
Feature Extraction with Handcrafted Methods and Convolutional Neural Networks for Facial Emotion Recognition





Abstract
:1. Introduction
2. Related Work
2.1. Handcrafted Feature Extraction Methods
2.2. Handcrafted vs. CNN-Based for Image Classification
2.3. Handcrafted vs. CNN-Based in FER Applications
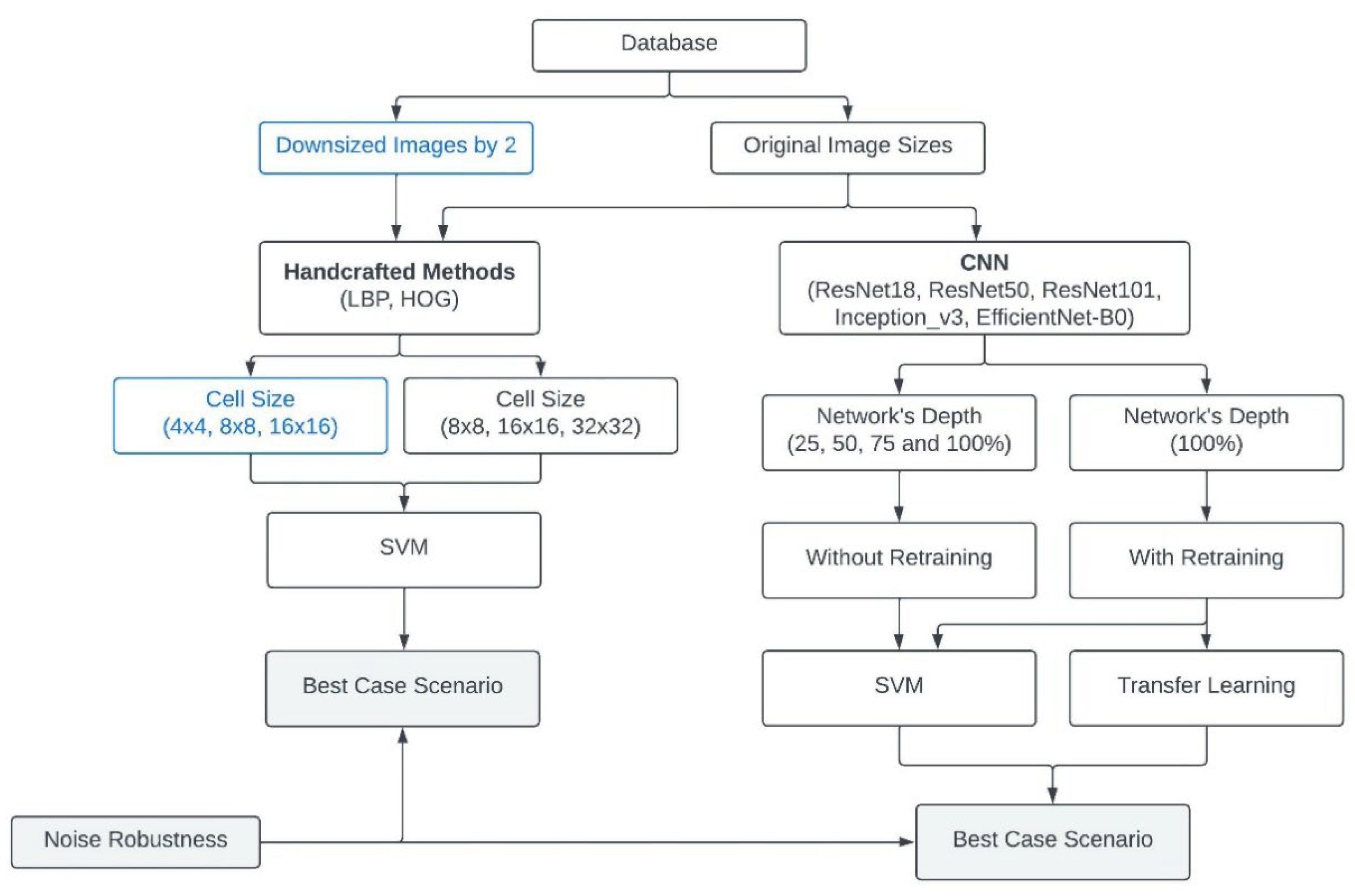
3. Materials and Methods
3.1. Databases Selection and Description
- KDEF consists of 4900 images divided equally into seven facial emotions viewed from five shooting angles. The participants are males and females in equal parts, between the ages of 20 and 30, who do not wear glasses and jewelry and do not have a beard or mustache. The images are 567 × 762 pixels with 24-bit color values in jpeg format [31];
- JAFFE consists of 213 frontal faces of 10 females expressing seven different emotions. The images are 256 × 256 pixels 8-bit grayscale in tiff format [32]. This database was employed to examine how the algorithms perform in small sets and low-resolution images;
- RaFD consists of 8040 images divided equally into eight facial emotions viewed from five shooting angles. The individuals are Caucasian adults, both men (30%) and women (28%), Caucasian children, both boys (6%) and girls (9%), and Moroccan Dutch males (27%). The images are 681 × 1024 pixels with 24-bit color values in jpeg format [33].
