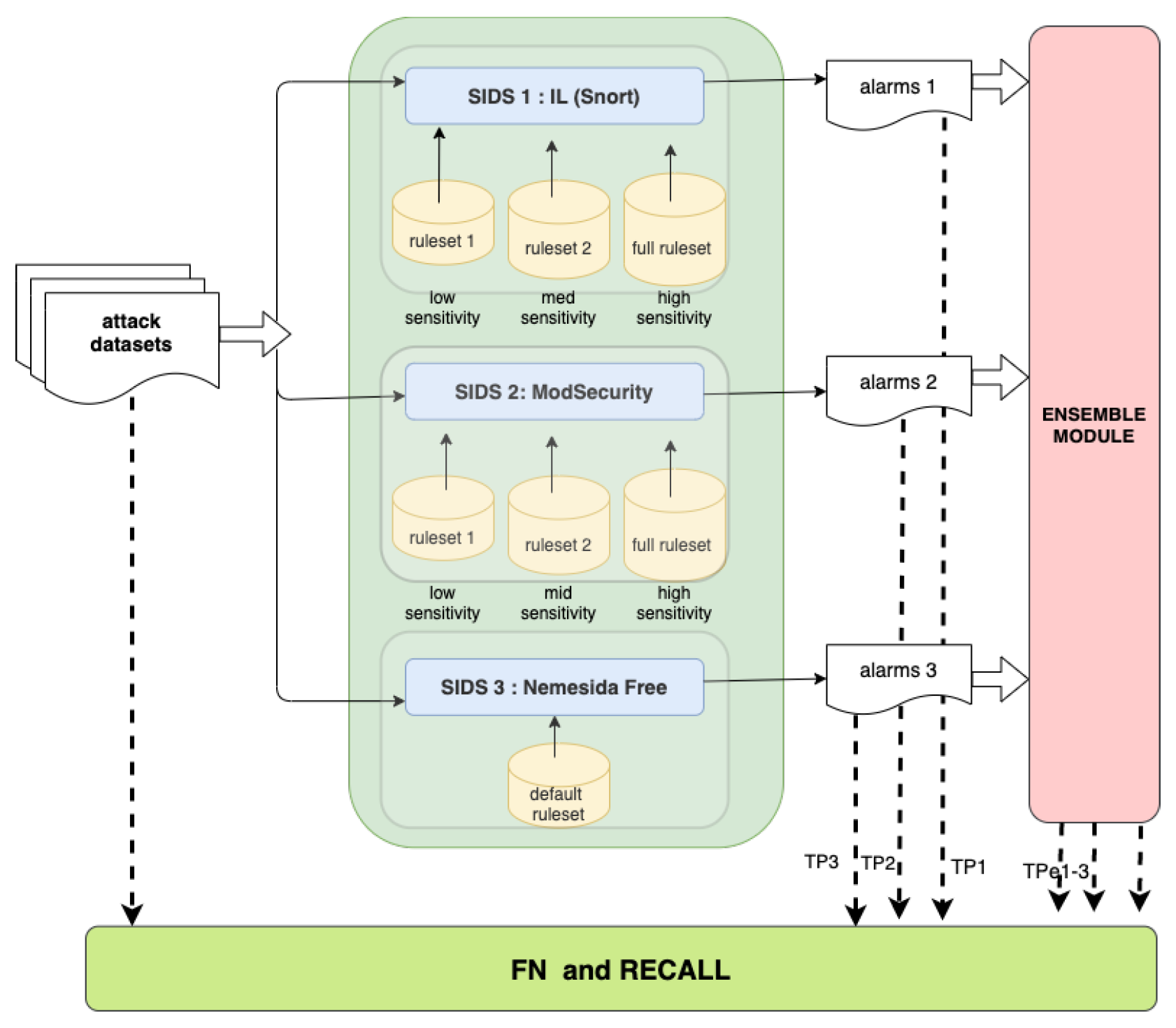
3. Methodology and Experimental Set-Up
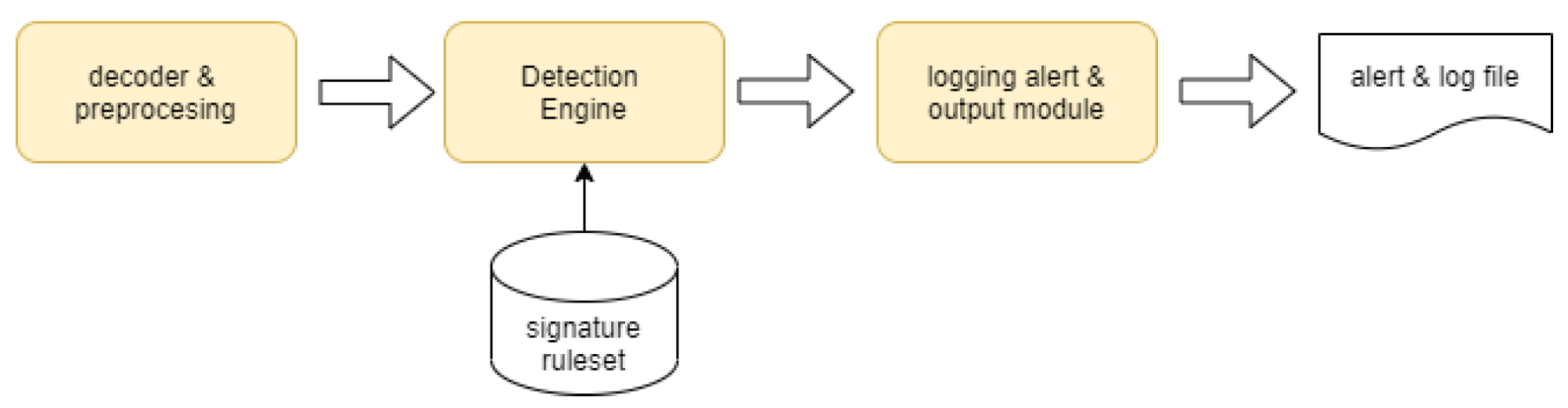
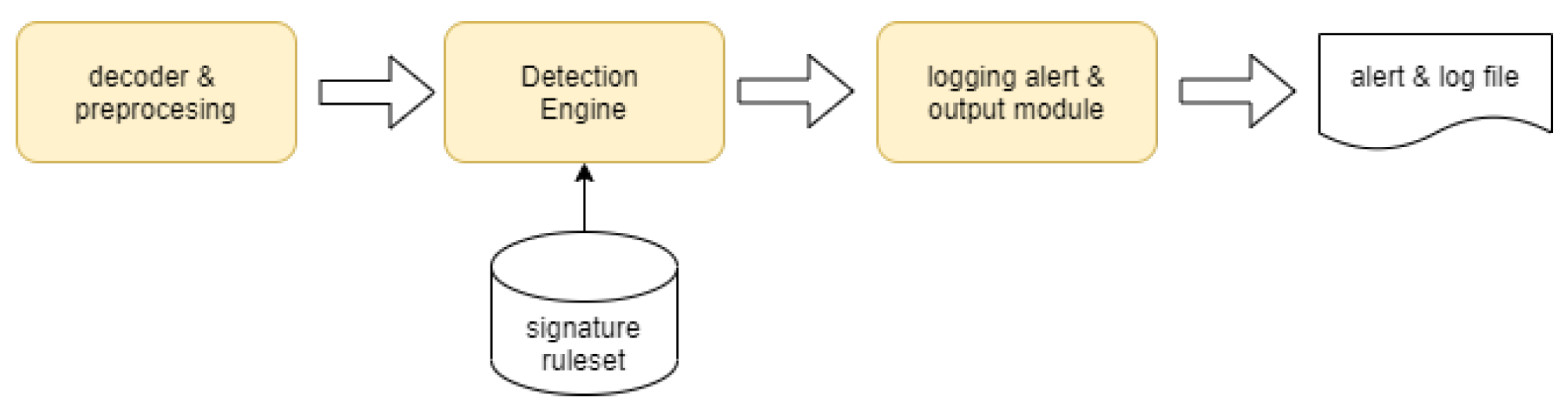
3.1. SIDS and Ruleset Configurations Included in the Study
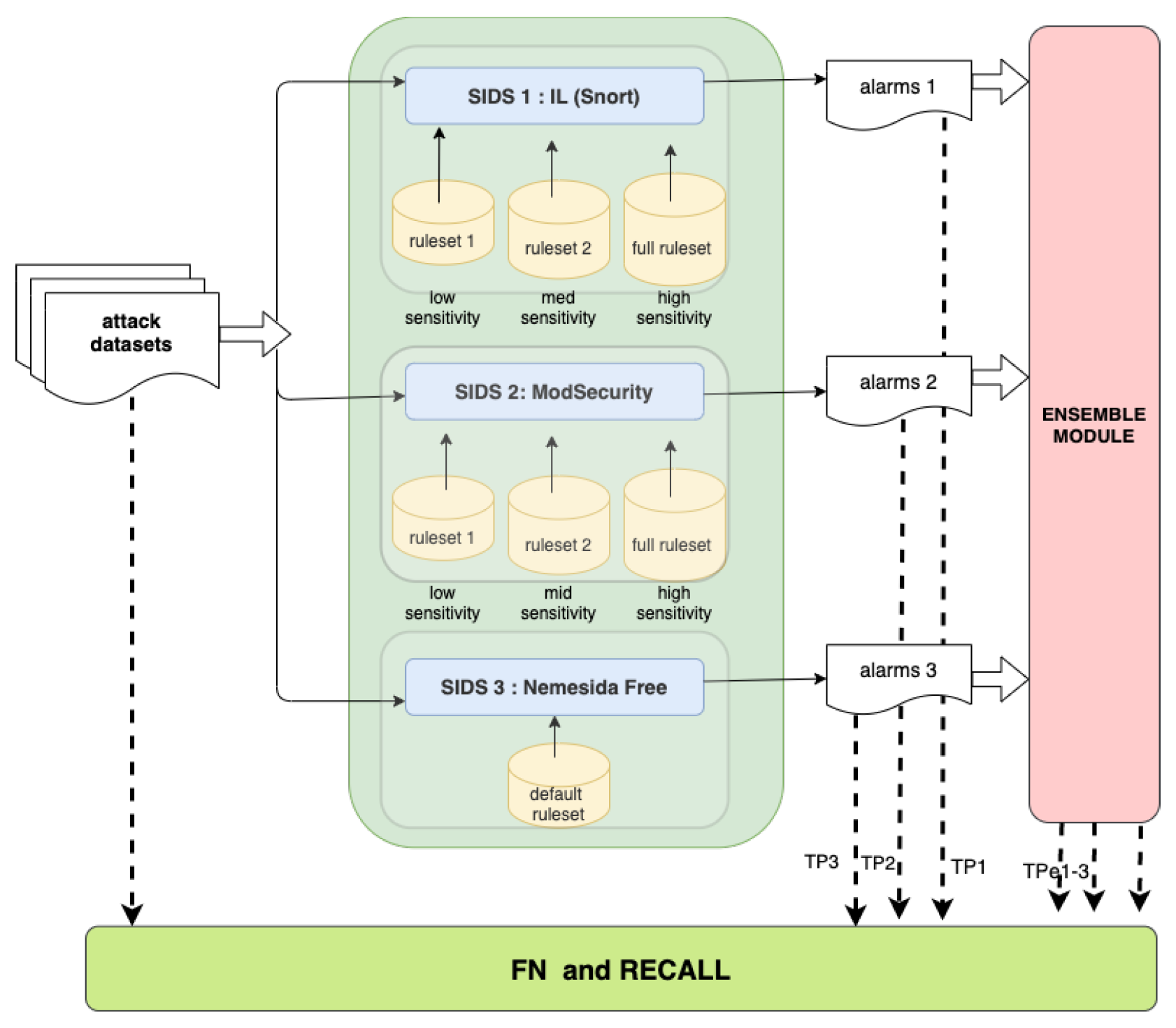
3.2. Experiment 1 Setup: Recall/Detection Rate Metric
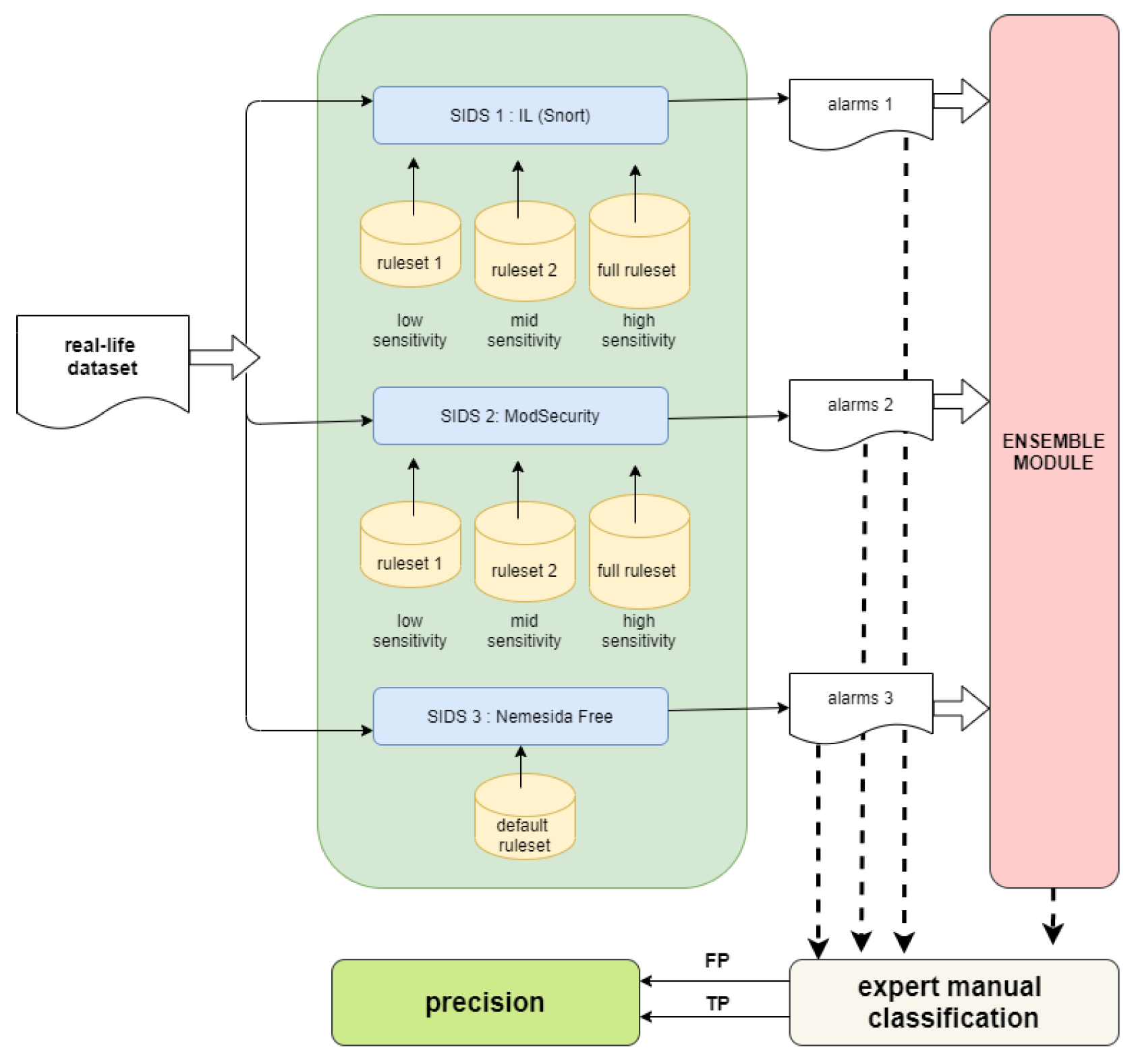
3.3. Experiment 2: Precision Metric
4. Results of Experiment 1: Recall/Detection Rate
4.1. Individual Performance
4.2. Cooperative Decision Performance
- Union. Alarm is produced if an attack is detected by at least one SIDS.
- Voting majority. Alarm is produced if an attack is detected by at least two SIDS.
- Intersection. Alarm is produced only if an attack is detected by the three SIDS.
