
Lazy Aggregation for Heterogeneous Federated Learning


Abstract
:1. Introduction
2. Related Work
2.1. Adaptive Optimization
2.2. Model Personalization
2.3. Data-Based Optimization
3. Methods
3.1. Problem
3.2. FedLA
| Algorithm 1: Federated Lazy Aggregate (FedLA) | ||
| Input: | ||
| Initialize | ||
| for t = 0, 1, 2, …, T − 1 do | ||
| Sample devices | ||
| Transmit to selected devices, respectively | ||
| for each device k in parallel do | ||
| Transmit device to server | ||
| end for | ||
| for k = 0, 1, 2, …, T − 1 do | ||
| end for | ||
| if do | ||
| else | ||
| end if | ||
| end for | ||
| Output: | ||
3.3. FedLAM
| Algorithm 2: Federated Lazy Aggregate with Momentum (FedLAM) | ||
| Input: | ||
| Initialize | ||
| for t = 0, 1, 2, …, T − 1 do | ||
| Sample devices | ||
| Transmit to selected devices, respectively | ||
| for each device in parallel do | ||
| Transmit device to server | ||
| end for | ||
| for k = 0, 1, 2, …, T − 1 do | ||
| end for | ||
| if do | ||
| (*) | ||
| else | ||
| end if | ||
| end for | ||
| Output: | ||
4. Evaluation
4.1. Experiment Setup
4.1.1. Datasets and Models
- Mnist, a widely used image classification task, contains a training dataset of 60,000 handwritten digit pictures and a test dataset of 10,000. Its elements are 28 × 28 pixel black and white pictures with 10 classification labels. Since the dataset is relatively simple and pure, and complex models (e.g., CNN, RNN) are little discriminated, for comparison, only single-layer MLP is used in this section.
- Emnist (Extend Mnist) expands 402,000 numbers and 411,000 26 letters samples on the basis of Mnist. Due to the huge amount of dataset, six types of splits (e.g., by class, by merge, letters etc.) are introduced. To distinguish from Mnist, the letters split is used, and a two-layer simple CNN is used for the test model.
- Cifar10 contains 60,000 32 × 32 pixel color images in 10 categories, and its classes are completely mutually exclusive (e.g., car and airplane), while the samples of the same category are quite different (e.g., car and truck). The difficulty of classification tasks has undoubtedly increased significantly, so we choose a three-layer convolutional layer and a two-layer fully connected layer CNN.
4.1.2. Data Partitions
- IID: The dataset is randomly shuffled and divided into several subsets of the same size.
- Label distribution skew: Zhao et al. [5] proposed a more demanding non-IID setting, the outstanding feature of which is that each subset only holds a few classes of samples.
- Dirichlet: Wang et al. [29] proposed a partition scheme based on the Dirichlet distribution, where each subset is also class-imbalanced with different amounts of samples. It is closer to a partition scheme than the real FL environments.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Samples | Classes | Devices | Partitions | Models | |
|---|---|---|---|---|---|---|
| MNIST | 69,035 | 10 | 100 | IID Class 1/3 Dir-0.1/0.3 | MLP | 101,770 |
| CIFAR10 | 60,000 | CNN | 553,514 | |||
| EMNIST (letters) | 145,600 | 26 | Class 3/9 | SimpleCNN | 28,938 | |
4.1.3. Baselines
- FedAvg: The vanilla FL Algorithm [3].
- FedProx: A popular FL adaptive optimization scheme that limits excessive offset of the device-side model by adding a proximal term [7].
- FedDyn: A dynamic regularization method for FL, and local objectives are dynamically updated to ensure that local optimums are asymptotically consistent with the global optimum [10].
- CFL: A clustering federated learning framework based on recursive bi-partition that uses cosine similarity to separate the devices with gradient conflicts and form their respective cluster center models [14].
