
Multi-Granularity Semantic Collaborative Reasoning Network for Visual Dialog

Abstract
:1. Introduction
2. Related Work
Visual Dialog
3. Methodology
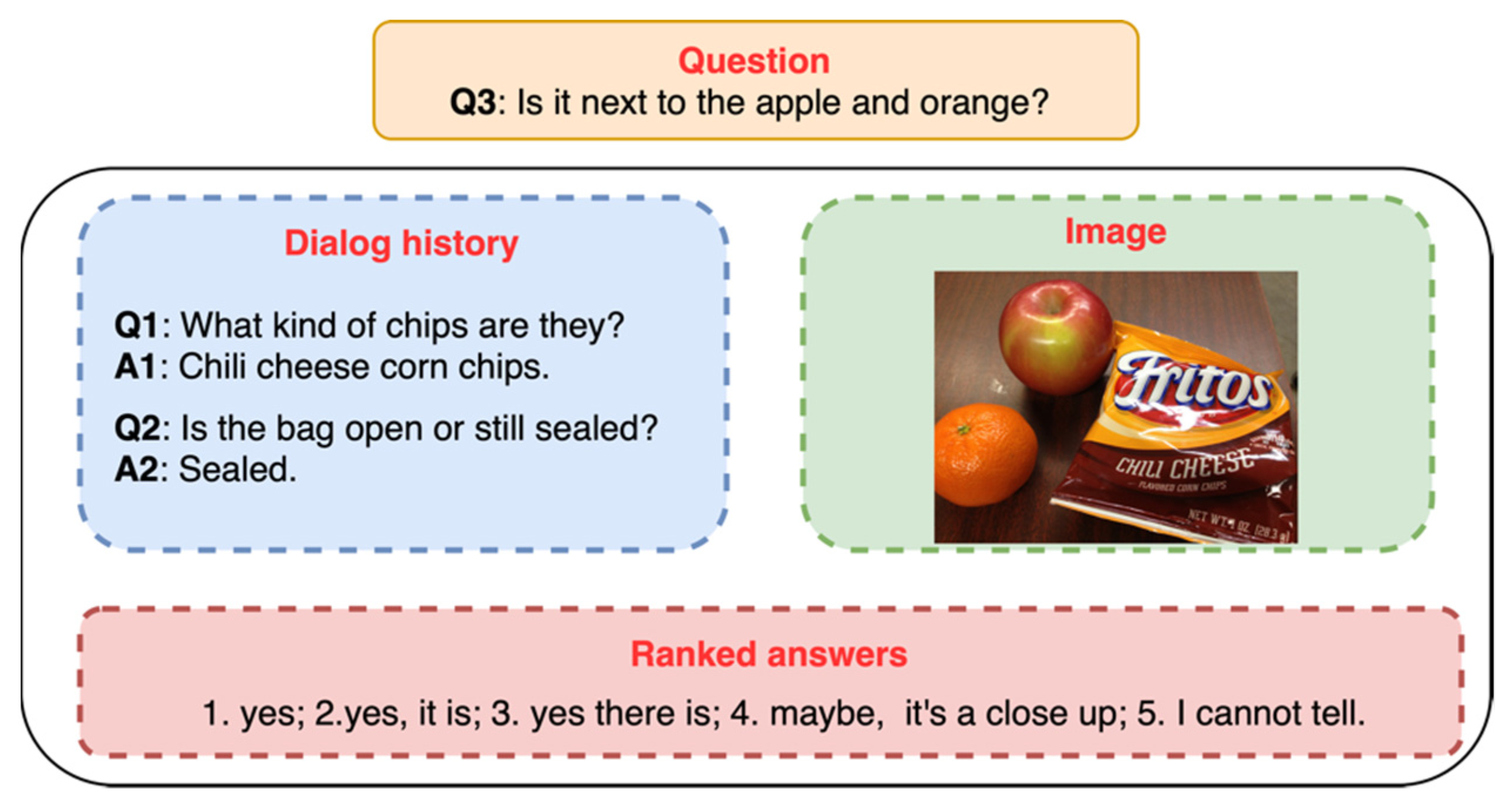
3.1. Problem Definition
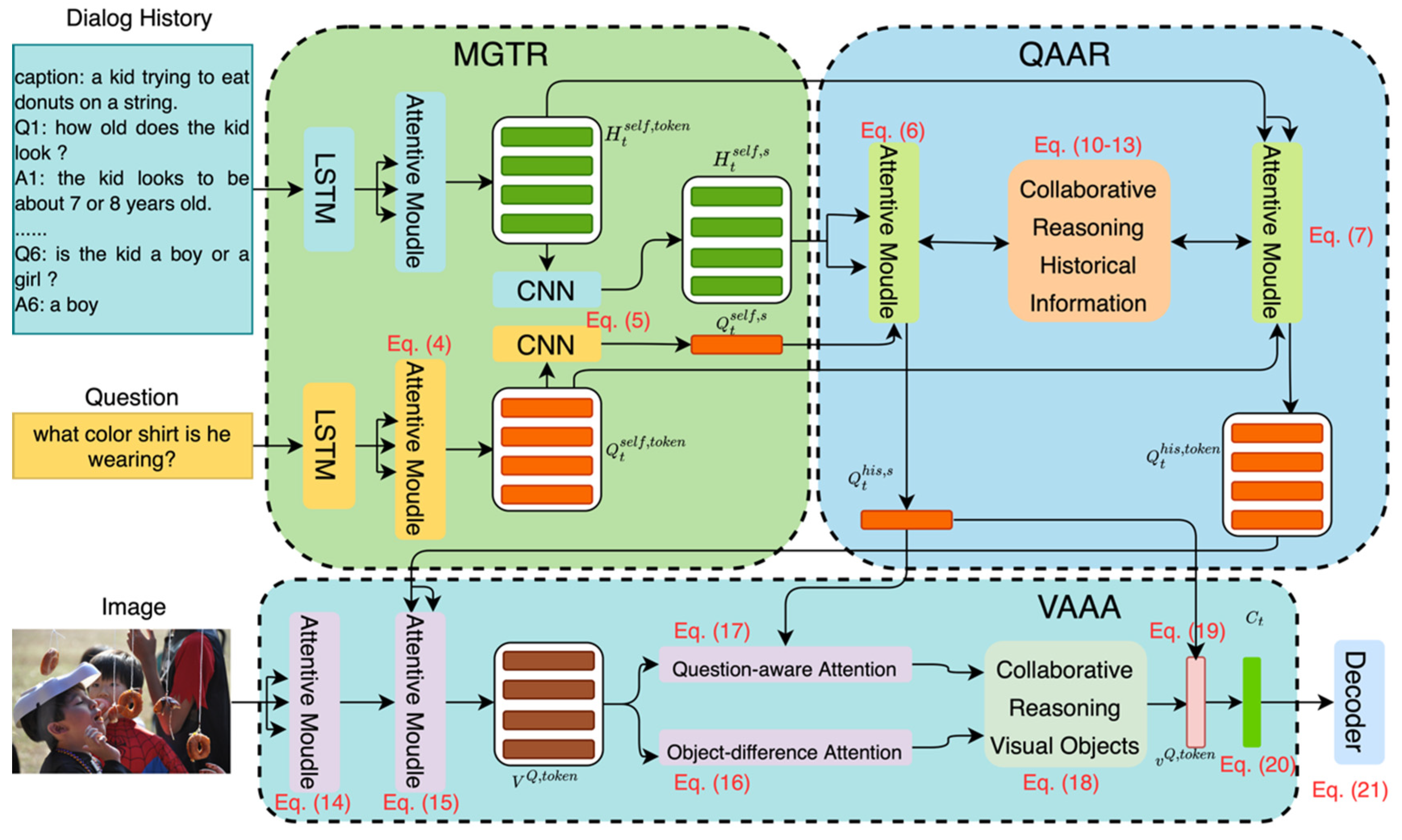
3.2. MGSCRN
3.2.1. MGTR
3.2.2. QAAR
3.2.3. VAAA
3.3. Discriminative Decoder
4. Experimental Setup and Metrics
4.1. Datasets
4.2. Evaluation Metrics
4.3. Training Details
5. Experimental Results and Analysis
5.1. Comparison with State-of-the-Art Methods
5.1.1. Results on Test-Standard v1.0 Split
5.1.2. Results on VisPro and VisDialConv Datasets
5.2. Ablation Study
- Sentence-granularity semantic representations (SgSR): This model used only sentence-granularity semantic representations of the question and dialog history to acquire clues via the attentive module and CNN (Equations (4)–(6)). Then, it located question-related visual objects from using the question-aware attention (Equation (17));
- Token-granularity semantic representations (TgSR): This model used only token-granularity semantic representations of the question and dialog history to acquire clues via the attentive module (Equations (4) and (7)). Then, it located question-related visual objects from : we first use the object-difference attention mechanism (Equation (16)) to obtain distribution on all of the visual objects, ; second, the final question-relevant visual representation is computed by . The -fused question features is fed to the discriminative decoder to predict answers;