5. Results of Experiment 2: Precision and Alarm Rate
5.1. Individual Performance
5.2. Cooperative Decision Performance
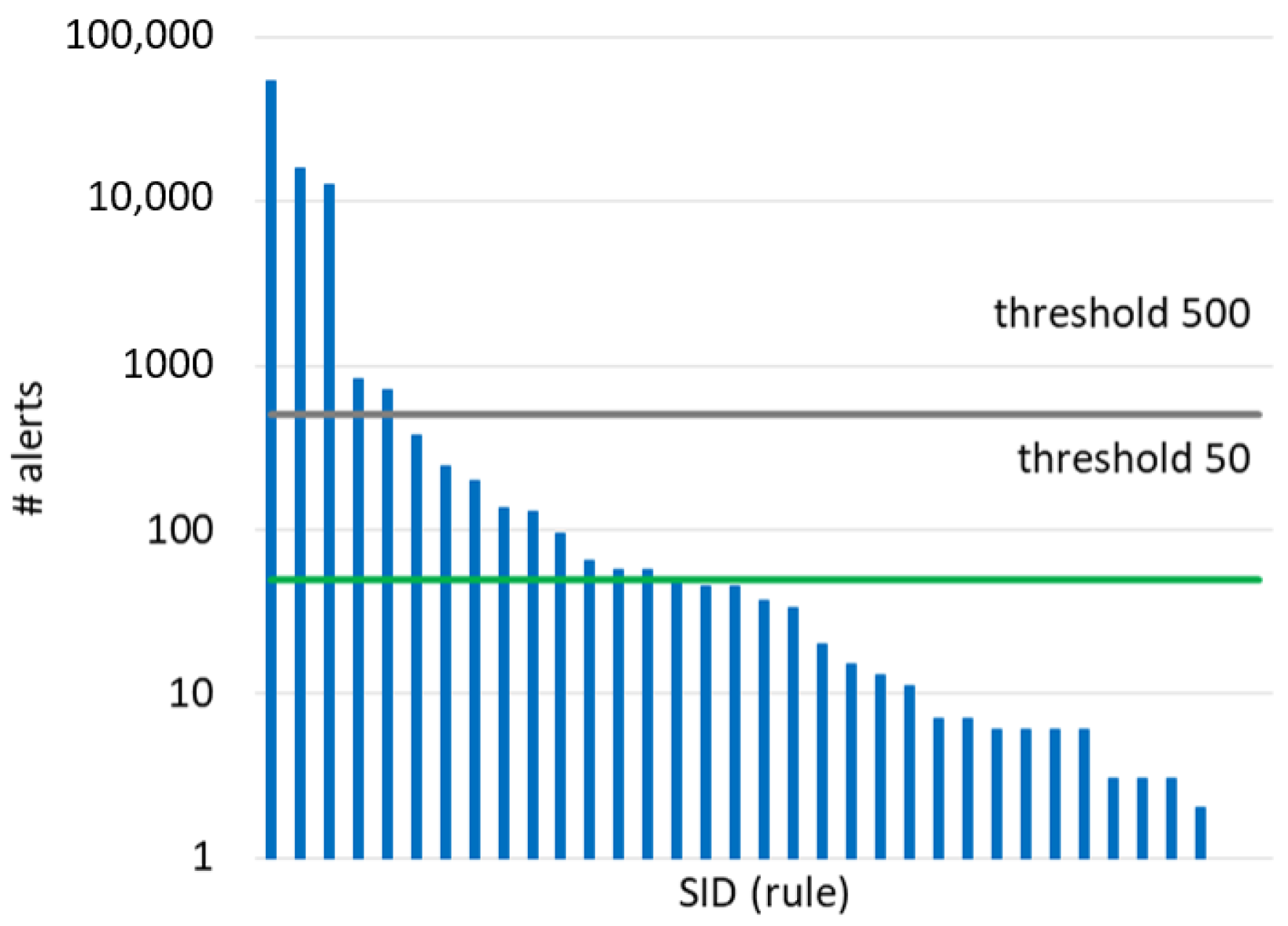
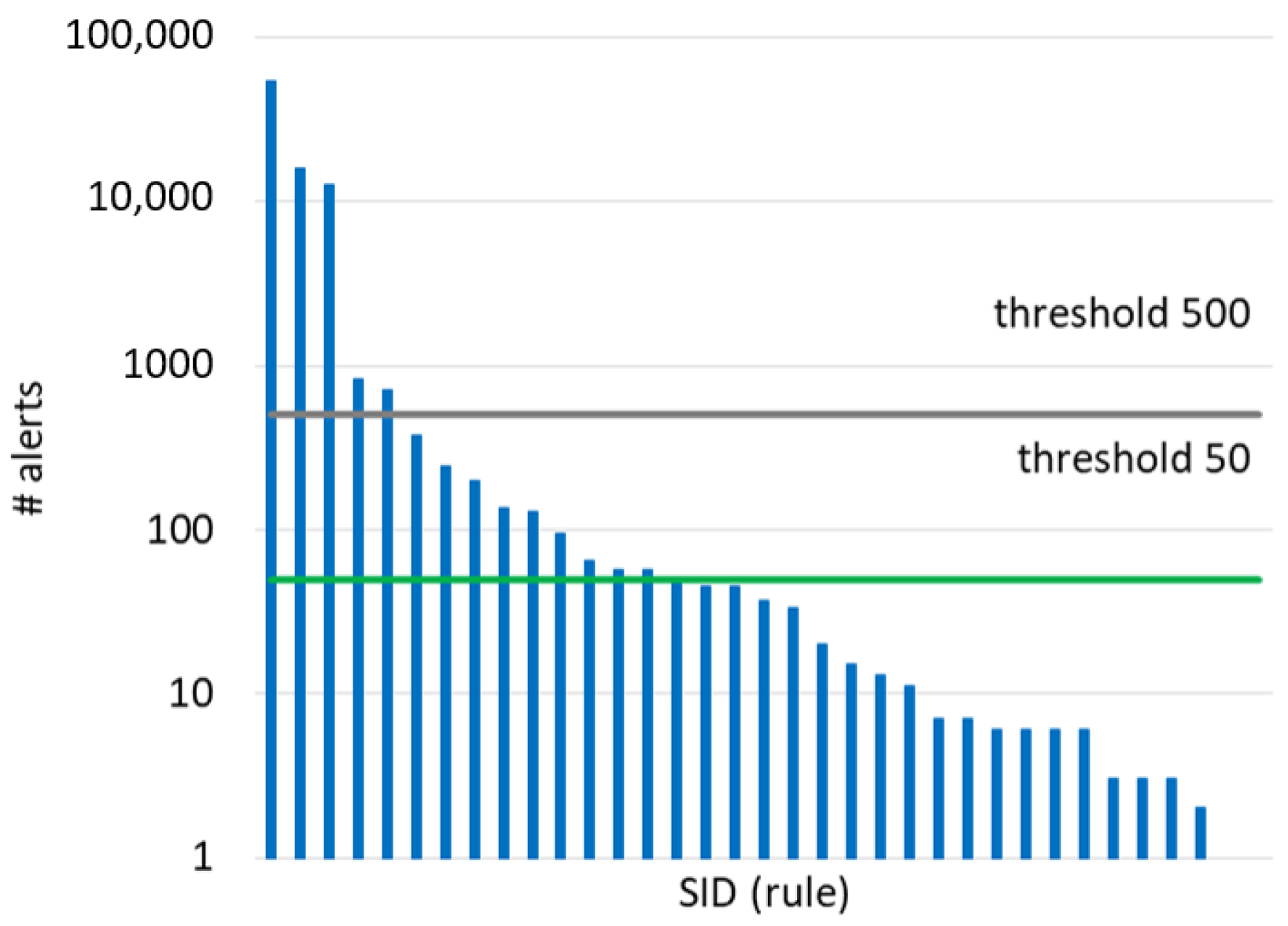
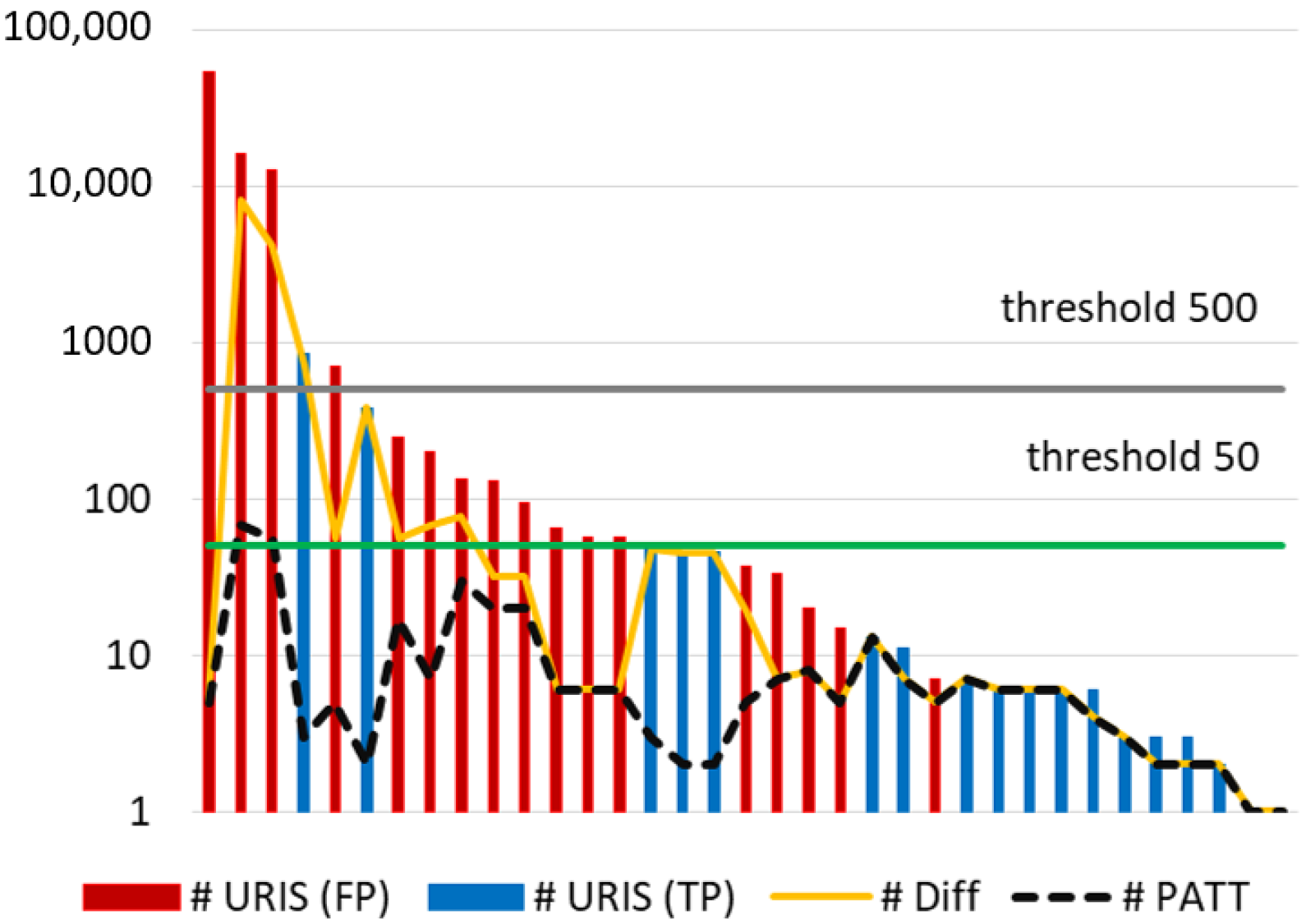
6. Method for Reducing the False Alarm Rate
| Algorithm 1: Algorithm for the selection of rules to be deactivated |
 |
- Delete duplicated URIs in the alerts generated by the rule. This notably reduces the number of alerts to examine. For instance, after suppressing duplicated alerts triggered by the top rule (SID = 1852), 53,738 attacks (URIs) were reduced to only 8.
- Sort the resulting URIs in lexicographic order to facilitate the identification of patterns (i.e., a regular expression