
SmartTips: Online Products Recommendations System Based on Analyzing Customers Reviews




Abstract
:1. Introduction
1.1. Research Objectives
1.2. Contributions
2. Background
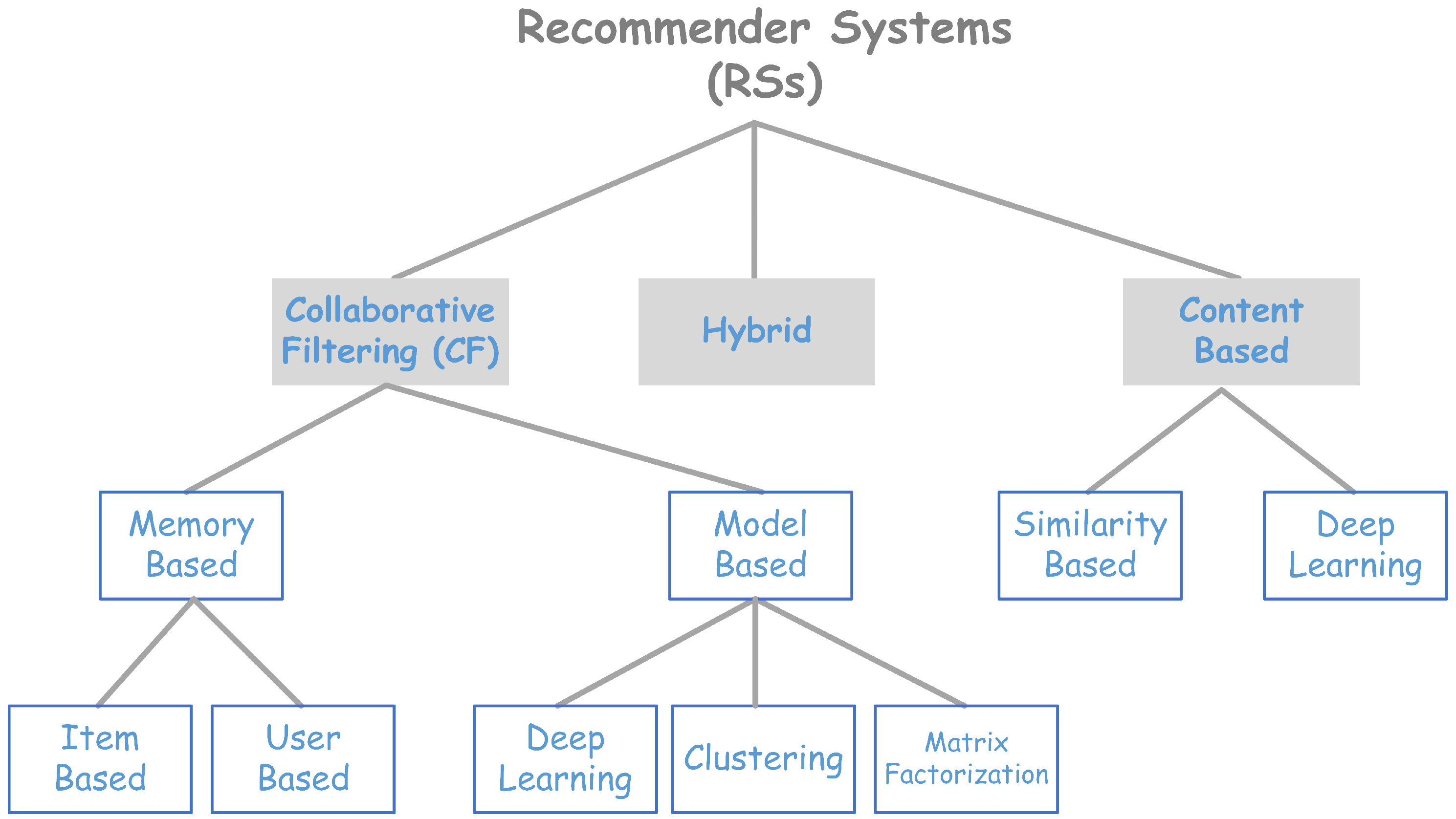
2.1. Basic Concepts of RSs
2.2. Methods for Creating RSs
2.2.1. Content-Based
2.2.2. Collaborative Filtering
2.2.3. Hybrid Models
2.3. Applications of RSs
- Online-contents Recommendations: Offering new content to enhance user engagement to the website. The goal is to introduce users to new content that may attract their interest and motivate them to consume more content; online content may include movies, books, news, etc.