3.2. Feature Extraction
3.2.1. Handcrafted Feature Extraction Methods
- (A)
- Local Binary Patterns
- (B)
- Histogram of Oriented Gradients
3.2.2. CNN-Based Features
- ResNets
- Inception_v3
- EfficientNet
3.3. Model Classifier
4. Scenarios
4.1. Extract Features with Handcrafted Methods
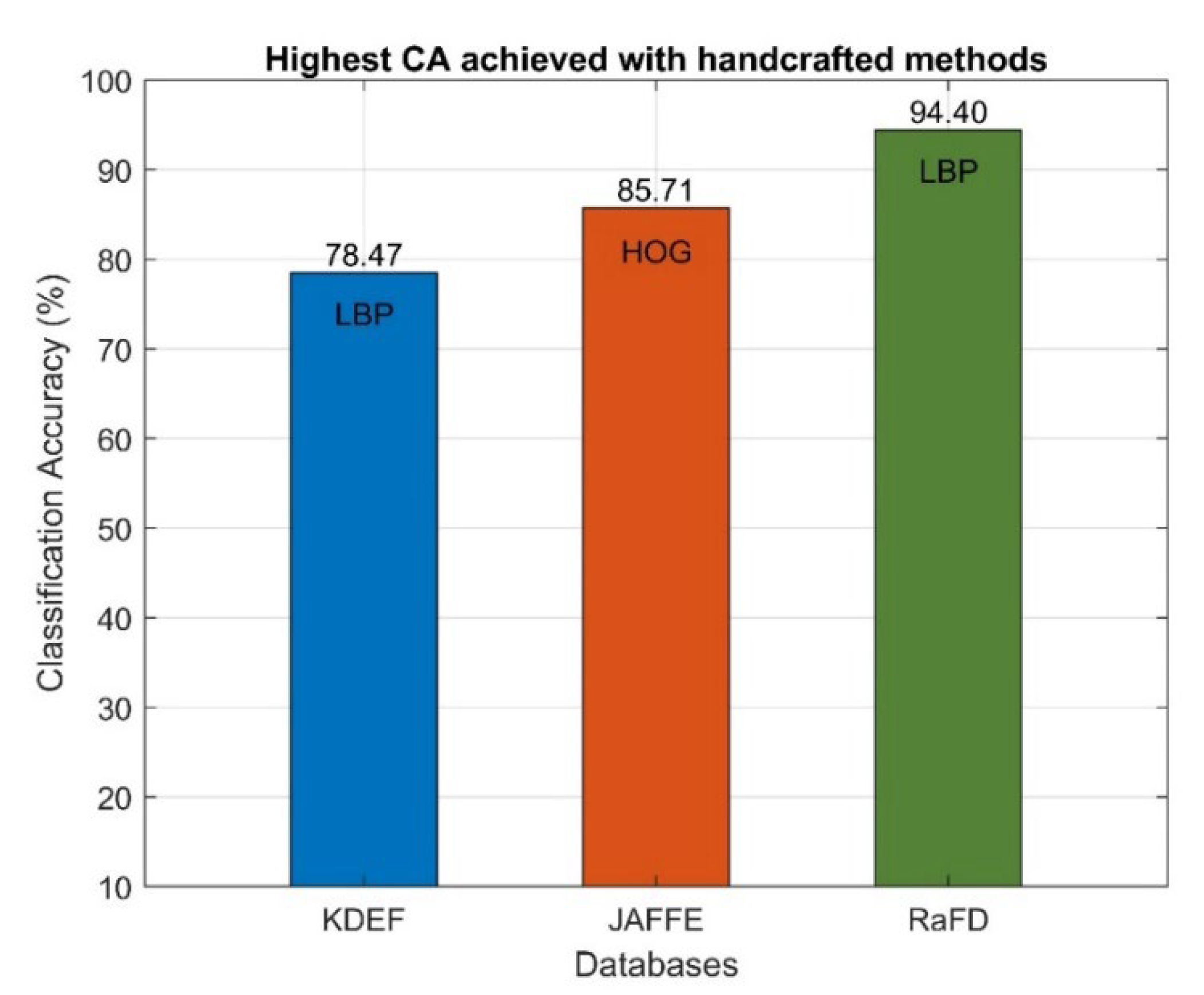
- LBP technique gives significantly improved classification accuracy compared to HOG in all databases, except for the JAFFE database;
- The highest classification accuracy for each technique and database is achieved with the same feature size;
- The downsizing of the images and cells (so that the feature is the same size) improves the classification accuracy up to downsizing by two for all databases. Specifically, the image reduction by a factor of two resulted in improved classification results with the HOG method for all databases. The results are improved only for KDEF and JAFFE databases with the LBP method.
4.2. Extract Features with CNNs
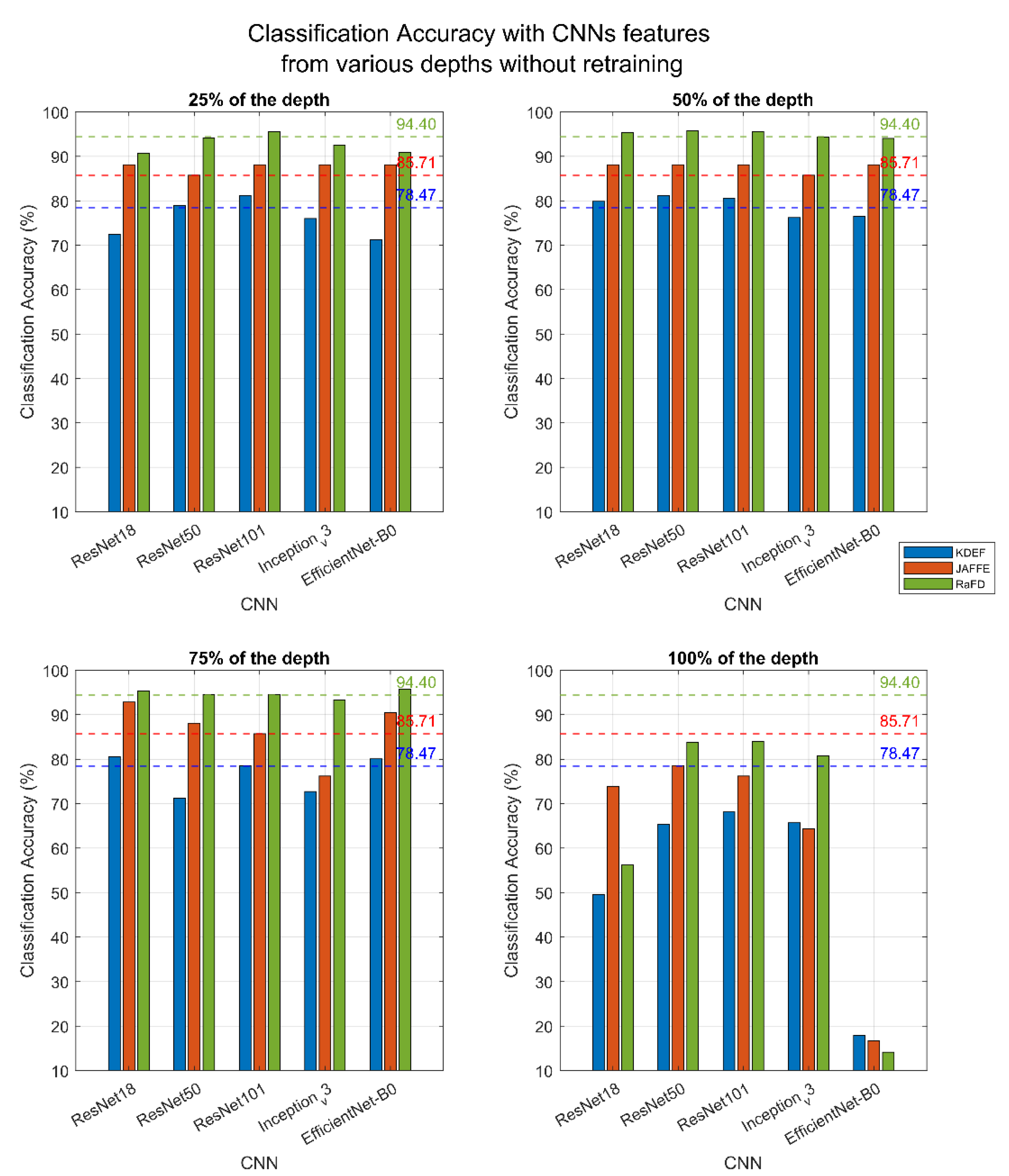