common to a set of URIs). For example, URIs that are similar in path and attributes but contain different values in the query will be arranged consecutively.
- Identification of patterns. Note that not all URIs will follow a pattern, but, in our experience, they do to a large extent. Patterns severely reduce the time spent for manual inspection.
- Manually discern TP and FP in the patterns discovered and unpatterned URIs. The decision made for a pattern will be extended to all the URIs that follow that pattern. The decision made for a URI will be also applied to duplicates URIs.
- After the manual classification of the URIs/patterns triggered by the rule, the precision is calculated (). If the rule does not reach the target precision, , it should be deactivated. Otherwise, the rule is included in the final ruleset, and the number of TP is updated to calculate the overall precision of the active ruleset ().
6.1. Cost of Applying the Method
6.2. Benefits of the Tuning Process
7. Limitations
8. Conclusions and Further Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ghafir, I.; Prenosil, V.; Svoboda, J.; Hammoudeh, M. A survey on network security monitoring systems. In Proceedings of the 2016 IEEE 4th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Vienna, Austria, 22–24 August 2016; pp. 77–82. [Google Scholar] [CrossRef] [Green Version]
- Masdari, M.; Khezri, H. A survey and taxonomy of the fuzzy signature-based intrusion detection systems. Appl. Soft Comput. 2020, 92, 106301. [Google Scholar] [CrossRef]
- Moustafa, N.; Hu, J.; Slay, J. A holistic review of network anomaly detection systems: A comprehensive survey. J. Netw. Comput. Appl. 2019, 128, 33–55. [Google Scholar] [CrossRef]
- Holm, H. Signature based intrusion detection for zero-day attacks: (not) a closed chapter? In Proceedings of the 2014 47th Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 6–9 January 2014; pp. 4895–4904. [Google Scholar] [CrossRef] [Green Version]
- Watchguard Launches 2016 Q4 Internet Security Report. Available online: https://www.northamber.com/sites/default/files/marketing/solutionsSite/PDFs/WatchGuard%20-Internet%20Security%20Report%20Q4%202016%20-_v1.pdf (accessed on 27 November 2021).