- TgSR without object-difference attention (TgSR w/o OdA): In this model, we performed self-attention instead of object-difference attention on to locate question-related visual objects. The other settings matched those of TgSR;
- SgSR+TgSR: This model further combined SgSR and TgSR. Specifically, in the discriminative decoder, two probability distributions over answer candidates from SgSR and TgSR were added after normalization to produce the final distribution. It notably did not include collaborative reasoning historical information (CRHI) and collaborative reasoning visual object (CRVO) operations;
- MGSCRN: This is our full semantic model, which combined SgSR and TgSR with CRHI and CRVO operations.
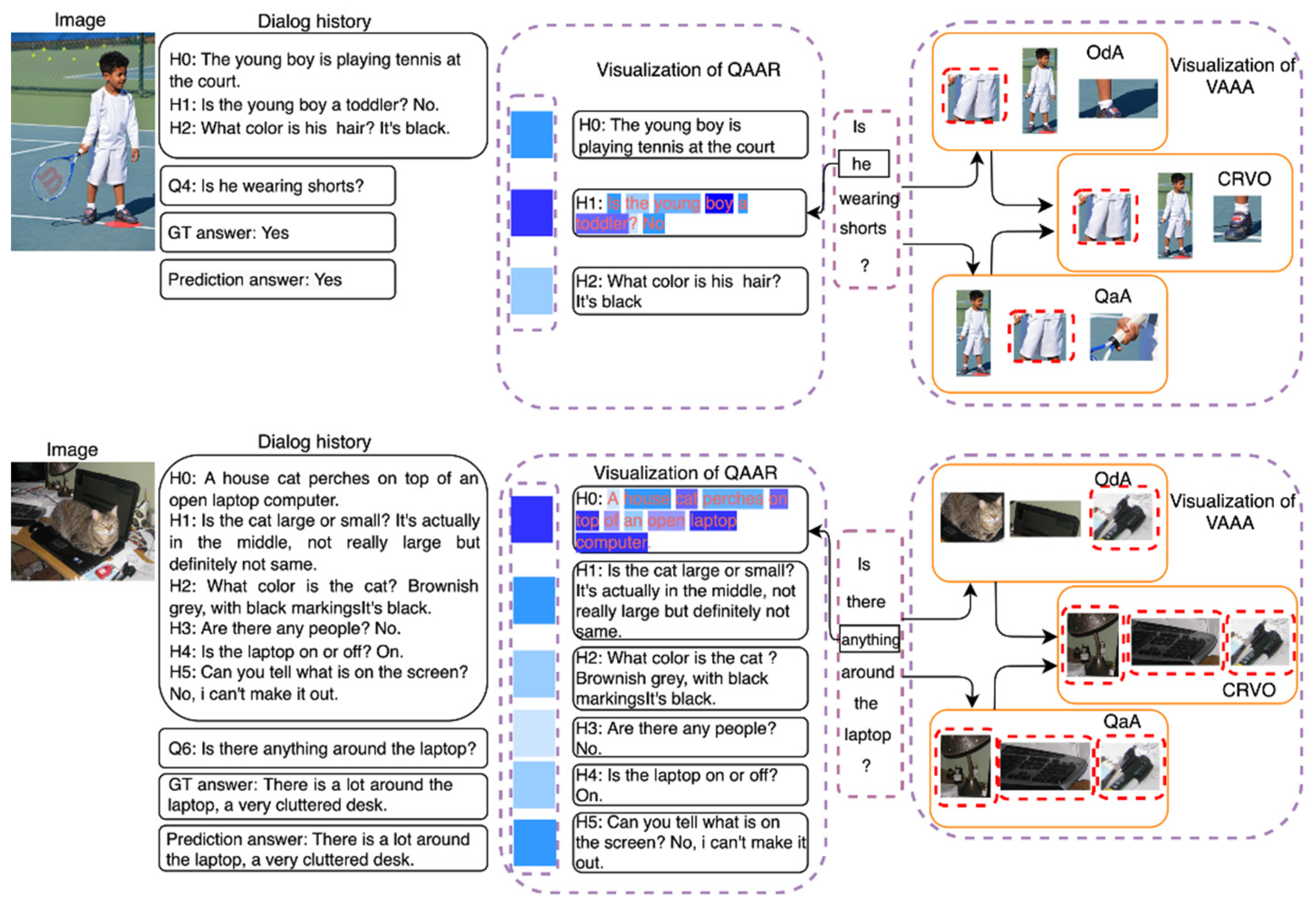
5.3. Qualitative Analysis
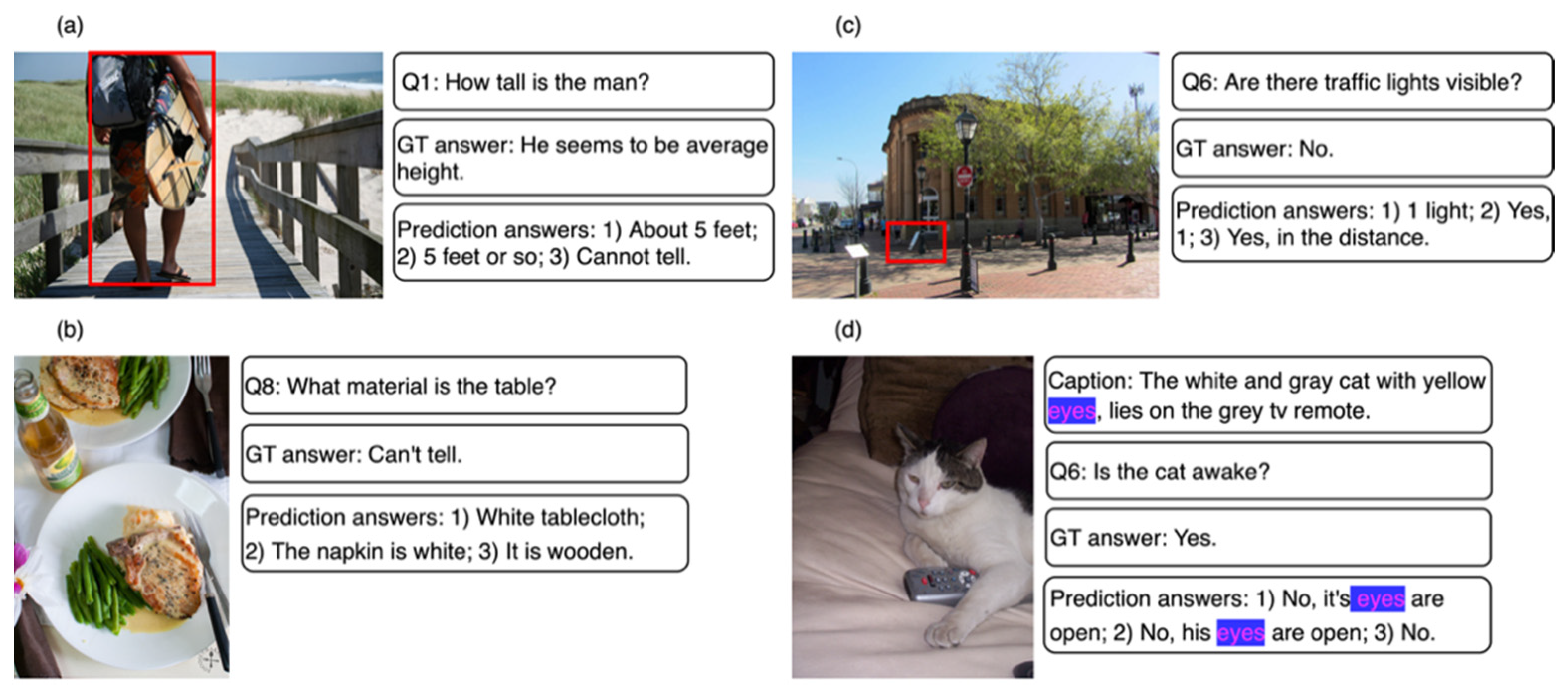
5.4. Error Case Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, L.; Liu, J.; Tang, J.; Li, J.; Luo, W.; Lu, H. Aligning Linguistic Words and Visual Semantic Units for Image Captioning. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 765–773. [Google Scholar]
- Zhan, H.; Xiong, P.; Wang, X.; Wang, X.; Yang, L. Visual Question Answering by Pattern Matching and Reasoning. Neurocomputing 2022, 467, 323–336. [Google Scholar] [CrossRef]
- Liu, J.; Wang, W.; Wang, L.; Yang, M.-H. Attribute-Guided Attention for Referring Expression Generation and Comprehension. IEEE Trans. Image Process. 2020, 29, 5244–5258. [Google Scholar] [CrossRef] [PubMed]
- Das, A.; Kottur, S.; Gupta, K.; Singh, A.; Yadav, D.; Lee, S.; Moura, J.M.F.; Parikh, D.; Batra, D. Visual Dialog. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1242–1256. [Google Scholar] [CrossRef] [PubMed]