4.2.1. Extract Features without Retraining
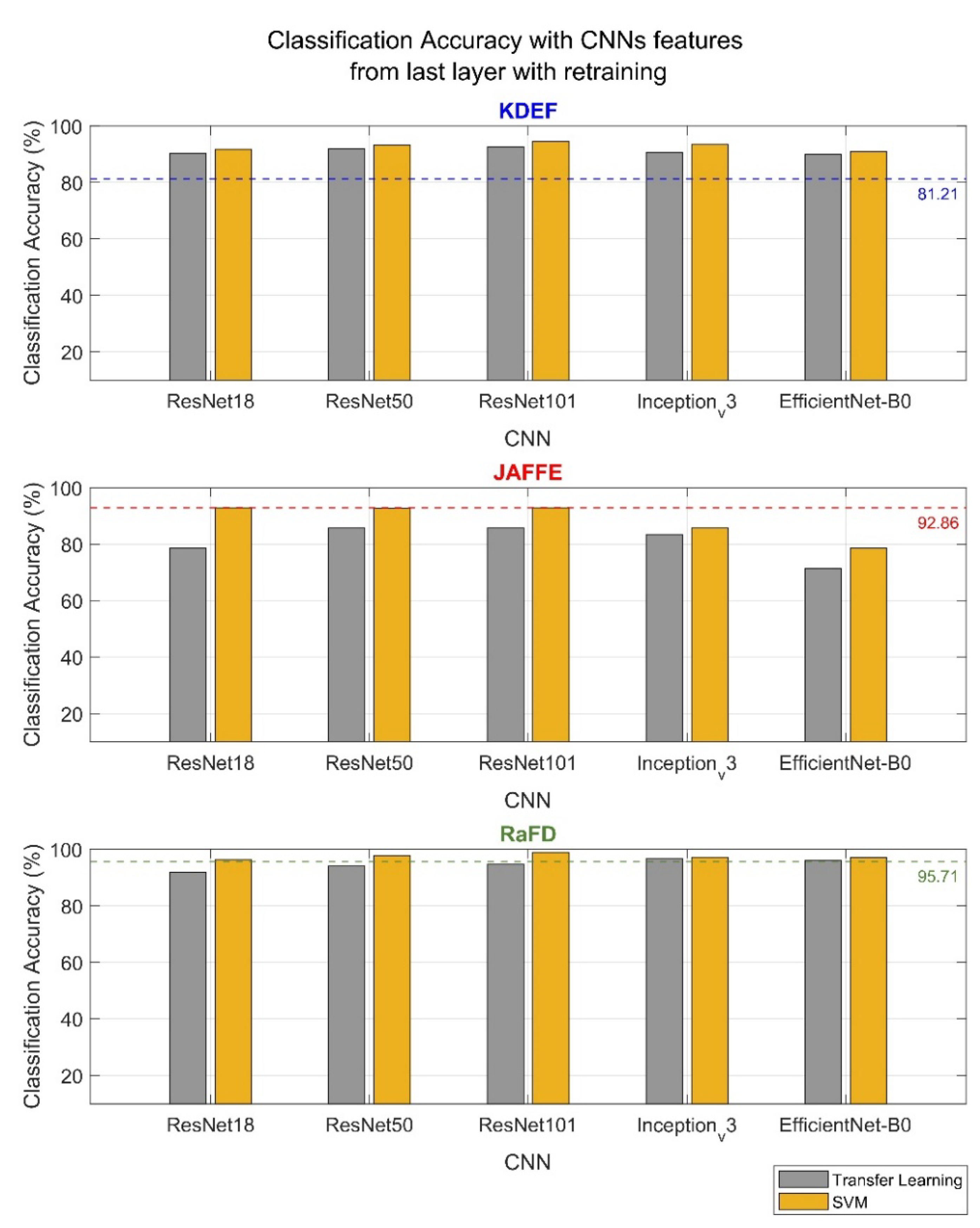
4.2.2. Extract Features with Retrained CNNs
- Optimizer is set to the stochastic gradient descent with momentum (SGDM) algorithm to minimize the loss function. In [45], SGDM appears to converge slower but generalizes better than the adaptive moment estimation (Adam) algorithm;
- The learning rate is equal to 0.001, meaning that small correction steps occur in each iteration;
- Since the JAFFE dataset is relatively small (213 images), the mini batch size was set equal to 10, so there is a sufficient number of iterations for weight calculation. The maximum number of epochs was set to 15 so that in combination with;
- The validation patience was set to 2 to check the intermediate values of epochs that are sufficient for retraining. Especially for JAFFE, we did not apply the hyper-parameter of validation patience as it is a small set, and we let the training be performed for all 15 epochs.