4.1.4. Evaluation Metric
4.2. Effects of the Proposed Algorithm
4.2.1. Performance
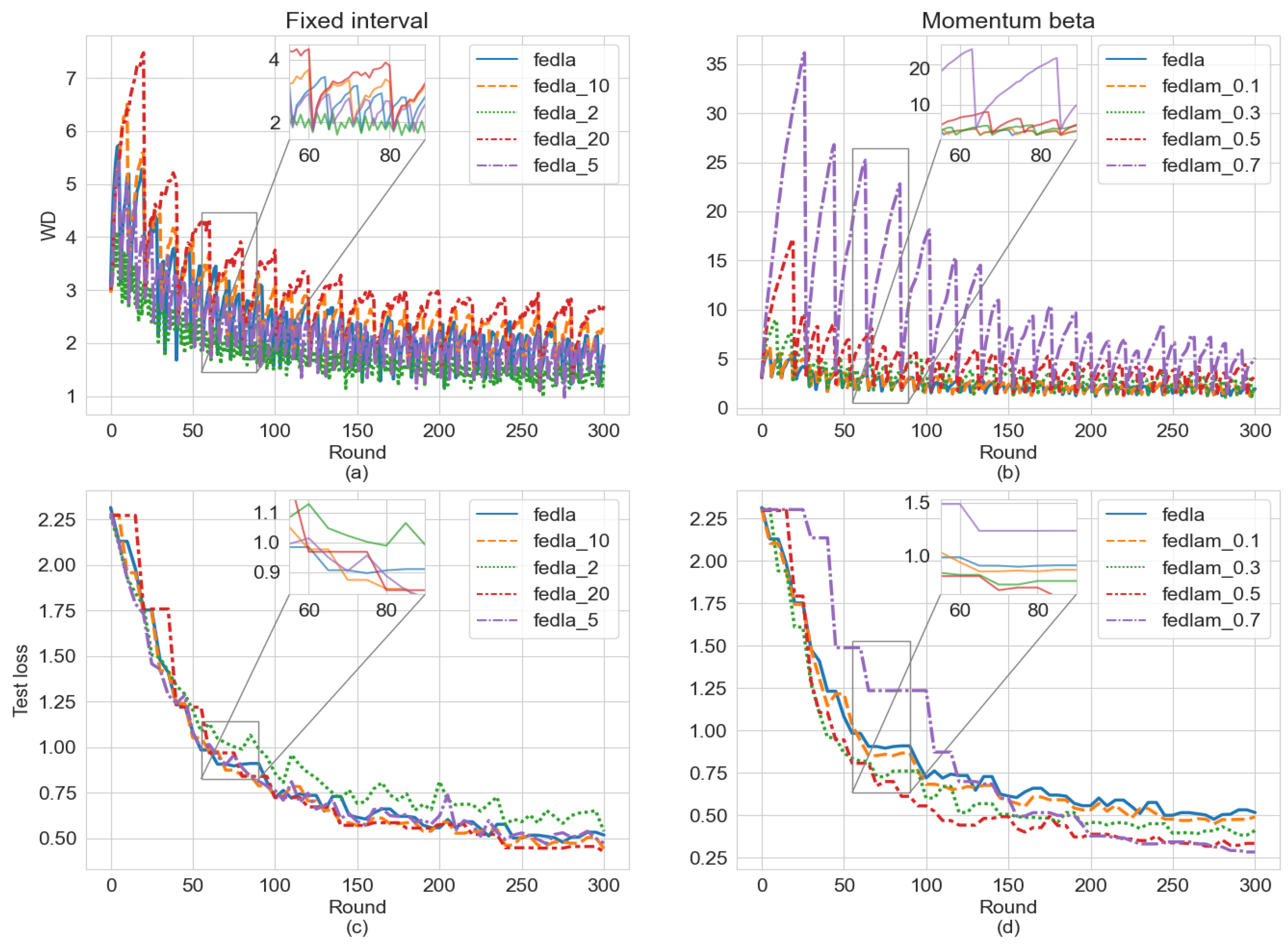
4.2.2. WDR and Cross-Device Momentum
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Processing Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Zhu, H.; Xu, J.; Liu, S.; Jin, Y. Federated learning on non-IID data: A survey. Neurocomputing 2021, 465, 371–390. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the Convergence of FedAvg on Non-IID Data. In Proceedings of the 8th International Conference on Learning Representations, Virtual, 26–30 April 2020. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Zeng, S.; Li, Z.; Yu, H.; He, Y.; Xu, Z.; Niyato, D.; Yu, H. Heterogeneous federated learning via grouped sequential-to-parallel training. In International Conference on Database Systems for Advanced Applications; Springer: Berlin/Heidelberg, Germany, 2022; pp. 455–471. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Shamir, O.; Srebro, N.; Zhang, T. Communication-efficient distributed optimization using an approximate newton-type method. In Proceedings of the 31th International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.J.; Stich, S.U.; Suresh, A.T. SCAFFOLD: Stochastic Controlled Averaging for Federated Learning. In Proceedings of the 37th on International Conference on Machine Learning, Virtual, 12–18 July 2020. [Google Scholar]
- Acar, D.A.E.; Zhao, Y.; Navarro, R.M.; Mattina, M.; Whatmough, P.N.; Saligrama, V. Federated learning based on dynamic regularization. In Proceedings of the 9th International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptationof deep networks. In Proceedings of the 34th on International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017. [Google Scholar]
- Fallah, A.; Mokhtari, A.; Ozdaglar, A. Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach. Adv. Neural Inf. Processing Syst. 2020, 33, 3557–3568. [Google Scholar]
- Arivazhagan, M.G.; Aggarwal, V.; Singh, A.K.; Choudhary, S. Federated learning with personalization layers. arXiv 2019, arXiv:1912.00818. [Google Scholar]
- Sattler, F.; Müller, K.-R.; Samek, W. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraint. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3710–3722. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, A.; Chung, J.; Yin, D.; Ramchandran, K. An efficient framework for clustered federated learning. Adv. Neural Inf. Processing Syst. 2020, 33, 19586–19597. [Google Scholar] [CrossRef]