- Stocks Recommendations: Present the most profitable stocks to customers. The novelty does not matter, where the list of recommendations may include early used promotions by the user; the importance relies on the return on equity.
- Products Recommendations: Recommend a combination of products, including previously consumed and new products. For the first class of products, the history of users’ transactions serves as a reminder of their frequent purchases. On the other hand, new products may be suggested according to similar users’ behavior.
- Conversational Recommender Systems (CRSs): It is a tool that tries to help the user determine which products he/she is going to buy by conversational mechanism. This agent can mimic a natural conversation between client and professional sales support to arouse customer preference.
3. Related Works
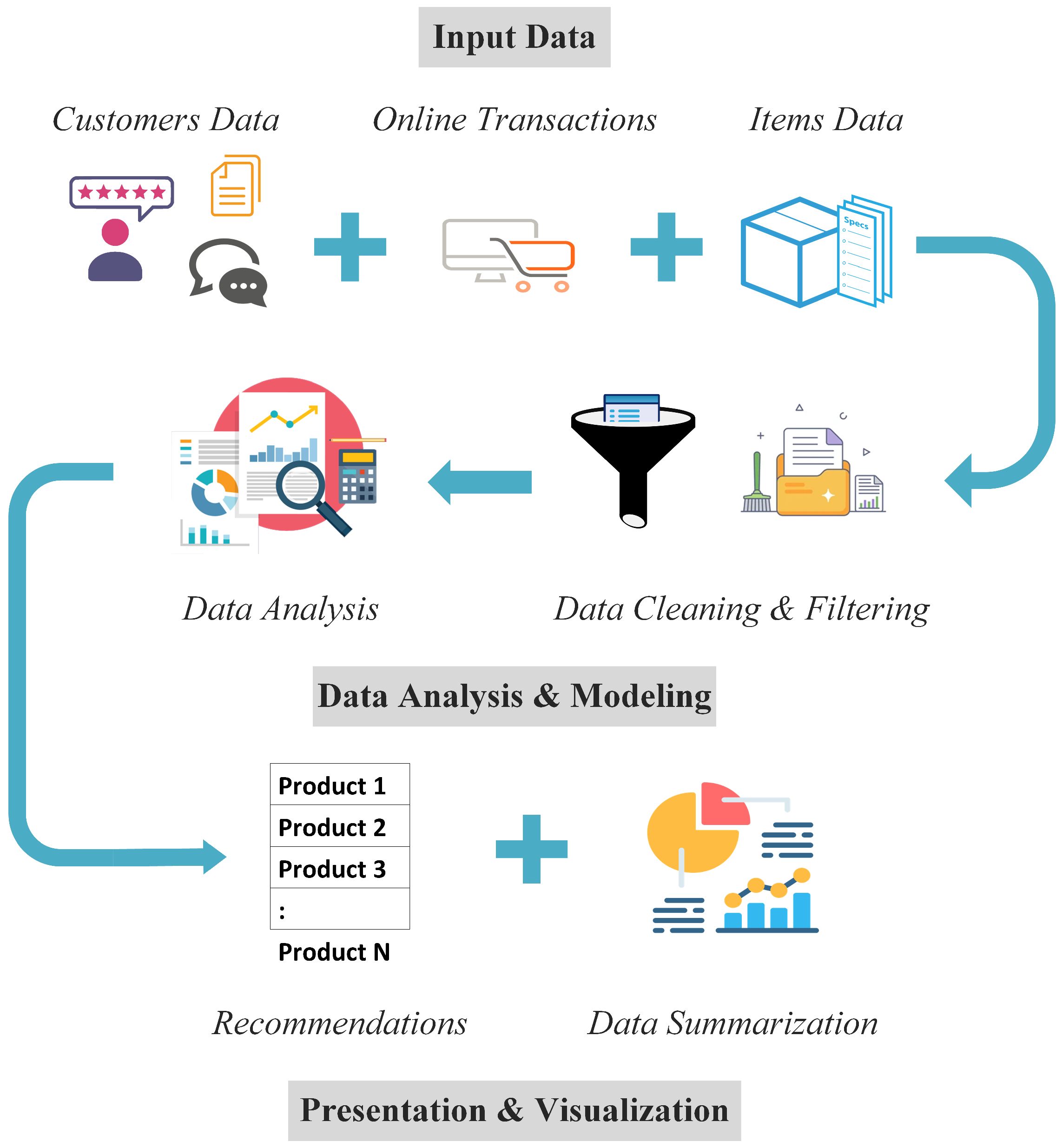
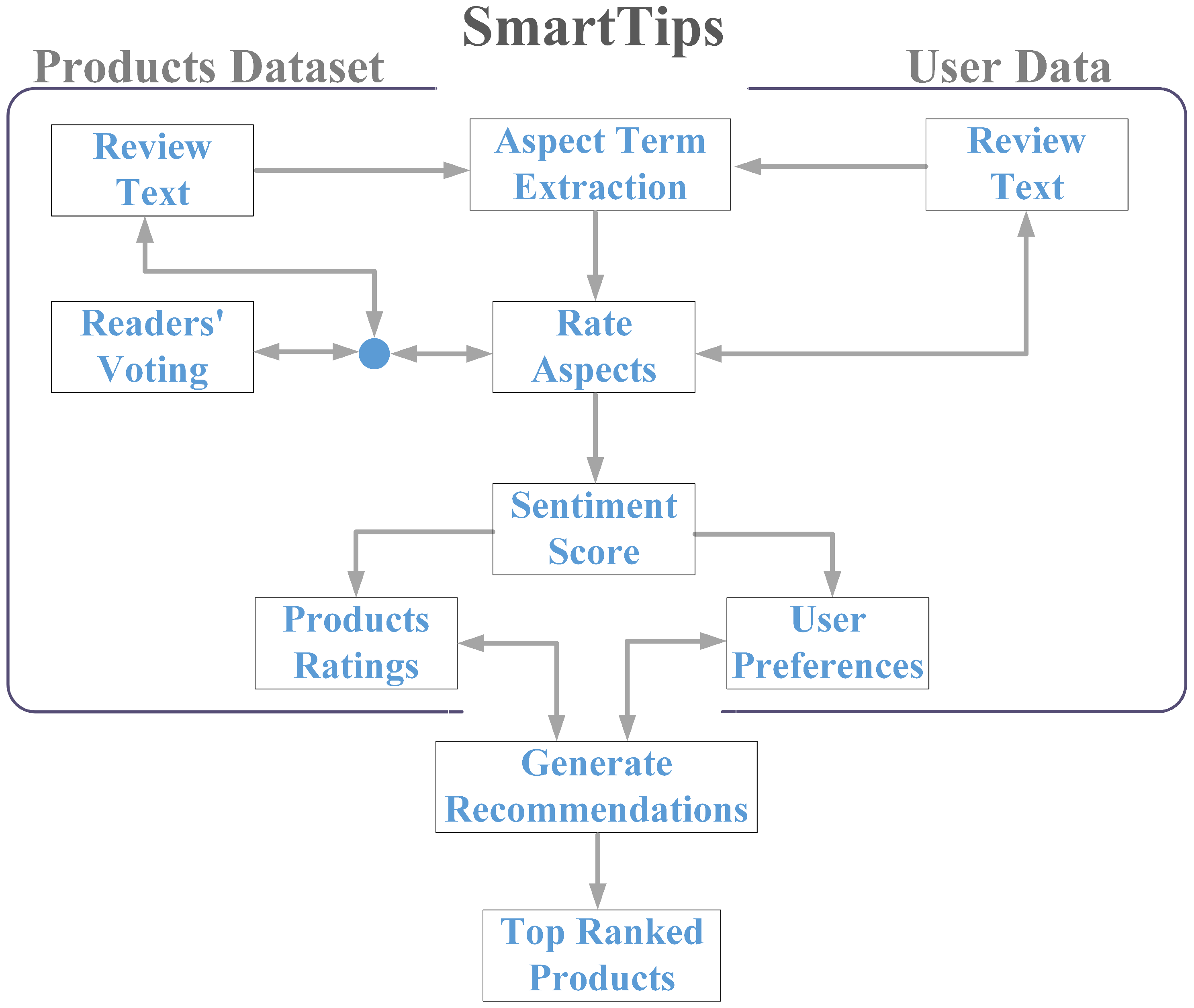
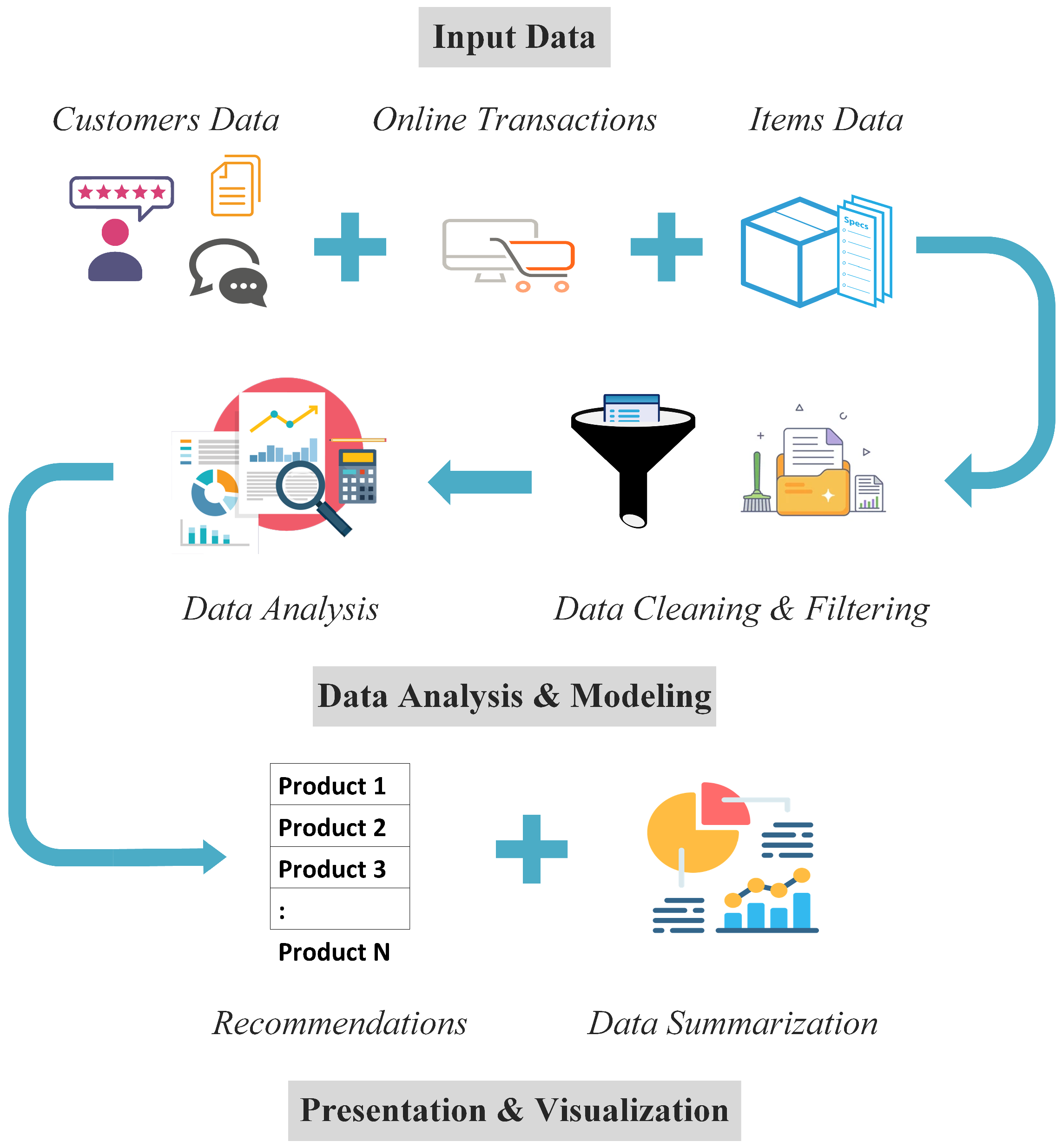
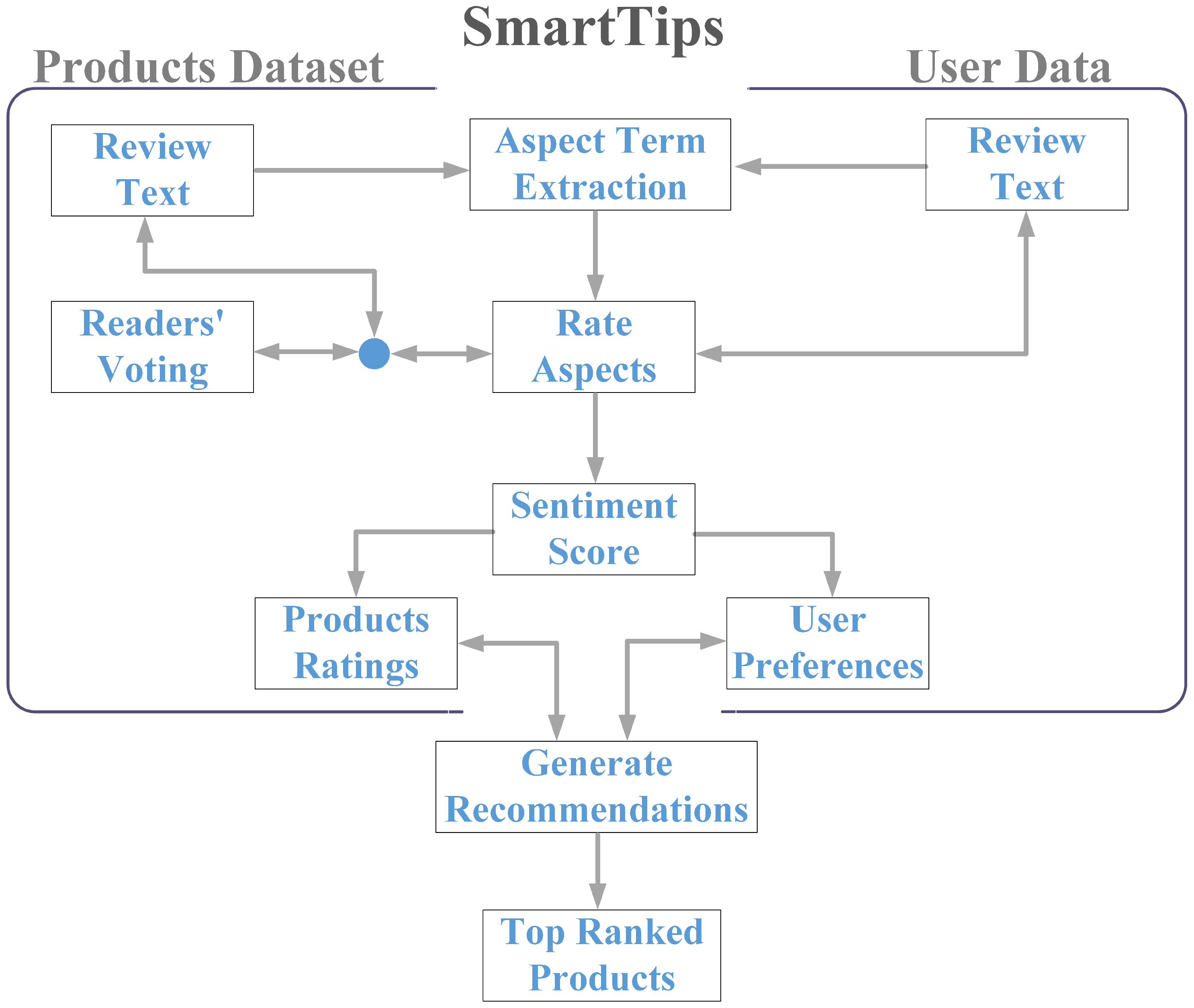
4. The Proposed System for Product Recommendations
4.1. Rating Products
| Algorithm 1 Computing the sentiment score |
Input: (LIST: Review_Data) (LIST: Aspect_Terms) Output: (LIST: Aspect_Ratings) Initialization: 1: Create ← (LIST : Aspect_Ratings) 2: for each review ∈ Review_Data do 3: Extract ← review ⇒ {v+,v−} 4: Extract ← review ⇒ “review_text” 5: for each token ∈ review_text do 6: if token ∈ Aspect_Terms then 7: if token ∉ Aspect_Ratings then 8: Append ← token ⇒ “Aspect_Ratings” 9: end if 10: Extract ← review_text : token ⇒ “sentiment_words” 11: Count ← sentiment_words ⇒ “csw” 12: Add ← csw ⇒ Aspect_Ratings[“token”][“sw_count”] 13: Detect ← sentiment_words ⇒ “polarity” 14: if (polarity == positive) then 15: psc = csw + v+ − v− 16: Add ← psc ⇒ Aspect_Ratings[“token”][“pscore”] 17: else if (polarity == negative) then 18: nsc = csw + v+ − v− 19: Add ← nsc ⇒ Aspect_Ratings[“token”][“nscore”] 20: end if 21: end if 22: end for 23: end for 24: for each aspect ∈ Aspect_Ratings do 25: ssc = (aspect[“pscore”] − aspect[“nscore”])/aspect[“sw_count”] 26: Add ← ssc ⇒ Aspect_Ratings[“aspect”][“sscore”] 27: end for 28: return Aspect_Ratings |
4.2. Extracting Preferences
4.3. Generating Recommendations
5. Experiments and Results
5.1. Datasets
5.2. Testing and Evaluation Metrics
5.2.1. Evaluation Metrics
5.2.2. Baseline Methods
- Matrix Factorization (MF) [41]: Represents one of the most common collaborative filtering recommender systems, classified as a model-based approach. Typically, matrix factorization uses a rating matrix that characterizes both items and users as input for rating prediction by estimating two low-ranked matrices.