- (A)
- By extracting the image features from the last (deepest) layer and feeding an SVM classifier with them. In this way, we examine the features in terms of their classification quality before and after retraining.
- (B)
- By transfer learning. That is, after the fine-tuning of the last layers of each network and the replacement of the outputs with the classes of each database, the classification is performed by the network itself. This way, we compare the classifiers, i.e., SVM and CNNs.
- Regarding features, retraining makes sense in sets with numerous files. Especially in KDEF, we observe a significant increase in classification accuracy, while in RaFD, which was already high, it increased slightly. For JAFFE, a small database, we see that network retraining is of no benefit as only the ResNets reach the previous maximum (with SVM);
- Regarding networks and their respective architectures and methods, ResNets deliver higher classification rates, and the deeper the network, the higher the classification accuracy. The Inception_v3 technique follows with results similar to those of ResNet50 for the databases of KDEF and RaFD. Last, the EfficientNet-B0 is performing well only with the most extensive database RaFD, whereas the smallest database, JAFFE, remarks the lowest classification accuracy of all networks;
- As for the classifiers, in all cases, the SVM gives better results than the inbuilt classifier of the CNN.
- For the KDEF database, the classification accuracy reached 94.59% with ReseNet101 (an improvement of 13.4%). ResNet50 and Inception_v3 also marked a significant improvement in the classification rate, by 12.1% and 12.3%, respectively, in less time;
- For the JAFFE database, the retraining of the networks did not lead to higher results. The classification rate reached the previous level of 92.86% but with the increased time required for the retraining process;
- For the RaFD database, classification accuracy was increased by 3.17%, reaching 98.88%, with ResNet101 being the highest (in terms of classification accuracy) of all networks.
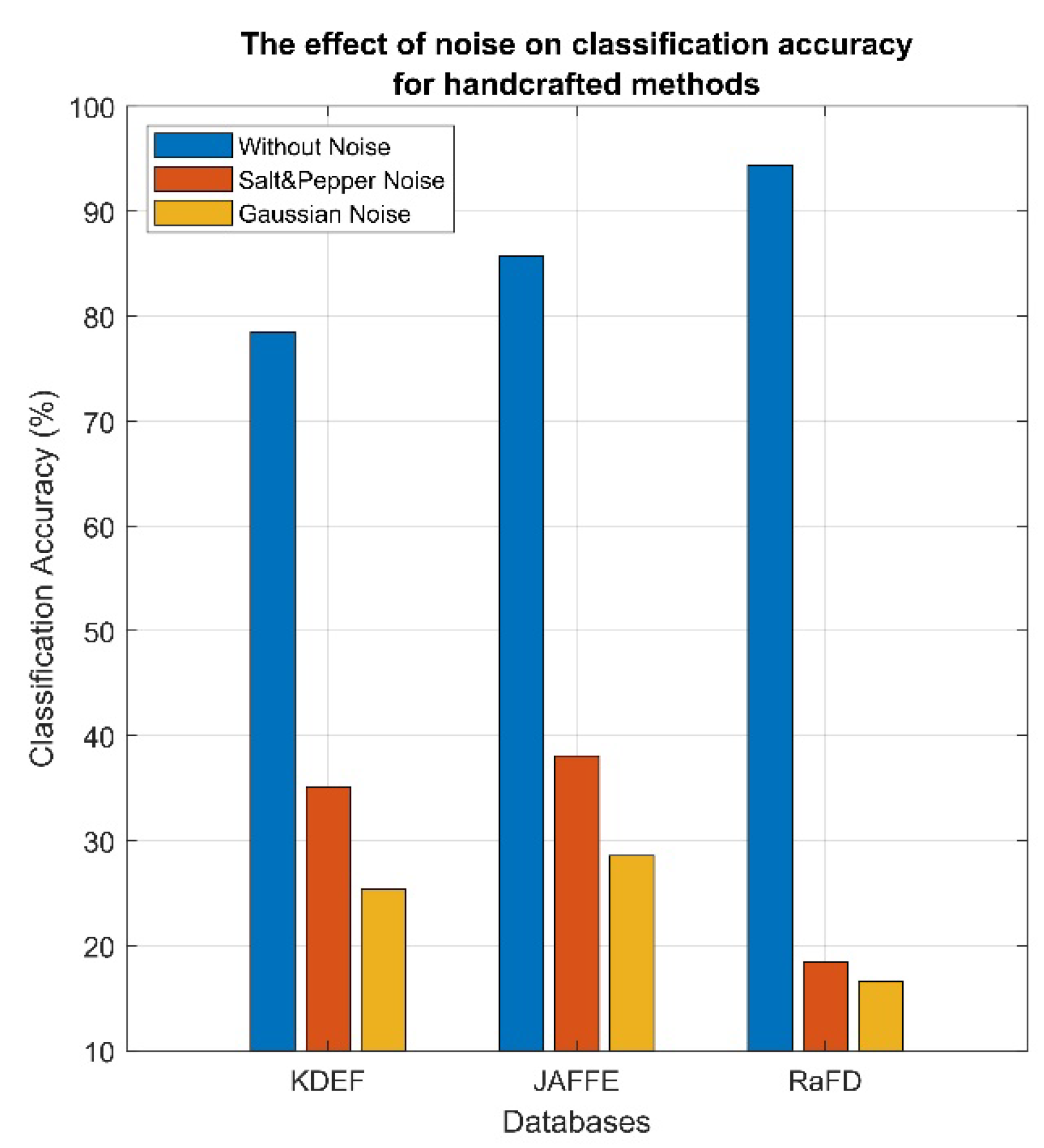
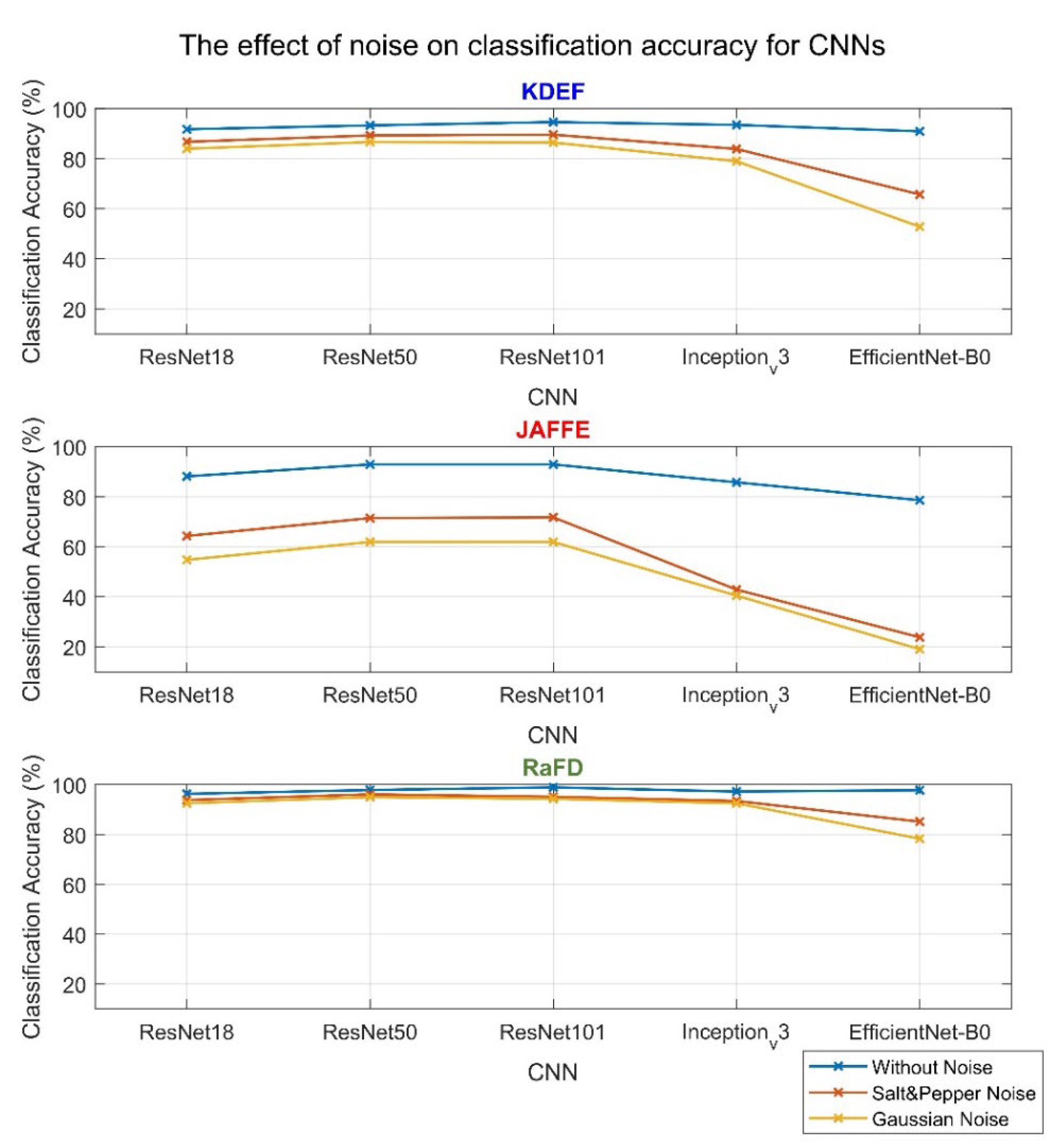
5. Robustness to Noise
- All CNNs are more robust (i.e., their classification accuracy is less severely affected by noise) in salt and pepper noise than in Gaussian noise.
- The performance among the networks keeps the same trend in all cases of the databases.
- Low-resolution grayscale JAFFE images appear more affected than KDEF and RaFD color images. In addition, RaFD high-resolution images are less affected by noise.
- The CNNs most affected by corrupted images are EfficientNet-B0 and Inception_v3, with the former being the less robust.
- The most robust network that is the one that, in all cases of the databases, the distance of the results of the classification accuracy between clear and corrupted images is the smallest is ResNet50.