- Kang, G.-C.; Lim, J.; Zhang, B.-T. Dual Attention Networks for Visual Reference Resolution in Visual Dialog. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 2024–2033. [Google Scholar]
- Gan, Z.; Cheng, Y.; Kholy, A.; Li, L.; Liu, J.; Gao, J. Multi-Step Reasoning via Recurrent Dual Attention for Visual Dialog. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 6463–6474. [Google Scholar]
- Chen, F.; Meng, F.; Xu, J.; Li, P.; Xu, B.; Zhou, J. DMRM: A Dual-Channel Multi-Hop Reasoning Model for Visual Dialog. AAAI 2020, 34, 7504–7511. [Google Scholar] [CrossRef]
- Nguyen, V.-Q.; Suganuma, M.; Okatani, T. Efficient Attention Mechanism for Visual Dialog That Can Handle All the Interactions between Multiple Inputs. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Agarwal, S.; Bui, T.; Lee, J.-Y.; Konstas, I.; Rieser, V. History for Visual Dialog: Do We Really Need It? In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 8182–8197. [Google Scholar]
- Park, S.; Whang, T.; Yoon, Y.; Lim, H. Multi-View Attention Network for Visual Dialog. Appl. Sci. 2021, 11, 3009. [Google Scholar] [CrossRef]
- Punia, S.K.; Kumar, M.; Stephan, T.; Deverajan, G.G.; Patan, R. Performance analysis of machine learning algorithms for big data classification: Ml and ai-based algorithms for big data analysis. Int. J. E-Health Med. Commun. (IJEHMC) 2021, 12, 60–75. [Google Scholar] [CrossRef]
- Rao, D.; Huang, S.; Jiang, Z.; Deverajan, G.G.; Patan, R. A dual deep neural network with phrase structure and attention mechanism for sentiment analysis. Neural Comput. Appl. 2021, 33, 11297–11308. [Google Scholar] [CrossRef]