- SVD++ [42]: This is one of the Latent factor-based models; SVD++ is an extension of the original Singular Value Decomposition model (SVD) that exploits the existence of both implicit and explicit feedback in order to improve the collaborative filtering-based recommendations performance.
- ALFM-P [9]: Aspect-based Latent Factor Model (ALFM) employs the item–property matrix made of word frequency to integrate ratings and review texts via the latent factor model.
- REAO [35]: Recommender system Exploiting Opinion mining (REAO) which consists of two major parts. The first is aspect-based opinion mining (ABOM) that employs a deep CNN model for aspect extraction with the help of the LDA technique to transform the extracted aspect terms into latent factors. The second is rating prediction, which computes the aspect-based ratings, forming a set of rating matrices that match a particular aspect.
5.2.3. Result Analysis and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ali, N.M. Aspect-Oriented Analytics of Big Data. In Proceedings of the 14th International Baltic Conference on Databases and Information Systems (Baltic DB&IS 2020); Matulevičius, R., Robal, T., Haav, H.M., Maigre, R., Petlenkov, E., Eds.; CEUR Workshop Proceedings: Tallinn, Estonia, 2020; Volume 2620, pp. 41–48. [Google Scholar]
- Sulikowski, P.; Zdziebko, T.; Turzyński, D. Modeling Online User Product Interest for Recommender Systems and Ergonomics Studies. Concurr. Comput. Pract. Exp. 2019, 31, e4301. [Google Scholar] [CrossRef]
- McAuley, J.; Leskovec, J. Hidden Factors and Hidden Topics: Understanding Rating Dimensions with Review Text. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 165–172. [Google Scholar] [CrossRef]
- Ali, N.M.; Novikov, B. A Multi-Source Big Data Framework for Capturing and Analyzing Customer Feedback. In Proceedings of the 2021 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (ElConRus), Moscow and St. Petersburg, Russia, 26–29 January 2021; pp. 185–190. [Google Scholar] [CrossRef]
- Hazrati, N.; Ricci, F. Recommender Systems Effect on the Evolution of Users’ Choices Distribution. Inf. Process. Manag. 2022, 59, 102766. [Google Scholar] [CrossRef]
- Ali, N.M.; Gadallah, A.M.; Hefny, H.A.; Novikov, B. An Integrated Framework for Web Data Preprocessing Towards Modeling User Behavior. In Proceedings of the 2020 International Multi-Conference on Industrial Engineering and Modern Technologies (FarEastCon), Vladivostok, Russia, 6–9 October 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Al-Yazeed, N.M.A.; Gadallah, A.M.; Hefny, H.A. A Hybrid Recommendation Model for Web Navigation. In Proceedings of the Seventh IEEE International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 12–14 December 2015; pp. 552–560. [Google Scholar] [CrossRef]
- Ali, N.M.; Gadallah, A.M.; Hefny, H.A.; Novikov, B.A. Online Web Navigation Assistant. Vestn. Udmurtsk. Univ. Mat. Mekh. Komp. Nauki 2021, 31, 116–131. [Google Scholar] [CrossRef]
- Qiu, L.; Gao, S.; Cheng, W.; Guo, J. Aspect-based Latent Factor Model by Integrating Ratings and Reviews for Recommender System. Knowl.-Based Syst. 2016, 110, 233–243. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, D. A Survey of Recommender Systems with Multi-Objective Optimization. Neurocomputing 2022, 474, 141–153. [Google Scholar] [CrossRef]
- Bag, S.; Kumar, S.K.; Tiwari, M.K. An Efficient Recommendation Generation using Relevant Jaccard Similarity. Inf. Sci. 2019, 483, 53–64. [Google Scholar] [CrossRef]
- Jain, G.; Mahara, T. An Efficient Similarity Measure to Alleviate the Cold-Start Problem. In Proceedings of the 2019 Fifteenth International Conference on Information Processing (ICINPRO), Bengaluru, India, 20–22 December 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Jain, G.; Mahara, T.; Tripathi, K.N. A Survey of Similarity Measures for Collaborative Filtering-Based Recommender System. In Soft Computing: Theories and Applications; Pant, M., Sharma, T.K., Verma, O.P., Singla, R., Sikander, A., Eds.; Springer: Singapore, 2020; Volume 1053, pp. 343–352. [Google Scholar] [CrossRef]