6. Conclusions
7. Future Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BoVW | Bag-Of-Visual-Words |
| BRIEF | Binary Robust Independent Elementary Features |
| CBD | Compact Binary Descriptor |
| CNN | Convolutional Neural Network |
| DCT | Discrete Cosine Transform |
| FER | Facial Expression Recognition |
| HOG | Histogram of Orient Gradients |
| JAFFE | Japanese Female Facial Expression |
| KDEF | Karolinska Directed Emotional Faces |
| kNN | k-Nearest Neighbors |
| LFW | Labeled Faces in the Wild |
| LDA | Linear Discriminant Analysis |
| LBP | Local Binary Patterns |
| LPQ | Local Phase Quantization |
| LTP | Local Ternary Pattern |
| ORB | Oriented Fast and Rotated Binary Robust Independent Elementary Features |
| PCA(N) | Principal Component Analysis (Network) |
| RaFD | Radboud Faces Database |
| ResNet | Residual Network |
| SIFT | Scale-Invariant Feature Transform |
| SURF | Speeded-Up Robust Feature |
| SGDM | Stochastic Gradient Descent with Momentum |
| SVM | Support Vector Machines |
References
- Picard, R.W. Affective Computing for HCI. HCI 1999, 1, 829–833. [Google Scholar]
- Sonawane, B.; Sharma, P. Review of automated emotion-based quantification of facial expression in Parkinson’s patients. Vis. Comput. 2021, 37, 1151–1167. [Google Scholar] [CrossRef]
- Mattavelli, G.; Barvas, E.; Longo, C.; Zappini, F.; Ottaviani, D.; Malaguti, M.C.; Papagno, C. Facial expressions recognition and discrimination in Parkinson’s disease. J. Neuropsychol. 2021, 15, 46–68. [Google Scholar] [CrossRef] [PubMed]
- Dhuheir, M.; Albaseer, A.; Baccour, E.; Erbad, A.; Abdallah, M.; Hamdi, M. Emotion recognition for healthcare surveillance systems using neural networks: A survey. In Proceedings of the 2021 International Wireless Communications and Mobile Computing (IWCMC), Harbin City, China, 28 June–2 July 2021; IEEE: New York, NY, USA, 2021; pp. 681–687. [Google Scholar]
- Kaushik, H.; Kumar, T.; Bhalla, K. iSecureHome: A deep fusion framework for surveillance of smart homes using real-time emotion recognition. Appl. Soft Comput. 2022, 122, 108788. [Google Scholar] [CrossRef]
- Du, G.; Wang, Z.; Gao, B.; Mumtaz, S.; Abualnaja, K.M.; Du, C. A convolution bidirectional long short-term memory neural network for driver emotion recognition. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4570–4578. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Facial action coding system. Environ. Psychol. Nonverbal Behav. 1978, 1, 97–114. [Google Scholar]
- Harris, C.; Stephens, M. A Combined Corner and Edge Detector. In Proceedings of the 4th Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; pp. 147–151. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Fusing Points and Lines for High Performance Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; pp. 1508–1511. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary Robust Independent Elementary Features. In Proceedings of the 11th European Conference on Computer Vision (ECCV), Heraklion, Crete, Greece, 5–11 September 2010; LNCS Springer: Berlin, Germany, 2010. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: New York, NY, USA, 2011; pp. 2564–2571. [Google Scholar]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE Features. In Proceedings of the Computer Vision—ECCV, Florence, Italy, 7–13 October 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7577, p. 214. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; IEEE: New York, NY, USA, 2005; pp. 886–893. [Google Scholar]
- Tareen, S.A.K.; Saleem, Z. A comparative analysis of sift, surf, kaze, akaze, orb, and brisk. In Proceedings of the International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 3–4 March 2018; IEEE: New York, NY, USA, 2018; pp. 1–10. [Google Scholar]
- Alhindi, T.J.; Kalra, S.; Ng, K.H.; Afrin, A.; Tizhoosh, H.R. Comparing LBP, HOG and deep features for classification of histopathology images. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: New York, NY, USA, 2018; pp. 1–7. [Google Scholar]
- Alshazly, H.; Linse, C.; Barth, E.; Martinetz, T. Handcrafted versus CNN features for ear recognition. Symmetry 2019, 11, 1493. [Google Scholar] [CrossRef]
- Lin, W.; Hasenstab, K.; Moura Cunha, G.; Schwartzman, A. Comparison of handcrafted features and convolutional neural networks for liver MR image adequacy assessment. Sci. Rep. 2020, 10, 20336. [Google Scholar] [CrossRef] [PubMed]
- Nanni, L.; Ghidoni, S.; Brahnam, S. Handcrafted vs. non-handcrafted features for computer vision classification. Pattern Recognit. 2017, 71, 158–172. [Google Scholar] [CrossRef]
- Zare, M.R.; Alebiosu, D.O.; Lee, S.L. Comparison of handcrafted features and deep learning in classification of medical X-ray images. In Proceedings of the Fourth International Conference on Information Retrieval and Knowledge Management (CAMP), Le Méridien Kota Kinabalu, Sabah, Malaysia, 26–28 March 2018; IEEE: New York, NY, USA, 2018; pp. 1–5. [Google Scholar]