- Hajj, S.; Sibai, R.E.; Abdo, J.B.; Demerjian, J.; Makhoul, A.; Guyeux, C. Anomaly-based intrusion detection systems: The requirements, methods, measurements, and datasets. Trans. Emerg. Telecommun. Technol. 2021, 32, e4240. [Google Scholar] [CrossRef]
- Sureda Riera, T.; Bermejo Higuera, J.R.; Bermejo Higuera, J.; Martinez Herraiz, J.; Sicilia Montalvo, J.A. Prevention and Fighting against Web Attacks through Anomaly Detection Technology. A Systematic Review. Sustainability 2020, 12, 1–45. [Google Scholar] [CrossRef]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2019, 2, 1–22. [Google Scholar] [CrossRef]
- Hussein, S.M. Performance evaluation of intrusion detection system using anomaly and signature based algorithms to reduction false alarm rate and detect unknown attacks. In Proceedings of the 2016 IEEE International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 15–17 December 2016; pp. 1064–1069. [Google Scholar]
- Praneet, S.; Verma, B. An efficient proactive artificial immune system based anomaly detection and prevention system. Expert Syst. Appl. 2016, 60, 311–320. [Google Scholar]
- Akash, G.; Maheshwari, P. Performance analysis of snort-based intrusion detection system. In Proceedings of the 2016 3rd International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 22–23 January 2016; Volume 1. [Google Scholar]
- Singh, J.J.; Samuel, H.; Zavarsky, P. Impact of paranoia levels on the effectiveness of the modsecurity web application firewall. In Proceedings of the 2018 1st International Conference on Data Intelligence and Security (ICDIS), South Padre Island, TX, USA, 8–10 April 2018; pp. 141–144. [Google Scholar]
- Holm, H.; Ekstedt, M. Estimates on the effectiveness of web application firewalls against targeted attacks. Inf. Manag. Comput. Secur. 2013, 21. [Google Scholar] [CrossRef]
- Neminath, H.; Suryanarayanan, V. False alarm minimization techniques in signature-based intrusion detection systems: A survey. Comput. Commun. 2014, 49, 1–17. [Google Scholar]
- Shah, S.A.R.; Issac, B. Performance comparison of intrusion detection systems and application of machine learning to Snort system. Future Gener. Comput. Syst. 2018, 80, 157–170. [Google Scholar] [CrossRef]
- Arwa, A.; Derhab, A.; Emam, A.Z. Deep learning approaches for anomaly-based intrusion detection systems: A survey, taxonomy, and open issues. Knowl.-Based Syst. 2020, 189, 105124. [Google Scholar]
- Hadi, L.; Ahmad, J.; Mtetwa, N. A heuristic intrusion detection system for Internet-of-Things (IoT). In Intelligent Computing-Proceedings of the Computing Conference; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Díaz-Verdejo, J.E.; Estepa, A.; Estepa, R.; Madinabeitia, G.; Muñoz-Calle, F.J. A methodology for conducting efficient sanitization of http training datasets. Future Gener. Comput. Syst. 2020, 109, 67–82. [Google Scholar] [CrossRef]
- Park, W.; Ahn, S. Performance comparison and detection analysis in snort and suricata environment. Wirel. Pers. Commun. 2017, 94, 241–252. [Google Scholar] [CrossRef]
- Murphy, B.R. Comparing the Performance of Intrusion Detection Systems: Snort and Suricata. Ph.D. Thesis, Colorado Technical University, Colorado Springs, CO, USA, 2019. [Google Scholar]
- Garcia-Teodoro, P.; Diaz-Verdejo, J.; Tapiador, J.; Salazar-Hernandez, R. Automatic generation of http intrusion signatures by selective identification of anomalies. Comput. Secur. 2015, 55, 159–174. [Google Scholar] [CrossRef]
- Gu, G.; Fogla, P.; Dagon, D.; Lee, W.; Skorić, B. Measuring intrusion detection capability: An information-theoretic approach. In Proceedings of the 2006 ACM Symposium on Information, Computer and Communications Security, ASIACCS ’06, Taipei, Taiwan, 21–24 March 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 90–101. [Google Scholar] [CrossRef]
- Tjhai, G.; Papadaki, M.; Furnell, S.; Clarke, N. Investigating the problem of ids false alarms: An experimental study using snort. In Proceedings of the IFIP TC 11 23rd International Information Security Conference, Milano, Italy, 7–10 September 2008; Jajodia, S., Samarati, P., Cimato, S., Eds.; Springer: Boston, MA, USA, 2008; Volume 278, pp. 253–267. [Google Scholar] [CrossRef]
- Afzal, Z.; Lindskog, S. Ids rule management made easy. In Proceedings of the 2016 8th International Conference on Electronics, Computers and Artificial Intelligence (ECAI), Ploiesti, Romania, 30 June–2 July 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Asad, H.; Gashi, I. Diversity in open source intrusion detection systems. In Computer Safety, Reliability, and Security; Gallina, B., Skavhaug, A., Bitsch, F., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 267–281. [Google Scholar]
- Subba, B.; Biswas, S.; Karmakar, S. False alarm reduction in signature-based ids: Game theory approach. Secur. Commun. Netw. 2016, 9, 4863–4881. [Google Scholar] [CrossRef]
- Agrawal, S.; Agrawal, J. Survey on anomaly detection using data mining techniques. Procedia Comput. Sci. 2015, 60, 708–713. [Google Scholar] [CrossRef] [Green Version]
- Waagsnes, H.; Ulltveit-Moe, N. Intrusion detection system test framework for scada systems. In Proceedings of the 4th International Conference on Information Systems Security and Privacy-ICISSP, Madeira, Portugal, 22–24 January 2018; pp. 275–285. [Google Scholar] [CrossRef]
- Albin, E.; Rowe, N.C. A realistic experimental comparison of the suricata and snort intrusion-detection systems. In Proceedings of the 2012 26th International Conference on Advanced Information Networking and Applications Workshops, Fukuoka-shi, Japan, 26–29 March 2012; pp. 122–127. [Google Scholar] [CrossRef]
- Chitrakar, R.; Huang, C. Anomaly based intrusion detection using hybrid learning approach of combining k-medoids clustering and naïve bayes classification. In Proceedings of the 2012 8th International Conference on Wireless Communications, Networking and Mobile Computing, Shanghai, China, 27–31 August 2012; pp. 1–5. [Google Scholar] [CrossRef]
- Singh, S.; Sharma, P.; Moon, S.; Park, J. A hybrid layered architecture for detection and analysis of network based zero-day attack. Comput. Commun. 2017, 106, 100–106. [Google Scholar] [CrossRef]
- Kumar, G.; Thakur, K.; Ayyagari, M.R. MLEsIDSs: Machine learning-based ensembles for intrusion detection systems—A review. J. Supercomput. 2020, 76, 8938–8971. [Google Scholar] [CrossRef]
- Peddabachigari, S.; Abraham, A.; Grosan, C.; Thomas, J. Modeling intrusion detection system using hybrid intelligent systems. J. Netw. Comput. Appl. 2007, 30, 114–132. [Google Scholar] [CrossRef]
- Zhong, Y.; Chen, W.; Wang, Z.; Chen, Y.; Wang, K.; Li, Y.; Yin, X.; Shi, X.; Yang, J.; Li, K. Helad: A novel network anomaly detection model based on heterogeneous ensemble learning. Comput. Netw. 2020, 169, 107049. [Google Scholar] [CrossRef]
- Spathoulas, G.P.; Katsikas, S.K. Enhancing ids performance through comprehensive alert post-processing. Comput. Secur. 2013, 37, 176–196. [Google Scholar] [CrossRef]
- Raftopoulos, E.; Dimitropoulos, X. A quality metric for IDS signatures: In the wild the size matters. Eurasip J. Inf. Secur. 2013, 2013, 7. [Google Scholar] [CrossRef] [Green Version]
- Estepa, R.; Díaz-Verdejo, J.E.; Estepa, A.; Madinabeitia, G. How much training data is enough? a case study for http anomaly-based intrusion detection. IEEE Access 2020, 8, 44410–44425. [Google Scholar] [CrossRef]
- Modsecurity Open Source Web Application Firewall. Available online: https://github.com/SpiderLabs/ModSecurity (accessed on 27 November 2021).