- Long, G.; Xie, M.; Shen, T.; Zhou, T.; Wang, X.; Jiang, J. Multi-center federated learning: Clients clustering for better personalization. World Wide Web 2022, 6, 1–20. [Google Scholar]
- Duan, M.; Liu, D.; Ji, X.; Liu, R.; Liang, L.; Chen, X.; Tan, Y. FedGroup: Efficient clustered federated learning via decomposed data-driven measure. arXiv 2020, arXiv:2010.06870. [Google Scholar]
- Li, C.; Li, G.; Varshney, P.K. Federated Learning with Soft Clustering. IEEE Internet Things. 2021, 9, 7773–7782. [Google Scholar]
- Yao, X.; Huang, T.; Zhang, R.-X.; Li, R.; Sun, L. Federated learning with unbiased gradient aggregation and controllable meta updating. arXiv 2019, arXiv:1910.08234. [Google Scholar]
- Tuor, T.; Wang, S.; Ko, B.J.; Liu, C.; Leung, K.K. Overcoming noisy and irrelevant data in federated learning. In Proceedings of the 25th International Conference on Pattern Recognition, Virtual, 10–15 January 2021. [Google Scholar]
- Tanner, M.A.; Wong, W.H. The calculation of posterior distributions by data augmentation. J. Am. Stat. Assoc. 1987, 82, 528–540. [Google Scholar] [CrossRef]
- Duan, M.; Liu, D.; Chen, X.; Tan, Y.; Ren, J.; Qiao, L.; Liang, L. Astraea: Self-balancing federated learning for improving classification accuracy of mobile deep learning applications. In Proceedings of the 2019 IEEE 37th International Conference on Computer Design, Abu Dhabi, United Arab Emirates, 17–20 November 2019. [Google Scholar]
- Buciluǎ, C.; Caruana, R.; Niculescu-Mizil, A. Model compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006. [Google Scholar]
- Lin, T.; Kong, L.; Stich, S.U.; Jaggi, M. Ensemble distillation for robust model fusion in federated learning. Adv. Neural Inf. Processing Syst. 2020, 33, 2351–2363. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Khaled, A.; Mishchenko, K.; Richtárik, P. Tighter theory for local SGD on identical and heterogeneous data. In Proceedings of the 23rd International Conference on Artificial Intelligence and Statistic, Parerlmo, Sicily, Italy, 26–28 August 2020. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Liu, W.; Chen, L.; Chen, Y.; Zhang, W. Accelerating federated learning via momentum gradient descent. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1754–1766. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated learning with matched averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Yann, L.; Corest, C.; Burges, C.J.C. The MNIST Database of Handwritten Digits. Available online: http://yann.lecun.com/exdb/mnist (accessed on 10 October 2021).