- Agarwal, S.; Rattani, A.; Chowdary, C.R. A comparative study on handcrafted features v/s deep features for open-set fingerprint liveness detection. Pattern Recognit. Lett. 2021, 147, 34–40. [Google Scholar] [CrossRef]
- Abdullah, S.M.S.A.; Ameen, S.Y.A.; Sadeeq, M.A.; Zeebaree, S. Multimodal emotion recognition using deep learning. J. Appl. Sci. Technol. Trends 2021, 2, 52–58. [Google Scholar] [CrossRef]
- Georgescu, M.I.; Ionescu, R.T.; Popescu, M. Local learning with deep and handcrafted features for facial expression recognition. IEEE Access 2019, 7, 64827–64836. [Google Scholar] [CrossRef]
- Li, B.; Lima, D. Facial expression recognition via ResNet-50. Int. J. Cogn. Comput. Eng. 2021, 2, 57–64. [Google Scholar] [CrossRef]
- Zhang, H.; Jolfaei, A.; Alazab, M. A face emotion recognition method using convolutional neural network and image edge computing. IEEE Access 2019, 7, 159081–159089. [Google Scholar] [CrossRef]
- Ahmed, T.U.; Hossain, S.; Hossain, M.S.; ul Islam, R.; Andersson, K. Facial expression recognition using convolutional neural network with data augmentation. In Proceedings of the Joint 8th International Conference on Informatics, Electronics & Vision (ICIEV) and 3rd International Conference on Imaging, Vision & Pattern Recognition (icIVPR), Spokane, WA, USA, 30 May–2 June 2019; IEEE: New York, NY, USA, 2019; pp. 336–341. [Google Scholar]
- Zang, H.; Foo, S.Y.; Bernadin, S.; Meyer-Baese, A. Facial Emotion Recognition Using Asymmetric Pyramidal Networks With Gradient Centralization. IEEE Access 2021, 9, 64487–64498. [Google Scholar] [CrossRef]
- Li, K.; Jin, Y.; Akram, M.W.; Han, R.; Chen, J. Facial expression recognition with convolutional neural networks via a new face cropping and rotation strategy. Vis. Comput. 2020, 36, 391–404. [Google Scholar] [CrossRef]
- Lundqvist, D.; Flykt, A.; Öhman, A. The Karolinska Directed Emotional Faces—KDEF [CD-ROM]; Department of Clinical Neuroscience, Psychology section, Karolinska Institutet: Stockholm, Sweden, 1998. [Google Scholar]
- Lyons, M.J.; Kamachi, M.; Gyoba, J. Coding facial expressions with Gabor wavelets. arXiv 2020, arXiv:2009.05938. [Google Scholar]
- Langner, O.; Dotsch, R.; Bijlstra, G.; Wigboldus, D.H.J.; Hawk, S.T.; van Knippenberg, A. Presentation and validation of the Radboud Faces Database. Cogn. Emot. 2010, 24, 1377–1388. [Google Scholar] [CrossRef]
- Adouani, A.; Henia, W.M.B.; Lachiri, Z. Comparison of Haar-like, HOG and LBP approaches for face detection in video sequences. In Proceedings of the 16th International Multi-Conference on Systems, Signals & Devices (SSD), Istanbul, Turkey, 21–24 March 2019; IEEE: New York, NY, USA, 2019; pp. 266–271. [Google Scholar]
- Chen, T.; Gao, T.; Li, S.; Zhang, X.; Cao, J.; Yao, D.; Li, Y. A novel face recognition method based on fusion of LBP and HOG. IET Image Process. 2021, 15, 3559–3572. [Google Scholar] [CrossRef]
- Sun, M.; Li, D. Smart face identification via improved LBP and HOG features. Internet Technol. Lett. 2021, 4, e229. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR 97; pp. 6105–6114. [Google Scholar]
- Tsalera, E.; Papadakis, A.; Samarakou, M. Novel principal component analysis-based feature selection mechanism for classroom sound classification. Comput. Intell. 2021, 37, 1827–1843. [Google Scholar] [CrossRef]
- Thanh Noi, P.; Kappas, M. Comparison of random forest, k-nearest neighbor, and support vector machine classifiers for land cover classification using Sentinel-2 imagery. Sensors 2017, 18, 18. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Tsalera, E.; Papadakis, A.; Samarakou, M. Comparison of Pre-Trained CNNs for Audio Classification Using Transfer Learning. J. Sens. Actuator Netw. 2021, 10, 72. [Google Scholar] [CrossRef]
- Zhou, P.; Feng, J.; Ma, C.; Xiong, C.; Hoi, S. Towards theoretically understanding why sgd generalizes better than adam in deep learning. arXiv 2020, arXiv:2010.05627. [Google Scholar]
- Kumain, S.C.; Singh, M.; Singh, N.; Kumar, K. An efficient Gaussian noise reduction technique for noisy images using optimized filter approach. In Proceedings of the First International Conference on Secure Cyber Computing and Communication (ICSCCC), Jalandhar, India, 15–17 December 2018; IEEE: New York, NY, USA, 2018; pp. 243–248. [Google Scholar]
- Fu, B.; Zhao, X.; Song, C.; Li, X.; Wang, X. A salt and pepper noise image denoising method based on the generative classification. Multimed. Tools Appl. 2019, 78, 12043–12053. [Google Scholar] [CrossRef]
- Awad, A. Denoising images corrupted with impulse, Gaussian, or a mixture of impulse and Gaussian noise. Eng. Sci. Technol. Int. J. 2019, 22, 746–753. [Google Scholar] [CrossRef]
- Karahan, S.; Yildirum, M.K.; Kirtac, K.; Rende, F.S.; Butun, G.; Ekenel, H.K. How image degradations affect deep CNN-based face recognition? In Proceedings of the International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 21–23 September 2016; IEEE: New York, NY, USA, 2016; pp. 1–5. [Google Scholar]
- Ziyadinov, V.; Tereshonok, M. Noise immunity and robustness study of image recognition using a convolutional neural network. Sensors 2022, 22, 1241. [Google Scholar] [CrossRef] [PubMed]