- Manochandar, S.; Punniyamoorthy, M. A New User Similarity Measure in A New Prediction Model for Collaborative Filtering. Appl. Intell. 2021, 51, 586–615. [Google Scholar] [CrossRef]
- Tan, Z.; He, L. An Efficient Similarity Measure for User-Based Collaborative Filtering Recommender Systems Inspired by the Physical Resonance Principle. IEEE Access 2017, 5, 27211–27228. [Google Scholar] [CrossRef]
- Wang, D.; Liang, Y.; Xu, D.; Feng, X.; Guan, R. A Content-based Recommender System for Computer Science Publications. Knowl.-Based Syst. 2018, 157, 1–9. [Google Scholar] [CrossRef]
- Okura, S.; Tagami, Y.; Ono, S.; Tajima, A. Embedding-based News Recommendation for Millions of Users. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1933–1942. [Google Scholar] [CrossRef]
- Chen, R.; Hua, Q.; Chang, Y.S.; Wang, B.; Zhang, L.; Kong, X. A Survey of Collaborative Filtering-Based Recommender Systems: From Traditional Methods to Hybrid Methods Based on Social Networks. IEEE Access 2018, 6, 64301–64320. [Google Scholar] [CrossRef]
- Ullah, F.; Zhang, B.; Khan, R.U.; Chung, T.S.; Attique, M.; Khan, K.; Khediri, S.E.; Jan, S. Deep Edu: A Deep Neural Collaborative Filtering for Educational Services Recommendation. IEEE Access 2020, 8, 110915–110928. [Google Scholar] [CrossRef]
- Xu, G.; Tang, Z.; Ma, C.; Liu, Y.; Daneshmand, M. A Collaborative Filtering Recommendation Algorithm Based on User Confidence and Time Context. J. Electr. Comput. Eng. 2019, 2019, 7070487. [Google Scholar] [CrossRef]
- Agarwal, A.; Mishra, D.S.; Kolekar, S.V. Knowledge-based Recommendation System Using Semantic Web Rules Based on Learning styles for MOOCs. Cogent Eng. 2022, 9, 2022568. [Google Scholar] [CrossRef]
- Khan, Z.A.; Raja, M.A.Z.; Chaudhary, N.I.; Mehmood, K.; He, Y. MISGD: Moving-Information-Based Stochastic Gradient Descent Paradigm for Personalized Fuzzy Recommender Systems. Int. J. Fuzzy Syst. 2022, 24, 686–712. [Google Scholar] [CrossRef]
- Khan, Z.A.; Zubair, S.; Chaudhary, N.I.; Raja, M.A.Z.; Khan, F.A.; Dedovic, N. Design of Normalized Fractional SGD Computing Paradigm for Recommender Systems. Neural Comput. Appl. 2020, 32, 10245–10262. [Google Scholar] [CrossRef]
- Jain, G.; Mishra, N.; Sharma, S. CRLRM: Category Based Recommendation Using Linear Regression Model. In Proceedings of the 2013 Third International Conference on Advances in Computing and Communications, Cochin, India, 29–31 August 2013; pp. 17–20. [Google Scholar] [CrossRef]
- Burke, R. Hybrid Recommender Systems: Survey and Experiments. User Model. User-Adapted Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Mu, R. A Survey of Recommender Systems Based on Deep Learning. IEEE Access 2018, 6, 69009–69022. [Google Scholar] [CrossRef]
- Sarker, I.H. Deep Learning: A Comprehensive Overview on Techniques, Taxonomy, Applications and Research Directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar] [CrossRef]
- Zhang, L.; Luo, T.; Zhang, F.; Wu, Y. A Recommendation Model Based on Deep Neural Network. IEEE Access 2018, 6, 9454–9463. [Google Scholar] [CrossRef]
- Batmaz, Z.; Yurekli, A.; Bilge, A.; Kaleli, C. A Review on Deep Learning for Recommender Systems: Challenges and Remedies. Artif. Intell. Rev. 2019, 52, 1–37. [Google Scholar] [CrossRef]
- Chavare, S.R.; Awati, C.J.; Shirgave, S.K. Smart Recommender System using Deep Learning. In Proceedings of the 2021 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 20–22 January 2021; pp. 590–594. [Google Scholar] [CrossRef]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & Deep Learning for Recommender Systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar] [CrossRef] [Green Version]