- Niu, Y.; Zhang, H.; Gopal, G. Emerging Trends and the Importance of Network Evolution in Big Data. Recent Adv. Comput. Sci. Commun. (Former. Recent Patents Comput. Sci.) 2020, 13, 158. [Google Scholar]
- De Vries, H.; Strub, F.; Chandar, S.; Pietquin, O.; Larochelle, H.; Courville, A. GuessWhat?! Visual Object Discovery through Multi-Modal Dialogue. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 4466–4475. [Google Scholar]
- Lin, B.; Zhu, Y.; Liang, X. Heterogeneous Excitation-and-Squeeze Network for Visual Dialog. Neurocomputing 2021, 449, 399–410. [Google Scholar] [CrossRef]
- Niu, Y.; Zhang, H.; Zhang, M.; Zhang, J.; Lu, Z.; Wen, J.-R. Recursive Visual Attention in Visual Dialog. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6672–6681. [Google Scholar]
- Zhang, H.; Wang, X.; Jiang, S. Reciprocal Question Representation Learning Network for Visual Dialog. Appl. Intell. 2022. [Google Scholar] [CrossRef]
- Jiang, T.; Shao, H.; Tian, X.; Ji, Y.; Liu, C. Aligning Vision-Language for Graph Inference in Visual Dialog. Image Vis. Comput. 2021, 116, 104316. [Google Scholar] [CrossRef]
- Guo, D.; Wang, H.; Wang, M. Context-Aware Graph Inference with Knowledge Distillation for Visual Dialog. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Joty, S.; Lyu, M.; King, I.; Xiong, C.; Hoi, S.C.H. VD-BERT: A Unified Vision and Dialog Transformer with BERT. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 3325–3338. [Google Scholar]