- Snort-Network Intrusion Detection & Prevention System. Available online: https://www.snort.org (accessed on 27 November 2021).
- Obi, C.A.; Papadaki, M. Guidelines/recommendations on best practices in fine tuning ids alarms. In Advances in Networks, Computing and Communications; Dowland, P., Furnell, S., Eds.; University of Plymouth: Plymouth, UK, 2011; Volume 6, pp. 107–114. [Google Scholar]
- Yu, Z.; Tsai, J.J.P.; Weigert, T. An adaptive automatically tuning intrusion detection system. ACM Trans. Auton. Adapt. Syst. 2008, 3. [Google Scholar] [CrossRef]
- Sonchack, J.; Aviv, A.J.; Smith, J.M. Cross-domain collaboration for improved ids rule set selection. J. Inf. Secur. Appl. 2015, 24–25, 25–40. [Google Scholar] [CrossRef] [Green Version]
- Kumar, M.; Hanumanthappa, M. Self tuning ids for changing environment. In Proceedings of the 2014 International Conference on Computational Intelligence and Communication Networks, Bhopal, India, 14–16 November 2014; pp. 1083–1087. [Google Scholar] [CrossRef]
- Badawy, M.A.; El-Fishawy, N.A.; Elshakankiry, O. Using patch management tools to enhance the signature customization for ids based on vulnerability scanner. In Proceedings of the 2014 11th International Conference on Information Technology: New Generations, Las Vegas, NV, USA, 7–9 April 2014; pp. 529–533. [Google Scholar] [CrossRef]
- Nemesida Web Application Firewall. Available online: https://nemesida-waf.com (accessed on 27 November 2021).
- Fwaf-Machine-Learning-Driven-Web-Application-Firewall. Available online: https://github.com/faizann24/Fwaf-Machine-Learning-driven-Web-Application-Firewall (accessed on 27 November 2021).
- Verdejo, J.E.D.; Alonso, R.M.E.; Alonso, A.J.E.; Luque, G.M.; Rodriguez, D. Metodología para la generación de conjuntos de datos de ataques basados en uri de http. In Actas de las Cuartas Jornadas Nacionales de Investigación en Ciberseguridad, 1st ed.; Mondragon Unibertsitatea: Mondragón, Spain, 2018; pp. 119–126. [Google Scholar]
- Salazar-Hernández, R.; Díaz-Verdejo, J.E. Hybrid detection of application layer attacks using markov models for normality and attacks. In Information and Communications Security; Soriano, M., Qing, S., López, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 416–429. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SIDS | Detection Sensitivity (Configuration) | Base Rule Set |
|---|---|---|
| InspectorLog [18] (Snort rules) | low. (default recommended rules) med. (all rules except DELETED) max. (all rules) | Talos (2021) |
| ModSecurity [38] | low. (PL1) med. (PL2) max. (PL4) | OWASP CRS 3.2.0 (2019) |
| Nemesida WAF [45] | default (Free version) | proprietary (September-2021) |
| Dataset | #URIs | Type (Source) | Content | Remarks |
|---|---|---|---|---|
| Fwaf-bad | 48 216 | public [46] | attacks (<2017) | WAF attacks |
| Fwaf-2200 | 2 200 | public [46] | attacks (<2017) | Fwaf-bad’s subset for CVEs covered by rules |
| ataques-800 | 832 | in-house [47] | attacks (<2017) | type-3 CVE included in Snort’s signatures |
| ataques-1100 | 1176 | in-house [47] | attacks (≤2017) | types 1 (CVE 2016 and 2017), 3 and 4 |
| rdb | 934 | in-house [21] | attacks (<2009) | attacks generated from RDB |
| osvdb | 6897 | in-house [48] | attacks (<2009) | attacks generated from OSVDB |
| A-420 | 420 | in-house | attacks (2017/18) | attacks generated with CVE 2017-18 and CVSS>9 |
| Dataset | Inspectorlog | ModSecurity | Nemesida | ||||
|---|---|---|---|---|---|---|---|
| low | med. | max. | low | med. | max. | Default | |
| attacks-800 | 0.48 | 87.14 | 92.07 | 8.41 | 42.55 | 70.43 | 68.03 |
| attacks-1100 | 0.60 | 89.37 | 93.71 | 5.70 | 51.96 | 75.17 | 72.45 |
| fwaf-bad | 0.99 | 61.12 | 66.16 | 8.63 | 30.59 | 55.80 | 52.37 |
| fwaf-2200 | 2.55 | 86.73 | 91.23 | 6.36 | 63.86 | 89.18 | 96.59 |
| rdb | 0.11 | 88.22 | 91.01 | 10.49 | 39.40 | 66.17 | 64.24 |
| osvdb | 5.87 | 58.43 | 66.96 | 2.64 | 65.67 | 80.37 | 54.72 |
| a-420 | 47.14 | 81.19 | 81.67 | 0.71 | 68.1 | 79.29 | 38.81 |