- Covington, P.; Adams, J.; Sargin, E. Deep Neural Networks for YouTube Recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 191–198. [Google Scholar] [CrossRef]
- Ni, J.; Li, J.; McAuley, J. Justifying Recommendations using Distantly-Labeled Reviews and Fine-Grained Aspects. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP) and the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; ACL: Stroudsburg, PA, USA, 2019; pp. 188–197. [Google Scholar] [CrossRef]
- Baizal, Z.K.A.; Widyantoro, D.H.; Maulidevi, N.U. Computational Model for Generating Interactions in Conversational Recommender System Based on Product Functional Requirements. Data Knowl. Eng. 2020, 128, 101813. [Google Scholar] [CrossRef]
- Da’u, A.; Salim, N.; Rabiu, I.; Osman, A. Recommendation System Exploiting Aspect-based Opinion Mining with Deep Learning Method. Inf. Sci. 2020, 512, 1279–1292. [Google Scholar] [CrossRef]
- Da’u, A.; Salim, N.; Rabiu, I.; Osman, A. Weighted Aspect-based Opinion Mining Using Deep Learning for Recommender System. Expert Syst. Appl. 2020, 140, 112871. [Google Scholar] [CrossRef]
- Ghasemi, N.; Momtazi, S. Neural Text Similarity of User Reviews for Improving Collaborative Filtering Recommender Systems. Electron. Commer. Res. Appl. 2021, 45, 101019. [Google Scholar] [CrossRef]
- Asani, E.; Vahdat-Nejad, H.; Sadri, J. Restaurant Recommender System Based on Sentiment Analysis. Mach. Learn. Appl. 2021, 6, 100114. [Google Scholar] [CrossRef]
- Ray, B.; Garain, A.; Sarkar, R. An Ensemble-based Hotel Recommender System Using Sentiment Analysis and Aspect Categorization of Hotel Reviews. Appl. Soft Comput. 2021, 98, 106935. [Google Scholar] [CrossRef]
- Ali, N.M.; Alshahrani, A.; Alghamdi, A.M.; Novikov, B. Extracting Prominent Aspects of Online Customer Reviews: A Data-Driven Approach to Big Data Analytics. Electronics 2022, 11, 2042. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Koren, Y. Factorization Meets the Neighborhood: A Multifaceted Collaborative Filtering Model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Dataset | #Users | #Items | #Reviews |
|---|---|---|---|
| Automotive | 133,254 | 47,539 | 188,387 |
| Cell Phone and Accessories | 68,039 | 7335 | 76,653 |
| Electronics | 811,032 | 80,613 | 1,189,549 |
| Movies and TV | 1,224,266 | 207,532 | 6,797,757 |
| Video Games | 228,516 | 20,335 | 364,484 |
| Dataset | MF | SVD++ | ALFM-P | REAO | SmartTips |
|---|---|---|---|---|---|
| Automotive | 1.715 | 1.439 | 0.565 | 0.663 | 0.473 |
| Cell Phone and Accessories | 2.323 | 2.112 | 0.364 | - | 0.330 |
| Electronics | 1.968 | 1.661 | 0.396 | - | 0.313 |
| Movies and TV | 0.627 | 0.544 | 0.412 | - | 0.393 |
| Video Games | 1.837 | 1.495 | 0.505 | 1.055 | 0.515 |
| Average | 1.694 | 1.450 | 0.448 | 0.859 | 0.405 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, N.M.; Alshahrani, A.; Alghamdi, A.M.; Novikov, B. SmartTips: Online Products Recommendations System Based on Analyzing Customers Reviews. Appl. Sci. 2022, 12, 8823. https://doi.org/10.3390/app12178823
Ali NM, Alshahrani A, Alghamdi AM, Novikov B. SmartTips: Online Products Recommendations System Based on Analyzing Customers Reviews. Applied Sciences. 2022; 12(17):8823. https://doi.org/10.3390/app12178823
Chicago/Turabian StyleAli, Noaman M., Abdullah Alshahrani, Ahmed M. Alghamdi, and Boris Novikov. 2022. "SmartTips: Online Products Recommendations System Based on Analyzing Customers Reviews" Applied Sciences 12, no. 17: 8823. https://doi.org/10.3390/app12178823
APA StyleAli, N. M., Alshahrani, A., Alghamdi, A. M., & Novikov, B. (2022). SmartTips: Online Products Recommendations System Based on Analyzing Customers Reviews. Applied Sciences, 12(17), 8823. https://doi.org/10.3390/app12178823