- Murahari, V.; Batra, D.; Parikh, D.; Das, A. Large-Scale Pretraining for Visual Dialog: A Simple State-of-the-Art Baseline. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Long Beach, CA, USA, 2017; pp. 6000–6010. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 26–28 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 1532–1543. [Google Scholar]
- Choi, H.; Kim, J.; Joe, S.; Gwon, Y. Evaluation of BERT and ALBERT Sentence Embedding Performance on Downstream NLP Tasks. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 5482–5487. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.-J.; Shamma, D.A.; et al. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. ISBN 978-3-319-10601-4. [Google Scholar]
- Kottur, S.; Moura, J.M.F.; Parikh, D.; Batra, D.; Rohrbach, M. Visual Coreference Resolution in Visual Dialog Using Neural Module Networks. In Computer Vision—ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11219, pp. 160–178. ISBN 978-3-030-01266-3. [Google Scholar]
- Zheng, Z.; Wang, W.; Qi, S.; Zhu, S.-C. Reasoning Visual Dialogs with Structural and Partial Observations. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6662–6671. [Google Scholar]
- Schwartz, I.; Yu, S.; Hazan, T.; Schwing, A.G. Factor Graph Attention. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2039–2048. [Google Scholar]
- Guo, D.; Wang, H.; Wang, M. Dual Visual Attention Network for Visual Dialog. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; International Joint Conferences on Artificial Intelligence Organization: Brussels, Belgium, 2019; pp. 4989–4995. [Google Scholar]