- Ren, H. A comprehensive study on robustness of HOG and LBP towards image distortions. J. Phys. Conf. Ser. 2019, 1325, 012012. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Files | Classes | Poses | Color | Pixels (Width × Height) | Format |
|---|---|---|---|---|---|---|
| KDEF | 4900 | 7 | 5 | true color | 562 × 762 | jpeg |
| JAFFE | 213 | 7 | 1 | grayscale | 256 × 256 | tiff |
| RaFD | 8040 | 8 | 5 | true color | 681 × 1024 | jpeg |
| LBP | KDEF | JAFFE | RaFD | |||
|---|---|---|---|---|---|---|
| Cell Size | Feature Size | CA (%) | Feature Size | CA (%) | Feature Size | CA (%) |
| 8 × 8 | 392,352 | 68.84 | 60,416 | 78.57 | 641,920 | 88.50 |
| 16 × 16 | 97,055 | 73.65 | 15,104 | 76.16 | 158,592 | 92.66 |
| 32 × 32 | 23,069 | 72.32 | 3776 | 50.00 | 39,648 | 94.40 |
| HOG | KDEF | JAFFE | RaFD | |||
|---|---|---|---|---|---|---|
| Cell Size | Feature Size | CA (%) | Feature Size | CA (%) | Feature Size | CA (%) |
| 8 × 8 | 233,496 | 55.57 | 34,596 | 80.95 | 384,048 | 69.84 |
| 16 × 16 | 56,304 | 59.65 | 8100 | 80.95 | 92,988 | 74.63 |
| 32 × 32 | 12,672 | 56.49 | 1764 | 83.33 | 22,320 | 76.12 |
| KDEF | JAFFE | RaFD | ||||
|---|---|---|---|---|---|---|
| Cell Size | LBP | HOG | LBP | HOG | LBP | HOG |
| 4 × 4 | 70.07% | 59.65% | 78.57% | 84.21% | 85.76% | 73.82% |
| 8 × 8 | 78.47% | 69.92% | 77.57% | 84.71% | 92.16% | 77.67% |
| 16 × 16 | 76.20% | 61.08% | 76.19% | 85.71% | 94.40% | 78.30% |
| Handcrafted Methods | CNNs | |||||
|---|---|---|---|---|---|---|
| Database | CA (%) | Technique | Time (s) | CA (%) | CNN and Depth | Time (s) |
| KDEF | 78.47 | (LPB 8 × 8) | 1623 | 81.21 | (ResNet50, 50% depth) | 1214 |
| JAFFE | 85.71 | (HOG 16 × 16) | 5 | 92.86 | (ResNet18, 75% depth) | 55 |
| RaFD | 94.40 | (LPB 16 × 16) | 3746 | 95.71 | (ResNet50, 50% depth) | 2988 |
| Database | Total Time (s) | ||||
|---|---|---|---|---|---|
| ResNet18 | ResNet50 | ResNet101 | Inception_v3 | EfficientNet-B0 | |
| KDEF | 2953 | 6642 | 8802 | 6764 | 19,808 |
| JAFFE | 131 | 327 | 683 | 638 | 1031 |
| RaFD | 3604 | 10,030 | 22,347 | 13,014 | 32,897 |
| ResNet18 | ResNet50 | ResNet101 | Inception_v3 | EfficientNet-B0 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Salt and Pepper | Gaussian | Salt and Pepper | Gaussian | Salt and Pepper | Gaussian | Salt and Pepper | Gaussian | Salt and Pepper | Gaussian | |
| KDEF | 5.46 | 8.47 | 4.28 | 7.12 | 5.30 | 8.65 | 10.27 | 15.51 | 27.75 | 41.91 |
| JAFFE | 27.03 | 37.84 | 23.08 | 33.34 | 23.08 | 33.34 | 49.99 | 52.77 | 69.70 | 75.75 |
| RaFD | 2.59 | 3.94 | 1.78 | 2.92 | 3.83 | 4.65 | 3.90 | 4.86 | 12.91 | 19.91 |
| Database | Salt and Pepper Noise | Gaussian Noise |
|---|---|---|
| KDEF | 55.22 | 67.72 |
| JAFFE | 55.55 | 66.67 |
| RaFD | 80.50 | 82.48 |
| Database | Method | CA (%) | Time (s) |
|---|---|---|---|
| KDEF | Handcrafted: LPB | 78.47 | 1623 |
| Direct Extraction from the 50% of ResNet50 | 81.21 | 1214 | |
| Transfer Learning on ResNet101 | 94.59 | 8802 | |
| JAFFE | Handcrafted: HOG | 85.71 | 5 |
| Direct Extraction from the 75% of ResNet18 | 92.86 | 55 | |
| Transfer Learning all ResNets | 92.86 | 131,327,683 | |
| RaFD | Handcrafted: LPB | 94.40 | 3746 |
| Direct Extraction from the 50% ResNet50 | 95.71 | 2988 | |
| Transfer Learning on ResNet101 | 98.88 | 22,347 |
| Database Type | Criterion | Selection |
|---|---|---|
| Small Size Low Quality Straight Poses | High Classification Accuracy | Direct extraction from 75% of the depth of ResNet18 |
| Short Computational Time | HOG | |
| Medium Size High Quality Multi-angle Images | High Classification Accuracy | Transfer Learning in ResNet101 |
| Short Computational Time | Direct extraction from 50% of the depth of ResNet50 | |
| Large Size High Quality Multi-angle Images | High Classification Accuracy | Transfer Learning in ResNet101 |
| Short Computational Time | Direct extraction from 50% of the depth of ResNet50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsalera, E.; Papadakis, A.; Samarakou, M.; Voyiatzis, I. Feature Extraction with Handcrafted Methods and Convolutional Neural Networks for Facial Emotion Recognition. Appl. Sci. 2022, 12, 8455. https://doi.org/10.3390/app12178455
Tsalera E, Papadakis A, Samarakou M, Voyiatzis I. Feature Extraction with Handcrafted Methods and Convolutional Neural Networks for Facial Emotion Recognition. Applied Sciences. 2022; 12(17):8455. https://doi.org/10.3390/app12178455
Chicago/Turabian StyleTsalera, Eleni, Andreas Papadakis, Maria Samarakou, and Ioannis Voyiatzis. 2022. "Feature Extraction with Handcrafted Methods and Convolutional Neural Networks for Facial Emotion Recognition" Applied Sciences 12, no. 17: 8455. https://doi.org/10.3390/app12178455
APA StyleTsalera, E., Papadakis, A., Samarakou, M., & Voyiatzis, I. (2022). Feature Extraction with Handcrafted Methods and Convolutional Neural Networks for Facial Emotion Recognition. Applied Sciences, 12(17), 8455. https://doi.org/10.3390/app12178455