- Cohen, G.; Afshar, S.; Tapson, J.; Van Schaik, A. EMNIST: Extending MNIST to handwritten letters. In Proceedings of the 2017 International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017. [Google Scholar]
- Doon, R.; Rawat, T.K.; Gautam, S. Cifar-10 classification using deep convolutional neural network. In Proceedings of the 2018 IEEE Punecon, Pune, India, 30 November–2 December 2018. [Google Scholar]
- Wang, Z.; Fan, X.; Qi, J.; Wen, C.; Wang, C.; Yu, R. Federated learning with fair averaging. arXiv 2021, arXiv:2104.14937. [Google Scholar]


| FedAvg | FedProx | FedDyn | FedLA | FedLAM | CFL | ||
|---|---|---|---|---|---|---|---|
| Mnist | IID | 91.5 | 91.5 | 93.7 | 91.4 | 95.3 | 91.6 |
| Class 1 | 83.3 | 83.2 | 85.8 | 87.6 | 90.6 | 70.8 | |
| Class 3 | 90.0 | 90.0 | 88.9 | 89.8 | 92.4 | 90.0 | |
| Dir 0.1 | 90.0 | 90.0 | 88.7 | 88.8 | 91.5 | 88.8 | |
| Dir 0.3 | 89.8 | 89.8 | 89.1 | 90.3 | 90.4 | 89.8 | |
| Emnist | IID | 89.4 | 89.7 | 91.4 | 89.9 | 89.4 | 89.9 |
| Class 3 | 79.1 | 79.6 | 84.9 | 79.3 | 85.3 | 79.2 | |
| Class 9 | 87.6 | 87.4 | 90.0 | 85.7 | 89.1 | 87.6 | |
| Dir 0.1 | 84.3 | 84.9 | 88.5 | 84.2 | 87.8 | 85.1 | |
| Dir 0.3 | 89.1 | 89.3 | 90.7 | 89.1 | 89.7 | 89.1 | |
| Cifar10 | IID | 70.8 | 69.6 | 71.5 | 70.4 | 76.3 | 70.9 |
| Class 1 | 27.0 | 27.0 | 41.8 | 17.1 | |||
| Class 3 | 65.3 | 66.2 | 64.1 | 67.3 | 71.1 | 66.0 | |
| Dir 0.1 | 62.5 | 62.1 | 59.3 | 60.4 | 64.6 | 62.7 | |
| Dir 0.3 | 66.0 | 66.1 | 65.6 | 68.1 | 71.5 | 66.5 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, G.; Kong, D.-L.; Chen, X.-B.; Liu, X. Lazy Aggregation for Heterogeneous Federated Learning. Appl. Sci. 2022, 12, 8515. https://doi.org/10.3390/app12178515
Xu G, Kong D-L, Chen X-B, Liu X. Lazy Aggregation for Heterogeneous Federated Learning. Applied Sciences. 2022; 12(17):8515. https://doi.org/10.3390/app12178515
Chicago/Turabian StyleXu, Gang, De-Lun Kong, Xiu-Bo Chen, and Xin Liu. 2022. "Lazy Aggregation for Heterogeneous Federated Learning" Applied Sciences 12, no. 17: 8515. https://doi.org/10.3390/app12178515
APA StyleXu, G., Kong, D.-L., Chen, X.-B., & Liu, X. (2022). Lazy Aggregation for Heterogeneous Federated Learning. Applied Sciences, 12(17), 8515. https://doi.org/10.3390/app12178515