- Jiang, X.; Yu, J.; Qin, Z.; Zhuang, Y.; Zhang, X.; Hu, Y.; Wu, Q. DualVD: An Adaptive Dual Encoding Model for Deep Visual Understanding in Visual Dialogue. AAAI 2020, 34, 11125–11132. [Google Scholar] [CrossRef]
- Yang, T.; Zha, Z.-J.; Zhang, H. Making History Matter: History-Advantage Sequence Training for Visual Dialog. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2561–2569. [Google Scholar]
- Guo, D.; Xu, C.; Tao, D. Image-Question-Answer Synergistic Network for Visual Dialog. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 10426–10435. [Google Scholar]
- Guo, D.; Wang, H.; Wang, S.; Wang, M. Textual-Visual Reference-Aware Attention Network for Visual Dialog. IEEE Trans. Image Process. 2020, 29, 6655–6666. [Google Scholar] [CrossRef]
- Chen, F.; Chen, X.; Xu, C.; Jiang, D. Learning to Ground Visual Objects for Visual Dialog. arXiv 2021, arXiv:2109.06013. [Google Scholar]
- Kim, H.; Tan, H.; Bansal, M. Modality-Balanced Models for Visual Dialogue. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | NDCG↑ | MRR↑ | R@1↑ | R@5↑ | R@10↑ | Mean↓ |
|---|---|---|---|---|---|---|
| LF | 45.31 | 55.42 | 40.95 | 72.45 | 82.83 | 5.95 |
| HRE | 45.46 | 54.16 | 39.93 | 70.45 | 81.50 | 6.41 |
| MN | 47.50 | 55.49 | 40.98 | 72.30 | 83.30 | 5.92 |
| CorefNMN | 54.70 | 61.50 | 47.55 | 78.10 | 88.80 | 4.40 |
| GNN | 52.82 | 61.37 | 47.33 | 77.98 | 87.83 | 4.57 |
| FGA | 52.10 | 63.70 | 49.58 | 80.97 | 88.55 | 4.51 |
| DVAN | 54.70 | 62.58 | 48.90 | 79.35 | 89.03 | 4.36 |
| RVA | 55.59 | 63.03 | 49.03 | 80.40 | 89.83 | 4.18 |