| AVERAGE | 8.25 | 78.89 | 83.26 | 6.13 | 51.73 | 73.77 | 63.89 |
| Dataset | Union | Voting Majority | Intersection | ||||||
|---|---|---|---|---|---|---|---|---|---|
| low | med. | max. | low | med. | max. | low | med. | max. | |
| attacks-800 | 72.5 | 95.6 | 98.1 | 4.3 | 71.1 | 79.7 | 0.0 | 31.0 | 52.6 |
| attacks-1100 | 74.7 | 95.8 | 98.4 | 4.0 | 75.1 | 82.0 | 0.0 | 42.7 | 60.7 |
| fwaf-bad | 58.8 | 86.6 | 97.4 | 3.2 | 44.0 | 51.3 | 0.0 | 14.2 | 26.2 |
| fwaf-2200 | 97.5 | 98.7 | 99.3 | 8.0 | 91.0 | 95.0 | 0.0 | 57.5 | 82.7 |
| rdb | 68.8 | 93.7 | 95.8 | 6.1 | 69.8 | 76.6 | 0.0 | 28.7 | 49.2 |
| osvdb | 58.3 | 86.8 | 92.5 | 7.0 | 64.4 | 71.4 | 0.0 | 33.3 | 44.6 |
| a-420 | 83.8 | 92.9 | 95.0 | 2.9 | 76.9 | 81.9 | 0.0 | 18.8 | 22.9 |
| AVERAGE | 73.5 | 92.8 | 96.7 | 5.1 | 70.3 | 76.8 | 0.0 | 32.3 | 48.4 |
| # Alerts | #TP | #FP | Precision | #Alerts/Day | ||
|---|---|---|---|---|---|---|
| Inspectorlog | low | 57 | 57 | 0 | 1.000 | 1.9 |
| med. | 85,641 | 1356 | 84,285 | 0.016 | 2854.7 | |
| max. | 91,791 | 1356 | 90,435 | 0.015 | 3059.7 | |
| ModSecurity | low | 2299 | 868 | 1431 | 0.378 | 76.6 |
| med. | 23,820 | 1714 | 22,106 | 0.072 | 794.0 | |
| Nemesida | Default | 2551 | 2127 | 424 | 0.834 | 85.0 |
| Union | Voting Majority | Intersection | |||||||
|---|---|---|---|---|---|---|---|---|---|
| low | med. | max. | low | med. | max. | low | med. | max. | |
| #Alerts | 3952 | 96,927 | 102,941 | 1625 | 14,317 | 14,452 | 52 | 1308 | 1312 |
| #FP | 1721 | 94,661 | 100,675 | 234 | 12,693 | 12,828 | 0 | 0 | 0 |
| #TP | 2231 | 2266 | 2266 | 1391 | 1624 | 1624 | 52 | 1308 | 1312 |
| Precision | 0.565 | 0.023 | 0.022 | 0.856 | 0.113 | 0.112 | 1.000 | 1.000 | 1.000 |
| #alerts/day | 131.7 | 3230.9 | 3431.4 | 54.2 | 477.2 | 481.7 | 1.7 | 43.6 | 43.7 |
| SID | freq. | DESCRIPTION |
|---|---|---|
| 1852 | 53738 | SERVER-WEBAPP robots.txt access |
| 41742 | 16182 | POLICY-OTHER external admin access attempt |
| 17410 | 12643 | OS-WINDOWS Generic HyperLink buffer overflow attempt |
| 1122 | 834 | SERVER-WEBAPP/etc./passwd file access attempt |
| 23362 | 707 | [SERVER-IIS tilde character file name discovery attempt-sid: 23362] |
| 13990 | 381 | SQL union select-possible sql injection attempt-GET parameter |
| 20528 | 245 | [SERVER-APACHE Apache mod_proxy reverse proxy information disclosure attempt-sid: 20528] |
| 1070 | 197 | [SERVER-WEBAPP WebDAV search access-sid: 1070] |
| 2056 | 134 | [SERVER-WEBAPP TRACE attempt-sid: 2056] |
| 17609 | 128 | [SERVER-WEBAPP Oracle Java Web Server WebDAV Stack Buffer Overflow attempt-sid: 17609] |
| Target Precision | # Rules | # Activated | # FP | # TP | Precision | Time (h) |
|---|---|---|---|---|---|---|
| =0 | 3198 | 35 | 84,285 | 1356 | 0.015 | 0 |
| = 0.5 | 3193 | 30 | 1030 | 1356 | 0.568 | 7.4 |
| = 0.9 | 3185 | 21 | 97 | 1356 | 0.933 | 12.2 |
| = 1 | 3179 | 18 | 0 | 1356 | 1 | 16.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Díaz-Verdejo, J.; Muñoz-Calle, J.; Estepa Alonso, A.; Estepa Alonso, R.; Madinabeitia, G. On the Detection Capabilities of Signature-Based Intrusion Detection Systems in the Context of Web Attacks. Appl. Sci. 2022, 12, 852. https://doi.org/10.3390/app12020852
Díaz-Verdejo J, Muñoz-Calle J, Estepa Alonso A, Estepa Alonso R, Madinabeitia G. On the Detection Capabilities of Signature-Based Intrusion Detection Systems in the Context of Web Attacks. Applied Sciences. 2022; 12(2):852. https://doi.org/10.3390/app12020852
Chicago/Turabian StyleDíaz-Verdejo, Jesús, Javier Muñoz-Calle, Antonio Estepa Alonso, Rafael Estepa Alonso, and Germán Madinabeitia. 2022. "On the Detection Capabilities of Signature-Based Intrusion Detection Systems in the Context of Web Attacks" Applied Sciences 12, no. 2: 852. https://doi.org/10.3390/app12020852
APA StyleDíaz-Verdejo, J., Muñoz-Calle, J., Estepa Alonso, A., Estepa Alonso, R., & Madinabeitia, G. (2022). On the Detection Capabilities of Signature-Based Intrusion Detection Systems in the Context of Web Attacks. Applied Sciences, 12(2), 852. https://doi.org/10.3390/app12020852