| DualVD | 56.32 | 63.23 | 49.25 | 80.23 | 89.70 | 4.11 |
| HACAN | 57.17 | 64.22 | 50.88 | 80.63 | 89.45 | 4.20 |
| Synergistic | 57.32 | 62.20 | 47.90 | 80.43 | 89.95 | 4.17 |
| DAN | 57.59 | 63.20 | 49.63 | 79.75 | 89.35 | 4.30 |
| RAA-Net | 55.42 | 62.86 | 49.05 | 79.65 | 88.85 | 4.35 |
| HESNet | 57.13 | 63.21 | 49.70 | 80.63 | 89.65 | 4.19 |
| CAG | 56.64 | 63.49 | 49.85 | 80.63 | 90.15 | 4.11 |
| LTMI-LG | 58.55 | 64.00 | 50.63 | 80.58 | 90.20 | 4.12 |
| VD-BERT | 59.96 | 65.44 | 51.63 | 82.23 | 90.68 | 3.90 |
| MVAN | 59.37 | 64.84 | 51.45 | 81.82 | 90.65 | 3.97 |
| MGSCRN | 60.98 | 65.40 | 51.92 | 81.94 | 90.89 | 3.88 |
| Model | NDCG↑ | MRR↑ | R@1↑ | R@5↑ | R@10↑ | Mean↓ |
|---|---|---|---|---|---|---|
| Synergistic | 57.88 | 63.42 | 49.30 | 80.77 | 90.68 | 3.97 |
| DAN | 59.36 | 64.40 | 59.90 | 81.18 | 90.40 | 3.99 |
| CDF | 59.49 | 64.40 | 50.90 | 81.18 | 90.40 | 3.99 |
| MVAN | 60.92 | 66.38 | 53.20 | 82.45 | 91.85 | 3.68 |
| MGSCRN | 62.25 | 67.42 | 53.99 | 82.96 | 92.14 | 3.60 |
| Model | NDCG↑ | MRR↑ | R@1↑ | R@5↑ | R@10↑ | Mean↓ |
|---|---|---|---|---|---|---|
| LTMI | 60.92 | 60.65 | 47.00 | 77.03 | 87.75 | 4.90 |
| ReDAN | 61.86 | 53.13 | 41.38 | 66.07 | 74.50 | 8.91 |
| MVAN | 63.15 | 63.02 | 49.43 | 79.48 | 89.40 | 4.38 |
| MGSCRN | 64.13 | 63.87 | 50.28 | 80.26 | 90.02 | 4.11 |
| Model | NDCG↑ | MRR↑ | R@1↑ | R@5↑ | R@10↑ | Mean↓ |
|---|---|---|---|---|---|---|
| VisPro dataset | ||||||
| MCA-I-HGuidedQ | 61.35 | 60.13 | 47.11 | 75.26 | 86.18 | 5.23 |
| MCA-I-VGH | 61.68 | 59.33 | 46.18 | 75.35 | 86.17 | 5.07 |
| MCA-I-H | 61.72 | 59.62 | 45.92 | 77.11 | 86.45 | 4.85 |
| MGSCRN | 62.57 | 61.56 | 48.73 | 78.06 | 88.11 | 4.70 |
| VisDialConv dataset | ||||||
| MCA-I-HGuidedQ | 53.18 | 62.29 | 48.35 | 80.10 | 88.76 | 4.42 |
| MCA-I-VGH | 55.48 | 58.45 | 44.54 | 74.95 | 86.19 | 5.18 |
| MCA-I-H | 53.01 | 61.24 | 47.63 | 79.07 | 87.94 | 4.77 |
| MGSCRN | 57.13 | 61.87 | 48.84 | 80.44 | 88.98 | 4.22 |
| Model | NDCG↑ | MRR↑ | R@1↑ | R@5↑ | R@10↑ | Mean↓ |
|---|---|---|---|---|---|---|
| SgSR | 59.85 | 63.65 | 50.88 | 80.76 | 89.20 | 4.37 |
| TgSR | 60.49 | 64.22 | 51.59 | 81.46 | 90.01 | 4.19 |
| TgSR w/o OdA | 59.58 | 63.45 | 50.93 | 80.80 | 89.38 | 4.32 |
| SgSR+TgSR | 61.25 | 64.98 | 52.68 | 81.92 | 90.46 | 4.01 |
| MGSCRN | 62.28 | 66.44 | 53.42 | 82.80 | 91.21 | 3.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Wang, X.; Jiang, S.; Li, X. Multi-Granularity Semantic Collaborative Reasoning Network for Visual Dialog. Appl. Sci. 2022, 12, 8947. https://doi.org/10.3390/app12188947
Zhang H, Wang X, Jiang S, Li X. Multi-Granularity Semantic Collaborative Reasoning Network for Visual Dialog. Applied Sciences. 2022; 12(18):8947. https://doi.org/10.3390/app12188947
Chicago/Turabian StyleZhang, Hongwei, Xiaojie Wang, Si Jiang, and Xuefeng Li. 2022. "Multi-Granularity Semantic Collaborative Reasoning Network for Visual Dialog" Applied Sciences 12, no. 18: 8947. https://doi.org/10.3390/app12188947
APA StyleZhang, H., Wang, X., Jiang, S., & Li, X. (2022). Multi-Granularity Semantic Collaborative Reasoning Network for Visual Dialog. Applied Sciences, 12(18), 8947. https://doi.org/10.3390/app12188947